人文情報学月報第154号【後編】
ISSN 2189-1621 / 2011年08月27日創刊
目次
【前編】
- 《巻頭言》「人文学と情報学、そして人文情報学を学ぶことの可能性」
:九州大学大学院人文科学研究院 - 《連載》「欧州・中東デジタル・ヒューマニティーズ動向」第70回
「機械翻訳モデルの評価方法と Hugging Face Evaluate Metric」
:筑波大学人文社会系 - 《連載》「仏教学のためのデジタルツール」第18回
「ACIP」
:東京大学大学院
【後編】
- 《特別寄稿》「歴史研究における「解釈行為」をモデル化する試み(3):来歴情報記述のための PROV Ontology とその歴史解釈行為構造化への応用可能性」
:国立情報学研究所 - 人文情報学イベント関連カレンダー
- イベントレポート「DH 国際シンポジウム「ビッグデータ時代の文学研究と研究基盤」
:国文学研究資料館 - 編集後記
《特別寄稿》「歴史研究における「解釈行為」をモデル化する試み(3):来歴情報記述のための PROV Ontology とその歴史解釈行為構造化への応用可能性」
これまで2回にわたって、歴史研究における解釈行為をデータとして構造化するための手法に関する研究を取り上げてきた[1]。それを踏まえて今回は、PROV Ontology(PROV-O)というデータモデルを取り上げる[2]。PROV-O は、必ずしも歴史研究に特化したデータモデルではないが、後述のように「事物」「行為」「行為主体」の記述からなるきわめて汎用的な情報構造化モデルを提供しており、歴史解釈の構造化にも大いに資するものがある。このことは、以前に紹介した Historical Context Ontology(HiCO)においてこのモデルが一部取り入れられていることからも明らかである[3]。本稿ではまず、PROV-Oの概要についてまとめたうえで、PROV-O を応用した最新の事例研究を取り上げる。そして最後に、事例研究の内容を踏まえつつ、歴史解釈行為の構造化に PROV-O がどのように活用されうるかの見通しを述べることとしたい。
PROV-O の詳細については W3C Recommendation のページに詳しいので、そちらを参照してもらうこととし、本稿では基本的なコンセプトの部分についてのみ確認しておく。そもそも PROV-O はその名の通り、事物の来歴(provenance)に関する情報を表現し、交換可能にするための語彙を提供するためのプロジェクトである。実際に提供されるクラス・プロパティは多岐に及ぶが、PROV-O ではおそらく利用者の便宜のために、それらを3つの大カテゴリーに分類して定義している。3つの大カテゴリーとは、「起点語彙 Starting Point Terms」「拡張語彙 Expanded Terms[4]」「限定語彙 Qualified Terms[5]」である。「起点語彙」はPROV-Oの基本的な構造を表現するための最低限の語彙、「拡張語彙」は「起点語彙」+αでより詳細なクラス・プロパティ記述を行うための語彙、「限定語彙 Qualified Terms」はエンティティ間の関係性を詳細に規定・限定するための語彙を含む。ここからわかるように、すべての基盤となるのは「起点語彙」であるため、本稿ではひとまずこの「起点語彙」に限定して PROV-O の基本的な構造を示す。
上述のように、PROV-O における情報表現は「事物」「行為」「行為主体」の三者の関連を軸に行われる。三者の関連の記述の詳細は以下の図1のようになる。
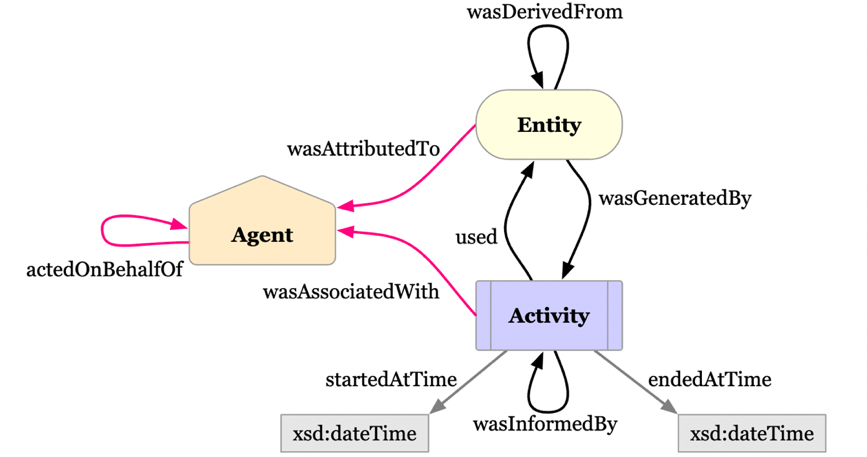
あくまで筆者の解釈ではあるが、この図を見ると情報記述の中心となるのはやはり「行為 Activity」であり、これは「事物の生成・変更を引き起こすあらゆる行為」を表す。そしてこの「行為」が何らかの「事物 Entity」(モノや概念)を「用いて used」遂行されることで、新たな「事物」が「生成される wasDerivedFrom」。そして、「事物」と「行為」は双方とも、それに関わる「主体 Agent」(人物や組織)を持つ。また、「事物」と「行為」はそれぞれ自己参照が可能であり、ある事物の「事物」の生成・変化のもとになった他の「事物」、ある「行為」に影響を与えた他の「行為」といった情報も記述することができる。これが PROV-O の基本コンセプトである。全体としてみれば、「行為」を中心として、その「行為」にインプット、あるいはアウトプットされる「事物」を記述することで、その来歴を記述するというのが PROV-O の基本構造といえよう。
この PROV-O を参照しつつ、データ・キュレーションのプロセス構造化のためのモデル設計を行う研究が国立情報学研究所のチームによって行われている[7]。この研究の背景には、近年のオープンサイエンスの動向の中で、解釈性と再利用性を備えた研究データの蓄積・共有がますます重要になっていること、そうした解釈性と再利用性を研究データに付与する活動としてのデータ・キュレーションのプロセス構造化のための枠組み設計の意義が高まっていることがあるという。こうした背景のもと研究チームは、生命科学・地球科学・社会科学といった諸分野において共有されているデータ・キュレーションの工程、そこで用いられる語彙のサーベイを通して共通項を抽出し、オントロジーを設計している。このオントロジーについて詳細に述べることはここではできないが、基本的には、データの評価やデータ処理といった「行為」を中心として、それに何らかのデータやファイルを入力として与えると、処理されたデータが出力されるというプロセスの連なりとしてデータが記述できるようなモデルになっている。実際のデータ記述の一例は、以下のようになる。
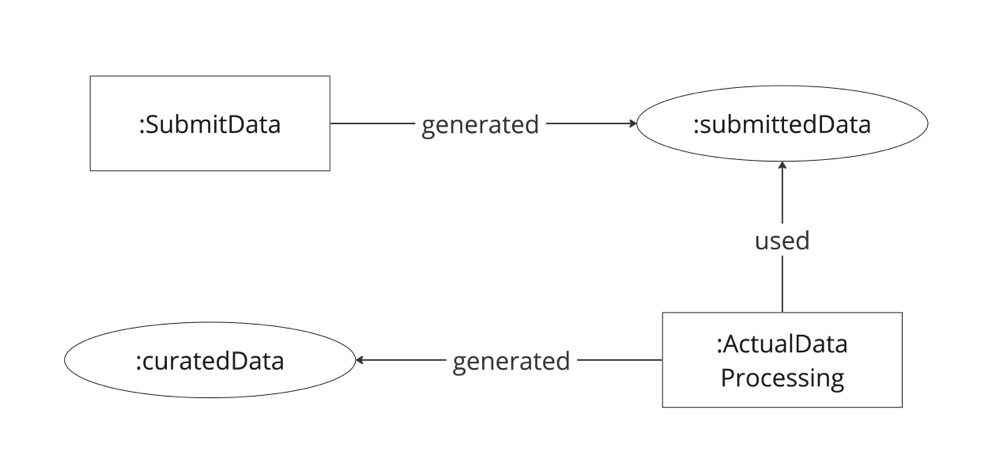
図2で示されているのは、「データ提出 SubmitData」という行為によって「提出されたデータ submittedData」が生成され、そのデータを用いて「データ処理 ActualDataProcessing」という行為が行われ、それによって「キュレーションされたデータ curatedData」が生成される、という一連のプロセスである。これをみると、「データ提出」や「データ処理」といった行為の遂行が PROV-O における「行為 Activity」にあたり、実際に生成されるデータが「事物 Entity」にあたることは(用いられているプロパティをみても)明らかである。また、「データ提出」や「データ処理」を表すクラスの最上位クラスには Activity というクラスが設定されている。研究チームはおそらく、各プロセスにおいて生成されるデータの来歴を記述するというコンセプトのもとに PROV-O を取り入れ、オントロジーを設計したものと思われる。この研究によって提案されたオントロジーは、データ・キュレーションという、分野によって具体的な方法が異なるプロセスを抽象化し、共通の知識的枠組みに基づいて相互運用可能にするという点で意義があるが、その基本構造において PROV-O を利用しているという事実は、PROV-O が新たな知識や情報が生成されていくプロセスそのものを構造化し、その解釈性と再利用可能性を確保するという課題に十分資することを意味している。
では、この PROV-O、あるいはそれを利用した上述の事例研究のオントロジーを歴史解釈の構造化に応用することは可能であろうか。すでに述べたように、HiCO においては一部で PROV-O 語彙の利用が想定されているが、その利用は限定的である。しかし、例えば HiCO において定義される「解釈行為 InterpretationAct」という概念を、事例研究におけるデータ・キュレーション行為と同様に、PROV-O の「行為 Activity」に属するものと考えることは十分に可能である。そして、解釈行為に際して用いられる史資料や、解釈行為の結果として生成される「解釈」、さらには解釈に基づく「叙述」については PROV-O の「事物 Entity」に属するものと考えられよう。
このように、「行為」「事物」「主体」の関係性記述からなる PROV-O の基本構造を歴史解釈の構造化に応用することは十分に可能であり、むしろそうすることで、他分野における知識創出や解釈形成のプロセスとの比較・対照も潜在的には可能になってくる。しかし一方で、PROV-O はあくまで抽象的な枠組みを提供するのみであり、実際の歴史研究のプロセスをデータとして詳細に構造化しようとすれば、事例研究で見たような研究プロセスの詳細なサーベイと、それに基づく独自語彙の定義も必要になるはずである。この点について、本稿はあくまで可能性を示すのみにとどめ、具体的な検討については今後の課題としたい。
人文情報学イベント関連カレンダー
【2024年6月】
-
2024-6-3 (Mon), 13 (Thu), 17 (Mon), 27 (Thu)
TEI 研究会於・オンライン -
2024-6-4 (Tue)
International DH Workshop Day1: Navigating Digital Humanities: Perspectives on Education and Researchhttps://sites.google.com/view/dhws2024b/%E3%83%9B%E3%83%BC%E3%83%A0?authuser=0
於・慶應大学三田キャンパス -
2024-6-5 (Wed)
International DH Workshop Day 2: Workshop on Digitization of Himalayhttps://sites.google.com/view/dhws2024b/%E3%83%9B%E3%83%BC%E3%83%A0?authuser=0
於・慶應大学三田キャンパス -
2024-6-6 (Thu)
第22回 CODH セミナー デジタル時代の変体仮名:日本の文字文化の継承と新たな展開http://codh.rois.ac.jp/seminar/hentaigana-20240606/
於・オンライン -
2024-6-15 (Sat) ~ 16 (Sun)
アート・ドキュメンテーション学会 第35回(2024)年次大会http://www.jads.org/news/2024/20240615-16.html
於・東京都写真美術館およびオンライン -
2024-6-15 (Sat)
日本図書館情報学会春季研究集会https://jslis.jp/events/spring-research-meeting/
於・京都橘大学
【2024年7月】
-
2024-7-1 (Mon), 11 (Thu), 15 (Mon), 25 (Thu), 29 (Mon)
TEI 研究会於・オンライン -
2024-7-8 (Mon)~12 (Fri)
Charting the European D-SEA: Digital Scholarship in East Asian Studieshttps://www.mpiwg-berlin.mpg.de/event/charting-european-d-sea
於・ベルリン国立図書館 -
2024-7-26 (Fri)~27 (Sat)
第2回 DH 若手の会(2024夏):デジタル・ヒューマニティーズで "繋がる×広がる" 人文学https://dh.nihu.jp/news/20240418
於・国際日本文化研究センター -
2024-7-26 (Fri)
第38回「東洋学へのコンピュータ利用」研究セミナーhttp://kanji.zinbun.kyoto-u.ac.jp/seminars/oricom/
於・京都大学人文科学研究所
【2024年8月】
-
2024-8-8 (Thu), 12 (Mon), 22 (Thu), 26 (Mon)
TEI 研究会於・オンライン -
2024-8-6 (Tue)~9 (Fri)
DH2024 – Reinvention & Responsibility於・Roy Rosenzweig Center for History and New Media -
2024-8-29 (Thu)~31 (Sat)
PNC 2024 Annual Conference and Joint Meetingshttps://sites.google.com/view/pnc2024
於・高麗大学校
Digital Humanities Events カレンダー共同編集人
イベントレポート「DH 国際シンポジウム「ビッグデータ時代の文学研究と研究基盤」」
2024年3月15日(金)に一橋講堂においてデジタル・ヒューマニティーズの国際シンポジウム「ビッグデータ時代の文学研究と研究基盤」が開催されました。そして、このシンポジウムでは2件の基調講演が行われました。そのうちのイリノイ大学教授 Ted Underwood 氏による「機械学習時代に変わりゆく文学をつかまえること」と題された基調講演について、徒然と感想を書きたいと思います。この講演では、HathiTrust Digital Library[1]のデータを用いて、フィクション作品における登場人物のジェンダーロールが通時的にみたときにどのように変化しているかなど、複数の作品を対象にしたテキスト分析の紹介が行われました。私自身は、主に平安文学作品を対象にデータを利用したテキスト分析を行っています。最近はデジタル・ヒューマニティーズの分野での発表の機会もいただいていますが、系統だった学問分野としてデジタル・ヒューマニティーズというものを学んだ経験はありません。興味の赴くまま、そして、必要に駆られて文学、言語学、コンピューティング、統計などを個別に学んできています。以下、至らない点や多少の記憶違いなどある場合には、ご容赦いただければと思います。
Ted Underwood 氏の基調講演において記憶に残っていることばがあります。それが以下3つです。
- start with literary significance
- numbers to interpret literature
- illuminate aspects of history/literature
これは、私自身が文学作品を対象にテキスト分析を行う時に、常に念頭においていることでもあります。1つ目の “start with literary significance”(文学的な意義から出発する)ということばは、デジタル・ヒューマニティーズにおける文学研究において非常に大切なことではないかと思います。デジタル化されたテキストをコンピュータ技術を活用して分析を行う際、何のために分析を行うのかを明確にすることが必要になります。もちろん、コンピュータ技術の発展の恩恵ではありますが、「これまでは不可能であった、規模の大きなデータを扱い、アナログでは到底処理できないような分析ができるようになった」ことだけが研究の出発点になってはならないということです。それはなぜか?その答えは、2つ目の “numbers to interpret literature”(文学を解明するための数字)ということばにあるように思います。データ分析を行うとき、語彙の数を数えたり、データにおけるある語彙の割合を出したり、統計分析を行ったりします。つまり、文学のテキストという数字とはあまり縁がなさそうに見える分析対象が、データに基づいた分析を行うことで数字となって表現されます。この数字は一体何なのか?数字が大きければいいのか?割合が大きければいいのか?はたまた p 値はいくつなのか?そういうことではないはずです。この数字は文学テキストが表出の形態を変えたものであり、テキストと別物ではありません。テキストと同様に何かを伝えようしていると考えるのであれば、この数字が何を意味しているのかを読み解かなくてはなりません。つまり、この数字が文学作品について何を伝えようとしているのかを突き止める必要があります。では、計算により得られた数字に意味付けをするということはどういうことなのでしょうか?その答えは、3つ目の “illuminate aspects of history/literature”(歴史や文学のあらゆる側面を明らかにする)ということばにあるように思います。つまり、データに基づく文学のテキスト分析により、その作品の文学的な特性や、書かれた時代や社会などについて知ることができるということです。文学作品そのものは一種の芸術作品として捉えることができると思うのですが、その中に描かれていることは、文化・歴史・言語・社会など多岐にわたります。そして、これら全てを1つの分析の中に凝縮することはできませんが、分析を積み重ねることにより1つ1つ解明することはできるはずです。しかし、データ分析により文化的・歴史的・言語的または社会的な何が解明されたのかを明らかにし、その裏付けをすることはなかなか骨の折れる作業です。Ted Underwood 氏の講演においても「分析結果が明らかにした通時的変化が、なぜ起こったのか、そして、その変化は何を意味しているのかという問いに対する明確な答えはまだ出せていない」という発言があったと記憶しています。そして、その答えを見つけるためには言語学者など他分野の研究者の協力が必要だとも述べています。
このように書いてみると、研究をする上で当たり前のことを書いているように見えるのですが、本当にそうなのでしょうか?新しく公開されるデータ、日々整備されていく研究のためのインフラ、そして続々と開発される様々な分析技術やソフトウェア。このようなものによってもたらされる「わくわく感」が先行し、上記で述べた自明なステップを1つも漏らさず研究をできているのだろうか、と感じる瞬間があります。
そこで、最後に「デジタル・ヒューマニティーズとは何か?」ということを振り返っておきたいと思います。ジャパンナレッジで調べてみると、デジタル・ヒューマニティーズとは「コンピューターによる情報科学の手法を、広く人文科学の研究に応用する学際的な学問分野」とあります[2]。つまり、人文学における諸問題の解決や理解の促進、そして広くは人文学諸分野の発展のためにデジタル技術を活用するということです。文学作品を対象としたテキスト分析に当てはめるのであれば、デジタル技術を活用することで、例えば、精読により行われてきた研究課題に新たな分析方法を適用することで新しい知見を得たり、作品が書かれた時代の社会制度やジェンダーロールがどのように反映されているかを理解したりすること、と言えるのではないかと思います。そのためには何が必要なのか?それには、一つ目の “start with literary significance”(文学的な意義から出発する)ことが大切なのだと思います。
Ted Underwood 氏の講演は、紹介された研究も非常に示唆に富んで興味深いものでしたが、もう一度研究の基本に立ち返る良い機会にもなりました。このような機会を提供してくださった一般財団法人人文情報学研究所、九州大学人文科学研究院、そして運営に尽力された皆様に感謝をして、本稿を終えたいと思います。
◆編集後記
人間文化研究機構に設置されたDH推進室の活動がいよいよ本格化してきました。昨年度末に開催した「若手の会」は大変盛り上がったようですが、7月下旬には第二回を開催するようです。公的資金が全面的に投入された、日本では希有なDHの専門組織ですので、研究や普及など、様々な側面で日本のDHを活性化し、国際的な動向ともうまく接続してくださること、そして、できればそこからさらに人文学そのものに包括的に貢献してくださることを期待したいところです。
ところで、このところ、IIIFに関する入門書を編集しています。7月に文学通信から刊行することを目指して最後の仕上げの段階です。
IIIFは日本でもいわゆるアーリーアダプター的な組織には十分に浸透しており、なかには大規模なコンテンツを公開しているところが多いため、国内でWeb公開されているデジタルコンテンツにおける割合としてはかなりIIIFが浸透したと言える状態になっているだろうと思います。しかしながら、IIIFを採用している機関という観点で見てみると、まだそれほど多くの機関が対応しているわけではないようです。これには色々な理由があることが個別のインタビューからわかっています。そういった原因を少しずつ解消していくことが、今後の重要な課題になっていくだろうと思っています。今回の入門書の刊行は、まさにそういう対応策の一環となるものです。デジタルアーカイブをより良いものにしていきたいと思われる方々におかれては、ぜひ手に取ってみていただけるとありがたいです。
こういったものを広めるためには対面のセミナーのような形でコミュニティを形成していくことも重要と考えてきましたが、コロナ禍でそういう機会は中断してしまいました。また近いうちに、ターゲットをうまく考えながら再開していきたいと思っております。
(永崎研宣)
- コメントを投稿するにはログインしてください