人文情報学月報第88号【後編】
ISSN 2189-1621 / 2011年8月27日創刊
目次
【前編】
- 《巻頭言》「人文情報学による100年前の落穂ひろい」
:広島大学総合科学部 - 《連載》「Digital Japanese Studies寸見」第44回
「デジタル・コレクションを定位する」
:国文学研究資料館古典籍共同研究事業センター - 《連載》「欧州・中東デジタル・ヒューマニティーズ動向」第8回
「ボドマー・コレクションが写本のオンライン・データベースを公開/ハンブルク大学が写本学のエクスツェレンツクラスター(ドイツ研究振興協会)を開設へ」
:ゲッティンゲン大学
【中編】
- 《連載》「東アジア研究と DH を学ぶ」第8回
「図書館総合展フォーラム「東アジア図書館とデジタルアーカイブ」」
:関西大学アジア・オープン・リサーチセンター - 《連載》「Tokyo DigitalHistory」第7回
「『1641 Depositions』データベースとデータ可視化」
: 東京大学大学院人文社会系研究科/日本学術振興会
【後編】
- 人文情報学イベントカレンダー
- 特別寄稿「書簡資料のデータ構造化と共有に関する国際的な研究動向:TEI2018書簡資料WSを通じて」
:キングスカレッジロンドン/東京大学大学院人文社会系研究科 - 編集後記
人文情報学イベント関連カレンダー
【2018年12月】
-
2018-12-01 (Sat)〜2018-12-02 (Sun):
じんもんこん2018於・東京都/東京大学地震研究所 -
2018-12-12 (Wed):
Galeシンポジウム2018「デジタル人文学への誘い」於・東京国際フォーラム ホールDhttp://gale.cengage.jp/content/news/Galeシンポジウム2018「デジタル人文学への誘い」開催/
-
2018-12-15 (Sat)〜2018-12-16 (Sun):
NINJAL シンポジウム「データに基づく日本語研究」於・東京都/東京証券会館https://www.ninjal.ac.jp/event/specialists/project-meeting/m-2018/20181215-sympo/
-
2018-12-18 (Tue)〜2018-12-21 (Fri):
9th International Conference of Digital Archives and DigitalHumanities (DADH2018) “Facing the Era of AI+DH”於・台湾/Dharma Drum Institute of Liberal Arts -
2018-12-19 (Wed):
第56回 [特別編]国際ARCセミナー「カリフォルニア大学バークレー校所蔵日本コレクションを取り巻く国際コラボレーションの展開」於・京都府/立命館大学アート・リサーチセンター2F 多目的ルーム
【2019年2月】
-
2019-02-16 (Sat):
第119回 人文科学とコンピュータ研究会発表会於・大阪府/大阪大学豊中キャンパス
Digital Humanities Events カレンダー共同編集人
特別寄稿「書簡資料のデータ構造化と共有に関する国際的な研究動向:TEI2018書簡資料WSを通じて」
本稿は、2018年9月中旬に東京で開催された第18回 Text Encoding Initiative(以下、TEI)年次国際大会のイベントレポートとして、書簡資料のデータ構造化と共有に向けた Correspondence Description の取り組みに焦点を絞って、国際的な研究動向を紹介したい。近年、歴史研究において「書簡」は、コミュニケーションの媒体としての意味や効力、文化・社会的背景や様式論など、幅広い議論の射程を持つ研究対象として注目されている[1]。人文情報学の観点からは、本論で紹介するように、書簡にまつわる人物・日付・地理情報などのデータを構造的に管理し、コミュニケーションの履歴を視覚的に把握できるような取り組みが行われてきた。本稿は、書簡資料にまつわるデータ構築に焦点を絞るが、ここでの記述が歴史学および人文情報学研究者の間の分野横断的な研究プロジェクトを進める際の参考になれば幸いである。
本論の構成は、(1)タグセット開発の経緯とタグの解説、(2)書簡メタデータをめぐるデジタル・エコシステム、(3)書簡資料の相互運用可能なメタデータファイルの機械的生成のためのツール、である。
1 タグセット開発の経緯とタグの解説[2]
1.1 先行事例
書簡および書簡群をTEIで構造化するプロジェクトは長きにわたって存在してきたが、プロジェクトごとに異なる独自スキーマやガイドラインが提供されていた。例えば、1990年代にサウス・カロライナ大学で始まった先駆的なプロジェクト The Model Editions Partnership[3]、2000年代におけるプロジェクトとして Digital Archive of Letters in Flanders[4]や Carl Maria von Weber ― Collected Works[5]、フィンセント・ファン・ゴッホの書簡について原文と翻訳文の対照が可能な Van Gogh The Letters[6]などがある。進行中のプロジェクトもいくつか存在しており[7]、マークアップの対象としての書簡資料への関心の高さが窺える。
書簡資料をTEIマークアップなどにより構造化することで、キーワード検索に加え、人名・地名の索引などを提供するようなインタフェースを開発することが可能である。このようなインタフェースの例としては、オクスフォード大学ボドリアン図書館の Early Modern Letters Online(EMLO)[8]や、ヴィクトリア大学図書館の Colonial Despatches[9]のほか、書簡資料のマークアップに関するオンラインフォーラムとしても機能する correspSearch[10]が挙げられる。発展的なデータ活用事例として、書簡資料のやりとりを通して人的結合関係などを把握するためにデータを可視化することもよく見られる。例えば、啓蒙期ヨーロッパにおける学者の交流を描くスタンフォード大学 Humanities + Design ラボの Mapping the Republic of Letters[11]、イースター蜂起期における書簡のクラウドソーシング翻刻プロジェクトから発展してきたメイヌース大学(アイルランド)のLetters of 1916[12]、テキサス入植で知られる Stephen Austin の書簡を中心的に扱った Digital Austin Papers[13]をはじめ、さまざまなプロジェクトがある[14]。
1.2 <correspDesc> の開発に向けて
これまで挙げたような先行事例に基づいて、「TEIでどのように書簡をマークアップするべきか」、「校訂した書簡がどのようにリンクし合えるか」というリサーチ・クエスチョンを掲げ、2008年に TEI コンソーシアム内に Correspondence SIG(Special Interest Group)が設置された[15]。彼らは、書簡資料の TEI マークアップの方法論を開発するにあたって、書簡を構成する要素として「物質性」と「イベント性」を重視した。このうち物質性に関しては、TEI P5ガイドラインの10章「手稿資料の記述(Manuscript Description)[16]のタグセットを用いて書簡資料のマークアップを行うことが可能だとしている。
次にイベント性に関しては、コミュニケーションの形態という側面に注目し、人・組織/日付/場所/前後のやり取りを表現できるようなタグセットの開発が必要だと考えられた。彼らの活動の成果として結実したものが、2015年4月に TEI P5ガイドラインVer 2.8.0にて実装された <correspDesc> タグセットである[17]。一連のタグセットは、この書簡コミュニケーションにおける「イベント性」を記述することが目的である。したがって、書簡に関する「物質性」と「イベント性」に関する情報を包括的に記述するなら、<msDesc> と <correspDesc> の組み合わせが必要だということになる。
1.3 タグセットの解説
本節では、図1に示すように、簡単に <correspDesc> タグセットの解説をしたい。まず <correspDesc> は、<teiHeader> 内におけるメタデータ記述の一部として記述され、親要素として<profileDesc>[18]を持つ。子要素として、<correspAction>[19]と<correspContext>[20]を持つ。前者の <correspAction> は、@type 属性の値(sent; received; transmitted; redirected; forwarded)によって、人物が書簡のやり取りにどのように関わったのかを記述できる。後者の <correspContext> では、<ref> エレメント内の @type 属性の値(prev, next)と、(図1には示されていないが)@target 属性の値に URI を記述することによるID参照を通じて、当該書簡の前後の文脈を記述することができる。

2 書簡メタデータをめぐるデジタル・エコシステム
前章で述べたように、書簡資料のメタデータを記述するためのタグセットが開発されるに至ったが、書簡資料に関するデータを相互運用可能な形で記述することによって、どのような利点が得られるのだろうか。この問い自体は、書簡資料に限らず、人文学資料のデジタル校訂版を作成するにあたって、マークアップ規則が厳しいと指摘されることのある TEI を採用することの妥当性を問うことにつながるだろう。
書簡資料のメタデータを <correspDesc> タグセットを用いて記述することの利点は、端的に言えばデジタル・エコシステムを生み出すことである。すなわち、独自の基準ではなく学術コミュニティ内で共有された形式でデータを構造化記述することにより、コンピュータによる処理プログラム作成のコストを減らしたり、プロジェクトの垣根を越えてデータの指し示す内容を理解しやすくしたり、他のプロジェクトでの二次利用を促しやすくすることができる[21]。書簡メタデータをめぐるデジタル・エコシステムを生み出すためのプラットフォームとして機能しているのは、冒頭でも紹介したウェブサイト correspSearch である。
correspSearch は、オープン・プラットフォーム上で共有できる書簡のメタデータを提供することを目指したシステムである。すなわち、書簡資料のデジタル校訂版からデータを集約すること、集約した書簡メタデータに基づいてプロジェクトや組織の垣根を越えてユーザが書簡データを検索できるようにすること、特定の研究関心や時空間的制約あるいはテーマ的制約に依存しないこと、基礎データを修正したり更新したりすることを容易にする標準的でオープンなシステムであること、各種自動化処理や二次利用のために、集約したデータをオープンな技術インタフェースを通して提供すること、を目指している。
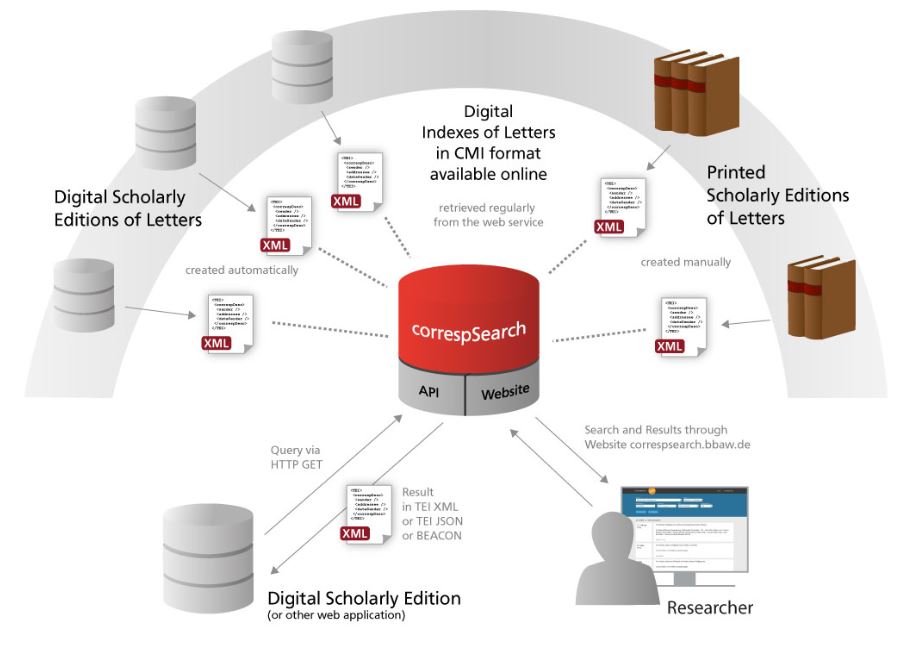
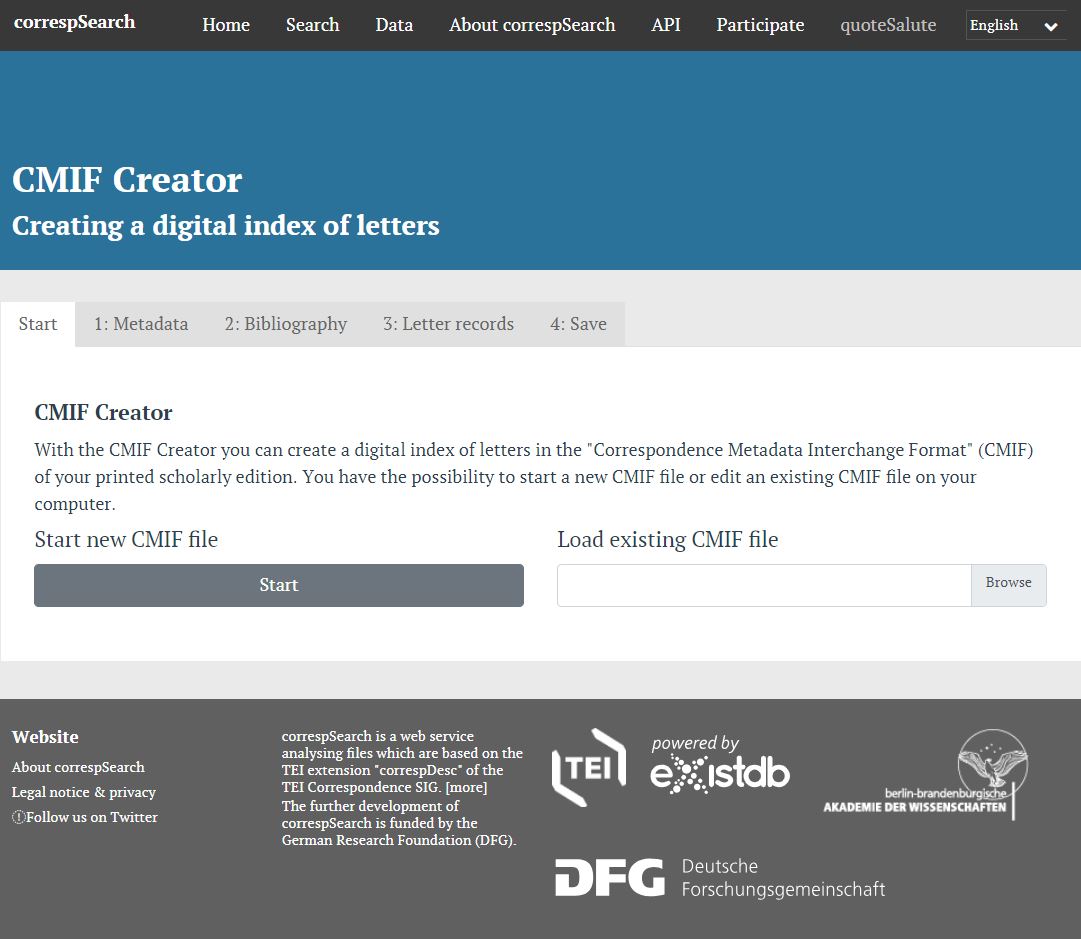
ここで言及される標準的な書簡メタデータというのは、前章で紹介した <correspDesc> の記述に基づいた CMIF(Correspondence Metadata Interchange Format)のことである。CMIF の記述対象は、書簡の本文ではなく、書簡資料のメタデータのみである。すなわち、書簡の送り手・受け手、書簡が書かれた(あるいは受け取られた)場所、あるいは書誌情報である。correspSearch では、この CMIF データを自動で生成する GUI ツール「CMIF Creator(図3参照)」を提供しているため、<correspDesc> の記法に習熟していなくとも、簡単な操作によって <correspDesc> に則って構造化された書簡資料のメタデータを取得することができる。
ここで重要なのは、correspSearch が自動生成する CMIF ファイルは、人物名・地名に関しては、各国の国立図書館などが提供する典拠ファイルに準拠するということである。現状において correspSearch は、人名については次の典拠ファイルへの外部参照データを付与することをサポートしている。すなわち、ドイツ国立図書館の GND(Gemeinsame Normdatei)[24]、フランス国立図書館の Autorités der Bibliothèque nationale de France[25]、アメリカ議会図書館の Library of Congress Authorities[26]、日本の国立国会図書館の Web NDL Authorities[27]、そして OCLC(Online Computer Library Center)が提供するバーチャル国際典拠ファイルVIAF(Virtual International Authority File)である[28]。地名については、GeoNames をサポートしている[29]。このように、マークアップテクストから離れて、外部の典拠情報のURIへのリンクを参照するということは、セマンティック・ウェブの観点からも重要であり[30]、TEIコミュニティでも長きにわたって建設的な議論が蓄積されてきた実践である[31]。correspSearch で生成され、API で提供された CMIF サンプルも公開されているので、ご関心の向きは参照されたい[32]。
3CMIF の機械的生成のためのツール
correspSearch では、GUI 操作による CMIF データの生成機能を提供しているのみだが、すでに表形式のプレーンテキストから CMIF データを自動生成してくれるツールが開発されている。この CSV2CMI ツールは、プログラミング言語 Python で開発されたオープンソースツールであり、ドイツの Saxon Academy of Sciences in Leipzig の Klaus Rettinghaus 氏によるものである[33]。CSV ファイルに書簡メタデータを記述しておくと、人名や地名に関しては correspSearch がサポートしている前述の典拠ファイルの情報と照合した上で、外部参照 URI を含めて CMIF データを出力してくれる[34]。もちろん、典拠ファイルとのリンク付けの信頼性について検討する必要はあるが、このように今では書簡資料のメタデータを簡単に生成できるようになっているため、生成された CMIF に基づいて書簡のやり取りに基づく人的結合関係の把握なども可能だろう。
4 おわりに
本稿は、TEI 2018 で行われた発表の中でも、特に書簡資料のマークアップに焦点を絞ったイベントレポートとなった。<correspDesc> タグセットの開発に至る経緯、書簡資料のメタデータをめぐるデジタル・エコシステムを生み出すプラットフォームとしての correspSearch、相互運用可能な書簡資料のメタデータファイル CMIF とその自動生成ツールについて紹介してきた。
関連事例として、個人的な研究実践で恐縮だが、書簡ネットワークの把握を試みたことがある。すなわち、筆者は2017年の第67回日本西洋史学会大会において、1860年代におけるイギリスと清朝中国との間の天津条約改正交渉にまつわるイギリス外務省内の政策決定過程について、イギリス外務省機密史料 FO 881を基に公信の送受信に基づく情報ネットワーク図を可視化したことがある[35]。データ可視化方法などについては自身のブログで公開しているが[36]、このような研究実践においても CMIF でデータ管理をしておくことが有効だったであろうと感じた。
冒頭で述べたように、書簡資料は歴史学および人文情報学の双方の分野で注目されている研究対象である。本稿が、日本でも書簡資料を対象とした TEI マークアッププロジェクトを分野横断的に進める際の参考になれば幸いである。
◆編集後記
本メルマガのイベントレポートは、Googleカレンダーを共有する形で共同編集人の方々によって情報提供されている。Googleカレンダーなので、読者のみなさまにおかれても、自分のカレンダーやサイトに組み込むこともできるので、ぜひ活用されたい。たとえば日本デジタル・ヒューマニティーズ学会では、これをサイトに組み込んで利用している。また、関連イベントは多岐にわたり、現在の編集人だけではフォローしきれないこともあり、情報を寄せていただけると大変ありがたい。
ちなみに、今週末は、国内最大級の人文情報学関連のシンポジウム、じんもんこん2018が東京大学にて開催される。お時間があればぜひご参加されたい。特に、今回は学生の参加費無料(要事前登録)となっているため、参加可能な学生諸氏はすぐにでもご登録されたい。
(永崎研宣)
- コメントを投稿するにはログインしてください