人文情報学月報第137号【前編】
ISSN 2189-1621 / 2011年08月27日創刊
目次
【前編】
- 《巻頭言》「デジタル化したテクストに「あいまいさ」を残すべきか」
:琉球大学附属図書館 - 《連載》「Digital Japanese Studies 寸見」第93回
「第27回情報知識学フォーラム「人文学テキストを通じた研究データ共有」開催」
:北海学園大学人文学部 - 《連載》「欧州・中東デジタル・ヒューマニティーズ動向」第54回
「古典語の Digital Reading Environment(デジタル読書環境)の開発:西洋古典の Scaife Viewer とユダヤ古典の Sefaria」
:人間文化研究機構国立国語研究所研究系 - 《連載》「デジタル・ヒストリーの小部屋」第12回
「可視化における誠実さ・訴求力・慣れ:デジタル・ヒストリーと可視化(3)」
:千葉大学人文社会科学系教育研究機構
【後編】
- 《連載》「仏教学のためのデジタルツール」第2回
「ゲオルク・アウグスト大学ゲッティンゲンの The Göttingen Register of Electronic Texts in Indian Languages」
:東京大学大学院人文社会系研究科博士課程単位取得退学 - 《特別寄稿》「Extended Matrix と考古学・歴史研究:3D モデル構築のプロセスを記録し可視化するためのデータモデル(後編)」
:ROIS-DS 人文学オープンデータ共同利用センター(CODH) - 《特別寄稿》「ハリー・フェアウェイエン「ヨーロピアナによる DX の駆動」講演録」
:フランス社会科学高等研究院 - 人文情報学イベント関連カレンダー
- イベントレポート「過去を研究するための Linked Open Data 活用について議論する場としての Linked Past Symposium」
:ROIS-DS 人文学オープンデータ共同利用センター(CODH) - 編集後記
《巻頭言》「デジタル化したテクストに「あいまいさ」を残すべきか」
TEI に関する勉強会に参加するようになったのは、2020年の秋ぐらいのことだったかと思う。デジタルアーカイブに関連する技術のひとつとして、同僚に誘われたのがきっかけであった。デジタルアーカイブ事業の担当者とはいえ、基本は掲載するデータを作成する担当であり、琉球・沖縄関係の古文献資料に関することを専らとしていた筆者にとって、技術的な勉強会についていけるのかとの一抹の不安も感じつつ参加してみたというのが最初である。当時コロナ禍で大学の講義を始め様々な会議や学会などのオンライン化が急速に進み、会議ツールにもようやく慣れてきた頃でもあった。
自宅のある沖縄から、東京や北海道等の遠方から接続する諸先生方と様々な情報を同時に共有するという状況は、不思議さを感じるとともに急速に変化する社会情勢を象徴するように思えた。また、TEI の勉強会に参加をすることで、今まで関わってきたコミュニティではおそらくは出会う可能性は少ないであろう多様な分野の研究者を知るきっかけになったのも大きな変化だ。参加者は歴史学だけでなく文学や言語学、宗教学や哲学といった分野の多様さもさることながら、研究対象としている地域も古今東西にわたっている。TEI というデジタル化技術に関する勉強会を軸として、参加者からの質問や提供される話題に世界が広がるような気がするのも面白い状況である。
勉強会に参加するようになり、自分なりにデジタルテクストへの TEI を実践してみるようになって以降、琉球・沖縄研究における基礎資料のテキストデータを如何に残していくかということを考えるようになった。現在は、琉球史研究において基礎的な資料である「家譜」資料のデジタルデータを TEI に準拠したファイルにし、データ作成の経緯や元の資料の情報と共に長期的に保存できるようにすることが目標である。
TEI のマークアップ作業について、自分なりに「人間が読んだ時に頭で考えていることをデジタル化したテクストに落とし込む作業」だと理解をしている。『人文学のためのテキストデータ構築入門』[1]の表紙に書かれている「私たちの読みを残し、共有し、たどれるようにすることで、どう読んだかを次世代に継承する」とあるように、人名や地名など人間が読みながら区別している固有表現をマークアップする。それによって、テクストが単なる文字列以上に様々な意味を含むように記録することができる、という点がこの作業の一番面白い部分かも知れない。
この数年でどうにかこうにか、自分なりに実践してきたことがまとまりはじめ、2022年11月23日に開催された第7回デジタルアーカイブ学会のサテライト企画セッション「琉球文化のテキストアーカイビング」にて発表の機会を頂いた。ディスカッションの場で、登壇者のお一人から「親雲上」の漢字を「ペーチン」と読むことについてルビなどの情報をテクストに補足するかどうかという質問を頂いた。後日自分のなかで掘り下げて考えると、やはりというかなんというか、なかなか一筋縄ではいかないということを改めて認識させられることになる。
「親雲上」は「ペーチン」と読むのが(少なくとも筆者や、今まで関わってきた研究上のコミュニティの大半では)一般的ではあるが、渡口眞清の『近世の琉球』では地頭所や名島を得た者は「ペークミ」と変化すると記録している[2]他、江戸立(ルビ:えどだち)[3]の際の日本側の資料では「バイキン」とふりがなが振られている例[4]がある。そもそも、「親雲上」は古くは「大やくもい」であり、後に「親雲上」の字を使用するようになったものである[5]。結局のところ、先日のサテライト企画セッションの時と同じく、はっきり「ペーチン」と読みを入れるには心許ないという実に歯切れの悪い結論になってしまった。
史資料をデジタル化していくにあたって、なるべく曖昧な情報は記録しないほうが良いとは思っている。ただ、こうやって普段深く考えていなかった事柄を改めて考え直し、曖昧さを含めて迷う過程は残しておいても良いのかも知れない、とも思う。
執筆者プロフィール
《連載》「Digital Japanese Studies 寸見」第93回
「第27回情報知識学フォーラム「人文学テキストを通じた研究データ共有」開催」
2022年12月18日、情報知識学会主催の情報知識学フォーラムが「人文学テキストを通じた研究データ共有」と題して行われた[1]。科学研究費 基盤研究(A)「仏教学デジタル知識基盤の継承と発展」(代表者:下田正弘)・TEI コンソーシアム 東アジア/日本語分科会・一般財団法人 人文情報学研究所が共催となり、稿者もほとんど名ばかりながら、共催者構成員として運営にかかわった。司会は人文情報学研究所の永崎研宣氏、講演は稿者のものをふくめ5件あり、テキストの構造化について、とくに TEI(Text Encoding Initiative)を利用したテキスト基盤構築をそれぞれ意識しつつ発題があった。『情報知識学会誌』第32巻第4号が予稿集を兼ねており、準備が整いしだい J-STAGE から公開されるということであり、以下の内容の詳細についてはそちらで確認されたい[2]。今回は、国立情報学研究所を会場としていたが、講師もふくめ、オンライン参加も数多くあった。
小風尚樹氏からは、「会計史料の構造化:ツリーかグラフか」と題して、会計史料を TEI で構造化する際のモデリングの課題、その解決としての DEPCHA と、それを用いたワークフローについて議論された。TEI をはじめとする XML を用いた符号化では、ツリー構造でデータ表現をするのが比較的容易であるが、原資料などに立ち現れる構造には素朴なツリー構造では表現しがたいものがある。その類型を整理し、TAGML[3]という記述言語を用いて解決を図るものに Bleeker et al.[4]があるが、小風氏はその類型を援用し、氏の取り組む会計史料にも同趣のものが現れることを示し、その解決手段として情報のグラフによる記述を TEI で行って RDF として取り出すフレームワークである DEPCHA[5]を援用することで発展的に解決できることを述べ、そのワークフローの具体例について論じた。質疑としては、会計史料のグラフ化はどのていどの解釈が伴うのかというものがあり、限界の説明がなされた。
稿者からは、「資料の構造を探り、他者に伝える:日本古辞書のばあい」と題して、符号化したテキストの作成にはテキストと独立に解釈を後世へ十全に伝える意義があることを、古辞書の解釈例とともに示した[6]。なお、稿者の講演以降、個別の質疑は行われていない。
間淵洋子氏からは、「日本語史研究資料の電子化—事例と課題」と題して、氏が長年携わってきた国立国語研究所の日本語コーパス類[7]における電子化の問題について述べられた。コーパスにおいては、単語を中心にさまざまな情報が符号化されることになるが、それと資料の趣を残すことの両立しなさについて古代から近代にいたる資料の符号化事例をもとに具体的に示された。国語研のコーパスにおいては、ほかに拠るべきものがなかったという理由から独自の XML が用いられているが、間淵氏としてはやむを得ず作られたものであり、共有という観点からは、TEI などの共通フォーマットへの転換なども必要となるのではないかという見解が示された。
この後、休憩を挟んでポスター発表もハイブリッド形式で開催された。広い意味ではテキストとデータ共有にかんする発表がほとんどであったと言えようか。教材にかんするもの、テキスト自動生成についてのもの、デジタルアーカイブについてのもの、構造化にかんする発表がなされた。会場から参加するポスター発表者には、距離をおいてブースが設けられ、そこから画面越しの参加者と対話するかたちとなった。件数にくらべて、いささか用意された時間は短く、2件の発表しか訪れることができなかったのは残念である。
ふたたび講演となり、金甫栄氏からは、「TEI を用いたテキスト構造化がもたらしたもの:『渋沢栄一伝記資料』から「渋沢栄一ダイアリー」へ」と題して、氏の勤務する渋沢栄一記念財団における『渋沢栄一伝記資料』の電子化[8]から、さらに別巻1・2の TEI を用いた構造化などの展開について述べられた。『渋沢栄一伝記資料』は、58巻と別巻10巻に及ぶ一大資料集であるが、TEI を利用して原資料との関連性をていねいに記述することができるようになった点、固有名詞などのマークアップが可能になった点で活用の道が大幅に広がったことが述べられた。その成果は「渋沢栄一ダイアリー」[9]として公開されている。
最後に、中村覚氏からは、「TEI データに対する可視化・分析ツールの開発」と題して、TEI の現状の利活用ワークフローについてレビューが行われた。TEI のような取り組みでは、利活用環境が重要であるとして、編集環境・変換環境・利活用の事例などの観点から説明が行われた。源氏物語の異文可視化ツール[10]や歴史資料の活用[11]など、氏が長年取り組んでこられたことの要を得た紹介ともなっていた。
質疑においては、まず、小風氏の発表にたいして、文献学的ツリー構造と会計資料的グラフ構造とを両立した符号化が可能かという質問がなされた。小風氏からは、DAPCHA においてはそのような模索はされていないが、墨守すべきものでもないという回答があった。なお、司会の永崎氏から、ツリーかグラフかというときのツリーがなにを指すものか曖昧であるという指摘もあった[12]。このほか、TEI を普及させるためにはどのようにすべきかという全員に対しての質問があり、ひとりひとりの回答をおおまかにまとめると、活用事例の増加や周知、利用の容易化(編集環境を親しみやすくする、分野別ガイドラインの整備等)や既存のデータからの円滑な転換が重要ではないかといった点で共通していたと思われる[13]。会場の議論として、TEI によって拓ける展望についてどういうものがあるかといった議論が最後になされた。
情報知識学会としても2回目のハイブリッド開催で、また、ポスターをハイブリッドで試みたのははじめてということであった。ポスター発表においては、会場参加者同士であっても、オンライン配信に耳に傾けるなどこれまでにはない場面もあり(会場内でのやりとりもなかったわけではない)、学会というものは、議論を発展させようという参加者の意思によって成り立つことをあらためて感じさせる機会だった。
岡田 一祐 (Kazuhiro Okada) - 資料の構造を探り、他者に伝える: 日本古辞書のばあい - 講演・口頭発表等 - researchmap https://researchmap.jp/kzhr/presentations/40734523。
《連載》「欧州・中東デジタル・ヒューマニティーズ動向」第54回
「古典語の Digital Reading Environment(デジタル読書環境)の開発:西洋古典の Scaife Viewer とユダヤ古典の Sefaria」
今回は、デジタル・ヒューマニティーズの分野で盛んになってきているデジタル読書環境の構築について述べる。Digital Reading Environment(DRE: デジタル読書環境)とは、インターネット上で、主に文学テキストを読めるアプリケーションのことを指すが、Kindle のような電子書籍や、Project Gutenberg のようにテキストのみではなく、そのアプリケーション上で容易に辞書を引けたり、活用形を引けたりでき、かつ、レイアウトが長時間のリーディングに耐えられる見やすいものであることが多い。対象のテキストも、現代の文学作品よりも、古典的作品や、宗教的な文献で、現代語ではなく古典語で、一般的な現代人が容易に読めることを想定していないものが多い。このように一般的な現代人から見れば、読むのが難しいと感じるテキストを、どれだけアプリケーション上のツールや機能で補佐して、多くはすでに死語となった古典語をできる限り容易に読めるようにするのが、DRE の役割である。今回、取り上げるプロジェクトとして、西洋古典 DRE の Scaife Viewer とユダヤ古典 DRE の Sefaria を取り上げる。
Scaife Viewer:西洋古典のデジタル読書環境
Scaife Viewer[1]は、西洋古典テキストの、注釈つきコーパスとして、西洋古典を学ぶものに非常によく使われている Perseus Digital Library[2](以下、Perseus)を母体とした DRE である。Scaife は、若くして亡くなった、デジタル西洋古典学者の Ross Scaife 氏の名前にちなんでいる。この Viewer は、西洋古典学の古代ギリシア語及びラテン語テキストのオープン化・デジタル化を進める Open Greek & Latin プロジェクトの一環として開発された[3]。
母体となった Perseus のウェブサイト自体も、その Web サイト上で、様々な西洋古典作品を、読むことができ、翻訳や語の意味なども容易に表示させることができる。例えば、翻訳のペインをクリックすれば、翻訳を見ることができる。テキストの単語にはリンクが貼られ、それをクリックすれば、古代ギリシア語–英語の大辞典 LSJ[4]や、ラテン語の大辞典 Lewis and Short[5]などのいくつかの辞典での記述を表示させることができる。さらに、語の統計など、簡易的な統計により、出現頻度などの分析も可能である。Perseus は、タフツ大学で始まったプロジェクトで、タフツ大学・ライプチヒ大学教授の Gregory Crane 氏によって牽引されてきた。Perseus は西洋古典学の学者や学生を中心に非常によく用いられており、筆者も古代ギリシア語やラテン語の意味や用例を調べるのに、紙の辞書や研究書、より研究者向けのデジタルツール Thesaurus Linguae Graecae[6]などと共に Perseus を併用してきた。
このように、Perseus で古典作品を読むことは可能であるが、Scaife Viewer は、レイアウトなど、デジタル読書環境に相応しい、より分かりやすいものになっている(図1)。フォントの大きさなども調整でき、表示できる翻訳も、対訳のように段落単位で並列させることが可能である。そのほか、Perseus では新しいウィンドウで開いていた単語の意味も、Scaife Viewer なら、テキストと同じウィンドウ画面の別ペインで、語の屈折・活用情報と意味を参照することができる。このように、Perseus のメインサイトよりも、Scaife Viewer はより見やすく、長時間の読書に耐えられる表示となっている。
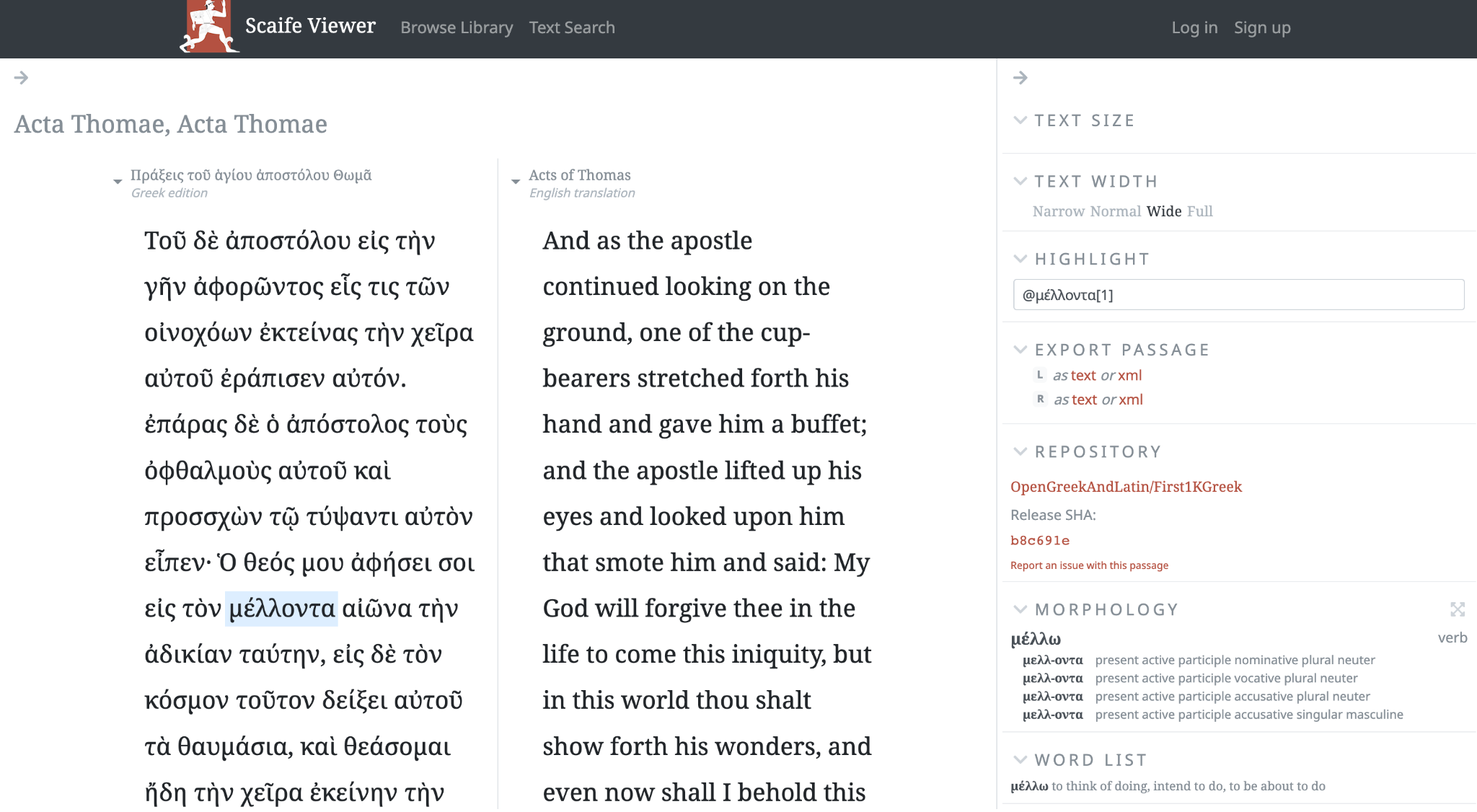
本稿の執筆時点で、Scaife Viewer で表示可能なテキストは、そのホームページによれば、2414作品であり、3195のエディション及び翻訳が閲覧可能である。このうち、1642のテキストは古代ギリシア語、636のテキストはラテン語のものである。テキスト全体の語数は約69,800,000語もあり、表示可能な西洋古典テキストがいかに巨大なものかが分かる。
Sefaria: ユダヤ古典のデジタル読書環境
Sefaria[7]は、ユダヤ古典の DRE プロジェクトであり、ベストセラー作家の Joshua Foer 氏と、元 Google 社員の Brett Lockspeiser 氏によって2011年に創設されたプロジェクトである。トーラー(モーセ五書)を中心としたユダヤ教の聖書であるタナハ(キリスト教の「旧約聖書」に相当)とユダヤ教の口伝律法を中心とした文書群であるタルムード、ユダヤ教神秘主義カバラーの書物であるゾハル、近代におけるユダヤ教ハシド主義ハバド派の書物であるタニヤなど、紀元前から現代までの様々な時代のユダヤ教の教典や古典を読むことができる。これらの古典の言語は、ヘブライ語が多いが、中にはヘブライ文字で書かれたアラム語での作品(『ゾハル』など)もある。Scaife Viewer と同じく、大変わかりやすくシンプルな操作画面であり、文字の大きさやレイアウトの調節、検索が可能で、同一ウィンドウの画面右のペインでは、語の意味や、高名なラビ(ユダヤ教の教師)の注釈などを参照することができる。2021年に大幅なデザインの刷新が行われ、大変読みやすくなった。Scaife Viewer と同様に、本文の語をダブルクリックすると、それと連動して、右ペインでその語の意味が引かれる。また、主要な古典では、翻訳は複数のものが用意されており、翻訳を、節や段落単位で、本文の下に表示できるほか、対訳のように、並列させてパラレルに表示することも可能である。さらに、複数の古典作品を比較するために、複数のテキストをパラレル配置することも可能である。また、ユーザ登録すれば、ブックマーク(しおり)を有効活用でき、スマートフォンを含めた様々なデバイスで、読書記録やブックマークが呼び出せる。
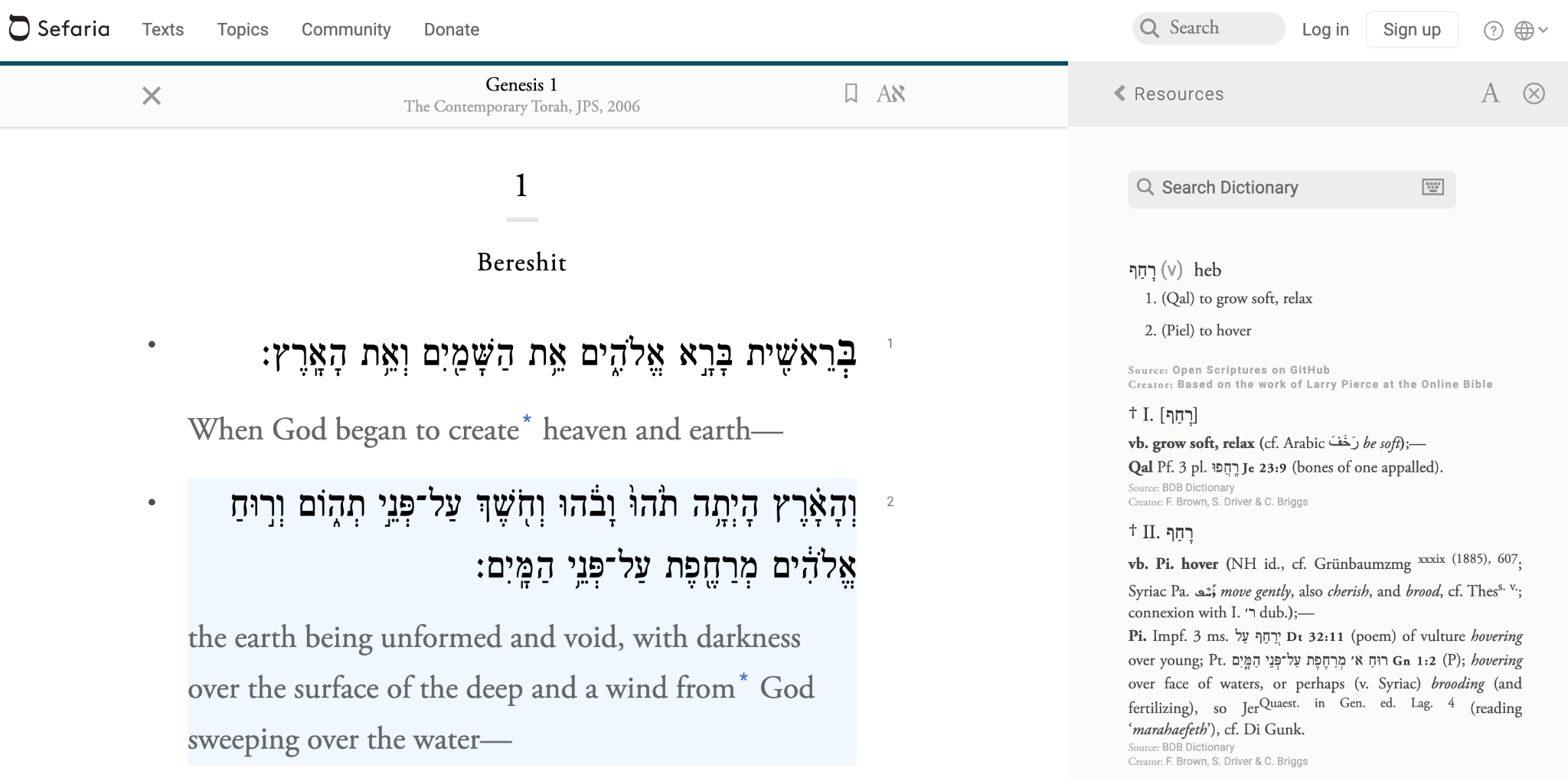
今回、Scaife Viewer と Sefaria という2つの、欧米・中東での代表的なデジタル読書環境(DRE)のプロジェクトについて述べた。DRE の定義は、管見では、まだ定まったものがないが、代表的な例から帰納法的に考察すると、①様々な作品が用意され、②節や段落ごとの翻訳の表示(本文とパラレル、もしくは本文と一対一の表示)がなされ、③同一ウィンドウ内で、辞書や注釈を参照でき、④シンプルなデザインで文字の大きさやレイアウトを調節でき、⑤ブックマーク機能など読書支援機能がある、という条件に当てはまるものが多い。もちろん、これら全てに当てはまらない DRE も存在するであろうが、研究者による分析の対象としてのテキストを提供するプロジェクトとは一線を画して、一般的なユーザや学習者が、その古典作品を自力で読み解けるよう、可能な限り使用が容易になるよう、デザインやレイアウトの見やすさ・読みやすさ・把握しやすさを突き詰めた、「ユーザ目線」に立った、機能・表示が特徴であると言える。
《連載》「デジタル・ヒストリーの小部屋」第12回
「可視化における誠実さ・訴求力・慣れ:デジタル・ヒストリーと可視化(3)」
(前回の連載から続く)
可視化における誠実さ
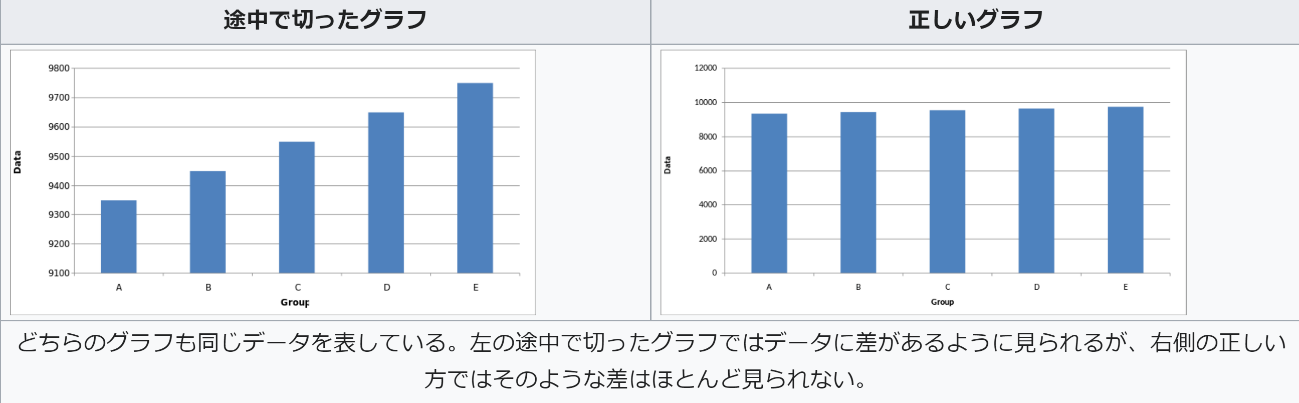
20世紀後半~末にかけて、歴史家が統計手法をどのように取り入れるかを議論していた一方で、統計学者は量的情報の可視化がどのように利用されるかについての考察を深めていった。可視化に関する3冊の理論書[1]を著したことで有名な Edward Tufte は、グラフや図表の美しさや説得力を詳細に精査する中で、いわゆるチャートジャンクと呼ばれる誤った可視化を批判した。正確な情報であっても、誤った表示方法を用いることによって、誤解を招く恐れがあり、場合によってはデータが示す実際の内容よりも大きな変化に見えてしまうことがあることには注意が必要である。図1で示したような基準値がゼロで始まらない棒グラフなどは典型的な悪いグラフである。実際よりも差を大きく見せる効果が生まれてしまっているためである。
可視化における誠実さという観点では、歴史家の伝統的な実践も批判されるべきところがある。Theibault による本エッセイが掲載されている書籍に採録された、ギブスとオーエンズのエッセイによれば、「歴史家は伝統的に、完成した作品では研究過程の紆余曲折を隠して、自分の主張をできる限り強くするように言われてきた[3]」とある。このようなアプローチは、当然のことながら可視化をブラックボックスのような不透明な研究過程の産物のように思わせてしまう危険性がある。用いたデータも可視化手法も、どちらもオープンなものにせよというオープン・サイエンスの要請が歴史学にも押し寄せ、とくにデジタル・ヒストリーの分野からの応答が見られていることは[4]、このような危険性を考えれば自然な成り行きに思える。しかし、歴史学の学術誌でこのようなオープン・サイエンスの姿勢を取るものは、全体で見ればごくごく少数にとどまっていると言わざるを得ないのが現状である[5]。
訴求力
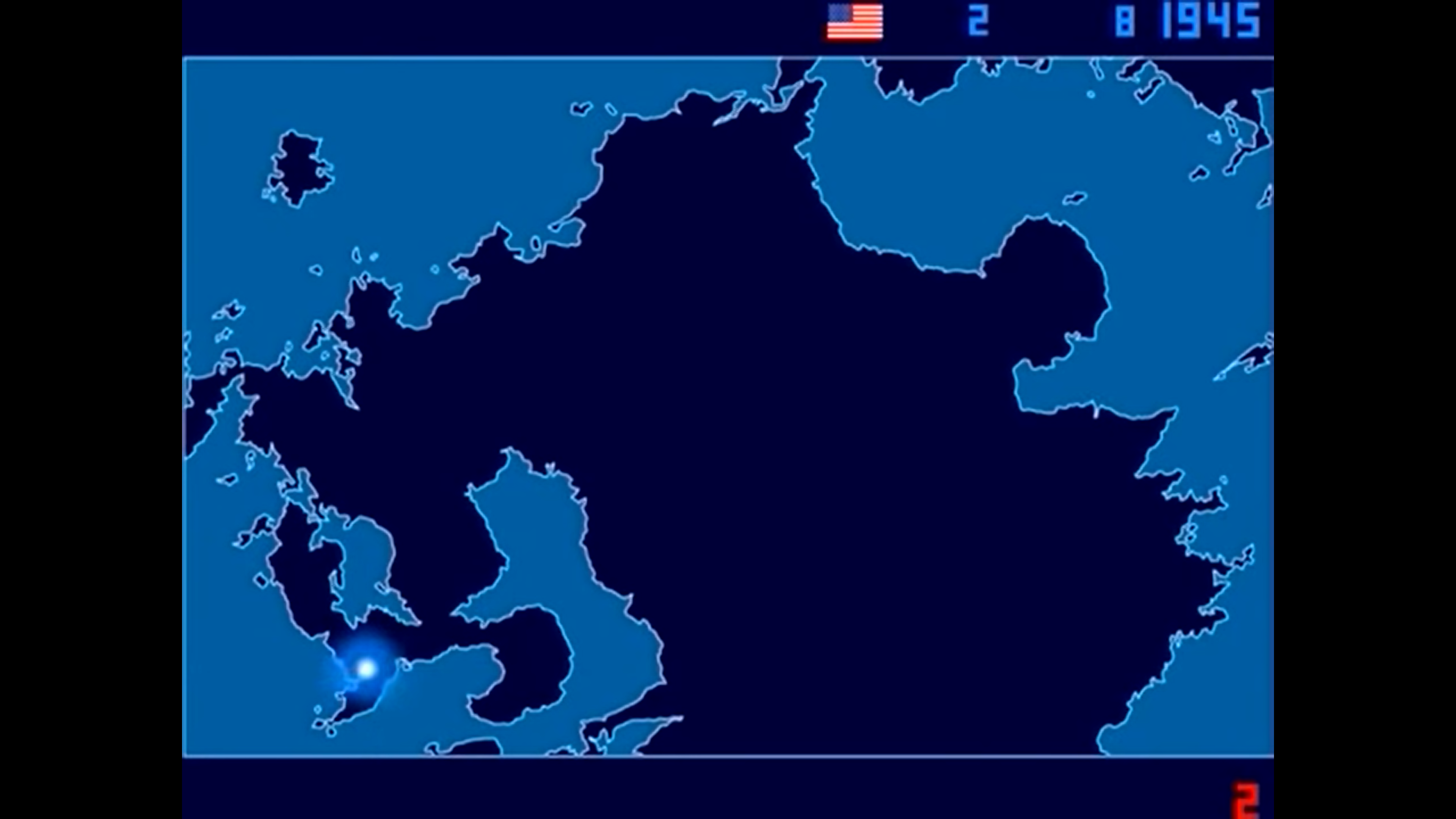
歴史研究において地図は豊かに発展してきた可視化媒体のひとつである。多くの人にとって地図は身近な存在であり、その意味を読み解くのにさほど困難は感じないだろう。そのような可視化媒体を利用する際は、多少ならば認知的負荷の高い可視化を作成しても良いと考えることもできる。地理空間情報の密度を高めるひとつの方法として、たとえば地図と時間軸のアニメーションを組み合わせることが挙げられる。図2に抜粋した1945~1998年までの2053回の核爆発のアニメーション地図はその好例で、動画のタイトル “1945–1998”が示す以外の背景情報はほとんどないにも関わらず、データが地図にプロットされる際の爆発音とともに核の時代の特徴を深く理解することができる。
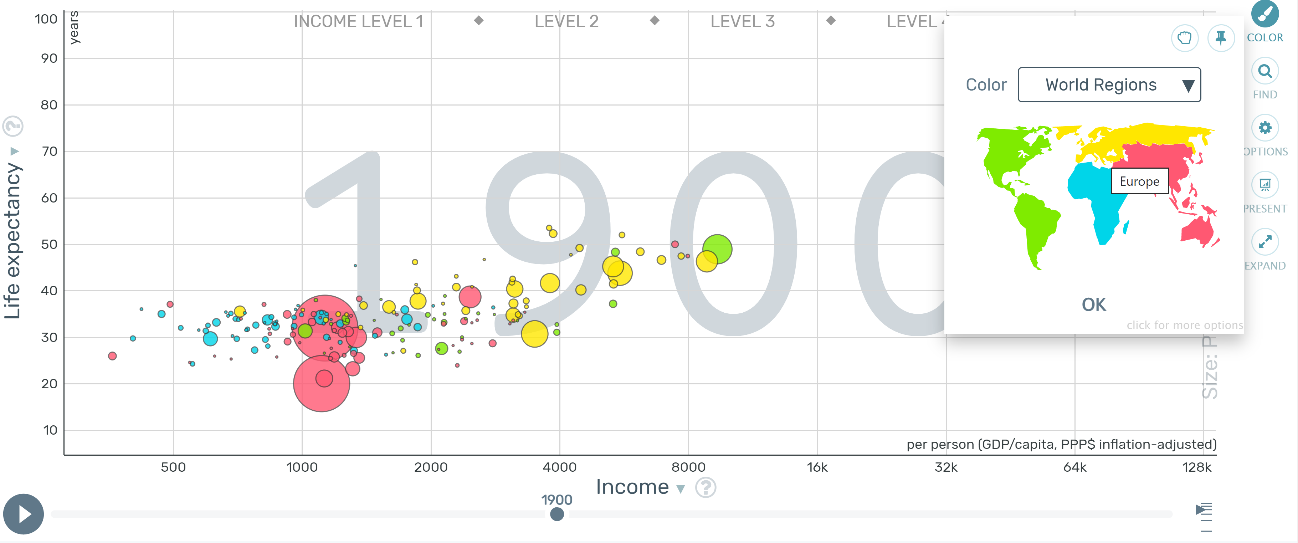
インタラクティブ性も、デジタル化によって可能になった革新のひとつである。図 3 に示したのは、ハンス・ロスリングによるバブルチャートである。平均寿命と GDP の関係を示した散布図に、円のサイズで表現された人口の大きさが要素として加えられた、3つの変数を可視化したグラフである。再生ボタンを押すと 200 年を超える変化が生き生きと浮かび上がってくる。グラフの左下から右上へとバブルが移行していく様は、世界がより高い水準の健康と富に収れんしていくストーリーを、叙述の力を借りることなく見る者に語りかけてくる。インタラクティブ性というのは、ユーザの関心に応じて操作することによって情報の表示をカスタマイズすることができ、グラフの特定の要素だけをピックアップして検討したりすることができることである。このインタラクティブチャートでは、どこかの年代や国・地域だけを切り取って平均寿命や GDP、人口の関係性を詳しく検討することができる。
慣れ
歴史家は、人・モノ・カネなどのネットワークをよく扱うが、社会科学者がどのようにネットワークを可視化してきたかについては、ほかの統計手法と比べてあまり詳しくない。というのも、ネットワークの可視化は、その数学的根拠を支えるグラフ理論が、過去に生きた人間の経験とはほとんど関係のない数学的原則に依拠しているため、歴史家にはなじみが薄いためである。ネットワーク図に登場するノードを作成するために使われているアルゴリズムを理解しなければ、ノード同士の関係性を読み解くことは不可能に近い。
SPSS、SAS、そして R が統計解析を可能にするために作られたように、Gephi のようなソフトウェアはネットワーク解析のために作られた。このような技術の進歩は、登場時点では革新的であった可視化手法を一般的なものに民主化させる意義がある。新しいものは常に新しいわけではなく、徐々に人々の目に触れることによって、人々の認識領域が広がり、可視化の可能性も徐々に広がっていくのである。図4で示した FlowingData のようなサイトでは、日々新しい可視化の利用法が展示されている。
このように革新的な可視化が、日々進化していることは明らかで、この種の情報に目を通しておくことは、歴史家がテキストを補完し、時にはそれに代わるより強力な議論を行うための戦略を得ることになる。しかしそのような議論を構築するには、可視化の解釈方法について同僚の歴史家を教育する作業が含まれなければならない。単純にその可視化形式に歴史家が慣れていないのであれば、その形式で作成した実例を多く提供する必要がある。あるいは、そのグラフを読み解くための背景知識が不足していることが懸念される場合は、まずはテキストを使って凡例や解説を充実させれば良いだろう。
可視化を活用した議論を前に進めるには、とにかく慣れが必要である。登場時点では目新しかった家系図や、ヒストグラムや散布図などの統計図表に対して、基本的に消費者として関わることの多かった歴史家が徐々に慣れていったように、ネットワーク図を読み解くことに慣れる日もいつかは来るのかもしれない。いや、そうする必要があるだろう。ネットワークは歴史家にとって最も関心のある論点のひとつなのだから。
おわりに
早いもので本連載をはじめて1年間が経過した。今後もデジタル・ヒストリーの関連論点を扱っていきたい。書評や翻訳を含めることもあるだろう。引き続きご高覧いただければ幸いである。
- コメントを投稿するにはログインしてください