人文情報学月報第91号【前編】
目次
【前編】
- 《巻頭言》「漢籍の書誌データと利用者タスク」
:慶應義塾大学 - 《連載》「Digital Japanese Studies寸見」第47回
「東京大学附属図書館アジア研究図書館・漢籍・法帖資料のFlickr公開停止に触れて」
:国文学研究資料館古典籍共同研究事業センター - 《連載》「欧州・中東デジタル・ヒューマニティーズ動向」第11回
「Trismegistos:紀元前8世紀から紀元後8世紀までのエジプト語・ギリシア語・ラテン語、シリア語などの文献のメタデータや関連する人名・地名などのウェブ・データベース群、および、Linked Open Data のサービス」
:ゲッティンゲン大学
【中編】
- 《連載》「東アジア研究と DH を学ぶ」第11回
「「オープン」に関わるイベントで思うことなど」
:関西大学アジア・オープン・リサーチセンター - 《連載》「Tokyo DigitalHistory」第9回
「多言語史料のTEI化:16世紀の銀山史料の比較研究を事例に」
: 東京大学大学院人文社会系研究科 - 特別寄稿「Gregory Crane 氏インタビュー全訳(第2回)」
:東京大学大学院人文社会系研究科
【後編】
- 特別寄稿「著作権法改正で Google Books のような検索サイトを作れるようになる?」
:国立国会図書館関西館 - 人文情報学イベントカレンダー
- 編集後記
《巻頭言》「漢籍の書誌データと利用者タスク」
古典籍等の画像をインターネット上で公開するシステム(以下,デジタルアーカイブと総称)が増えつつありますが,せっかくたくさんの画像が公開されていても,書誌データが誤っていたり,不十分だったりすれば,検索しても出てこない,あるいは誤った結果がたくさん出てきて正しい結果が埋もれてしまう可能性があります。こうした状況は資料の発見の機会を減らすことにつながりかねないので,書誌データの充実は,画像データの充実および提供方法の標準化と同様に,デジタルアーカイブにとって重要な課題であると考えています。
筆者はもともと東アジアの図書館が作成する典拠データの比較などを行っていましたが,近年は漢籍の目録を研究対象としています。漢籍目録といえば,四部分類によって分類された冊子体分類目録を頭に思い浮かべる方が多いと思います。漢籍の冊子体分類目録はそれ自体,漢籍の組織化の完成形とも言えます。これらは基本的に一つの所蔵機関に収められる漢籍の書誌を収録した単館目録ですので,記述される書誌事項や記述の仕方はそれぞれ少しずつ異なります。例えば,現物に「〇〇輯」(〇〇は著者名)と書いてあるものを,「〇〇撰」と記録するか「〇〇編」と記録するか,刊行年に西暦を附すか附さないか,出版事項をどこまで詳しく書くか,冊数を書くか書かないかといったことは,目録によって異なります。もちろん単館目録である以上,このことに特に問題はありません。冊子体でなくカード目録であっても,単館目録であれば同じく問題はありません。しかし,「全國漢籍データベース」[1]のように複数機関の冊子体目録やカード目録に書かれた情報(書誌データ)を統合利用する場合には,上述したような細かな違いが検索に影響を及ぼす可能性があります。ただ,「全國漢籍データベース」ではデータソースが明確に示されています[2]し,その特徴を理解した上で研究者が利用する分には,問題はないと思われます。
デジタルアーカイブ上の漢籍の書誌データを統合利用することを考える際には,もう少し事情が複雑となります。デジタルアーカイブの書誌データは,冊子体目録やカード目録に由来するものもあれば,主に大学図書館が参加する総合目録システム NACSIS-CAT に入力される形式(CATP フォーマット)のもの,公共図書館によるもの,機関リポジトリ用のフォーマットのもの,図書館以外の機関が作成したものなど,様々なものがあり,フォーマットが異なるのみならず,記録されている書誌データ要素も多様です。またデジタルアーカイブは,研究者だけでなく,一般ユーザによる検索や利用も想定されていることが多いように見受けられます。せめて図書館で作成される漢籍の書誌データだけでも,もう少し統一できないものかと考えています。
日本の図書館では,目録規則(注:ここで言う目録規則とは書誌を作成するための規則で,分類のための規則ではありません)として『日本目録規則1987年版改訂3版』[3]が広く用いられており,また昨年末には,内容を大幅に改訂した『日本目録規則2018年版』[4]が刊行されました。日本の図書館では和古書と漢籍が同一資料群として扱われる傾向にあり,『日本目録規則』においても,和古書と漢籍にはほぼ同一の規則を適用することになっています。筆者は,和古書と漢籍では,記録すべき書誌データ要素,確認すべき情報源,用語,そして利用者群にも相違があり,同一資料群として扱うのは無理があると考えています。他方,今日の図書館目録作成をとりまく環境を考えると,書誌学的な成果としての目録を図書館が独力で作成するのはもはや難しく,図書館員が最低限の知識で作成可能な書誌データをとりあえずの到達点とするのが妥当と思われます。既に京都大学人文科学研究所附属漢字情報研究センターによる『漢籍目録:カードのとりかた:京都大学人文科学研究所漢籍目録カード作成要領』[5]があるので,これを基礎としつつ,多様なフォーマットに対応可能であるように,書誌データ要素のひとつひとつを再考すべき時機,おおげさに言えば,デジタルアーカイブ隆盛の時代に対応した新しい漢籍の組織化を考えるべき時機にさしかかっているのではないでしょうか。
近年の図書館目録の世界的趨勢として,目録作成者の経験から書誌データ要素を決めるのではなく,利用者による検索や利用の過程における一つ一つの行動(利用者タスク)を考慮した上で書誌データ要素を決定することが重視されています[6]。これは図書館が,利用者のニーズを蔵書構成や利用者サービスに反映させる努力をするのと同じように,目録にも反映させようという試みの一つといってよいかもしれません。そこで筆者は昨年より,実際に漢籍を利用した研究をされている研究者の方々へのインタビュー調査を通じて,漢籍の利用者タスクを明らかにする研究を行っています。その上で,各利用者タスクに対応した書誌データ要素を検討し,さらなるインタビュー調査によって各書誌データ要素の有用性を検証したいと考えています。もちろん研究内容や研究環境,あるいは世代の違いによって,漢籍の利用のされ方は異なることが予想されるため,海外の研究者を含めできるだけ幅広く調査を行い,多様な利用者タスクを明らかにすることが重要と考えています。既にご協力いただいた皆様には心より御礼申し上げますとともに,ご研究の中で漢籍の現物,画像,テキスト等を使用される研究者の皆様には,何卒ご協力を賜りたく,お願い申し上げる次第です。
執筆者プロフィール
《連載》「Digital Japanese Studies 寸見」第47回
「東京大学附属図書館アジア研究図書館・漢籍・法帖資料のFlickr公開停止に触れて」
東京大学附属図書館アジア研究図書館上廣倫理財団寄附研究部門(U-PARL)では、所蔵漢籍・碑帖拓本[1]の公開先としてこれまで利用してきた Flickr アカウント[2]の運用を2019年3月末で停止し、2018年9月14日に東京大学学術資産等アーカイブズ共用サーバではじめられた IIIF による公開[3]のみとすることを発表した[4]。U-PARL の発表では言及されておらず関係はないのかもしれないが、Flickr は、昨秋、無料アカウントで利用できる機能のおおはばな制限を発表したところであり[5]、有料アカウントに移行しなければ、自分の手で消さずともいずれ消えてしまうところではあった[6]。
U-PARL における Flickr での画像公開は、2017年5月30日であった[7]。公開に際しては、トークイベントを開催して検討事項を報告したり[8]、論考のかたちで報告をしたり[9]するなど、かならずしもデジタル資料公開に適しているとはいえない Flickr という場の制約をみずから引き受けて、専用のシステムに公開するのと同じかそれ以上の労力を費やしてことにあたっていることが印象的であった。じっさい、新しい共用サーバではFlickrでは活かしきれなかったメタデータが Omeka S に搭載されることで活きたデータとして利用しやすくなっており[10]、たんに Flickr で公開するためだけであれば過剰なほどの注力あってこそという感をあらためて深くする。
無記名の U-PARL ブログの記事[4]は、「公開した画像を取り下げるという点で、我々としても断腸の思いでございます」と締めくくられているが、稿者としては、予期していた事態に次の手を打てたことこそが素晴らしいことだと思う。Flickr 公開にこぎつけた労力そのものは報われているだろうからである。IIIF やつぎなるシステムもまた、いずれはこのようなときが来るのだろうが、このときの知見がまた活きることになればなお素晴らしいことであろう。
U-PARL「漢籍・碑帖拓本資料」をリニューアル公開しました | 東京大学附属図書館 https://www.lib.u-tokyo.ac.jp/ja/library/general/news/20180920
なお、Flickr においては、「本コンテンツは、オープンデータの国際的動向に鑑み、「クリエイティブ・コモンズ表示4.0国際 ライセンス(CC BY)」 の条件で提供しています。利用条件の内容については「ライセンスの要約」をご参照ください。なお、本コンテンツは制作時期などから合理的に著作権保護期間の満了が推定できるものとして提供しています。また、二次元資料の撮影に際して著作権は発生しないものと考えています。」という条件のもとに公開されていたが、公開先移転にともない、東大附属総合図書館全体の公開条件に統合することとされた。すなわち、利用許諾を求めることを止め、所蔵先の明示等、利用に際してのお願いを述べるに留めるというものである。
情報学広場:情報処理学会電子図書館 http://id.nii.ac.jp/1001/00185462/
A005935-01-0010 | 星鳳楼帖十二巻 Xingfenglou Tie 12 juan 東京大学総合図書館所… | Flickr https://www.flickr.com/photos/asianresearchlibrary/34284061534/in/album-72157681676772764/
U-PARL漢籍・碑帖拓本資料 · 星鳳楼帖 子 [A005935-01] · 東京大学学術資産等アーカイブズ共用サーバ https://iiif.dl.itc.u-tokyo.ac.jp/repo/s/uparl/document/5c0fb38a-56b5-4429-a781-f58f439b3485
共用サーバでは、リンクトデータでもメタデータが提供されているのが印象的である。なお、現状、漢籍・碑帖拓本資料用メタデータの語彙定義は公開されていない。
《連載》「欧州・中東デジタル・ヒューマニティーズ動向」第11回
「Trismegistos:紀元前8世紀から紀元後8世紀までのエジプト語・ギリシア語・ラテン語、シリア語などの文献のメタデータや関連する人名・地名などのウェブ・データベース群、および、Linked Open Data のサービス」
はじめに
近年、ドイツでは、先月号で紹介した、ベルリンの「エジプト博物館とパピルス・コレクション」のBerlPal(http://berlpap.smb.museum/)やハイデルベルク大学図書館パピルス・コレクションのウェブ・アーカイブ(https://www.ub.uni-heidelberg.de/helios/digi/hd_papyrus.html)など、先進的なパピルス文献のデジタル・アーカイブが開発されてきているが、それらのデジタル・アーカイブの個々の文献とリンクされているデータベースとして Trismegistos と Papyri.info がある。今回は、Trismegistos を紹介する。今回のタイトルがややぎこちないが、それは、この Trismegistos の対象とする文献の言語と時代が様々であること、そして Trismegistos は現時点で8つの異なるデータベースを有することを意味する。ここでは、エジプト語はヒエログリフ(聖刻文字)、ヒエラティック(神官文字)[1]、デモティック(民衆文字)、コプト文字(この文字で書かれたエジプト語はコプト語と呼ばれる)で書かれたエジプト語を意味する。また、対象を紀元前8世紀から紀元後8世紀にエジプトで写された、もしくは、製作されたと推定される文献を中心とするため、文献の言語は、エジプト語とギリシア語が多く、次にアラビア語、ラテン語、シリア語、アルメニア語、ジョージア語(グルジア語)、さらには、古期ヌビア語、メロエ語、パフラヴィー語、コーカサス・アルバニア語[2]、古代南アラビア語、フェニキア語、カリア語、ゲエズ語、ケルト諸語、エトルリア語、トラキア語など[3]と、大変幅広い。そのデータの種類の膨大さから、単純に数語でこの Trismegistos を説明することは容易ではない。
Trismegistos(https://www.trismegistos.org/)
Trismegistos は紀元前8世紀から紀元後8世紀の主にエジプトを中心とする古代から、古代末期を通して、中世にかけての地中海世界の文献のメタデータ、そしてその文献に出てくる人名や地名などのオンライン・データベース群である。ベルギーのルーヴァンの民衆文字エジプト語の文献学者 Mark Depauw を中心に開発が進められてきた。Trismegistos の名前の由来は、ギリシア神話のヘルメス神がヘレニズム期エジプトにおいて古代エジプトの知恵の神トト神と習合し、さらに錬金術師ヘルメスと同一視され、ヘルメス文書を著したと考えられたヘルメス・トリスメギストス(3倍偉大なヘルメス)から来ている。一度、最初のページを開くと、Texts、Collections、Archives、People、Networks、Places、Authors、Editors と書かれた8つのタイルが出現する。これらのタイルをクリックするとそれぞれ別々のデータベースに到達できる。ここでは、それぞれのデータベースについて紹介する。
Texts(https://www.trismegistos.org/tm/index.php)
Texts は Trismegistos のメインとなるデータベースである。紀元前8世紀から紀元後8世紀までが範囲であり、エジプトで出土した文献、例えば、コプト語を含むエジプト語、ギリシア語、ラテン語などの文献の所蔵場所、所蔵番号、言語、研究資料、年代、製作場所、出土場所、ジャンル、校訂など現代のエディションなどの情報が書かれている。いわば文献のウェブ・カタログ、メタデータ・カタログであるが、重要なのは、このデータベースは当該の文献を全て網羅することを目標としており、一つ一つの文献に TM Number という ID を割り振っている。この ID が、他の DH プロジェクトで、文献を特定し、相互利用を促進するための識別子として昨今広く利用されてきている。例えば、先月号で紹介した BerlPal はこの TM Number を利用しているほか、のちに紹介する Papyri.info、そして、筆者が働いているコプト語コーパス言語学のプロジェクトである Coptic SCRIPTORIUM でも TM Number を用いている。現在、この Texts データベースには、 778820の文献のエントリーがある[4]。このデータベースが始まったのは2005年であり、初めは、ギリシャ・ローマ時代のエジプトのパピルス文献を対象としていたが、のちに紀元前8世紀から紀元後8世紀のパピルス、羊皮紙、紙、碑文、グラフィティなど全ての文献へと対象が広げられた。
Collections(https://www.trismegistos.org/coll/index.php)
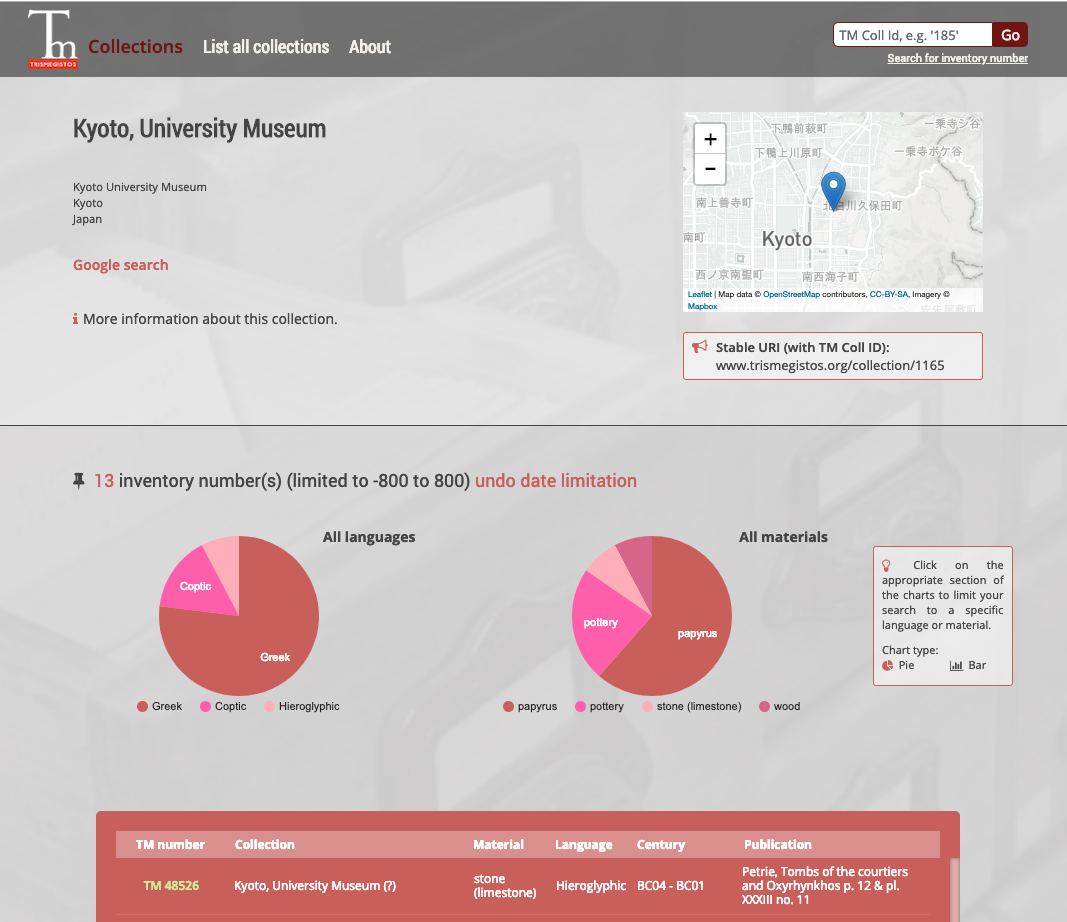
Collections は、Texts が対象としている文献を所蔵している博物館や図書館、大学などのコレクションのデータベースである。Leuven Homepage of Papyrus Collections を拡張したものである。3935のコレクションと、それらのコレクションの238806の所蔵品が所蔵番号とともに登録されている。エジプト出土の文献なので、植民地時代に多数を取得した欧米やエジプト本国が多いが、日本の博物館も登録されている。下の写真は京都大学総合博物館のものである。京都大学総合博物館は、ロンドン大学ユニヴァーシティー・カレッジ(UCL)のエジプト学および考古学の教授であったフリンダース・ピートリー卿(Sir Flinders Petrie)が、彼の UCL での教え子であり、京都大学の考古学の教授となり、のちに京大総長に就いた濱田耕作に贈ったピートリー・コレクションを有する[5]。Trismegistos Collections では、京都大学総合博物館に13の所蔵物が登録されており、その内訳は、Trismegistos Collections によれば、ギリシア語の文献は10、コプト語の文献は2つ、ヒエログリフで書かれたエジプト語の文献は1つである[6]。
Archives(https://www.trismegistos.org/arch/index.php)
Archives は、現代のアーカイブではなく、古代の蔵書や手紙、メモなどのアーカイブである。例えば、キリスト教の修道僧フランゲ(Frange)のアーカイブ[7]は多数のコプト語の手紙を含んでおり、コプト語パピルス学者の間で大変有名である。そのような蔵書は、現代では世界の図書館や博物館に散らばって所蔵されていることが多い。このデータベースでは、そういった古代のアーカイブの情報が調べられる。現時点(2019年2月13日)では、主にエジプトの529アーカイブ、そしてそれらのアーカイブに含まれる18860のテクストがある。
People(https://www.trismegistos.org/ref/index.php)
People は、紀元前8世紀から紀元後8世紀までのあらゆる言語のエジプト出土文献に出てくる人物および名前のデータベースであり、Prosopographia Ptolemaica をもとにしたものである。現在、王のものではない名前が501454集められている。一つの名前の、ヒエログリフ・ヒエラティックの対応形、デモティックの対応系、コプト語の対応形、ギリシア語の対応形、ラテン語の対応形が一覧でき、大変便利である。
Networks(https://www.trismegistos.org/network/index.php)
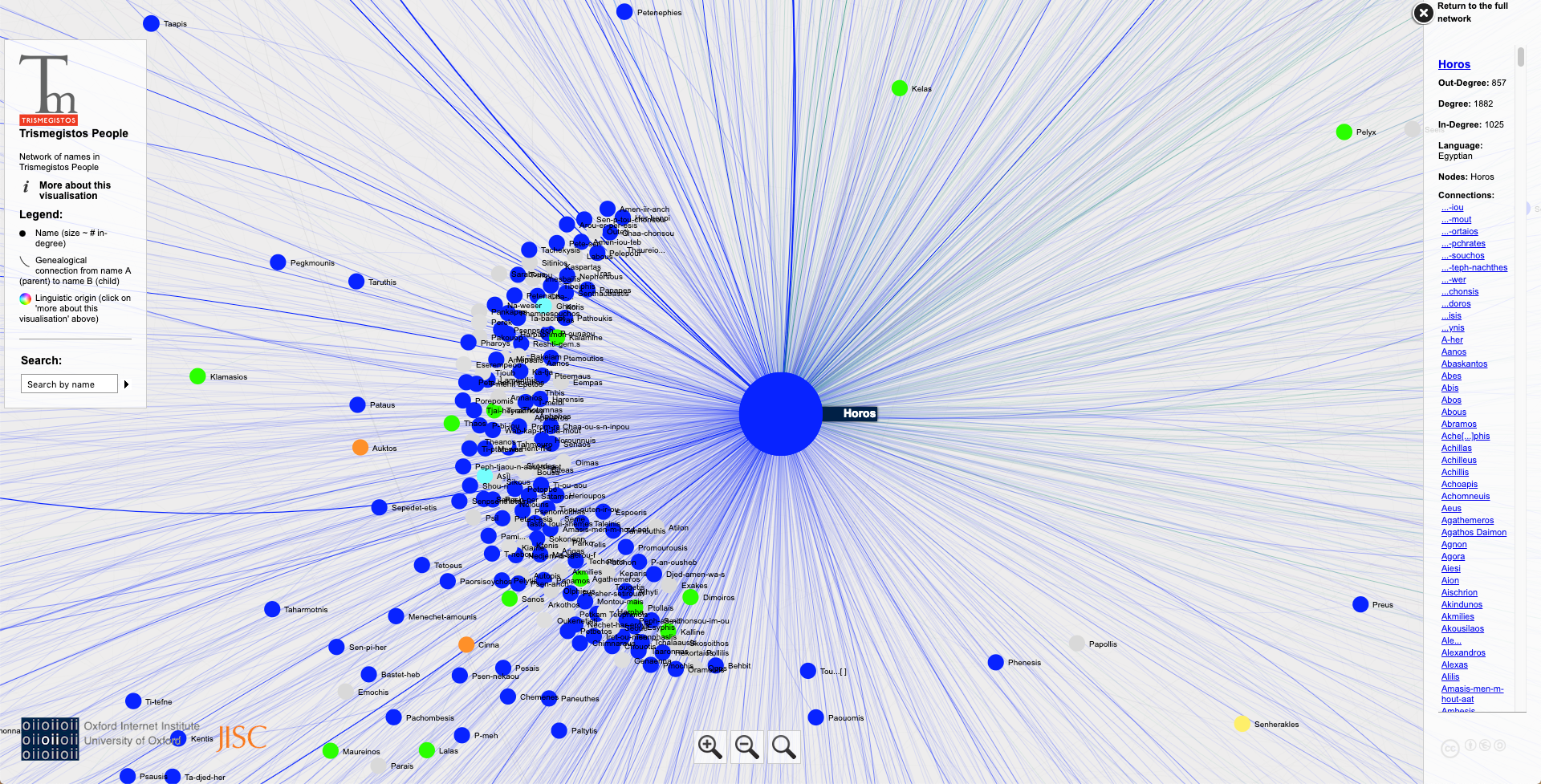
Networks は、Trismegistos の他のデータベースのデータ、例えば People の人名のデータベースのデータを基に描かれたネットワーク分析のデータベースであり、他のデータベースと趣が異なっている。下の画像は、Trismegistos People の人名のネットワーク分析で、Shenoute を検索し、Horosを中心に据えた時のスクリーンショットである。
Places(https://www.trismegistos.org/geo/index.php)
紀元前8世紀から紀元後8世紀までのあらゆる言語の資料に出てくるエジプトおよびその周辺の地名のデータベースである。現在、220234の地名がエントリーされている。これらの地名は、諸言語・諸文字における文献に出てきた語形の一覧を見ることができ、また、西洋古典学やエジプト学・コプト学などの地理データベースである Pleiades とリンクされており Pleiades 上で地図上で位置を確認できる。地名を調べるときに大変便利である。
Authors(https://www.trismegistos.org/authors/index.php)
紀元前8世紀から紀元後8世紀にエジプトで写された文献の著者のデータベースである。いくつか例を挙げれば、古代ギリシアのアリストファネスや、キリスト教のギリシア教父オリゲネス、コプト語で著述した修道院長シェヌーテ、マニ教文献、アラブ人によるエジプト征服の後のアラビア語による著述家など様々である。Aboutのページ[8]によれば、6191の著者が現在登録されているとあるが、現在(2019年2月17日時点)で ID は1の Aba Antonius から7268の Anonymus of the Didascalia CCCXVIII patrum Nicaenorum まである。各々のエントリーを開くと、その著者の作品がワードクラウドのように表示され、その著者の著作の言語、パピルス、羊皮紙や紙などの文献の物質、そして、文献が作られた地域の割合などが円グラフとして表示される。また、Authors のメインページでは、このデータベース全体で著述家の性別や言語の割合の円グラフ(棒グラフに変更可能)や、写本が製作された年毎のエントリーの量の折れ線グラフなどが表示される。
Editors(https://www.trismegistos.org/edit/index.php)
Texts で記録されている諸文献の現代のエディション(校訂本や文献の翻刻本など)のエディターのデータベースである。現在は20894人のエディターがエントリーされている[9]。あるエディターを選択すると、そのエディターが編集した文献の言語、媒体、地域などが円グラフで表示できる他、棒グラフに変更することも可能である。また、どの都市にいくつエディションを出版したかを棒グラフによって見ることができる他、編集した文献の年代の折れ線グラフが表示される。下にスクロール・ダウンすると、そのエディターに関連するネットワーク分析が3つほど表示される。
Trismegistos Data Services(https://www.trismegistos.org/dataservices/)
これは、欧州のデジタル・インフラストラクチャーのプロジェクト DARIAH のベルギー版である DARIAH-BE[10]のLinked Open Data Frameworkに準拠したデータサービスであり、Trismegistos のデータが Linked Open Data の概念の基、より他のプロジェクトで使われることを推進する先進的な取り組みである。このデータは、CC BY-SA 4.0 license で提供される。
以上が、Trismegistos の概観である。このデータベース群は非常に膨大であるため、全ての機能を連載中の一回で紹介することは到底できない。ぜひ興味がある方は、ご自分でこのデータベース群を試していただきたい。次回は、フランスやイギリスのデジタル・アーカイブ、もしくは、パピルス文献の翻刻ポータルである Papyri.info を紹介する。
- コメントを投稿するにはログインしてください