人文情報学月報第165号
ISSN 2189-1621 / 2011年08月27日創刊
目次
- 《巻頭言》「Humanitext Planetarium:古典文献に基づく革新的な星空解説の構築」
:名古屋大学デジタル人文社会科学研究推進センター - 《連載》「欧州・中東デジタル・ヒューマニティーズ動向」第81回
「Digital Giza プロジェクト:エジプト・ギザ台地の大ピラミッド遺跡群の3D モデルと考古資料のデジタル・アーカイブ」
:筑波大学人文社会系 - 《連載》「英米文学と DH」第4回
「データの準備」
:中央大学国際情報学部 - 人文情報学イベント関連カレンダー
- 編集後記
《巻頭言》「Humanitext Planetarium:古典文献に基づく革新的な星空解説の構築」
2024年10月、「プラネタリウムでの星空解説の際に、ギリシア神話と星の話が語られますが、その内容は古典文献に依拠しておらず、一般に流布した言説を元に解説されてしまうことが多いと感じています。これをなんとかできないでしょうか?たとえば任意の星座について、その説明はもちろんのこと、どの文献のどこにその記述があるというのがわかるようになれば、西洋古典学的に正しい情報が伝わるようになるのではないかと思うのですが」という相談を博士課程の学生さんから受けました。この時既に、同僚でギリシア哲学がご専門の岩田直也先生は Humanitext Antiqua(以下 Humanitext)を公開されており、その中に星空に関連する西洋古典文献を追加すればよいのではないだろうか?という趣旨でした。
ところが、星空に関する西洋古典文献を Humanitext の中に組み込むというのは、簡単ではありません。なぜなら、Humanitext の中の文献は、Perseus Digital Library(以下 Perseus)で公開されているテクストデータを LLM に取り込んでいるので回答が生成できますが、科学史関連の西洋古典文献は Perseus に入っていないことが多く、すぐに使えるテクストデータ自体がないからです。つまり、これまでとは異なるアプローチが必要になります。
どうするのかを考え、発想の転換をすることにしました。幸い、西洋古典分野の科学史関連の著作の校訂自体は古くから行われており、中には版権が既に切れたものもあります。これらを利用すればよいのではないか、と思ったのです。ただ、校訂本を PDF にして OCR にかけ、テクストデータを作成するにしても、最終チェックは人の目が必要になります。さらに、一人で確認すると間違いを見逃すこともあるため、二人で確認作業をする方が望ましいでしょう。それには、作業にあたる人員が複数名必要になります。
幸い、私が勤務する名古屋大学文学部・人文学研究科西洋古典学研究室には、当時14名ほどの学部生・大学院生が在籍しており、ギリシア語・ラテン語で書かれた作品を日頃から読んでいます。彼らに協力を仰ぐとよいのではないか?と考え、数名の学生さんに声をかけたところ、是非やりたいとのことでした。彼らの特別な技能への対価を支払う必要がありますので、名古屋大学の学内助成金である未来社会創造プロジェクト(若手アカデミア組成)に、岩田先生と友人で電波天文学者の佐野栄俊先生の三人で応募しました。プロジェクトのタイトルは「古典文献に基づく革新的な星空解説の構築」。西洋古典籍中の天文学や星に関する作品をテクスト化し、古代における天文学や星の知見を正確に提供し、プラネタリウムでの解説の精度を上げることを目指しました。
プロジェクトに応募した当初は、エラトステネスによる『カタステリスモイ』(前3世紀)、ヒュギヌスの『天文詩』(前1世紀)、マニリウスの『アストロノミカ』(後1世紀)の三作品をテクストデータ化することを目標にしました。これらの作品の版権が切れた校訂本の PDF は入手していたこともあり、助成金の採択後の1月中旬からからテクストを OCR にかけ、生成されたテクストデータを原典と比較して、誤りがあれば修正していく作業を学生さん4名に進めてもらいました。しかし、既存のギリシア語・ラテン語の OCR アプリやソフトウェアの精度が高くなく、かなりの内容を手直ししてもらわなければならないということが、作業開始一週間で判明しました。
この事態をどう打開できるでしょうか?と岩田先生に月曜日のランチタイムにご相談したところ(名古屋大学デジタル人文社会科学研究推進センターでは、月曜日のお昼時に希望者が集まってご飯を食べており、研究の話から研究とは特段関係のない話までざっくばらんにお話します)、即座に Humanitext OCR のプロトタイプを作成され、その後も改良を重ねられました。2025年4月にリリースされた Humanitext OCR(https://ocr.humanitext.ai/)は、2025年1月に作られたものをベースにしつつ、機能をより充実させた OCR で、古典ギリシア語やラテン語の場合、99%の精度で PDF や画像データを元にテクストデータ化することができます。
岩田先生の OCR のおかげで、天文や星に関する西洋古典籍のテクストデータ化の速度は各段に上がりました。また忘れてはならないのは、春休みで時間的余裕があり、なおかつ「卒業する前に、大学生だからこそできることをやりたい」という意欲的な学生たちのおかげでどんどんテクストの確認作業が進んだということです。助成金に応募した時点では三作品が目標でしたが、最終的にはアキレウス『断片』、アウィエヌス『アラテア』、ゲルマニクス『アラテア』、ニギディウス・フィグルス『断片』、ヒッパルコス『エウドクソス』とアラトス『エウドクソスとアラトスの「パイノメナ」註解』もテクストデータ化と、ダブル・チェックを終えることができました。現在これらの作品は、Humanitext 内の「Planetarium」というジャンルの中に収められています。
2025年2月21日には、成果を発表し、Humanitext Planetarium のお披露目するためのワークショップ、「古典文献に基づく革新的な星空解説の構築をめざして」を実施しました。ワークショップでは、最初の相談をされ、プロジェクトを牽引した小島敦さん、京都大学大学院文学研究科助教で『アストロノミカ』を翻訳された竹下哲文先生、明石市立天文科学館館長の井上毅先生にご講演いただき、多くの西洋古典学および、天文学・プラネタリウム関係者、星座が好きな方々にもご参加いただきました。
一人の大学院生さんの相談から始まった本プロジェクト。まだ加えるべき西洋古典籍はありますが、古代地中海世界における天文学や星に関心がある万人が、何か疑問に思ったときに聞くことができるものになったかと思います。研究協力者の先生方はもちろんのこと、プロジェクトの影の立役者である川村瑠美さん、小島敦さん、嶋﨑矢さん、安岡涼さん、四名の労に感謝し、筆を擱きたいと思います。
執筆者プロフィール
《連載》「欧州・中東デジタル・ヒューマニティーズ動向」第81回
「Digital Giza プロジェクト:エジプト・ギザ台地の大ピラミッド遺跡群の3D モデルと考古資料のデジタル・アーカイブ」
デジタル人文学の潮流に乗り、エジプト学においてもデジタル技術を駆使した新しい試みが注目されている。その代表的な事例がハーバード大学が主導する Digital Giza プロジェクト[1]である。本プロジェクトは、UNESCO の世界文化遺産「メンフィスとその墓地遺跡—ギザからダハシュールまでのピラミッド地帯」を構成する遺跡のうち、エジプト・ギザ台地のピラミッド群とその周辺の墓地や集落に関する膨大な考古学的記録をデジタル化し、体系的に統合・公開する非営利の国際的イニシアチブである。
プロジェクトの歴史と目的
Digital Giza の前身は、2000年から2011年にかけてボストン美術館で実施された「Giza Archives Project」である[2]。このプロジェクトは、アンドリュー・W・メロン財団の支援を受け、ハーバード大学=ボストン美術館合同調査隊が1902年~1947年に行ったギザ発掘調査の全記録(写真乾板、発掘日誌、遺物記録など)をデジタル化しオンラインで無料公開した画期的な試みであった。
その後、2011年に活動拠点をハーバード大学に移し、Digital Giza として再編されると、世界各地の博物館や研究機関が所蔵する資料へと対象を広げ、ギザ遺跡に関する多様なアーカイブデータを単一プラットフォームで統合・公開することを目標としている。これにより、150年以上にわたるギザ調査の歴史において蓄積された膨大な資料が、初めて体系的に整理され、共有されるようになった。
デジタル・アーカイブの構築
プロジェクトの中心となるデータベースが、Giza Consolidated Archaeological Reference Database(GizaCARD)である[3]。GizaCARD には1800年代の初期調査から最新の発掘調査に至るまで、世界中の機関から集められた15万件を超えるファイルや記録が収録されている。
これらの資料は、単にアーカイブ化されるだけではなく、各遺跡、出土遺物、文書記録、写真、図面、3D モデルなどが意味的に関連付けられ、統合的にアクセス可能な形で整理されている。この関連付けにより、例えばある特定の墓を検索すると、その墓の平面図、発掘時の写真、出土遺物の記録、発掘者の日記の該当部分、最新の3D モデルといった多様な情報に一度にアクセスすることが可能になる。
GizaCARD に収録されているデータ種別は多岐にわたり、ピラミッドや墓などの建造物情報、出土遺物のカタログ、地図や平面図、発掘写真、考古学者のフィールド日記や調査ノート、遺物写真、3D グラフィックモデル、出版物や未公開原稿、書簡、梱包リスト、360度パノラマ写真など、ギザに関するあらゆる記録が含まれている。Digital Giza のウェブサイトはこのデータベースからリアルタイムで情報を取得しており、常に最新の研究成果が反映されている。
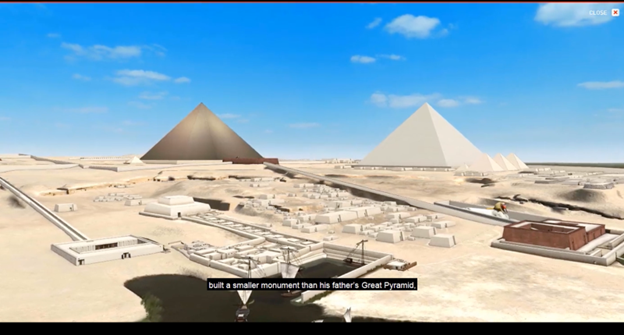
3D 技術による仮想復元
Digital Giza プロジェクトの最大の特徴は、高度なデジタル技術による遺跡の3D 仮想復元(Giza 3D)である[4]。この仮想環境は、現在のギザ台地と遺跡の3D モデルを提供するだけでなく、過去の様々な時代の景観や建造物を学術的根拠に基づいて精密に再構築している。この取り組みには、最新の測量データと歴史的資料が活用されており、考古学者とウェブ・エンジニアとの緊密な連携が不可欠である。

これまでに約20のピラミッドや墓などの遺跡が詳細にモデル化され、将来的にはその他の数百の遺跡についても同様の3D 再現が予定されている。モデル化の対象には、クフ王、カフラー王、メンカウラー王の各ピラミッドとその附属神殿群、大スフィンクスとスフィンクス神殿、ヘテプヘレス王妃の墓、メルエスアンク三世王妃の墓など、ギザを代表する重要遺構が含まれる。
Giza 3D 環境はウェブブラウザを介して誰でも自由に利用でき、ギザ台地を仮想的に散策することが可能である。利用者は時代ごとの景観を切り替えたり、通常は立ち入りが制限されている墓の内部に入室し、関連資料を閲覧することもできる。また、VR(仮想現実)や AR(拡張現実)技術の応用、3D スキャンによる遺物の立体復元や3D プリントなど、遺跡を多角的に体験するための新しい取り組みも進められている。こうしたインタラクティブな技術は、エジプト学研究の新しい手法としても重要視されている。
教育リソースと国際連携
教育普及の面でも Digital Giza プロジェクトの貢献は顕著である。プロジェクトは「Giza @ School」[5]というウェブ・セクションを通じて、古代エジプトの日常生活、ピラミッド建設、宗教観などのテーマに関する教育リソースを提供している。これらの教材は、ビジュアル教材、専門用語集、インタラクティブな映像教材を含み、世界中の学校で古代エジプトについて学ぶ貴重な教材となっている。
多機関連携も Digital Giza プロジェクトの重要な特徴である。現在、ハーバード大学(米国)、ボストン美術館(米国)、エジプト考古学博物館(通称・カイロ博物館;エジプト)、大エジプト博物館(エジプト)、ベルリン・エジプト博物二人での確認作業をする方が望ましいでしょう。館(ドイツ)、ウィーン美術史美術館(オーストリア)、トリノ・エジプト博物館(イタリア)、ペンシルバニア大学考古学人類学博物館(米国)をはじめとする世界各地の機関がパートナーとして参加している。これら機関の所蔵するギザ関連資料をデジタル的に統合することで、従来は物理的・制度的な制約から困難であった包括的研究が可能になっている[7]。
プロジェクトの意義と展望
Digital Giza プロジェクトは、デジタル人文学の視点から見て、以下のような重要な意義を持つ。
第一に、アーカイブの民主化である。過去には一部の専門家しかアクセスできなかった貴重なギザ台地の考古学的記録が、Digital Giza によってオンラインで誰でも利用可能になった。これにより、研究の透明性と多様性が高まり、新たな視点からの解釈や発見が促進されている。
第二に、データの相互連携である。個々の記録を単に公開するだけでなく、それらを意味的に連携させることで、より豊かな文脈情報を提供し、新たな研究洞察の可能性を広げている。これは、デジタル・アーカイブにおける有機的なデータ統合のモデルとなっている。
第三に、没入型体験の提供である。3D モデリングとバーチャル・リアリティ技術を活用することで、物理的にはアクセスできない古代の環境を「体験」することが可能になっている。これは考古学の成果を広く伝達する新しい方法として注目されている。
第四に、文化遺産のデジタル保存である。物理的な遺跡が時間の経過や環境条件、観光圧力によって損なわれる可能性がある中で、3D を中心とするデジタル記録とモデルは、技術的には、これらの重要な文化遺産の永続的な記録として機能する。
最後に、学際的研究の促進である。考古学者、エジプト学者、建築史家、デジタル人文学者、ウェブ・エンジニアなど、様々な分野の専門家が同じデータセットを共有し、協力することで、新たなアプローチと発見が可能になっている。
以上のように、Digital Giza プロジェクトは、デジタル技術が単なる情報管理ツール以上のものとなり、考古学的知識の創出、解釈、共有、そして体験の方法を変革する可能性を大いに示している。今後も技術の進化とともに、このプロジェクトはギザのピラミッドとその周辺遺跡に関する理解を深め、世界中の人々がこの著名な文化遺産にオンラインでアクセスし、歴史を探求する方法を示し続けるだろう。
《連載》「英米文学と DH」第4回
「データの準備」
データカプセルと書籍データ
前回の連載では、ハティトラスト・リサーチセンター(以下 HTRC)が提供する仮想マシンのデータ分析サービスである、データカプセルの概要について述べた[1]。今回は書籍データの概要とデータカプセルの操作について述べたい。前回、データカプセルをセキュアモードに変更するとハティトラストの書籍データを利用できることを述べた。データカプセルには HTRC Workset Toolkit という名の書籍データを操作するコマンド( htrc )が用意されている[2]。ターミナル上で動かすシェルのコマンドである。Volume ID と呼ばれるハティトラストで使われる ID をデータとして与えてダウンロードすることが多いだろう。
例えば、ディケンズの『デイヴィッド・コパフィールド』という書籍をダウンロードしたいとする[3]。ターミナル上で、htrc download -o /media/secure_volume/myworkset/ uiuo.ark:/13960/t2v40nz4t と入力して実行すると(図1)、myworkset という名前のフォルダーに書籍データがダウンロードされる。ここで htrc は HTRC Workset Toolkit のコマンド名、-o と /media/secure_volume/myworkset/ の二つは出力先のフォルダーの指定である。uiuo.ark:/13960/t2v40nz4t は個別の書籍データに紐づけられた Volume ID であり、『デイヴィッド・コパフィールド』を指している。ダウンロード先のフォルダーを開くと、Volume ID の名前のフォルダーがあり、さらにその中にテクストファイルが1000件ほどあることが確認できる。これは、書籍1ページごとの書籍データである。
書籍データの概要
先ほどの例をまとめると、書籍データはデータカプセル上で図2のように管理される。書籍データは HTRC Workset Toolkit を介してダウンロードされる。どの書籍データをダウンロードするかは、Volume ID や URL、メタデータなどの一意の ID のリスト(一件でもよい)で指定する。コマンドが実行されると、ID ごとにフォルダーが作成され、ページごとのテクストデータが入る。このテクストデータは OCR で機械的にデジタル化され、本文以外の表紙や奥付、白紙のページ、ページ番号や章タイトルなどの欄外の情報も含まれる。なおファイルをページごとではなく一冊ごとにしたり、ヘッダーやフッターの欄外情報を除くオプションもある(それぞれ-c、-hf)[2]。
分析を行う際には、ID ごとのフォルダーに入った、ページごとまたは書籍ごとに分かれたファイルを分析していくことになる。この際、OCR エラーや、除いていない場合は欄外等の本文外の情報が含まれることに留意する必要がある。
データカプセル自体の操作と留意点
ここで、データカプセル自体の具体的な操作方法に触れておく。データカプセルはブラウザ上で操作する。データカプセルを起動させるには、まず HTRC のウェブサイトを開き[1]、Sign in ボタンを押してサインインし、その後上部タブから、「Tools」―「My Data Allocations」と選び、個人に割り当てられたデータカプセル自体の情報を表示させる。その中の先に申請して作成したプロジェクト名をクリックして、プロジェクトの概要ページを開く。このプロジェクトの概要ページから、データカプセルの設定や接続、分析結果のダウンロードを行う(図3)。
操作項目のうち大事なものについて述べる。緑の Start Capsule ボタン(青の Stop Capsule と切り替え)は、データカプセル自体の起動、終了のボタンである。Start Capsule ボタンが表示されデータカプセルが未起動状態のとき、Update Resources ボタンが表示される。ここで CPU やメモリ、ハードディスクの容量を変更できる。Start Capsule ボタンを押してデータカプセルを起動したら、Connect via Remote Desktop ボタンを押してデータカプセルに接続できる。ウインドウズのような GUI 環境である。
図4はデータカプセルの画面の表示例である。プロジェクト名の下に現在のモード(セキュアモードまたはメンテナンスモード)が表示される。右側の青いボタンでモードを切り替えることができる。
データカプセルを使う上で四点ほど留意点がある。一点目は、データカプセルは基本的に起動したままである。Stop Capsule のボタンを押した場合もしくは明示的にシャットダウンした場合のみ停止する。つまり、時間のかかる作業をする場合ブラウザを閉じてよいし、自分の使うローカルのPCもシャットダウンしてよい。二点目は、何らかのエラーが生じた場合、HTRC を一度ログアウトし、再ログインして接続し直すとよい。三点目は、キーマッピングの問題から一部のキー(コロン「:」やパイプライン「|」)は入力できないため、オンスクリーンキーボードから入力するとよい(「設定」-「ユニバーサルアクセス」-「タイピング」-「オンスクリーンキーボード」を1にする)。四点目は、自分のローカルPCとデータカプセルの間でコピーペーストなどはできないことである。
次回は書籍データのリストの作成方法について述べたい。
人文情報学イベント関連カレンダー
【2025年5月】
-
2025-5-1 (Thu), 6 (Wed), 15 (Thu), 20 (Wed), 29 (Thu)
TEI 研究会於・オンライン -
2025-5-17 (Sat)
第138回人文科学とコンピュータ研究発表会於・慶應義塾大学三田キャンパス -
2025-5-31 (Sat) ~ 2025-6-1 (Sun)
情報知識学会 第33回(2025年度)年次大会於・筑波大学筑波キャンパス中地区 -
2025-5-31 (Sat)
日本出版学会2025年総会・春季研究発表会https://www.shuppan.jp/event/2025/04/15/3310/
於・専修大学神田キャンパス
【2025年6月】
-
2025-6-3(Wed), 12 (Thu), 17 (Wed), 26 (Thu)
TEI 研究会於・オンライン
【2025年7月】
-
2025-7-1 (Wed), 10 (Thu), 15 (Wed), 24 (Thu), 29 (Wed)
TEI 研究会於・オンライン -
2025-7-20 (Sun) ~ 2025-7-22 (Tue)
DHEAC: Annual International conference on digital humanities for East Asia Classics於・Beijing Library
Digital Humanities Events カレンダー共同編集人
◆編集後記
2025年度は、デジタル・ヒューマニティーズ(DH)に関わる科学研究費の大規模プロジェクトが新たに二つ始まったようです。一つは学術変革領域研究(A)「歴史情報学の創成」、もう一つは、特別推進研究「デジタル研究基盤としての令和大蔵経の編纂―次世代人文学の研究基盤構築モデルの提示」です。いずれも科学研究費助成事業のなかでは非常に大規模なもので、前者は人文系で2件、後者は人文社会科学系を通じて1件しか選ばれていないというもので、人文系を代表するような大規模研究助成事業において DH に深くコミットするものが2件も採択されるというのは、まさに DH を発展させる貴重な機会になっていると言えるでしょう。2024年度に始まった基盤研究(S)「史料データセンシングに基づく日本列島記憶継承モデルの確立」や、文部科学省委託事業「人文学・社会科学の DX 化に向けた研究開発推進事業」等に加えて、さらに大きな動きが始まったという形になります。
一方で、こうした研究から生み出される研究データが、昨今のオープンサイエンスやオープンデータといった動向とどのようにつながり、どのようなオープンサイエンス的な成果を再生産していけるのか、ということも気になるところです。それに関しては学術情報流通関係者との協力関係を期待したいところです。生成 AI の発展と普及で、人文学の今後が様々な形で問い直される場面が増えてきていますが、そのような状況だからこそ、DH に本格的に参入しようと思っている方々にとってはよい機会が各地で提供されることになりそうな気がします。今後が楽しみですね。
- コメントを投稿するにはログインしてください