人文情報学月報第129号【中編】
ISSN 2189-1621 / 2011年08月27日創刊
目次
【前編】
- 《巻頭言》「古辞書はコーパスに馴染むか」
:京都府立大学文学部日本・中国文学科 - 《連載》「Digital Japanese Studies 寸見」第85回
「Creative Commons が政策文書「文化遺産のよりよい共有に向けて:著作権改革への論題」を公開」
:北海学園大学人文学部 - 《連載》「欧州・中東デジタル・ヒューマニティーズ動向」第46回
「危機言語の音声・テキストのデジタル・アーカイブ:Endangered Language Archive と Pangloss Collection」
:人間文化研究機構国立国語研究所研究系
【中編】
- 《連載》「デジタル・ヒストリーの小部屋」第4回
「詳細なレシピもいいが、肝心の料理の質を上げてくれ:議論主導型のデジタル・ヒストリーと探索的データ分析」
:千葉大学人文社会科学系教育研究機構 - 《特別寄稿》「YAIST:部品と画数で漢字を検索するための Unicode 入力支援ツールについて」
:岡山大学大学院社会文化科学研究科
【後編】
- 人文情報学イベント関連カレンダー
- イベントレポート「シンポジウム「第17回京都大学人文科学研究所 TOKYO 漢籍 SEMINAR『デジタル漢籍』」」
:東京大学大学院人文社会系研究科 - イベントレポート「日仏図書館情報学会主催「Gallica―その戦略のゆくえ」」
:お茶の水女子大学大学院 - 編集後記
《連載》「デジタル・ヒストリーの小部屋」第4回
「詳細なレシピもいいが、肝心の料理の質を上げてくれ:議論主導型のデジタル・ヒストリーと探索的データ分析」
はじめに
今回の連載では、2021年に Journal of Social History 誌に掲載されたデジタル・ヒストリー特集の序文にあたる論文「デジタル・ヒストリーと議論する:歴史的解釈のパターン[1]」(以下、同論文)を扱う。著者は、本連載第1回に登場した Stephen Robertson と、ジョージ・メイソン大学での彼の同僚である Lincoln Mullen である。彼らの所属するジョージ・メイソン大学に関しては、ロイ・ローゼンツヴァイク歴史とニューメディア研究センターを擁しており、本誌の読者の方々にも馴染み深いであろう Omeka や Zotero といったツールの開発でも知られているほか、この研究センターがアメリカにおけるパブリック・ヒストリーの史学史の中に位置づけられるべきこともおさえておきたい点である[2]。
同論文の目的を簡単に述べると、これまでデジタル・ヒストリー研究の大半が、手法的な新規性を論じるあまり、中身のある議論を充分に展開することができなかったことを指摘した上で、その問題を解決するために、従来の歴史家と議論するための型やパターンを提示することである。「デジタル・ヒストリーは議論がない」という問題自体は、すでにさまざまな場面で異口同音に指摘されてきたことであり[3]、未熟な筆者としても耳が痛い限りである。しかし、手法と解釈の記述の分量についての折り合いをどのように付けるか、という点は、デジタル・ヒストリーだけでなくデジタル・ヒューマニティーズ研究に関心を持つ本誌読者の方々にも参考になるだろうと思われる。以下、論文の構成に沿って内容を紹介していきたい。
なぜデジタル・ヒストリアンは議論をしてこなかったのか
同論文では、まず議論の前提として、デジタル・ヒストリアンがなぜ中身のある議論をしてこなかったのか、その原因をいくつか論じている。それら原因の要点のみ挙げていくと、(1)電子学術リソースの作成、すなわち情報基盤を蓄積していく仕事にかかる労力が大きいこと、(2)実験すること、データ分析の手法としての可能性を示すこと自体を目的としていたこと、(3)手法よりも解釈に重きが置かれる場合、それはデジタル・ヒストリーとしては見えてこず、従来の歴史研究の成果として、ある意味ではデジタル・ヒストリーと切り離されてしまうこと。つまり、デジタルに注目させて従来の歴史学と差別化を図ることによって自らを定義していることの逆説的な帰結でもある、ということである。(4)特定の歴史学分野の議論に資することを目的としたものは、デジタル・ヒストリーやデジタル・ヒューマニティーズに関心を寄せる他分野のオーディエンスの関心を引くものになりにくいこと、などが挙げられている。
しかしそれでも、近年いくつかの学術誌で、デジタル・ヒストリアンが好むような論文の特集が組まれるようになったという。American Historical Review 誌、Journal of American History 誌、Journal of Social History 誌、Law and History Review 誌といった例が挙げられている。なお、このような傾向は日本でも見られており、たとえば2020年から『西洋史学』誌のデジタル・ヒストリー特集コーナーとして常設されている Digital History Insights や、『歴史学研究』で時折特集が組まれたほか、日本西洋史学会をはじめとする学会の年次大会などでデジタル・ヒストリー関連のシンポジウムや企画セッションが組まれてきている。デジタル・ヒストリアンとして重要なのは、このような機を逃さず、手法の新規性を示すだけでなく特定の歴史分野にも貢献しうるような議論を提示できるようにすることである、と同論文では主張されており、筆者もこれに同意するところである。
議論主導型デジタル・ヒストリーのパターン
同論文では、前述のような議論の模範になる10本の論文の成果が具体的に示されていくことになる。注目すべきは、ロイ・ローゼンツヴァイク歴史とニューメディア研究センターのサーバー上に、Models of Argument-Driven Digital History というサイトが設置され[4]、そこでは10本の論文の内容をすべて閲覧できるようになっていると同時に、基礎データの作成経緯、データ分析の手法やデータ可視化の結果、地図やグラフの作成方法や限界、といった註釈情報が原文に付されていることである(図1参照)。
このようなデータ分析の註釈情報を歴史叙述と並置する試みは、前号の本連載で紹介した Journal of Digital History 誌の「デジタル解釈学」に基づく多層的論文出版プラットフォームと通ずる部分がある[6]。ただ、Models of Argument-Driven Digital History で企図されているのは、そこで註釈として示されている情報が、類似の種類の史資料や手法に基づいて異なる分野で議論を展開しようとするデジタル・ヒストリアンの参考として機能するようにということである。
さて、本稿では、これら10本の論文すべての内容と意義を詳細に論じることよりも、むしろ議論の展開として共通するような要素に注目したい。なぜなら、この要素は、デジタル・ヒストリーに限らず、デジタル・ヒューマニティーズの分野でもつとに議論されてきた点であり、本誌『人文情報学月報』の読者諸氏にも資するところがあるだろうと思われたからである。同論文では、従来の歴史研究と比べて大量のデータを用いて議論を進めるデジタル・ヒストリーのアプローチとして共通するものについて、次のように述べている。
ここで論じられているのは、一言でまとめるとするならば、探索的データ分析の考え方である。つまり、従来の研究で用いられてきた情報を内包する広範なデータセットを対象としたマクロな視点からの分析が、先行研究とは異なった箇所を注目に値するものとして浮かび上がらせ、その次のステップとして、その箇所をミクロに検討していくという手順を踏むことにつながっていくということである。以前、この探索的データ分析について筆者は口頭発表を行っており、そこでは1970年代の数量歴史学、現代のデータサイエンスやテキストマイニングの議論を参照して、次のように論じた[8]。
広義のデジタルアーカイブの普及に伴って、われわれが手にすることができる歴史データは飛躍的に増加している。そこで「なぜ特定の部分に注目したのか、その妥当性はあるのか」ということを説明するために、テキストマイニングや GIS 分析、あるいは統計分析を用いた定量化手法が、探索的データ分析として貢献しうる。つまり、従来の歴史研究が依拠してきたような先行研究との差異や自分自身の問題関心といった情報からいったん距離を置き、定量的な手法を探索的に用いることによって得られた何らかの尺度において注目に値する点を特定することが、選択の妥当性を第三者に示すことにつながるということである。ここで注意しておきたいのは、データ分析の結果を鵜呑みにせず、その分析過程で重要な情報が欠落していないか、といった点を確認できるようにしておくことである。予備段階としての探索的データ分析とその後の精読というステップを繰り返しながら考察を深めていくことが肝要である、といった論旨である。
同論文では、GIS 分析やネットワーク分析、3D モデリングやデータ・ビジュアライゼーション、そしてテキストマイニングの手法を用いた優れたデジタル・ヒストリーの研究成果を紹介している。どれもその根底には読者を全体像から個別事例へと誘う叙述戦略、言わば遠読から精読への流れを意識した論文の構造を有していると考えられる。とはいえ、このような研究を実践するのは易しいことではない。議論主導型のデジタル・ヒストリー研究とは、従来よりも広く、そして多くのデータを扱うためにデータ分析の下準備や前処理を行い、その上で探索的データ分析を実施し、そこからさらに従来の研究成果と同じかそれ以上の深みを持った議論を展開することを目指すものなのである。
おわりに
議論主導型のデジタル・ヒストリー研究の論文を紹介するつもりが、結局、手法的考察に収れんしてしまった。手法と解釈を両立させるのはかくも難しいと実感せざるを得ない。ともあれ、デジタル・ヒストリーの優れた研究を紹介する同論文、関心を持った個々の論文とあわせてぜひご覧いただきたい。
特別寄稿「YAIST:部品と画数で漢字を検索するための Unicode 入力支援ツールについて」
2022年2月19日に第128回人文科学とコンピュータ研究会発表会(http://www.jinmoncom.jp/index.php?CH128)が開催された。報告者は秦漢時代の出土文字資料について研究しており、難しい漢字の検索方法及び入力方法を学ぶために参加した。報告者にとってもっとも参考となった劉冠偉・中村覚・山田太造「部品と画数で漢字を検索するための Unicode 入力支援ツール」について報告したい。
研究の背景として、符号化文字集合 Unicode の更新に伴い、中国語・日本語で書かれた史料のテキストデータベースに利用できる漢字符号が大幅に増加しているという現状が指摘された。史料の内容を最大限に再現するためには、できる限り多くの異体字、人名、地名などを原本の字形に近い漢字符号で利用できるようになることが望ましいが、以下の2つの問題点があるという。
そこで、Unicode の漢字符号を構成する部品と画数で検索し、TEI を含めて検索結果を任意のフォーマットで出力することが可能なツールの開発が目的とされた。検索する漢字の難字・異体字の取得を支援するため、関連漢字を自動的に推薦するシステムについても検討された。
Unicode を用いた史料データベースの作成が一般的であることから、第一に文献の翻字に特化した Unicode 入力支援ツールが求められる。今回作成されたツールは、①「idsfind」と②「YAIST」(Yet Another IDS Search Tool)であった。①の idsfind は、CHISE(Character Information Service Environment)プロジェクトの漢字構造情報データベース(https://www.chise.org/ids/index.ja.html)を利用し、目的の漢字を構成する部品から検索する。この idsfind を組み込んだウェブアプリが YAIST になる。YAIST は左の検索パネルに漢字の部品と残りの画数を入力すると、右の表示パネルに漢字の候補の一覧が出現する。一方、②の YAIST の特徴は、Unicode と IVS の対応、GlyphWiki との連携、TEI への対応、関連漢字の提示である。
今後の課題として、アプリケーションの利便性の向上が挙げられた。現状では初回のアクセスの際に、約11MB のデータをダウンロードする必要がある。漢字構成データの格納方式の再検討することで通信時間の短縮などを実現するとのことである。
以上、本発表の研究報告書(http://id.nii.ac.jp/1001/00216218/)も参考にしながら、発表の概要をまとめた。続いて、本発表で紹介された YAIST を報告者の研究に利用してみた結果についても述べたい。報告者の専門は中国古代史である。具体的には、簡牘(紙が普及する前に使われた竹の札や木の札)に記録された官吏の犯罪行為及び処罰に着目し、秦漢時代の「吏治」(官吏の治政方法)を分析している。簡牘の整理、分析を通じて研究していく必要がある。
秦漢史研究には、大量の伝世文献と出土文字資料が必要である。歴史研究をする時には、史料の原文を読むことは不可欠であるが、史料の位置をより早く探すことが可能になるデータベースの存在は有益である。現在、報告者は伝世文献の検索には基本的に漢籍電子文献資料庫(http://hanchi.ihp.sinica.edu.tw/ihp/hanji.htm)というデータベースを利用している。正史の範囲では、正確性が高くて非常に便利である。その一方、出土文字資料の検索には完璧なデータベースはなく、簡牘の検索は不便である。
そこで報告者は、張家山漢簡『二年律令』と、岳麓書院蔵秦簡の秦律と秦令の部分のデータベースを作った。簡牘のデータベースを作成には、識別と入力の2点に問題がある。以下にそれぞれについて、簡文と共に説明する。簡文の日本語訳は「嶽麓書院所藏簡《秦律令(壹)》譯注稿 その(一)」[1]、「嶽麓書院所藏簡《秦律令(壹)》譯注稿 その(二)」[2]、『江陵張家山二四七號墓出土漢律令の研究 譯注篇』[3]を参考にした。
1. 識別の問題
1983年に出土した張家山漢簡『二年律令』に記載される漢律の律名は28種である。その中の「傳食律」を例として挙げる。『二年律令』傳食律228簡には、
(およそ乘傳が、長安を出発して□陵、□陽、□□に行くときは、□〼。)
とある。この原文を OCR[5]で読み取ると、「乘傳」は「乘傅」になった。これは相似した字形による混乱である。秦漢時代には「傅律」という律名があり、傅籍(秦漢時代の徭役制度、名籍ともいう)に関しての規定も多くある。このため、出土文字資料においても「傅」の字は多く見られ、条文の中に「傅」を見ても違和感がない。簡牘の原文を確認しなければ、条文内容に誤解を招きやすい。
その一方、一部の漢字は単純に読み取ることができなかった。『岳麓秦簡』徭律157簡の条文を例として挙げる。『岳麓秦簡』には、
(徒の人数、勝手に動員してはならず、また勝手に敖童・私屬・奴や徴用に該当しない車牛を使役してはならない。およそ免老および敖童のまだ傅籍されていない者は、県が使役してはならない。)
とある。この原文を OCR で読み取ると、
になった。「倳」という文字が「傳」に間違えられた。「倳」という文字は、現代の中国と日本では基本的に使われていないため、全く読み取ることができない。岳麓秦簡の整理小組は「倳」を「使」に変換して翻刻しているが、それ以外に注釈はなく、簡牘原文の文字の識別は非常に難しい。このため、OCR に頼らず、簡牘の原文を確認しながら一つずつ入力しなければならない。
2. 入力の問題
コンピュータで簡牘の条文の漢字を入力する際に最も用いられる方法は、「読み方」で入力することである。しかし、出土文字資料には、現在の日本、さらには中国でも使われていない中国の古文字も多くある。出土文字資料の整理小組の注釈は、これらの古文字を現在使用されている漢字に置き換えているが、元々の文字の「読み方」については注釈していない。
先述の『岳麓秦簡』157簡を例にすれば、整理小組は「倳」に「使」という注釈を加えている。中国史を研究している人には、この律文の意味は明らかであるが、「倳」[zì]と「使」[shǐ]の発音は全く異なる。「倳」をコンピュータで入力する際に、[shǐ]という発音で入力すれば、検索の結果は疑いなく間違える。読み方が確定できず、OCR で読み取る時も別の文字(例えば「傳」)に変わってしまう。また、たとえ辞書でこのような難しい文字の発音を見つけても、その文字がインプットメソッドに収録されていない可能性もあり、コンピュータで入力することは依然としてできない。
このような漢字に対する報告者のこれまでの入力方法は、漢字の部品情報を利用して検索を行うというものだった。すなわち、「倳」を「亻(人部)+事」に分けて表現し、検索していた。しかし、このような検索方法の問題は、漢字の部首が複雑である場合に明らかになる。「倳」[zì]という文字を「亻+事」に分ける場合では、「亻」であれ「事」であれ、単独で入力することができるため、検索することができる。その一方、一部の漢字の構成は極めて複雑であり、元々の漢字を部首によって分けることはできない。例えば、『岳麓秦簡』に、
……日六錢計之,皆與盗同灋。[7]
(……一日あたり六銭として計算し、いずれも盗罪と同じ法律を適用する。)
奴婢繫城旦舂而去亡者,繫六歲者,黥其顔頯……[8]
(奴婢が繫城旦舂に処されていながら逃亡すれば、繫六年の者はその顔を黥に処し……)
奴婢亡而得、黥顔頯、畀其主。……[9]
(奴婢が逃亡して捕らえられたならば、黥とする、その主人に引き渡す。……)
とある。「灋」の字は「氵」部(水部)、「頯」の字は「頁」部、であるが、「灋」の字の右半分と、「頯」の字の左半分は入力できない。「灋」と「頯」の検索には時間がかかる。「畀」の筆画は少ないが、現代の中国では基本的に使われていないため、検索にも時間がかかる。「倳」の亻(人部)以外の部分は「事」であるため、入力することは簡単である。しかし、「畀」は「田+丌」という上下の部分形から構成され、上半分の田部は明確であるが、残りの「丌」の読み方は確認できず、簡単に検索することはできない。
また、『二年律令』賊律には、
(喧嘩で人に傷害をあたえ、傷がもとで二十日以内に死亡に至ったならば、殺人と見なす。)
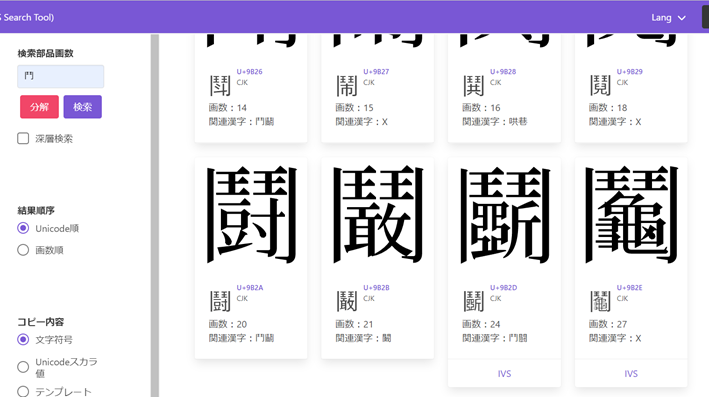
とある。「鬭」は内外の部分形から構成される漢字であり、前述の漢字と同じ、鬥部以内の部分は複雑であり検索することは難しい。さらに、「鬭」を入力するもう一つの難点は「鬭」の異体字がいくつかあり、区別する工夫が必要であることである。
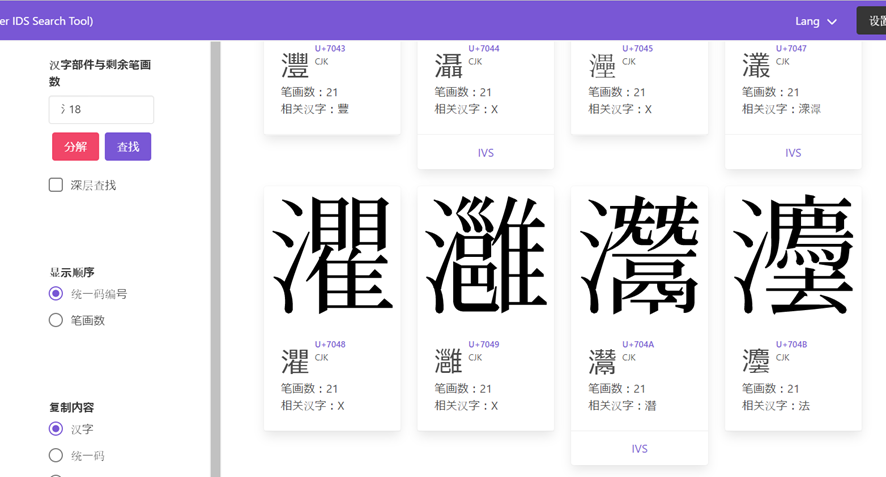
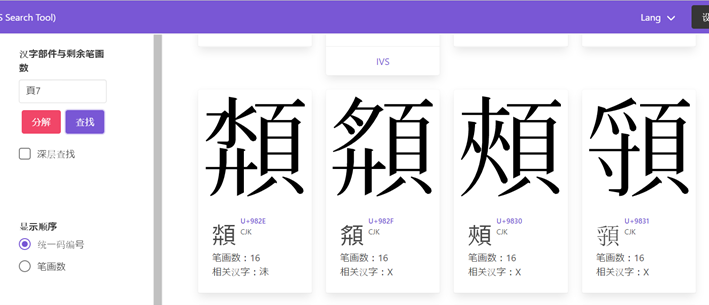
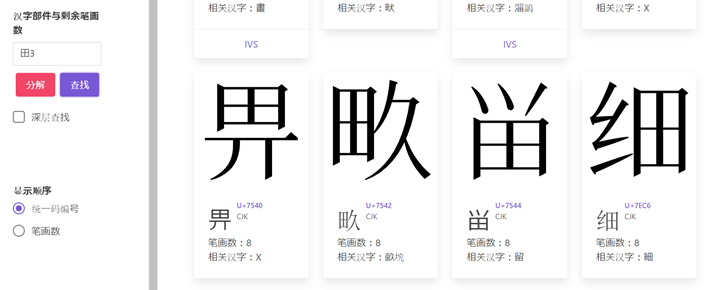
今回の発表会で、漢字の部品と残り画数で Unicode 漢字符号を検索する YAIST の利用方法を学んだ報告者は、さっそく『岳麓秦簡』の条文で試してみた。このツールは、漢字を「部首+残り画数」に分けて検索し、入力できない部分を画数で入力することで、検索時間を短縮することができる。例えば、前述の「灋」については、入力できない右半分を「18」に替え、「氵18」で入力すれば、「灋」を検索することができた。検索結果の画面を以下の図1に示す。「頯」については、左半分を「7」に替え、「頁7」で入力すれば、「頯」を検索することができた。検索結果の画面を以下の図2に示す。「畀」については、下半分を「3」に替え、「田3」で入力すれば、「畀」を検索することができた。検索結果の画面を以下の図3に示す。「鬭」については、「鬥」で入力すれば、結果数は34であり、「鬭」を検索することができた。「鬭」の異体字その一覧も確認できた。検索結果の画面や異体字の画面を以下の図4と図5に示す。
これで、簡牘に現れる難しい漢字に対して、左右の部分形から構成される漢字であれ、上下の部分形から構成される漢字であれ、内外の部分形から構成される漢字であれ、YAIST を利用していずれも「部首+残り画数」に分けて検索でき、さらに目的の漢字の異体字にも確認でき、簡牘研究者にとっては極めて便利である。

報告者がこれまでに整理した簡牘に現れた難しい古文字を検索してみたところ、大部分の漢字は検索でき、入力もできた。しかし、まだこのツールでも検索できない漢字もある。『岳麓書院藏秦簡(肆)』37簡に「![]() 」という字が見える。整理小組は、この文字を「顔」の異体字とみなしている[11]。報告者は修士論文でこの簡文を引用したが、入力できなかったため、注を加えて「顔」の字で代用した。YAIST で「頁11」を検索したところ結果数は39であったが、目的の漢字は出てこなかった。
」という字が見える。整理小組は、この文字を「顔」の異体字とみなしている[11]。報告者は修士論文でこの簡文を引用したが、入力できなかったため、注を加えて「顔」の字で代用した。YAIST で「頁11」を検索したところ結果数は39であったが、目的の漢字は出てこなかった。
また、検索結果が出てこないこと以外にも、報告者が YAIST を試用した際に、目的の漢字の異体字は確認できるが、異体字のコピー・ペーストはできないことは多少不便と感じた。例えば、前述の「鬭」を例として、IVS が存在する漢字はその一覧を確認できるが(図5)、コピー・ペーストはできない。『江陵張家山二四七號墓出土漢律令の研究 譯注篇』において、この簡文は当に図5の IVS: E0102の異体字が使われている[12]。このため、YAIST に検索できる漢字の異体字もコピー・ペーストできればより便利と考える。
報告者のこれまでの研究方法は、伝世文献と出土文字資料そのものを利用するというものであった。最も重要なことは、様々な史料の内容を整理、比較、分析することである。デジタル技術を利用して研究する機会は少なく、デジタルヒューマニティーズに関しての専門的な知識も不足している。データベースの作成は、あくまで史料の検索性を向上させるためであり、「顔」の異体字のような漢字が入力できるかどうかは、史料の内容に対する理解に影響を与えない。しかし、漢字検索ツールの発展は、中国古代史を専門とする研究者により良い研究環境を提供する。デジタルと人文学の組み合わせも、秦漢史研究に新しい視点を提供できるかもしれない。そのため、報告者はこれからもデジタルと歴史学の結合に注目し、デジタル技術を適切に自分の研究に活用していきたい。
以上、第128回人文科学とコンピュータ研究会発表会に参加し、劉冠偉先生らの発表内容の概要と、報告者が漢字検索ツール YAIST を使ってみた実例について報告した。発表会で発表者や他の参加者の方々からいただいた知見を参考に、出土文字資料に現れる漢字の検索能力を高めながら、秦漢史研究に取り組んでいきたいと考える。
- コメントを投稿するにはログインしてください