人文情報学月報第158号【前編】
ISSN 2189-1621 / 2011年08月27日創刊
目次
【前編】
- 《巻頭言》「訓点資料とテキストデータ」
:九州大学人文科学研究院 - 《連載》「欧州・中東デジタル・ヒューマニティーズ動向」第74回
「引用などを自動で検出するテキスト・リユース探知ソフトウェア Passim」
:筑波大学人文社会系 - 《連載》「仏教学のためのデジタルツール」第22回
「浄土真宗聖典全書オンライン検索システム」
:浄土真宗本願寺派総合研究所
【後編】
- 《特別寄稿》「Krista Stinne Greve Rasmussen による「7. Reading or Using a Digital Edition? Reader Roles in Scholarly Editions」『Digital Scholarly Editing:Theories and Practices』所収)の要約と紹介」
:早稲田大学大学院文学研究科 - 人文情報学イベント関連カレンダー
- イベントレポート「DH2024と文学分野の研究発表」
:中央大学国際情報学部 - イベントレポート「DH2024参加記(前半)」
:名城大学理工学部 - 編集後記
《巻頭言》「訓点資料とテキストデータ」
古代より、日本人は漢文をよむ際、翻訳ではなく訓読をしてきた。訓読とは、漢字・漢語をひとつずつ日本語に置きかえ、時には漢語のまま使用し、語順を日本語のそれに整えて、日本語“っぽく”よんでいく方法である。文脈を読みとりながら自然な日本語にしていく翻訳とは異なり、より形式化された逐語訳のようなものである。漢文をよむには、以下のみっつの段階が必要である。
①白文:(古代)中国語そのままの文
②訓読文:①に、日本語としてよむのに必要なテニヲハや返り点をつけたもの
③読み下し文:②を漢字仮名交じりで日本語としてあらわしたもの
外国語(漢文)を日本語の資料として使えるのは、②~③の段階があるからである。特に②のように、よみ方の注記(訓点)がついた資料群を訓点資料と呼ぶ。訓読は奈良時代にすでに起こっており、訓点のために片仮名が発達し、訓読によって生じた、あるいは残存した語彙・語法があるなど、日本語の書きことばを語るうえで外せない存在である。訓点資料は、後世の写本でしか残らない和文資料とは違い、訓点がつけられた当時の原本が残るので、一次資料としての価値が高い。実際の訓点資料をよんでみると、高校の授業で習った訓法とは必ずしも一致せず、形式化されてない生の言語活動の姿がありありと浮かび上がる。
しかし、訓点資料の訓読は、単に訓点をよめばいいわけではない。テニヲハのすべてが片仮名で書かれているわけでも、一二点が必ずついているわけでもないからである。片仮名もあるが、ヲコト点という・や-などの記号の、漢字における位置によって、テニヲハが示される。

訓点はあくまで訓読の“補助”であるため、加点者にとって“必要ない”ものは書かれない。書かれていない部分は解読者が補わなければならず、ある程度のコツとワザが必要となる。そのため、解読者によって読み下しの結果が異なることもある。訓点資料の有用性は誰もが認めるところだが、日本語史の資料として使うにはハードルが高い。公刊されている読み下し文もごく限られており、テキストデータ化されているものはほとんどないため、現代的な研究手法の中で顧みられづらくなっている。限られた読み下し文を使うにも、原資料の影印の出版・公開されていないものがほとんどで、その読み下し文をつくった研究者を信じるしかなく、誤写や誤読など自分での再解釈の余地がなくなる。また、読み下し文には現れない、仮名字体や声点によるアクセントなど、一次資料ならではの情報にアクセスできなくなる。
このような訓点資料の状況をふまえて、訓点を“そのまま”の形で記述できないか、点そのものを検索できるようにならないかと考え、訓点情報をできるだけそのまま保存したデータベースの作成を検討してきた。漢字1字ずつをひとまとまりのデータとして、漢字ごとの訓点を、とりあえず Excel でいいので整理したい、ヲコト点は位置と形とである程度のよみが判明しているので、マクロを組んで該当位置をポチっとするだけで読みが自動で出てくるようなフォームをつくり、画像データが手元にあった九州大学図書館蔵の『金光明最勝王経』[1]全10巻分をデータにしてみた。
データの作成にあたり、採録者の解釈は最小限に、見たまま記述し、あえて読み下しはしないという方針をたてた。そのため、文脈的な検索はできないが、少なくともどのようなテニヲハがあるのか、どのような訓があるのかは調べられるデータができあがった。点の蒐集にはやはり採録者の“目”が入るが、それを「その周辺の類似の点」と捉えれば、利用者が再解釈することも可能である。そこがこのデータの最大のメリットである。日本語研究のためには読み下し文の作成が必要だが、本データベースによって訓点の種類や使用状況が俯瞰的に見渡せるようになったので、統一的な解釈で読み下し文が作れる。
一方で、解釈をしない方針による弊害もみえてきた。ひとつが語彙の情報である。漢字1字をひとデータとした構成としており、たしかに古代語は一字漢語が多いが、たとえば「菩薩は」のデータは「菩」と「薩は」とにわかれてしまう。点を俯瞰的に見られるのがメリットとはいえ、文脈をばらしてしまうデータ構成では点の再検討もしようがない。なら、漢字ではなく、語単位でデータをつくればいいではないか。しかし漢語の場合、どこまでを1語とするか判然としないものが多い。検索の便を考えると、事情はさらに複雑になる。片仮名による仮名点から、語彙の検索もできればよいが、実際の仮名点は「マフ(=給ふ)」のように語の一部のみを示すものもあり、採録者が「タ」を補わないと語彙データとして使えない。利用という観点を考えれば考えるほど、採録者の解釈が必要になるというジレンマに陥る。
課題のふたつめが仮名字体の情報である。訓点資料は片仮名の変遷を反映した資料である。そのため、仮名字体の記録はその資料を理解するうえで重要な情報のひとつである。データ化の初期の構想では、似た形の記号や文字を使用しようとしたが、当然ながら実際の字形とは細かな差異があり、しかもこの差が大事な情報となる。画像をデータに貼るというのが一番の解決策なのだろうが、画像の検索方法や、そもそも画像データがあるのかという課題が残る。
みっつめは、やはり読み下し文がないと日本語資料としては使いにくいという点である。語彙や語法は文脈の中で初めて生きる。訓点のデータ化自体は、手前味噌ではあるが、有益であったと思う。データ化された資料が増えれば、これまでの資料優位の研究方法ではできなかった研究の可能性も期待できる。何より、句読や返り点、声点などの情報は、このようなデータにしない限り記録されることがなかったろう。しかし、日本語の研究は日本語の文脈の中で行われるものである。となると、先ほどの例でいうところの②と③の両方の情報を含んだデータが、日本語研究においては必要となる。
敢えて解釈しないという方針によってデータを作った結果、解釈をふんだんに盛り込んだ読み下し文を作らねばという結論に至ったのが現在の状況である。次なる目標は読み下し文の作成と、そのテキストデータ化である。そんな折、TEI(テキストエンコーディングイニシアチブ)に出会った。これならば、読み下し文だけではなく、訓読の情報も何らかのルールによったテキストデータにできるのではないか。それを読み下し文と併記すれば、参照しやすくなるのではないか。ヲコト点は、データベースと同様「その周辺の類似の点」という情報として理解できるよう、仮名におこす以外の方法を考えねばならない。くどいが声点などの情報を考え合わせると、ここまで作成したデータベースに紐づけするのもいい。どうやって?を二の次にすれば、夢はさらに膨らんでいく。
普通の、一言語による文章や翻訳文とは異なる“訓読”というステップを、しかも文字ではない形で書き入れた訓点資料。こんな面倒で面白い資料をどうデータに表現してやろうか。読み下し文からだけではわからない面白さがこの資料にはあるのである。
執筆者プロフィール
《連載》「欧州・中東デジタル・ヒューマニティーズ動向」第74回
「引用などを自動で検出するテキスト・リユース探知ソフトウェア Passim」
テキスト・リユース(Text Reuse)は、デジタル・ヒューマニティーズの分野において重要な研究対象である。テキスト・リユースとは、ある文書の一部または全体が他の文書で使用されることを指し、直接的な引用、パラフレーズ、引喩(allusion)、あるいは意図的・非意図的な剽窃(plagiarism)など、様々な形態が存在する[1]。特に歴史的文献研究においては、テキスト・リユースの検出、すなわちテキスト・リユース探知(Text Reuse Detection)が古典テキストの伝播経路や影響関係を明らかにする上で重要な役割を果たしている。
このようなテキスト・リユースを自動的に検出するためのツールとして、近年、Passim が注目を集めている。Passim は、米国ノースイースタン大学の David Smith 氏らによって開発されたオープンソースのソフトウェアである[2]。大規模なテキストコーパスを効率的に処理し、テキストの再利用関係を自動的に検出する能力に優れており、特に歴史的文献や新聞記事における引用や転載のパターンを明らかにするのに適している。
Passim の処理は主に二段階で行われる。第一段階では、入力されたテキストを n-gram と呼ばれる小さな単位に分割し、共通する n-gram を持つチャンクを候補ペアとして抽出する。n-gram とは、連続する n 個の要素(この場合は単語や文字)の並びを指す。例えば、「a digital humanities journal」という文字列を単語単位で3-gram に分割すると、「a digital humanities」「digital humanities journal」「humanities journal a」「journal a digital」といった具合になる。第二段階では、Smith-Waterman アルゴリズムを用いて詳細な類似度計算を行い、再利用関係を特定する[3]。このアルゴリズムは、元々は DNA やタンパク質の配列アラインメント(並べ合わせ)のために開発されたものであるが、テキスト比較にも応用されている。これにより、二つのテキスト間の最適なアラインメントを見つけ出し、詳細な類似度を計算する。このプロセスにより、大規模なデータセットでも迅速かつ正確にテキスト・リユースを検出できる。
Passim の技術的特徴として、Apache Spark を活用した並列分散処理により、テラバイト級の大規模コーパスでも現実的な時間内で処理が可能である点が挙げられる。また、JSONL フォーマットの採用により、構造化されたデータを柔軟に扱うことができ、テキスト本文だけでなくメタデータも含めた高度な分析が可能である。さらに、Unicode 文字セットを全面的にサポートしており、世界中の様々な言語で書かれたテキストを処理することができる。また、n-gram の長さ、類似度の閾値、アライメントの最小長など、様々なパラメータをユーザーが調整できる点も特徴的である[4]。
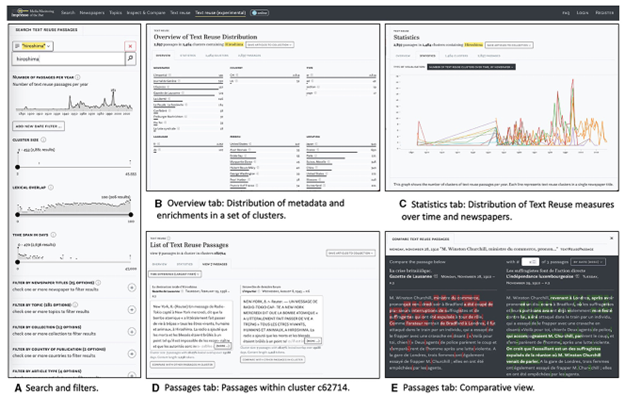
Passim の具体的な活用事例としては、The Viral Texts Project による19世紀アメリカの新聞コーパス分析が挙げられる[5]。この研究では、19世紀のアメリカで発行された膨大な数の新聞記事を対象に、Passim を用いてテキスト再利用の分析が行われた。その結果、ニュースの伝播経路を可視化することができ、ある記事がどの地域からどの地域へ、どのような順序で転載されていったかを地図上に表示することが可能となった。これにより、当時のメディアネットワークの構造や情報の流れを視覚的に理解することができるようになった。また、新聞記事を扱った DH プロジェクトとしてはルクセンブルク大学の impresso が著名であるが、このプロジェクトでもテキスト・リユース探知で Passim を用いている (図1)[6]。
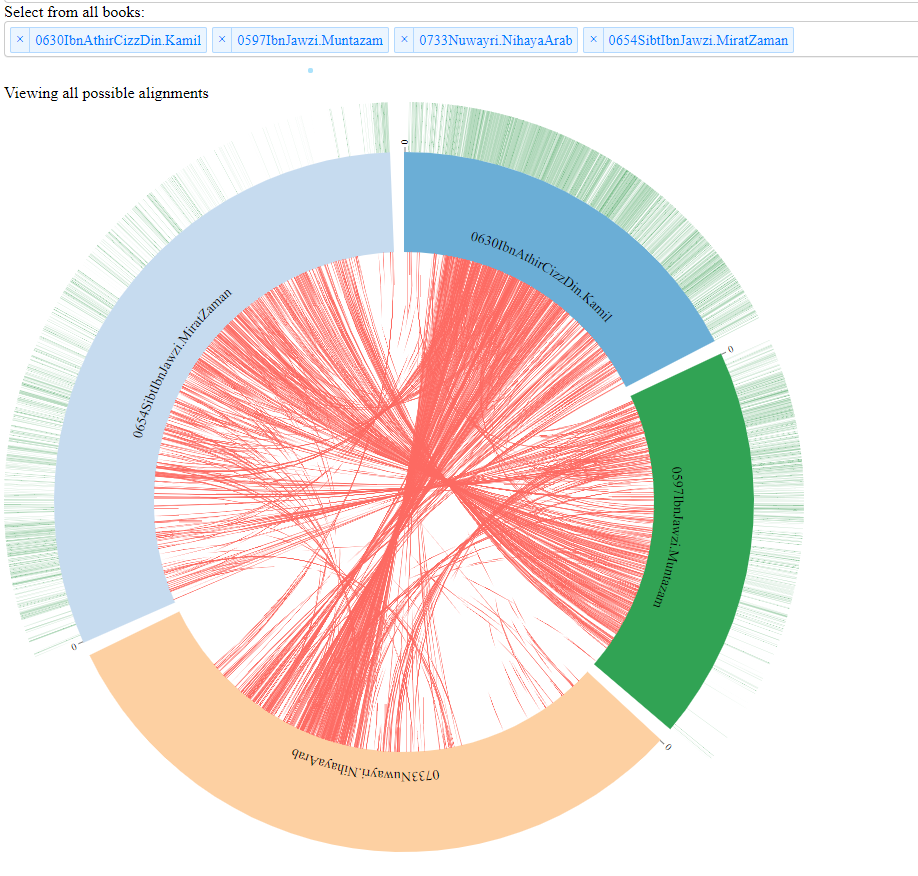
また、アラビア語の古典文献コーパスを対象とした研究も KITAB プロジェクトによって行われている(図2)。イスラム世界の古典文献を対象に、Passim を用いて著作間の引用・参照関係を抽出する試みである[7]。この研究では、ある学者の著作がどのように後世の著作に引用され、影響を与えていったかを時系列で追跡することが可能となった。さらに、現存する著作中の引用から、既に失われた文献の内容を部分的に復元する試みも行われている。
一方で、Passim と同様にテキスト再利用検出を行うツールとして「TRACER」がある[9]。TRACER は、ドイツのライプチヒ大学およびゲッティンゲン大学で開発されたツールで、Passim とは異なるアプローチを採用している。TRACER は7段階の処理パイプラインを持ち、ステミングやストップワード除去などの豊富な前処理オプションを提供する。また、複数の類似度計算アルゴリズムを選択できるため、特定の研究ニーズに応じたカスタマイズが可能である。
Passim と TRACER を比較すると、Passim は大規模データの処理に優れ、TRACER は細かな設定が可能であるという違いがある。Passim は、特に処理速度や拡張性の面で優位性があるが、TRACER はコンフィギュレーションの XML ファイルを備えており、容易にパラメータを調整でき、初心者でも扱いやすいという利点がある。研究目的や対象コーパスの特性に応じて、適切なツールを選択することが重要である。
さらに、現状の Passim は表層的な文字列の一致のみを検出しているため、意味的類似性を考慮した検出が困難であるという課題がある。例えば、同じ内容を異なる表現で記述した場合や、翻訳された文章間の類似性を検出することは現在のシステムでは難しい。これは、WordNet や BabelNet などの概念辞典や対訳レキシコンを取り込むことで、パラフレーズや引喩や複数言語間のテキスト・リユースまで検出可能である TRACER とは異なる[10]。
Passim と TRACER には共通の課題も存在する。例えば、これらの性能は、n-gram の長さや類似度の閾値など、様々なパラメータ設定に大きく依存する。パラメータの最適値は、対象とするコーパスの特性や研究目的によって異なるため、適切な設定には経験と試行錯誤が必要となる。また、言語依存性の問題も存在する。Passim と TRACER は基本的に単語単位での n-gram 生成を前提としているが、日本語や中国語など、分かち書きのない言語では前処理として単語分割が必要となる。この単語分割の精度が全体の性能に大きく影響する。
これらの課題に対して、今後の展望としては、機械学習技術を活用し、コーパスの特性や研究目的に応じて自動的に最適なパラメータを推定するシステムの開発が期待されている。これにより、初心者でも容易に高精度な分析が可能になると考えられる。また、言語非依存の文字レベル n-gram と単語レベル n-gram を組み合わせたハイブリッドアプローチの開発や、最新の自然言語処理技術を用いた高精度な単語分割手法の導入が検討されている。さらに、大規模言語モデルや意味埋め込み技術を活用し、意味レベルでの類似性を考慮できるようにすることが期待されている。
テキスト・リユース探知は、デジタル・ヒューマニティーズ研究に新たな視点をもたらす強力な手法である。Passim をはじめとする各種ツールの特性を理解し、適切に活用することで、テキスト間の複雑な関係性を解明し、人文学研究に新たな知見をもたらすことが期待される。
《連載》「仏教学のためのデジタルツール」第22回
仏教学は世界的に広く研究されており各地に研究拠点がありそれぞれに様々なデジタル研究プロジェクトを展開しています。本連載では、そのようななかでも、実際に研究や教育に役立てられるツールに焦点をあて、それをどのように役立てているか、若手を含む様々な立場の研究者に現場から報告していただきます。仏教学には縁が薄い読者の皆様におかれましても、デジタルツールの多様性やその有用性の在り方といった観点からご高覧いただけますと幸いです。
「浄土真宗聖典全書オンライン検索システム」
今回は、浄土真宗本願寺派総合研究所(以下、総研)のホームページ(http://j-soken.jp/)において2022年12月より公開されている「浄土真宗聖典全書オンライン検索システム」(https://j-soken.net/ 以下、本システム)について紹介する。本システムは、総研の聖典編纂部門で作成したテキストデータを基に、人文情報学研究所の永崎研宣氏と東京大学史料編纂所の中村覚氏の協力を得て、公開に至ることとなった。まずシステムの紹介に先立ち、『浄土真宗聖典全書』(以下、『聖典全書』)について説明をしておきたい。
近年の本願寺派における聖典編纂の事業は、昭和57(1982)年から始まった。『聖典全書』の刊行以前には、「浄土真宗聖典」シリーズ(原典版・註釈版・現代語版)が出版されており、宗派内を中心に現在まで広く用いられるものとなっている。それを承けた『聖典全書』の編纂事業は、2011年度の「親鸞聖人750回大遠忌法要」を迎えるに際して企画されたものである。宗門長期振興計画の一環として、新たな編纂方針のもとで推進されることとなった。事業は2005年から2019年まで、足かけ15年にわたって進められ、全6巻の刊行をもって一応の完結を迎えている。総計40名以上の聖典編纂担当をはじめとし、約140に及ぶテキストの所蔵者、そして30名を超える外部有識者など多くの協力を受けての大事業であり、今日において『聖典全書』は、浄土真宗聖典の集大成に位置づけられるテキストとなっている[1]。各巻の名称ならびに収録されている主な典籍は以下の通りである。
- 第1巻 三経七祖篇(浄土三部経とその異訳、浄土真宗の七祖の著作)
- 第2巻 宗祖篇上(『教行信証』をはじめとする親鸞の著作など)
- 第3巻 宗祖篇下(親鸞の書写本や加点本など)
- 第4巻 相伝篇上(本願寺の覚如や存覚の著作、真宗高田派の真仏や顕智の書写本など)
- 第5巻 相伝篇下(本願寺第八代蓮如の著作や言行録など)
- 第6巻 補遺篇(法然の法語や伝記、初期真宗教団や本願寺の成立に関する史料など)
なお、本システムの開発に至る経緯については、『全仏』659号(2023年10月)に記事が掲載されているので、参照されたい(https://www.jbf.ne.jp/newsletters/detail?id=16438)[2]。また、開発に際しての技術的課題などについては、共同研究として『じんもんこん2022論文集』に論攷を掲載しており、そちらも併せてご覧いただきたい(https://ipsj.ixsq.nii.ac.jp/ej/?action=pages_view_main&active_action=repository_view_main_item_detail&item_id=223274&item_no=1&page_id=13&block_id=8)。
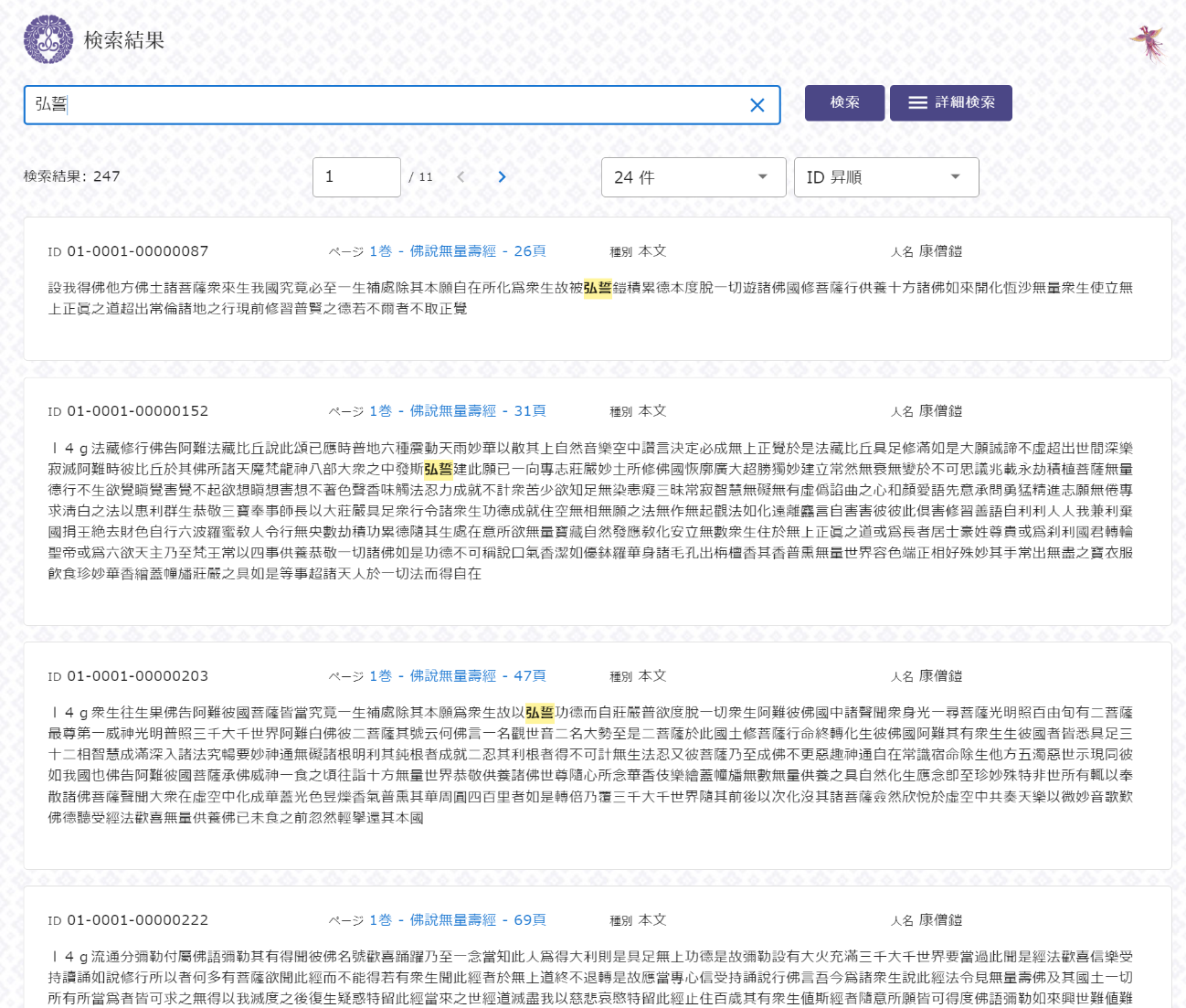
それでは、本システムの紹介に移りたい。使い方については、基本的に SAT 大正新脩大蔵経テキストデータベース(https://21dzk.l.u-tokyo.ac.jp/SAT/)や浄土宗全書検索システム(https://jodoshuzensho.jp/jozensearch_post/)と大きくは変わらない。検索画面を開き、たとえば「弘誓」と打ち込んで検索ボタンを押せば、検索結果が以下のように表示される。
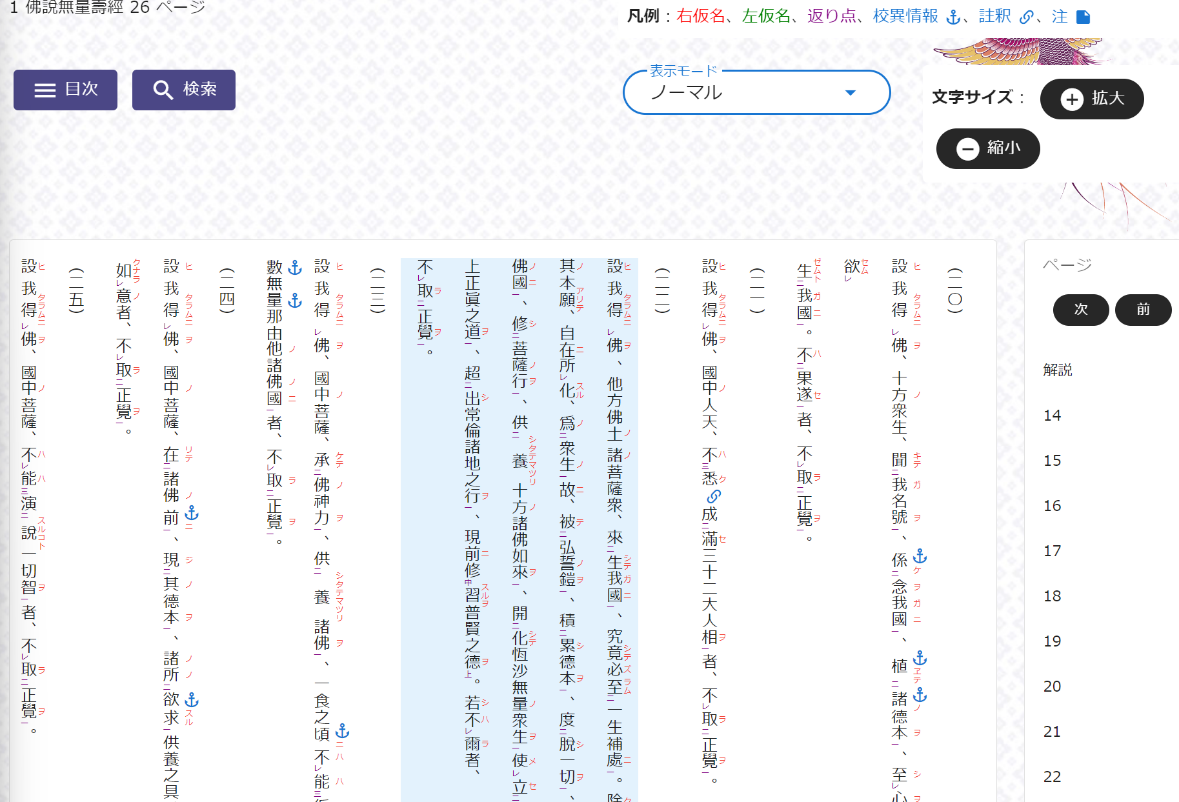
ここで一番上の検索結果の青字の箇所をクリックすると、縦書きの本文の表示画面に遷移する。本文の表示においては、「ノーマル」「シンプル」の2種類のモードが搭載されている。まずノーマルモードでは、書籍の『聖典全書』と同様、縦書きの本文に加えてルビや返点も表示され、画面上で漢文を読解する便になる(画像2)。ただし、この状態では検索語の「弘誓」がどこにあるのかが明らかでない。これは現状のシステムでは、2文字以上の検索語の中にルビが含まれている場合、ハイライト表示ができないためである。
それをハイライト表示させたい場合、画面右上にある「表示モード」をノーマルからシンプルに変えるとよい。すると、ルビや返点は表示されずに本文のみが表示されるため、「弘誓」とある箇所が黄色でハイライト表示され、検索語の所在が明らかとなる(画像3)。また、本文が表示されるまでの時間も短縮されるため、語句の所在のみを調べたいときは、シンプルモードをおすすめする。

そのほか、詳細検索を用いれば、『聖典全書』の巻数、あるいは典籍の著者・書写者、経典の訳者などを指定して検索することもできる。そして本システムで画期的なのは、本文の右仮名や左仮名を検索対象とすることができる点である[3]。一般的に、右仮名はその字の読み方を、左仮名はその字や語句の意味を示している場合が多い。それらの中、特に左仮名については、著者や書写者の特徴的な理解が示されている場合もあり、それ自体を検索したいと思うことがしばしばある。
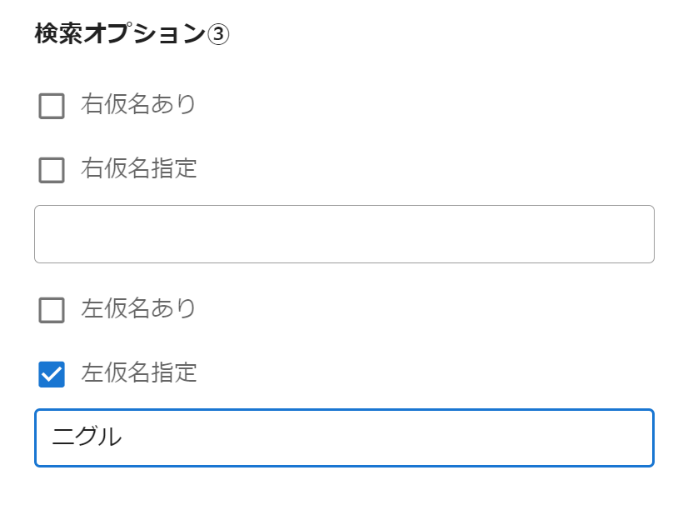
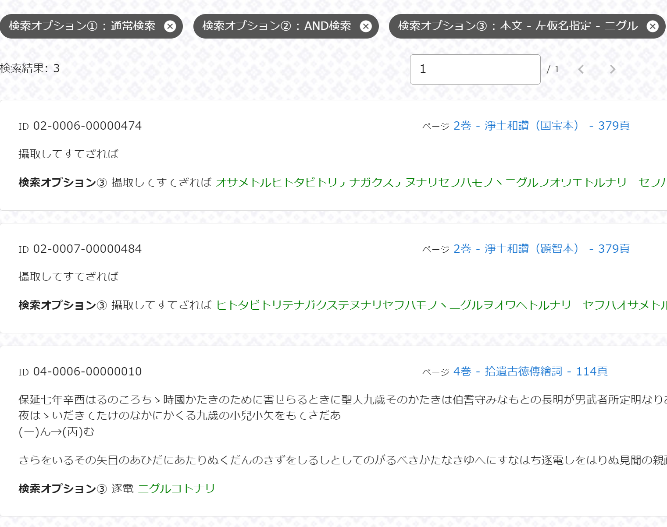
たとえば一例を挙げてみると、浄土真宗の開祖、親鸞(1173–1263)の『浄土和讃』という著作のなかには、「モノヽニグルヲオワエトルナリ(ものの逃ぐるを追わえ取るなり)」という左仮名が付されているテキストがある。これは「摂取してすてざれば」という本文のうち、「摂」という字の意味について記した左仮名であり、大まかに意味をとれば「逃げている者を追いかけて救いとる」となる。阿弥陀仏の智慧と慈悲のはたらきは、仏に背を向け、仏教から遠ざかるような生き方をしている者にこそ向けられるのだという、浄土真宗の救いが端的に述べられる特徴的な左仮名である。この和讃ならびに左仮名は、浄土真宗の法話などでもたびたび用いられるものであり、特に宗内では聞きなじみのある方も多い。たとえば、この左仮名を法話や講義などで取り上げたいが、その出典を思い出せない場合、これまでの検索システムでは左仮名が検索対象になっておらず、その所在を調べることはできなかった。それが本システムにおいては可能となっている。具体的には、以下の画像4のように「詳細検索」の画面右下にある検索オプション③を入力し、ページ上部の検索窓は空欄にした状態で検索ボタンをクリックすれば検索をかけることができる。そしてその結果(画像5)からは、『浄土和讃』の国宝本と顕智本にその左仮名が記されていることが知られる。あくまでも一例であるが、このように右仮名や左仮名も含めて検索ができることは、利用者にとってもメリットが大きく、本システムの大きな特徴といえるだろう。
その一方で、本システムの元データには、右仮名・左仮名のほかに返点や傍註、各条の通し番号など様々な要素がタグとして含まれており、非常に複雑なものとなっている。それゆえ現状のシステムでは、上手く表示ができていない箇所などもあり、それらの修正・改善は今後の課題である。
以上、紙幅の都合もあって紹介しきれていない機能も多いが、ぜひ一度ご利用いただきたい。また総研ホームページには、「デジタル版『教行信証』」(https://dbook.hongwanji.or.jp/signin)も公開しているので、そちらも併せてご活用いただけると幸いである。
- コメントを投稿するにはログインしてください