人文情報学月報第116号
ISSN 2189-1621 / 2011年8月27日創刊
目次
- 《巻頭言》「人文学と研究データ:デジタル時代の人文学のために」
:一般財団法人人文情報学研究所 - 《連載》「Digital Japanese Studies 寸見」第72回
「言語情報学のひとつのありかた」
:北海学園大学人文学部 - 《連載》「欧州・中東デジタル・ヒューマニティーズ動向」第33回
「深層学習を用いた kraken による OCR と、kraken を用いた HTR を通してデジタル学術編集版作成を目指す eScripta」
:関西大学アジア・オープン・リサーチセンター「KU-ORCAS」 - 特別寄稿「論文紹介:A. Fickers & T. van der Heijden「交易空間の中で:デジタル・ヒストリー実験室でのティンカリング」(後編)」
:東京大学大学院人文社会系研究科 - 人文情報学イベント関連カレンダー
- 編集後記
《巻頭言》「人文学と研究データ:デジタル時代の人文学のために」
3月23日の夜、オンラインで開催されていたアジア研究学会(AAS)2021年大会の「手法としての視覚化:アジアの(デジタル)ヒューマニティーズの文脈でのデータ視覚化を位置づける」[1]というパネルディスカッションをのぞいていたところ、「データの視覚化とは、視覚的に見せる部分だけではなくて、データセットから視覚化されたものに至る色々な手続きの一連の流れのことである」(意訳)[2]というようなコメントを聞いて、まったくおっしゃるとおり、と思った。ちょうどこれに関わる課題に取り組んでいたところでもあり、やはり今回はこれをテーマにすることにした。
筆者が取り組んでいる課題というのは、現在の学術界が全体として向かおうとしているオープンサイエンスに関わるものである。日本学術会議の提言[3]を見ていると、その流れが大きくなってきていることはなんとなく想像できる。多額の公的資金を投入して得られた研究成果(電子学術雑誌に掲載された論文)を閲覧するために多額の費用を電子ジャーナル会社に支払わなければならない、という状況を抜本的に変革してしまうというのが一つ、成果のみならずその根拠となった研究データまでもオープンにすることでサイエンスへの参加障壁を下げようというのが一つ、これに加えて、各研究分野の壁を越えてデータを自由に共有できるようにすることで横断的・包括的な新たな視点を獲得できるようにする、といったことが狙いになっているようである。
目標だけを聞いているとどれも机上の空論なのではないか…と思えてしまうが、実のところ、欧州では各国の研究助成機関が連携して本格的に乗り出したことによって半ば実現しつつある。そもそも研究助成機関が配分した費用で研究をして成果を公表し、その際に論文掲載料(日本の多くの人文系論文誌と異なり、理工系はほぼ有料)が出ることになるのであり、要求する成果の条件として無料で閲覧できる電子ジャーナル、つまりオープンアクセスジャーナルでなければ成果として認めない、という条件を出して研究助成金を配分すれば、研究者はそれに従わざるを得ない。もちろん、事態はもっと複雑であり、結果として、「オープンアクセスにするための論文掲載料」として、有料閲覧の場合よりも高額な掲載料(APC)を支払うことになっている。すでに多くの電子ジャーナルが対応しているが、論文1本あたり10万円~40万円くらいが相場とされている。とはいえ、その費用自体も研究助成金から支払われることになるため、研究助成機関の意向がこの方向で続けばやがてオープンアクセスは一層広まっていくことだろう。
さて、日本で人文学に専心していると、そういった動向からはかなり縁遠い。そもそも日本の人文系学術雑誌は、有料電子ジャーナルになっていることが非常に稀であり、多額の費用が電子ジャーナル会社に流れる、といった問題に触れるのは、学術情報流通そのものに関心を持っているのでなければ、大学図書館の財務等に何らかの形で関わることになった場合くらいなのではないだろうか。そうすると、付随してくるところの研究データに関する議論にも触れることはあまりなさそうにも思われる。
しかし一方で、たとえば科学研究費の研究助成金を申請する際に「成果をデータベースとして構築する」「Web に公開する」といったことを盛り込むことは人文系でも以前から広くみられることである。実際に様々なデータベースが公開され、未だに残っていたりいつのまにか消えていたり、中には研究助成金が切れた後は有料データベースになってしまうものもみられる。
このような流れはつい最近始まったようなものではなく、たどっていくと1980年代にはすでに盛んになっていたようである。たとえば、1985年9月3日には「哲学者のためのテキスト・データベース研究会」の第一回が東京大学大型計算機センター集会室において開催され、第三回目からは「哲学者のための」という名称が外れて、広く人文・社会科学研究者のための「テキスト・データベース研究会」となり、英語名は「JACH」(Japanese Association for Computer and Humanities)[4]となる。この段階では、コンテンツとしては、デカルトの『省察』、ギリシャ語原典、トーマス・マン、東洋学が挙げられており、技術面では、テキスト・データベースの各種機能や OCR、人工知能が挙げられていた。
一方、1987年頃より日本文学テキストのデータ共有を目指した情報処理語学文学研究会、英語名を JALLC(Japanese Association for Literary and Linguistic Computing)[5]とするコミュニティも運営されていた。JALLC では、テキストデータを共有するということに関しては深い検討が行われ、1989年に始まる GNU GPL によるコピーレフト運動の影響も強く受けたようであり、現在のオープンデータ推進の先駆的な活動であったと言ってもいいようなものであった。ただ、その検討の結果として、JALLC の主な活動は、研究者同士でのテキストデータの共有を目指す互助的なものとなっていったようである。
こうした活動の一端は、現在も活動を続ける「東洋学へのコンピュータ利用」研究セミナー[6]や情報処理学会人文科学とコンピュータ研究会[7]、情報知識学会[8]等での当時の発表にも見受けられる。人文学の研究データと言えば、まずはテキストデータということになるが、それ自体は日本でも新しい話ではなく、むしろ1980年代にはすでにコミュニティレベルでの取組みが行われていたのである。
なお、JALLC でも JACH でも、名称が示すように海外志向があり、1990年代初頭には Text Encoding Initiative の導入に関する議論も散見されるものの、こういった流れは現在まで明示的に続くことはなく、いったん途切れたように思われる[9]。
さて、現在に目を移してみると、人文学におけるデータとしては、国文学研究資料館が「日本語の歴史的典籍の国際共同研究ネットワーク構築計画」[10]として構築を目指す30万点のデジタル画像が目を引く。これはもちろん研究に使えるデータなのだが、これを研究に使うというのは、多くの場合、人が画像を見て内容を判断するということになるのであり、コンピュータで処理することで何らかの意味がある情報を取り出せる素材としてのデータとは少し様相が異なる。もちろん、くずし字 OCR[11]のような手段でテキストデータを取り出せるようになれば、状況はかなり変わってくるのであり、それほど遠くない将来にそのようになっていることを期待したい。
一方で、そのようにして機械で取り出したデータだけでなく、研究者が少し手をかけて作成した研究データというのもあり得る。たとえば、くずし字 OCR と同じ人文学オープンデータ共同利用センター(CODH)で作成している顔貌コレクション[12]などは、そもそも画像から人の顔を切り出して顔という意味を持つデータを抽出するだけでなく、それがどういう属性を持つ顔であるかということまで研究者の判断に基づいて作成した、人手による研究データなのである。このデータは、研究データとして他の研究者が活用するに際しても、コンピュータで処理することで何らかの意味を見出すことがかなり容易であり、また、何らかの観点から類似するデータが入手できればそれと比較して様々な知見を見出すことも期待できるだろう。もちろん、テキストデータも同様に考えることができ、TEI ガイドライン[13]に準拠したタグ付きテキストデータであれば、さらに有用性は高まることになる。
ここでは文献資料しか見ていないが、人文学において研究データと言った場合、(1)デジタル画像のように(これは動画や音声データにおいてもある程度みられることだが)、基本的に機械のセンサーを用いて作成し、データ量が比較的大きく、しかしそこから直接何かの情報を機械的に得ることはやや難しいデータと、(2)タグ付きテキストデータや顔貌コレクションのように研究者がある程度人手をかけて整備し、データ量は比較的小さく、しかしそこから直接機械的に有用な情報を得やすいデータ[14]、という2種類のデータに大別することができる。また、客観性が比較的強いか、主観性が強いか、といったことも両者の差異として見出すことはできるだろう。いずれも研究には有用なものだが、同じように研究データと言っても作成するためのノウハウも評価のされ方も作成後の扱いについてもかなり異なるものになる。人文学に限らず他の分野においても同様の状況は生じていると想像されるが、人文学でもこの点は踏まえておきたい。
このような研究データを、オープンなものとして利用可能にするのがオープンサイエンスの流れであり、人文学においてもそれが求められるようになってきている。欧州では EU の主導により欧州研究基盤コンソーシアム(European Research Infrastructure Consortium (ERIC))[15]が形成され、そのもとで CLARIN ERIC[16]と DARIAH ERIC[17]が人文学の研究データとその活用のための活動を担っている。すでに相当数の研究データやツール、そしてデータを作成・活用するための、いわゆる デジタル人文学教育用コンテンツが蓄積されており、特に上記の(2)の意味でのデータがすでに多く蓄積されていることが目を引く。
日本でも、研究データの蓄積公開に機関として取り組んでいるところとしては、人間文化研究機構の統合検索システム nihuINT[18]をはじめとして以前から様々な機関がある。一方で、ERIC のような広く研究データを預かるような取組みとしては、最近、日本学術振興会による「人文学・社会科学データインフラストラクチャー構築推進事業」[19]が開始され、こういったデータの蓄積に向けた動きが始まったところである。また、オープンアクセスリポジトリ推進協会(JPCOAR)では、研究データを各大学等の機関リポジトリに登載することを推奨するための支援策を提供しつつある。研究データの登載に対応している機関リポジトリはまだそれほど多くないようだが、いずれは広がっていくことを期待したい。
このようにして蓄積されたデータは、すでに一人の研究者がすべて目を通して理解することは不可能な分量であり、今後さらに増加していくことになる。その有力な用途の一つとして、冒頭に触れた「視覚化」が出てくる。蓄積された多様なデータセットに、コンピュータを用いた様々な処理によって様々な方向から横串を刺し、文化社会の様々な現象に対する横断的・包括的な把握を実現しようというのである。視覚化は、単に何らかのソフトウェアを適用してグラフや表、あるいは地図や年表上にプロットして視覚的に理解しやすいようにすれば完了というわけではない。研究データのまとまりとしての個々のデータセットを分析しやすい形に変換し、統計処理等の分析を行い、その上で見やすい形で表示することになる。このプロセスにおいては、もしそれぞれのデータセットが独自の形式で作成されていたなら、データセットが増えれば増えるほどそれぞれに対応した処理を行わねばならないために作業量も増えてしまい、横断的な分析が困難なものとなってしまう。そのような状況を改善するにあたっては、たとえば TEI ガイドラインのような共通フォーマットをデータ公開時に採用することが有用である。さらに言えば、諸外国で用いられているフォーマットと共通化されていれば、日本のデータセットだけでなく各国のデータセットをも含めて統合的に分析し視覚化することや、諸外国の研究者が日本のデータセットを研究対象に含めることも現実的なものとなるだろう。より身近な例としては、Unicodeが普及したことにより言語毎のソフトウェアやデータの互換性を考慮しなくてよくなったことも挙げられる。対応が難しいフォーマットに無理してあわせる必要はないが、相互運用しやすいフォーマットにあわせた公開用データの作成ということは視野に入れていく必要があるだろう。そして、それを可能とするためには、共通フォーマットをより使いやすいものとする工夫も必要である[20]。データセットがそのようにして適切に蓄積されていったなら、「視覚化」はより広汎な形で実現可能となる。もちろん、これだけで人間の文化社会のすべてを理解することは不可能だが、データを根拠とした検証可能な解釈の導出にはつながる可能性が高く、それが、より包括的な人間文化の理解の一助になることは期待してもいいのではないだろうか。
このような研究の方向性は、先頃改正され人文科学も対象に含まれることになった科学技術・イノベーション基本法に基づく「第六期科学技術・イノベーション基本計画」においては「データ駆動型研究」として課題の一つとなる見通しであり、人文学の新たな方向性の一つとしてもデータ駆動型人文学[21] が挙げられるようになってきている。それを適切に実現しデジタル時代における人文学の存在意義を示していく上でも、データのフォーマットの共通化に向けた取組みは、地味ではあるが大きな鍵となるだろう。
https://digitalnagasaki.hatenablog.com/entry/2020/10/28/042209
《連載》「Digital Japanese Studies 寸見」第72回
「言語情報学のひとつのありかた」
2021年3月4日、北海道大学大学院文学研究院言語科学講座教授の池田証壽氏が最終講義を行った[1]。池田氏は、稿者の大学院における指導者であるので、以下では―つとめて読者に対して公平を保つよう努めるが―先生とお呼びすることをまずお許し願いたい(敬語はなるべく控える)。
池田先生は、北大文学部の国語学研究室の出身で、石塚晴通氏の指導のもとに学び、1997年に、同学部の言語情報学講座に教員として着任している。それ以来、23年にわたって後進の指導にあたったわけである。言語情報学講座は、2019年に(大学院重点化を経て成った)文学研究科が文学院・文学研究院に改組される際、西洋言語学講座と併合して言語科学講座となった[2]。
北大における言語情報学講座は、1995年の学部改組にともない、池田先生が学んだ国語学講座と、言語学講座の一部から構成された講座であった[3]。言語学系の教員はここでは措き、北大における「言語情報学」の系譜をすこしひもときつつ、池田先生の最終講義の位置づけを考えたい。
網羅する必要もないと思うが、言語情報学は、べつに北海道大学文学部の専有物ではなく、東北大学には情報科学研究科に言語情報学講座があり、東京大学では総合文化研究科に言語情報科学専攻がある。人文情報学と言語情報学とは、人文学と言語学の関係のあいまいさ―以前、言語学が人文学にふくまれるかはっきりしない見方について触れたことがある[4]―とに似た関係があり、それぞれの講座で情報学と言語学とにどのように力点を置くかはとうぜんに異なってくる。
北大のそれでは、国語学講座が組織上プレゼンスを持っていたことが特徴で、石塚氏・豊島正之氏の文献(言語)学のたちばから言語情報学が模索されたことにユニークさがあるのではなかろうか。両氏にくわえて、言語情報学としての内実を充実させるべく、EUC-JP の開発などにもたずさわった[5]小野芳彦氏が招かれている[6]。石塚氏は漢字研究についても著名な業績があり[7]、豊島氏も JIS 漢字について積極的な発言を行ったのみならず、いわゆる97JIS(JIS X 0208:1997)から2000JIS(JIS X 0213:2000)にかけての JIS 漢字制定の中心を担ってもいる。このように、文献を着実に情報として扱う基礎研究がなされたことは、北大言語情報学の特徴と言ってよい[8]。
池田先生のもともとの専門は平安期古辞書、とくに原撰本『類聚名義抄』を中心にした研究である。最終講義でも、これを中心に先生の研究の発展が紹介されていた。具体的には、1990年前後からの古辞書研究への情報処理技術(具体的にはデータベース化・テキスト化による機械検索対応)の導入による研究の発展と、それにあたっての問題点の解消、すなわち文字コードに欠ける文字への対応である。それは、文字がたんに不足していると叫ぶのではなく、JIS 漢字制定の一翼を担うことによって成し遂げられた。豊島氏と同じく、97JIS と2000JIS にかけての JIS 漢字原案制定に調査委員として、現代日本語を扱ううえで不足しているものを用例に基づいて拡張する作業に従事したのである。その後は、ふたたび古辞書の研究に戻るが、平安期古辞書を中心とする一大データベース群 HDIC の作成に従事している[9]。
最終講義では、学問の継承ということがテーマのひとつとして挙げられ、先生も参画し長年継続されている高山寺調査と、そこでの発見について最後に述べられた。その詳細について触れることは、本連載の範疇を超えるが、HDIC も継承を意識して、GitHub 上でデータを提供しているという発言があった。ここに北大言語情報学の伝統と先生の創意とが生きていることは疑いようもない。たとえば、李媛氏などとともに研究を深めているところの、深入りしすぎない漢字の処理が北大言語情報学の伝統を受け継いだものだとすれば[10]、リレーショナルデータベースによって辞書データベースを構築することによって校訂の質を高めることは、先生ならではのものであろう[11]。ご退休ののちも、HDIC の整備に引き続き当たってゆかれるとのことであった。
また、学問の継承ということで、ついでのことになってしまうが、東北大学文学部の言語学研究室でながらく教鞭を執っておられた後藤斉氏も今春ご退休とのことである[12]。後藤氏が言語情報学という意識を持っておいでであったかは知るところにないが、ウェブの活用やコーパスへの取組みなど、池田先生ともご縁はあったものと思う。このほかにも、人文情報学を大学や研究所などに根付かせた研究者たちが職から退きつつあるいま(東京外国語大学アジア・アフリカ言語文化研究所の小田淳一氏など)、なにを継承できているのかと自問するところである。
《連載》「欧州・中東デジタル・ヒューマニティーズ動向」第33回
「深層学習を用いた kraken による OCR と、kraken を用いた HTR を通してデジタル学術編集版作成を目指す eScripta」
前回は Anaconda[1]を用いて kraken[2]を MacBook Pro 16 inch Late 2019上で動かし、行認識及び分割をした後 ground truth 入力用の HTML ファイルを生成してどれくらい行認識の精度が良いか試した。書く方向が右から左で行は上から下に流れる横書きのアラビア文字で書かれたアラビア語の『千夜一夜物語』の印刷物[3]では、行認識が完璧にできた一方、書く方向が上から下で行は左から右に流れる縦書きのモンゴル文字で書かれたモンゴル語の印刷物は、縦書き用のコマンドを用いたにも関わらず全く正確に行認識ができなかった。
今回、あるプロジェクトからいくつかのコプト語文献の OCR を頼まれたので、その文献で kraken を用いて文字認識させてみた。文献は活版印刷で印刷された20世紀前半のものであり、行間隔は十分であった。ただ元の画像がグレースケールで解像度の粗いものしかないとのことだったので、そのあまり OCR に向かない画像を用いた。1ページ分の文字量が少なかったので、30ページ分を切り出して、kraken 内蔵のプログラムを用いて、白黒化及び行認識及び ground truth 入力ファイルの生成を行った。一部だけ2行あるところが、1行として認識されたこと以外は、問題はなかった。ちなみにコプト文字は左から右に書かれ、行は上から下に流れるため、デフォルトのコマンドで処理できる。その後、ブラウザで ground truth 入力用の HTML ファイルを開いて、ground truth を入力、つまり、写真のテクストの翻刻を行った。kraken では、1行ごとに入力ボックスに入力するのだが、対応する行が、左に並べられた文献の画像上に赤枠で示される。ただし、トレーニングの段階で問題が生じた。Anaconda を用いたものでは、ガイドラインに沿ってトレーニングのコマンドを入力しても、常にエラーが生じ、トレーニングが完了できなかった。そこで、筆者がドイツ留学中に kraken を用いるのに成功した、ゲッティンゲン大学のコンピュータ科学研究所が所有する ROEDEL というハイパフォーマンスコンピュータ[4]上で全く同じコマンドを入力したところ、全く問題なくトレーニングできた。このコンピュータのオペレーティング・システムは Linux のディストロ(配布・導入パッケージ)の一つである Debian[5]である。
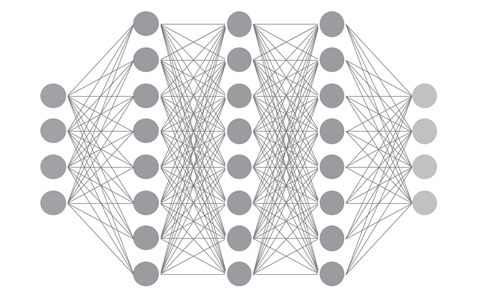
kraken は多層人工ニューラルネットワーク[6]を用いている。より正確に言えば、その中でも CLSTM neural network library を用いているのだが、ここではその詳しい説明は割愛する[7]。多層人工ニューラルネットワークとは、非常に大雑把に言えば、人間の脳内のニューロン(脳神経細胞)の結びつきを模したものである(図1)。入力と出力の間に複数のニューロンの層が多数積み重なっており、入力に入った信号がさまざまなニューロンを経由してある出力に辿り着く。どのニューロンからどのニューロンに行くかは、最初はランダムである。そこで、入力に対する正しい出力(訓練データ)を人間が用意して、その入力に対して正しい出力が出る割合が最も高くなるまで学習させることで(重みづけ)、精度が高いモデルを作ることができる。OCR の場合は、入力は文字の画像、出力はその文字に対応したデジタルに符号化された文字(現在では Unicode)である。そして、学習に使われる人間が用意する訓練データは ground truth と呼ばれ、kraken は、この ground truth の画像を入力に入れて、それが ground truth の正しい Unicode を出す割合が最も高くなるまで調整がなされ続ける。別の多層の人工ニューラルネットワークモデルを用いている OCRopus[8]は、デフォルトではトレーニング回数が1000回になるたびにモデルファイルが保存され、どのモデルファイルが最も精度が高いかは、別のコマンドを用いて調べなければならない。それに対して、kraken はトレーニングのプロセスの中で自動で出力を ground truth の翻刻と照合させ精度を評定し、最も精度が高かったトレーニング回数のモデルファイルのみを出力するため、精度を調べる時間が省ける。多層の人工ニューラルネットワークを用いた OCR では、回数を多くするほど初めの数万回の学習では精度が高くなっていくのは通常であるが、ある一定数の学習を超えると、回数が多いほど精度が高いということはなくなってくる。逆に、前の回よりも精度が低くなることもある。
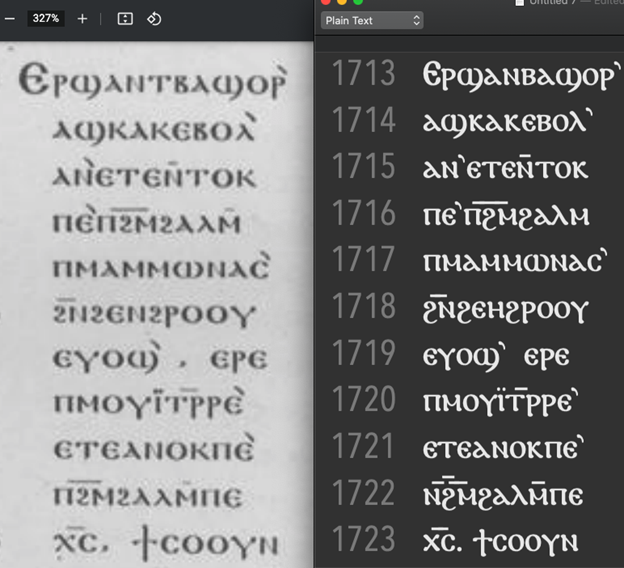
このトレーニングのプロセスを経て8分ほどで、最適なモデルファイルを kraken は出力した。その最適なモデルファイルの ground truth に対する精度は97.6%であった。これは、100%に近いものの、最近は100%により近いモデルも Calamari や OCRopus を用いて手軽に作れることから、良いとは言い難いが、OCR としては実用に堪えられる数値である。そして、同じフォントを用いている低画質の依頼されていた資料の全てのページの画像をそのモデルで文字認識させ、結果をテクストファイルに出力した。kraken はテクストファイルだけでなく、デジタル人文学でテクストマークアップに使われる世界標準形式である TEI XML、OCR 専用のファイル形式である hOCR、市販の OCR ソフトである ABBYY FineReader で使われる abbyyXML フォーマットの出力にも対応している。依頼主に kraken が文献写真の文字を読み取って出力したデジタルテクスト(図2)を送ると、ほとんど正確だとの良い評価を頂いた。
前回は、kraken の行認識の欠点を書いたが、現在その欠点を補うプロジェクトが eScripta[11]で進められている。eScripta とは、PSL 研究大学を中心に始動しているプロジェクトである。PSL 研究大学とはパリのエコール・ノルマル・シュペリウールなどのグランゼコール(高等専門大学校)などが2010年に連合して設立した新しい大学である。
eScripta は、文献の写真の HTR(Handwritten Text Recognition:手書きテクスト認識)からデジタル学術編集版のウェブ公開までの一連のプロセスのスタンダードを提示する。ツールは CNN(convolutional neural network)を用いた新しい行認識プログラム、kraken、Archetype[12]、Pyrrha、TEI Publisher[13]である。CNN のものは、kraken 内蔵の行認識プログラムよりも優れた行認識能力を持っているようであり、これによって HTR が可能になる[14]。これで行認識した後、学習済の kraken で文字を認識させ、Archetype で文献情報や言語学的情報をタグ付けした後、Pyrrha で誤認識などのエラーを修正し、最後は TEI Publisher で、TEI XML のデータを変形させてウェブ・デジタル学術編集版としてその文献をウェブ公開する。このプロジェクトは、これから、メロエ語[15]、ウガリト語、エラム語、ソグド語、トカラ語、パーリ語、古ジャワ語など、ラテン文字転写ではない、元の一次資料の文字を用いたデジタル学術編集版があまり作られていない言語の手書き文献のデジタル学術編集版を作成していく予定である[16]。将来的には、行認識、文字認識、エラー修正、タグ付け、ウェブでのデジタル学術編集版の公開というデジタル学術出版版を作成する一連のプロセスのモデルを提示することが期待されている。
特別寄稿「論文紹介:A. Fickers & T. van der Heijden「交易空間の中で:デジタル・ヒストリー実験室でのティンカリング」(後編)」
学際的交易空間と「境界的事物」
著者によれば学際的交易空間としての DTU は、「学際性」・「共通言語」・「ローカル性」という3つの観点から分析されるべきだという。
なかでも「学際性」は、DTU の核心ともいうべき概念であるという。ここでいう「学際性」は、J. T. Klein いうところの「方法論的学際性」と「理論的・批判的学際性」の双方を含む概念として定義されており[1]、「異なる知識領域に由来する方法や観点を集積することができる」という利点を有する。それゆえ DTU においては、学生による多分野連携プロジェクトや相互学習の機会が設けられており、学生たちもその意義を実感していることがインタビュー調査から窺われる。その一方で、学際研究に際して浮き彫りとなる人文学とコンピュータ・サイエンスにおける学問認識の相違、すなわち客観性や科学的実証性を巡る認識問題が課題としてあげられている。DTU は、こうした主観性―客観性という対立構図を「デジタル解釈学という概念を用いて克服すること」を目指している。それはすなわち、コンピュータ・サイエンスの手法によってもたらされる客観的なデータを、いかにしてより主観的で解釈依存的な歴史分析に接続しうるのかを十分に考察する、ということであろう。そのためには、そうしたデータを生み出すデジタル技術・手法を十分に理解し、批判的に分析する能力が求められると同時に、従来の人文学的思考力もまた要求されることになるという。
つぎに「共通言語」についてみれば、これは複数の要素から成る集団の形成原理という文脈で言及される。すなわち、そうした集団は均質性―異質性および協調性―強制性という二つの対比軸から成る4象限の性質を持ちうるが、このうち「共通言語に基づく集団」は均質性および協調性を強く持つという。DTU は当初、「共通言語に基づく集団」の形成を志したようである。というのも、異なる学問的背景を持つ学生を集めた DTU は、その形成時においては必然的に異質性および強制性に基づく「強制された空間」たらざるをえず、そこに共通基盤を構築することが志向されたからである。そして、こうした共通基盤構築のために用意されたのが上述(前編)の「準備期間」である。しかし、著者はこうした試みが中途で再検討を余儀なくされたことを明らかにしている。「準備期間」における必修カリキュラムは、必ずしも自身の研究に直結しない事柄の学習を強制された学生たちによるある種の抵抗を惹起したのである。こうした事実は、より大きな文脈でみれば、個人の研究と学際的研究との間の緊張関係とも捉えられるであろう。
最後の「ローカル性」は、物理的な近接性に関わる概念である。DTU は、各々が別々の場所にあって遠隔につながる「グローバル性」より、一所に物理的に集まる「ローカル性」を重視しているといい、そのために上述(前編)のような「場」を用意した。この「場」がある程度有効に機能し、遠隔では生じえなかった学生相互の交流や協働を促進したことはインタビュー調査からも窺われる。その意味では、物理的な近接性が学際的交易空間の形成に寄与したことは明らかである。だが一方、各学生が持つ個別の研究室やプライベートな空間との住み分けが問題となり、当初の意図に沿った空間形成が進んでいないことも明らかにされている。
以上のように、学際的交易空間の形成を巡っては、異分野間の認識論的・方法論的差異を架橋するための「デジタル解釈学」「共通言語」「場」など、様々な「境界的事物」の設定が試みられたことがわかる。そして、そうした試みは一定の成果を上げると同時に、今後さらに検討されるべき重要な課題をも浮き彫りにしたと言えるだろう。
ティンカリング
ここまでは学際的交易空間の形成に関する議論であったが、4章では、交易空間の中で実際にどのような実践が行われているのかが語られる。そこで重要になるのが、ティンカリングという概念である。ティンカリングとは前編註6でも記したように「素材や道具、機械を『いじくりまわす』こと」であるが、論考中では、1)方法論的なティンカリングと発見可能性、2)認識論的な批判を含む解釈学的実践としてのティンカリング、という2つの側面から検討が加えられる。いずれの場合にも実験的試行錯誤とハンズオンが重要視されていることは言うまでもない。
1つ目の観点である方法論的なティンカリングについては、テキストマイニングやネットワーク分析といった分析手法、およびそのためのデジタルツールの利用と分析を通して、「自身の史資料を分析・可視化・解釈し、意味のあるパターンや関係性、例外を発見するためにデータベース構造やテキストマイニングのアルゴリズム、データ可視化技術とどのように向き合うべきか」を学ぶ環境が用意されていることが明らかにされる。
他方、認識論的なティンカリングについては、分析的手法の導入に至る以前、すなわち「モノ」としての史資料からデータへ、データから構造化されたデータベースへという変換過程における情報の変質や欠損、再構成といったより根本的な側面に注意が向けられ、デジタルデータや構造化された情報についての認識論的側面が扱われる。具体的には、史資料のデジタル化やデータベース構築をハンズオン形式で実際に体験することで、それらの問題に自覚的に向き合うカリキュラムが用意されている。
おわりに
ここまで、論考自体の構成に沿いつつ、その内容を辿ってきた。「基盤としての環境整備」から始まり、「学際的交易空間形成の理念と実際」、そして「具体的な研究実践」の検討へと進む論考の骨子を紹介することはできたと思う。このような本論の記述を踏まえ、著者は結論において3つの教訓を引き出している。それは、1)空間としての「場」の意義、2)学問領域的・制度的な溝の認識、3)共同研究プロジェクトの設定による専門研究と学際研究間の緊張関係緩和の可能性、である。これらの教訓は、これからの日本におけるデジタル・ヒストリー研究環境・教育を考える上でも十分に検討されるべき課題であると思う。
1つ目にあげられた「場」の意義の認識と整備は十分に進んでいない。ここでいう「場」とは物理的な意味であるが、現在、DTU に比するような諸々の設備を備えた独自の研究室・実験室を持つデジタル・ヒストリー部門は皆無である。設備のみならず、デジタル・ヒストリーに携わる学生・研究者が日常的に交流しうる「場」も非常に限定的である以上、「場」の環境整備をいかに進めるか―あるいはあえて進めないか―は議論される必要がある。
2つ目の問題はより制度的な問題であるが、著者も指摘するように、各々の学問領域に属する、必ずしもデジタル・ヒストリーには関わらない教職員との関係性や、彼らが果たす役割も無視されるべきではないだろう。
そして3つ目の教訓は、とくに学生にとって非常に重大な問題である。論考でも指摘されているように、個人の専門研究とデジタル・ヒストリーの学習・研究が乖離した場合、学生は両者の緊張関係に苦しむことになる。両者を相互補完的な形で進めうる環境を実現するためにも、どこまでの内容を共通して学ぶべき―いわば必修―事項として設定しつつ、個別のニーズに合わせたカリキュラムを提供しうるかを考慮する必要がある。また、個々の専門研究に資するような共同研究を促進し、学生でも参加できる環境を整えていくことも重要な課題になるであろう。
人文情報学イベント関連カレンダー
【2021年4月】
-
2021-04-09 (Sun)
第117回デジタルアーカイブサロン:国際博物館会議(ICOM) 国際ドキュメンテーション委員会(CIDOC) 2020大会報告於・オンライン -
2021-04-23 (Fri)~2021-04-24 (Sat)
デジタルアーカイブ学会第6回研究大会於・オンライン
【2021年5月】
-
2021-05-22 (Sat)
第126回 人文科学とコンピュータ研究会発表会於・オンライン
【2021年6月】
-
2021-06-19 (Sat)~2021-06-20 (Sun)
アート・ドキュメンテーション学会 第32回(2021)年次大会於・立命館大学衣笠キャンパス
Digital Humanities Events カレンダー共同編集人
◆編集後記
巻頭言執筆後、「第六期科学技術・イノベーション基本計画」が閣議決定された。今期は初めて、人文・社会科学に関するいくつかの課題設定が行われており、なかでも巻頭言で扱った人文学研究データの件は次のような文言で期限も含めて提示されている。
期間が短く、じっくり議論するのは困難かもしれないが、こういった課題を人文学自身をより良いものにしていくためにどのように活かしていけるか、それによって人文学の将来をどのように描いていけるか、皆でうまく智慧を寄せ合えればと思っている。
(永崎研宣)
- コメントを投稿するにはログインしてください