人文情報学月報第103号
ISSN 2189-1621 / 2011年8月27日創刊
目次
- 《巻頭言》「美術史・美術・技術 ある作品を起点に継承性を考える」
:ROIS-DS 人文学オープンデータ共同利用センター・国立情報学研究所 - 《連載》「Digital Japanese Studies 寸見」第59回
「ColBase リニューアル」
:国文学研究資料館古典籍共同研究事業センター - 《連載》「欧州・中東デジタル・ヒューマニティーズ動向」第21回
「テクスト・コーパスのための言語学的なインターリニア・グロス付け」
:ゲッティンゲン大学 - 特別寄稿「西洋古典・古代史史料のデジタル校訂と Leiden+:デジタル校訂実践の裾野拡大の可能性」
:東京大学大学院人文社会系研究科 - 人文情報学イベント関連カレンダー
- イベントレポート「第38回人文機構シンポジウム デジタル・ヒューマニティーズってなに?:コンピュータがひもとく歴史の世界」
:東京大学史料編纂所 - イベントレポート「「マシンと読むくずし字」シンポジウム 参加報告」
:一般財団法人人文情報学研究所 - 編集後記
《巻頭言》「美術史・美術・技術 ある作品を起点に継承性を考える」
いきなりの宣伝となり恐縮ですが、このメールマガジンが配信されるしばらく前に、ROIS-DS 人文学オープンデータ共同利用センター(CODH)から新しい機械学習向けデータセット「顔コレデータセット」が公開されている予定です。このデータセットは、筆者が CODHに 着任してしばらく後に構築を始めた「顔貌コレクション(顔コレ)」を機械学習に使いやすい形にして提供するものとなります[1]。筆者は2000年代初頭には美術史を学び出版流通会社への勤務を挟んだ後、2010年代前半に文化資源学の大学院に社会人入学し、現在は人文学分野でのオープンデータや情報学の活用を軸に研究を行っています。今回のデータセット公開は20年越しでの研究分野への回帰ということができるかもしれません。
敢えて筆者が紹介するまでもないことですが、美術史分野でのデジタルを活用した研究には様々な進展が見られます。The Getty Foundation による Digital Art History の助成成果一覧を見るだけでも、時空間情報を扱うプロジェクトから、美術作品の素材そのものをデジタル上で整理するためのツール開発まで幅広い研究を目にすることができます[2]。
日本国内においては日本美術を対象としたものに限定しても、仏像の様式を AI と協力して分析するプロジェクトや、『源氏物語』をテーマとした美術作品群いわゆる「源氏絵」をアーカイブするとともに AI と人間の分析を融合する試みなどをはじめ、いくつも研究が進められています[3]。美術史研究全体に大きなインパクトを与える段階に至るまでにはまだいくつかの課題があるかもしれませんが、今後のますますの進展が期待される状況です。手前みそではありますが、筆者の「顔コレ」を軸とした研究活動も、こういった美術史におけるデジタル技術の活用・情報学との融合の一助になると考えています。
そもそも美術史は、研究する対象が視覚的な作品であることが多いため、印刷や写真などの技術をかなり早い時期から教育・研究に取り入れてきた分野でした。筆者が美術史の学生であった頃にあらゆる講義で使われていた「スライド映写機」も、現在では生産が終了しプロジェクターなどによる投影に切り替わってはいるが、時代を遡れば技術の導入が美術史の教育を大きく変えた例であることはすでに指摘されています[4]。
技術が美術史研究を変える可能性を追求することと、筆者にとって表裏一体の関心事として、技術と美術の関係性があります。筆者自身はマニエリスム期と呼ばれる16世紀のイタリア美術で修士論文を書き、現在取り組む顔コレでは室町末から江戸時代初期の日本の絵本や絵巻物を対象としています。しかし2000年初頭の美術史研究室時代、先生の一人から告げられた「研究を志すならば、専門に関わらず自分と同時代の活動に触れなければならない。可能ならば自分と将来の美術史のために、作品を買わねばならない。」という言葉が頭の片隅に常にあり、一受容者として現代の美術に触れる努力はしてきました。残念ながら「買う」方に関しては、現職に就いてから一点だけ現代写真家のコラージュ作品を購入したにとどまっていますが。
話を戻しますと、デジタルを含めた技術の発展とともに、新しい技術を利用した作品が次々と生み出されてきました。2020年の今日で言えば AI アートが最新の技術との関わりの中で、どのように位置づけられるべきかを議論されています。一方で技術の発展スピードは、思わぬところで美術作品のあり方を揺り動かしています。最近このことを再度思い起こしたのは、九州にある、あるメディアアート作品を巡る動きからでした。キャナルシティ博多という大型商業施設の中に、筆者の大先輩でもあるナム・ジュン・パイクの大型作品、『Fuku/Luck,Fuku=Luck,Matrix』(1996年)があります。壁面一面に180台のブラウン管テレビを並べて、それぞれに様々なイメージを流すことで、時にカオスな、時に明るい印象を与える大型作品です。しかし2019年末にふとキャナルシティ博多の公式サイトを訪れた際に、「【修理のための調査分析中】現在、展示していません。」という表記が追記されていました。
実はこの作品は、筆者が学芸員科目を教える際、修復を考える時間に必ず取り上げてきた作品です。ブラウン管テレビは当時ごく一般的な家電製品で、もちろん筆者の家にもありましたが、今日各メーカーがブラウン管テレビの生産を終了しています。そういった状況のなかでこの作品の今後はどうなるのかということを問うことは、美術作品の修復や継承、同一性を考える上で格好の素材だったからです。
パブリックな場所に設置されている作品だけに、キャナルシティ博多を訪れた多くの人が『Fuku/Luck,Fuku=Luck,Matrix』の動画や写真を撮影しています。多くの画像をネット上で確認することができますので、ぜひ検索してそのいくつかを見ていただければと思います。一つまた一つと進むブラウン管テレビの故障によって、制作から20年以上を経た状態では大半の画面が真っ黒になり、カオス感も明るさもない、見る人によっては怖い印象さえ受ける作品となっていることがわかります。
流れる映像の中身とレイアウトこそがナム・ジュン・パイク作品で、それが映る機材は交換可能な要素だと考えれば、プラズマディスプレイなどに置き換えれば修復できるといえるかもしれません。一方で、ナム・ジュン・パイクの表現は彼の生きた時代と技術をコンテクストとしているため、ブラウン管テレビと一体不可分であるという考え方もできます。現状の外見を変えてしまうような修復を避けるべきという、チェーザレ・ブランディによる提唱を一つの契機に、判別性や可逆性の原則が重んじられるようになっている今日においても、簡単に一つの答えを出せる状況ではありません[5]。
この問題は、研究と技術の関係も想起させます。ある時代に特定の技術に依存して作られたデータが、しばらくして利用できなくなるという問題は繰り返し指摘され、それを乗り越えるために多くの教訓が蓄積されてきました。一時的に利用できなくなっていた過去のデータを再度利用可能にする試みは、多くの成果を上げています。例えば最近の例であれば東京大学総合図書館所蔵の亀井文庫『ピラネージ版画集 Opere di Giovanni Battista Piranesi, Francesco Piranesi e d’altri』がありますが、復元される以前のデータベースは美術史の学生だった時代に構築が進められていたのを覚えています[6]。
デジタル化されたことで活用可能となった研究資源を、情報技術を生かした研究のためのツールを、今後もどうやって継承していくかは、データ提供者、利用者、開発者それぞれが自分ごととして考えていくべき課題であり、ここで筆者がおいそれと結論じみたことを言えるものではありません。一つだけ、「顔コレ」のように複数の機関が公開してくれている画像を集め、研究データとして整理する試みの経験からは、公開機関に対して敬意を持ち、常にコミュニケーションを取っていく態度が重要であることは断言できます。
ちなみに『Fuku/Luck,Fuku=Luck,Matrix』の修復はまだ終了していませんが、ブラウン管テレビを調達して再度置き直しているという情報があります。デジタルアーカイブに置き直してみるとかなりの力技にあたるかもしれませんが、続報に期待したいところです。
執筆者プロフィール
《連載》「Digital Japanese Studies 寸見」第59回
「ColBase リニューアル」
2020年2月20日、国立文化財機構は国立博物館所蔵品統合検索システム ColBase をリニューアルした[1]。お知らせに「ColBase をリニューアルしました。デザインを一新してより見やすい画面にし、検索機能を改善して目的の作品を探しやすくしました。また、画像や解説文を含む作品データの品質も改善しました」とあり[2]、デザインの改善を越えたものであることが分かる。
ColBase は、2017年3月27日に公開されたもので[3]、国立文化財機構に属する4博物館、すなわち東京・京都・奈良・九州の国立博物館の収蔵品の大部分を検索できるものである[4]。同機構の村田良二氏によれば、同機構の奈良文化財研究所の木簡データについても今後追加予定であるとのことである[5]。現在は、日英中韓に対応するが、日本語以外は解説が完備していないという。とはいえ、わずかでも解説や UI が需要の高いこれら4言語に対応しているのは国際化として堅実な策である(読み仮名が全言語版に出る理由は分からない)。品名をはじめとした各項目で国際化対応しているが、員数および法量、また記銘などは日本語のまま提供されているものがある。寄贈者は対応しているものとしていないものがどちらも見られた。英語版に全角英数字が入っていたり、中国語版で日本の字体のままで簡体字になっていなかったりと、データの質には改善の余地がある。メタデータの準備が追いついていない言語で所蔵品を見ようとしたときは、いわゆる404が返ってきてしまう。利用者にとって所蔵品が存在しないばあいと判別が難しく、英語版があるときは英語版、なければ日本語版のデータを表示するほうがよいのではないか。
画像の質の改善も今回の重要なリニューアルの要素であるという。例示は避けるが、たしかに、いくらか見比べてみると(書跡が比較しやすい)、内容を読み取りきれない画質のものから内容まで読めるような画質にまで改善したようである。画像は、拡大縮小ができるのみで、遷移機能はなく、ビューワーとしてはすこし使いにくい。[5]には固まってきた技術を採り入れたいとあるので、今後の展開しだいでは、IIIF などのフレームワークの採用などもあるのかもしれない。コンテンツは政府標準利用規約2.0で提供されているものの、第三者の権利にかかるものが混在しているとのことであるので、ColBase にあって注意書きがないからといって CC 相当の条件で使えないのは、利用しにくい。そのような点は、IIIF などの採用で改善する点かと思われる。
いささか細かいはなしではあるが(いまさら断ることではないかも知れないが)、HTTPS で提供されているコンテンツと HTTP で提供されているコンテンツが混在しており、ブラウザ上で安全性に問題があると表示されてしまっている。些事のようではあるが、他サイトとの連携において困難をきたすばあいもあり、あえて贅言するところである。
いろいろ述べはしたが、全体的なコンセプトはよく練られており、後発のサービスにとって操作感や安定した運営の見本となっていくのではなかろうか。
《連載》「欧州・中東デジタル・ヒューマニティーズ動向」第21回
「テクスト・コーパスのための言語学的なインターリニア・グロス付け」
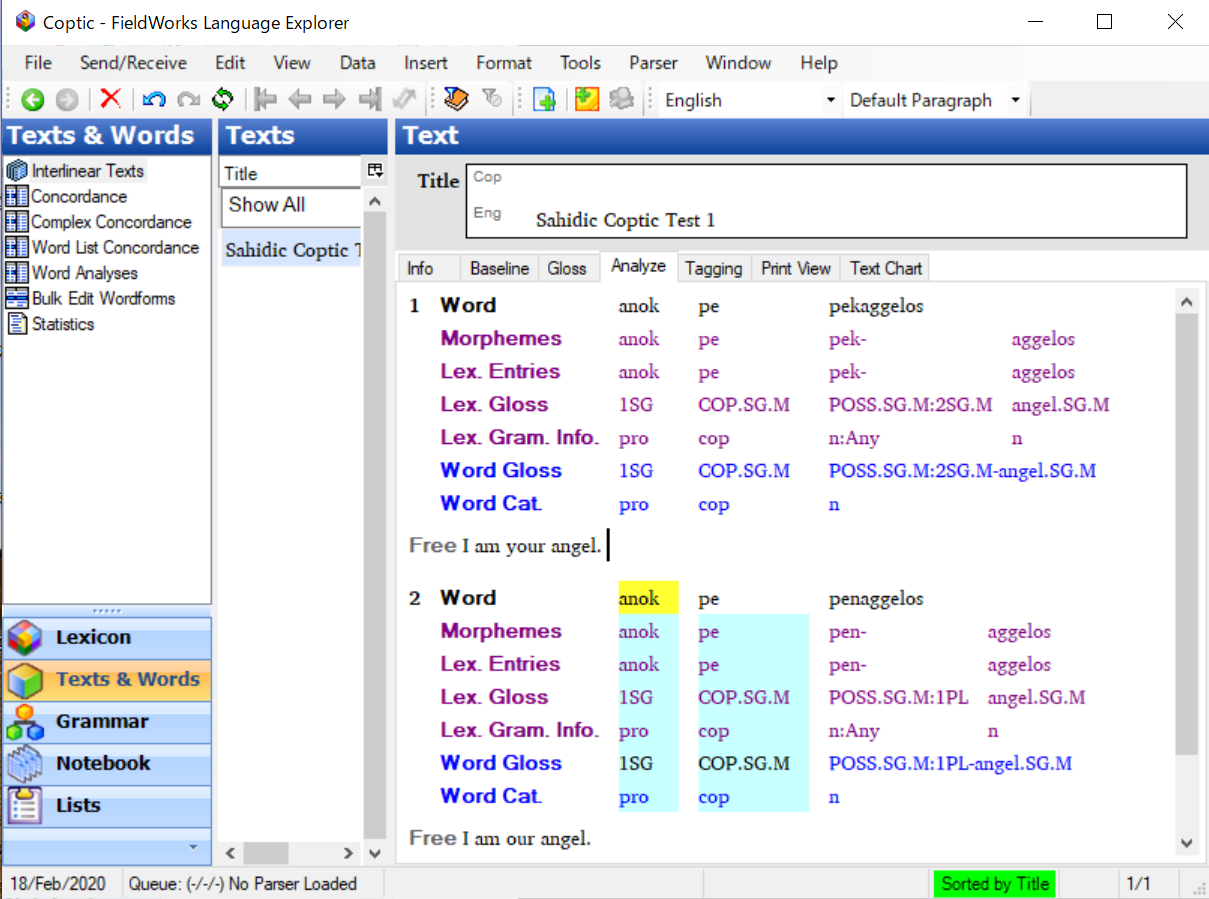
語学の論文では、通常、その言語を知らない言語学者でも、各形態素の意味がわかるように、例文にグロスが書かれる。ここでいうグロスは、通常は図1のように、分綴されたそれぞれの語の下に形態素ごとに意味や文法情報が書かれるインターリニア・グロスである。

言語学者は通常は LaTeX、もしくは、Microsoft Word などを用いて論文を書く。Word の場合は、表を使う方法、もしくは、シンプルにタブを多用する方法などがあるが、煩雑になる場合が多い。それに比べ、LaTeX ではより少ない操作でより容易により美しいインターリニア・グロスを作成することができる。LaTeX は、数学者であるドナルド・クヌースが作成した TeX にさらにマクロパッケージを組み込んで、レスリー・ランポートが作成した電子組版ソフトウェアで、容易に非常に美しい文書を作成することが可能であり、多くの言語学者やコンピュータ科学者、数学者や物理学者が用いている。作成する方法としては、TeX をコンピュータにインストールして環境を整えた上でエディタで作成するのがこれまでによく用いられてきた方法であったが、Overleaf(https://www.overleaf.com/)[1]のように、無料かつリアルタイムの共同作業も可能なオンライン上のプラットフォームで作成することが現在流行している。日本語で文書を作成する場合は、Unicode の日本語フォントが使用可能な XeLaTeX や LuaLaTeX を Overleaf 上で用いて文書を作成することが可能である。しかし、それよりも、大学院生やポスドクを支援する日本の企業である株式会社アカリクが運営している CloudLaTeX(https://cloudlatex.io/)というオンライン・プラットフォーム上で日本語専用の pLaTeX または upLaTeX を用いて作成するほうが、より容易により美しい日本語文書を作成することができる。
LaTeX で言語学的なグロスを作成するパッケージとしては、gb4e、lingmacros、covington、linguex、expex[2]などがある。筆者は通常は大変高機能な expex を用いている。前出の図1は、CloudLaTeX 上で pLaTeX、そして expex パッケージを用いて、コプト語サイード方言の文にグロスを付した一例である。
LaTeX で作成した文書は PDFで出力できる。これは、言語学の論文を作成するためには良いものの、ウェブで公開する際は PDF かソースコードでしか公開できず、デジタル・ヒューマニティーズのプロジェクトとして公開する場合は、それでは物足りない。また、LaTeX 単体では全て手作業でグロスを振らないといけない。例文のデータが多数あり、一つ一つ最初から全て手作業でグロス付けを行う場合、LaTeX を使えば、Word に比べて時間は短縮されるものの、それでも多大な時間と労力を使うことになる。
そのようなときに役に立つのが、自動グロス付けができるソフトウェアである。言語学者に最もよく使われているものとしては、Field Linguist’s Toolbox(https://software.sil.org/toolbox/)と FieldWorks Language Explorer(FLEx; https://software.sil.org/fieldworks/)[3]が知られている。これらは、世界の様々な言語を話す民族へのキリスト教の宣教のために1934年に設立された Summer Institute of Linguistics(夏期言語講座)を母体とする SIL International が作成したものである。前者の Toolbox はより古く、サイズも小さく、ファイルの記法も大変シンプルなソフトウェアであり、ソフトウェアごと全てクラウド・ドライブに入れることができ、大変便利である。基本は Windows 専用だが、Wine などのエミュレータを用いれば、Mac でも Linux でも動く。後者の FLEx はより新しく、より高機能である反面、ファイル・サイズが重く、フリーズすることも多かったが、開発が進み新しいバージョンが次々と生まれ、改善されてきているようである。FLEx も Windows 専用だが、Mac では、エミュレータを使っても、重すぎてうまく動かないことが多いため、Parallels などの仮想マシン上で起動させた Windows 上で使用するのが良いようである。
Toolbox でも FLEx でも、辞書データのモジュールで、形態素を意味や変化形や変異形と共に登録しておき、テクストを入力してインターリニア化ボタンを押せば、テクストの単語が自動的に形態素分解されて、グロスが各形態素の下に表示される。品詞情報を登録しておけば、品詞情報もグロスの下に表示させることもできる。解析結果が複数ある場合は、その旨が表示され、ユーザはそのうちの一つから選ぶことができる。
言語学では、過去には学者によってそれぞれ異なる方法でグロスが作られてきたが、バーナード・コムリーが率いたライプチヒのマックス・プランク進化人類学研究所の言語学部門によって、通言語的なグロスの標準である Leipzig Glossing Rules(LGR; https://www.eva.mpg.de/lingua/pdf/Glossing-Rules.pdf)[4]が制定された。近年では、記述言語学や言語類型論の諸部門でLGRが用いられることが標準となっている。
しかしながら、LGR は Universal Dependencies の UPOS のように全ての言語で同じ記法をするのではなく、ある程度、言語記述者に選択肢を提示しながら、よく使われる事項は標準になるよう求める。例えば、基本的には形態素境界にハイフン、一形態素が複数の文法事項を表すときは、文法事項の間にドット、接語境界にはイコールマークが用いられるが、より精確に表記したい場合は、~ で重複、<> で囲んで接中辞、\ で形態音韻論的な変化による文法情報のマーキングなどと、より細かく書き分けることもできる。
LGR の作成を容易にするパッケージもいくつか開発されている。例えば、ウェブページ用には JavaScript の leipzig.js(https://bdchauvette.net/leipzig.js/)が、LaTeX 用には、leipzig パッケージ(https://www.ctan.org/pkg/leipzig)がある。
以上、効率的に言語学的なグロスを作成する手順としては、LGR の記法を使って、FLEx または Toolbox で形態素解析し、グロスを自動生成した後、手動で手直しし、最もシンプルな Toolbox の方式でエクスポートし、簡単なスクリプトや正規表現で leipzig.js や LaTeX の expex などの形式に変換して、ウェブページもしくは LaTeX 文書にグロスを載せる手順が考えられる。または、FLEx でインターリニア・データを HTML 形式でエクスポートしてウェブページに載せることもできる。しかしながら、これらだけならレンマや文法事項だけに絞って検索したり、簡易な統計分析をすることはできない。次回は ANNIS など、インターリニア・グロスも表示できる、コーパス言語学的な検索・分析に特化したコーパス・プラットフォームについて述べる。
特別寄稿「西洋古典・古代史史料のデジタル校訂と Leiden+:デジタル校訂実践の裾野拡大の可能性」
西洋古典学、あるいは西洋古代史の分野において、主に碑文・パピルス史料を校訂する際に国際的に広く用いられているのが Leiden 記法である[1]。Leiden記法を用いることによって、諸校訂間における校訂記号が統一され、相互の比較参照が容易となった。
Leiden 記法は、当然ながら紙媒体の出版を想定して制定された規格であるが、近年のデジタル化に伴うデジタル校訂においても、有用な規格として採用された。しかしながら、Leiden 記法は、そのままでは機械可読でないために、規格を保ちつつこれを変換する必要があった。そのような試みの一つとして、TEI のサブセットである EpiDoc があげられる。EpiDoc は、史料上の欠損箇所や異読、校訂者による補いなどを <gap/> や <choice/>、<supplied/> といったタグを用いて表現したうえで、出版の際には変換スキーマを用いて Leiden 記法に則った形で出力できるようにしている[2]。 また EFES のようなデジタル出版のためのプラットフォームも開発されている点を考えれば[3]、EpiDoc周辺の技術環境は相当に整備されてきており、古典・古代史史料のデジタル校訂における標準規格としての地位が確固たるものとなりつつある。事実、Perseus Digital Library を始め、西洋古典・古代史分野における名だたるデータベースの多くは、EpiDoc 準拠のデータを提供するようになっている[4]。
しかしながら、実際に EpiDoc の規格に則って史料を校訂・マークアップする段になると、人材の確保という問題が生じる。というのも、EpiDoc が TEI のサブセットであり、TEI が現状では XML の枠組みの中で記述されている点を踏まえると、XML に関する基本的な知識と経験を有している必要があるからだ。これは、デジタル技術に親しんでいるわけではない古典・古代史研究者には負担が大きく、とくに TEI の普及が欧米ほどには進んでいない日本においては大きな障害となりうる。こうした負担を軽減し、古典・古代史研究者がかねて親しんでいるLeiden記法をそのまま用いてデジタル校訂を行うことを可能にするためのマークアップ言語が Leiden+ である。Leiden+は、Integrating Digital Papyrological Project が、Papyri.info の利用者、ことにデジタル校訂者のために提供している言語であり、Papyri.info の校訂プラットフォーム内において主に利用されている。以下では、Leiden+ のガイドラインに基づいて[5]、その記法を簡潔に紹介したい。
まず、文構造の記述に関しては XML での構造化と大きな相違はなく、用いる記号が異なるのみである。まず冒頭では、<S=.--- という形で言語宣言を行う。例えば、<S=.grc とすれば、ギリシア語の文書であることを示している。それ以降は、XML と同じく開始記号と終了記号で各構造要素を囲むことで文構造を表現する。例えば、XML で <div n=‘r’>---</div> と記述する部分は <D=.r --- =D> と記述し、<ab>---</ab> で囲む部分は <= --- => で囲む。行番号に関しての記述は XML と比して非常に簡潔で、テクストの先頭に、1. のように番号とピリオドを挿入すればよい。それゆえ、全体の構造としては以下のようになる。
| Leiden+ | XML |
| <S=.grc <D=.1 <= 1. ---text--- 2. ---text--- 3. ---text--- =>=D> <D=.2 <= 1. ---text--- 2. ---text--- 3. ---text--- =>=D> |
<div xml:lang=‘grc’> <div n=‘1’> <ab> <lb n=‘1’/>---text--- <lb n=‘2’/>---text--- <lb n=‘3’/>---text--- </ab> </div> <div n=‘2’> <ab> <lb n=‘1’/>---text--- <lb n=‘2’/>---text--- <lb n=‘3’/>---text--- </ab> </div> </div> |
以上が、基本的な構造の記述方法である。要素を記号で囲むという点に関しては Leiden+ と XML で大きな違いはないが、Leiden+ のほうがより簡略化されており、特に行番号の記述に関しては非常に直感的である。
次に、テクストの校訂について述べる。テクストの校訂においては、Leiden 記法の記述方法をほとんどそのまま入力することができ、Leiden+ の真価が発揮される点であると言えよう。
まず、基本的な表記の例として、校訂者による補記・欠落箇所・省略を見ることで、Leiden+ が、Leiden 記法に慣れ親しんだ者にとっていかに直感的な記述を可能にしているかを示したい。Leiden 記法において、校訂者による補記は、補われた文言を[]で囲む形で表される。すなわち、Iul[ius] C[ae]sar と表記されていた場合、ius と ae の部分は判読不可であったが、校訂者により前後の文言から推測され、補われたことになる。こうした補記は、XML では [] 部分を <supplied></supplied> に置き換えて記述する必要がある一方、Leiden+ においては Leiden 記法と全く同様に記述することができる。欠落箇所は、Leiden 記法では [.....](5文字欠落)、[ -ca.10- ](約10文字欠落)、あるいは [ - - - ](欠落文字数不明)という形で表す。これを XML で表そうとするとそれぞれ、<gap reason=‘lost’ quantity=‘5’/>、<gap reason=‘lost’ quantity=‘10’ precision=‘low’/>、<gap reason=‘lost’ quantity=‘unknown’/> と記述する必要があるが、Leiden+ ではそれぞれ、[.5]、[ca.10]、[.?] と表記すれば事足りる。最後に、省略について、Leiden 記法では省略部分を () で囲う。Iul(ius) Caes(ar)と記述されていれば、原文には Iul Caes としか記されていない(欠落があるわけではない)が、校訂者が省略部分を補ったことを意味する。これを XML で記述するためには、<exapn><abbr>Iul</abbr><ex>ius</ex></expan><expan><abbr>Caes</abbr><ex>ar</ex></expan> というように、多くのタグを記述する必要があるが、Leiden+ では (Iul(ius)) (Caes(ar))と記述すればよい。
このように、テクスト本文の校訂に関してみれば、Leiden+ の記述方法は概ね Leiden 記法を踏襲しており、古典・古代史研究者にとって直感的に理解しやすいものになっていると言えよう。
次に、テクスト本文の校訂記号ではなく、異読等の注釈、クリティカル・アパラタスに関わる記述を見てみたい。まず、綴りの正規化、つまり原テクストで綴りを誤って記されている語を、正書法に則った形に修正する場合、Leiden+ では<:(正書表現)|reg|(原テクスト):> を用いて表す。例えば、再度カエサルを例にとれば、<:Iulius Caesar|reg|Iullius Cesar:> といった具合である。これを XML で記述すると、<choice><reg>Iulius Caesar</reg><orig>Iullius Cesar</orig></choice> とする必要がある。次に異読に関しては、<:(原テクスト) |alt| (異読):> とする。例えば、底本ではユリウス・カエサルと読んでいるところを、テクストの欠落が原因で解釈が分かれ、別の写本ではデキウス・カエサルと読んでいるような場合、<:[Iu]lius Caesar|alt|[De]cius Caesar.> と記述することになる。XML では、<app type=‘alternative’><lem><supplied>Iu</supplied>lius Caesar</lem><rdg><supplied>De</supplied>cius Caesar</rdg></app> となるだろう。
このように、XML では原テクストと正書表現・異読の双方をタグで囲む必要があるうえに、上の例のような補記、あるいは欠落、省略などがある場合には、それも一々タグで囲まねばならず、場合によってはタグの入れ子構造が相当複雑になることも考えられる。この点でもやはり、Leiden+ は XML に比してより直感的な記述を可能にしているといえるだろう。では Leiden+ は、Papyri.info において実際にどのように利用されているのか。最後にこの点を紹介して、本稿をまとめたいと思う。
まず、Papyri.info にサインインしたうえで、ページ上部に並ぶ DDbDP、HGV、APIS などの諸パピルス・データベースから編集したいパピルスを選択し、エディターで開くと、以下のような Leiden+ 対応のエディターが表示される(図1)。
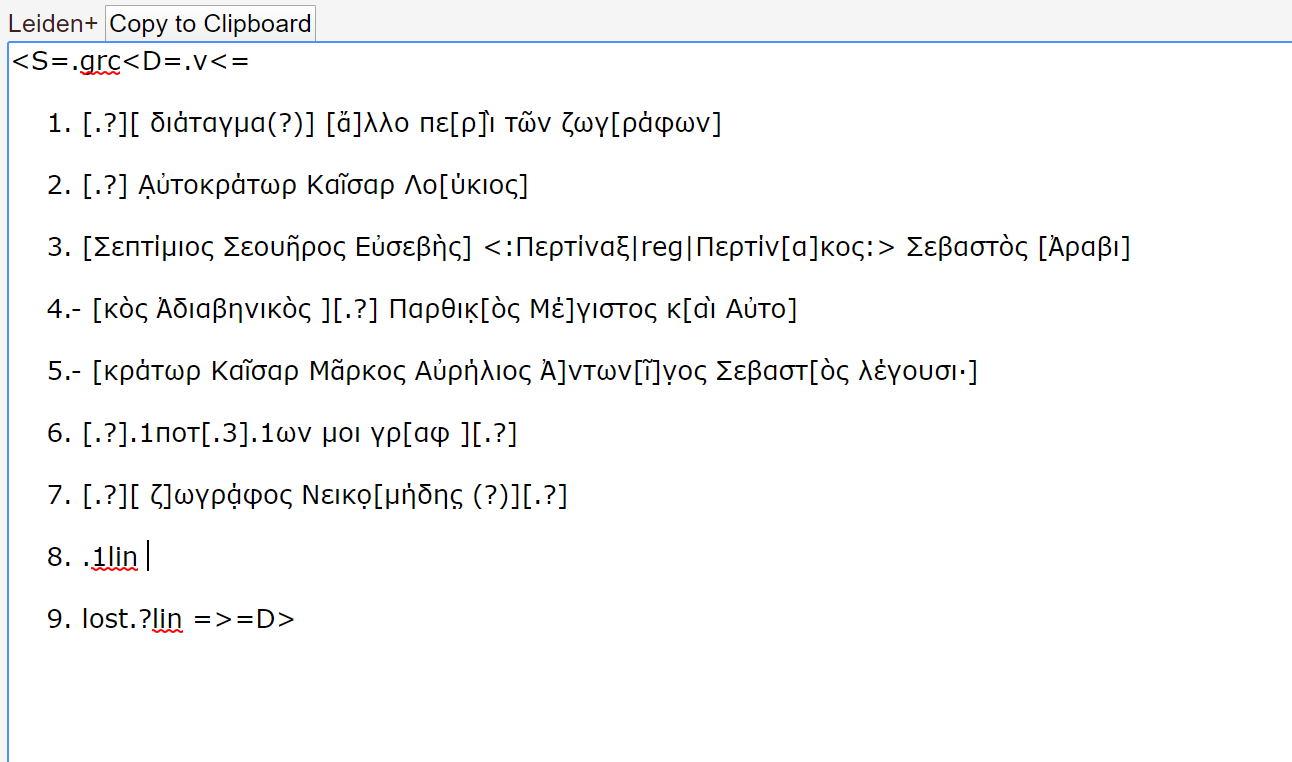
ここで、Leiden+ の規格に従ってテクストを校訂し、Save ボタンを押すと、編集結果が自動的に EpiDoc 準拠の XML ファイルに反映される(図2)。

このように専用のエディターが用意されているため、校訂者は記述が容易な Leiden+ を用いてテクストを編集するだけで、自動的に XML ファイルをも編集することができる。これにより、必ずしもデジタル校訂に慣れ親しんでいないパピルス研究者も含めた幅広い協働が可能になっていることは間違いないだろう。Papyri.info の目標の一つである既存データの EpiDoc XML への変換という課題はもちろん[6]、パピルスの総数が膨大である点、未校訂のパピルスが多数存在する点を考えても、プロジェクトの成功のためにはクラウドソーシングのような手段が不可欠であり、そのためには、校訂作業をできるだけ容易にすることが非常に重要である。その意味で、Leiden+ のような、パピルスを扱う研究者にとって親しみやすいマークアップ言語を開発し利用することが、パピルス研究者によるデジタル校訂の実践を容易にしていると言えよう。
同じことは、パピルスのみならず、碑文のデジタル校訂についても言える。Leiden 記法自体は碑文とパピルスの校訂を想定して設定された規格であるため、当然、碑文にも適用可能である。しかしながら、碑文のデータベース、あるいは Papyri.info の如きプラットフォームにおいて、Leiden+ のようなマークアップ言語を利用して広く校訂者を募るといった試みは管見の限り見出せない。こうした状況を踏まえてか Gregory Crane 氏も、パピルス研究者に比して、碑文研究者間の協働は進んでいないように思われると述べている[7]。もちろん、EpiDoc の啓蒙活動を中心に、多くの研究者が碑文のデジタル校訂に関われるようにすることを目指す動きは広まりつつあるが[8]、今後はさらに、実際にデジタル校訂に参加できる機会をいかに作っていくか、そしてなによりも、Leiden+ のような実践環境の整備・簡略化をいかに進めていくかが課題となるだろう。こうした環境整備の方向性として、校訂や異読などの文献学的情報については Leiden+ をそのまま活用することも可能であり、これを適用することは一考に値しよう。それに加えて、人名や地名、社会的関係等の歴史学的情報の取り扱いについては、別に検討していく必要があるだろう。
人文情報学イベント関連カレンダー(今後、中止になる可能性がありますのでくれぐれもご注意ください)
【2020年3月】
-
2020-03-06 (Fri)
【中止】CH 研究会30周年企画「はじめての人文情報学:情報処理技術で文化資料の分析に挑戦しよう!」(情報処理学会第82回全国大会)於・石川県/金沢工業大学扇が丘キャンパスhttps://www.gakkai-web.net/ipsj/82/event/html/event/C-3.html
-
2020-03-06 (Fri)
東洋学へのコンピュータ利用第32回研究セミナー於・京都大学人文科学研究所本館1Fガラス張りセミナー室 -
2020-03-09 (Mon)
【中止】公開講座「仏教の智慧を開く -浄土宗大本山増上寺所蔵元版大蔵経デジタルアーカイブ化-」於・東京都/浄土宗大本山増上寺光摂殿 -
2020-03-11 (Wed)
【中止】大蔵経公開講座~デジタル大蔵経の現在と未来~於・東京都/東京大学本郷キャンパス法文二号館一番大教室http://www.jbf.ne.jp/assets/files/pdf/Daizokyo/daizokyokoza20200311.pdf
-
2020-03-12 (Thu)
【中止】西洋中世学会若手セミナー「西洋中世学研究者のためのデジタル・ヒューマニティーズ入門」於・東京都/東京大学本郷キャンパス 経済学研究科学術交流棟https://drive.google.com/file/d/1jwA36b0PF2PQLdpKf6ZJNSK8KgwkhW1y/view
-
2020-03-13 (Fri)
【中止】「通時コーパス」シンポジウム2020於・東京都/立川総合研究棟(国立極地研究所、国文学研究資料館、統計数理研究所)2階大会議室https://www.ninjal.ac.jp/event/specialists/project-meeting/m-2019/20200313/
-
2020-03-16 (Mon)
【中止】第15回京都大学人文科学研究所 TOKYO 漢籍 SEMINAR『漢字と情報』於・東京都/一橋大学一橋講堂中会議場http://www.zinbun.kyoto-u.ac.jp/zinbun/tokyo_kanseki_seminar2020.htm
【2020年4月】
-
2020-04-25 (Sat)〜2020-04-26 (Sun)
デジタルアーカイブ学会第4回研究大会於・東京都/学術総合センター一橋講堂
Digital Humanities Events カレンダー共同編集人
イベントレポート「第38回人文機構シンポジウム デジタル・ヒューマニティーズってなに?:コンピュータがひもとく歴史の世界」
はじめに
2020年1月25日、東京都日比谷図書文化館にて、表題のシンポジウムが人間文化研究機構によって開催された。本シンポジウムは、学術イベントというよりは一般参加者にも開かれたイベントとして、デジタル・ヒューマニティーズ全般の可能性と課題をひろく共有することを目的として企画されたようである。プログラムの詳細については、公式ページをご覧いただきたい[1]。各講演では、本誌の読者諸氏にとってなじみ深いと思われるプロジェクトがいくつか紹介されたが、本イベントレポートでは、それぞれのプロジェクト等の詳細に立ち入るというよりは、全体を通して論点になったことを中心に紹介しつつ、私見を付け加えたい。
「デジタル」と「ヒューマニティーズ」の相補性
まずは最初の講演内容を概観したい。後藤真「コンピュータが読む日本語」では、日本史学・日本文学における文字資料とデジタル技術との関わりに焦点を絞り、(1)国立歴史民俗博物館(歴博)による Text Encoding Initiative 準拠の延喜式本文テクストのマークアッププロジェクト、(2)「みんなで翻刻」プロジェクトと人文学オープンデータ共同利用センター(CODH)のくずし字AI認識プロジェクト、(3)歴博の総合資料学情報基盤システム「Khirin」プロジェクトの概要が紹介された。これらを踏まえ、「オープンとクラウド(Crowd)」、「AI」を2つのキーワードとしてさらなる議論が展開された。すなわち、人文学のデータを構築するプロジェクトに、専門家としての人文学者に加えて、情報学者や関心ある市民、そしてAIが携わることが一般的になりつつあり、むしろこのような連携が不可欠であるケースが出てきているということである。ここで氏が聴衆に問いかけたのは、人文学者の役割を何に/どこに見出すかという点である。
この問題に対して用意された答えは、本シンポジウム全体を通して重要な論点となった「人間と機械の協働」である。つまり、非専門家(他分野の研究者や一般市民、AI)によって提供されたデータについて、それらが好ましいデータかどうかを判断し、どのように解釈して学術的・社会的価値を生み出すかに、人文学者の役割があるとした。これに関連して、最後の総合討論でも後藤氏が話題に挙げたのは、データが「正しい/望ましい」かどうかを判断するためには人文学の知見(人文知)が必要であり、その判断の基準となる人文知を社会で共有すべく発信することも人文学者の重要な役割であるということであった。
このように、AI をはじめとするデジタル技術と人文知は、相補的な関係性を保つことによってこそ望ましい発展が得られるというのは、本シンポジウムが発した主要なメッセージである。たとえば、AI によるくずし字認識は、専門家の知見を踏まえた「正解」データを学習用データとして準備することで AI がアルゴリズムを構築し、結果的に人文学者がテクストの解釈に注力することを AI がサポートする。その際、北本朝展氏のコメント「最善主義と完璧主義」が示したように、100%の精度で AI が処理できるようにアルゴリズムを開発するのではなく、80%程度の精度を目指して開発を進めることによって、研究効率が上がるとの指摘も重要である。
これまでのデジタル・ヒューマニティーズ研究では、人文学研究に対して情報学的な知見や手法をどのように活用できるかに注目が集まりがちであったが、今後は人文知にもとづく価値判断の尺度をデジタル技術の活用に適用することが求められるという見通しも示された。実際、社会の文化・慣習と適合するように AI の発展を導いていくためには、倫理的観点が欠かせない。人間社会のあり方それ自体を論じる人文学だからこそできる貢献が、デジタル技術の台頭によって浮き彫りになっていると感じた次第である。
不確かさと向き合う
2つ目の講演、朝日祥之「コンピュータが読む写真」では、AI による画像認識を通した自動タグ付けや、モノクロ映像のカラー化を扱ったプロジェクトが紹介された。日付や地理情報などのメタデータが用意されていないことが多い写真資料を第三者として分析する際、画像認識技術によってどのような要素が撮影されているかを検出することは有効である。本講演では、氏がオーストリア科学アカデミーとの共同研究で用いた CLARIFAI という Web サービスが紹介され、CLARIFAI による写真の要素の自動タグ付け結果がさまざまな形で示された。たとえば、撮影された要素の名称と件数の分布、写真資料群におけるそれらの要素同士の関係性のネットワーク表示を通じて、分析者は読み込ませた写真資料の群としての特徴を窺い知ることができる。テキストマイニングならぬ、ピクチャマイニングといった趣である。もちろん、提示された結果の分析には、ここでも人文知が必要不可欠である。さらなる分析は今後の課題とされたので、展開に期待したい。
さて、AI によるモノクロ映像のカラー化は、シンポジウム全体を通して重要な論点を提示した。「不確かさと向き合う」ことである。筆者は幼少のころ、モノクロ写真を目にするたび、「昔の世界には色がなかったのか」と誤解をしていたものだが、それはさておき想像で補うしかなかった過去の光景は、いまや深層学習に基づく自動カラー化によって、鮮明な色彩を伴ってわれわれに迫ってくる。ひとたびもっともらしいカラー画像が示されると、その強烈に鮮明なイメージはわれわれの脳裏に焼き付くと同時に、この色は「正しい」のだろうかという疑問が浮かぶこともあるだろう。この疑問に対して、冷静にふるまうよう勧めたのは、日下九八氏のコメントである。
日下氏は、長らく Wikipedia に携わってきた経験から、Wikipedia の便利さについての議論を紹介した。すなわち、Wikipedia を便利だと主張する人は、記事に書かれている内容をまるごと信頼することなく、しかし信頼できる範囲で知的活動に活用する一方で、Wikipedia を便利でないと主張する人は、記載内容を鵜呑みにしてしまう傾向にあるとした。つまり、提供されているものを鵜呑みにせず、リテラシーを持って信頼に足る部分を見極める姿勢は、Wikipedia に対しても AI に対しても共通して持つべきものだということである。
この「不確かさと向き合う」ことについては、歴史家リン・ハントによる「暫定的真実」の説明を借りてまとめよう。
ある歴史解釈が本当の事実に立脚し、論理的に首尾一貫し、できる限り完全なものに整序されているときでさえ、その解釈の真実性は暫定的なものにとどまる。新たな事実が発見されることもあるし、完全性の指標も時代によって変化するからだ[2]。
モノクロ映像のカラー化に関しても、AI が提示した結果が確からしい/もっともらしいものであろうと、その結果を鵜呑みにして不変の真実だと断ずることなく、丁寧に言葉を紡いで議論を重ねる姿勢を持ち続けるのが良いだろう。
おわりに
本シンポジウムは、一般参加者にも開かれたものということで、基本的な論点を幅広くていねいに提示したところに意義があったように感じた。それと同時に、日下氏がコメントで述べた批判、すなわち、研究成果を社会に発信する際、分析結果だけでなく分析過程の作業についてもツール等の紹介をする必要があるのではないか、研究の世界で前提となっている知識を省かずにひろく共有するのも重要ではないか、という旨の指摘が今後ひろく意識されるようになると良いとも感じた。つまり、デジタル・ヒューマニティーズの世界は、さまざまな人が多様な背景や専門性、あるいは好奇心をもって集まる場であるからこそ、前提を共有していないことを前提として、互いに足りない部分を補い合えるような共創の場であってほしいと考えるのである。
イベントレポート「「マシンと読むくずし字」シンポジウム 参加報告」
2020年2月8日、慶應義塾大学日吉キャンパスにて開催された「マシンと読むくずし字」シンポジウム[1]に参加した。「翻刻」にテーマを絞ったシンポジウムとのことであり、全体として、興味深い発表が目白押しだったが、ここでは筆者の関心のある事項に限ってご紹介したい。
天理大学附属天理図書館司書研究員の宮川真弥氏による司会により始まったシンポジウムの最初の講演は、津田眞弓氏による「実験授業<マシンと学ぶくずし字>報告」であった。慶應義塾大学では全学部の教養教育において実験授業[2]という枠組みがあり、津田氏は、これを利用し、「理系も文系も集う場」、「昔の人の文字を読むこと」、「システムの発展に貢献する実験への参画」、「古典籍に直接触れる」、といった意義を掲げて「機械(マシン)と学ぶ「くずし字」(はじめの一歩)」という授業を実施したとのことである[3]。人数制限にもかかわらずたくさんの受講があったそうだ。以下に、授業の模様についての報告を簡単にまとめてみよう。
台風による中止・順延があったものの、90分×2コマ、30名で、全三回、くずし字の翻刻と斯道文庫での古典籍に触れる授業が行われた。既習者3名のみという状況で、あとは初体験とのことであった。最初はグループ学習として展開、凸版印刷が提供する OCR 翻刻支援ツールを用いて3人一組 PC 1台で取り組み、当初は『船弁慶』を扱い、能としてどう演じられていたかも確認しながら進めた。その後、全員が各々参加する形で草双紙を扱った。草双紙では、参加者全員が1枚の紙を読んでみて、1800字/20分、正答率89%だった。草双紙の際のシステムでは、未翻刻は赤、誰かが作業している時は緑の枠が各単語・文節等の単位で付与されており、ネットで互いに進捗を確認できるため、陣取り合戦的な面白さもあったためかみんなで盛り上がった。20名ほどがログインしての作業だった。一方で、実際の和本にも触れた方が良いため、斯道文庫の佐々木孝浩先生にレクチャーをお願いし、実際に斯道文庫の和本に触れる機会も提供した。
以上が授業についての報告の概要である。さらに、今後の授業のための課題として、採点・授業の組み立てには字形のデータ、正答のデータの整理が必要になるため、一人では難しく、何らかの形でデータを共有することが有用であるという提起があった。
筆者自身、くずし字 OCR 共同翻刻を活用した授業展開の話を聞いたのは初めてだったため、非常に有用な話だった。この授業が専門分野の学生をターゲットとしたものでなく、一般教養として専攻を問わず知的好奇心を刺激する場として機能していたようであることは、今後の古典教育を考える上で大変示唆的である。今後、同種の取り組みが各地で広まっていくことを期待したい。
シンポジウムとしては、その後、大澤留次郎氏による凸版印刷くずし字 OCR とその周辺状況、橋本雄太氏によるくずし字学習アプリ KuLA から「みんなで翻刻」に至る流れとその近況、そして、海野圭介氏からは、このような動向に関して、国文学研究者の立場からみた様々な課題が報告された。それに続く全体討論では、フロアも交えつつ、この動向の先にどんなことがあるのか、ということを中心として活発な議論が展開された。
なお、このシンポジウムでは、凸版印刷のくずし字学習ツールと「みんなで翻刻」のデモンストレーションの場が用意され、6台ほどのノート PC から参加者がそれぞれに試行していた。シンポジウムの趣旨をより直接的に実感できるという点でこの取り組みは有用であったと思われる。また、本シンポジウムの全編にわたり、出版社・文学通信によりインターネット中継が提供された点も記しておきたい。
ここのところ、人文学オープンデータ共同利用センター(CODH)の活躍により AI 技術を用いたくずし字 OCR が大きく注目を浴びるようになりつつあるが、本シンポジウムはそのような仕組みが教育現場でどのようにして活用され得るかを具体的に提示してくれるものであり、筆者にとっても大いに有益であった。
◆編集後記
新型コロナウイルスで学会・研究会やシンポジウム等はほぼ一斉に中止になりました。各地で対応に苦労しておられることと思います。しかし一方で、積み上げていくべき成果やキャリアは待ってくれるわけではありません。踏むべき重要なステップをこの期間に逃してしまった、特に若手の方々には、なるべくきちんとフォローしていけるような流れができていくことを願っております。(永崎研宣)
- コメントを投稿するにはログインしてください