人文情報学月報第157号
ISSN 2189-1621 / 2011年08月27日創刊
目次
- 《巻頭言》「アラブ首長国連邦の DH 会議に参加して」
:東京外国語大学アジア・アフリカ言語文化研究所 - 《連載》「欧州・中東デジタル・ヒューマニティーズ動向」第73回
「Perseus Digital Library の進化:古典語文献のデジタル閲読プラットフォーム Beyond Translation」
:筑波大学人文社会系 - 《連載》「仏教学のためのデジタルツール」第21回
「ITLR (Indo-Tibetan Lexical Resource) について」
:慶應義塾大学/一般財団法人人文情報学研究所 - 《特別寄稿》「Dirk Van Hulle による「6. Exogenetic Digital Editing and Enactive Cognition」(『Digital Scholarly Editing:Theories and Practices』所収)の要約と紹介」
:早稲田大学大学院文学研究科 - 人文情報学イベント関連カレンダー
- 編集後記
《巻頭言》「アラブ首長国連邦の DH 会議に参加して」
私は南アジアのパキスタンにおける出版文化について研究しており、その過程でアラビア文字の HTR や、出版産業のネットワークに興味を持つようになった。2024年3月、アラブ首長国連邦のシャルジャにてイスラーム世界やアラビア語圏の研究に特化したデジタルヒューマニティーズ(以下、DH と略す)の学術会議に参加したので報告したい。
2024年3月6日と7日、シャルジャ・アメリカン大学にて二日間の国際会議「DH の実践:アラブ・イスラーム世界の地平の拡張と学問の変革」[1]が開催された。主催は同大学のアラビア語・翻訳学科で、初日は基調講演に続いて8本の個人発表、二日目は8本の発表が報告された。会議は基本的に英語で進み、いくつかの発表のみアラビア語で行われた。
興味深かった発表としては、中東・湾岸諸国の地域史を扱う研究があった。これは中東においてデジタルアーカイブに特に力を入れているカタールの「カタール・デジタルライブラリー・インド省文書」[2]を使い、19世紀後半から20世紀前半の奴隷解放文書の分析するものであった。英語とアラビア語が混合する多言語資料のHTRによるテキスト化、データセットの作成、テキストの計量分析などから同地域の社会史を明らかにしていた。
また、シャルジャで新たに開館したアラビア語古典写本図書館の取り組みを紹介する発表にも注目が集まっていた。同館は2023年9月の開館時から写本のデジタル化に取り組んでおり、大型の写本コレクションの収集も計画している。ただしデジタル化には独自のプラットフォームを使用していて、同館の閲覧室からのみアクセス可能となっている。将来的な IIIF への対応やオープンなアクセス環境の整備の必要性がフロアから指摘された。このほかにも、中東のジェンダー研究のリファレンスを集めたデータベース構築プロジェクトの発表など、今まさに知が可視化されていく過程を見る醍醐味を味わえた。
登壇者・参加者は湾岸諸国周辺の研究者や主催校の学生が多く、特に質問が集まったのは、アラビア語のAI翻訳やその教育への活用関連であったかと思う。アラビア語は中東を中心に多くのアラブ諸国で話されており、書き言葉である正則アラビア語(フスハー)と各地の口語(アンミーヤ)にかなりの開きがある。ChatGPT におけるアラビア語の自然言語処理能力を測った研究では、正則アラビア語の翻訳はある程度こなせるものの、各地の口語については同音異義語や慣用表現、時制などで課題が残ることが示された。
今回の会議は初めての開催であったため直前まで全容がつかめずにいたが、コンパクトな規模であったことと、アラブ文化に倣ってネットワーキングに十分な時間がとられていたことから、多くの研究者と交流することができた。開催地のシャルジャ・アメリカン大学の近くには上記で取り上げた写本図書館とは別に、叡智の館[3]と呼ばれる大規模な図書館も2020年に開館しており、同国の知的インフラへの関心と投資額の大きさに驚かされた。今回複数の発表者を送り出したニューヨーク大学アブダビ校のアラビア語 HTR プロジェクト[4]や、会議の主催者である Mai Zaki 教授がチーフエディターになっている雑誌『Journal of Digital Islamicate Research』[5]の創刊など、今後の中東・イスラーム諸国での DH の盛り上がりが期待される。
執筆者プロフィール
《連載》「欧州・中東デジタル・ヒューマニティーズ動向」第73回
「Perseus Digital Library の進化:古典語文献のデジタル閲読プラットフォーム Beyond Translation」
Perseus Digital Library[1]は、1987年に設立された古典文献を中心とする大規模な人文学のデジタルライブラリーであり、タフツ大学/ライプチヒ大学の Gregory Crane 氏が率いている。本誌では、本プロジェクトについては、2014年の吉川斉氏による特集「デジタル学術資料の現況から」「ペルセウス・デジタル・ライブラリーのご紹介」(計3回)[2]や、2019年の小川潤氏による「Gregory Crane 氏インタビュー全訳」(計4回)で詳しく紹介されている[3]。このプラットフォームは、テキスト、美術・考古学資料、言語学的アノテーションなど、膨大で多様なコンテンツを集積し、オープンアクセスで提供してきた。本記事では、Perseus Digital Library の最新アップデートのうち、特に Beyond Translation[4]に焦点を当てる。
2023年3月に発表された Perseus 6.0への移行[5]において、中核となるのが、Scaife Viewer[6]をベースにした Beyond Translation である(図1)。Scaife Viewer は、Perseus の新しいリーディング環境として開発されてきた。直感的なインターフェースを備え、テキストや翻訳を読みやすく表示することができる。他方、Beyond Translation は、テキストと翻訳の行レベル・句レベルでのアラインメント(対訳や異編テキストなどにおける複数テキスト間の単語や句同士の対応づけ)や、韻律の説明など、閲読に必要なデータを実装している。

Scaife Viewer と Beyond Translation を統合することで、読者はテキストと翻訳を詳細に比較しながら読み進めることができるようになる。また、韻律や文体など、テキストの多様な側面にアプローチすることも可能になる。これは言語学習や文学研究に新たな地平を開くものと期待される。Beyond Translation が実現する革新的な機能は、古典語のための自然言語処理プロジェクトの発展に負うところが大きい。例えば、単語や句レベルでの原文と翻訳のアラインメント(図2)は、UGRIT プロジェクト[8]など機械翻訳の分野で開発された手法を応用したものであると見られる。

Beyond Translation の大きな特徴の一つは、古典語の文法情報を可視化する点にある。図2は、図1をシンタックスツリー(統語樹)モードに変えたものであり、語彙や文法情報を可視化しているインターリニアーに加えて、単語同士の関係を表す統語情報(係り受け)を依存文法の枠組みによるグラフで可視化している。
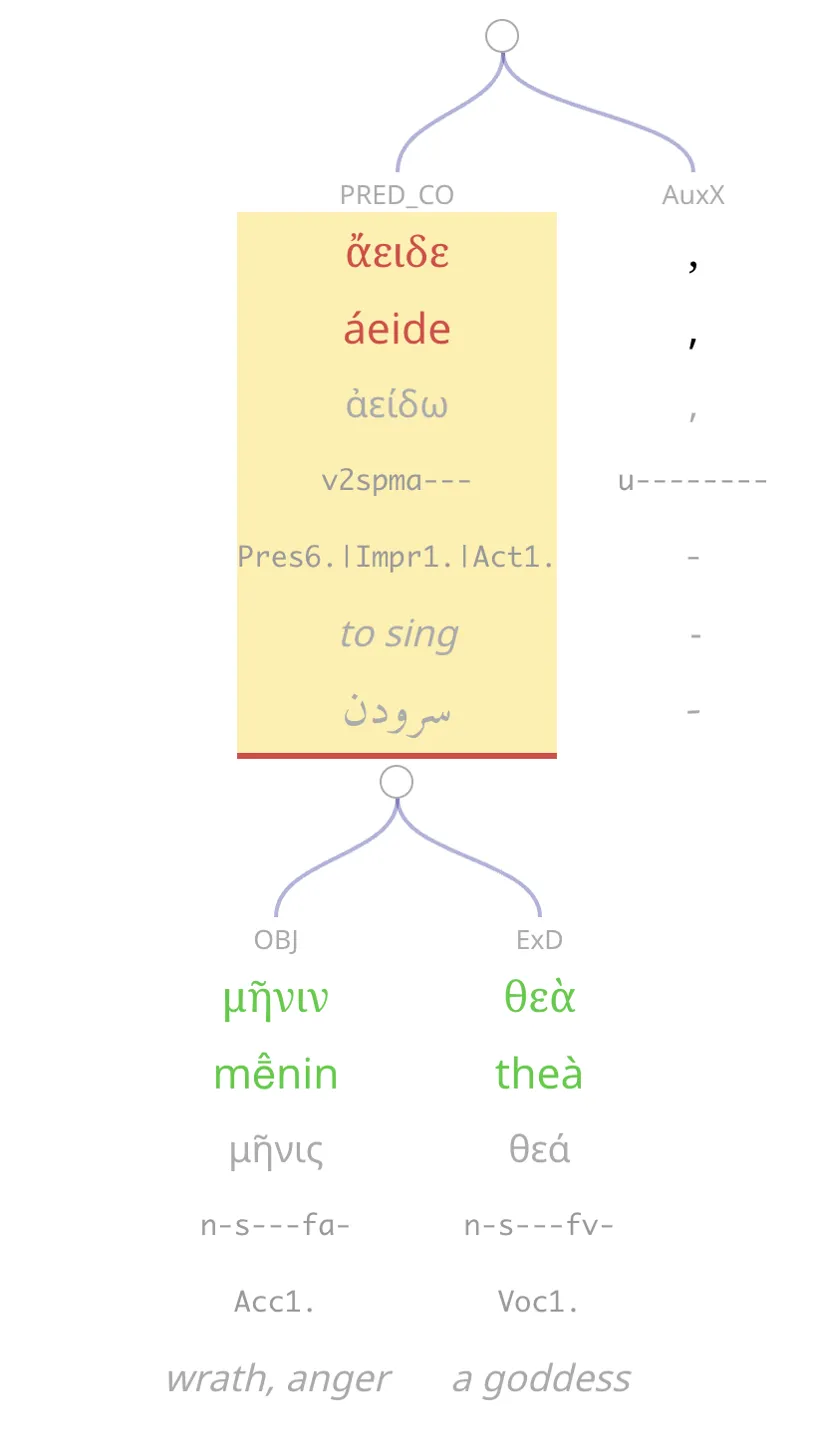
画面上部の枠内には、原文の単語が並べられており、それぞれの単語から伸びる枝は、統語上の役割や相互の関係性を表している。例えば、動詞 ἄειδε「歌え」から μῆνιν「怒りを」への枝には、OBJ「目的語」というラベルで μῆνιν が目的語であることが示されており、さらに μῆνιν の下には Acc(対格)というラベルがあり、この語形は対格(Accusative)であることがわかる。なお、数字は、同じ格の項ごとに振り分けられているようである。このような依存関係ツリー(dependency tree)は、統語構造を直観的に可視化するためのツールとして広く用いられる可能性がある。
Beyond Translation は、古典テキストの言語的特性を分析するためのツールも提供している。本文閲読画面の右パネルには、「Lemma Occurrences」の項目があり、そこではクリックされた語彙について、作品内での出現箇所と頻度が詳細に記される。このような情報は、特定の語彙の文体的特徴や主題的意義を探る上で、重要な手掛かりとなるだろう。
また、古典ギリシア語-英語辞書の定番である「LSJ (Liddell-Scott-Jones)」をはじめとする複数の辞書項目にリンクが張られているため、個々の語彙の意味用法についても容易に参照できる。頻出語彙のリストも準備されており、作品の文体的特性を統計的側面から把握することも可能である。以上のように、Beyond Translation は、古典テキストの言語的特性を、巨視的・微視的双方の観点から分析するためのツールを提供していると言える。

本文閲読画面を、韻律表示モードにすると図4のようになる。これは、『イーリアス』冒頭部分の韻律アノテーション機能を示している。具体的には、長音節と短音節の別、休止の位置、句切れの種類などが記号化されており、これを辿ることで、ホメーロスの詩行がもつリズムの特徴を視覚的に把握することができる。このような韻律アノテーションは、復元朗読や古典語教育など、より実践的な領域においても、詩文の音声化を支援する重要な手がかりとなるだろう。実際に、本ビューワの右パネルには、学術的な見地に基づいた、『イーリアス』本文の朗読が1クリックで聴くことができ、視覚と聴覚の両方から、韻律を学ぶことができる。
さらに、Beyond Translation は、同一テキストに対する通時的な複数の注釈を集積・可視化することで、古典作品をめぐる学説史的考察に寄与する。例えば、『イーリアス』冒頭部に対する Leonard Muellner と Greg Nagy の注釈を比較すると、μῆνιν 「怒りを」という語に関する言及の仕方に違いが見られることが即座にわかる。
このほか、様々な閲読のためのツールが Beyond Translation には搭載されており、ぜひ、それらを体験していただきたい。『イーリアス』のテキストは、Munro & Allen による校訂テキストがデフォルトになっているが、ヴェネツィア A 写本などの写本の翻刻を本文にして、閲読することもできる。
また、Beyond Translation には、古典ギリシア語・ラテン語だけではなく、古英語の『ベーオウルフ』や、詩人ハーフェズのペルシア語詩などが、現在閲覧可能になっている。情報量は、『イーリアス』よりは少ないが、『ベーオウルフ』にはインターリニアグロス(原語のテキストの各単語の下に単語の意味や文法情報をそれぞれ付したもの)が用意されている。あらゆる言語の古典作品の閲読環境を目指していると思われる。
以上、Beyond Translation の諸機能とその学術的意義について論じてきた。文法情報の的確な可視化、多言語対訳インターフェースの充実、語彙分析ツールの豊富さ、注釈の通時的集積など、このプラットフォームは古典テキストを学際的・総合的に研究する上で、極めて有用な基盤を提供している。
もとより、古典作品の理解は、言語的側面の分析のみで達成されるものではない。テキストの背後にある歴史的文脈、社会的慣習、宗教的規範など、言語外の広範な文化事象を視野に入れる必要がある。その意味で、Beyond Translation は、あくまで古典学習の出発点に過ぎない。
しかしだからこそ、このプラットフォームの存在意義は大きい。Beyond Translation を基点として、古典学と隣接諸学の相互交流が活性化されることを期待したい。
《連載》「仏教学のためのデジタルツール」第21回
仏教学は世界的に広く研究されており各地に研究拠点がありそれぞれに様々なデジタル研究プロジェクトを展開しています。本連載では、そのようななかでも、実際に研究や教育に役立てられるツールに焦点をあて、それをどのように役立てているか、若手を含む様々な立場の研究者に現場から報告していただきます。仏教学には縁が薄い読者の皆様におかれましても、デジタルツールの多様性やその有用性の在り方といった観点からご高覧いただけますと幸いです。
「ITLR (Indo-Tibetan Lexical Resource) について」

ITLR (Indo-Tibetan Lexical Resource) https://www.itlr.net/viewer は、インド・チベットの思想を主なテーマとした協働構築による辞典である。その Web サイト(図1)における説明では以下のように記されている。
このプロジェクトの構想は、2009年にハンブルク大学において行われた学術集会で大きく進展し、その後、一般財団法人人文情報学研究所、東京大学の三者による協働プロジェクトとして具体化が始まった。そして、すべての作業を Web 上で行えるように、入力編集から作業管理まで、一通り対応できる Web コラボレーションシステムが独自開発された[1]。
その後、現在に至るまで、データ構築が着実に継続的に行われてきている。世界各地の協力者がデータを入力した後、毎年1~2回程度、編集委員会によるチェックが行われ、チェックを経たものが公開されている。
ITLR では、上記のように見出し語はサンスクリット語になっており、同音異義語と見なしえるものは項目を分けて立てられている。表示されている順序はラテンアルファベットの順序になっており、サンスクリット語に親しんでいる人には若干違和感があるかもしれない。現在のところ、項目数は3700件ほどとなっており、検索機能も提供されている。検索機能では、見出し語のみを対象とした検索、独自分類に基づく分野別検索、説明等も含めた全文検索等の検索が可能となっている。
各項目には、サンスクリット語の見出し語に続いて、サンスクリット語としての文法情報が記述され、その後は、典拠情報とともに、チベット語、中国語での表記(複数のものがあれば複数を併記)、様々な現代語での訳語、その単語についての基本的な情報、一次資料としてのサンスクリット語、チベット語、他様々な言語での用例、二次資料での用例など、様々な情報が用意されている。また、関連する項目同士が連結され、ユーザはリンクでたどっていくことができる。(図2)
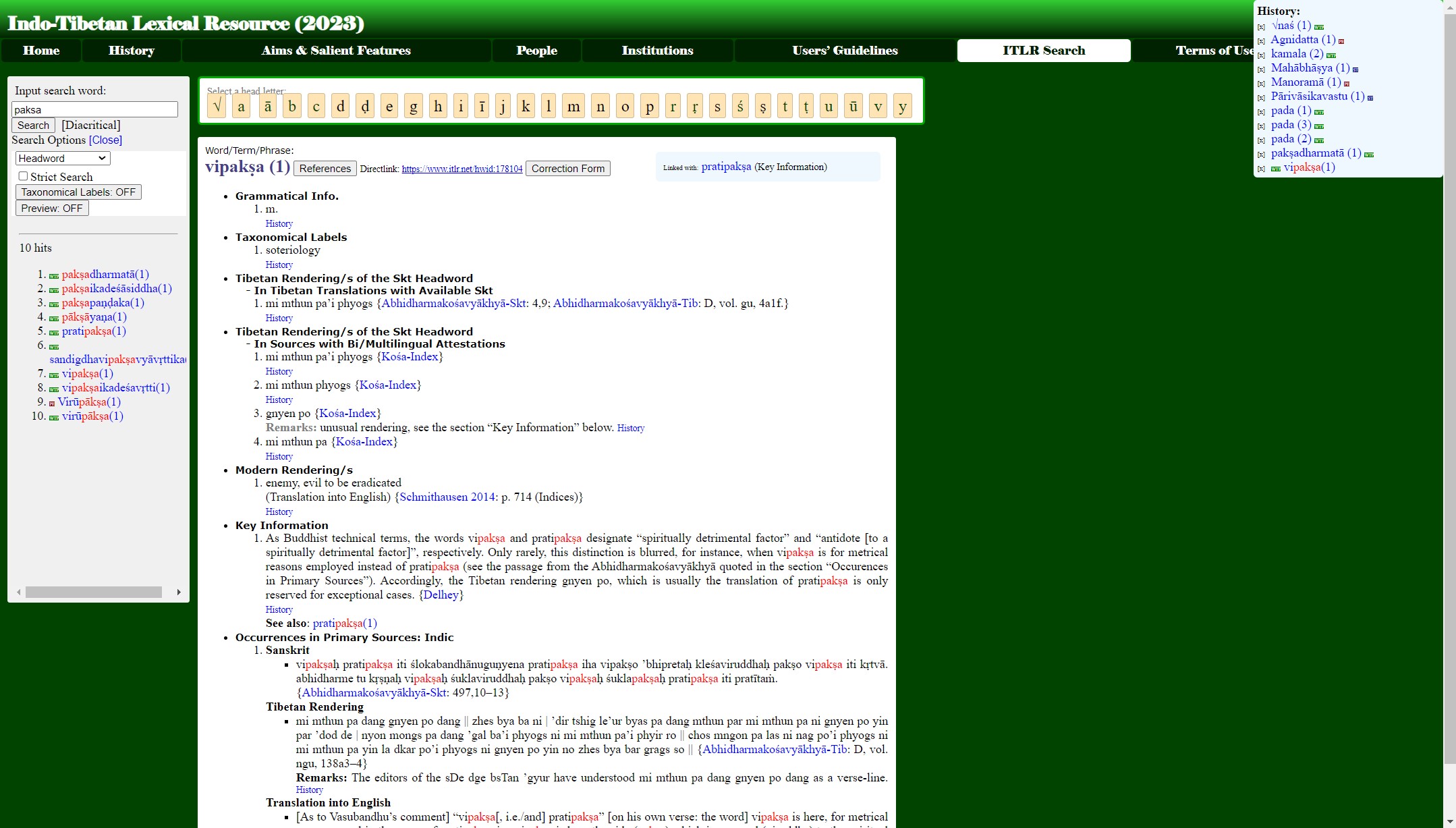
技術的なことにも少し言及しておくと、この辞書はデータ形式が複雑であり、可塑的なものである必要があるため、表形式ではなくグラフ形式のデータ構造としている。そして、これを動的に XML や RDF の形式で出力できる仕組みを用意している。後者のデータに関しては、Christian Steinert 氏が運用する統合的なデジタル蔵英辞典 Tibetan-English dictionary (https://dictionary.christian-steinert.de/#home) に登録され、横断的に検索できるようになっている。
ITLR は、継続的に拡張し改良されつづける協働辞書として、国際的なコミュニティのなかで形成されてきており、当初の機関に加えて、オーストリア科学アカデミー、筑波大学、三重大学、ナポリ東洋大学が参画している。すぐに誰にでも役立つようなものではないが、今後構築を継続していくなかで、着実に有用なものとなっていくと期待される。
《特別寄稿》「Dirk Van Hulle による「6. Exogenetic Digital Editing and Enactive Cognition」(『Digital Scholarly Editing:Theories and Practices』所収)の要約と紹介」
Dirk Van Hulle よる本章[1]は『Digital Scholarly Editing』の理論篇の第5章に位置し、認知科学のパラダイムに基づき、「モダニズム作家の個人蔵書、読書メモ、草稿を「拡張された心」の一側面として考察し、こうした能動的認知の形態を研究するために生成論的デジタル編集(原語:genetic digital editing)がどの程度まで展開できるかを検討するもの」である。
著者曰く、認知科学の中の一つの考え方である「エナクティヴィズム」は、「心は「拡張」されるだけでなく、「広範」であることを示して」いる。言い換えると「心は頭蓋骨の中の何かに限定されるものではなく」、環境も心の一部であることから、心とは「知的な行為者とその文化的・物質的な状況との間の相互作用で構成」されている。作家の場合、「紙、ノート、本の余白」などである。
検討の例として、著者はサミュエル・ベケットが好んだペトラルカの『ソネット』の一節「chi può dir com’egli arde, è ’n picciol foco」をめぐる間テクスト性のネットワークに着目する。この一節はベケットの残した膨大な蔵書群、資料群から、ベケットがこの一節を『ソネット』からではなく、モンテーニュのエッセイから引用し、それを『リア王』のお気に入りの一節「最悪とは、『これは最悪だ』と言える限り最悪ではない」と近い意味―「自らが燃えていると知る者は小さい火の中で燃えている」で解釈していたことがわかっている。著者はこれが50年以上にわたって行われており、「ベケットが自分の広範な心の働きについて、空間という観点だけでなく、「時間」という要素も合わせて体験したことは、作家の心(物語世界の生成)のレベル」で、認知物語論に関連しているとする。「ベケットがペトラルカの引用だけでなく、それが絡み合う間テクスト性のネットワーク全体と連携する方法」に注目すると、ベケットは「自己は連続する自己から構成されているということだけでなく、これらの自己と人間の心は絶え間ない物語の結果である」と認識していたこと、そしてそれは間テクスト性のネットワークが適切な比喩として機能することを指摘できる。著者はダニエル・C・デネットの言葉を借りてこれを「物語的自我」と呼び、「心の働きを呼び起こそうとする試みで有名な」モダニズム作家に敷衍してみせる。間テクスト性を単なる他人の著作への暗示と見るのではなく、意識を「構成的に[…]世界を巻き込む」広範な心という観点から見るならば、「間テクスト性はこの物語的自我性の自然な構成要素であるといえるだろう」。
こうしたことから著者は、「間テクスト性が広範な心のモデルとしてどのように機能するかを示す」ために、「作家の個人的な蔵書を統合するデジタル学術編集のアプローチが必要である」と主張する。蔵書は「作家の現存する蔵書(現在も保存されている書籍、おそらく余白への書き込みがあることを特徴とする)と再構築した蔵書(物理的に現存しないが、作家のメモによって読んだことがわかっている書籍、新聞、雑誌、パンフ)の両方を含むことが可能である」。こうした蔵書の統合は、「単一の作品に限定されない、作家の全作品を網羅する編集版において最も効果的であり」、これによって「間テクスト的パターンをマッピングし、ある特定の資料のある一節が複数の作品に繰り返し登場する方法を再構築でき」、あるいは「作家の作品群の中の1つにおいて特定の一節がどのように間テクストの複雑な組合せの結果となるのかについても再構築できる」のである。「ほとんどの生成論的編集版」は「内的生成」、つまり「執筆と改訂の過程に焦点をあてて」いるが、そうしたものにこの「外的生成的な次元を含むことは、作家の環境の別の側面を開き、作品において間テクスト性を「エナクティヴィズム」[2]の一形態として示す」ことになる。しかし、作家の蔵書を編集版に組み込む際の問題として、その蔵書と作家との関わりの深さがどの程度であるかが問題となる。著者は、「多くの作家の蔵書の特徴として、現存する本の中には明らかに特定の作品の執筆に使われたものもあれば、一度も読まれることなく作家の書棚にただ置かれていたものもある」ため、その蔵書と作家の関わりの深さを示す「グレースケール」という尺度を提案している。「グレースケール」とは S・E・ゴンタルスキーが「グレーカノン」と呼ぶ作家の蔵書、「例えば、手稿、手紙、伝記、インタビュー、創作メモ、余白のメモ、読書メモなど」に「様々な度合いを加える」ものであり、「SDE が作家の蔵書をどの程度取り込むように設定するかによって、様々なプロジェクトに適用可能である」。
こうした外的生成の次元を取り込むことの効果について、著者はベケットにおける「De nobis ipsis silemus」をめぐる状況を挙げて説明する。ベケットはエルンスト・カッシーラーによるエッセイ付きのカント全集『Immanuel Kants Werke』のコピーの余白に、カッシーラーによる典拠説明を書き込み、1930年代末に「Whoroscope」ノート(UoR MS 300, 44r)に書き留め、戦後『名づけえぬもの』の初稿が含まれているノートの裏表紙の内側に書き込み、続いてそれを初稿そのものの中に書き込んだ。著者が主催する Beckett Digital Manuscripts Project では、この文章の全てのバージョンを比較することができ、テクストが書かれた文書の物質性に焦点をあてる「ドキュメント指向のアプローチとテクスト指向のアプロ―チを間テクスト的次元から豊かにする」ような編集版となっていると述べ、メモや余白の書き込みが「作品における「広範な心」の視覚化のポテンシャルを持って」いると主張する。
生成論的編集では、「作家の「脳」に直接由来するとされるもの、つまり内的生成に焦点があてられる傾向にある」。しかし、「ドキュメント指向での手稿のページごとのマッピングが示すのは」、「この限られた環境でさえも、広範な心を構成する相互作用に一役かって」いることであり、「これをテクスト指向や間テクスト指向のアプローチと組み合わせることで」、「作品における創造的な心の働きの広がりに注目することができる」。結論として著者は、「SDE に外的生成(例えば作家の蔵書による)を組み込むことは、その作品の形成に貢献した「環境要因」を含める方法となり得」、脳と環境との相互作用からなる精神活動として理解するための方法となるであろうと述べている。
以上、論考の表現を借りながら要約と紹介を行った。文学理論の用語として定着して久しい「間テクスト性」とデジタル技術を用いて、従来の研究とは異なる規模で生成論を展開しようとしようとする本論考はデジタル技術の応用可能性を考える際に有用な研究事例となっている。また、この研究の背景として、この分野は欧米圏において研究の蓄積があることを押さえておかなければならない。現在状況はさらに進展しており、2023年出版の『Genetic Criticism in Motion』では、「デジタル技術とデジタルツールは特に学術編集、生成論的編集において広く適用されるようになった」[3]と評されており、当該書にデジタル技術と生成論に関する章が組み込まれていることからも、デジタル技術の応用は生成論において無視できないほどの影響を持つようになってきている。日本の自筆資料の研究においても、こうした動きを取り入れて行くことは、これまでになかった視点や規模で研究を行うことを可能にするだろうし、また、国際的な研究潮流を踏まえた、よりグローバルな範囲での知見交換につながるのではないか。
人文情報学イベント関連カレンダー
【2024年9月】
-
2024-9-5 (Thu), 9 (Mon), 19 (Thu), 23 (Mon)
TEI 研究会於・オンライン -
2024-9-7 (Sat)~8 (Sun)
Code4Lib JAPANカンファレンス2024https://www.code4lib.jp/2024/05/conference-call-for-proposal/
於・麗澤大学柏キャンパス -
2024-9-11 (Wed)~14 (Sat)
The 34th EAJRS Conferencehttp://www.eajrs.net/conferences/2024-sofia
於・Sofia University -
2024-9-16 (Mon)~20 (Fri)
iPRES 2024於・Ghent & Flanders 及びオンライン -
2024-9-17 (Tue)
DH国際ワークショップ「人文学と3D/3D Scholarly Editing」https://sites.google.com/view/dhws20243dscholarlyedition/
於・慶應義塾大学三田キャンパス東別館9階 -
2024-9-18 (Wed)~20 (Fri)
JADH 2024https://jadh2024.l.u-tokyo.ac.jp/
於・東京大学本郷キャンパス -
2024-9-28 (Sat)~29 (Sun)
日本図書館情報学会第72回研究大会https://jslis.jp/events/annual-conference/
於・筑波大学筑波キャンパス春日エリア春日講堂、7A棟
【2024年10月】
-
2024-10-3 (Thu), 7 (Mon), 17 (Thu), 21 (Mon), 31 (Thu)
TEI 研究会於・オンライン -
2024-10-7 (Mon)~11 (Fri)
TEI 2024於・Universidad del Salvador
【2024年11月】
-
2024-11-4 (Mon), 14 (Thu), 18 (Mon), 28 (Thu)
TEI 研究会於・オンライン -
2024-11-15 (Fri)~16 (Sat)
The 4th International Conference on Natural Language Processing for Digital Humanitieshttps://www.nlp4dh.com/nlp4dh-2024
於・Miami
Digital Humanities Events カレンダー共同編集人
◆編集後記
8月の上旬には、国際デジタル・ヒューマニティーズ学会連合(ADHO, Alliance of Digital Humanities Organizations)の年次国際学術大会、DH2024が開催されました。ハリケーンの近づくワシントン DC 近郊での開催でしたが、主催者発表によれば、発表400件、対面での参加者600名程、それに加えてオンライン参加者200名程という状況でした。そして、国別発表者数では、日本は米国・ドイツに続いて3位でした。基準はよくわかりませんが、著者の所属組織のある国ということで共著者も含めてすべてカウントしたのかもしれません。いずれにしてもなかなかの大躍進で、大変うれしいことでした。
DH2024自体はいつも通り色々な人達が集まって盛り上がりました。筆者は、前半の方はこの会の裏方として運営委員会に朝から晩まで参加してへとへとでしたが、後半には2つ研究発表をできました。この種の国際会議では休憩時間が30分ずつ確保されているため、コーヒー等が用意されている懇談会場で参加者の方々とじっくり話をすることができ、その時々の発表に関する議論だけでなく、旧交を温めたり新しい国際プロジェクトの話をしてみたりと、国際会議ならではの有意義な時間を過ごすことができます。会場となったジョージ・メイソン大学は、この分野では共同書誌情報管理ソフト Zotero やデジタルコンテンツの Web 共同管理システム Omeka 等を開発したデジタル歴史学のセンターが有名な私立大学で、建物は大変きれいで使いやすいところでした。
DH2024の模様については、来月号にてイベントレポートを掲載予定ですので、お楽しみにしてください。
- コメントを投稿するにはログインしてください