人文情報学月報第100号
ISSN 2189-1621 / 2011年8月27日創刊
目次
- 《巻頭言》「『人文情報学月報』100号を迎えて」
:一般財団法人人文情報学研究所 - 《連載》「Digital Japanese Studies 寸見」第56回
「デジタル情報保存連合のデジタル資料保存支援」
:国文学研究資料館古典籍共同研究事業センター - 《連載》「欧州・中東デジタル・ヒューマニティーズ動向」第18回
「概念辞書・「コプト語 WordNet」の開発」
:ゲッティンゲン大学 - 人文情報学イベント関連カレンダー
- イベントレポート「18世紀研究における DH の広がり:第15回国際十八世紀学会(ISECS 2019)に参加して 第4回:大学での教育実践と新たな DH プロジェクトの支援」
:お茶の水女子大学大学院人間文化創成科学研究科 - イベントレポート「TEI2019参加報告(後編):セマンティック記述とリンクトデータ構築の動き」
小川潤:東京大学大学院人文社会系研究科 - 編集後記
《巻頭言》「『人文情報学月報』100号を迎えて」
人文情報学に関するメールマガジンの刊行を着想したのは、2011年に入ってからまもなくのことだった。この頃筆者は、国際的に活動する関連研究者の方々とともに、国際デジタル・ヒューマニティーズ学会連合(ADHO)において、情報処理学会人文科学とコンピュータ研究会をはじめとする日本での研究の蓄積を国際的に認知させるべく様々な活動を進めていた。そして、現在は日本での ADHO 構成学会となっている日本デジタル・ヒューマニティーズ学会の前身にあたる人文情報学推進協議会の設立記念シンポジウム(2011年9月、於大阪大学豊中キャンパス)の開催を控えていた。世界に伍する日本の様々な人文情報学研究を国際的に知らしめ、相互に交流しやすくするための窓口を設けることは、国内外の双方を益することが明らかであった。
一方で、そのような窓口が機能するためには、海外の先進事例の情報のみならず、日本の先進事例についても、日本の研究者・実践者の間で共有できるようにする必要があった。海外はともかく、日本におけるこの種の情報については、いくつかの関係学会・研究会の論文誌や研究報告に一通り目を通せばほぼ網羅できるものの、実際のところ、学会研究会等で発表を聞く限りでは、それはなかなか容易なことではなかったようである。人文情報学の研究プロジェクトの多くが、先行事例の調査よりもむしろ、目の前にある資料と人文学研究者の関心を起点として始まり展開していくことを考えると、これは致し方ないことであるようにも思われた。そして、そうであるなら、情報収集を容易にすることが状況の改善に大きく寄与するはずであると考えた。
まずは Web サイトを作成することを検討し、過去の関連論文検索機能を Omeka で構築してみたものの、いきなりこの種の論文を読むことのハードルの高さや、定期的な更新の手間を考えたとき、実効性がどれくらいあるのかということが疑問になってしまい、別の方法も検討してみた。結果として、個々人のメールボックスにそれほど長くなく比較的わかりやすい内容が一定量定期的に届けられるメールマガジンという形式が有効ではないかと考えた。さらに、それを Web サイトに掲載すれば、Google 検索でも容易に発見してもらえるのではないかと期待した。
しかしながら、メールマガジンの発行とは、それを介したある種のコミュニティを形成することでもあり、2011年時点でまったくノウハウのない状態から開始するのは困難であるように思われた。そこで、インターネットの学術利用について90年代からメールマガジン ACADEMIC RESOURCE GUIDE(ARG)を刊行していた岡本真氏のアカデミック・リソース・ガイド株式会社にご協力を賜り、2011年8月に創刊となった次第である。
当初は、ARG を範としつつ、巻頭言・イベントカレンダー/レポートという形式をとり、巻頭言は一定の実績のある主に若手・中堅の研究者や実践者の方々にお願いした。イベントカレンダーは、共同管理する Google カレンダーに記載し、それを取り出して転載するという ARG のワークフローを踏襲させていただいた。イベントレポートは、当初は筆者が書くことも多かったが、筆者が参加したイベントで書いてくれそうな人に依頼してみたり、参加できなかったイベントでも主催者側にお願いして寄稿者を探していただいたりしたこともあった。
その後、特別寄稿や連載といった形式も採り入れ、海外研究者による講演録や寄稿の翻訳記事も掲載するなど、海外動向についても様々な角度からの情報提供を心がけてきた。若手の執筆の機会を増やすことも目的の一つとしており、東京大学大学院人文社会系研究科人文情報学拠点において2012年より授業が開始され、また、当研究所が筑波大学大学院人文社会科学研究科のインターンシップを受け入れたこともあり、大学院生の執筆者が徐々に増えてくることとなった。
連載としては、菊池信彦氏が「Digital Humanities/Digital History の動向」として第18号から第42号まで国内外の人文情報学の動向を紹介してくださった後、続いて第53号までは「西洋史 DH の動向とレビュー」として、主に西洋史に関する人文情報学の動向紹介ということで長期にわたって寄稿してくださった。この連載のおかげで、誌面として充実したものを提供できるようになった。これに若干重なる形で第45号より開始された岡田一祐氏の連載「Digital Japanese Studies 寸見」は、現在もその忌憚のない筆致とともに継続しており、2019年8月にはこれをまとめて加筆修正されたものが『ネット文化資源の読み方・作り方:図書館・自治体・研究者必携ガイド』として文学通信より刊行されるに至った。さらに第81号からは、関西大学 KU-ORCAS プロジェクトに移籍した菊池氏による「東アジア研究と DH を学ぶ」と、人文情報学の最先端の地の一つであるゲッティンゲン大学でコプト語文献学・言語学の人文情報学プロジェクトに従事する宮川創氏による「欧州・中東デジタル・ヒューマニティーズ動向」の連載が開始された。前者は第92号で終了したものの、近年盛り上がりつつある東アジア研究における人文情報学を紹介する連載として時宜を得たものであった。後者は、宮川氏の旺盛な好奇心ともあいまって、日本語で読むことのできる最先端の欧州の人文情報学の動向という、欧州・中東研究者のみならず、人文情報学に関わる人々全体にとって貴重な情報源となっている。
記事の内容が詳細化するにつれて、画像の取り込みと UTF-8化を避けることが難しい状況となり、人文情報学研究所の単独刊行となった第83号からは、画像を取り込むべく HTML 形式での配信とし、さらに、UTF-8対応のために配信システムをまぐまぐから切り替えた。500名以上の方が切り替えにお付き合いくださったことには深く感謝したい。
100号に渡って刊行された人文情報学月報は、多くの執筆者と読者、そして関係者の方々により創られてきたものである。ここに寄稿した記事を介して新しい仕事が来たという若手の話も聞くことがあり、わかりやすい情報を提供する媒体という枠を超えて、人文情報学に関する情報流通の場としても機能しつつあるようである。とはいえ、長期にわたって継続するためには、手を広げすぎないことも重要である。幸い、最近は、上述の岡田氏の本以外にも、後藤真・橋本雄太編『歴史情報学の教科書:歴史のデータが世界をひらく』(文学通信、2019)や京都大学人文科学研究所共同研究班「人文学研究資料にとっての Web の可能性を再探する」編『日本の文化をデジタル世界に伝える』(樹村房、2019)など、この種のテーマの書籍が刊行されるようになってきており、特に前者はオープンアクセスとしても公開されている。したがって、こちらはあくまでもメールマガジンとしての分をわきまえていくことを忘れないようにしつつ、もう100号、さらにはそれ以上継続していければと願っている。
なお、これまでの総括をするのであれば、テキストマイニングによる分析のようなことをすれば当メールマガジンの趣旨にはふさわしいかもしれない。しかしこれは練習台としてちょうど有用なものであるように思われるので、そういったことを志す他の方々にお譲りしたい。筆者としては、そういった分析の成果をどこかで目にすることができれば幸甚である。
執筆者プロフィール
《連載》「Digital Japanese Studies 寸見」第56回
「デジタル情報保存連合のデジタル資料保存支援」
イギリスに拠点を置くデジタル情報保存連合(Digital Preservation Coalition: DPC)は、2019年11月7日に「絶滅の恐れのあるデジタル種の世界的リスト:BitList」(The Global List of Digitally Endangered Species: BitList)を公表した[1]。DPC は、2002年に設立されたデジタル情報保存のための互助連合で[2]、会員機関におけるデジタル資料長期保存に関する技術支援を基本的な目的とするが、これまでも Technology Watch Reports[3]や Digital Preservation Handbook[4]を公表したり、Digital Preservation Awards[5]や World Digital Preservation Day[6]を開催するなど、公の理解の推進にも意欲的である。
DPC は、現在、27の正会員と多数の準会員からなる。会員のほとんどが欧州、とりわけイギリスの組織で、そのほかに国連等の国際組織、若干のアメリカとオーストラリアの組織と、わずかなアジアからの加盟組織からなる。公的機関のみならず、ロイズ銀行や BT(ブリティッシュテレコム)、バカルディ=マルティーニ・グループなどのアーカイブ部門も加わる。アジアからはカタール国立図書館が加盟するのみである[7]。
このたび公開された BitList は、2017年の試行版を引き継いだ第2版である[8]。初版同様、DPC 会員からひろく危機的な保存形態を挙げてもらい、これまでの版のものも含めて完全に見直したのが第2版であるという。個人レベルで保管される研究データが危機的状況にあるというのは、意外性もないと思うが、一般に安全とされる PDF/A が適正に使用されていないために脆弱であることが指摘されるなど、この手のものに詳しいつもりでも思い込みを見直すうえで見通す価値はあろうかと思われる。
本年追加されたものには、さきに述べた PDF/A のほか、Adobe Flash などの近年急激に避けられつつあるメディアフォーマットが絶滅寸前とされたものなどがある[9]。このほかにも、脆弱であるという評価ではあるもののいわゆるクラウドサーバー関連のものが大量に追加され[10]、さいきん MH17便撃墜事件などでも注目を浴びた「オープン・ソース・インテリジェンス」(公開情報による諜報)関連の情報源などが「実用上絶滅」扱いとなっている[11]点なども、「フェイク」時代をかなり意識したランク付けとなっている。
DPC が本年公開した関連の文書も同時に見ておきたい。ひとつめは、2019年5月17日に公表された組織の意思決定上でデジタル資料保存の位置づけの訴えを手助けするデジタル保存のための執行部対策ガイド(Executive Guide on Digital Preservation)で[12]、これは UNESCO と共同で作成されたものであるという。UNESCO は、2015年にデジタル形式を含む記録遺産の保護及びアクセスに関する勧告を採択しており[13]、その一環としてUNESCO の世界の記憶プログラムおよびその PERSIST プロジェクト(将来にわたってデジタル情報へのアクセスを確保することを目的としたプロジェクト)と共同して本ガイドを作成することとなったものである。本ガイドを用いて、資料保存担当者が、上層部になにを必要とするのか説明する材料となることが期待されている。
もうひとつは、2019年9月19日に iPRES2019で公表された DPC 迅速評価モデル(DPC Rapid Assessment Model)で[14]、こちらはイギリス原子力廃止措置機関(Nuclear Decommissioning Authority)と共同で設計された。これは、やはり資料保存担当者が、みずからの(機関の)責務(現況と目指すべき地点、ロードマップ)を把握するために作られたツールで、自己評価式のものである。より高得点が望ましいとはいえ、外部評価ではないので、できること・すべきこと・できないこと・すべきでないことを整理するものと見るべきである(そのため、△はないとのことである)。
これは、Digital Preservation Awards 2014受賞の著でもあるAdrian Brown氏の『実用的デジタル情報保存』[15]で提示された「デジタル情報保存成熟モデル」を下敷きにして作成されたもので、長期的価値のあるどのような資源にも対応でき、どのような分野のどのような大きさの機関でもそれぞれにあった選択を可能とするものを目指したものである。本モデルを利用するためには DPC 会員である必要はないが、DPC会員間では情報共有がされ、追加情報が得られるとのことである。
DPC の文書は、会員組織に奉仕する目的との兼ね合いもあるのだろうが、具体的な対策には踏み込まず、考え方の指針を示すに留まるものが多いようである。本文書においても、どのような点で脆弱であり、どのような対応をすべきかについては、雑多な箇条書きに留まり、具体的にてもとにある資料をそれらの観点からすぐに評価できるようにはできていない。それ自体は個別的な事柄ではあり、自信がないばあいは DPC などの専門家に支援を仰ぐべしということなのであろう。
これらの文書では、戦争や自然災害、あるいは資源枯渇などといった問題やライセンスなど、データ保存の技術外の側面については特筆されるところが少ない。しかしながら、おりしも、CreativeCommons 有志が CC ライセンスの文化財データへの野放図な適用に理解を示しつつ、けっきょくはよからぬことを招くとの懸念を示したときでもあり[16]、守り手としての社会的責務がそのつど守り手になにをすべきか教えるものであることを痛感する。
The Global List of Digitally Endangered Species (2019) - Digital Preservation Coalition https://dpconline.org/news/the-global-list-of-digitally-endangered-species-2019
Digitally Endangered Species - Digital Preservation Coalition https://www.dpconline.org/our-work/bit-list
BitList 2018: The Global List of Digitally Endangered Species - Digital Preservation Coalition https://www.dpconline.org/blog/idpd/bitlist-2018-the-global-list-of-digitally-endangered-species
以下も関係がある。
Completed investigations based on open source intelligence sources - Digital Preservation Coalition https://www.dpconline.org/our-work/bit-list/endangered/bitlist2019-osint-completed
UNESCO and DPC release Executive Guide on Digital Preservation https://en.unesco.org/news/unesco-and-dpc-release-executive-guide-digital-preservation
Executive Guide on Digital Preservation - Digital Preservation Coalition https://dpconline.org/our-work/dpeg-home
DPC launches Rapid Assessment Model (DPC RAM) - Digital Preservation Coalition https://www.dpconline.org/news/dpc-ram-launch
Introducing the DPC RAM - Digital Preservation Coalition https://www.dpconline.org/blog/introducing-the-dpc-ram
DPC Rapid Assessment Model - Digital Preservation Coalition https://dpconline.org/our-work/dpc-ram
DPA 2014: Practical Digital Preservation: a how-to guide for organizations of any size, Adrian Brown - Digital Preservation Coalition https://www.dpconline.org/knowledge-base/preservation-lifecycle/advocacy
《連載》「欧州・中東デジタル・ヒューマニティーズ動向」第18回
「概念辞書・「コプト語 WordNet」の開発」
WordNet とは、同義語のまとまりである synset をベースに下位語、上位語、全体語、部分語など様々な語彙素同士の関係性を記述した概念辞書と呼ばれるデータベースであり、元祖は、プリンストン大学認知科学研究所が開発した英語の Princeton WordNet である。近年では、Global WordNet Association(http://globalwordnet.org/[1]) を中心に、英語以外の言語で開発が進み、昨今は特に少数言語や古典語でもその数が増えてきている。この WordNet を使えば、例えば、類義語や同義語などの検索ができるほか、様々な用途で応用されている[2]。この WordNet が最もよく用いられているであろう分野は語義曖昧性解消(Word Sense Disambiguation)である。
ノルウェーのオスロ大学の情報学部の准教授であるローラ・スローター(Laura Slaughter)、シンガポールの南洋工科大学の博士課程学生であるルイス・モルガード・ダ・コスタ(Luis Morgado da Costa)、そして筆者は、古代末期に多数の重要な文献が書かれた、エジプトの古典語であるコプト語(コプト・エジプト語)の WordNet を開発している。なお、モルガード・ダ・コスタの指導教官は、日本語 WordNet[3]の開発で有名で、現在 Global WordNet Association を牽引している南洋工科大学准教授フランシス・ボンド(Francis Bond)である。
このコプト語 WordNet の成果は、ローラ・スローター、ルイス・モルガード・ダ・コスタ、宮川創、マルコ・ビュヒラー(Marco Büchler)、アミール・ゼルデス(Amir Zeldes)、ヒューゴ・ルンドハウグ(Hugo Lundhaug)、ハイケ・ベールマー(Heike Behlmer)によって、ポーランドのヴロツワフで開催された Global WordNet Conference 2019(https://gwc2019.clarin-pl.eu/)で発表された。その論文は、当学会のプロシィーディングスに掲載され、出版される予定である 。
コプト語 DH を促進させる KELLIA プロジェクト(http://kellia.uni-goettingen.de/)の枠組みで、Coptic SCRIPTORIUM(https://copticscriptorium.org/)と Thesaurus Linguae Aegyptiae(http://aaew.bbaw.de/tla/)の両プロジェクトによって、Crum のコプト語辞書[5]をベースとしたコプト語の辞書データが開発された。この辞書データは、Coptic Dictionary Online(https://coptic-dictionary.org/)として、正規表現を使って検索可能な形のウェブアプリとして公開されている。各語彙は、コプト語コーパスプロジェクトの Coptic SCRIPTORIUM とリンクされ、そのコーパス内での頻度やコンコーダンスを1クリックで見ることができる。
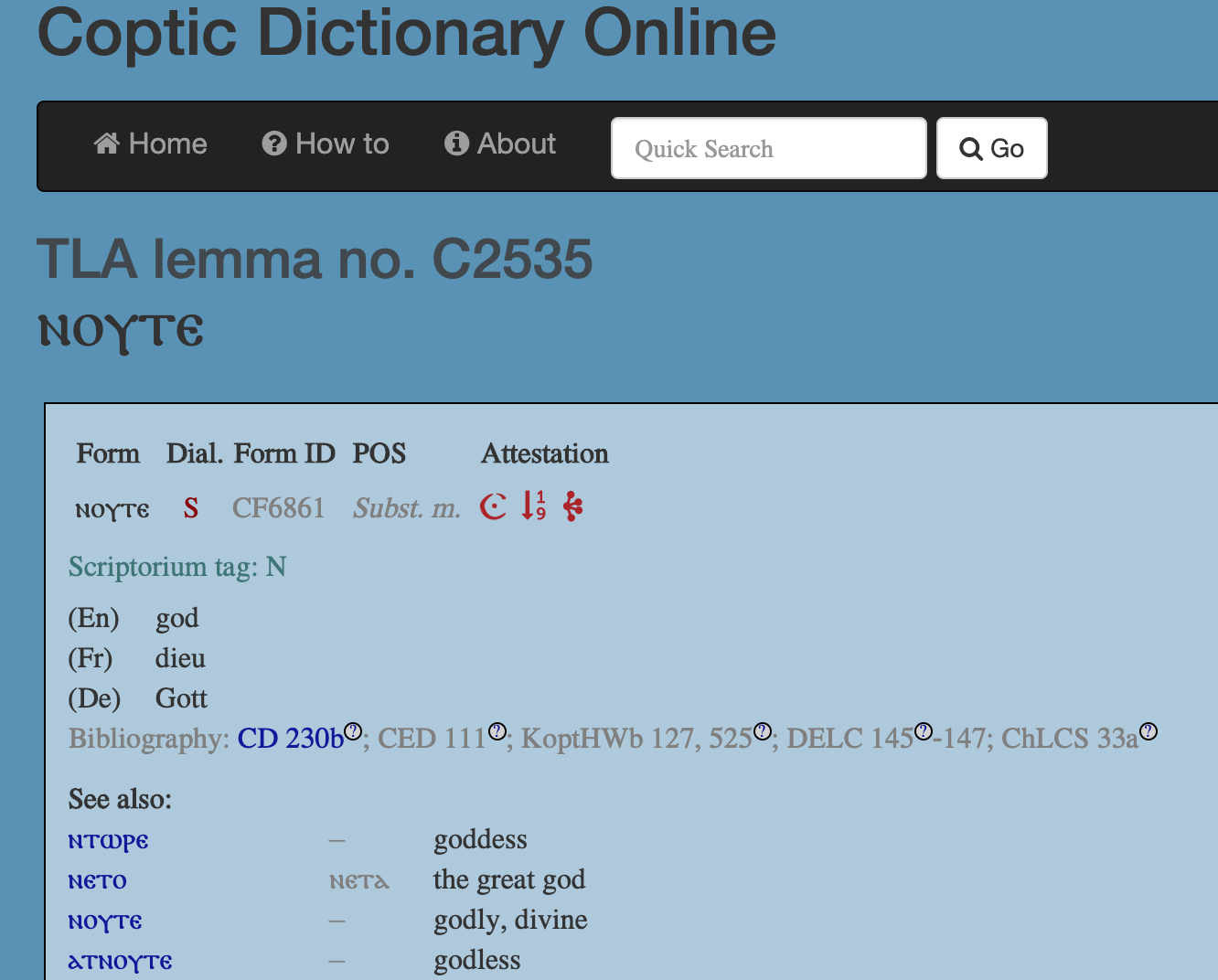
一方、Marcion(http://marcion.sourceforge.net/)という Java と MySQL をベースとしたソフトウェアでもコプト語辞書データ[6]がある。このプログラムでは、コプト語、ギリシア語の辞書が使えるほか、コプト語のテクストにインターリニアーグロスをつけることができる機能もある。
KELLIA プロジェクトのコプト語辞書データでは、英語、フランス語、ドイツ語が、そして Marcion のコプト語辞書データでは、英語とチェコ語の訳が全てのコプト語語彙素に付されてある。KELLIAプロジェクトの辞書データは TEI XML[7]、Marcion の方は MySQL でデータが書かれている[8]。
WordNet の専門家であるモルガード・ダ・コスタは、これら2つの辞書データの意味データと既存の大言語の WordNet をリンクさせて、コプト語 WordNet の原型を作ることを提案した。この方法では、雛形の大言語の WordNet の語彙素情報の影響を強く受けざるをえないものの、早く効率的に WordNet のプロトタイプを作ることが可能となる。
これらの2つの辞書データの他に、コプト語におけるギリシア語からの借用語の辞書データが DDGLC プロジェクト[9]から提供された。今では、このデータも Coptic Dictionary Online に組み込まれているものの、コプト語 WordNet を作成した当時は、まだ組み込まれていなかった。これらのコプト語の意味データを既存の英語、フランス語、ドイツ語、チェコ語の WordNet の synset にリンクさせ、既存の synset がコプト語のそれぞれの語彙素に対応する蓋然性を数値で出した。そのうち、数値が高いものを抜き出し、コプト語の専門家4名がサンプルのチェックを行い、自動的に作成された WordNet の精度が実用に足りるものであることが確認された[10]。現在は筆者を含むコプト語学者が自動生成の結果を修正している。
最初のコプト語 WordNet の活用先は筆者の博士論文のトピックであるテクストリユースのソフトウェアである TRACER である。TRACER は、ゲッティンゲン DH センターおよびゲッティンゲン大学コンピュータ科学研究所の eTRAP プロジェクト(https://www.etrap.eu/)で開発された、テクストリユースの探知ソフトウェアである。TRACER は、現代の剽窃などではなく、特に過去の文献における引用や引喩などの文学的なテクストリユースを探知することを目的としている。彼らは既に古典ギリシア語、ラテン語、ドイツ語、英語、チベット語などの古典的な文学でテクストリユースを探知するプロジェクトで TRACER を用いて成功している。現在は筆者が働いているプロジェクト(SFB1136)と提携して、コプト語でも TRACER を用いて、まだ発見されていないテクストリユースを探知している。テクストリユース、そのうちでも特に引用では、近代以前では、著者が引用元の文章を一部変更することがよくある。筆者が TRACER を用いてその聖書からのテクストリユースを調べているシェヌーテ(紀元後4–5世紀の上エジプトの修道院長)もそのような一部語彙を変更した引用を頻繁に用いた。その語彙変更は、共-上位語(co-hyponym)間で行われることが多い。共-上位語というのは、同族語とも呼ばれるが、上位語を共有する下位語同士のことである。例えば、apple と orange は上位語 fruit を共有する共-上位語の関係である。共-上位語間で変更された引用というのは、例えば、“Boys, be ambitious!” を “Girls, be ambitious!” と語彙を変えて引用するようなものである。共-上位語の他には、同義語間でも一部変更がなされることが多い。このような共-上位語および同義語間での変更を考慮しながらテクストリユースを探知するために、コプト語 WordNet がそれらのデータを提供する。
その次のコプト語 WordNet の活用先は、Coptic Dictionary Online である。この辞書アプリにコプト語 WordNet のデータを追加し、単語を検索すれば、類義語や同義語、上位語、下位語などもその単語の意味とともに表示され、ユーザーが1つの語彙、および、その派生語あるいは複合語だけでなく[11]、意味的な関連のある諸語彙をも同時に学習できるようにする予定である。
人文情報学イベント関連カレンダー
【2019年12月】
-
2019-12-03 (Tue)〜2019-12-06 (Fri)
於・台湾/国立台湾師範大学 -
2019-12-07 (Sat)
於・京都府/国立国会図書館 関西館 -
2019-12-14 (Sat)〜2019-12-15 (Sun)
於・大阪府/立命館大学大阪いばらきキャンパス -
発表申込締切:2019-12-18 (Wed)
於・佐賀県/佐賀大学理工学部
【2020年1月】
-
2020-01-17 (Fri)
於・東京都/都市センターホテル
【2020年2月】
-
2020-02-01 (Sat)
於・佐賀県/佐賀大学理工学部 -
2020-02-15 (Sat)
於・大阪府/立命館大学 大阪梅田キャンパス
Digital Humanities Events カレンダー共同編集人
イベントレポート「18世紀研究における DH の広がり:第15回国際十八世紀学会(ISECS 2019)に参加して 第4回:大学での教育実践と新たな DH プロジェクトの支援」
1. はじめに
2019年7月14日(日)から19日(金)にかけて、エディンバラ大学にて第15回国際十八世紀学会(International Society of Eighteenth-Century Studies)大会(以下、ISECS2019)が開催された。筆者は18世紀研究におけるデジタル・ヒューマニティーズ(以下、DH)の広がりを概観すべく、8月号より、本大会の参加報告を連載している[1]。第4回である本稿は、参加記の最終回として、大学における教育実践に関するセッションや、新たな DH プロジェクトの支援に関するセッションについて簡単に紹介することとしたい。
2. 大学における教育実践
15日に開かれたラウンドテーブル “The Digital Eighteenth Century: Directions and Opportunities” では、ヘルシンキ大学、ジョージア工科大学、メリーマウント大学、セゲド大学におけるDH教育の実践例が取り上げられた。本章では、メリーマウント大学の Tonya Howe による発表について紹介したい[2]。彼女の発表では、Literature in Context[3]というオープンリソースを用いて、1660–1830年の著名な英文学者の生きた時代に関する理解を深める、という学部生向けの授業実践が紹介された。彼女の指導する学部生は、文学に関する専門知識は発展途上の段階にあり、プログラミングなどの情報技術はほとんど持たないとのことであった。彼女の主張は、その教育段階における限界を認識した上で、操作の容易なデータ可視化ソフトウェアを利用したり、授業の中で TEI マークアップを共同で進めることで、研究対象に対する理解を深めるとともに、DH に対する関心と知識を養成するのが良いだろうというものであった。
筆者は、自身の経験から、初学者にとって、当事者性がDH実践への扉を開く大きなきっかけになりうると考えている。そのため、導入的位置付けでデータ可視化ソフトを利用し、自身や、自身の分野に関連する研究材料を使ってみるという教育実践のあり方は説得的であるように思えた。DH に触れる多くの学生は、自身の研究に活きる可能性が自身の研究材料によって示されることで、研究の道具としてのデジタル技術や知識の有用性を認識し、実践者になることを促されるのではないだろうか。
Tonya Howe の発表では学生が作成した可視化データが次々に紹介されたが、そのような DH 教育が学生のその後の研究にどのように活きたのかに言及がなかったことは残念に思った。というのも、彼女らのラウンドテーブルのテーマは「方向性と好機」であり、まだ教育や研究に DH 的アプローチを取り入れていない層にそのアプローチの有用性を示すためのものであったように筆者には思えたからだ。教育に取り入れるかを迷っている教員にとっては、DH 的アプローチがその後の学生の研究に活きたという、具体的な事例が示されるとなお良かったのではないだろうか。
3. 新たな DH プロジェクトの支援
18日には、Emily Friedman によって新たな DH プロジェクトを支援するためのワークショップが開催された[4]。 同ワークショップは、参加者が配布されたシートの項目を埋めながら、自らの DH プロジェクトの構想を練るものであった。同じワークショップに参加した研究者とのディスカッションを通して、自分達に必要なものを練り上げていくプロセスは、自らのデジタル技術に関する知識の不足からくる不安を取り除くのに効果的であろう。
このような不安の例には、前章で挙げた “The Digital Eighteenth Century: Directions and Opportunities” の主宰者 Mikko Tolonen が言及していたものがある。彼はラウンドテーブルの導入として、DH プロジェクトでデータを作成する際には、そのプロジェクトが大規模であればあるだけ、研究成果を発表するまでに時間がかかるという危惧と、データ・クリーニングにかかる労力が大きいという難点を挙げた。また Róbert Péter は、同ラウンドテーブルにおいて、多くの DH 研究が公開されているものの、コードの公開は不十分であるように思えることから、プロジェクトの再現・再生産は可能なのか、という疑問を投げかけた[5]。このように、DH プロジェクトの中では様々な困難や課題が立ち現れてくるだろう。Friedman が主宰したようなワークショップを、そのような困難や課題を解決するための糸口として利用できると良いのではないだろうか。
近年、国内の人文系の学会でも DH に焦点が当てられた研究や企画が徐々に増えてきたことを踏まえると、デジタル史資料がこれほどまでに流布し、さらに爆発的な増加が見込まれる現在、人文学者がデジタル史資料やデジタルツールの使い方を学ぶ必要性はますます高まっていくことだろう。その結果として独学で DH の世界に足を踏み入れざるを得なくなる研究者も少なくないと思われる。そこで、人文系の学会で DH プロジェクトそのものをサポートするような企画、すなわち、成果発表の場としてではなく、研究手法を学び、その場でフィードバックを得られるような勉強会としての性格を持つ企画が組まれることは、コミュニティ全体の DH に関する知識の底上げに寄与し、デジタル研究環境の整備への気運を高める上で有益であるように感じた。
4. おわりに
第15回国際十八世紀学会における DH 関連発表の全体を見通してみると、プロバイダによる情報提供だけでなく、専門研究における実践例、未来の実践者の心がけと教育方法の検討までをカバーしており、この機会に DH について理解を深めたい研究者にとってバランスのとれた構成をしていた。また、発表者だけでなく参加者も DH に対するリテラシーが高く、技術的な質問や DH 的アプローチの意義を批判的に問う姿勢が見られた。
今回の DH 関連発表の多くに共通して見られた特徴は、データベースやコレクションに依存した研究が多かったという点である。このような発表の多くは、データベースやコレクションを作成したチームが、自分たちの成果物がどのような性格を持ち、どのような分析に適用しうるかを示したものであった。このようなコンテンツ依存の分析は、作成者によるアピールの手法としては有効だが、広範なデータベースを紹介した一部の発表において、18世紀の書物の性格を一般化するような見解が示されたことには疑念をもった。当時の出版物すべてを収集することは物理的に不可能なため、どれほど広範なデータベースを使ったとしても、分析結果の一般化には慎重になるべきである。デジタル史資料の利用の際には、紙媒体と同じく、データベースやコレクションの性質や限界を把握することが大切である。
とはいえ、データベースに含まれるデータが特定の史資料に特化し、かつその史資料に関しては網羅的であるために、含まれる史資料の性格について明示しやすいものもある。本連載で紹介したデータベースの中では、ハプスブルク帝国の最重要メディア Wien[n]erische Diarium の画像・テキストデータを集めた DIGITARIUM[6]や、パリ王立科学アカデミー(1666–1793)の『年誌・論文集』のテキストデータを集めた MHARS[7]が該当するだろう。種々の出版物を扱うような広範なデータベースの場合には、フィルタリングによって対象を限定することで、紙で閲覧するのと同様に、史料批判を行い、信頼性の高いデータを使って分析する可能性が開かれるだろう。
データだけでは十分でない。今後 DH の実践者が増加するとともに充実していくことが予想されるこれらのデータを適切に利用していくためには、ユーザのリテラシー向上が要となる。データ利用や分析手法などの理解を通してユーザが批判的実践者となっていけば、リソース全体の質も向上し、特定の史資料に特化したリソースもその真価を発揮しやすくなるだろう。
人文系の研究にデジタル技術が浸透していくにつれ、ユーザ側のリテラシー形成が急務になってきているように思う。全員が DH プロジェクトの牽引者にならずとも、広くアンテナを張って情報を収集したり、利用してみた上でそれが自らの研究に役立ちうるのかを判断できるようになれば良い。本連載は、これまであまり DH の流れに関心のなかった18世紀研究者が、DH に興味を持ったタイミングで役に立てば、との願いを持って書いてきた。本連載で紹介した内容は一部であるし、筆者の力不足で伝えられない情報もたくさんあったため、18世紀研究に限らない、より詳しいDH関連技術や概念については、『歴史情報学の教科書:歴史のデータが世界をひらく』[8]などをご参照いただきたい。
イベントレポート「TEI2019参加報告(後編):セマンティック記述とリンクトデータ構築の動き」
筆者は、2019年9月にオーストリア・グラーツ大学で開催された TEI2019: What is text, really? TEI and beyond に参加した。TEI(Text Encoding Initiative)は、人文社会科学におけるデジタルテクスト校訂のための共通規格を策定するための国際共同プロジェクトの名称であり、年に一回、欧州や北米を中心に総会を開催し、XMLの詳細な技術論から、TEIガイドラインに掲載される記述モデルの提案、さらには人文社会科学における実際の応用例まで幅広く議論している。
人文情報学月報第99号に掲載された前編では、筆者が参加したワークショップの内容を中心に、デジタル校訂版の出版・公開と関連ツールについて紹介した。後編では、セマンティック記述を含むデジタル校訂についての議論を軸に、研究発表の内容を紹介したい 。今回は、初日に “TEI, formal ontologies, controlled vocabularies and Linked Open Data” と題するセッションが組まれるとともに、最終日には、ボローニャ大学のFrancesca Tomasi氏が “Linked Open Data perspectives in Semantic Digital Editing” というタイトルで基調講演を行った。このことからも、異なるデータセット間でのデータ収集や比較を可能にするセマンティック記述やリンクトデータの構築が、デジタル校訂を考える際に重要なものとして認識されていることが見てとれる。
さて、まず言及したいのは、DEPCHA(Digital Edition Publishing Cooperative for Historical Accounts)についての発表である[2]。DEPCHA は、歴史学で用いる財務記録史料を主な対象として、独自のオントロジーを用いた RDF 記述モデルと、この記述を含む形でのデジタル校訂版編集のための規格を提供しようとするプロジェクトである。DEPCHA が構築したオントロジーは、財務記録史料特有の情報構造を適確に記述できる語彙を用意しており、こうした史料を用いてデジタル・ヒストリーの実践を試みる研究者にとっては、非常に有用なものであろう[3]。筆者は、自らの研究でこうした史料を用いる機会がないため、その内容についてこれ以上詳述はしないが[4]、より一般的な話として、こうした特徴的な性質を持つ史料の記述・構造化に特化した規格を策定することには大きな意義があると言えるだろう。
DEPCHA は財務記録史料という、特定の形式を持つ史料を扱うものであったが、特殊な文字や記法を含む史料の記述を試みる例としては、種々の図像を複雑に組み合わせた象形表現を持つ古代マヤ文字を機械可読な形式で記述し、そのコーパスを構築する TWKM(Textdatenbank und Wöeterbuch des Klassischen Maya)の試みをあげておきたい[5]。このプロジェクトは、種々の図像と、そのアルファベット表記の対応関係をオントロジー形式で記述したデータセットである Sign Catalogue に含まれる図像URIを用いて古代マヤ文字をマークアップすることで、文字構造の記述と機械可読な言語表記への変換を行い、その後の言語分析への応用を可能にしている。このプロジェクトは、古代マヤの象形文字のように特殊な文字・記法を含み、その全容が明らかになっていないような言語を用いたテクストの構造化はもちろん、より広い視野で見れば、TEIが発展した欧米圏とは異なる文字文化、言語文化を持つ地域のテクストをいかに扱うかという問題全体においても、有益な事例を提供していると言えるだろう[6]。
上の DEPCHA も含めて、これらはいずれも一群の史資料の「特殊性」をどう扱うかという問題につながる発表であったように思う。このような「特殊性」への対応としては、古代の碑文史料(碑文以外にも適用可能)記述のための EpiDoc や、書簡史料記述のための correspDesc といった TEI の規格整備はもちろん、セマンティックウェブやリンクトデータの構築までを視野に入れるなら、上述のプロジェクトが試みたように、各々に固有の概念、情報を記述するための語彙(オントロジー)設計も進めていく必要があるのではないか。そして、こうした分野ごとの語彙設計という作業の場においてこそ、必ずしも TEI や XML に関して深い技術的知見を持たない人文系研究者による貢献の余地があり、その専門性を活かしてデジタル校訂の記述モデルの構築に関わることが可能であると考えることもできる。
また、「特殊性」からは少し離れるが、トークンに分割されたテクストの各要素間の関係をオントロジーに基づいて記述することで、テクストの系統的変遷をセマンティックウェブとして表現する試みも紹介された[7]。これは、テクスト内容の注釈を旨とする DEPCHA や TWKM とは少し異なり、テクストのメタな側面により焦点を当てたものと言えよう。このように、テクストのセマンティック記述に関しては、その内容、系統など様々な側面からの記述モデル構築が試みられている。こうした記述モデルが様々な分野において定められ、それに則ってデータが構造化されることで、個々の分野において共有可能なリンクトデータが構築され、今後の研究の発展に大きく資することは間違いないだろう。
ここまで、いくつかの発表内容を踏まえ、各分野における史料群の「特殊性」を考慮した形での語彙設計、そして、それを記述できる構造化モデルを構築する意義を考えた。最後に、これまでの議論とも関わる内容として、テクストマークアップの自動化や効率化の試みについて、いくつかの発表に言及しておきたい。というのも、セマンティック記述を含む形でテクストの「深い」構造化を行おうとすれば、往々にして節や段落といったテクストの形式面での構造を記述するのみでは不十分で、人物や場所、種々の物といった要素をもマークアップする必要が出てくる。これをすべて手動で行おうとすれば大変な労力がかかり、プロジェクトなどで進める場合にはコスト面でも大きな問題となりうる。つまり、セマンティック記述を行い、広くデータを繋げようと試みるならば、何らかの形でマークアップの効率化を行うことが不可欠であると言えるだろう。
効率化の試みとして、今回の諸発表においては二つの方向性が示されたように思う。一つは言うまでもなく、技術的側面からの効率化の試みである。まずテクストの構造抽出に関しては、OCR を利用して辞書の構造を抽出する事例、OCR に加えて Schematron QuickFix の機能を用いて詩の構造化を自動で行う事例などが紹介された[8]。また、語句単位のマークアップに関しては、各語句ごとにエレメント開始位置、エレメント内包などの情報を明記した表形式のデータから、XML ファイルにエレメントタグを自動で挿入するためのプログラムが紹介された[9]。以上が技術的側面からの自動マークアップの試みであるが[10]、もう一つの方向性として、コミュニティベースのマークアップがある。こうした試みの例としてはやはり、Recogito をあげておきたい。Recogito は地名・人名・出来事に基づくテクスト注釈のためのオンライン共有プラットフォームであり、各人が操作性の高い UI 上でテクストに注釈を付与し、それをオープンデータとして公開することもできる[11]。そして、今回の質疑応答でも話題になったように、現状では地名の注釈のみ対応可能といった点で一定の制約はあるものの、TEI/XML ファイルのインポート・エクスポートが可能である。このように、必ずしも TEI に関して知識がなくとも UI 上で注釈を行い、それを TEI/XML ファイルに反映させられる仕組みを用いることで、コミュニティベースでマークアップの効率化、大規模化を図ることは可能であるように思う。
以上、TEI2019における発表、議論の内容を紹介しつつ、セマンティック記述を含む記述モデルの構築、そしてテクストマークアップ効率化の試みについて述べた。筆者自身、TEI やセマンティックウェブ関連技術、リンクトデータについてはいずれも勉強中の身であり、本報告の記述が所々不明瞭なものとなってしまっている感は否めない。それでも、各所で進むセマンティックウェブやリンクトデータ構築の試みに TEI がいかに対応し、どのような記述モデルを構築していくのかという問題についての活発な議論の一端を紹介することができたのではないかと思う。そして、こうした動きが今後さらに進むであろうことを考えれば、日本の人文系研究者が何らかの形で TEI に貢献する余地もこの辺りにあるのかもしれない、と感じる次第である。
◆編集後記
小川氏報告のTEI国際会議は、海外開催では初めて、日本からの参加者が二桁になりました。今後が楽しみです。
(永崎研宣)
- コメントを投稿するにはログインしてください