人文情報学月報第89号【中編】
目次
【前編】
- 《巻頭言》「原典回帰—パラ言語を補完する人文情報学」
:国立国語研究所 - 《連載》「Digital Japanese Studies寸見」第45回
「「くずし字データセット」と「KMNIST データセット」」
:国文学研究資料館古典籍共同研究事業センター - 《連載》「欧州・中東デジタル・ヒューマニティーズ動向」第9回
「テクスト・リユースと間テクスト性研究の歴史と発展」
:ゲッティンゲン大学
【中編】
- 《連載》「東アジア研究と DH を学ぶ」第9回
「DH 研究情報の集約と発信に向けた取り組み」
:関西大学アジア・オープン・リサーチセンター - 《連載》「Tokyo DigitalHistory」第8回
「Omeka S を用いたデータ管理システムの試作」
:東京大学情報基盤センター
【後編】
- 特別寄稿「Carolina Digital Humanities Initiative Fellow の経験を通じて〈前半〉」
- 人文情報学イベントカレンダー
- 編集後記
《連載》「東アジア研究と DH を学ぶ」第9回
「DH 研究情報の集約と発信に向けた取り組み」
デジタルヒューマニティーズ(DH)の研究を進める場合において、自分の研究テーマに関連したデータやツールがすでに世にあるならば、それを利用した方が楽なのは言うまでもないし、先行研究を把握するという意味で必須とすら言える。また、たとえ自分の研究テーマそのものではなくとも、DH の成果としてどのようなデータが生まれ、あるいは、ツールが作成されているかを知ることは、DH 全体の業界動向を把握するうえでも有用である。
しかしながら、日進月歩のこの DH 業界において、その種の情報やデータを網羅するのはとかく困難である。それらは「研究データ」として位置づけられるものではあるが、その「研究データ管理」はまだ途上にあると言えよう[1]。したがって、現状に即して言えば、信頼に足る DH に関するデータやツール情報の入手は、自身で Google 等を検索するほかは、DH 情報の集約サイトやコミュニティによる情報発信をキャッチするしかない。
前置きが長くなってしまったが、本稿で紹介するのは、そのような DH 情報の集約サイトやコミュニティによる情報発信のうち、特に東アジア研究に関わるものである。
Digital Sinology
Digital Sinology は、前近代の中国語学・文化・歴史を対象に、デジタルの活用に関する情報をまとめたウェブサイトである[2]。この WordPress サイトのほかに、Facebook と MediaWiki のサイトがある。Digital Sinology には2つの Facebook ページがあるが、このうち特に Digital Sinology Group というコミュニティには1,000人以上の研究者等が参加しており、情報共有が日々活発に行われている[3]。また、MediaWiki のサイト[4]は、データベースやツール、プラットフォーム等のデジタルリソースについての “持続性のある” カタログを作成することを目的として運営されている。全文データベース・ツール・地理情報システム・人物データベース等のカテゴリに分かれ情報が登録されているが、情報が充実しているとは言い難い。しかし、Digital Sinology Group の活況さを思えば、今後の拡充が期待できるだろう。
Digital Scholarship Resources for East Asian Studies and Beyond
Digital Scholarship Resources for East Asian Studies and Beyond は、北米の東亜図書館協会(CEAL)の Committee on Technical Processing が作成している[5]。人物情報や地理情報、文献情報の各データベース、DH のプラットフォームやツール情報がまとめられている。大蔵経テキストデータベースが収録されていることからも分かるように、Digital Sinology とは異なり、中国だけでなく東アジア各国の情報がリストアップされている。
しかしながら、PDF で公開されておりユーザ側での情報の追加ができないこと、東アジアを手広く対象としつつも、委員会の選定基準が不明であるため、やや雑駁な印象を受けざるを得ないように思う。
CrossAsia
CrossAsia は、先述の Digital Sinology の Wiki サイトの紹介によると、「ドイツの機関に所属する個人会員にアジア研究についての活字および電子資料を提供するインターネットポータルサイト」であるという。運営は、ベルリン州立図書館の東アジア部門と、2016年からは ハイデルベルク大学とが共同で管理をしているとのことである。
CrossAsia は、約12万タイトル、1,300万ページのフルテキストデータベースを提供するなど、充実した研究プラットフォームとして機能している。また、リソースオンラインガイドには、有償無償を問わず1万件を超えるウェブリソースの情報とそのリンクがまとめられており、それらは主題や国・地域、言語などで絞り込み検索が可能である。さらに、DH による研究支援も進められており、今後、SRU 等の API 開発を通じてテキストデータの検索と情報の抽出を可能としたり、N-gram 分析をしたりするための環境整備も予定されている。しかし、一部の情報検索は日本からも利用可能ではあるが、全サービスを利用するには「ドイツの登録機関メンバーであれば」となるのが残念ではある。
以上、海外、特に北米とドイツの東アジア DH 情報のポータルサイトを紹介してきた。ちなみに、日本の機関による情報のまとめには、例えば国立国会図書館関西館アジア情報室による「アジアの文化機関のデジタルアーカイブ(中国・台湾・韓国)」があるが[6]、これはあくまでデジタル化資料の公開サイトの紹介にとどまっており、DHの研究データやツール情報は得ることができない。
KU-ORCAS は、「研究ノウハウのオープン化」を掲げており、このような東アジア研究に関する DH の研究データやツール情報の発信整備も計画に含まれている。筆者としては、少なくとも国内の東アジアに関する DH 情報は集約し、それらを国内外の研究者に向けて提供できるよう努めていきたいと考えている。そのための情報収集も提供の仕方も、KU-ORCAS だけで行うのではなく、国内の DH 研究機関や JADH 等の学協会、そしてここで挙げたような各ポータルとの積極的な連携が不可欠であろう。
本稿で言及した情報は、英語をはじめ欧州言語のものが中心であるため、すでによく知られていながら筆者が確認できていないものもあるかもしれない。有用なポータルサイトの情報をご存じの方がおられれば、ぜひ情報提供をいただけると幸いである。
なお、Digital Sinology Group は非公開グループであり、参加登録に際してはアンケート(自己紹介)への回答が求められている。
http://www.eastasianlib.org/newsite/wp-content/uploads/2018/09/Digital-Scholarship-Resources_CTP.pdf(アクセス日:2018-12-20)。
《連載》「Tokyo Digital History」第8回
「Omeka S を用いたデータ管理システムの試作」
はじめに
Tokyo Digital History の連載第8回となる今回は、情報システムに関心を持つ筆者が担当ということで、Omeka S というソフトウェアを中心に、少し技術的な内容について報告したい。読みにくい点が多々あるかと思われるが、お付き合いいただければ幸いである。
報告の背景として、2018年10月20日(土)・21日(日)に一橋大学において開催された2018年度政治経済学・経済史学会秋季学術大会にて、Tokyo Digital History メンバーが中心となり、「情報技術の活用と研究基盤の拡充による新たな日本経済史研究の可能性」と題するパネル・ディスカッション[1]を行った。具体的には、渋沢栄一記念財団情報資源センター長・茂原暢氏、筆者、東京大学・山崎翔平氏、東京大学・福田真人氏の4名が発表を行い、東京大学教授・鈴木淳氏にコメントをいただいた。日本経済史をはじめとする人文・社会科学研究分野において、情報技術をもちいた研究情報資源の活用の可能性について報告した。このパネル・ディスカッションの報告内容については、別の機会に紹介したい。
このパネル・ディスカッションにおいて、筆者は「研究データ管理システムの試作」と題する発表を行った。これは、筆者がこれまで取り組んできた歴史研究者の資料管理を支援するシステムの開発および研究事例[2]に基づき、研究過程で生み出されるデータ管理の重要性や、研究成果としてのデータ共有のメリットについて報告したものである。この報告の機会に合わせて、これまで独自に構築してきたシステムを、Omeka S という OSS(オープンソースソフトウェア)へ移行する作業を実施した。
本稿では、この Omeka S というソフトウェアの簡単な紹介を行うとともに、システムの移行を行った理由や、移行によって生まれた利点について述べる。
Omeka S
本メールマガジンの読者であれば、Omeka というソフトウェアの名前を一度は耳にしたことがあると思われるが、ここで改めて簡単に紹介したい。Omeka とは、オンラインのデジタルコレクションのためのフリーでオープンソースのコンテンツ管理システム[3]であり、ジョージ・メイソン大学の Roy Rosenzweig Center for History and New Media によって開発された OSS である。「テーマ」を用いて UI(ユーザインタフェース)を変更し、「プラグイン」を用いて機能を拡張することができる。特に後者のプラグインについて、人文学研究に適した様々なプラグインがこれまで数多く開発されており、これが DH プロジェクトや教育プログラムに Omeka が積極的に採用される理由の1つとなっている。
2008年に初版となるパブリック・ベータ版がリリースされ、その後コミュニティによる継続的な開発・改良が進められ、2018年2月に10周年を迎えた[4]。この過程において、2010年10月には Omeka のクラウド版である Omeka.net[5]が公開され、サーバマシン等を用意することなく、アカウントの登録のみで Omeka を利用できるオプションが追加された。このクラウド版には無料・有料オプション[6]があり、この無料オプションを利用することで、Omeka の機能を簡単に試すことができる。一方、最上位の有料オプションにおいても、利用可能なプラグインに制限があるなど、利用にあたっては一部注意が必要である。また、2017年11月には、Omeka S という新しいソフトウェアが正式に公開され、これにより、従来の Omeka の名称が Omeka Classic に変更となった。Omeka Classic が個別プロジェクトおよび教育者向けのソフトウェアであるのに対し、Omeka S は組織向けのソフトウェアということが謳われている[7]。この理由として、1つのシステムをインストールすることで、テーマや検索対象が異なる複数のサイトを公開できるようになっている点などが挙げられる。例えば、筆者が開発に携わっている東京大学デジタルアーカイブズ事業[8]のデジタルコレクションでは、1つの Omeka S で複数のコレクションを管理・公開している。
その他、Omeka S は Omeka Classic から数多くの改良や機能追加がみられるが、筆者が特に惹かれた点は、Linked Data への標準対応である。Linked Data とは、Web 上のデータをつなぐことで、新しい価値を生み出そうとする取り組みであり、データを共有(公開)し、相互につなぐ仕組みを提供する。Linked Data の4原則として以下がある[9]。
- あらゆるデータの識別子として URI(Uniform Resource Identifier)を使用する。
- 識別子には HTTP URI を使用し、参照やアクセスを可能にする。
- URI にアクセスされた際には有用な情報を標準的なフォーマット(RDF など)で提供する。
- データには他の情報源における関連情報へのリンクを含め、ウェブ上の情報発見を支援する。
Omeka S というソフトウェア上でデータ作成を行うことにより、上記の4原則に即したデータが自動的に作成される。例えば、Omeka S に登録されたアイテム(資料を管理する単位)やメディア(画像や動画など)にはURIが自動的に与えられ、その URI にアクセスすることにより、当該資源に関する情報(メタデータ)が JSON-LD 形式で出力される。なお、JSON-LD とは JSON(JavaScript Object Notation)という軽量なデータ交換フォーマットを利用して、Linked Dataを表現するためのフォーマットである。このデータを介して、アイテム同士の関係やアイテムとメディアとの関係、インターネット上の他のリソースとのつながりを記述することが可能となる。
この Linked Data への標準対応については、RDF(Resource Description Framework)等の要素技術に関する理解が Omeka S の利用にあたって必要となるなど、これまでの Omeka(Classic)が掲げていた「簡易な利用」という特徴が損なわれていると感じる点もある。この点については、Omeka S と Omeka Classic の用途に応じた適切な使い分けが求められる。
Omeka S へのシステム移行
Omeka S に移行する以前のシステムにおいても、登録した画像やメタデータ等の各種データが Linked Data の原則に即して生成・格納されるシステムとして開発してきた。データ管理システムの機能概要を図1に示す。本システムはウェブアプリケーションである。まず、研究者が収集した画像等のメディアをシステムにアップロードする。システム内部では、登録したデータに関する情報が RDF で表現され、RDF ストアに格納される。さらに RDF ストアに対してデータの追加や更新を行うことで、資料の書誌的な情報や、研究メモ等を登録する仕組みを提供する。また、SPARQL という RDF のクエリ言語を使用し、必要なデータを適宜抽出し、データの各種可視化による分析を支援する機能を提供する。
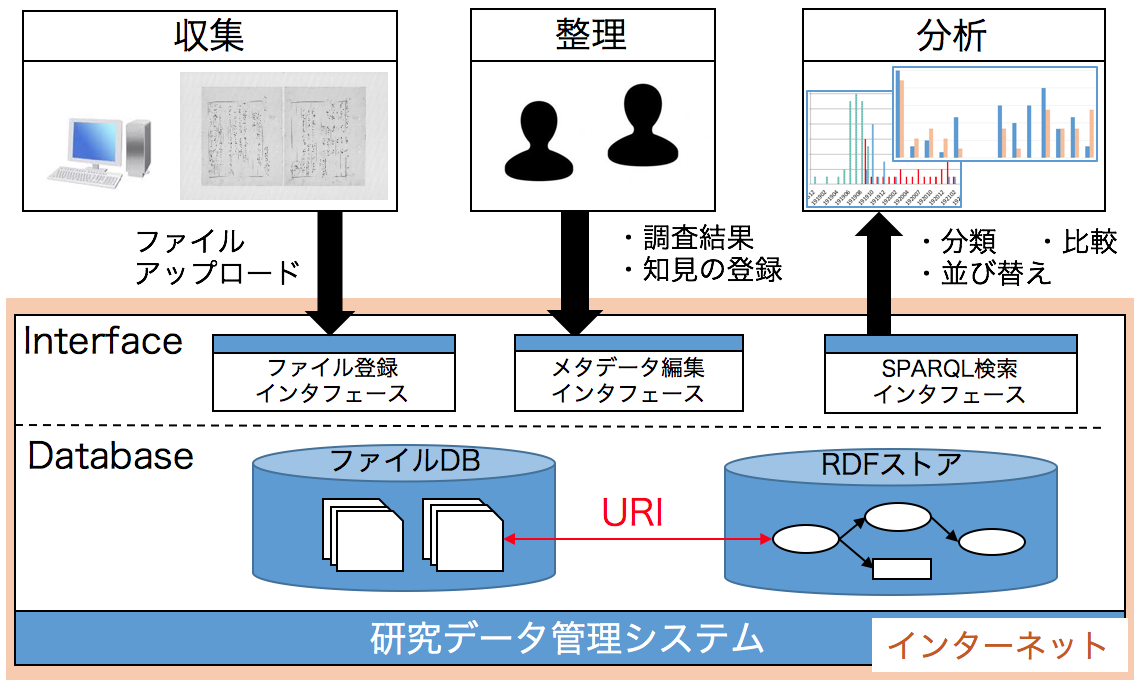
本システムを複数の資料管理・研究事例に適用した結果、登録したメタデータに基づく定量的な比較・分析が容易になるなど、一定の成果を確認することができた。一方、本システムの継続的な維持・メンテナンスが課題となった。本システムは Java を用いて開発しており、レンタルサーバ等でも提供される LAMP(Linux・Apache・MySQL・PHP)環境などに比べ、サーバ管理のコストが高かった。また、より喫緊の課題として、ソフトウェアの開発・改良を担う人的リソースの不足が課題であった。もちろんフレームワークを用いて開発されたシステムではあったが、スクラッチ開発による機能も数多く含まれており、十分なメンテナンスができない状態が続いていた。
このような課題を抱えている中、2017年11月に Linked Data に標準対応した Omeka S が正式にリリースされたことを知り、数ヶ月の機能検証を踏まえ、Omeka S への移行を決めた。
Omeka S を用いたデータ管理システムの試作
ここでは Omeka S を用いたデータ管理システムの試作、具体的には図1で示した機能群について、標準機能と各種プラグインを用いて実現した方法について述べる。
まず、データ管理システムの一機能として、画像や動画等のアップロード機能が求められる。これについては、Omeka S の標準機能を利用することができる。Omeka S ではローカル環境にあるメディアをアップロードできる他、URL 参照による登録、IIIF Image API を利用した画像の登録、YouTube の Video URL を指定した登録などが標準で利用可能となっている。さらに、CSV Import[9][10]というプラグインを利用することにより、CSV ファイル等に記述した複数のメタデータやメディアを一括で登録することができる。さらに、IIIF Server[11]というプラグインを利用することで、登録した画像を IIIF が定める API(具体的にはIIIF Image API と IIIF Presentation API)に準拠して利用することが可能となる。これらの IIIF 準拠画像の閲覧については、Universal Viewer[12]というプラグインを追加することにより、Omeka S 上で Universal Viewer を用いた画像閲覧が可能となる。これらの観点から、少なくとも IIIF 対応が実現できたという点で、既存システムからの移行の利点を確認した。
次に、研究者が目的に応じて画像等の資料に関するメタデータを登録、編集する機能の実現について説明する。Omeka S では Linked Data によるデータ記述が原則となるため、メタデータの項目については、Dublin Core や Bibliographic Ontology、FOAF(Friend of a Friend)等の既存の語彙で定義されている項目(Property)を選択して利用する必要がある。語彙を新規に登録するための機能も提供されており、例えば DC-NDL(国立国会図書館ダブリンコアメタデータ記述)の RDF スキーマ:NDL Metadata Terms(プロパティ・語彙符号化スキーム・構文符号化スキーム)の RDF ファイル[13]をアップロードすることで、本スキーマが定める3つのクラスと77のプロパティが Omeka S から即座に利用可能となる。一方、研究者のニーズは多様であり、独自の項目(プロパティ)を利用したいケースが想定される。この場合には、Custom Ontology[14]というプラグインを利用することにより、利用者が独自の語彙を定義することができる。一方、この場合には「URI にアクセスされた際には有用な情報を標準的なフォーマットで提供する。」という原則を守れないケースが多いため、この点については注意が必要である。このような注意が一部必要ではあるが、研究者の多様なニーズに基づくメタデータ項目を Omeka S で設定できることは、システム移行において重要な点であった。
3つ目の機能である、システムに登録したデータを用いた分析支援、特にデータ抽出の部分については、Omeka S(および Omeka Classic)が標準機能として提供している REST API1[15]を利用する。本 API を利用することにより、外部アプリケーションからデータ抽出および利用が可能となり、各種可視化アプリケーションとの接続が可能となる。また、各種データは JSON-LD の形式で取得することができるため、例えばシステム内のリソース全件を取得し、他の RDF ストア等にインポートすることで、筆者がこれまで開発してきた既存システムと同様、SPARQL Endpoint を介したデータ利用も可能となる。例えば筆者の場合、Omeka S から全件エクスポートしたデータを RDF/XML 形式に変換し、Dydra[16]というクラウド型の RDF ストアに当該データをインポートすることで、SPARQL を用いたデータ利用を行っている。エクスポートすることにより、データの同期性が失われるという課題はあるが、このエクスポートを自動化するプラグインを開発するなどすれば対応可能である。一方、Omeka S の標準機能を利用することで、Linked Data を利用した各種データ処理や利活用ができる点は、システムに登録されたデータに対する多様な観点での共有・分析を実現するにあたり、有益な機能である。
最後に、Omeka S への移行による利点として、メンテナンスコストの低減が挙げられる。コミュニティによって(現時点では)積極的な開発・改良が行われているため、既存のシステムの状況と比較して、ソフトウェアを適切にメンテナンスすることが可能となった。また、自分自身が行うソフトウェアの改良についても、それをコミュニティに還元することができる点は、改良作業を実施するインセンティブにつながっている。さらに、メンテナンスのコスト低減に関しては、Omeka S が LAMP 環境で実行可能なソフトウェアである点が大きい。本システムの例ではレンタルサーバに移行することで、サーバのメンテンナスコストを大幅に下げることができた。もちろん、サーバの性能の低下による問題(動作速度の低下など)も生じ得るが、その場合には高性能なサーバに移行するなど、用途に応じて利用する環境を選択可能となった点が、既存システムからの移行に伴う利点の1つである。
まとめ
本稿では、Omeka S の機能紹介を行うとともに、システム移行の理由や Omeka S を用いる利点について述べた。本稿で述べたシステムの移行にあたり、Omeka コミュニティの関係者、開発者の方々に深く感謝する。このようなソフトウェアが OSS として開発、利用可能であることは、DH の実践と発展に多大な効果をもたらしている。自分自身もこのような DH の基盤として機能しうる技術開発に貢献していきたい。なお、筆者はソフトウェアのスクラッチ開発を否定するわけではなく、筆者が今回直面した、開発リソースが限られた環境においては、Omeka 等のパッケージシステムの導入による利点が大きかったことを報告した次第である。
最後に、Roy Rosenzweig Center for History and New Media が同様に開発しているソフトウェアである Tropy[17]との違いについて、簡単に触れておきたい。Tropy は史料画像を管理するためのソフトウェアであり、本稿で紹介したデータ管理システムと同様の目的を有するシステムである。また、Omeka がデジタルコレクションの構築やオンライン展示を意図したシステムであり、Tropy から Omeka S にデータをエクスポートする機能が提供されていることを踏まえると、史料の収集・管理の過程で使用するソフトウェアとしては Tropy のほうが適していると言えるかもしれない。現時点では Tropy はローカル環境のみで利用可能なソフトウェアであるため、複数研究者による共同作業やデータ共有は難しい。この観点から現時点では Omeka を採用したが、クラウド版の Tropy が開発された際などには、改めてシステム選定を行う必要があると考えている。
執筆者プロフィール
- コメントを投稿するにはログインしてください