人文情報学月報第163号
ISSN 2189-1621 / 2011年08月27日創刊
目次
- 《巻頭言》「哲学的議論を踏まえた文献検索の可能性」
:九州大学人文科学研究院 - 《連載》「欧州・中東デジタル・ヒューマニティーズ動向」第79回
「ノーコードで RAG を利用した人文学のための AI アプリケーションを作る」
:筑波大学人文社会系 - 《連載》「英米文学と DH」第2回
「ハティトラスト・リサーチセンター」
:中央大学国際情報学部 - 人文情報学イベント関連カレンダー
- 編集後記
《巻頭言》「哲学的議論を踏まえた文献検索の可能性」
文献を簡単に探したい。これはどんな研究者でも一度は考えたことがあるだろう。筆者は20世紀以降の現代の英語圏の哲学・倫理学を専門としており、現在は哲学・倫理学の文献のデジタル化及び検索システムの構築を目指している。
最初に20世紀以降の英語圏の哲学・倫理学文献のデジタル化について私が把握している限りで、簡単に述べておきたい。論文に関してはデジタル化及びオープンアクセスは整備されつつあると言ってもよいだろう。欧米語論文は約15年前に設立された PhilPapers[1]と呼ばれるデータベースにおいて、日本語論文は J-STAGE において文献情報やオープンアクセス化された論文の掲載、あるいはリポジトリへのアクセスの導線がなされている。とはいえ、哲学・倫理学の教育・研究においては、論文以上に書籍へのアクセスが重要である。それは、一つの立場や理論を形成する議論は論文でその萌芽が示され、書籍で紙幅を割いて論ぜられることが多いためである。書籍に関しては、欧米語のものはデジタル化が進みつつあると言えるだろう。20世紀までの欧米語の書籍は Project Gutenberg や JSTOR でのオープンアクセスが進んでいる。それ以降のものは、それぞれの哲学者のいわゆる主著とされる著作のデジタル版が各出版社あるいは Kindle で出版されているケースが多い。一方で、日本語の書籍のデジタル化は進んでいない。2010年代以降に出版されたものや文庫、新書はデジタル版も発売されるケースも増えてきている。しかし、それ以前のものは訳書を中心に学術的に価値のある文献であってもデジタル化されておらず、紙の書籍も絶版になり容易に入手できなくなりつつある。
また、哲学・倫理学の研究に必要な文献を効率的に検索することも困難である。というのも、哲学・倫理学においてより重要なのは結論自体ではなく、その結論が導出される論証の方だからである。そのため、研究に資するには、どのような主題についてのどのような結論か以外にも、どのような根拠からどのような論証によってその結論が得られたのかが検索できる必要がある。
第一段階として、文献をデータ化し、全文検索を可能にした。上記の PhilPapers も含め、従来の文献検索の方法はタイトルや著者名、要約といった書誌情報に基づく検索に限られていたが、本文内の特定の語句を直接検索できるようにした。これにより、特定の主題が論じられている文献をより的確に検索することを目指した。しかし、全文検索には「特定の単語が登場する文献が内容に問わずヒットしてしまい、実際に関連する内容の文献かどうかの判断が難しい」という問題があった。
この問題を解決するために、第二段階としてテキストマイニングを用いて抽出されたキーワードによる検索を試みた。キーワードを用いることで、特定の主題や議論に関する文献をより精度高く検索できるようになることが期待された。しかし、キーワード抽出には、単純に頻度の高い語をキーワードとすると、議論構造を正確に捉えられないという課題が見られた。例えば、中絶に関する倫理的な議論では、「権利」「原則」「生命」などの語が頻出するが、これらが中絶の擁護、中絶の批判、これまでの議論のまとめといった、どのような結論を導くために用いられているのかは、文脈を考慮しなければ正確に分類できない。
この問題をさらに解決するために、第三段階として ChatGPT を活用した文献分類を試みた。ChatGPT により、文献を「中絶を擁護する論文」「中絶を批判する論文」「これまでの議論をまとめた論文」の3つに自動分類するプロセスを導入した。この方法では、まず ChatGPT による分類を実施し、それを基に各カテゴリーに特徴的なキーワードを抽出する。その後、得られたキーワードにより、新たな文献を機械的に分類するシステムを構築した。得られたキーワードは妥当なものだと思われる一方で、分類結果を検証したところ、一部で誤分類が発生する問題も確認された。
特に「消極的議論」の分類が難しい点が課題となった。例えば、ある論文が中絶擁護論への反論を中心に展開する場合、その文献の主張は中絶を批判するものであるにもかかわらず、擁護論のキーワードが多く含まれるために、誤って中絶を擁護する論文として分類されてしまう。また、倫理学の議論は多くの場合、異なる立場の主張を比較検討する形をとるため、一つの論文の中に複数の立場が混在していることが多い。こうした複雑な議論構造を機械的に分類することには、依然として課題が残る。
ChatGPT による分類結果を基にしたフィードバックとキーワードの見直しを進めることで分類の精度を向上させ、より正確な分類が可能になることが期待される。さらに、分類結果を確率的に表示し、論文の議論構造をある程度反映させる試みも行った。例えば、ある論文が「擁護論60%、批判論30%、議論のまとめ10%」と分類される場合、それの論文は完全に擁護論ではなく、批判論の視点も含むことを示すことができる。一方で、この分類結果を文献の検索にどう落とし込むかが課題であった。
行き詰まっていたところ、12月21日に開催された「仏教研究と DH 国際シンポジウム」に参加した。そこで西洋古典特化型 AI「ヒューマニテクスト」に関する発表を聞き、現代哲学・倫理学の領域でも議論を踏まえた文献の構造が可能なのではないか、と光明を見た気分であった。今後は文献のデータ化を進めつつ、RAG を用いた文献検索システムの構築を目指していきたいと考えている。
執筆者プロフィール
《連載》「欧州・中東デジタル・ヒューマニティーズ動向」第79回
「ノーコードで RAG を利用した人文学のための AI アプリケーションを作る」
現在、文献言語の教育や、消滅危機言語の保存継承の分野では、大規模言語モデル(LLM)を活用した AI アプリケーションの導入が新たな研究手法を開拓しつつある。特に、専門知識を検索拡張生成(Retrieval-Augmented Generation; RAG)によって、LLM に与え、研究に活かす手法は、デジタル・ヒューマニティーズ (DH) の分野でも徐々に普及しつつある。例えば、慶應義塾大学および人文情報学研究所の永崎研宣氏による仏教研究支援用ボット・バウッタ AI はその一例である[1]。
最近では、さらにノーコードで AI を開発できるプラットフォームが登場したことによって、プログラミングの専門知識を有しない研究者でも、歴史文書の分析や言語学習の支援などに積極的に AI を利用できるようになってきている。こうした AI プラットフォームとして注目されるのが Dify[2]と Miibo[3]である。
Dify はオープンソースの AI アプリ開発環境を提供している点が最大の強みである。ユーザはクラウド上、あるいはオンプレミスで Dify を動かし、コードを書くことなく AI ワークフローを構築することができる。また、視覚的なノードエディタを用いて、ユーザ入力を受け付けるステップや外部ツールとの連携、そして LLM を呼び出すタイミングを設計し、それぞれを連結して一連の対話処理を形作ることができる。複雑な解析を要する領域でも、直感的な操作で機能を拡張可能であり、さらには LLM 自身に外部APIを使わせる設計も実現しやすい。オープンソースであるため拡張性が高く、多数のプラグインを追加したり、自前のベクトル検索システムと組み合わせたりといった柔軟な運用が可能となっている。研究者が自らの専門領域のデータを組み込む場合にも、ベクトルデータベースを用いた RAG のパイプラインを手軽に整備できる点は大きな利点である。
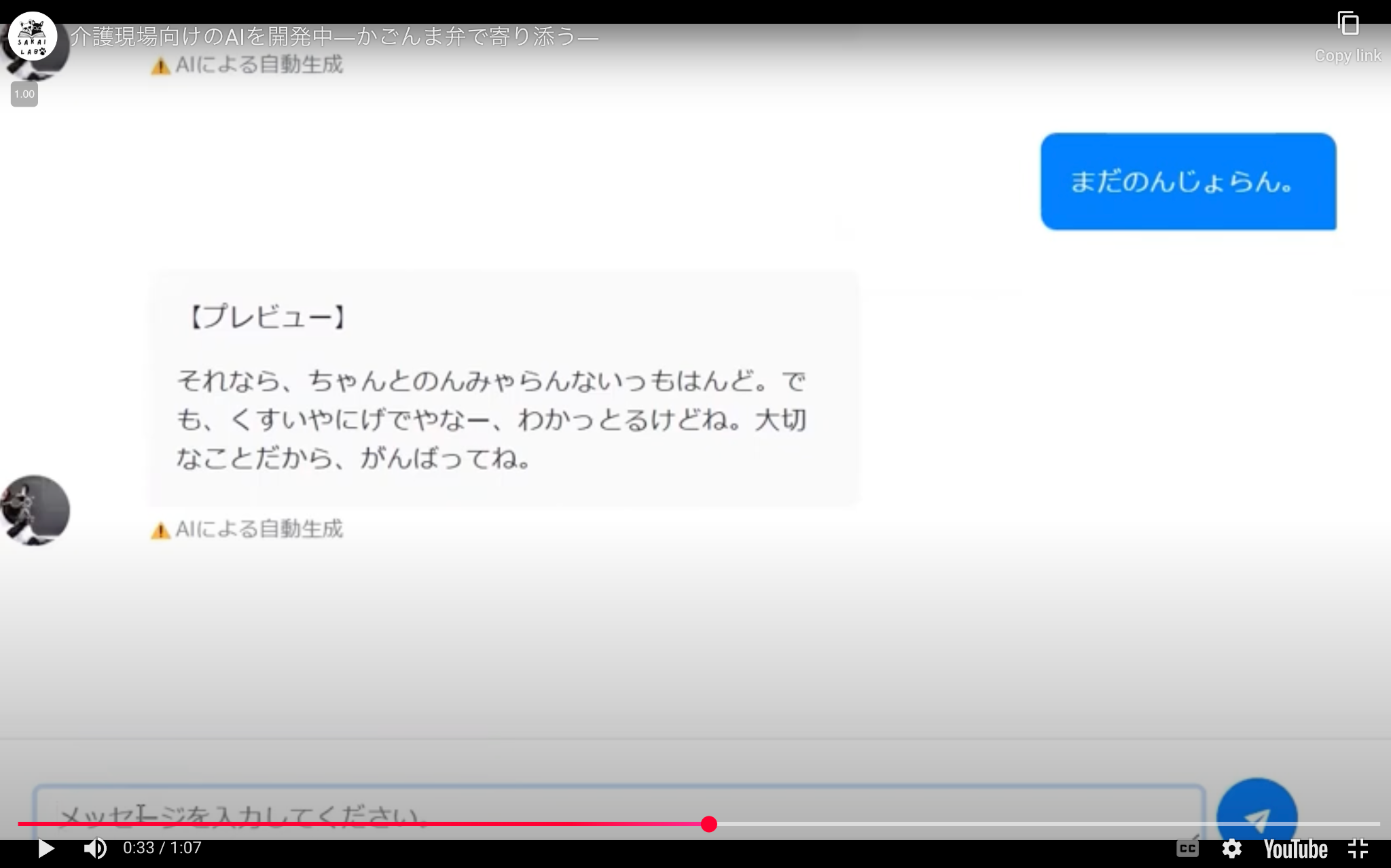
一方、Miibo は誰でもすぐに会話型 AI を作ることができる点に特化しているプラットフォームである。高度な対話管理や豊富なテンプレートが揃っているため、研究者はシナリオベースの対話フローを視覚的に編集しながら、研究や教育に使えるチャットボットをスピーディに作ることができる。LINE や Slack など既存のコミュニケーションツールとの連携が容易で、受け答えのパターンを分岐して細かく制御したい場合などに適している。対応可能な LLM も複数揃っており、GPT-4o や Claude 3.5 Sonnet などを切り替えながら実験し、どのモデルが自分の研究対象に最適なのかを比較検討することも可能である。複雑なプログラミングなしに高度な AI 対話サービスを自分の専門分野に合わせて展開できるのである。例えば、消滅危機言語の保存・継承の分野では、鹿児島大学の坂井美日氏が率いるチームが、Miibo を活用した、鹿児島方言対話ボット (図1) を開発している[4]。
AI アプリを実際に開発する際には、まずどのようなタスクを自動化したいかを明確化し、それに応じてプラットフォームを選ぶ。Dify はワークフロー構築の自由度が高く、ベクトルデータベースとの統合による検索拡張が充実している。RAG を使うことで、専門性の高い文書や未公開アーカイブを取り込んだ状態で AI 応答が得られる仕組みを手早く実装できるのが大きい。Miibo は会話型シナリオを構築するときの利便性に優れ、膨大なチャットフローを設計しても管理画面から把握しやすく、テンプレート機能も充実している。どちらもノーコード開発という点が共通しており、専門知識のない研究者でも、短期間で AI アプリを作成し運用に乗せることができる。
さらに、RAG のメリットを活かせば、学術的な裏付けを持つ回答を AI が返してくれるようになる。AI はときにハルシネーションを起こしがちであるが、RAG のプロセスではあらかじめ登録した信頼性の高いデータベースを検索し、その検索結果を踏まえたうえで AI が応答を生成するため、回答に根拠を示しやすくなる。人文学のプロジェクトにおいては、資料の出典確認や参考文献の明示が必須な場合が多い。したがって、RAG の導入は研究者にとっても安心感が大きく、AI が提示した情報がどの文献のどの箇所から引用されたのかをチェックしながら共同作業を進められるメリットがある。このような文献資料に基づく RAG が手軽にできるものとしては、Google が提供している NotebookLM[6]がある。
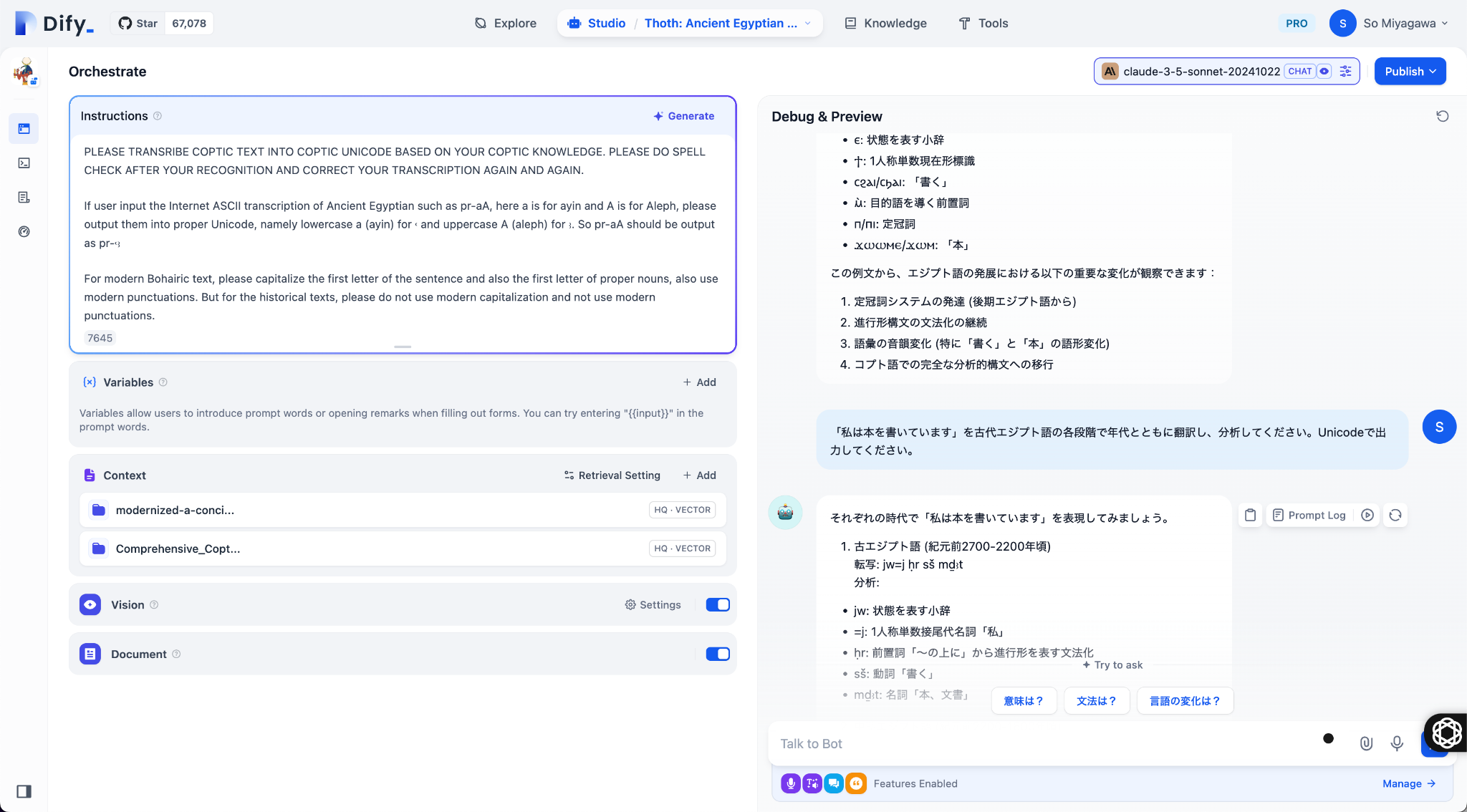
今回、筆者は、Dify 上で古代エジプト語・コプト語の分析を行う THOTH AI[7](図2)を作成した。これは Dify を活用して構築された AI アプリケーションで、Claude 3.5を基盤としながら、研究者が保有している文法書や辞書、翻訳資料をベクトルデータベースに登録して RAG を実装している。ユーザから古代エジプト語やコプト語の文章を入力された際に、AI が OCR や文法解析を行い、語彙の対応関係を調べながらそれぞれの時代の古代エジプト語の注釈付き翻訳などの応答を返す仕組みになっている。THOTH AI の開発運用においては、データの信頼性と AI のハルシネーションへの対応が課題として挙げられる。RAG により専門的資料を取り込むことで AI の回答精度が上がる一方、引き続き出力内容を専門家が検証する工程は欠かせない。学術分野では誤訳や誤った語源解釈が大きな問題を引き起こす可能性があるため、最終的な判断を専門家が下す体制を組み込みつつ、ユーザからのフィードバックを集めて AI を日々改善する必要がある。これはまさに DH における AI 活用の新しい形であり、AI と人間の協働を継続的に試行することで、より正確で専門性の高い研究支援ツールとして成熟していくことが期待される。
また、Dify や Miibo のようなノーコード AI プラットフォームは、一般企業や公共機関などでも導入が進んでおり、ユーザ・コミュニティが拡大することで新しいプラグインや連携サービスの開発も活発化している。結果として、自前で構築せずともプラットフォームに追加された機能をすぐに利用できる可能性が高まっていく。たとえば、OCR や機械翻訳の高精度化、複数言語を横断する検索や音声入力など、研究者が必要とする機能が取り込まれていくことで、学術用途の AI アプリ開発が容易になるだろう。
このようなノーコード AI プラットフォームの出現により、DH での AI の活用が大幅に増える可能性がある。AI アプリ開発のハードルが下がり、必要なデータさえあれば、誰でも AI でアプリを開発できる時代が到来している。この流れを利用して成果を上げるためには、AI の出力を正しく批判的に評価し、人間が専門知識と洞察力をもって最終判断を下す姿勢が欠かせない。AI は便利である一方、AI を無条件で信用するのではなく、ユーザが主体性を保ちながら AI を育成・活用していくことが重要である。そうした相互補完のあり方こそが、DH における AI 活用をより豊かにし、学術研究の地平を切り開いていく原動力となるに違いない。
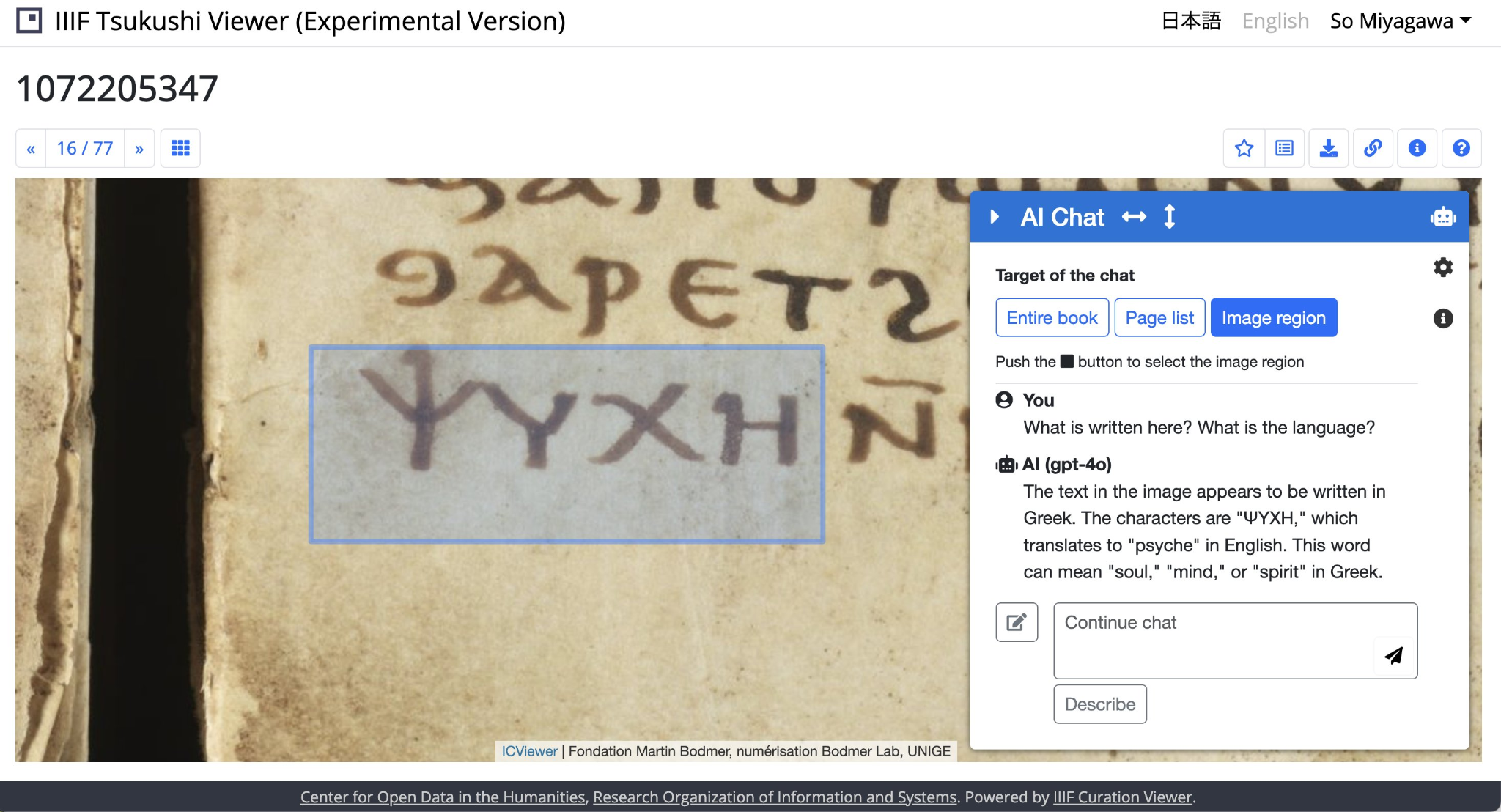
今後は AI モデルの高性能化とともに、マルチモーダルな資料分析を取り入れた研究も活発化していくと考えられる。文字情報だけでなく、画像や音声、動画といった異なるメディアを横断して情報を統合し、それを LLM が総合的に理解して回答する場面が増えるはずである。マルチモーダル解析をノーコードで提供できるようになれば、たとえば古文書をスキャンした画像を解析し、文脈を踏まえて歴史的背景を紐解くようなアプリも容易に構築できるようになるだろう。古典籍の画像上の複数の文字の範囲を指定して、チャットボットに尋ねると、その意味などを解説してくれる、CODH が開発・公開している IIIF Tsukushi Viewer[8]は、それに近い(図3)。現在は、コーディングが必要であるかもしれないが、今後 Dify や Miibo のような AI プラットフォームを用いてノーコードでこういった AI アプリケーションが作成できれば、DH の可能性をさらに押し広げることになるだろう。
《連載》「英米文学と DH」第2回
「ハティトラスト・リサーチセンター」
ハティトラスト・リサーチセンターとは
前回の連載では、世界各国の大学図書館が所蔵する電子テクストを利用できるハティトラスト・デジタルライブラリーの話を書いた。このハティトラスト・デジタルライブラリーには、関連組織として、蔵書の電子テクストを使ったデータ分析サービスを提供するハティトラスト・リサーチセンター(以下 HTRC)がある[1]。例えばある用語の男性・女性別の使われ方の変化やジャンルの推移の分析など[2][3]、長期間かつ大量の電子テクストに対しデータマイニングなどの分析を行うことができる。原稿執筆時、HTRC は2026年末までハティトラストから助成を受けることが決まっており、その後は未定であることから[4]、この原稿の読者が研究目的で利用する場合は2026年までに研究を完結する形で利用するとよい。また2027年以降この原稿を読まれる方は、著作権保護期間中のデータを含むデータ分析サービスのベストプラクティスの記録として読まれるとよいだろう。
ハティトラスト・リサーチセンターの分析サービスの概要
HTRC が提供する分析サービスは多岐にわたるが、大別すると、1.コーパス作成用メタデータ(Worksets と呼ばれる)の作成と利用[5][6]、2.所蔵する電子テクスト全体の用語の出現数、BookNLP を利用した電子テクストの用語の出現数、あるいは文学ジャンルの電子テクストに特化した用語の出現数や文学ジャンルのテクストの地理情報といった加工済みデータセット(Derived Datasetsと呼ばれる)の利用[7][8]、3.用語の出現頻度の推移(Bookworm と呼ばれる Google の Ngram Viewer のようなサービス)や固有名詞抽出、トピックモデリングなどのWeb分析サービスの利用(Algorithms と呼ばれる)[9][10]、4.データカプセル(Data Capsule)と呼ばれるデータ分析用仮想サーバー環境の利用[11]があげられる(図1参照)。利用者は、1.で Volume ID と呼ばれるHTRC専用の書籍識別 ID のメタデータリストを準備したうえで、2.、3.、4.の分析サービスを利用することになる。電子テクストのデータやメタデータはハティトラスト・デジタルライブラリーから提供される。本稿は次回4.のデータカプセルを中心に紹介するが、今回はデータカプセルで何ができるのか、また HTRC のデータの扱いはどのようであるかについて述べる。
何ができるのか
データカプセルは、仮想サーバー環境と電子テクストのデータが与えられるため、自由度の高い分析ができる。その分析の強みの一つは、膨大なテクストを俯瞰しテクスト全体にわたる何らかの傾向を見出す「遠読」と呼ばれる分析を行えることである。世界各国の大学図書館の電子テクストというデータが既にあり、そのデータを自在に扱って様々な角度から検討ができる。例えば、書籍の数に着目して出版年代ごとの収蔵数のヒストグラムを作ってもよいし、テクストの単語に着目してある単語が現れる量を書籍のジャンルや出版年代ごとにみてもよいだろう。筆者が行った18、19世紀イギリスの戦争詩の分析をもとに二つの例をあげたい。
一つ目は、戦争詩に固有の語彙の作成である。戦争詩とは、各種の雑誌や詩集に掲載された、戦争への賛成反対を問わず一般的に戦争を主題とする詩の一ジャンルである。この戦争詩には、自由と正義、祖国の偉大さ、残された家族や孤児、帰還兵の孤独などの繰り返し現れるテーマがある。また使われる用語も、同時代の他の詩と比べ特徴的な用語が目に付く。戦争詩に固有の語彙を作成したとすれば、ある詩が戦争詩かどうか判定することができるだろう。このような場合、データカプセルは有用である。簡易な例としては、戦争詩のアンソロジー[12]を用意し、各用語の出現割合を作成しておく。その出現割合から、同時代のすべての文学の書籍に現れる各用語の出現割合を引くことで、戦争詩に固有の用語の出現割合の差が得られ、上位200語を取り出すなどして、戦争詩らしさを示す用語ベクトルを作成できる[13](筆者の研究では、ハティトラスト・デジタルライブラリーに適当な書籍がなかったため、紙の書籍を OCR でデジタル化し分析に使用した)。
もう一つの例は、トピックモデリングなどのより発展的な分析である。トピックモデリングとは、同時に使われることの多い単語ごとにグループ化し、意味に応じて単語を分類する手法であり、分類された単語群は同じ主題を示すとされる[14]。フランス革命前後100年間のイギリスの文学関連の書籍を、トピックモデリングの手法を使用して100のトピックに分類したとき、戦争や戦争詩に関するトピックは現れるだろうか[15]。データカプセルには、MALLET[16]や R や Jupyter Notebook といった分析ツールがあらかじめ用意されている。MALLET を使用してフランス革命前後100年間の電子テクストにトピックモデリングの分類を行い、結果にラベリングを行い、また戦争詩らしさを示す用語ベクトルを使用して戦争詩に関するトピックを得たとする。だがトピックが現れる時間的推移を可視化すると、また違った一面が現れる。図2はそのようなデータの可視化の例である。トピックの出現頻度を時系列でみることで、このトピックが主要な戦争と同期し、戦争文学の隆盛を示すことが確認できる。
ただし、HTRC の電子テクストのデータとしての特性には注意が必要である。別の図書館が所蔵する同じ書籍や、異なる版、全集に所収された書籍などの重複、大学図書館が揃える種類の書籍というデータ上の偏り、自動 OCR による読み取りエラーやロングエス(19世紀初めごろまで使われた小文字の s の古い用法。長い s)などの問題がある。
データの扱い
HTRC では、アメリカの著作権に配慮し、データを非消費研究の枠組みの中で扱っている。非消費研究とは、テクストに対してコンピュータによる分析を行うが、テクストにおいて表現された内容を理解するためにテクストの本質的な部分を読んだり表示したりすることのない研究である[17]。HTRC が扱う電子テクストのデータは著作権保護期間内のテクストとパブリックドメインのテクストが混在するが、一貫してテクストは表示しないという姿勢をとることで著作権に対応している。もとの内容が推測できない加工済みのテクストは表示することに問題はない。なおどのテクストが著作権保護期間内かは個別のメタデータや一般的なパブリックドメインのガイドライン[18]を参照することで知ることができることを付記しておく。
ハティトラスト・デジタルライブラリーが提供する電子テクスト
なおハティトラスト・デジタルライブラリーの側でも書籍のメタデータリストや[19]、リサーチ・データセットと呼ばれる電子テクストのデータ提供サービスを用意している[20]。これは適切な書類をそろえて申請すれば、Google との契約の有無および居住地(アメリカ国内外)の区分に応じて研究用に電子テクストを一括でダウンロードできるものである。原稿執筆時点でアメリカ国外の研究者が利用できる電子テクストの大きさは351GB とのことである[20]。次回は HTRC の実際の利用方法に触れたい。
人文情報学イベント関連カレンダー
【2025年3月】
-
2025-3-1 (Sat)
DH コンソーシアムプロジェクトキックオフ国際シンポジウム:人文学データの国際流通からみた研究の高度化・多様化https://dh.nihu.jp/news/hudx_20250206
於・トラストシティカンファレンス神谷町 -
2025-3-2 (Sun)
文部科学省委託事業「人文学・社会科学の DX 化に向けた研究開発推進事業」DH コンソーシアムプロジェクト・研究基盤ハブ・シンポジウム:TEI の現在と実践https://forms.gle/nMcZxi1NVzZmWrPy9
於・慶應義塾大学三田キャンパス -
2025-3-6 (Thu), 12 (Wed), 20 (Thu), 26 (Wed)
TEI 研究会於・オンライン -
2025-3-8 (Sat)
「通時コーパス」シンポジウム 2025https://www.ninjal.ac.jp/events_jp/20250308a/
於・国立国語研究所およびオンライン -
2025-3-8 (Sat)
義太夫節浄瑠璃作品翻刻の意義と未来―AI活用推進の中での問題提起―https://www.jwu.ac.jp/unv/jwu_times/2025_0207_01.html
於・日本女子大学目白キャンパス -
2025-3-8 (Sat) ~ 2025-3-9 (Sun)
みんぱく創設50周年記念国際シンポジウム「22世紀のミュージアム―未来のコミュニケーション空間を創造する―」https://www.minpaku.ac.jp/ai1ec_event/54839
於・国立民族学博物館みんぱくインテリジェントホール -
2025-3-10 (Mon) ~ 2025-3-14 (Fri)
言語処理学会第31回年次大会(NLP2025)於・出島メッセ長崎 -
2025-3-12 (Wed)
大本山總持寺デジタルアーカイブ公開記念シンポジウムhttps://www.sotozen-net.or.jp/gyojiannai/20250210_1
於・鶴見大学記念館 -
2025-3-21 (Fri)
広領域連携型基幹研究プロジェクト「異分野融合による総合書物学の拡張的研究」https://www.nijl.ac.jp/~ibunya/event/2024_symposium/index.html
於・国文学研究資料館 -
2025-3-22 (Sat)
第14回 知識・芸術・文化情報学研究会https://www.jsik.jp/?kansai20250322
於・立命館いばらきフューチャープラザ -
2025-3-25 (Sat)
研究集会「人文学のためのテキストデータ構造化の現状と課題」(Web サイトは近日公開)於・慶應義塾大学三田キャンパスおよびオンライン
【2025年4月】
-
2025-4-3 (Thu), 9 (Wed), 17 (Thu), 23 (Wed)
TEI 研究会於・オンライン
【2025年5月】
-
2025-5-1 (Thu), 7 (Wed), 15 (Thu), 21 (Wed), 29 (Thu)
TEI 研究会於・オンライン -
2025-5-31 (Sat) ~ 2025-6-1 (Sun)
情報知識学会 第33回(2025年度)年次大会於・筑波大学筑波キャンパス中地区
Digital Humanities Events カレンダー共同編集人
◆編集後記
2月は、筆者がお手伝いしている事業が中心となって TEI ガイドラインの初心者向けセミナーが大阪大学と九州大学で開催されました。この事業というのは、文部科学省の委託事業として開始され人間文化研究機構が中核機関として推進している「人文学・社会科学の DX 化に向けた研究開発推進事業」における「データ基盤ハブ」というもので、慶應義塾ミュージアム・コモンズが受託したものです。このハブでは、TEI ガイドラインに準拠した国際的な枠組みのなかで、東アジアテキスト資料のデータモデルを構築するとともに、これを踏まえたユースケースの作成や普及活動、人材育成を目指しています。そこで、冒頭のセミナー開催となりました。今後も、このハブでは各地で初心者セミナーを開催していく予定です。
生成 AI が一般化していくなか、筆者もそれを用いた RAG と呼ばれるシステムを昨年10月頃から作成しており、ようやく2月になって人文科学とコンピュータ研究会で発表できました。この発表中にも触れたことですが、生成 AI の発展が速すぎて、それを用いた応用事例を学会等で発表しようとするとしばしば難しいことになってしまう、ということをまさに体験したところです。というのは、研究発表をする直前になって生成 AI の新しいバージョンが公表されたりすると、発表直前にシステム改修を行なわねばならない…という事態に2月の発表で陥ったのです。しかも、その前には10月の UC バークリーと12月の東京大学での国際シンポジウムで発表していたのですが、その際にも経験してきたことがさらにもう一度起きた、という形になったのでした。自分で苦労するならまだしも、生成 AI を使っての研究発表を他人におすすめするのはなかなか難しいところですね。(永崎研宣)
- コメントを投稿するにはログインしてください