人文情報学月報第142号【前編】
ISSN 2189-1621 / 2011年08月27日創刊
目次
【前編】
- 《巻頭言》「人文情報学から見たヴェーダ文献学のいま」
:東京大学大学院人文社会系研究科 - 《連載》「Digital Japanese Studies 寸見」第98回
「2023年度日本語学会春季大会でシンポジウム「情報技術と大規模テキスト資源がひらく日本語史研究」が開催」
:慶應義塾大学文学部 - 《連載》「欧州・中東デジタル・ヒューマニティーズ動向」第59回
「世界の諸言語の文法類型地図データベース・Grambank の誕生:WALS との違いについて」
:人間文化研究機構国立国語研究所研究系
【後編】
- 《連載》「デジタル・ヒストリーの小部屋」第16回
「デジタル史料批判と草の根のデジタル化:フィンランドにおけるデジタル・ヒストリー(1)」
:千葉大学人文社会科学系教育研究機構 - 《連載》「仏教学のためのデジタルツール」第7回
「龍谷大学図書館貴重資料画像データベース「龍谷蔵」」
:龍谷大学大学院文学研究科 - 人文情報学イベント関連カレンダー
- イベントレポート「“Advanced Computational Methods for Studying Buddhist Texts”シンポジウム参加報告」
:東京大学大学院人文社会系研究科 - 編集後記
《巻頭言》「人文情報学から見たヴェーダ文献学のいま」
筆者は、古代インドの言語であるサンスクリット語を研究している。その中でも特に古いヴェーダに用いられるサンスクリット語(以下、ヴェーダ語)を扱っている。学部から修士、博士まで言語学に身を置いてヴェーダ語研究をする一方で、ヴェーダを対象とした自然言語処理にも従事してきた。偶然身につけた Python を使い、簡単なテキストの整形から深層学習まで行ってきた。このような研究の経験を踏まえて、人文情報学の観点からみたヴェーダ文献学のこれまでとこれからを述べよう。
サンスクリット語は、大きく分ければ、ヴェーダのサンスクリット語と古典サンスクリット語の2つに分かれる。古典という名にも関わらず、ヴェーダよりも新しいことに注意が必要である。ヴェーダ語が古典サンスクリット語と異なる点として代表的なものとして、アクセントが弁別的であることと、動詞の活用が豊富であることが挙げられる。特にこのアクセントが、後に見ていく電子テキストと大きく関わっている。
ヴェーダ文献群は、他のサンスクリット文献と同様、数多くが電子化されている。サンスクリット文献を収録している、主要なデータベース/プロジェクトを次に挙げる:GRETIL (Göttingen Register of Electronic Texts in Indian Languages) [1], TITUS (Thesaurus Indogermanischer Text- und Sprachmaterialien) [2], SARIT (Search and Retrieval of Indic Texts) [3], DCS (Digital Corpus of Sanskrit) [4], VedaWeb [5]。まずはこれらの概要を簡単に見ていく。
GRETIL:機械可読テキストを提供するプラットフォーム。ヴェーダも含むサンスクリット語、中期インド・アーリア語(パーリ語、プラークリット)、新期インド・アーリア語(ヒンディー語、マラーティー語)、ドラヴィダ語といったインドの諸言語や古ジャワ語やチベット語のテキストがある。個人や研究機関が持っていた電子テキストが登録されている。GRETIL になくても TITUS にあるものは TITUS へのリンクがある。いつのまにか、テキストを TEI 化することにも取り組み始めていた。
TITUS:インド・ヨーロッパ語(以下、印欧語)を対象として、検索エンジンおよびテキストベータベースの他さまざまな機能を持つ。特に印欧語が強く、古い言語のテキストを数多く持つ。プレーンなテキストと TITUS で見るための HTML のテキストを提供している。
SARIT:サンスクリット語のテキストおよびテキスト検索機能を提供する。テキストは、裏で TEI/XML で用意されており、全て Github で公開されている(https://github.com/sarit/SARIT-corpus/)。さらにはアプリケーション自体も公開されている(https://github.com/sarit/sarit-existdb)。
DCS:サンディ(単語の境界部分の音が変わる現象)が解除され、形態情報や語彙情報を持ったテキストからなるコーパス。言語学的研究および文献学的研究のために作られている。検索、辞書、テキスト、引用関係などの機能を持つ。データが Github で公開されているが、テキストは CoNLL-U Formart(https://universaldependencies.org/format.html)で置かれている。
VedaWeb:サンスクリット語、特にヴェーダ語の言語学的研究のために作られている比較的新しいプラットフォーム。形態情報や検索、辞書との接続といった機能を持つ。パイロット版として、『リグ・ヴェーダ』が公開された。テキストは TEI/XML で、ウェブからエクスポートが可能であり、Github でも公開されている。
さて、これらの中でヴェーダ文献を含んでいるのは、GRETIL, TITUS, DCS, VedaWeb(これは名前の通り)の4つである。筆者はいずれも触れたことがあり、後で述べるように TITUS のおかげで卒業論文から博士論文まで書くことができた。実は、筆者が主に読んでいるのは『リグ・ヴェーダ』という1つの文献である。2017年には、『リグ・ヴェーダ』の電子テキストは、TITUS から手に入れるしかなかったと記憶している。そのころは GREIL のテキストはプレーンなテキストだったし、VedaWeb も公開されてはいなかった。その中で、TITUS は構造化されたとは言えなくもないテキスト(図1)を公開していた。そのため、TITUS のテキストを元に、自身の研究で使えるような形式―詩節情報および韻律情報が付与された形―に整えていた。ちなみに、その一方で、フロッピーディスクからデータを取ってきてユニコードではない文字で作られた電子テキストと格闘したこともある。それが数年経った今となっては、GRETIL でも VedaWeb でも TEI/XML のテキストを入手でき、DCS では形態や統語関係まで記述されたテキストを使うことができる。
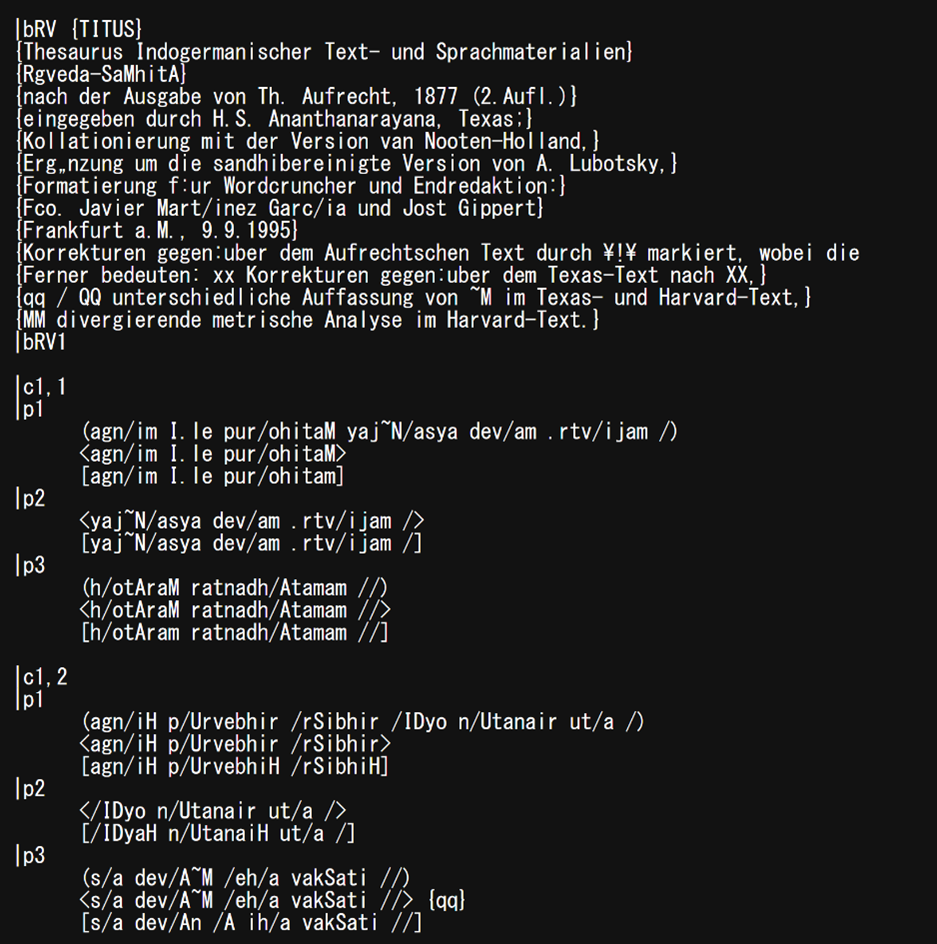
では、このようなテキストを使ってどのような研究がなされてきたのか。それを見る前にまず、サンスクリット語の処理に際しての問題を知る必要がある。DCS の概要で少し触れたサンディ(sandhi、連声)の問題がある。つまり、文中において単語の境界部分の音が変化し、時には単語同士がくっついてまるで1単語のように見えることがある。そのため、まずは文を単語に切り分けるところから始めなければならない。これは、日本語での分かち書きに相当する。この問題をコンピュータで解決するための研究が長年なされてきた。ルールベースでサンディを解除する流れから一変して、2018年には深層学習の波がやってきた[6], [7], [8]。このような流れの中で、「データ駆動型科学が解き明かす古代インド文献の時空間的特徴」というプロジェクト(https://ancientindia-datascience.jp)が始まったことは注目に値する。そこでは、ヴェーダ文献の構造分析や分散表現による類似度の推定、依存構造解析など、DH らしい種々の研究成果が発表された。少しずつ整備されてきたヴェーダ文献の電子テキストを利用し、情報技術を活用した研究の道は確実に開けてきている。
ヴェーダ文献学は、テキスト作りから分析まで、まさにデジタル化の真只中である。デジタルという点では30年前から既にそうだっただろうが、転写方式やテキストの作り方といった基本的なところから異なるデータの乱立(GRETIL, TITUS)から、徐々に同一の指針で作り直されている(TEI 化)。また、単純な単語検索から、高度な検索までカバーするようになり(SARIT, DCS, VedaWeb)、元データの扱いやすさからも、大規模な分析がより簡単になってきている。実際にヴェーダのテキストデータを対象とした研究がだんだんと盛り上がってきていることを見た。この発展に筆者自身も寄与していきたいと考えている。
執筆者プロフィール
《連載》「Digital Japanese Studies 寸見」第98回
「2023年度日本語学会春季大会でシンポジウム「情報技術と大規模テキスト資源がひらく日本語史研究」が開催」
2023年度日本語学会春季大会でシンポジウム「情報技術と大規模テキスト資源がひらく日本語史研究」が開催された[1]。このシンポジウムは、昨今の歴史的な日本語テキスト資源を取り巻く環境の変化を受け、日本語の歴史的研究(以下日本語史研究)の現在地の確認と将来への展望を開くことを目的としたものである。なお関連して、本大会では、日本語学会会長の近藤泰弘氏が事前に会長企画講演をウェブ配信しており、その内容は「日本語研究から見た ChatGPT」というものであった[2]。大規模言語モデルの歴史から ChatGPT の可能性を振り返りながら、さらに言語学的研究にどのように活用可能かという問題にまで説き及ぶものである。このなかで、シンポジウム内でも指摘があったが、大規模言語モデルの学習から漏れている、古典文献や方言文献の電子的資料の利用容易性の向上が大きな課題であるとされた点は、ことによっては人文学的危機であり契機でありうるものであろう。
さて、シンポジウムの登壇者は、企画および司会の小木曽智信氏および北﨑勇帆氏、そしてパネリストの大川孔明氏(日本学術振興会/青山学院大学)、青池亨氏(国立国会図書館)、および古宮嘉那子氏(東京農工大学)の5名であった(パネリストは登壇順)。企画趣旨の説明の後、大川氏はコーパスを利用して日本語史研究を行ってきた立場、青池氏は国立国会図書館において昨今のデジタル資料の電子テキスト化を推進してきた立場、古宮氏は自然言語処理分野において、語義曖昧性解消などから出発して前時代語などにその成果を適用する研究を行ってきた立場から提題し、それをふまえて司会や会場からの問いかけをふまえてのディスカッションが行われた。なお、各提題には、小木曽氏からは国立国語研究所において日本語歴史コーパス[3]の開発を主導してきた立場から古宮氏にたいして、北﨑氏からはコーパスを利用した日本語史研究を行ってきた立場から大川氏および青池氏にたいしてコメントがなされた。
企画趣旨としては([1]にも示されている)、日本語史研究における情報技術やテキスト資源への興味関心が古くからあり、それが自然言語処理技術の向上と密接な関係にあることを再確認し、そのうえで、近年の深層学習の進歩が今後の日本語史研究にどのような影響をもたらすかを議論する場であることが説明された。
大川氏の提題は、日本語史研究における電子的コーパス利用の現状と課題について総覧したものだった。大川氏からは、日本語歴史コーパスなどのアノテーションが整備されたコーパスが利用可能になったことにより、従来は研究に限界があった単語の出現環境を精緻に調べた研究が現れていることが述べられた。また、アノテーションやパラレルコーパスを活用して、統計的な分析が従来よりはるかに容易になったことが具体的な研究例とともに示された。弱点として、すでに附与されたアノテーションに依存してしまう問題、(とくに国立国語研究所による)コーパス化の対象外の資料を研究対象とすることの難しさが述べられた。これにたいして北﨑氏からコメントがあり[4]、コーパスにないものを発掘しつづける意義や、(続く青池氏の発表で示されるような)ツールの活用によって乗り越えられないかという期待が述べられた。
ついで、青池氏からの提題では国立国会図書館における OCR 関連事業の成果について述べられた。これについては、興味のあるところとは思うが、以前述べたところと大部分重なるので繰り返さない[5]。最後のスライドで、OCR 関連事業の成果のどの部分がどんなときに活用されるかフローチャートが示されたのは分かりやすかった。北﨑氏からのコメントとしては、OCR テキストの日本語(史)研究における利用可能性について、方言を書き留めた文献の発掘、活字化されていない文献への検索利用などが挙げられた。また、OCR の誤りへの警戒の仕方について論じられた。
最後に、古宮氏から提題があった。自身の研究の推移について説明があったのち、それが小木曽氏らとの日本語歴史コーパスにかんする共同研究にどう活かされたかが示された。具体的には、国立国語研究所の『分類語彙表』(増補改訂版)[6]を用いて、多義的な語の用法の特定を機械的に処理する作業を、学習用のデータの豊富な現代語のデータから過去の時代に適用するといった試みや、前近代資料の現代語への機械翻訳などの試みの紹介である。過去の時代に適用するとひとことで言ってもさまざまな可能性があり、どのような手法が現状有望かといった検討まで概観的に示された点で興味深かった。これにたいしては小木曽氏からコメントがあり、古宮氏の研究室の取組みを一般的な読者や日本語史研究者が直接的に活用できるようにするにはどういうことが考えられるか展望が述べられたあと、このような研究が可能になったのは、テキスト資源として整備されてきたからだということであり、今後さらに日本語史資料の自然言語処理技術の発展を目指すためには、さらなるデータ整備が必要であることが強調された。
ディスカッションでは、多岐にわたる話題が論じられたが、古宮氏が ChatGPT の衝撃について問われ、ChatGPT 3.5は自然言語処理研究者にとってとくに目新しさがない(BERT の衝撃をこそ語っていて、理解できるところである)と述べたことは、まさにキラーアプリケーションの問題として難しい問題をはらんでいるように思われる。キラーアプリケーションといえば、小木曽氏から、この10年の変化として、「やりたいことができるようになってきた」という感慨が述べられたのも、まさに小木曽氏がリーダーシップを取って心血を注いできたところの日本語歴史コーパスがキラーアプリケーション化してきたことを意味するのだろう。しかし、同時に小木曽氏が述べたように、日本語歴史コーパスがあまりに完結した存在であるために、構築者と利用者の断絶がいよいよ広がってしまっていることへの危惧も深く、予算減のなかで今後大規模な拡充が期待しかねるなかで、日本語史研究者コミュニティとコーパス維持との関わり合い方はかなり問題になっていくだろう(それは、日本語歴史コーパスが一貫性のために切り落とさざるを得なかった部分(それには、稿者の専門とする文字も含まれるのだが)を対象とする研究者との難しい関係をさらに浮き彫りにする可能性はある)。好きな研究をしていれば学術に貢献できる(ように思えた)時代はすでに終り、学界の維持というあまり見栄えのしないことと、内から湧き出る興味関心の追求の両立をいよいよ組織的に考えねばならないのだろうと思う(そうして学界と職場とに研究者は身が引き裂かれるのであるが……)。
長くなったが、最後に、Sli.do というリアルタイム質問共有サービスも活用されており、そのなかの質問で、「大規模データをどう活用していくか、途方に暮れている」といったものがあった。たしかに、そのまま受け止めようにも、従来の目視と抜き書きによる研究からは太刀打ちできないデータ量となりつつある。それは必然的に、どのように手に負える範囲にダウンサイジングしていくかという方法の模索以外にはあるべくもないことが示されている。しかしながら、大規模データそのものが手許にあればさまざまな手法があるのは承知の上で、現実的には日本語歴史コーパスにしても国立国会図書館デジタルコレクションにしても、データ「セット」として直接提供されていない。図書館系データベースで近時よく用いられるファセット検索は、それを補う対話的ダウンサイジングの手段のひとつのはずであったが、いまのところうまく機能をしていない(それこそAIが働いていないからだろう)。これは、「AI の民主化」なる、意味ありげなものよりも、データの圧縮(可視化ではない)のほうがはるかに「民主化」されるべきということを示してはいないだろうか。それが、人類知へと繫がるデータをわれわれが手にする唯一の手段なのだから。
なお、このシンポジウムは YouTube でも配信され、録画が公開中である(一部配信の不具合あり)。
日本語学会2023年度春季大会・式典・シンポジウム - YouTube https://www.youtube.com/watch?v=6UE-vDgdF94。
予稿集はプログラムページで公開されている。
日本語学会2023年度春季大会プログラム | 日本語学会 https://www.jpling.gr.jp/taikai/2023a/2023a_program/。
北﨑勇帆 (Kitazaki Yuho) - 情報技術と大規模テキスト資源がひらく日本語史研究(コメント) - 講演・口頭発表等 - researchmap https://researchmap.jp/ufo/presentations/42344987。
《連載》「欧州・中東デジタル・ヒューマニティーズ動向」第59回
「世界の諸言語の文法類型地図データベース・Grambank の誕生:WALS との違いについて」
Grambank[1]は、世界中の言語の文法的特徴を記録したデータベースである。このデータベースは、多様な言語の多様な文法に焦点を当てることによって、その重要性を示している。このプロジェクトは、ライプツィヒのマックス・プランク進化人類学研究所とネイメーヘンのマックス・プランク心理言語学研究所を中心に、オーストラリア国立大学、ハーヴァード大学、SOAS(ロンドン大学東洋アフリカ研究学院)、ウプサラ大学などの欧米の様々な大学や研究プロジェクト、研究者が参加している国際的な共同研究によって運営されている。
Grambank が主眼を置いているのは言語類型論である。言語類型論とは、世界の諸言語の構造に関する普遍性とバリエーションを解明する言語学の分野である。Grambank は言語類型論のデータを提供している。2023年5月19日現在、Grambank には、2,467の言語が含まれており、語順や動詞の時制、名詞の複数形など195の特徴(feature)にわたる幅広い文法現象を捉えることができる。これらの特徴は言語構造の様々な項目に関するものである。例えば「主語-述語-目的語の語順」や「後置定冠詞があるか」などである。Grambank は、これらの特徴を二値化(yes/no)または多値化(yes/no/maybe/other など)して符号化し、各言語に値を割り当てている。Grambank のデータは、オンラインで公開されており、誰でも自由にアクセスすることができる。Grambank は、言語類型論において普遍性や相関性を発見するために有用なツールであるとともに、個別言語や地域ごとの文法的多様性を示すためにも役立つ。
Grambank は、Glottobank[2]という研究コンソーシアムの一部であり、レキシコンのデータベースである Lexibank[3]、形態論的変化を集めた Parabank、数詞のデータを集めた Numeralbank、音韻変化のデータを集めた Phonobank などの姉妹データベースプロジェクトが進行中である。このうち2023年5月19日現在、データが公開されているのは、Grambank と Lexibank である。
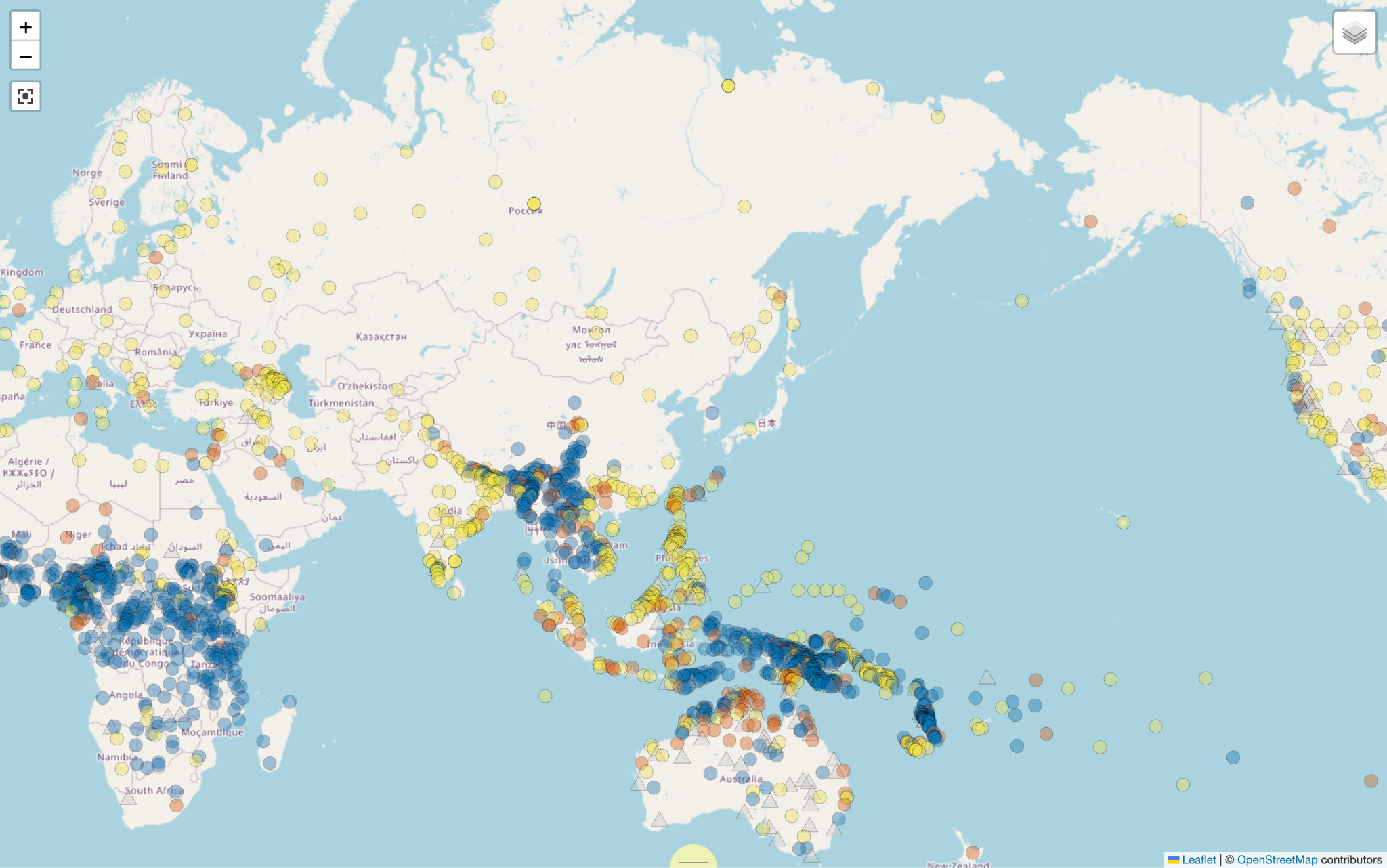
例えば、図1は Grambank による「数詞が名詞を修飾するときの、数詞と名詞の語順」の地図である。ここでは、黄色い丸は「常に数詞が名詞に先行する」ことを、青い丸は「常に数詞が名詞に後行する」ことを、オレンジの丸は「数詞が名詞に先行することもあれば後行することもある」ことを、灰色の三角は不明であることを意味している。
Grambank は、リリースされた当初、マックス・プランク進化人類学研究所が作成した World Atlas of Language Structures(WALS)[5]との比較がよくなされ、WALS よりもデータが多いことから WALS の上位互換であるという認識が広まったが、実際はそうとも言い切れない。確かに、Grambank と WALS は、両方とも、マックス・プランク進化人類学研究所が関わり、Cross Linguistic Linked Data(CLLD)[6]をウェブプラットフォームとして用いながら、世界の言語の構造的な特徴を分類し、地図上に示した言語類型論のデータベースである。しかし、両者にはいくつかの違いがある。
WALS とは、世界の言語の音韻的・文法的・語彙的特徴を、参照文法などの言語記述資料から収集したデータベースである。WALS は、55名の言語学者によって作成された。WALS の最初の版は、2005年にオックスフォード大学出版局から本と CD-ROM として出版された。2008年4月には、インターネット上で第2版が公開された 。WALS の特徴は、2〜28の異なる値を持ち、地図上では異なる色や形で示される。
これに対し、Grambank は2022年に公開されたばかりの新しいデータベースであり、WALS は2005年に初版が出版されたものである。したがって、Grambank は WALS よりも最新のデータを含んでいる。次に、2023年5月19日現在、Grambank は195個の特徴項目を持ち、WALS は192個の特徴項目を持っている。Grambank の特徴項目は、ほとんどが二値的なものであり、形態統語論に焦点を当てている。WALS の特徴項目は、多値的なものも多く含み、音韻論や語彙論などもカバーしている。
さらに、Grambank は約3,000言語のデータを目指しており、現在は2,467言語のデータを収録している。WALS は2,662言語のデータを収録しているが、各特徴項目については平均400言語程度のデータしかない。また、WALS とは異なり、Grambank は言語類型論だけでなく、言語変化や言語接触などの歴史的な研究にも役立つことを目指しており、Lexibank や Parabank など他のデータベースと連携している。
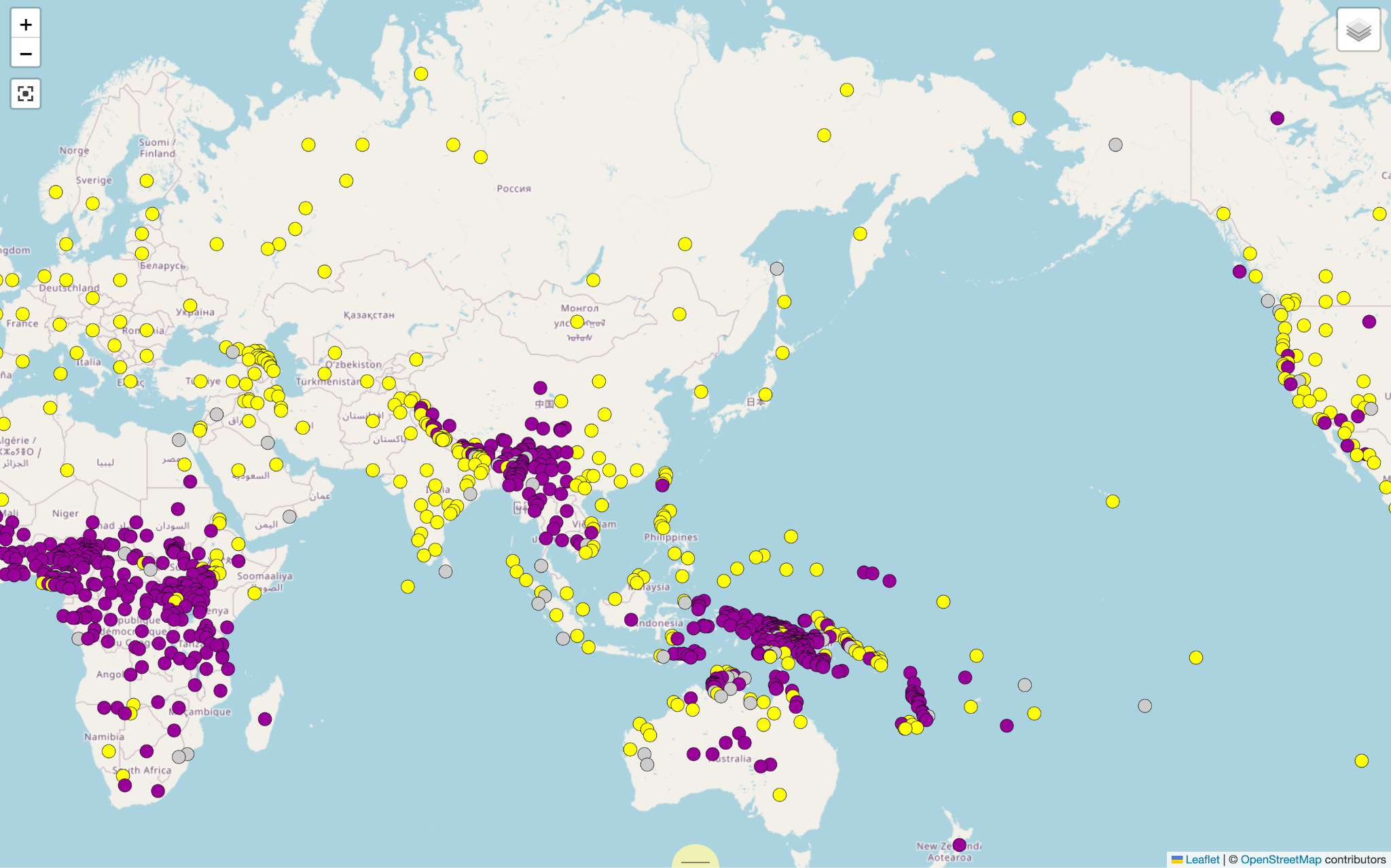
図2は、図1と同様、数詞と名詞の語順の類型の文法を WALS で示したものである。黄色の丸は、数詞が名詞に先行し、紫の丸は数詞が名詞に後行し、灰色の丸はどちらもありうる、そして、図2の範囲に表示できていないが、ブラジルにある2言語のみ「数詞は動詞だけを修飾する」という白い丸がある。図1と図2を比べると、Grambank の方が WALS よりも収録している言語数が多いことがわかる。
以上が Grambank と WALS の主な違いである。両者はそれぞれ異なる目的や方法で作成されたデータベースであるが、両者とも言語類型論研究において有用な情報源となっている。
両者は CLLD を用いて作成されている。CLLD とは、分散されたリソースの統合メカニズムとして Linked Open Data の原則を用いて相互運用可能なデータ公開構造を開発・管理するプロジェクトである。その哲学は、WALS や WOLD(世界借用語データベース)[8]などの個別のデータベースを小規模な努力で公開することを可能にし、公開物間で統一されたユーザー体験を促進することにある。このアプローチは様々な語彙・文法データベースの公開に適用されている。例えば、Dictionaria[9]は、CLLD フレームワーク上で動作しており、複数の辞書を公開している。言語データを言語に固有にリンクするためには、各言語や各方言に対して言語コードが必要である。この言語コードはすべての言語、語族、方言のカタログを目指している Glottolog[10]にて CLLD を用いて提供されている。
最近、Grambank には新しいデータが追加され、世界各地の少数民族の言語など、さらに多数の言語がカバーされるようになった。これらのデータを使って、言語学者は地理的広がりや文化的交流、歴史的変遷を調査し、言語の発展や変化の要因を明らかにすることができる。また、言語間の類似性や相互影響を分析することによって、言語学の理論的知見が深まることが期待される。Grambank やその他の Glottobank プロジェクトは、言語学だけでなく、人類学や考古学との学際的研究にも重要な情報源となるであろう。例えば、言語の変遷や拡散に関する研究は、人類の移動や文化交流、技術革新の歴史を解明する上で重要な手がかりを提供している。このような国際的な共同研究プロジェクトは言語多様性の理解を深めるための重要な取り組みである。
- コメントを投稿するにはログインしてください