人文情報学月報第136号【前編】
ISSN 2189-1621 / 2011年08月27日創刊
目次
【前編】
- 《巻頭言》「新しい「目」としてのテキストマイニング」
:上智大学基盤教育センター - 《連載》「Digital Japanese Studies 寸見」第92回
「比較実演芸術データベース「Global Jukebox」が正式リリース」
:北海学園大学人文学部 - 《連載》「欧州・中東デジタル・ヒューマニティーズ動向」第53回
「世界最大の古代エジプト語コーパス Thesaurus Linguae Aegyptiae の大刷新:TLA v2.0」
:人間文化研究機構国立国語研究所研究系
【後編】
- 《連載》「デジタル・ヒストリーの小部屋」第11回
「透明性・正確性・情報の密度:デジタル・ヒストリーと可視化(2)」
:千葉大学人文社会科学系教育研究機構 - 《連載》「仏教学のためのデジタルツール」第1回
「オスロ大学の Bibliotheca Polyglotta / Thesaurus Literaturae Buddhicae」
:東京大学大学院人文社会系研究科 - 人文情報学イベント関連カレンダー
- イベントレポート「TEI 2022参加報告」
:ROIS-DS 人文学オープンデータ共同利用センター(CODH) - 編集後記
《巻頭言》「新しい「目」としてのテキストマイニング」
筆者はこのたび、日本の大正期の思想的テキストを題材にテキストマイニングを用いた研究を行い、その成果を永崎研宣氏とともに執筆した共著論文が「じんもんこん2022」に採択された。研究の詳しい内容は『じんもんこん2022論文集』を見ていただくとして、今回はその研究を進める過程で考えた、哲学・思想研究におけるデジタル技術活用の可能性と意義についての私見を述べたい。
筆者の専門は哲学・倫理学で、19世紀後半から20世紀前半にフランスで活動した哲学者 アンリ・ベルクソンの哲学を主に研究している。今回テキストマイニングを用いた研究に取り組むことになったきっかけは、大正時代の日本にベルクソンを論じたテキストが数多く存在していることが分かったことだった。大量のテキストの読解のために、それらの全体の傾向や「読みどころ」を掴む方法はないか、と考えていたとき、テキストマイニングを用いた研究が有効なのではないかとひらめいたのだった。
とはいえ、これまで思想・思想史研究分野ではテキストマイニングを用いた研究は先例があまりない。筆者が研究者としての訓練を受けた大学院の倫理学研究室でも、研究の出発点はなんといってもテキストの「精読」だった。ひとりの思想家のテキストを、何年も繰り返し読み、思想史全体の知識も踏まえながら自分なりの「読み筋」を見つけ、テキスト解釈を行っていく。筆者もそのスタイルの研究を続けてきた。だから、テキストマイニングを用いた研究は、伝統的な精読ベースの研究の補助的な手段となればいいな、という軽い期待のもとで取り組み始めたのだった。
ところが、今回の研究において、テキストデータを作成し、KH Coder によってもたらされた結果を眺めながら、私は新しい「目」をもったような不思議な感覚にとらわれていた。私は、今まで知っていた「読む」とは違う手法を用いてテキストを捉えていると感じたのである。補助的な手段に過ぎないと考えていたが、実はテキストマイニングだからこそ示しうることがあるのではないか。そうした感覚を得た。それが何か、という答えはまだはっきりと掴み得ていないから、これより後の考察はすべてアイディアの段階であることをお許しいただきたい。
思想研究の進展プロセスを考えると、第一ステップとして、精読と思索という研究者の内心で展開するプロセスがある。第二ステップとして、それを論文や口頭発表へと表現する段階がある。そして、第三ステップとして、提示された研究成果の意義や価値を決める学術的コミュニティでの批評という段階がある。新しく提示された研究成果は、公共の場である学会で議論されたり、書評が出たりすることによって、やがて評価が定まっていく。プロセスを単純化すれば、[1. 精読と思索(内心)]→[2. 表現]→[3. 批評(公共)]となる。内心で形成された研究成果の客観性は、発表後に、公共である学術コミュニティでのレビューによって担保されるという構造だ。
テキストマイニングは、テキストの量的分析によって、内心プロセスに量的データという客観的な素材をもたらす。つまり公に発表する前に、客観的なデータが与えられるのである。その客観性は、分析対象のデータが正しく、分析手法に妥当性があれば、誰が試行しても揺らがない堅固なものである。テキストマイニングを用いた研究では、精読という研究者の「目」を用いた手法に対して、コンピュータ・プログラムによる分析という新しい「目」が加わっているのである。この新しい「目」はどのように働き、どのように私たちの知を変えていくのだろうか。それを考えてみたいと思うようになった。
比較文学研究者の F. Moretti が「精読 close reading」に対して「遠読 distant reading」を提唱したのは、文学史におけるいわゆる「正典(カノン)」ではない、忘れられた無数の文学作品を扱うためだった[1]。精読では量的にも言語的にも扱いきれないテキストを、図式化やプロットの分析によって、その意義や傾向を捉えようとする発想である。
この発想は、哲学・思想研究にも有効である。永崎研宣は人文情報学が哲学・思想研究にもたらす可能性について、「研究基盤の構築」と「気づきの支援」の二側面を挙げる[2]。前者は、「SAT 大正新脩大藏經テキストデータベース」に代表されるような、研究に利用されるテキストの基盤を整備するという貢献である。後者の「気づきの支援」が、Moretti の「遠読」ともつながりをもつ概念であり、これまで量的に扱いきれなかったテキストを、デジタル技術を用いて分析することによって、研究における気づきを支援するというものである。Moretti が注目した正典以外の作品のように、思想研究においても、今では読まれない忘れられた思想家の作品は数多い(今回筆者が行ったベルクソン受容研究で主要なアクターとなっている大正期の在野批評家らがまさにそうである)。読み継がれなかった思想家が何を考えていたのかを捉えることは、その時代の思潮全体を捉えることに繋がっていく。正典の作者も時代のなかで思索を紡いだのであるから、周縁の思想家の研究が進むことで、正典となっている思想家の読解にもそれがフィードバックされ、より豊かなその時代の思想像を私たちは手にすることができるだろう。デジタルの「目」は、そうした意味で思想史研究をより豊かにしうる。
加えて、量的な豊穣化という側面だけではなく、数量化されたデータという堅固なデータが内心の解釈プロセスに入ってくることで、テキストそれ自体が新たな相貌を見せる面もあるのではないか、と筆者は考えている。私たちの手元に現在あるテキストは、人類の知的活動の成果であり、生産物である。そうした対象(モノ)としてのテキストに対して、従来型の精読は、時代や言語や思潮のさまざまな制約を受けた私という一個人の目を通じてアプローチすることであった。それに対して、プログラムによる分析は、私個人を縛る制約から離れた角度からのデータを提示する。テキストマイニングという「目」によって、内心プロセスに別の視角が入りこむのである。それによって見えてくるテキストは、精読のみの場合とは異なった一面を私たちに見せるだろう。テキストマイニングによってもたらされたデータを解釈することは、私たちが精読でこれまで何を読みとってきたのかということを問い直す契機にもなると思われる。
テキストマイニングによって、思想研究に何がもたらされるのかを、筆者はまだ明確に定式化することができない。人文情報学での試行錯誤を続けながら、デジタルという新しい「目」がもたらすものの可能性を考えていきたいと思っている。
執筆者プロフィール
《連載》「Digital Japanese Studies 寸見」第92回
「比較実演芸術データベース「Global Jukebox」が正式リリース」
Association for Cultural Equity(以下 ACE)は、慶應義塾大学のパトリック・サベジ氏の研究室の協力のもと、比較パフォーミングアーツ(実演芸術)のデータベースであるという Global Jukebox の正式リリースを発表した[1][2][3]。正式リリースは報告論文[2]の公刊をもってのことのようで、2022年11月2日のことと思われる。また、ここでいう実演芸術とは、慶應義塾大学からのプレスリリースでは「伝統芸能」とされているが[4]、現代音楽も必要に応じて含まれていて、伝統芸能にかぎられるものではないようであるし、また、実演芸術とはいっても、文化人類学の観点から、そのなかでも音楽とそれに附随する要素に注目したもののようである。Global Jukebox は2017年に暫定版が公開されていたが、5年間のデータ分析を経て、このたびの正式公開を迎えたものだという。
ACE は、この Global Jukebox の根幹となるデータを蒐集した音楽学者のアラン・ローマックスが1983年に設立したもので[5][6]、それぞれの文化が平等に権益を享受することをうったえる慈善団体である。ローマックスの死後、娘で文化人類学者のアナ・L・C・ウッド氏が、ローマックスの残したデータを生かし、遺志を受け継いで活動の中心をしているものだという。ローマックスはアメリカの民族音楽の研究を1930年代末からアメリカ議会図書館の委嘱で行っていたが、伝統文化があたらしい経済文化に押しつぶされそうになっているのを目の当たりにして、記録することで対抗しようとしたという。そこで60年代から80年代にかけて、アメリカを越えて、世界の伝統音楽の記録を行ったということである。その録音や一部の実演風景の記録録画も ACE で公開されている[7]。
ローマックスは、たんに記録を取ればいいとしたのではなく、カントメトリクスという研究手法を提唱し、音楽文化を数値化して、そのうえで比較を行うことを試みた。その実践がこの Global Jukebox のプロトタイプであったが、ローマックスは2002年に没し、それ以来ウッド氏が引き継いでいたということである[8]。
今回の正式公開でデータ整備を主導したサベジ氏は、比較音楽学の研究者で、とくにパターン変化についての業績がある[9]。カントメトリクスの観点からも Global Jukebox を用いた研究をさっそく行っている[10]。
今回の報告論文によれば[2]、1,026の文化から蒐集された5,776曲について、ローマックスのカントメトリクスで指摘された9つの要因からおもに分かれた37変数の評価を行い、データセットが作成された。それと関連する音楽や言語などの要因についての6のデータセットが用意され主たるデータセットができ、それを補う社会的要因についてのふたつのデータセットも作られている。すべてのデータセットは GitHub 上および Zenodo 上で公開されているという[11]。それぞれの曲は、暫定版から正式公開までのあいだに、データセットの質の向上のみならず、多文化比較に必要なデータセットとの相互参照や記述の充実などが図られたとのことである。データセットに関する記述としても、補遺として付されたデータセットの記述が70ページに及ぶことから窺えるように、微細に及ぶものである。そこには、今後のデータセット整備予定についても触れられている。データセットの信頼性については、比較音楽学の話になるので稿者の能力を超えているが、これがどういう意味を持つのか今後の検討が期待される。
データセットについては公開されているが、録音そのものについては、継承コミュニティの権利の保護の観点から、過半が視聴のみの許可とされ、2000件程度が研究利用できるようにされている。継承コミュニティからの許諾を得られなかった等の理由から、視聴もできないものがあるという。
Global Jukebox は、いま見たようなデータセットを可視化するものだけでなく、教育的なコンテンツも用意されており、出自の多様性を音楽で辿るようなコンテンツ(“Find your musical roots”)などが用意され、文化的断絶の回復を重視していることが窺える。アカウントを作成するとこれらのコンテンツの結果が保存できるほか、再生リストの共有もできるようになっている。
日本という観点で見てみると、Lomax Digital Archive[7]にはまったく日本に関するデータは見られなかったが、こちらにはローマックスの協力者などから得られた録音が収められている。アイヌの分類のためかと思われるが、北海道は和人文化もふくめて東北ユーラシアに含まれているのは注意が必要だろう(和人文化といっても、「江差追分」しかないが)。和人および琉球(および韓国)のデータは、桝源次郎によって蒐集された録音をもとにローマックスがコロンビアから出版したもの[12]などに基づいている(桝らの蒐集がローマックスからの委嘱によるものなのかは分からないが、データの由来についてはそこまで説明がない)。アイヌの録音については、近藤鏡二郎やフォスコ・マライーニによるものが多い。日本研究での利用からすれば、国立国会図書館の歴音などともあわせて[13]、比較できるものが増えていれば興味深いのであろう。
教育的観点ということでいえば、この手のことに無知な人間という立場になったつもりで見てしまうと、すこし世界の広さに放り出される感じが強い。出自文化の尊重という点でも、複雑な人間の移動からすると、すこし安易な仮定を前提にしているようにも思える。前近代の尊重(といっても20世紀半ばの採録ではある)は、もはや、戦後七十年を経た若者にはもう一段の間が必要なのではないだろうか。それが、このような研究と教育を両立させるプロジェクトのかたちを取れるかは分からないが、曾祖父母の世代の文化にいきなり帰れというのは、やはり濫妨なのだと思う。
《連載》「欧州・中東デジタル・ヒューマニティーズ動向」第53回
「世界最大の古代エジプト語コーパス Thesaurus Linguae Aegyptiae の大刷新:TLA v2.0」
Thesaurus Linguae Aegyptiae (TLA)[1]は、世界最大の古代エジプト語の辞書及びコーパスである。古代エジプト語は、単語レベルでは紀元前32世紀頃から書記記録があるが、TLA は、文レベルの書記記録が現れる紀元前27世紀頃から、コプト文字で書かれたエジプト語であるコプト語を除外した、最後の古代エジプト文字の書記記録である紀元後5世紀までの、可能な限りの全てのテキストを対象としている。
前身は世界最大の古代エジプト語辞典、『エジプト語辞典(Wörterbuch der Ägyptischen Sprache)』[2]のプロジェクトであった。その後、この辞書を拡張し、全ての用例をコーパスを用いて示す計画が練られた。これは、元々は紙ベースのプロジェクトであったが、デジタル化の波に押されて、デジタルプラットフォームをつくり、2004年に、前身プロジェクトの創立者の1人であり、古代エジプト語学の大家であった Adolf Erman の生誕150年を記念して、第一版のウェブアプリケーションが公開された[3]。
これは、基本となる語彙の検索と、その用例の検索、そしてコーパスの閲覧が基本的な機能となっているアプリケーションである。ベルリン・ブランデンブルク科学アカデミーとザクセン科学アカデミーを中心に編集・開発がなされてきたが、コーパス自体は、様々な研究機関から提供されている。ドイツには、科学アカデミーという組織が各地にあり、通常は州もしくは都市単位となっている。ベルリン・ブランデンブルク科学アカデミーは都市ベルリンとブランデンブルク州が、ザクセン科学アカデミーはザクセン州が、ゲッティンゲン科学アカデミーはゲッティンゲンという都市が単位となっている。科学アカデミーは、3–5年単位のドイツ研究振興協会の諸プロジェクトよりも長く続く規模の大きいプロジェクトを擁していることが特徴である。例えば、グリム兄弟がはじめた『グリム・ドイツ語辞典』プロジェクトは、第二次世界大戦後、東ドイツのベルリン・ブランデンブルク科学アカデミーと、西ドイツのゲッティンゲン科学アカデミーが継続させた。筆者が関わっていた、ゲッティンゲン科学アカデミーのコプト語訳旧約聖書デジタルエディションプロジェクト[4]も20年以上続けることを予定している。このように TLA も数十年続く長期のプロジェクトである。
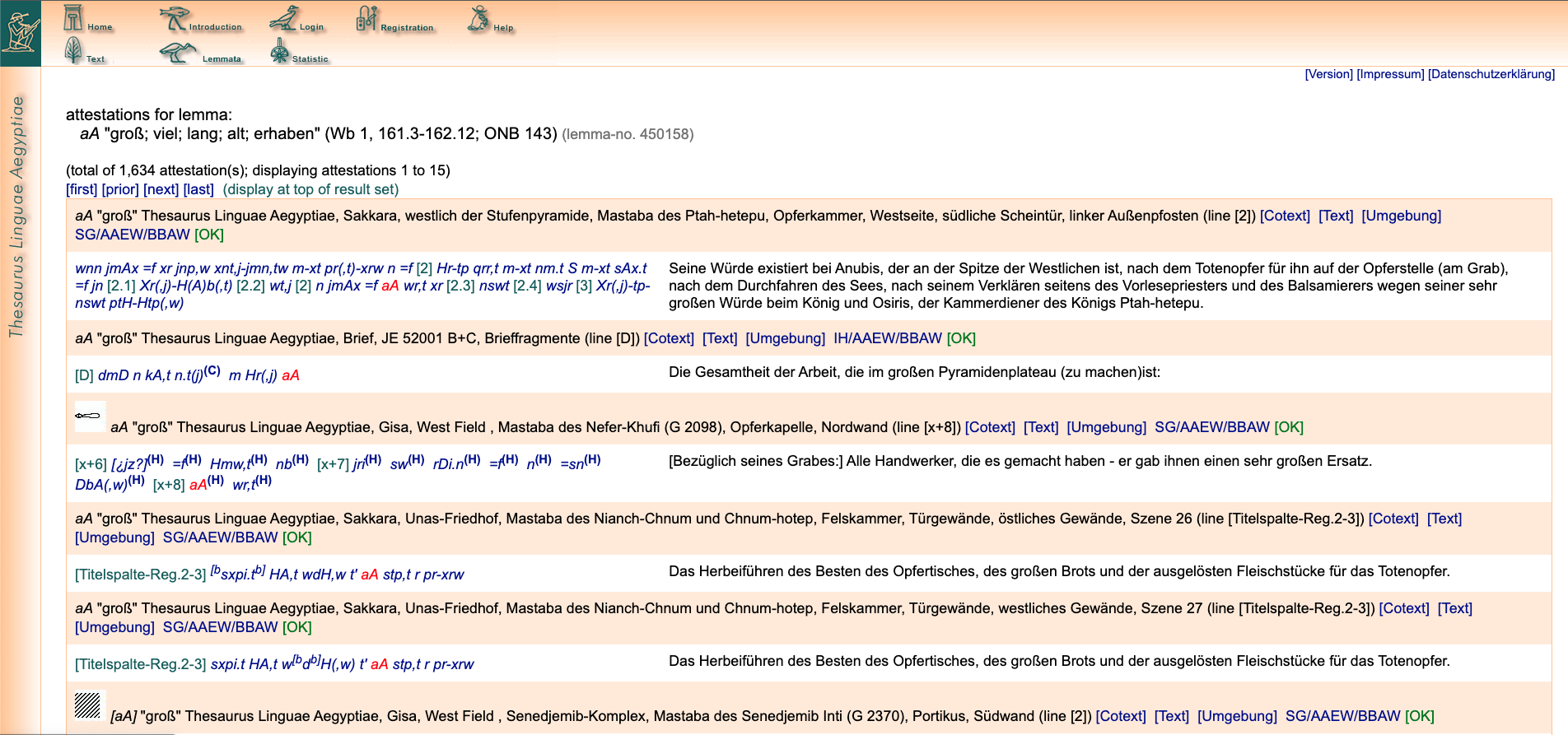
TLA の初版では、コーパスはすべてレンマ化され、語彙のページから、その語彙が出現する全てのテキストデータをコンコーダンスの形で見ることができた。古代エジプト文字(ヒエログリフ、ヒエラティック、デモティック)は同じ語彙に異綴が多い。しかしながら、旧版では、一部の文字しか表示されず、また、ラテン文字転写の ASCII 以外の文字は、全て ASCII で表示できるよう英数字の大文字で表示するなどの方策が採られた。そのため、特にこの表記に慣れていない者や、実際の古代エジプト文字の表記を見たいユーザには困難が伴った。しかし、今回、この v2.0でそれが刷新された。ヒエログリフで書かれたものはそのヒエログリフを、ヒエラティックが一次資料であるものはヒエラティックから変換されたヒエログリフを表示することが可能で、それらは、JSesh[5]というヒエログリフ文作成ソフトを用いて、画像で表示される。一方、ヒエログリフにも Unicode はある。現状では基礎的な文字しかなく、さらに、ヒエログリフを矩形のなかに詰めるように、文字を縦に並べたり、大きな文字の右肩に小さな文字を書いたりするスクエアライティングには完全には対応していない。一応、スクエアライティングができるように制御文字が Unicode に実装されたが[6]、フォントレベルでそれを行える技術は未公開である。そこで、TLA では、Marwan Kilani が開発した EgyptianHiero というフォント[7]を用いて、Unicode で語彙を書いている。このフォントは、リガチャ機能を使って基本的なスクエアライティングを表示可能にしたフォントで、Mark-Jan Nederhof の New Gardiner フォントをベースにしており、筆者も関わっていた SINUHE the Hierotyper プロジェクト[8]でも使用していた。TLA は、将来どの例文・コーパスデータも完全に Unicode 化することを目的に掲げている。そして、v2.0では、ラテン文字転写でエジプト学で用いられる特殊な記号も Unicode で表示できるようになった。これにより、ラテン文字転写と ASCII 文字との対応を覚えなくてもよくなり、初学者のユーザには利用が容易になったことであろう。
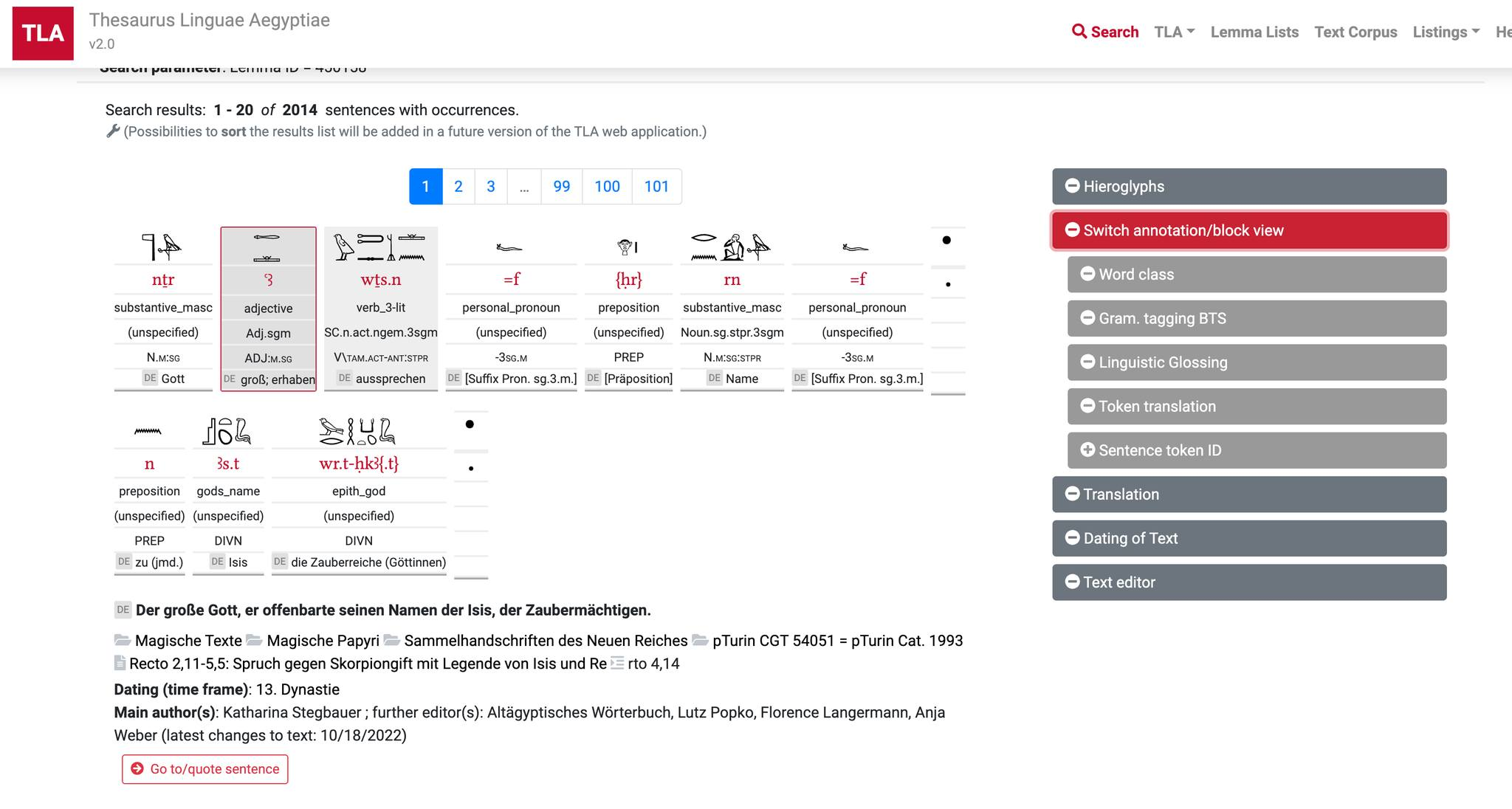
さらに初学者にとって役に立つ新機能として、インターリニアグロスをコーパスに表示させる機能がある。インターリニアグロスとは、言語学で広く使われる例文の表示方法で、その言語を知らない学者でも、その言語の例文とそれぞれの形態素の意味がわかるようにするためのものである。例文のそれぞれの単語の下にその意味と文法機能が書かれ、形態素で分けられる部分は、例文でもグロスでもハイフンで分けられている。例えば、「猫」を意味する英語 cat の複数形である cats は、cat-s と例文で書かれ、グロスでは「猫-PL」と書かれる。ここでは PL は plural(複数)の意味である。ここでは、英語の例文を、語彙の意味の部分は日本語で、文法的な部分は英語の略号で書いた。日本では、このように、和文論文の際は、語彙の意味を日本語で、文法機能を英語の略号で書くことが多い。ただ、英語のように広く知られた言語の場合、インターリニアグロスを振るのは、注意すべき解釈の時以外まれで、そして論文が英語で書いてあるときは、グロスも英語で書くのが通常である。そして、形態素や接語、重複など様々な文法現象に対応するため、特に言語類型論や記述言語学では、よく使われる Leipzig Glossing Rules (LGR)[9]というインターリニアグロスが標準である。TLA では、LGR に即したインターリニアグロスが使われているが、古代エジプト語特有の文法現象には、LGR にはない略号が用いられている。v2.0では、LGR タイプのグロスだけでなく、単語毎の訳を見ることができるが、その訳はドイツ語しか表示されないことが多く、英訳の実装は開発途中であることが見受けられる。
このようにまだ英語化は中途半端にしかできておらず、ドイツ語を解しないものにとっては、多少困難が伴う。しかしながら、TLA は、古代エジプト語の語彙の用例を学習・研究する上で大変強力な唯一無二のツールであり、今回の刷新で、インターリニアグロスとヒエログリフの表示が強化され、その地位は不動のものになったといえる。残る課題は、これまでに述べた英語化・Unicode 化などである。また、デモティックのコーパスでは、デモティックはヒエログリフとは一対一対応しないことが通常であるため、ラテン文字転写しか書かれていない。デモティックの Unicode 化も、ハイデルベルク大学を中心に議論されており、今後、代表形が選定され、デジタルで表示する術ができ、TLA に実装されることを期待している。実際に、ハイデルベルク大学の Demotic Paleographical Database Project (DPDP) プロジェクト[10]では、デモティックのフォントが開発され、その古書体学的データベースに基づき、標準化を行える状況が整いつつある。また、 TLA 旧版では、2つの単語までしかコロケーション検索ができず、KWIC 検索機能もシンプルなものであったが、v2.0では、時代・地域での条件別やより複雑な構文検索など、今後は様々な条件での検索ができることを期待している。
TLA v2.0の Introduction のページでは、「“legacy TLA”」と呼ばれている。“TLA — Introduction,” Thesaurus Linguae Aegyptiae v2.0, accessed November 18, 2022, https://thesaurus-linguae-aegyptiae.de/info/introduction.
- コメントを投稿するにはログインしてください