人文情報学月報第129号【前編】
ISSN 2189-1621 / 2011年08月27日創刊
目次
【前編】
- 《巻頭言》「古辞書はコーパスに馴染むか」
:京都府立大学文学部日本・中国文学科 - 《連載》「Digital Japanese Studies 寸見」第85回
「Creative Commons が政策文書「文化遺産のよりよい共有に向けて:著作権改革への論題」を公開」
:北海学園大学人文学部 - 《連載》「欧州・中東デジタル・ヒューマニティーズ動向」第46回
「危機言語の音声・テキストのデジタル・アーカイブ:Endangered Language Archive と Pangloss Collection」
:人間文化研究機構国立国語研究所研究系
【中編】
- 《連載》「デジタル・ヒストリーの小部屋」第4回
「詳細なレシピもいいが、肝心の料理の質を上げてくれ:議論主導型のデジタル・ヒストリーと探索的データ分析」
:千葉大学人文社会科学系教育研究機構 - 《特別寄稿》「YAIST:部品と画数で漢字を検索するための Unicode 入力支援ツールについて」
:岡山大学大学院社会文化科学研究科
【後編】
- 人文情報学イベント関連カレンダー
- イベントレポート「シンポジウム「第17回京都大学人文科学研究所 TOKYO 漢籍 SEMINAR『デジタル漢籍』」」
:東京大学大学院人文社会系研究科 - イベントレポート「日仏図書館情報学会主催「Gallica―その戦略のゆくえ」」
:お茶の水女子大学大学院 - 編集後記
《巻頭言》「古辞書はコーパスに馴染むか」
2022年3月10日に、シンポジウム「古辞書・漢字音研究と人文情報学」[1]がオンライン開催された。北海道大学の池田証壽先生と共催させていただいたものであるが、日本語学>日本語史>さらに狭い専門であると考えられる古辞書・漢字音研究の会合に、延べ100名以上が参加してくださり、活発な質疑のおこなわれたことは、予想外の活況と評してよいものであったと思う。古辞書や漢字音のデータベースの公開情報を知りたい、というのみならず、できれば積極的に開発にかかわりたい、とか、作り方や作るうえでの問題点を知りたい、その解決に寄与したいといった学界の気運を共有できたことは、収穫であった。しかしその多くの参加者は、発表者諸氏(の一部)や私自身を含め、決して人文情報学に明るい者ばかりではなかったことが、顔ぶれやアンケート結果からも明らかであった。このこともまた画期的な現象であったと思う。
大学に勤務するようになってまだ年数の浅い私であるが、過去に国立国語研究所でのコーパス構築に携わった経歴があることから、「実務家教員」として、授業でコーパスの使い方を教えることがままある。しかし現場の人文系の学者(教員)は、未だに、データベース、コーパス、テキストマイニングといった単語自体に拒否反応を示すことが少なくなく、なぜか「紙の文献」と対置させてデジタル資料を語る傾向にある。そのような思考は、日々、学生にも伝播しており、学生曰く、「日本語学は計量的なことをやらないといけない、コーパスの使い方を覚えないといけないので、敬遠したい」。このような学生たちの根本的誤解に触れるにつけ、追いかけて行って、「語学でなく文学や歴史の研究だって、コーパスはとても役に立つよ」と言ってあげたくなる。(次に述べるように、私自身の研究にはコーパスを利用すること稀であるが、コロナ禍の授業や研究においては、デジタル資料全般の存在に大いに助けられた)
そもそも私自身は、日本の古辞書[2]研究、語彙史研究という分野の人間である。古辞書の語彙は、コーパス化に不向きな「文脈のない」語群であることが多い。以前、「和名類聚抄」[3]を対象にして構造化の一案を示したことがある[4]が、「和名類聚抄」を取り上げたのは、注釈が漢文体の文章で書かれており、研究者による解釈の揺れが少ないものと判断したためである。他の古辞書には、単語が羅列されているだけのような様式のものが多いため、データベース構築の費用対効果を考えると、どうしても腰が引けてしまう。つまり、もとより辞書とは何らかの順番で字や語が並んでいるものであり、データベースを介さず、直接その字や語を探すことが可能である(=辞書自体がデータベースである)ためである。そのため専門家自身が、公開できるクオリティの古辞書データを作成し、公開するメリットは非常に乏しいものと考えられてきたように思う。また古辞書研究や語彙史研究では、語に当てられた用字も重要な要素となる(イトホシという古語にたいして、現実の紙の上では「憐」「糸惜」や Unicode 範囲外の字を含む多様な表記がおこなわれてきており、古辞書にも異表記・異体字が複数挙がる。どの文献でどの字が選択されるか、どの字がどの辞書に登載されるかといった点が、研究上は重要となる)。しかし古辞書に収録された語の用例を調べようとしたとき、例えば現在日本語の通時コーパスとして最も有用とされる『日本語歴史コーパス』[5]の底本の大部分を占める『新編日本古典文学全集』の表記は、原写本等から大きく改変されたことが知られており、少なくともそのままの形で研究に用いることはできない。コーパスの強みは、「統語的に」「代表的表記・語形で」語を調べられるところにあり、ひとつの単語の表記が現実にどうであるかということまで、現段階ではフォローされていないためである。しかも古辞書の語彙を、『日本語歴史コーパス』に収録されるような普通の日本語文と比較するという手法は決して学界の主流ではなく、研究においてはむしろ辞書同士の語彙を比較することが多いため、これまでの古辞書研究にとって、既存のデータベース・コーパス類の存在はほぼ無力であるようにも見えてきた。実際のところ、古辞書研究の世界は、利用するにせよ構築・発信するにせよ、デジタルの世界に無縁のままでも、まだしばらくは成果の出せる分野であったと思う。
しかしある頃、池田証壽氏を筆頭とした北海道大学のグループが、数種の古辞書 DB の公開を経て、ついに代表的古辞書である「類聚名義抄」[6](観智院本)の公開を開始するということを知った。この報に接した古辞書研究者のうち次のように考えた者がいたとしても決しておかしくはない。「専門家に解読されて簡単に引けるようにされてしまっては、古辞書の授業で教えることが減ってしまうではないか」「これを契機に、機械に古辞書が読めるようになられては商売あがったりである」。実際のところ、専門家が自身の「研究時間を費やして」作成したデータベースを他人に「無償で」公開することに消極的であることは、どの分野でもあり得ることと思われる。また一方で、人文系研究者が「翻字」データベースを公開することは、論文数本分(下手をすると1本以下)の価値程度にしか見積もられないことも多く、「業績」としてのカウント方法も定まっていないのが現状である[7]。しかして始まった「類聚名義抄」の公開[8]であるが、古辞書に少しでも触れたことのある者であれば、これが、論文10本、20本どころの価値ではないことはすぐにわかったであろう。
冒頭に触れたシンポジウムでは、日進月歩の人文情報学の世界と、日本語学の中でも「伝統的」分野であった古辞書の世界がやっと交わったという感触を得た。言うまでもなく池田氏のプロジェクトは既に長きにわたって成果を公表し続けてきたのであるが、この感触は実は、この文章の中でやや皮肉を交えて描いた、「以前はデータベース類に拒否反応を抱いていた」層の一部を本格的に取り込みつつあるといった私の実感に基づいている。そしてその旧態依然とした層の一人は、私自身であることを、このシンポジウムを通しても痛感したのであった。「古辞書の授業で教え(られ)ることが減ってしまう」と馬鹿なことを考えたのも私自身である。データベース拡充によってできなくなることではなく、可能となる研究に頭を使うべきであること、言を俟たない。現在ではまだ難しいコーパス上での日本語の表記研究や、辞書語彙同士の比較研究なども、将来的にはもっと手軽におこなえるようになればよい。そのための土台作りに微力でも尽力したいと考えている[9]。
シンポジウムの閉会の挨拶中、池田先生が、これらの研究を若い人々にバトンタッチする必要がある、これからは若い人たちの時代である、という点を特に強調されたことが印象深かった[10]。ご自身が長年推進・蓄積されてきた研究の足跡が途絶えてしまうことは耐えがたいことであろうと推察するが、それは杞憂であり、先生が拓いてくださっている道が、古辞書研究界以外においても、様々な形で結実していくことを確信している。
執筆者プロフィール
《連載》「Digital Japanese Studies 寸見」第85回
「Creative Commons が政策文書「文化遺産のよりよい共有に向けて:著作権改革への論題」を公開」
2022年2月9日、Creative Commons は “Towards Better Sharing of Cultural Heritage — An Agenda for Copyright Reform” という政策文書を公開した[1]。Creative Commons(以下 CC)は、いうまでもなくオープンな文化的資源を実現するためのライセンスであるが、このようなオープンな文化を標榜するシンクタンクとしての機能も果たしている。
この文書の著者は CC の政策・オープンカルチャー・GLAM(Galleries, Libraries, Archives, and Museums; 美術館・図書館・文書館・博物館の総称。文化施設と考えてよい)部門長である Brigitte Vézina 氏によって執筆されている[2]。カナダの弁護士資格を持ち、WIPO(世界知的所有権機関)で経験を積み、SPARC(国際学術情報流通基盤整備事業)ヨーロッパや Europeana などへのコンサルタントとして働いてきた人物である。本文書には、Europeana や欧米の文化資源のデジタル化やオープン化に取り組んできた人々からのインプットが明記されている。
この文書が出された背景には、Creative Commons Network という著作権改革を訴える取組みが始められたことがあるようだ[3]。この活動は、2013年の著作権改革宣言を背景にしたもので[4]、著作権保護が本来あるべき公共と著作者との権益のバランスを失っているとして、著作権改革のための運動を支援するものとして設立されたものである。
したがって、本文書も、GLAM 分野における著作権の権益のバランスについて考量するものとなっている。
本文書では、まず前段として、GLAM が(教育や文化にかんする)人権を享受するために果たす役割について確認し(pp. 2–3)、GLAM がデジタル環境において、均衡を欠いた著作権法によってその役割をじゅうぶんに果たし得ていない現状を述べ(pp. 3–5)、その解決策が著作権の調整と改革を措いてないことを主張する(pp. 5–6)。
本編として、GLAM の公共的な活動を阻碍する著作権上の要因について、論点を七つに整理する:「公共的用途のための明快な例外規定と権利制限」(pp. 6–16)、「パブリックドメインに著作権のさらなる層を掛けさせない」(pp. 16–18)、「保護期間の短縮(延長ではなく)」(pp. 18–19)、「善意にもとづく GLAM の行動に対する処罰や救済措置を限定する」(p. 19)、「文化的権利・伝統文化的表現・先住民族の文化遺産と返還に関する法的ないし倫理的問題」(pp. 19–22)、「人工知能と文化遺産」(pp. 22–23)、「著作権・文化的権利・文化遺産関連法の相互関係」である。最後のものは、挙げられてはいるが、本文内の項目としては見当たらない。記述としては、p. 22に1段落だけで触れられている。
最初のものは、もっとも長く、GLAM にとっての利点、それによって社会的に生じる便益が詳細に論じられている。要点としては、GLAM のための著作権利用の例外規定や権利制限がないか、あったとしても曖昧であったりして、適切な GLAM の保存継承のための行動を妨げているので、改善する必要性が高いということである。ここでいう保存継承のための行動とは、たんに保存のための複製を作成することだけではなく、障碍者のための必要最低限の改変やオンライン展示などもふくめた享受による社会的継承、作成された複製の展示への貸与なども含まれる。例外規定や権利制限の明確化には、社会の構成員たる一般市民が安心して著作物を利用することにも繫がるとする。また、例外規定や権利制限を契約や技術的手段によって弱めることに対する反対も述べられている。
ここで、GLAM が孤児著作物ないし絶版著作物の保存と社会的利用のための権限を持つべきだという見解があるが(pp. 9–10)、著作を発表する権利などとのかねあいについてはあまり検討されていない。よって立つ法制度の差異もあろうが、著作物をコントロールしたい欲望が生じうるのは人間として自然のことと思われるところ、それを論じないことで、円滑な対話が進むのかは疑問に思った。
2点目は、パブリックドメインに入った著作物を遡及してふたたび著作権保護のもとに置いたりすることへの反論が述べられる。また、各国の保護期間がまちまちで、地域によって保護下にあるかどうか不明瞭であることも、適正な利用の阻碍要因であることが示されている(たとえば、日本とアメリカとでは著作権保護期間の考え方が異なり、日本で著作権が消尽した作品が、アメリカではなぜかまだ有効である例などもある)。ここでは、GLAM 機関が所蔵物にたいする著作権を主張することについても否定的に述べられている。
3点目では、著作権の短縮を真剣に検討すべき理由が述べられる。15年で十分という研究すらあるようだ[5]。
4点目は、善意、ここではすなわち著作権にかんする事実を知らずに侵害を行ってしまったようなばあいに、法的な罰や救済措置を商業的なそれと同列に扱うべきではないということが述べられている。
5点目は、著作権と先住民族の文化的権利の相克について述べる。つまり、著作権上はパブリックドメインにあるとされても、ことそれが先住民族に属するものであれば(ここに衰退下にある地域文化を入れてよいだろうか?)、さまざまな検討事項が発生する。特段新しい議論はないが、このような被簒奪者の権利について整理する Local Contexts という試みがあることを知った[6]。
6点目は、AI の学習などの用途にデジタル化した資料を用いさせてよいかという論点である。ここでは、既存の著作権の保護や権利制限の枠組みとどのように対応するのか明確ではないとしつつ、公益に資するようなものには利用を認めてしかるべきことが述べられている。
以上のことがらは、日本の法制ではあるていど対応されているようなところもあるように思われ、その点、欧米法からのインプットしかなかったことは残念である。とはいえ、著作権と文化機関の関係についてあらためて整理されたものとして、議論のよい出発点になるものと思われる。本文書をもとにしたワークショップも5月に開催予定とのことであり[7]、そこで意見を述べることもできよう(稿者は予定が合わないが)。
本文書のライセンスは明示されていないが、CC のウェブサイトは原則として CC by 4.0で提供されているので、これもそれに当たると考えてよいのだろうか? あんがい、CC の文書には、ライセンスの明示がなく、不安にさせられるところである。
クリエイティブ・コモンズ、GLAM の活動に関連する著作権上の課題についてのポリシーペーパーを公開 | カレントアウェアネス・ポータル https://current.ndl.go.jp/node/45937。
network-platforms/copyright-reform.md at main - creativecommons/network-platforms https://github.com/creativecommons/network-platforms/blob/main/copyright-reform.md.
《連載》「欧州・中東デジタル・ヒューマニティーズ動向」第46回
「危機言語の音声・テキストのデジタル・アーカイブ:Endangered Language Archive と Pangloss Collection[1]」
言語および方言の定義にもよるが、現在地球上には7000ほどの言語があると言われている。そして、そのうちの4分の1はすでに母語話者がいなくなりかけている危機的状況であるという[2]。この消滅の危機にある言語を危機言語と呼ぶ。危機言語のほとんどが文字を持たない言語である。UNESCO(国連教育科学文化機関)によれば、1950年以後に約230の言語が「消滅した」(母語話者がいなくなった)と言われている[3]。
UNESCO が2009年2月に発表した「危機言語世界地図」(Atlas of the World’s Languages in Danger)の第3版において、アイヌ語を極めて深刻な言語、八重山語と与那国語を重大な危機にある言語、八丈語、奄美語、国頭語、沖縄語、宮古語を絶滅の危険にある言語とした[4]。近年の比較歴史言語学的研究では、アイヌ語はもちろんのこと、琉球諸語を本土の日本語とは異なる言語であると認めていた。それに対して、日本の方言学者の間では、琉球諸語や八丈語は、日本語の一方言とする見方が根強かった。しかし、UNESCO の発表を受けて、日本の文化庁は、これらを消滅の危機にある個別の言語であると認めた。このことは、それぞれの母語話者の、自分たちの言語に対する認識にも、肯定的な影響を与えた。一方、本土の日本語に関しても、数多くの方言が消滅の危機に瀕している。
消滅の危機にある言語・方言のアーカイブ化の国内の一大拠点である大学共同利用機関法人人間文化研究機構国立国語研究所は、「危機言語データベース」[5]、「ことばのミュージアム」[6]、「アイヌ語口承文芸コーパス」[7]などで、これら日本国内の危機言語、危機方言のデジタル・アーカイブ化を進めている。また、国立アイヌ民族博物館でも、アイヌ語のデジタル・アーカイブを開発・公開するなど[8]、これらの消滅の危機にある言語・方言のアーカイブ化は日本で進みつつあるが、消滅の速度に追いつくのが急務となっている。
そのため、これらの言語の保存・継承・復興のためにも危機言語の音声、テキスト、動画などのアーカイブ化が急務となっている。危機言語のアーカイブ化は、世界各地でなされてきたが、リオデジャネイロのブラジル国立博物館の2018年9月の火災で、貴重なブラジル先住民の言語資料が失われたように、失われやすいアナログ資料をデジタル化することも持続可能な現代のデジタル危機言語アーカイブに必要なこととなっている。本稿では、欧州を拠点とする、代表的な2つの危機言語のアーカイブを紹介する。
危機言語アーカイブ「Endangered Language Archive(ELAR)」[9]
「危機言語アーカイブ」(Endangered Language Archive; ELAR)は世界でも最も大規模な危機言語のデジタル・アーカイブの1つである[10]。ELAR はもとはロンドン大学東洋アフリカ学院を拠点としていたが、維持の困難さから、2021年7月よりドイツのベルリン・ブランデンブルク学術アカデミーに開発・維持拠点が移った。このアーカイブでは、非文字言語で現在失われつつある危機言語の音声・映像記録、音声書き起こし、翻訳、辞書、入門書をデジタル化し、保存・公開している。古いアナログの資料(レコード盤やカセットテープなど)も数多くデジタル化している。現在、70カ国以上で記録された550以上の危機言語の資料をデジタル・アーカイブ化している。この ELAR のプロジェクトは、メタデータの作成、データ管理、フォーマット、キュレーション、そしてアナログフォーマットのデジタル化と多岐にわたる。このプロジェクトは、言語学者、話者、地域コミュニティなどからの危機言語に関する資料の提供を常に募集している。例えば、ELAN[11]という、言語音声、テキストを言語学的に注釈するプログラムを用いた言語ドキュメンテーションの1〜2週間のトレーニングプログラム等である。
ELAR は「デジタル危機言語・音楽アーカイブネットワーク」(Digital Endangered Languages and Musics Archives Network; DELAMAN)の創立メンバーである。この団体は、世界中で絶滅の危機に瀕している言語や音楽を記録・保存することを目的とした団体である。また、ELAR は「CLARIN 言語多様性と言語ドキュメンテーションの知識センター」(CLARIN Knowledge-Centre for Linguistic Diversity and Language Documentation; CKLD)のメンバーで 、デジタル・コーパスの作成とアーカイブに関するアドバイスも行っている[12]。
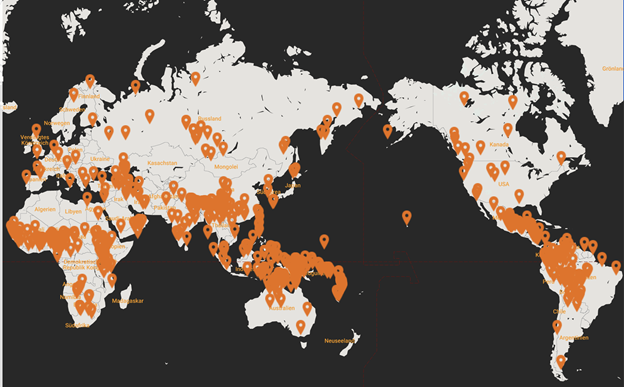
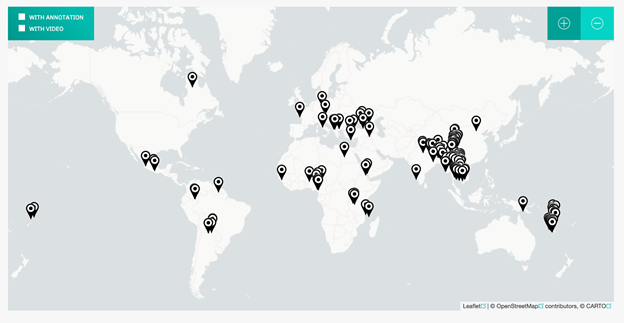
Pangloss Collection[13]
Pangloss は、フランス国立科学研究センターが運営する危機言語アーカイブで、世界の言語遺産の保護に貢献するオープンなアーカイブを目指している。音声とテキストのアーカイブ化がなされており、2020年現在、170以上の言語で780時間の録音を有し、そのうち約半数の音源(3600件中1530件)で文字起こし、注釈、翻訳が完了し、公開されている。大変モダンで洗練されたデザインの CoCoON プラットフォームを用いており、ウェブサイト自体は「デジタル口承コーパスコレクション」(Collection de Corpus Oraux Numériques)によってホストされている。
ELAR ではより多くの様々な形式の音声・テキストがアーカイブ化されているのに比べ、Pangloss ではテキストと注釈は統一された XML フォーマットで、音声も mp3形式でダウンロードできるほか、テキストと訳と音声を文レベルで同時に視聴することができる。そして、全体の音声速度はプレイヤー上で変えることもできる。また、一つ一つの例文の文毎に「https://doi.org/10.24397/pangloss-0000299#S25」といった DOI(Digital Object Identifier)が付されている。コーパスとは別に、現在6言語の辞書が公開され、PDF、HTML、XML などのフォーマットでダウンロードが可能である。
Pangloss は、ELAR と同じく、危機言語資料の公開ウェブアーカイブというジャンルで、目的も消滅の危機にある言語の資料の保存である。ELAR は資料の量が多いが、形式が統一されていない。それに対して、Pangloss はアーカイブ化した言語数は ELAR よりは少ないものの、テキスト・注釈の XML データの形式を統一し、さらに昨今のオープンサイエンスで普及している DOI を使用している。
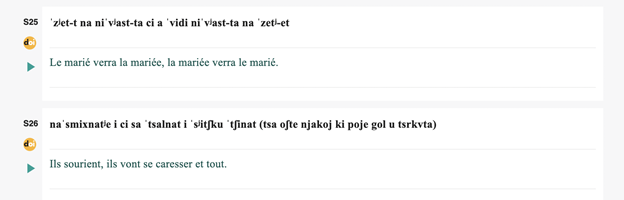
テキストの内容自体は様々なものがあるが、Pangloss は新規のボランティアに対して、フランスの言語学者・神話学者のジョルジュ・デュメジルがウビフ語の研究で用いた「ヤギと羊」というテキストを様々な危機言語で収録することを推奨している。
Pangloss Collection の特長として、自由で分散化されたインターネットの中でのオープン・アーカイブを標榜しており、透明性とプライバシーの尊重を目指している。具体的には、ウェブサイト上では、クッキーを用いず、ユーザの行動を記録しない他、言語学者のために設計された「プロフェッショナル」モードでは、認証やログインを必要とせず、だれでもアクセスできる。Pangloss Collection は、OLAC(Open Language Archive Community)[14]に加盟している他、ELAR と同様 DELAMAN にも加盟している。
今回、ELAR と Pangloss Collection というヨーロッパを拠点とした二つの危機言語デジタル・アーカイブについて論じたが、世界には他にもいくつかの大規模危機言語デジタル・アーカイブがある。次回は、そのなかでもアジア太平洋地域の危機言語にフォーカスした、オーストラリアの PARADISEC 等、より地域に根ざした危機言語アーカイブを取り上げようと思う。
- コメントを投稿するにはログインしてください