人文情報学月報第105号
ISSN 2189-1621 / 2011年8月27日創刊
目次
- 《巻頭言》「デジタル・ヒストリアンの Ac/Countability:レオポール・ジェニコの先駆的実践を手がかりに」
:千葉大学人文社会科学系教育研究機構 - 《連載》「Digital Japanese Studies 寸見」第61回
「「データ引用の共同宣言」日本語版公開」
:北海学園大学人文学部 - 《連載》「欧州・中東デジタル・ヒューマニティーズ動向」第22回
「Chester Beatty Digital Collections の発展:エジプト出土パピルス文献を中心に」
:関西大学アジア・オープン・リサーチセンター「KU-ORCAS」 - 特別寄稿「PapyGreek による歴史言語研究のためのギリシア語コーパス構築の試み:文書パピルスの言語学的アノテーション」
:東京大学大学院人文社会系研究科 - 編集後記
《巻頭言》「デジタル・ヒストリアンの Ac/Countability:レオポール・ジェニコの先駆的実践を手がかりに」
近年、日本の歴史学界でも、オンライン・データベースの拡充に伴って、歴史研究におけるコンピュータの利活用可能性が徐々に認められつつある。かつては、さまざまな歴史家がコンピュータ利用の弊害について論じたものだが、近年ではそうした論調は比較的低調になったようにも思われる。しかし、簡単に歴史的データにアクセスできるようになった時代だからこそ、過去を紡ぐ際の注意点は強調されるべきである。本稿では、ある先駆的なコンピュータ歴史学の実践にまつわる議論を手がかりに、今後のデジタル・ヒストリアン像を展望したい。
西洋中世史研究者にはよく知られていることのようだが、ベルギーの中世史家レオポール・ジェニコは、1960年代からすでに IBM のチームと協働して、歴史研究におけるコンピュータ利用を促進していた。その実践内容は今読んでも色あせない計量テキスト分析であり、ジェニコの先見の明には舌を巻くばかりである。たとえば、時代・場所・作者・作品ごとのキーワードの相対使用頻度や語の共起関係の分析、KWIC(Keyword in Context)分析例が詳細に紹介されている[1]。
一方、日本の近世フランス史家である二宮宏之は、ジェニコの同書を評するにあたって、1960年代初期という非常に早い段階において歴史研究にコンピュータを駆使した先進性については積極的に評価しつつも、史料に残されたテキストと歴史的現実の間に横たわる乖離に対しての意識が希薄で、「時に史料万能主義を思わせるところがある」と言語論的転回の観点から批判した[2]。
ただしジェニコは、この史料批判の問題について、コンピュータ利用の効能を引き合いに出して、ひとつのアプローチを示唆していたようにも思われる。というのも、扱う史料の真正性や伝来経路を検証するにあたって、同一著者による他の文献がある場合には、頻出語一覧やその使用頻度に基づく特徴的な表現方法を割り出すとともに、平均的な文の長さを算出して著者同定作業を行う重要性を示したのである。確かに、これもテキストに依存した分析である点で二宮の批判に完全に応えることができるわけではない。しかし、コンピュータを史料批判に利用できるひとつの可能性を示している点で興味深い。
ジェニコの研究において、歴史学の専門領域における議論の進展にコンピュータ利用が貢献した要因のひとつは、研究における有機的な分業体制だったように思われる。ジェニコは、情報学的観点での議論には踏み込まないことを明示しており、はっきりとした分業体制の下で研究プロジェクトを進めていたことがわかる。それでも、互いの領分を行き来できるような研究チーム作りが行われていたことが窺える。コンピュータの領分としてジェニコが強調したのは、正確で網羅的な計算、そして歴史家の領分は、その計算結果の解釈と説明である。つまり、コンピュータの計算する力 Countability を利用し、その結果を歴史の文脈に落とし込んで説明する力 Accountability が歴史家に求められていると言い換えることができよう。
いまや、パーソナルコンピュータやインターネットの発展・普及に伴い、個々人が高度な計算やデータ分析をできるような時代になった。歴史研究者も、さまざまな情報源から簡単に史料の各種データを取得することができるようになった。このような状況の中で、データ分析手法に習熟することに注力するあまり、分析対象としたテキストそのものの歴史的背景や妥当性に意識がいかないような片手落ちは避けたいものである。逆に、コンピュータの計算能力を充分に駆使しようとすることなく、歴史の未開拓領域を手つかずのままにしておくことも勿体ないことではないか。デジタル手法に長けた歴史家、すなわちデジタル・ヒストリアンは、Ac/Countability を兼ね備えるか、集合的に双方のリテラシーを兼ね備えるチーム作りとその中での橋渡し役として協働研究に貢献することが期待されていると思われる。このような人材を志す研究者にとって、ジェニコの先駆的実践はひとつの道標として参照に値する。
最後に、私事で恐縮だが、2020年4月1日から千葉大学人文社会科学系教育研究機構の助教としてデジタル・ヒューマニティーズ教育に携わることになった。ひとりの研究者としては、デジタル・ヒストリアンの範となるような成果を出すことに努め、ひとりの教育者としては、Ac/Countability を兼ね備えた人材を輩出できるように励みたい。
執筆者プロフィール
《連載》「Digital Japanese Studies 寸見」第61回
「「データ引用の共同宣言」日本語版公開」
私事であるが、2020年4月より北海学園大学人文学部に着任した。連載を開始したときと同じ札幌に戻り、また職としてデジタル人文学をもっぱらとしなくなって、これまでと同じようには行かないかもしれないが、ひきつづき動向に注意を払っていきたい。
さて、2020年1月のこととされるが、研究データ利活用協議会リサーチデータサイテーション小委員会から「データ引用の共同宣言」の日本語訳が公開されている[1][2][3][4]。これは、研究データの流通変革を目指す運動組織である FORCE11が2014年に公開した文書の翻訳である[5]。
研究データをどう引用するかという問題は、検証可能性を高めるという観点や、そもそも研究評価においてデータ作成が評価されなくなるにしたがって必然的に問題となった[3][6]。引用データベースに入らないと評価が適切にされないというのは、研究評価に関する研究者らによる声明であるライデン声明の危惧することそのもののようにも思うが[7]、とはいえ、そのためにデータ解説の論文を書いてそれを引用させるというような対処もあり、データそのものの評価のありかたを考える必要はあったといえよう。
この文書は、さまざまな分野でデータの引用と活用を容易たらしむる引用習慣を形成する際、考えるべきことがらについての指針を与えるもので、それじたいはごく短い。これに付随して、用語集と起草者たちの想定する引用の方式を説明する文書があるが、これについては訳出されていない。宣言は8項目からなり、日本語版の表現を借りれば、「重要性」・「クレジットと帰属」・「エビデンス」・「識別」・「アクセス」・「永続性」・「特定性と検証可能性」・「相互運用性と柔軟性」の観点から「人間が理解でき、かつ機械が使用できる引用方法を提示する」[2]ものである。ここで「機械が使用できる」とされた箇所は、原文では machine-actionable とあり、用語集によれば、コンピュータが利用し操作できる内容であることをいう。機械可読 machine-readable であることは当然として、FAIR 原則の理念のもと、機械がプログラムのもとにみずからデータに対して行動を起こしていくことをも意図したという[8]。内容としてはデータがそれじたいとして価値のあるものと認めるべきことを訴えるほかは、引用形式の議論としては常識的な内容が述べられている。
なお、訳についてすこし述べれば、もうすこし検討の余地があるようにも思える。たとえば、前述の machine-actionable を「機械使用可能」と訳すのは分かりやすいことであろうか。actionable は「実用」という訳が見え[9]、こちらのほうが意図をよく伝えるように思うがいかがであろうか。その他、誤訳がわずかに見られるが、原文も分かりにくくはないので訳文で気になった際に参照すればあまり問題とはならないものと思われる。
このような宣言の企図するところは、分野における議論を促進するところにあるわけであるから、本宣言が提出されてから5年を経てなおデータ引用がじゅうぶんに議論されているとは言いかねる状況は憂慮に足るものといえよう[3][6]。デジタル人文学における状況を考えてみると、資料提供機関が引用をお願いしつつ、願ったとおりの形式で引用されないという問題を仄聞するところである。そのことじたいは、科研費が検索できもしない形式で研究課題番号の引用を課すようなもので、分野との対話を経ずに事情によってそのようなお願いをしているのだから、座視していても変わらないのは道理ではある。デジタル人文学そのものがまだ引用データベースと付き合いかねている状況で、ひとり提供者たちが引用を求めても理解は得られまい。
その点、この宣言は引用評価に関する考え方が分かりやすく示されており、引用評価全般が議論の進んでいない分野において、とっかかりとして読むのもいいように思われる。訳者らはデータ引用に関する理解の深まりを願って翻訳したというが[10]、ちょうど人文系の研究評価について議論が急ピッチで進められているところでもあり[11]、時宜を得たものといえよう。
“野村さん、能勢さんと書きました。3行でまとめると、
- 研究者は、データを公開しても引用されないことが心配+公開のインセンティブとして引用を重視
- でもデータ引用は普及していない
- そこで図書館や学術界がデータ引用を広めるのに使えそうな国際共同宣言を翻訳してみましたー
という話です。…”
https://twitter.com/oui_ui/status/1232962088449933314?s=21.
《連載》「欧州・中東デジタル・ヒューマニティーズ動向」第22回
「Chester Beatty Digital Collections の発展:エジプト出土パピルス文献を中心に」
チェスター・ビーティ図書館は、アメリカ人の鉱業実業家アルフレッド・チェスター・ビーティ卿 (1875–1968)によって集められたコレクションを元に開かれた図書館で、元はロンドンにあったが、2000年に、卿が晩年活躍したダブリンに移された。現在はダブリン城の一角を占める建物にあり、世界中の貴重な文献・美術品を所蔵しているため、世界中の大勢の研究者がここを訪れている。

この図書館は、特に、日本、中国、東南アジア、インド、中近東の古今の貴重な文献や絵画、そして、筆者の専門である、エジプト出土の大変貴重なギリシア語およびコプト語で書かれた初期キリスト教やマニ教[1]などのパピルス文献や、コプト語以前の段階の古代エジプト語のパピルス文献を多数所蔵していることで有名である。
チェスター・ビーティ図書館は、そのオンライン・アーカイブである Chester Beatty Digital Collections を現在公開している[2]。プロジェクト自体は2017年から始まっている。現在は1人のフォトグラファー、そして1人のデジタル・キュレーターを含めた4人がこのプロジェクトのチームである[3]。Instagram[4]やブログ[5]でも情報発信を行っている。とくに Instagram ではプロジェクトが作成したチェスター・ビーティ図書館の諸文献の美しい写真を見ることができる。しかしながら、2020年4月18日時点では Instagram のポストはたった12個であり、より高頻度のポスティングが求められる。ブログのほうもまだ5つしか記事がない。しかし、ブログには、使用している機材などの詳細が書かれており、読みごたえがある[6]。ブログによれば、カメラマンは Phase One XF のカメラに IQ380のデジタル・バックをつけて使用しているようである。Phase One はデンマークの視聴覚機械器具・光学器械器具メーカーであり、プロフェッショナルな高級カメラなどを生産している。
このデジタル・アーカイブのビューワーでは、ビューワーの画面の右横のコラムの一番下の「Downloads」の縦型タブから高画質の写真を JPEG、PNG、そして PDF 形式でダウンロードできる。オブジェクトのメタデータはメタデータ記述の標準形式の一つである METS 形式でダウンロードでき、さらに、国際的な画像の相互運用の枠組みである IIIF の Presentation Manifest を取得することもできる。この IIIF Presentation Manifest により、別のサイトでのオブジェクトの二次利用が容易になる。画像データの私的利用は無料であるが、出版物や商用物に掲載する場合は、費用を図書館に支払わなければならず、その場合は図書館に連絡するようにと書いてある。
現時点ではこのデジタル・コレクションには2,770点のオブジェクトがある。これらのオブジェクトは、現在、26のコレクションに分かれている。それらのコレクションの内訳は、「アラブ・コレクション」[7]、「アルメニア」、「聖書パピルス」、「ビルマ」、「中国」、「粘土板」、「コプト」、「エジプト語パピルス」、「エチオピア」、「ヘブライ」、「インド」、「インド(非ムガル)」、「イスラーム」、「日本」、「マニ教パピルス」、「マートン・パピルス」、「パピルス」、「ペルシア」、「スマトラ」、「シリア」、「タイ」、「チベット」、「トルコ」、「西洋」、「西洋種々雑多」、「西洋版画と絵画」である。順序は、英語でのアルファベット順である。「粘土板コレクション」は、シュメール語やアッカド語など楔形文字を用いた古代メソポタミアとその周辺の諸言語の粘土板文献のコレクションである。また、「シリア・コレクション」は、古典シリア語のキリスト教文献がメインである。コプト語はエジプト語の最終段階だが、「エジプト語パピルス・コレクション」は、コプト語以前のエジプト語、すなわち、古エジプト語、中エジプト語、新エジプト語、および、民衆文字エジプト語で書かれたパピルスのコレクションを指しており、コプト語パピルスはここではなく、「コプト・コレクション」に入る。この図書館のマニ教パピルス文献はコプト語で書かれたが、これらは、「コプト・コレクション」には入らず、「マニ教パピルス・コレクション」に入っている。このように、これらのコレクションでは、各コレクションの名称が指し示すものの住み分けが完全にはなされておらず、多数の重なりがある。ほかにも、例えば、「聖書パピルス・コレクション」には、パピルスに書かれた聖書の断片などがあるが、「パピルス・コレクション」という「聖書パピルス・コレクション」と同列に扱われているコレクションにも、パピルスに書かれた聖書の断片が入っている。ただし、「パピルス・コレクション」のほうは、ギリシア語による手紙パピルスなど、聖書パピルスでもコプト語パピルスでもマニ教パピルスでも古代エジプト語パピルスでもないものが主体である。しかし、「聖書パピルス・コレクション」があるなら、どうしてギリシア語聖書パピルスのいくつかが、「聖書パピルス・コレクション」ではなく、「パピルス・コレクション」に入っているのかが不思議である。そして、カテゴリーはこれらと重複するものの、Wilfred Merton(1888–1957)が収集した「マートン・パピルス・コレクション」はこれらとは同列の別コレクションになっている。
このデジタル・アーカイブで筆者が特に注目しているのは、マニ教の教義が記された、世界で2つ残存している『ケファライア』のうちの一つ、「ダブリン・ケファライア」[8]の高画質写真が公開されていることである。これは、コプト語のうちのリコポリス方言(別称:準アクミーム方言)で書かれている。このサイトで使い辛いのは、基本的に様々な写本がフォリオ毎に分けられ混ざって写本毎に整理されずに公開されていることである。例えば、「マニ教パピルス・コレクション」を選んだ場合は、『ケファライア』の写本のフォリオが『シナクシス』や『詩編』や『説教集』などの他のコプト語マニ教文献の写本のフォリオと一緒に混ざって表示される。「マニ教パピルス・コレクション」を選択したあと、様々な文献が選択でき、それらの文献の中で『ケファライア』を選択すれば、そのフォリオが順番に表示される、といったシステムにしたほうが、より整理され、ユーザにとってより便利であろう。

この図書館は、エジプト出土の初期キリスト教時代の聖書や聖書外典の写本のパピルス文献でも有名である。これらは「聖書パピルス・コレクション」を選択すれば表示される。こちらは「マニ教パピルス・コレクション」と異なりページ毎に分けられているものもあるが、文献が混ざって表示されるのは同じで、非常に使い辛い。このように、写本など文献毎ではなく、フォリオまたはページ毎に様々な文献が混ざって表示されること、また、コレクションのカテゴリー分けに様々な重複があり、時々目的の文献を探しにくいことがこのデジタル・アーカイブの改善すべき点である。しかし、IIIF Presentation Manifest を公開していること、そしてマニ教文献など大変貴重な文献を高画質のまま様々な形式でダウンロード可能にして公開していることは大変高く評価されるべきである。
特別寄稿「PapyGreek による歴史言語研究のためのギリシア語コーパス構築の試み:文書パピルスの言語学的アノテーション」
PapyGreek(Digital Grammar of Greek Documentary Papyri)は、フィンランド・ヘルシンキ大学の古典学者 Marja Vierros を代表とし、言語学部が中心となって運営するプロジェクトであり、ギリシア語の歴史的変遷を形態・音韻の両面から研究するためのデータ構築を目的とする[1]。そのために、テクストへの言語学的アノテーション付与を共同で行うためのプラットフォームを用意し[2]、幅広い協働が可能になる環境を整備している。
このプロジェクトで扱う主なテクストは、ヘレニズム時代からアラブによる征服までの約1000年間に、主にエジプトで作成、保存されたギリシア語文書パピルスである。文書パピルス(documentary papyri)とは、一般的には文献パピルス(literary papyri)と対置される種類の史料で、行政文書等の公的文書および書簡、契約書などの私的文書を含む。詩や文学を記す文献パピルスに比べ、作成当時の言語使用状況をよく反映するものとされ、古典期以後のギリシア語の歴史的変遷を扱う言語研究には不可欠なテクストである。
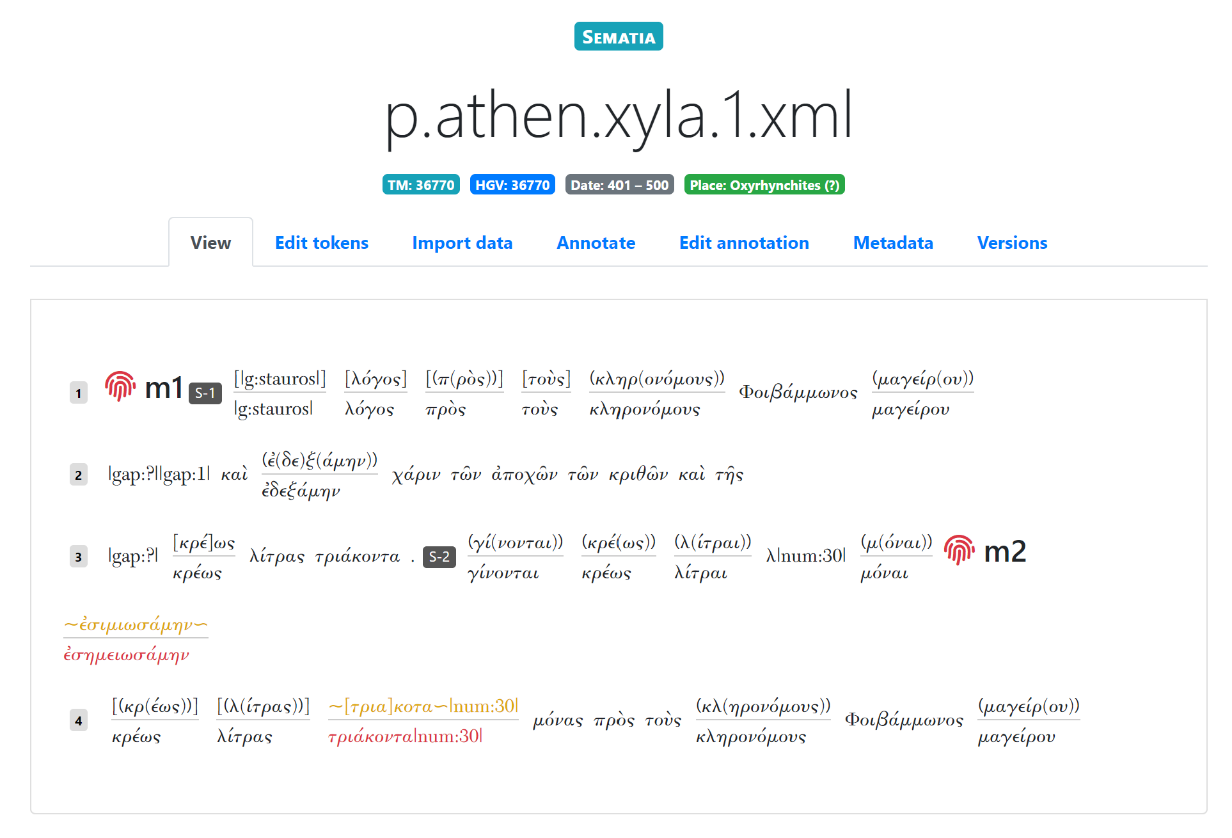
さて、ここからは PapyGreek の操作について具体的にみていく。サインインしたのち、まずはアノテーションを付与するパピルス文書を選択することになるが、これはページ上部の "Collections" から行う。"Collections" には、「文書パピルス documentary papyri」「文献パピルス literary papyri」「碑文 inscriptions」の三つの項目があるが、上述の通り文書パピルスが主要なテクストであり、「文献パピルス」と「碑文」については未だ整備が進んでいないように見受けられる。文書パピルスのテクストデータは、Papyri.info と同様に DDbDP(Duke Databank of Documentary Papyri)のものを利用している[3]。パピルス文書を選択すると、テクスト表示・編集画面に遷移する(図1)。
(https://papygreek.hum.helsinki.fi/text/22280)
この画面におけるテクスト表示方法は、PapyGreek 独自のものである。ここで注目すべきは、テクスト中で上下2段になっている箇所である。PapyGreek においては、テクストの「オリジナル」と「レギュラライズ」、すなわち史料に記されたままの形と、辞書に則った形での正書法を明確に分離し、別々にアノテーションを行うことが重視されており、ここでは上段が「オリジナル」、下段が「レギュラライズ」された語となっている。すでに述べたように、テクストそのものは DDbDP から、おそらく XML 形式でエクスポートされたものである。ただし、Marja Vierros の説明から考えるに[4]、PapyGreek ではデータ形式を変換し、校訂・異読情報は保持したうえで、XML タグを取り外しているものと思われる。なぜならば、PapyGreek ではアノテーション付与のためにテクストを Arethusa にアップロードする必要があるのだが[5]、Arethusa は予めツリーバンク形式で構造化されたものを除いて[6]、XML ファイルのアップロードはできないからである。Arethusa 自体では、プレーンテクスト入力、あるいは Perseus Digital Library と連携したテクストインポートが可能だが、PapyGreek では、Arethusa へのアップロード可能な何らかの形式にデータを変換しているものと考えられる。
さてアノテーションについてであるが、"Annotate" タグをクリックすると、"Original" と "Regular" の二択が表示される。すでに述べたように、PapyGreek においては「オリジナル」と「レギュラライズ」の区別が重要であり、別個にアノテーションを行う必要がある。これによって綴りや語形の「揺れ」をデータ化し、その変遷の研究に用いることができるのである。校訂者が "Original" か "Regular" のどちらかを選択し、"edit" をクリックすると、選択したほうのテクストが Arethusa にアップロードされ、アノテーション付与画面に移行する。ここからのアノテーション付与の具体的な操作は、前号に掲載した論考において詳述したのでここでは省くが[7]、「オリジナル」のアノテーションを行う場合には、語の原形(lemma)などの入力に際しても史料に記されたままの形(綴り・語形など)を保持することが重要である[8]。
アノテーション付与が完了したら、これを提出(submit)する必要がある。提出は "edit" の隣にある "submit" から行うことができ、承認されればデータとして公開され、PapyGreek からダウンロードが可能になる。PapyGreek は、アカウント登録をすれば誰でも自由にテクストを選択し、アノテーションを行うことができるオープンプラットフォームであり、クラウドソーシングの理念に沿ってデータ構築を目指すプロジェクトであると言える。それゆえ、クオリティコントロールは必然的に問題となるが、提出/承認というプロセスを経ることで、この問題に対処しているものと思われる。このようなシステムが、一定のクオリティを担保するために有用なことは疑いなく、あとはプロジェクトの規模、承認者の負担とのバランスの問題になるだろう。
ここまでで、パピルス文書に対するアノテーション付与作業は完了する。このように作成されたデータは、言語学者間で共有され、ある種のビッグデータに基づいた歴史言語学的研究に寄与することになる。パピルスという史料は、一つ一つは断片的であることが多いものの、その総数は膨大である。これをデータ化、しかも言語学研究に利用可能なアノテーションを施してデータ化するとなれば、パピルスに携わる研究者間の協働無くしては不可能である。その点、Papyri.info や Arethusa―ひいては Perseids Project に代表される Open Philology の試み―と連携しつつ、協働を容易にしている点は高く評価されよう。このプロジェクトは未だ進行中であり、現状ではアノテーション付与済みのテクスト数も限られているように思われるが、今後もプロジェクトが長く継続されるならば、ヘレニズム期からイスラーム支配に至るまでの約1000年という途方もないスケールで、歴史言語研究に資するギリシア語言語コーパスが構築されることになるはずである。
◆編集後記
この4月から、連載記事を持ってくださっているお二人に加え、巻頭言を執筆された小風氏も、新天地にて活動を開始されました。COVID-19 の影響による授業や研究活動の大規模なオンライン化という 未曾有の事態の中で新しい仕事に取り組み始めるというのは、仕事量が多くなってしまうだけでなく不安も多く大変なことだろうと思いますが、一方で、皆様それぞれに、人文情報学という 観点を活かして新たな局面を切り拓くべく、建設的に研究・教育に取り組んでくださるだろうという期待も大きく持っております。今後を楽しみにしております。
オンラインでのイベントも世界的に急速に広まりつつあり、日本でも、 4/26の UTDH アンカンファレンス、4/29の Day of DH 2020 UTokyo Digital Humanities Meetup など、人文情報学関連のオンラインイベントも徐々に出てきています。 今月号には間に合わない日程だったこともあり今回は採り上げられませんでしたが、 今後は、オンラインイベントにも焦点を当てていきたいと思っております。 (永崎研宣)
- コメントを投稿するにはログインしてください