人文情報学月報第118号
ISSN 2189-1621 / 2011年8月27日創刊
目次
- 《巻頭言》「人文学者のキャリア形成におけるデジタル技術習得の意義」
:広島大学大学院人間社会科学研究科・株式会社アカリク - 《連載》「Digital Japanese Studies 寸見」第74回
「『国立国会図書館七十年記念館史』および「ビジョン2021–2025:国立国会図書館のデジタルシフト」が公開」
:北海学園大学人文学部 - 《連載》「欧州・中東デジタル・ヒューマニティーズ動向」第35回
「ウェブブラウザ上で使用可能な、歴史的文献資料の自動デジタル翻刻アプリケーション:Transkribus Lite と OCR4all」
:京都大学大学院文学研究科附属文化遺産学・人文知連携センター - 人文情報学イベント関連カレンダー
- 編集後記
《巻頭言》「人文学者のキャリア形成におけるデジタル技術習得の意義」
ご存知の通り、人文学の学位を修め、そのまま自分の専門分野で不自由なく食べていける人は限られています。特に人文学系で専門性が直結するというのは大学教員や学芸員などアカデミアの仕事が想定されるでしょうから、そもそもの採用枠が足りていません。斯く言う私自身も大学や大学院で向き合ってきた「エジプト学」や「言語学」から離れたキャリア支援の領域で仕事をしてきました。
大学院を後にしてから研究者や大学院生のキャリア支援業務に携わる中で常々感じているのは、デジタル・ヒューマニティーズが日本でも隆盛する一方で、人文学とデジタル技術の距離はまだまだ遠いということです。狭義の「人文学」に絞ってみると、全体としてはデジタル技術の活用というのは、文献調査でのインターネットを利用する、資料や原稿をクラウド上にバックアップする、シンプルな目録としてのデータベースを作成するといった程度に留まっているのではないでしょうか。
広義の人文学で考えると、心理学や経済学のように実験や数値計算が行われる分野では自然とデジタル技術を駆使する方向へと進み、統計解析でプログラミング言語を利用するのは当たり前のことになっています。実際に私もキャリアアドバイザーとして社会科学系の修士や博士をデータサイエンティストとして送り出してきました。ただ、その全員がいわゆる開発エンジニアのようなスキルや経験を持っているわけではありませんでした。
2000年代に入り「データサイエンス」が日本でも流行り始め、当初はデータサイエンスを行うためのシステム開発やデータベース構築を担うエンジニアの需要が大きく供給が追いついていませんでした。次第に便利なツールが充実したことで、データを活用するための分析や提案を担えるデータサイエンティストの需要が高まりました。つまり、データを定量的に解析するだけでなく、その結果の価値や意義を定性的な分析も交えて実際にビジネスの現場に役立つよう整えることが求められるようになっています。その際に「人文知」とも呼ばれる知識やそこに連なる多角的な観点が重要となってくるのです。
ちなみに最近では医学・薬学を含む理工系分野で「ELSI」(Ethical, Legal and Social Implications)という概念が広まっています。これは「倫理的・法制度的・社会的課題」を認識あるいは予見しながら研究開発を推進するという試みです。こういった人文学的な観点を取り入れた理工学的な探求というのは、学問本来の姿への回帰なのかもしれません。
日本の人文学がデジタル化された研究データの利活用において諸外国に遅れを取っていることは以前から指摘されている事実で[1]、データサイエンスを活用する研究は今後の主流として推進されていくでしょう。大学院生や若手研究者はこの新たな潮流を逃さないように、意識的に技術や道具を取り入れて、理工系と相互に補完し合う観点を持つことが必要となっていきます。人文学には、諸学で行われる各分野内での「分析による説明」だけでなく、分野を越えて社会に発信するための「総合による理解」という特性があります[2]。研究活動を通じてデータを扱う経験を持つ人文学の研究者は、情報を翻訳して文脈に合わせて価値を伝えるというデータサイエンティストの仕事との相性が良いのです。
キャリア支援を行う側にいる人間としては、人文学の研究者にこそデータサイエンスを使ってほしいと思います。技術習得や知識獲得では遅れをとってしまうものの、技術を活用する経験は今からでも積むことができます。具体的な困難や課題を解決するという経験によって自分に何ができるのかを客観的に判断できるようにすることは、アカデミアにおいて応募できるポストを増やすためにも大切ですが、産業界での雇用可能性を高めるためにも重要な観点です。
科学技術・学術政策研究所(NISTEP)の『博士人材追跡調査』においても、大学院博士課程修了までに涵養してきた(1)論理性や批判的思考力、(2)自ら課題を発見し設定する力、(3)データ処理・活用能力が、実際の仕事で役立っているという結果が出ています[3]。これらは研究分野を問わず共通するもので、さらに言えば産業界においてもメインプレイヤーに求められる能力です。デジタル技術を「使う」能力さえ伸ばすことができれば、人文学研究者のキャリアは必ずしも悲観的なものではありません。
私の大学院時代の恩師が仰っていた言葉を借りると、これからの人文学研究者は「透明なタコツボ」を目指すべきなのでしょう。遠くにあると思われていた分野から人文学へと歩み寄り始めている今こそ、より広い世界と繋がり、新たな人文知の価値を組み立てていくタイミングなのだと思います。従来どおり研究者として自らの専門知を研鑽するため内向きで濃密な議論をしつつ、他分野や社会の動向にも関心を持ち、新たな環境や道具を使いこなす意識を持つことが肝要なのだと、私はそう思います。
執筆者プロフィール
《連載》「Digital Japanese Studies 寸見」第74回
「『国立国会図書館七十年記念館史』および「ビジョン2021–2025:国立国会図書館のデジタルシフト」が公開」
国立国会図書館から、2021年3月31日に『国立国会図書館七十年記念館史』(以下『70年史』)[1][2]、また2021年4月1日に「ビジョン2021–2025:国立国会図書館のデジタルシフト」(以下「デジタルシフト」)が公開された[3][4]。まず、『70年史』は、『国立国会図書館五十年史』(国立国会図書館、1999–2001)が開館からの50年をまとめたのを引継ぎ、1998年から2018年までの20年間をまとめたものである。『国立国会図書館五十年史』にあった資料編はいまのところ欠くが、刊行計画は示されていない。ついで、「デジタルシフト」は、2021年から2025年までの5か年についてのビジョンを示すものである。
まず『70年史』について見ておきたい。言うまでもなく、国立国会図書館は、日本の中央図書館であり、この300ページに迫る厚みは、業務を網羅したものではないと凡例に断られてはいるが、同館の活動範囲の広さを表すものであって、それをすべて紹介することはできないが、自身が国立国会図書館と言われて思い描くものの狭さに気づかされた。
本連載のテーマと関係のあるところを中心に取り上げるが(編纂者の思う読ませどころを紹介するものではない)、いちおう章と節の構成を示しておこう。序章では「国会サービス」「資料の収集」「庁舎・書庫建設」「利用者サービス」「図書館協力と書誌情報共有」と同館の業務が概観される。第1章「国会活動を支える、発信する」では、「国会サービスの20年」「立法府のブレーン」「議員のための情報センター―情報基盤の環境整備」「国会と国民とをつなぐ役割―国会発生情報の発信」と、国会関係の業務について詳説される。第2章「収集対象の拡大」では、「電子媒体の収集」「この20年間の蔵書構築」「電子図書館の蔵書構築と媒体変換」について触れられ、同館におけるデジタル収集の推進と従来からの紙資料収集との兼ね合いなどについても知ることができる。また、マイクロ(フィルム・フィッシュ)資料のデジタル変換については、国立国会図書館デジタルライブラリー利用者からも不評の声を聞くので、その存在意義を知るうえでも一読の価値があろう。また、WARP 事業や歴音の開始、Google Books への対応なども興味深いトピックである。第3章「利用者サービスの変革」では、「総論」(NDL-OPAC から国会図書館オンラインへの移行を含む)「遠隔サービス」「来館サービス」など、コロナ禍下にますます注目を集めるサービス群に触れられている。「近代デジタルライブラリー」にはじまるデジタル資料提供についても本章で論じられる。それとはべつに来館サービスの変遷も、今期前半に同館のお世話になりはじめた稿者からしても懐かしいものの移り変わりが述べられている。第4章「関西館」では「関西館の設立」「関西館のあゆみ」「関西館の機能強化」と、とくにデジタル機能のおおくを担う関西館のあゆみが記されており、やはり一読の価値がある。第5章「国際子ども図書館」は「国際子ども図書館の誕生」「国際子ども図書館のサービスのあゆみ」「電子図書館と国際子ども図書館」「国際子ども図書館のリニューアル」と、旧上野図書館建造物を受け継ぐ国際子ども図書館とデジタルサービスの関係など、興味深い。第6章「図書館協力」では、「国立国会図書館における図書館協力について」「総合目録事業」「レファレンス協同データベース事業」「調査研究事業」「図書館員向けの研修」「障害者サービス」「国際協力」と重要な事業について触れられている。本連載でも大きくおかげを被っている「カレントアウェアネス」について触れられるのもこの章である。第7章「行政・司法の支部図書館」では、「中央省庁等改革に伴う支部図書館の再編」「情報基盤の整備と電子情報の進展」「支部図書館制度の運営」「『びぶろす』の電子的提供」と、官庁図書館としての同館の一面が述べられ、国家公務員以外にははじめて知る側面もおおいものと思われる。『びぶろす』の位置がここにあるのも、同館からすれば当然であろうが、稿者には新鮮だった。補章として「組織運営」があり、「活動評価制度の導入と使命・役割の再確認」「外部委託の拡大」「組織改編」「システム構築」と、昨今の中央官庁の抱える困難とそれを奇貨とした取組みが述べられている。各章には節ごとの参照文献が明示されているほか、巻末には充実した索引が備わる。また、紹介できなかったがコラムもさまざまなトピックが取り上げられており目次を見るだけで楽しい。
とはいえ、あくまで印刷されなかった紙の本だなという印象は受ける。横長のタイムラインはあるが、これくらいは紙の本でも予算さえかければ対応できるものであるし、PDF ビューワーで見たばあいの使い勝手も落ちている。デジタルライブラリーから配信されているという点では電子出版かもしれないが、デジタル媒体として編成はされていないといえるだろう。Adobe Acrobat のアクセシビリティチェック機能を使って検証するかぎりでは、アクセシビリティについてもとくだんの配慮は見られない。また、資料編が予告もされていないのは気にかかる。業務を網羅したものではないから不要という判断かもしれないが、関係審議会の委員の一覧など、資料とすべきものはあるはずであり、心配である。
ついで、「デジタルシフト」は、そのようなこれまでを踏まえて、今後の重点的取組みを宣言するものである。あらたな取組みとして「情報資源と知的資源をつなぐ7つの重点事業」、ミッションの基盤である「国立国会図書館の基本的役割」の二本立てとなっている。「情報資源と知的資源をつなぐ7つの重点事業」では、さらに、「ユニバーサルアクセスの実現」と「国のデジタル情報基盤の拡充」を挙げ、前者に4項目、後者に3項目を設定してある。短文の説明が各項目をクリックすると見られる。ここで、「国立国会図書館の基本的役割」が挙げられていることも、重要であろう。ここで各項目を逐一掲げはしないが、同館の意義をノートパソコン一画面ほどの大きさに収めてあり、ぜひ公共系機関がこの手のものを作るときにまねをしてほしいものである。
ビジョンとしては、『70年史』でもとくに取り上げられていたような内容を今後も継続するというもので、いわゆる目新しさはなく、環境に恵まれているという感想をあるいは持つかもしれない。とはいえ、このようなメッセージは、そこで働く人々に対して守るべき価値と、切り開いていくべき局面を示すものだから、「恵まれていてよい」というようなことではなく、自分自身のお守りとして心の糧にすべきものなのである。このビジョンを盾に予算も取れなければ、ここにあることしかしないということが許されるわけでもない。そういう意味で、空文化はしうるが、よりどころとして反照される間はそうはならないというのがこういったものの効用であろう。『70年史』と「デジタルシフト」が一日を隔てて公にされた意義はまことに大きいものと思われるのである。
(付記)
《連載》「欧州・中東デジタル・ヒューマニティーズ動向」第35回
「ウェブブラウザ上で使用可能な、歴史的文献資料の自動デジタル翻刻アプリケーション:Transkribus Lite と OCR4all」
現在、ヨーロッパでは、深層学習(deep learning)を用いた、人文学資料のために OCR(optical character recognition:光学文字認識)、あるいは、HTR(handwritten text recognition:手書きテクスト認識)をなす複数のプログラムの開発が進展している。その中でも、特に、文字列を打ちこんで操作する CUI(character user interface)ではなく、カーソルを動かしボタンを押すなどして視覚的に操作する GUI(graphical user interface)を持つ OCR/HTR プログラムが増えてきている。今回は、その中でもブラウザ上で動かすことができる、オーストリアのインスブルック大学を中心に開発されている Transkribus Lite[1]と、ドイツのヴュルツブルク大学を中心に開発されている OCR4all[2]を紹介する。
まず、まだ OCR や HTR を知らない方のために、基本用語の説明から入る。OCR とは、光学文字認識の略であり、紙に印刷された、もしくは書かれた文字をスキャンして得られた文字の画像を、プログラムを使って、読み取り(認識し)、符号化されたデジタルな文字、通常であれば Unicode を出力する技術を指す。OCR にはコンピュータやワードプロセッサでプリントされた文書や、活版印刷で印刷された文書など、文字が均質な(タイプセットされた)文書の文字をデジタル化していくものもあれば、古代の写本など、人が手で書いた文書の文字をデジタル化するものも射程に入る。前者の印刷された文字の場合、欧州の諸言語なら ABBYY FineReader[3]、日本語なら「読取革命」[4]や「e.Typist」[5]、様々な言語に対応した Acrobat Pro[6]の OCR 機能など、市販されている OCR ソフトがある。しかしながら、これらの市販の OCR ソフトウェアは、現在流通しているフォントには対応しているが、文献学者や歴史学者が扱う古いフォントや古い字体の文書には対応していないことが通常である。ABBYY などは、ラテン語などいくつかの歴史的な言語にも対応しているものの、コプト語や古ジャワ語など歴史的な文献言語の多くには対応していない。
このような観点から、歴史的な文献を扱うデジタル人文学者の場合、まず、その文献の文字をデジタル化する必要があるが、それをすべて手入力で行うには相当な時間と労力がいる[7]。そのため、OCR を用いて、まず機械に認識させたあと、人間が機械のエラーを修正していくというプロセスが最も時間と労力が少なく高品質なデジタル翻刻が行えるものであると思われる。
この利点は、手書き文書の場合も同様である。古代・中世の写本、近代の歴史的人物のノートなどの手書き文書の場合、対応できる市販の OCR ソフトはほとんどないが、ヨーロッパでは今回紹介する Transkribus、日本語のくずし字では人文学オープンデータ共同利用センター(CODH)の KuroNet など[8]、優れたプログラムの開発が世界各地で進行している。手書き文書の場合は、OCR よりも、行認識やレイアウト認識、文字の方向認識などが複雑になるため、それらの認識が高い精度で行えるプログラムが求められる。ヨーロッパでは、手書き文字 OCR だけではなく、行・レイアウト・方向など写本や手書き文書をより効率的に高い精度で認識しデジタル化できるようにする技術のことを特別に Handwritten Text Recognition、略して HTR と呼んでいる。
HTR として最も成功しているソフトウェアとしては、本連載でも何度も取り上げた Transkribus がある[9]。Transkribus は元々無料であったが、2020年の11月号で取り上げたように、2020年10月に一部課金制になった。しかしながら、新規ユーザには500クレジット[10]が付与されている。また、博士論文で Transkribus を活用する学生や、Transkribus を授業で教育のために用いる教育者は、申請すれば、無料で使用することができる。
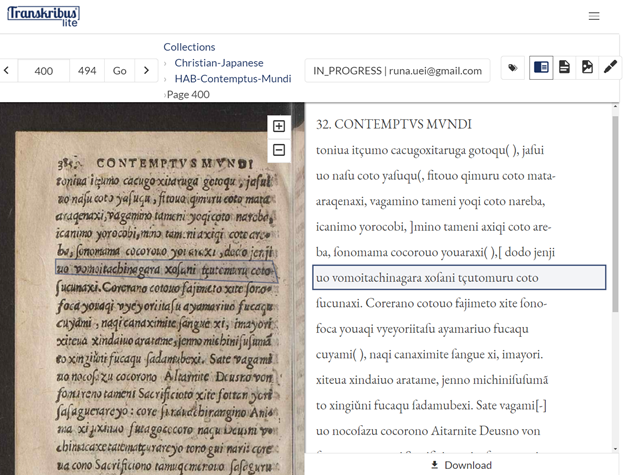
さて、この Transkribus であるが、課金化に加えて、Transkribus Lite というブラウザ上で動く Transkribus が開発されており、近頃はそれが十分に使えるレベルになっていることを感じている。図1は、筆者が、日本語文献学者でボーフム大学日本語・日本文学科教授のスヱン・オースタカンプ氏[11]と共同で Transkribus をトレーニングさせ、作成したモデルで OCR 処理を行った、後期中世日本語で書かれたローマ字キリシタン資料である『コンテムツスムンヂ』のいわゆる HAB 本を Transkribus Lite で表示させた画面である[12]。現時点の機能としては、ローカル版で行い、クラウド上に保存された文字認識のエラーの修正がここでできるが、HTR を独自にトレーニングしたり、新しく文書を HTR したりするのはローカル版でしかできないようである。
この Transkribus に対抗しようとしているものは、ヴュルツブルク大学の OCR4all とパリの PSL 大学の eScripta が開発している eScriptorium[13]である。eScripta のほうはまだ開発段階で、ユーザガイドなどが充実していない。OCR4all は最近、パッケージ化やユーザガイド作成などがなされ、徐々にユーザにとって使いやすいものになってきている。ちなみに、OCR4all は OCR エンジンには Tensorflow を用いた calamari、eScripta は本連載でも何度か紹介した kraken を用いている。
現在、東京大学の大向一輝氏と人文情報学研究所の永崎研宣氏を中心とする東京大学デジタルヒューマニティーズ勉強会、通称 UTDH 勉強会では、知識グラフ勉強会や3D 勉強会など、トピック毎に特化した分科勉強会が存在する。その中の一つに多言語テキスト勉強会があり、筆者が幹事をさせてもらっている[14]。2021年5月1日に行われた第一回目では、OCR4all のインストールおよび行認識までを勉強会のメンバーとともに行った。OCR4all は、将来は、すべてウェブベースとなり、ブラウザのみで使用可能になるそうだが、現状は、VirtualBox か Docker を通してしか利用できない[15]。VirtualBox を用いた場合、仮想マシン上で OCR4all が内蔵された Ubuntu を起動させたあと、ローカルマシン上でブラウザを用いて、VirtualBox を通して稼働している OCR4all にアクセスし、作業をしていく流れである。この時、ローカルマシン上の使用フォルダをうまく設定しておかないと、OCR4all に認識させたいファイルが読み込めないことになってしまうので、注意が必要である[16]。
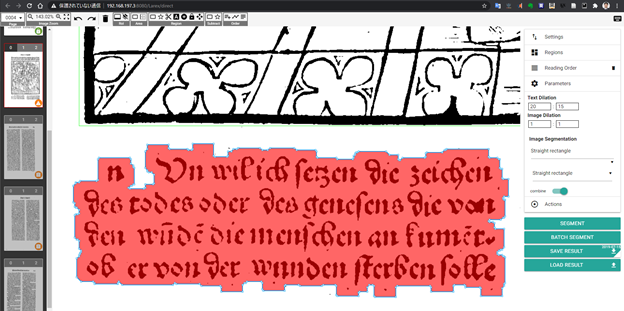
筆者らはテストデータとして付いてきた近世のドイツ語の書籍の写真の前処理、ノイズの除去、行・レイアウト・書字方向の認識などのセグメンテーションまで行った。前処理では、カラーで撮られた写真を白黒にバイナライズしたり、歪みを補正したりを自動で行い、ノイズ除去では、ごみやほこりやインクのこぼれなどのノイズを自動で除去した。そのあとのセグメンテーションは HTR の要であるが、LAREX というヴュルツブルク大学の Christian Reul 氏が開発したプログラムによってなされている。段落や行を認識するのだが、斜めや縦方向に行が書かれている場合も認識可能である。セグメンテーションが終われば、文字が書かれているブロックの範囲、行のベースライン、挿絵の範囲などが様々な色で表示される(図2)。誤っている箇所があれば、それぞれの範囲の枠線を構成する小さな点をドラッグすることで、範囲を変更できる。
次回の多言語テキスト勉強会では、OCR4all で、Ground Truth と呼ばれるトレーニングデータを翻刻し、それをもとに OCR4all の深層学習系 OCR エンジンである calamari をトレーニングさせるところまで行く予定である。本連載でもその結果を報告したい。
人文情報学イベント関連カレンダー
【2021年6月】
-
2021-06-03 (Thu)
TEI勉強会 『校異源氏物語』編於・オンライン -
2021-06-7 (Mon)
日本デジタル・ヒューマニティーズ学会年次学術大会(JADH2021)発表申し込み締切り於・オンライン -
2021-06-12 (Sat)
第4回関西デジタルヒストリー研究会「KH Coder を使った歴史研究実践」於・オンライン -
2021-06-12 (Sat)
日本近世文学会 2021春季大会シンポジウム「デジタル時代の和本リテラシー:古典文学研究と教育の未来」於・オンライン -
2021-06-17 (Thu)
TEIガイドライン翻訳会於・オンライン -
2021-06-19 (Sat)~2021-06-20 (Sun)
アート・ドキュメンテーション学会 第32回(2021)年次大会於・オンライン -
2021-07-01 (Thu)
TEI勉強会 『校異源氏物語』編於・オンライン
Digital Humanities Events カレンダー共同編集人
◆編集後記
本メールマガジンのなかでも西洋研究関連の記事を集めて、若手研究者達が中心になって再編集した『欧米圏デジタル・ヒューマニティーズの基礎知識』が文学通信より7月に刊行される運びになりました。 ゲラになったものを読み直してみたところ、色々と新たな発見がありました。当時は見えていなかった文脈が今になってみると よくわかったということもありました。まとまった形になったものを、現在の状況から捉え直してみるというのもなかなか興味深いものがあります。この面白さをみなさまとも共有できればと 思っております。
(永崎研宣)
- コメントを投稿するにはログインしてください