人文情報学月報第150号【後編】
ISSN 2189-1621 / 2011年08月27日創刊
目次
【前編】
- 《巻頭言》「イギリス文学の研究にデジタル・ヒューマニティーズを取り入れることの楽しさ-読みを後押しする数字」
:中央大学国際情報学部 - 《連載》「欧州・中東デジタル・ヒューマニティーズ動向」第67回
「Coptic Translator:コプト語多層タグ付きコーパス Coptic SCRIPTORIUM を学習させた英語–コプト語・コプト語–英語のニューラル機械翻訳」
:人間文化研究機構国立国語研究所研究系
【後編】
- 《特別寄稿》「歴史研究における「解釈行為」をモデル化する試み(1)」
:ROIS-DS 人文学オープンデータ共同利用センター - 《特別寄稿》「Patrick Sahle による「2. What is a Scholarly Digital Edition?」(『Digital Scholarly Editing-Theories and Practices』所収)の要約と紹介」
:早稲田大学大学院文学研究科 - 人文情報学イベント関連カレンダー
- イベントレポート「Digital Humanities Winter Days 2023:ハンブルク大学・ロマノフ先生を迎えて」
:東京外国語大学アジア・アフリカ言語文化研究所 - 編集後記
《特別寄稿》「歴史研究における「解釈行為」をモデル化する試み(1)」
デジタル・ヒストリー研究といった場合、デジタル技術を用いて何らかの具体的な歴史事象を分析するという含意がある一方で、そうした分析の基盤となる歴史研究データの整備自体も、研究活動の重要な一環とみなされる[1]。ここでいう歴史データには、資料のメタデータから地名・人名などの典拠データ、そして TEI や IIIF といった特定の形式で構造化された資料のテクスト・画像データなどが含まれる。ところで、これらのデータはいずれも何らかのデータモデルに沿って構造化されることで共有可能性や相互運用性を確保し、検証・再現が可能なデータ駆動型歴史研究の基盤として機能するということができるのであり、その意味では、歴史情報をいかに構造化するかを決定づけるデータモデルの設計・運用が、デジタル・ヒストリー研究においてはきわめて重要である[2]。
さらに、データモデルに基づく知識の構造化という営みは近年、上述のようなデータの構造化に留まらず、「解釈の形成」という歴史研究行為そのもののプロセスを構造化する方向にも進展しつつある。これは、これまでに蓄積されてきた資料や関連情報に関する研究基盤整備の動きとも接続しつつ、個々の歴史研究者がどのような資料の記述に基づき、それらをいかに関連づけることで歴史解釈を形成するのかをデータとして表現し、計算可能にしようとするものである。その意味では、単なる歴史情報の構造化ではなく、そうした歴史情報をどのように操作するのかという、より一段メタな観点からの試みであるとも言えよう。
こうした、歴史研究における解釈形成過程そのものを構造化することを志向する比較的早い時期の研究として、Historical Context Ontology(以下、HiCO)の提唱がある[3]。2015年の論文において M. Daquino と F. Tomasi は、「文化的な事物は、そのコンテキストとの関連で扱われる必要がある」と主張し、とくにその事物に関する「解釈の過程 interpretative process」というコンテキストを含めることによって、「情報量が豊かで、自己記述的で理解可能なデータ」を構築することの重要性を指摘している[4]。その上で、そうした解釈記述の対象を「出来事」「人物」「人物間の関係」という情報に限定し、これを RDF で記述するためのモデルを提案する。
HiCO の基本構造は、書誌レコード記録のために設計された概念モデルである旧 FRBR(現在は IFLA LRM に置換)に依拠しており[5]、以下の図1のように、原資料(左)の Expression をもとに作成される、刊本や翻訳、あるいは二次研究文献といった二次的資料(右)に基づいて「解釈行為 Interpretation Act」が遂行されるという基本コンセプトを有している。この原資料、すなわち原著者によるオリジナルな作品と、校訂や翻訳をもとにした二次的資料の区別は HiCO においてきわめて重要である。なぜなら、何らかの資料についての「解釈」は常に、テクストの再建や校訂、翻訳を経た二次的資料において行われるからである。このようなコンセプトは、図における InterpretationAct が、hico:isExtractedFrom プロパティによって二次的資料(図の右)の Expression を参照することで概念的に示されている。
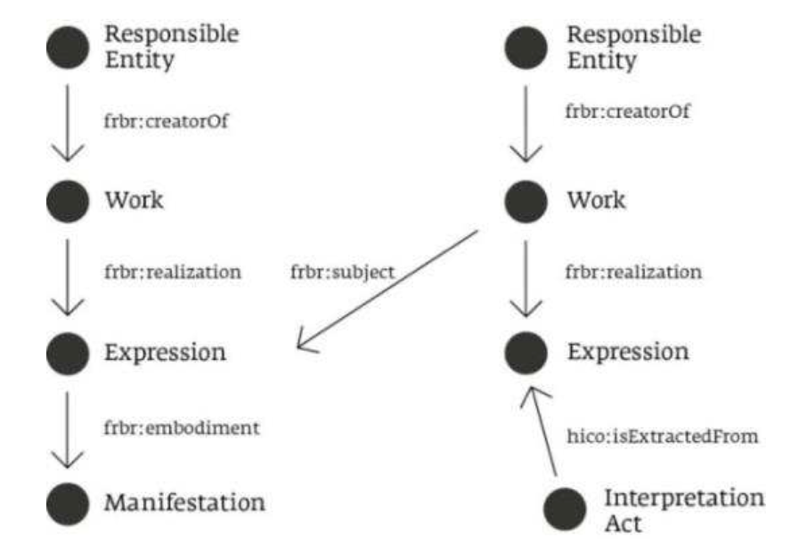
図中の IntepretationAct という概念は、HiCO オントロジーにおけるクラスとしては hico:InterpretationAct と表現されるが、このクラスは必要に応じてさらに二つのプロパティによって定義されうる。hico:hasInterpretationType と hico:hasInterpretationCriterion はそれぞれ、文献学的・歴史学的・言語学的といった解釈の種別、仮説の採用や文献参照といった解釈基準に関する情報を IntepretationAct に付与する。
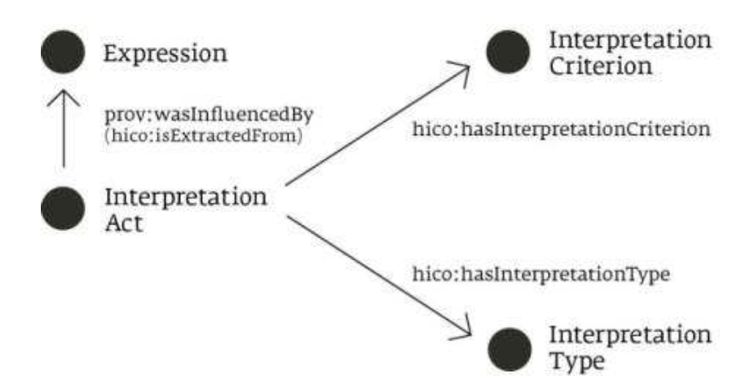
このように、HiCO における InterpretationAct という概念は、原資料に基づく二次的資料に基づきつつ、その解釈行為の種別や基準を機械可読なデータとして表現することを可能にしている。さらに HiCO では、解釈行為に関するRDFトリプルデータ記述に責任を持つ主体や解釈が行われた日時に関する記述、さらに、複数の InterpretationAct 間の関係性の記述方法も定義されている。とくに InterpretationAct 間の関係性の記述は、それによってそれぞれの解釈間にどのような支持・批判・依拠といった関係が存在するのかをデータとして明示的に表現ことができるという点で、きわめて重要である。HiCO において、こうした InterpretationAct 間の関係性の記述には CiTO オントロジーが提供するプロパティが用いられる[6]。
最後に、それぞれの InterpretationAct の内容、すなわち、解釈の対象となる種々の「出来事」「人物」「人物間の関係」といった情報をどのように記述するかにについて述べておきたい。Daquino と Tomasi の論考の中では、例として以下のような RDF データが示されている。

このデータは、ある「書簡の送付」という出来事を表現するものである。1行目のトリプルの主語は「ある時点における書簡の送付者」という特定のコンテキストを持つ「役割」を表すリソースであり、2行目には「役割」の時間情報、3行目には「役割」の保持者、4行目には関連文書、5行目には役割種別が記述されている。そして特に重要なのは最終行に記述されたトリプルの目的語であり、このリソースが HiCO における hico:InterpretationAct のインスタンスである。すなわち、1行目から5行目で記述されている「役割」に関する情報はすべて、ここで:intact-1-ft-transc-lett-1 というリソースとして記述されている解釈行為によって生成されたものである、ということになる。このように、「解釈行為」と、それによって生成される歴史知識を接続し、情報の解釈依存性をデータとして表現しうる点が HiCO の大きな利点であることが、この事例からも明らかである。
HiCO は、旧 FRBR モデルに依拠しながら、原資料と、その二次表現であり解釈の対象となる二次的資料の厳密な区別を行いつつ、そうした資料に対する「解釈行為」についてのメタな記述から、解釈の結果として生成される具体的な歴史知識までを RDF として構造化するためのオントロジーとして、きわめてシンプルでありながらも精密な概念モデルを提供している。本稿で取り上げた論文そのものは2015年のものとやや古く、オントロジーのヴァージョン更新も2020年を最後に途絶えてはいるものの[7]、そこで提案されたコンセプトそのものは現在でも十分に利用可能であり、類似の研究とも比較しつつ、必要に応じて変更や拡張を加えていくことで、「解釈行為」が非常に重要な意味を持つ歴史研究のプロセスそのもののデジタル空間における表現という課題に貢献しうるのではないだろうか。
《特別寄稿》「Patrick Sahle による「2. What is a Scholarly Digital Edition?」(『Digital Scholarly Editing-Theories and Practices』所収)の要約と紹介」
Patrick Sahle による本章は[1]『Digital Scholarly Editing』の理論篇の第1章に位置しており、そのタイトルの通り、「学術デジタル編集版 (原語 Scholarly digital edition、ここではSDEと略す)」とは何かを問い、それに答えるものである。
著者曰く、批判的編集(critical editing)―人文学の対象である様々な文化遺産を信頼できる形で再現したいという願いから発展したこの概念は独立した研究分野となり、人文学の様々な方法と関連するが故に、この分野の包括的な定義は存在しない。本章のテーマとなる SDE は、「印刷技術の限界を克服する機会を与えるものであ」り、「批判的編集の理論と方法論に根本的な影響を与えるものである」。しかし、批判的編集同様、明確な定義はない状況が続いている。本章では、著者が20年間にわたる SDE の調査の際に使用した定義を用いて議論することで、「学術編集の新たな方法論と理論の構築」に役立てることを目指す。
著者の用いた定義―「学術編集版(scholarly edition)とは、歴史的な文書を批判的に表現(representation)したものである」は次のように4つのポイントから解説される。①「表現」とは物質的な意味での対象資料の複製の作成から「テキストの新しい読みを構築すること―例えば、失われた原本や著者の意図の再構成〔…〕など―幅広い」範囲を指す。これは「対象を全体として捉えようとすることであり、さらに出版物へと形を変えることが出来る」。そして、表現は学術編集版が学術編集版たり得るために必要不可欠な要素である。②「批判的に」とは、「学問的な意図に基づいて」対象資料に関わり、「それを「開く」手助けをする全ての過程を指す」。こちらも学術編集版作成において欠くべからざる要素である。③「文書」について。「学術編集版は、テキストや作品に焦点を当ててい」る場合が多いが、中には「テキストの内容や、〔…〕作品という概念が、その学術編集版の中心ではない場合もある」。また、「物的な文書そのものが編集の関心の中心にある分野、流派、理論的なアプローチもあ」る。しかし、どの概念も基点となっているのは物理的な文書であることからこの言葉を用いている。④「歴史的」とは、現代の読者にとって「時間的な隔たり、歴史の違い」があるため、その意味するところが明らかでないことを示している。こうした対象が、批判的編集を必要とするのである。
この定義をもとに、SDE について著者は「違いは、学術編集版とSDEの間にあるというより」、印刷物かデジタルかという様な編集版がとり得る形態の違いにあると述べ、「紙の学術編集版 が〔…〕書籍の印刷に関する文化的慣習によって形成されたパラダイムに従ってきた様に、SDE はデジタルのパラダイムに従っている」ことから、印刷物の単なるデジタル化をSDEとは言わない、と主張する。SDE となるためには、多数の文書ーファクシミリやディプロマティックな転写、リーディング・バージョンなど―を読者が必要に応じて異なる見方で表現できるようにし、検索や本当のハイパーリンクなどの印刷物としては実装できない機能が必要である。よって、SDE の定義は次のように表すことが出来る。「SDE は、その理論、方法、実践においてデジタルのパラダイムに従う学術編集版である」。
著者は、デジタルのパラダイムと編集との関わりについて以下の様に簡単に説明している。まず、SDE は、「編集プロジェクトにおける編集知識の現状を表し」、頻繁に更新されることから、従来の紙の学術編集版が有した「権威ある最終声明」としての存在ではなく、永続的で可変的であり「製品ではなく、むしろ過程」として理解できる。そのため、最終的な完成形に至ることはなく、更なる資料や知識の追加へ向かい、外部との連携であるソーシャル編集版へも繋がっていくことから、「学術的な、あるいはより広い関心を持つ一般の人々のコミュニティを引きつけ」、「全ての人を潜在的な編集者」にする。次に、SDE に含まれる資料や情報にアクセスするためのブラウザや検索機能は、読者に「テキストや文書をより積極的に扱うことを求め」、最終的に「一次資料やそれに対する解釈や分析のための利用と研究成果の発表との間の境界がなくなる」。また、紙の学術編集版ではあくまでも1つのテキストが提供されていたが、SDE では複数のテキストが提供されることから、編集されたテキストは相対化される。これまでの紙の学術編集版では「編集されたテキストが最も重要な中心要素であ」ることから、「図版、書誌情報〔…〕異文」等はテキストの素材にすぎなかった。しかし、「デジタルのパラダイムでは、これが逆転し」、「編集されたテキストは、視覚的証拠から転写を経て」様々な学術的な知識を適用することで「徐々に発展していくものである」。最後に、技術的な観点からは、「電子テキストの基本概念、記述的マークアップ」等は、「シングルソースの原則と呼ばれるものに繋がっており」、1つのデータから任意の形式を選択することから、「メディア製品としての学術編集版から、モデル化された情報リソースとしての学術編集版への移行が見られる」。つまり、「真の意味での SDE は、上に述べたデジタルのパラダイムの特徴の一部または大部分を示す」。
これまでの記述は、SDE を定義する一方で、新たな問いを生み出している。例えば、SDE と DSE(Digital Scholarly Edition の略称)の違いは何か。SDE とデジタルアーカイブズはどのような関係にあるのか。どこまでを1つの SDE と考えるのか。学術編集版とは出版物なのか、それともその背後にあるデータなのか。著者は、これらの問いのいくつかについては現時点での見解を述べているが、著者も言うように「未解決の問題やさらなる考察が必要とされる」問いも残る。
結論として、著者はある対象を SDE の目録に収録することを検討する際、以下の四つの問いを投げかける。①研究対象が完全に表現されているかどうか。②批判的かどうか。③その編集版は学術的な質を具えており、一次資料に戻ることなく学術研究を可能にするかどうか。④その学術編集版はデジタルのパラダイムに従っているかどうか。これは、「デジタル時代の編集に関する1つの見解」であるが、研究対象も分野も方法もジャンルも異なる全てを尊重し「伝統と現在の変化の間に橋をかけようとするものである」。
以上、原著の表現を用いながら要約と紹介を行った。本章は、ヨーロッパにおける資料のデジタル化が、厳密な理論に基づく実践であることを示している。今後は日本においても SDE の作成が行われることが想定されるが、その際本章で論じられたような SDE の定義は実践的な指針として機能するだろう。またそのようにすることは、日本の SDE ひいては日本語資料を国際的な議論の俎上にのせることにも繋がるはずである。
人文情報学イベント関連カレンダー
【2024年2月】
-
2024-2-9 (Fri)
DH 若手の会「デジタル・ヒューマニティーズで“繋がる×広がる”人文学」https://www.nihu.jp/ja/event/20240209
於・一橋大学一橋講堂・中会議場 -
2024-2-8 (Thu), 14 (Wed), 22 (Thu), 28 (Wed)
TEI 研究会於・オンライン -
2024-2-13 (Tue)
2023年度西洋中世学会若手セミナーhttps://www.medievalstudies.jp/general/20240117/
於・東京大学本郷キャンパス -
2024-2-17 (Sat)
第134回 人文科学とコンピュータ研究発表会http://www.jinmoncom.jp/?CH134
於・オンライン
【2024年3月】
-
2024-3-7 (Thu), 13 (Wed), 21 (Thu), 27 (Wed)
TEI 研究会於・オンライン -
2024-3-15 (Fri)
DH国際シンポジウム「ビッグデータ時代の文学研究と研究基盤」於・一橋講堂(千代田区一ツ橋) -
2024-3-17 (Sun)
歴史フェス@名古屋大学https://sites.google.com/view/historyfes2024/home
於・名古屋大学東山キャンパスおよびオンライン -
2024-3-23 (Sat)
第13回「知識・芸術・文化情報学研究会」https://www.jsik.jp/?kansai20240323cfp
於・立命館大阪梅田キャンパス
【2024年4月】
-
2024-4-4 (Thu), 10 (Wed), 18 (Thu), 24 (Wed)
TEI 研究会於・オンライン
Digital Humanities Events カレンダー共同編集人
イベントレポート「Digital Humanities Winter Days 2023:ハンブルク大学・ロマノフ先生を迎えて」
去る2023年12月16日~17日、都内にて「Digital Humanities Winter Days 2023」が開催された。本ワークショップは科研費学術変革領域研究(A)「イスラーム的コネクティビティにみる信頼構築」C01(デジタルヒューマニティーズ的手法によるコネクティビティ分析)班及び早稲田大学 Chair of the State of Qatar for Islamic Area Studies(カタールチェア)の共催において、イスラーム史及びアラビア語文献研究におけるデジタル・ヒューマニティーズの世界的第一人者である、マキシム・ロマノフ先生(ハンブルク大学)を講師に迎え、ハンズオン形式でデジタル・ヒューマニティーズの手法を学ぶというものである。
本イベントに先立ち、ロマノフ先生はカタールチェアが主催した中世地中海世界をめぐる国際ワークショップ(“The Middle East and Europe, 1097–1517”、2023年12月9日~10日)に登壇されたが、その際にもデジタル・ヒューマニティーズのパネルセッションが組まれた。また、本ワークショップに院生からベテラン研究者まで、年代も研究分野も多岐にわたる参加者が集ったことも、歴史・地域研究におけるデジタル・ヒューマニティーズの盛り上がりの証左といえるだろう。
初日は講義形式で行なわれ、最新のデジタル・ヒューマニティーズの動向として、現在ロマノフ先生がリーダーを務める複数のプロジェクトが紹介された。第一は、今や中東歴史・文献研究において必須のインフラになったといっても過言ではない、アラビア語テキスト・コーパスの開発プロジェクトである KITAB(アーガー・ハーン大学)の Open ITI(Open Islamicate Texts Initiative)である。この Open ITI は西暦600年頃から1980年代に至るまで、現段階でおよそ3,330名のユニーク・オーサーによる8,468ものテキストを機械可読な形式で収録した巨大コーパスである。現在 Open ITI にアラビア語以外のテキストはないが、将来的にはペルシア語、ウルドゥー語、オスマン・トルコ語などのイスラーム圏の諸言語へと拡張するという。レクチャーでは、コーパスのメタデータがどのように組織化・構造化されているかについて丁寧な解説があった。
またこのデジタルテキストの活用方法として、ロマノフ先生の提唱する Open ITI mARkdown によるタグ付けが紹介された。Open ITI mARkdown は 現在主流であるマークアップ言語の TEI/XML と比較して大幅にシンプルであり、かつアラビア語のように、右から左へと表記する諸言語(RTL テキスト)に適合したものである。参加者からは TEI/XML 形式でのアラビア語へのタグ付けにおける困難が指摘されたが、文字列の方向に起因する煩雑さが Open ITI mARkdown ではクリアされ、TEI/XML 形式への変換も可能である。さらに現在は mARkdownMSS という写本を対象としたマークアップ方法も開発中であるという。
続いて2021年より開始したドイツ研究振興協会・エミー・ネーター・プログラムの “The Evolution of Islamic Societies (c.600–1600 CE): Algorithmic Analysis into Social History”(EIS1600)が紹介された。EIS1600の掲げるゴールの一つは、膨大な中世アラビア語史料間の関係を解明することにある。これは、後世の著者による初期の著者のテキスト利用や情報の改変を量的に分析するため、ナラティブではなく、細分化されたデータに着目するものである。具体的には、テキスト群を最小限の情報単位(MIU: minimal information unit)に分割し、概念を抽出、マイニングを行ない、固有名詞、人名、地名、日付等を識別することで、歴史記述において通底する “MasterChronicle” の構築を目標としているという。当プロジェクトでとりわけ注目を集めたのは、アラビア語テキストへの自動タグ付けである。情報の種別にもよるが、試験段階である現在でも8割から9割に近い精度で自動でのタグ付けが可能であるという。これまで精読でしか成しえないと考えられていたテキストのマークアップが自動化されれば、個人や出来事に関するメタデータの取得が極めて容易になり、テキスト分析のみならず、歴史・地域研究においても飛躍的な発展が見込まれるだろう。
初日の最後には、参加者全員に対するヒアリングを経て、共通の関心として、人々、あるいは史料間の関係性をネットワークとして表現することが浮上した。そこで二日目のハンズオン・セッションでは、まずはデジタルテキストから必要な情報を抽出するための正規表現 (regular expression) を学び、その後ネットワークを可視化するためのツールと手法について扱うこととなった。
正規表現は指定する条件と一致する複数の文字列を表示させる 文字列の集合を一つの文字列で表現することで複数の文字列を検索・置換できるようにする記法であるが、中東諸言語の場合、人名や地名の表記揺れのほか、アルファベットに転写した際の表記の幅も大きな問題となっている。同じエンティティをめぐるあらゆる表記の可能性を想定することは、テキスト分析において不可欠といえるだろう。
だがロマノフ先生によれば、正規表現を用いて出来るのは文字列の検索だけではない。 正規表現検索は、単に目当ての文字列を発見するだけでなく、検索結果、とりわけヒット数を用いて明らかにできることもあるという。たとえば、テキストを読まずとも、年代への言及が多く含まれる場合は年代記の可能性が高く、頻繁に言及される年代が分かれば、テキストの扱う時代を特定できる。また、年代や人名の言及数を示すグラフの形状によって、年代単位で記された書物(=年代記)か、アルファベット順に人名を収録した書物(=人名録)かなども判明するため、膨大なテキストを対象に、記述形式を通時的に探ることも可能である。二日目の約半分がこの正規表現のハンズオンに充てられた。
続いて、参加者の一人が16世紀のアラビア語人名録から抽出した師弟関係をめぐるデータを例に、ネットワーク分析のデモンストレーションが行なわれた。まずは参加者の作成した Excel 形式のデータをプログラムが理解できるようクリーニングする作業を行なった。具体的には文字列重複や空白を整えプログラミング言語に置き換えること、同じエンティティであることが明らかになるよう指示詞や代名詞を置き換えるなど、データをノーマライズ(正規化)することである。これにより得られたネットワークのテーブルを、まずは Obsidian を用いて可視化することになった。ノートアプリ Obsidian は、社会学者ニクラス・ルーマンが考案した、ネットワーク型の情報整理法として有名な Zettelkasten(ツェッテルカステン)をローカル環境で行なうイメージである。モノを介して人と人がつながる様子を図示でき、人々のクラスターやコネクティングパワーのあるノードが明示されるため、ネットワーク分析においても有用である。そのうえで同じデータを用い、ネットワーク可視化ツールである Gephi[1]を用いたハンズオンが行なわれた。
最後の総合ディスカッションでは、ノードに対する ID の付与、ネットワークの中心性の計算方法、正規表現で抽出したデータの分析方法などに質問が及んだ。ロマノフ先生によれば、後者についてはスクリプティングが必要であり、仮に生成AIを用いたとしても、どのようなスクリプトを記すかは指示を出さなければならない。ワークショップで扱った既存のアプリケーションは、人文社会系の研究に特化したものではないため、研究に利用するなかで不足を感じることもあるだろう。そのため、これらを用いて対応できる範囲を超える分析を行なうには、ある程度プログラミング言語にも通じている必要がある。このことは次なるステップを目指す際の障壁にもなり得るが、何らかのソリューションが生まれれば、デジタル・ヒューマニティーズの門に足を踏み入れる研究者の数は格段に増えるだろう。
本ワークショップはイスラーム史におけるデジタル・ヒューマニティーズの最前線から参加者の関心に応じたハンズオンまで、ロマノフ先生が「一日で四日分に相当する題材を扱った」とおっしゃったほど、密度の高い、大変充実した内容であった。上記のほかに、人々の越境的移動を量的に分析する al-Ṯurayyā Project、アラビア語の転写方法である Arabic BetaCode、Metadata の記法である SPOAP モデルについてもレクチャーが行なわれた。紙幅の都合上、そのすべてを紹介できないことが惜しまれる。全体を通じ、あらゆる人文情報学の手法に通暁した先生が、参加者の質問に真摯に答え、ともに最適解を探ってくださるという、極めて贅沢かつ刺激的な時間であった。ロマノフ先生及び本セミナーを企画された関係者の皆様に心から御礼を申し上げる。
◆編集後記
太田氏がレポートしてくださったワークショップには、筆者も初日だけ参加しました。講師のロマノフ氏は、かつて、専門分野は異なるものの、西洋古典データベースとして有名なペルセウス・デジタル図書館のグレゴリー・クレイン氏の下で働いたことがあり、薫陶を受けたのだそうです。ワークショップのなかでも、その図書館の活動のなかで開発された枠組みがイスラームのテキストに適用されている話もあり、デジタル・ヒューマニティーズの目指す方法論の共有地(Methodological Commons)という在り方がここでもまさに実現されていることを目の当たりにできたよい機会でした。
デジタル・ヒューマニティーズと言えば、今月半ばに、文部科学省の「人文学・社会科学のDX化に向けた研究開発推進事業」(この PDF の6頁目)に1億円の予算がついたことが公表されました。「そんな金額では何もできませんよね」と、某新聞社の文化部記者には鼻で笑われてしまったのですが、たしかに、色々な大規模デジタル化予算等にくらべたらごく小さなものではありますが、デジタル・ヒューマニティーズの成果を通じて人文学の研究基盤を支えるという、EU では10年以上前から推進されてきたことが、日本でもようやく政策として開始された、ということですので、まずその点において貴重なことだと思います。また、「国際規格対応」や「データ規格のモデルガイドライン策定」、それらを踏まえた事例の創出など、あくまでも既存の研究基盤を踏まえてその安定化を目指すということになるようですので、何かを一からすべて立ち上げるような予算を必要としている話ではなさそうです。そのようなことで、この事業で効果的に予算が使われて、我々にとって広く役立てられるような成果が生み出され、そこからさらに新たな研究が様々に生まれてくるような、そういう状況を、この事業に携わる方々が作ってくださることだろうと、大変期待しているところです。
- コメントを投稿するにはログインしてください