人文情報学月報第128号【後編】
ISSN 2189-1621 / 2011年08月27日創刊
目次
【前編】
- 《巻頭言》「情報学的手法は文献研究をどのように変えるか?」
:京都大学白眉センター・人文科学研究所 - 《連載》「Digital Japanese Studies 寸見」第84回
「DH Awards 2021開催」
:北海学園大学人文学部 - 《連載》「欧州・中東デジタル・ヒューマニティーズ動向」第45回
「ユトレヒト大学のデジタル・アーカイブにおける新発見キリシタン版の画像公開:附・発見者のスヱン・オースタカンプ教授へのインタビュー」
:京都大学大学院文学研究科附属文化遺産学・人文知連携センター
【後編】
- 《連載》「デジタル・ヒストリーの小部屋」第3回
「フルコースにレシピを添えて:Journal of Digital History 誌のねらいと意義」
:千葉大学人文社会科学系教育研究機構 - 人文情報学イベント関連カレンダー
- イベントレポート「シンポジウム「古辞書・漢字音研究と人文情報学」」
:東京大学大学院人文社会系研究科 - イベントレポート「第11回知識・芸術・文化情報学研究会」
:岡山大学大学院社会文化科学研究科 - 編集後記
《連載》「デジタル・ヒストリーの小部屋」第3回
「フルコースにレシピを添えて:Journal of Digital History 誌のねらいと意義」
前回は、デジタル時代における史料の「歪み」について、Ranke.2や Geben Zaagsma の論を引きながら、文書館のデジタル化方針における記憶の政治力学や国家戦略の影響を中心に考察した。今回は、このような「歪み」とどう向き合うのかについて、とくに近年のデジタル・ヒストリーで注目すべき学術誌 Journal of Digital History のねらいから考えていきたい。
「科学」としての歴史学
さて、そもそも、ここまで述べてきたような史料における「歪み」はなくなるものではない。誰かが残し、誰かが読み、誰かが解釈し、誰かが選び、誰かがデータ化し、誰かが言語化するのであるから、過去に起こったできごとがまっすぐにくもりなく伝えられていると考える方が難しい[1]。このような曖昧さを有する歴史学を、客観的な科学であるとする立場をとる遅塚は、次のように述べている。
ふつう、学問における客観性というのは、そこで提示された命題(proposition, 研究者のおこなった判断を言語で表現したもの、平たく言えば見解)が、だれにでも積極的に支持されうることだと考えられている。水は100℃ で沸騰するという命題は、だれが試してみても必ずそうなる(普遍妥当的で、かつ必然的である)から、客観的な命題なのだ。ところが、歴史学の対象は、過ぎ去って二度と還らぬ過去の事実であるから、それについて提示された命題をもう一度試してみる(追試験する)ことができない。つまり、歴史学上の命題は、追試によって積極的に(ポジティヴに)証明され支持されることができない。しかしながら、その命題は、消極的に(ネガティヴに)受容され支持されることはできる。つまり、提示された命題に対して、さしあたり、だれも「反証」(反対の論拠)を挙げて論破することがないならば、その命題は、その当座、消極的に受容され支持されているという意味において、客観性を有すると言えるのだ。したがって、歴史学は、そこで提示された命題が公衆の自由な討議に付されて、その命題の「反証可能性」(falsifiability, だれでもが反証を挙げてそれを論破しうる可能性)が保証されているかぎり、消極的にではあれ、客観的な科学と見なされてよいのである[2]。
ここで注目しておきたいのは、遅塚の言う科学としての歴史学の「消極的」客観性が担保されるには、命題に対する反証可能性が保証されていることが必要であるという点である。そのためには、たとえばどのような史料に基づいて立論したのか、その史料の所在はどこで、どのように閲覧可能で、史料的性質からしてどのような限界があり、どのような理論的枠組みを通してその史料を読み解いたのか、など歴史研究者としての自らの手の内を開示することによってまず検証可能性を担保しておくことが必要である。それによって、他の研究者が新しい視角から立論するための参照軸を示すことになり、議論の土台ができ、結果的に反証可能性が生まれると考えて良いだろう。
「デジタル解釈学」と手の内を開示するための論文出版モデル
さて、デジタル・ヒストリーの登場によって、前述のような科学としての歴史学の反証可能性を担保する手立ては増えたと言って良い。つまり、デジタル化された史料から抽出したテキストデータや地理情報データなどを対象に、ソフトウェアやプログラミングを用いた分析によって史料の読解・解釈を補強するような手法を導入するデジタル・ヒストリーは、その過程において研究の副産物としての基礎データやプログラミングのソースコードなどが生成されるため、それらが新たな検証材料として第三者に提供されることが増えてきたのである。もちろん、この文脈において、研究データ管理を志向する大学機関リポジトリの整備や、コンピュータを用いた分析に有用な構造化データなどを公開してオープンサイエンスを促進させることをねらうデータ・ジャーナルの存在が重要なことは言うまでもない。ややシニカルな見方をすれば、機関リポジトリやデータ・ジャーナルは、このような新たな検証材料を研究の「副産物」と位置づけ、たとえば紙幅の都合などの理由で歴史研究の「本体」としての叙述と切り離して、あるいは切り離さざるを得ないものとして、提示しようとする営みであると考えられる。
これに対して、今回紹介したい Journal of Digital History(以下、JDH)誌のねらいは、歴史叙述とそれを支えるデータや分析手法のソースコードを同等に扱い、これらの層を柔軟に行き来しながらその議論を検証できる環境を用意しようとすることにある。以下では、JDH 誌の創刊号に採録された編集方針を明示した論考の内容を中心に紹介し[3]、適宜補足を加えていくこととしたい。
まず、JDH 誌の構成の独特な点として、図1のように掲載論文すべてに叙述層 narrative layer と解釈学層 hermeneutics layer が用意されており、クリックひとつで動的にそれらの層を行き来しながら歴史叙述とそれを支えるデータ分析の過程を検証できるようになっていることがある。なお、解釈学層には、Jupyter Notebook が採用されており、Python のプログラミング言語としての学習コストの低さやコードの再現性の高さがその選定基準であるとされている。

この構成の意図を理解するには、その背景にある理念「デジタル解釈学 Digital Hermeneutics」について触れる必要がある。一言で言うならば、「デジタル解釈学」は、デジタル・ヒストリーの研究過程のあらゆる局面においてデジタル技術・手法がどのような影響を及ぼしているかを詳らかにしようとする態度のことである。すなわち、データベースにおける検索アルゴリズムの仕組み、分析に用いたソフトウェアなどのツールの挙動、データ可視化モデルの長短といった、研究成果が生み出されるまでの道のりを記録し、自分自身にも他者にも透明性を担保し、まさに検証可能性を確保しようとする営みであると理解できる[5]。
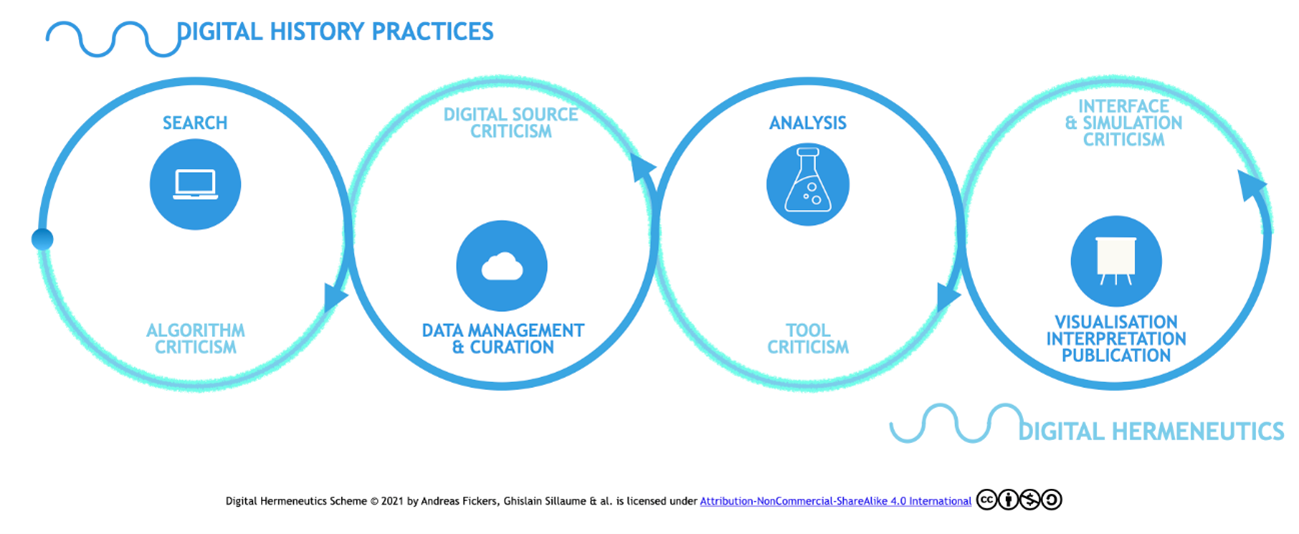
「デジタル解釈学」を重視する立場の研究者や JDH 誌が問題視するのは、歴史研究の成果を出版する際の定番かつ権威的な形態であるモノグラフや査読つき雑誌論文が、歴史叙述を支える文学的表現と論拠に基づいた議論に焦点を絞ることで、分析の最終成果物や要約そして物語的叙述を提示するにとどまり、デジタル環境における情報検索やデータ分析の道筋とその妥当性を議論するに至らず、結果的に研究過程におけるブラックボックスを生じさせてしまっているということである。このことは、今やほとんどすべての歴史研究者が、デジタル・ヒストリーの実践者であるかどうかに関わらず、何らかのデジタル技術を用いて検索・分析を実践している事実からして[7]、不健全な状態にあると言うべきであろう。
まとめると、このような「デジタル解釈学」の理念を具現化するために JDH 誌が提供するのが、図1に示した多層的な論文出版プラットフォームであり、ここでは研究の到達点とそこに至る道筋、その道のりを踏破するために用いた道具のすべてを、著者の案内を頼りに読者がたどれるようにすることが目指されている。注目すべきは、読者の関心に応じて、しかもクリックひとつで、叙述とデータを動的に切り替えられるようにすることで、解釈を説明するための貴重な紙幅が、読者によっては退屈に感じる手法の説明によって圧迫されてしまうことを見事に回避できている点であると思われる[8]。さながら、料理のフルコースを楽しむことに重きを置くならばそうすれば良いし、ひとつひとつの料理の原材料や作り方が気になるならばそれをいつでも確認できるレシピが傍らに用意されているといった趣だろうか。
おわりに
歴史学の科学的客観性を支えるための検証可能性、ひいては反証可能性を保証するための手立てとしての分析手法の開示という営みは、デジタル・ヒストリーの実践における「デジタル解釈学」という理念を背景として開発された JDH 誌の層状の出版プラットフォームによって、その重要性が実践的に可視化されたと言ってよいだろう。なお、このような取り組みは、デジタル・ヒストリーだけでなくデータ・ジャーナリズムの分野でも見られ、ここでも Jupyter Notebook が用いられている点で共通している[9]。
たしかに、手法の再現・検証・反証可能性を担保しようとすることは、学問の科学性を保証することに躍起になっているとシニカルに捉えることもできるだろう。しかし、研究手法をひろく共有し、研究過程におけるブラックボックスを解消しようとする行為は、関心ある後進の研究者が同様の取り組みをしやすくなる土台を作ることになり、結果的に学問のすそ野を広げることにつながるのではないだろうか。
人文情報学イベント関連カレンダー
【2022年5月】
-
2022-5-21 (Sat)
第129回人文科学とコンピュータ研究発表会於・オンライン
Digital Humanities Events カレンダー共同編集人
イベントレポート「シンポジウム「古辞書・漢字音研究と人文情報学」」
2022年3月10日に、シンポジウム「古辞書・漢字音研究と人文情報学」がオンライン(Zoom)で開催された。本シンポジウムは、池田証壽氏が代表を務める基盤研究(A)「平安時代漢字字書総合データベースの機能高度化と類聚名義抄注釈の作成」と、藤本灯氏が代表を務める基盤研究(B)「『色葉字類抄』の語彙研究および総合データベースの構築」の共催によるものである。また、この他に3件の科研費の協力があり、そのうちの2件は漢字音のデータベース構築に関わる研究で、午後の部の後半に発表があった。常時70名以上が参加しており、最大接続人数は80名を超えた。質問も多く上がり、またチャット欄での議論も活発に行われた。
プログラムは、ウェブサイト「平安時代漢字字書研究」に公開されている。午前に3件の発表、午後に4件の発表と1件の講演があり、その後懇親会が開かれた。
以下では、各発表について、簡単な紹介と所感を述べさせていただく。ただし、加藤大鶴氏ほか計四名の先生方による発表ならびに関連するプロジェクトについては、筆者の専門領域と深く関わるため、稿を改めて紹介させていただくこととしたい。
中野直樹氏の発表では、近世中期の画引き字典である、毛利貞斎『増続大広益会玉篇大全』(以下『玉篇大全』と略す)について、研究史を踏まえた丁寧な解説が行われ、また最後にデータベースの構築案が示された[1]。『玉篇大全』は、『和玉篇』のような多くの和訓を付す形式と、中国の字書の本文をそのまま活かす形式との、両タイプが融合した「近世期における字書のひとつの到達点」であり、「典拠が明確な読みを豊富に提供できる」点に、データベース作成上の価値が見出せるという。他の古辞書データベースとの連携において、「掲出字」ではなく「和訓」を共通キーとする構想が示されたが、仮名遣い等の問題をどう解決するかという質問もあった。
小林雄一氏の発表では、鎌倉時代の語源辞書で、天下の孤本として知られる『名語記』について、注釈構造を中心とした総合的な解説がなされた。出典が明示されていないものの『色葉字類抄』の利用が推定される記述があることについて、曖昧性をふくむ情報をデジタルでどう表現するかという質問があった。明示されない間接引用は、多くの古文献に認められるところであろうから、日本の古典籍の構造化にあたっては重要な問題となろう[2]。
古代日本史を専門とする本庄総子氏の発表では、「疫癘(えきれい)」「時行」といった疾病関連語彙の資料的・年代的な偏りと、疫病観の変遷との関連についての問題が取り扱われた。歴史学の立場から、漢語の受容史や言語生活史の一面を考察したものであり、大変興味深く拝聴した。
李媛氏・池田証壽氏の発表では、平安時代漢字字書総合データベース(HDIC)のうちの観智院本『類聚名義抄』のデータ[3]について、作成中の注釈や、GlyphWiki を活用した字形再現の方法の紹介がなされ、また本方法に拠って掲出字の排列について共通する字形構成部分をグループ化する試みも行われた。質疑応答では、「とめはね」等のどのレベルまでを字形差と考えるかについて、議論が起こった。
申雄哲氏・劉冠偉氏による発表では、前半では申氏によって、図書寮本『類聚名義抄』のテキストを構造化する試みが紹介された。後半では劉氏によって、申氏が作成した出典情報[4]を、D3.js という JavaScript ライブラリを用いて可視化する試みが示され、大いに目を引いた[5]。1950年代に吉田金彦氏によって手書きで発表された論文[6]が、発展継承され、このような形でビジュアライズされたことに、人文情報学の真髄を見たような気さえした。今後の課題としては、国会図書館デジタルコレクションに公開されている複製本画像との連携が挙がっていた。
澤田達也氏の発表では、原本系を中心とする『玉篇』の佚文(諸資料に引用される形で伝わっている文)について、諸先学による成果を統合し、横断的な検索を可能にするシステムの紹介がなされた。また、大谷大学図書館蔵『三教指帰注集』の成安注に引かれた佚文の考察では、『篆隷万象名義』とも宋本『玉篇』とも一致しない反切注の存することが示された。字体情報の示し方についての議論が、チャットで盛り上がった。質疑応答で交わされた、データ公開の在り方を巡る議論も興味深いものであった。
永崎研宣氏による講演では、古文献の文字情報をどのようにデータ化し、共有していくべきかについて、具体的な提言がなされた。文字については、表現可能な場合は Unicode/IVS に従うことが望ましく、また文字情報の構造化については「共通の記述ルール」を共有することが重要とのことであった。データ公開にあたっては、長期保存のためには「公開システム」と「研究データ」を別にすることが肝要であることが強調され、生データを公開する場としての各種リポジトリや、周知のための各種カタログサイトが紹介された。
最後に、全体の感想を述べたい。漢字系のシンポジウムはいくつかあるものの、研究成果の発表に留まらず、技術面などの実際的な問題について、一般の方も参加可能な形で広く議論できる場は、貴重であるように思われる。加えて本シンポジウムは日本語史に特化した発表が多く、議論も盛んであったため、自らの研究にも活かしうるような知見が多く得られ、大変勉強になった。懇親会でも、様々な情報交換を行うことができ、刺激的なー日となった。同様のシンポジウムが今後も開催されてゆくことを切に願う。
イベントレポート「第11回知識・芸術・文化情報学研究会」
情報知識学会による第11回知識・芸術・文化情報学研究会[1]は、2022年2月12日にオンラインで実施された。鎧兜のデジタルコンテンツの作成や、寺院壁画レリーフのセマンティック・セグメンテーションなど、情報処理の知識を使用した芸術や文化を対象とする9件の発表があった。このうち、江戸時代の漢文小説を研究する報告者にとって印象深かった相田愛子氏の発表に関する報告を行う。
相田氏の発表のタイトルは「『法華経』の和歌と絵画のテキスト解析を通じた分析」であった。『法華経』とは、『妙法蓮華経』の略称であり、大乗仏教初期にインドで成立した経典とされる。すべての仏教テキストのうちでも、もっとも重要な経典の一つである。相田氏は、『法華経』の8巻28品を27の主題に分類した。そして、平安時代から室町時代までの約500年にわたる二十一代集から312首、私撰集から189首、私家集から475首、定数歌から363首、 合計1027首の『法華経』を主題とする和歌(法華経歌)を対象として分析した。
私撰集のデータは、国歌大観で対象となる和歌を選定した後、日文研の「和歌データベース」[2]からテキストを取り込んで作成された。『法華経』の各巻各章に対応する和歌のデータベースを作成した後、MATLAB R2020a でテキスト解析をしていた。MATLAB の Text Analytics Toolbox では、日本語の形態素解析器として MeCab が使われている。品詞情報を用いて単語の選別を行う際に、これは非常に便利である。『法華経』における単語の品詞情報を得た後、全体的な特徴を分析するため、N-gram によって頻出語を出していた。特に名詞や名詞句に着目すると、1-gram で最多の名詞は、130回の「法」、最少は17回の「そら」であった。名詞のみでは23件が抽出できたが、これらは非常に一般的な名詞用語である。一語としては、特定の主題に結びつけることが困難である。そのため、名詞以外の修飾語や文脈などによって、特定の主題を分析する必要がある。例えば、「雨」や「裏」など漢語に基づく名詞を分析しながら、名詞と助詞の組み合わせから歌言葉と掛け言葉の関連性を研究していた。
次に、名詞と助詞の組み合わせを分析するため、2-gram での分析が行われた。しかし、名詞の数が多く煩雑な結果しか得られなかった。続いて、3-gram で最多の組み合わせは19回の「わしの山」、最少は3回の「夢の中」、「しかのその」、「みつの車」などであった。名詞句は49件を抽出できた。相田氏はこれらの名詞や名詞句が『法華経』のどの主題に結び付いているかを考察し、7種の頻出句と主題の関連性を明らかにした。
一方、同時期に成立した『法華経』を主題とする絵画「法華経絵」についても分析されていた。『法華経絵』におけるモチーフと特徴語を比較することで、絵と言葉の対応関係を示すことが目的である。例えば、「紺紙金字法華経巻第一」では、「法の花」、「御法の花」のような言葉が、見返絵の花の絵と対応している[3]。このような言葉と絵画の対応は、仏教説話画から世俗画への広がりを解明するための手掛かりとなる可能性がある。
今回相田氏は、法華経歌の頻出句と主題との対応、法華経歌の特徴語と『法華経絵』のモチーフの対応を明らかにした。まだ解明されていない対応関係を、今後も研究していくと述べていた。
本研究会は、研究者間で新たな知識や技術などを共有する機会となっていた。報告者にとって一番勉強になったことは、国歌大観から和歌テキストを取り込み、整理する手順である。そして、MATLAB R2020a の使用方法も理解することができた。報告者の研究の中にも同じ作業があるため、相田氏の手法を参照に、これらの技術を取り入れていきたい。
◆編集後記
いよいよ2022年度を迎えることになります。2021年度も継続したコロナ禍で、若干の対面会合はあったものの、 やはりオンラインでの会合が主でした。筆者も国内外の大学や学会で話をする機会が色々ありましたが、 いずれもオンラインで、用事が終わるとコミュニケーションが切れてしまうので、これまでのような つながりを作ることがなかなか難しい、と感じながら2021年度を過ごしました。 さりとて、オンラインでの会合やイベントは、今後は一定条件下で定着していきそうです。 昨日・一昨日は、京都大学の関連部局の主催で TEIのワークショップをオンラインで開催させていただきましたが、世界中からの参加があり、 対面ほどの濃密さは実現できなかったとは言え、やはり、必要な情報を入手するに際して 住んでいる場所を考慮する必要が大きく減ったことは、これも今更ではありますが、 大きなメリットだろうと思います。ですので、そのような場合に事後もコミュニケーションを 継続させるための振る舞いなど、オンラインコミュニケーションでの弱いところを フォローする方法をお互いに意識していくことが重要であると改めて思ったところでした。
そのようななかで、2022年度は、国際デジタル・ヒューマニティーズ学会連合ADHOによる 国際学術大会、DH2022がオンラインで開催されます。オンラインでの国際学会は時差の調整が 難しいところがありますが、今回は主催が東京ですので、日本の人には参加しやすい時間帯に なっています。このこともめったにない機会ですので、ご都合があう方におかれましてはぜひご参加いただければと思います。
(永崎研宣)
- コメントを投稿するにはログインしてください