人文情報学月報第117号
ISSN 2189-1621 / 2011年8月27日創刊
目次
- 《巻頭言》「デジタル時代の歴史資料」
:京都大学大学院文学研究科 - 《連載》「Digital Japanese Studies 寸見」第73回
「篆書字体データセットの公開」
:北海学園大学人文学部 - 《連載》「欧州・中東デジタル・ヒューマニティーズ動向」第34回
「Arborator-Grew:ウェブ上で直感的に共同編集できる Universal Dependencies のツリーバンクエディタ」
:京都大学大学院文学研究科附属文化遺産学・人文知連携センター - 人文情報学イベント関連カレンダー
- 編集後記
《巻頭言》「デジタル時代の歴史資料」
2009年から2010年にかけて、Stanford 大学のコンピュータ・サイエンス科の Terry Winograd 教授の招聘枠で Visiting Scholar として在外研究をしたことがある。まだ設立されて数年しかたっていなかった d.school にも出入りして、HCI(Human Computer Interaction)の教育法を学びつつ、研究対象としてきたコンピュータ科学者(とその卵たち)に交じって1年を過ごした。2010年といえば、ちょうど iPad 第一世代が発売された年で、ネットワーク管理の助手をしていた Mike Krieger が私がアメリカを離れてまもなく、CTO となって Instagram を設立した年でもある。
その1年には、HCI に関する最新研究についてのセミナーが毎週のように開かれていたが、Google や Yahoo! といった検索ポータル大手の研究所から訪れる人々の、実データに基づくユーザ研究の迫力は圧倒的で、大学の研究者も彼らと共同研究する以外に道はないのではないかとすら思わされた。幸い現在日本では、国立情報学研究所の情報学研究データレポジトリで民間企業提供データが公開されているので、そうしたデータの一端を研究者が垣間見ることは可能だ。
滞在中、研究室が近かった説得テクノロジー(Persuasive Technology)の研究グループの研究者が議論をふっかけてきた。「歴史研究をしてるんだって? これから膨大な記録が残っていく時代の歴史はどうなるの?」
HCI の研究でも、Web 上に人々が日々生成するデータの膨大さは実感しているが、記録をどう残すべきか、いやそもそも研究者のアクセス可能性はどうなるのか。一方で政治的なことがらについては、あったはずのデータの痕跡が消されていることもあるのでは? むしろその欠損したデータこそがこれまで歴史研究が対象にしてきたような史料なのではないか……などと、さまざまな思考実験をしながら議論が続いたが、もちろん簡単には答えがでるわけではない。実際、これは実にやっかいな問題だ。
時代が遡れば遡るほど、残されている記録は断片的になる。しかし史料の数こそ少ないが、失われた言語の知識が必要になることもあり、読み解くには相当の研鑽が求められる。逆に時代が下れば、徐々に史料の数は増えるわけだが、デジタル的なデータが日々生成されていく現代を対象にするに至ると、歴史研究にも混沌とした大量の情報のなかから物語を紡ぐ、帰納的な思考力も必要になってくるだろう。
こうした未来の歴史研究の議論の前提になっているデジタル史料の蓄積のひとつが書籍のデジタル化である。2009年頃はちょうど Google Books に続々と大学図書館が協力し始めた時期である一方、外国の出版社から著作権違反の訴えが上がるなどして、議論が盛んに行われていた。そして日々生成されては消えていく Web データの蓄積も大きな問題であった。ちょうど10年ほど前から始まっていた Internet Archive などによる Web アーカイブの標準化が進み、IIPC(International Internet Preservation Consortium)の WARC 形式が国際標準機構(ISO)の国際規格に認められたのも2009年である。
2018年に再度在外研究の機会があり、コンピュータ史博物館の学芸員から紹介されて、カリフォルニアにある Internet Archive を訪ねることができた。そこで、以前に来日した際にインタビューしたことのある Ted Nelson に再会するという嬉しいおまけつきで、彼が相変わらず筋のいい技術への嗅覚が鋭いのに感心した。デファクトスタンダードを作っていく力のある Internet Archive の技術者たちの様子は、アメリカらしくカジュアルだったが、自らが開発してきたクローラー Heritrix が、同種の Web アーカイブ機関で標準的に利用され、同じく自らのフォーマットがもとになって WARC が定まり、閲覧アプリケーションである Wayback Machine もオープンソース化して世界で使われているのであるから、自分たちの仕事の意義に誇りを持っていて、非常に力強く勢いがあった。そして資料収集が、TV ニュース、映画、音楽、ソフトウェアなどへと拡がっていて文化史研究の材料が豊かになっていっているのが印象的であった。
こうして現在は、民間の Web サービス機関が持つ全データが一般の研究者に公開されることにはならないにせよ、API の仕様によっては過去のデータをある程度得ることができるようになっているし、書籍のデジタル化や Web アーカイビングをはじめとするデジタルアーカイブ化も進んできて、思考実験のように「あらゆるデータが残っている状態」にはほど遠いにせよ、もはや人力では読み尽くせない量の記録が蓄積されていっているのは間違いない。従って、こうした現代を扱うことになる未来の歴史学者には情報技術の素養は必須になるだろう。もちろん古いフォーマットのさまざまなデータが読み込めなくなる後方互換性の断絶問題がそう簡単に消えるわけではないから、それらを復元して読む環境を整える能力も必要になるのかもしれない。断片的で読解困難な史料をつなぐ想像力や思考力のある人文学者から、大量のデータと格闘する人文情報学者へと、歴史研究者も対象となる時代とともに大いに変化することになるのであろう。
関連リンク
(https://warp.da.ndl.go.jp/contents/reccommend/mechanism/index.html)
執筆者プロフィール
《連載》「Digital Japanese Studies 寸見」第73回
「篆書字体データセットの公開」
2021年3月31日、国文学研究資料館が複数の機関から収集し、情報・システム研究機構データサイエンス共同利用基盤施設人文学オープンデータ共同利用センター(以下 CODH)が加工した篆書字体データセットが CODH から公開された[1][2]。これは、国文学研究資料館・総合研究大学院大学の青田寿美氏が主導する科学研究費助成事業・挑戦的研究(萌芽)のプロジェクトの成果のひとつで[3]、篆書字体データセット作成委員会が組織され、協力者の助力のもと作業が進められているようである。
篆書字体とはされているが、漢字の歴史的発展における篆書の収載を企図したものではなく、より近しい時代における篆書受容、とくには印章などにおける篆書の機械的処理の促進にこのデータセットやプロジェクトの趣旨は置かれている([3]の研究課題名にも「蔵書印」が挙げられている)。印章類になぜ篆書が用いられるのかは、大西克也氏による解説がある[4]。ここで必要な長さにまでみじかくしていえば、印章類には威厳があり、それに用いるだけの威厳が篆書にはかつてあったということである。篆書には、このほか、造形の自由度が高いという特徴があり、構成の妙は現代の固定化された手書き書体には比ぶべくもないものがある。それゆえに、印影というもののそもそもの読みにくさも相俟って(いまでも印影が鮮明に出ず、捺し直しになることはよくある)、篆書の印章の読解は難渋を要するものとなっており、篆書による印章の読解を補助する手段が、既存の字書のたぐいを越えて、必要であったということができる。いわゆるくずし字 AI のたぐいの前段階に「くずし字データセット」があったように[5]、篆書のばあいには、篆書字形のデータセットが必要とされたということである。
青田氏は、国文学研究資料館において蔵書印データベース[6]の責任編集担当として、2008年以来データベースの充実に携わってこられたという。そのなかのあたらしい展開として本データセットは位置づけられるようであり、じっさい、本データセット作成上の成果物を活用した篆字部首検索システム[7]が本データセットの公開に先駆けて公表されている(2019年3月12日 β 版公開、2020年3月30日正式版公開)。
篆書字体データセットは、「国文研くずし字データセット」のデータ作成仕様を参考に[8]、人文情報学研究所の永崎研宣氏作成の画像切り出しツールを一部に用いて作成されたという。じっさいの印章からデータが作成されたわけではなく、篆書を集めた明清期や江戸期の7種の刊本や写本について、それを切り出して作成されたものである[9]。選定の基準は明らかにされていないが、印章類の篆刻の際に、よく利用されたものから採取したということかと思われるので、印章から文字形状をうまく特定できれば、あとは、このデータセットから学習した判定器を使えばよいということなのであろう。データセットの凡例[10]によれば、機械学習の用途に供するべく、鮮明さに欠けたり、ほかの文字と重なっていたりして、単体として条件が揃わない篆書の例は、切り出す対象としなかったとのことである。論点はありそうに思うが、いちおうの理解はできよう。
それぞれの集成に示された篆書の例は、見出しとして掲出される楷書体の親字によって、画像がまとめられている。親字がなければその例に附随する解説にしたがって解釈するとされる。ただし、「親字が二文字以上列記されることがある『偏類六書通』については、解釈の違いに応じて2種類のデータセットを提供する」として、「原本の記述に忠実に、親字のフォルダには異体字もしくは同音字として通用仮借が可能な篆書字体を収める」データセットと、「字例(示された伝抄古文や他の篆書字体)を解読し、親字のフォルダには同一の文字と解釈可能な篆書字体を収める」データセットに分けたという。このようなじみちな作業は、労を多としたく思うのである。
以下に述べることは、全体のごく一部にしか係わらないことであることを断って、このデータセットの親字の扱いについて疑念を述べたい。
『偏類六書通』のふたつのデータセットについて、おそらくは、学界の進展にあわせて、第2のデータセットのほうが字体解釈の精度が高いものと推察される。では、新旧の両方を併用してほしいのかといえば、そんなことはとうぜんなく、「機械学習への利用には第二のデータセットを推奨する」とのことである。しかしながら、『偏類六書通』以外のものも、現在的観点に立って原本のまちがいを直すとされているならばともかく、そうではない。このように資料ごとに推奨されるデータセットの作りが違っていては、こののちに述べることともあわせて、データセットをどのように利用してほしいのか分りにくくさせてしまうのではなかろうか。
また、字体のデータセットとは言われるが、字体差として記述可能とまでの意味合いは込められていないのだとは思う。がいして、このような字書は、用例を整理したいのか、字体を整理したいのかなどといった、なにを整理したのかについてはっきりしないことが多い。ここで取り上げられた諸集成も一見のかぎりそのようである。そのようなものの親字について、凡例に、「親字の Unicode は、原則、掲出された親字の形に従うこととし、字体の統合は行っていない。字書・字彙類を一次資料として、できるだけ原形のまま本データセットに反映・保存すべきであると判断したためである」[10]とされるのは、便益がよく分らない。親字はあくまで見出しであるのだから、篆書の構成の理解に繫がるわけでもなく、機械学習のためという目的―そのために鮮明でない文字を対象外にさえしたのに―にどのように合致するのか。続く文には、「整版本の版下書きの書き癖や正字ではない字体の頻出等を鑑み、切り出す篆書字体を参看した上で、合致・近似する文字や正字に依拠した文字の Unicode を付与した場合もある」[10]とあって、意図して行ったものもあろうが、無意識的な包摂も多そうである。どれだけ慎重に作業をしたところで、そもそもが恣意的な Unicode の包摂基準にあわせれば(それじたいは時代の要請があり、Unicode だけの責任ではないにしても)、どこまでも恣意に流れるだけであり、やる必要のないことではなかっただろうか。たとえば、『汗簡』の「𫝹(U+2B779)(GlyphWikiで字形を参照)」のみを「念(U+5FF5)」と分離するのはそのような例で、篆書じたいの差が分離に繫がらないし、『聯珠篆文』では統合されている。この個別例がどうこうではなく、不必要な混乱のもとになっているということである。「国文研くずし字データセット」は、学習効率を重視して字体の新旧を揃えており、そのような観点からも首をひねらざるを得ない。
これらの問題が問題として現れてくるのは、ごく一部であることは繰返し述べておきたい。利用価値の高いデータセットとなることは疑いのないものである。それでもなお、篆書について知らない者が方針だけを見て利用するにはすこし負担が多いように思えた。後半の問題提起は、そのような観点からのものと受け取っていただければ幸いである。
陳俋佐「宋代における「古文篆書」―常杓の「盤谷序」を例として―」『書学書道史研究』29(2019) https://doi.org/10.11166/shogakushodoshi.2019.15。
《連載》「欧州・中東デジタル・ヒューマニティーズ動向」第34回
「Arborator-Grew:ウェブ上で直感的に共同編集できる Universal Dependencies のツリーバンクエディタ」
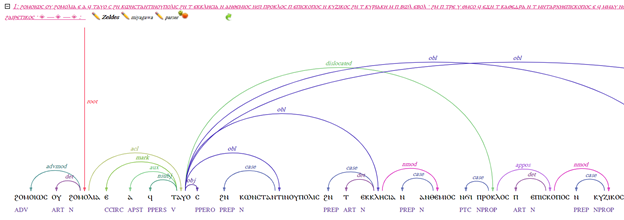
本連載では、どんな言語でも同じ記法で主語や目的語など統語情報を書けるようにする、Universal Dependencies(UD)[1]について何度か書いてきた[2]。この UD は、CoNNL-U 形式というファイルで書かれるが、より簡便に編集するために、いくつかの GUI エディタが開発されてきた。その一つが、フランスの研究機関である国立デジタル科学技術研究所(Institut national de recherche en sciences et technologies du numérique; INRIA)[3]が開発した Arborator[4]であり、筆者も参加している全米人文学基金(National Endowment for the Humanities; NEH)の Coptic SCRIPTORIUM[5]というコプト語のタグ付き多層コーパスの開発プロジェクトで図1のように統語情報を編集するために使用されている。Coptic SCRIPTORIUM では、TreeTagger[6]や MaltParser[7]を組み合わせて、コプト語のテクストを与えるだけで、そのテクストのすべての単語のレンマ、品詞、UD に基づく統語情報を解析する Coptic NLP Service[8]を用意している。これらの情報は、SGML でタグ付けされるが、デジタル・ヒューマニティーズで人文学資料をマークアップするための標準形式となっている TEI XML[9]、そして、UD を記述するための標準形式である CoNNL-U 形式[10]に変換可能である。Arborator を使用する際は、自動で統語情報を解析した SGML のテクストデータを一旦 CoNNL-U 形式に戻して、Arborator で自動解析のエラーを修正している。また、コーパスを視覚化し、品詞情報やレンマ情報、英訳など様々な情報をウェブ上で表示する、ベルリン・フンボルト大学が開発した、多層ウェブコーパスプラットフォーム ANNIS[11]でも、Arborator の JavaScript 版による表示だけの機能をもつ Arborator Draft によって、このツリーバンク[12]が表示される。
しかし、Coptic SCRIPTORIUM で使われているような旧来の Arborator は単なるツリーバンクのビジュアルエディタであり、ウェブ上での個人作業しかできなかったが、今回新しく開発された Arborator-Grew[14]はチームの共同編集が可能で、バージョン管理もなされる。また、新たに追加された Grew のクエリ言語は非常に単純であり、ツリーバンクの分析・検索もこのアプリ上でできるようになった。
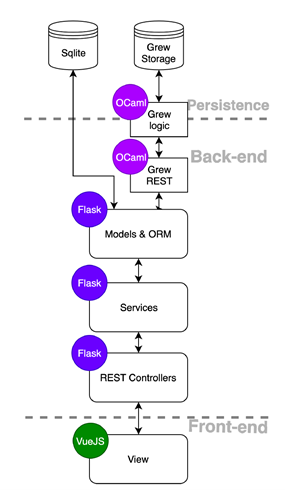
旧版の Arborator はバックエンドで SQLite[15]と Python 2[16]、フロントエンドで jQuery[17]と SVG を描くのに Raphael.js[18]を用いていた。Arborator-Query は抜本的に書き換えられ、バックエンドでは、一部で SQLite を用いつつ、Python 3と INRIA が開発した OCaml[19]、そして Python 用のウェブアプリケーションフレームワークの Flask[20]が用いられ、フロントエンドでは近年 AngularJS や React などと並んでよく用いられている JavaScript フレームワークの一つである Vue.js[21]が使われている(図2)。旧版ではエディタとビューワーのみであったが、新版の Arborator-Grew では、本格的に、アプリのモジュールを役割ごとに Model, View Controller に分割する MVC モデルを取り入れた。
このような抜本的な変更により、チームによるリアルタイムの共同作業や GitHub との連携によるバージョン管理、ツリーバンクの公開、そして、クエリ言語による分析が可能になり、学部での言語学の授業でも使えるようなビジュアル的な分かりやすさや使いやすさを得た。実際に、Arborator-Grew の主要論文である Guibon et al.(2020)では、Arborator-Grew は、学部の言語学や情報科学の授業などで学生が共同で言語を分析するツールとして使用することも考慮したと書いてある。アカウントは、Google アカウントまたは GitHub アカウントと連携することにより即座に作成することができる。プロジェクトや教室での共同作業のために、それぞれのユーザーに Guest, Annotator, Validator, Administrator, SuperAdmin のどれかの役割が割り当てられる。開発者らは、Guibon et al.(2020)を書いた時点で、ナイジェリア英語(Naija)、古フランス語のツリーバンクプロジェクトをこの Arborator-Grew 上で複数人で共同作業で行い、使いやすさ、実用性を確認したという。そののちに数多くのツリーバンクプロジェクトが Arborator-Grew 上で行われ、2021年4月18日現在、筆者の目視では104のプロジェクトが Arborator-Grew 上に存在している。
筆者は、ちょうどそのときに日琉語族琉球諸語のなかの八重山語石垣島白保方言の研究者から当言語のインターリニアーグロス付きテクストデータを得て、そのデータを加工して CoNNL-U データを作っていた。この CoNNL-U 形式のデータを Arborator-Grew にインポートしてみたが、エラーが多く出た。そこで、UD の GitHub リポジトリ上にあるトレーニングデータとして使われているデバッグされたはずのアラビア語 UD[23]の CoNNL-U ファイルを、試しに Arborator-Grew にインポートしてみたが、エラーが出てインポートできなかった。
共同作業で UD ツリーバンクを作るウェブアプリとしては WebAnno[24]が有名であるが、操作が分かりづらい WebAnno と比べ、Arborator-Grew は矢印をドラッグして係り受けを操作するという非常に直感的な操作ができる。また、Arborator-Grew は、係り受けを意味する矢印が大きな弧を描いており、基本的に角ばった小さい矢印を用いる WebAnno よりも見やすい。また、Grew を搭載することにより、さらに UD ツリーバンクを検索できるクエリ言語も搭載された。Arborator-Grew は、UD ツリーバンクの共同作業による直感的なアノテーション、公開、そしてクエリによる分析がこのアプリ一つでできるようになり、大変優れたウェブアプリとして生まれ変わったと感じた。
人文情報学イベント関連カレンダー
【2021年5月】
-
2021-05-03 (Mon)~2021-05-04 (Tue)
デジタル・ヒューマニティーズ&アーカイブ 黙々会於・オンライン -
2021-05-22 (Sat)
第126回 人文科学とコンピュータ研究会発表会於・オンライン
【2021年6月】
-
2021-06-12 (Sat)
第4回関西デジタルヒストリー研究会「KH Coder を使った歴史研究実践」於・オンライン -
2021-06-19 (Sat)~2021-06-20 (Sun)
アート・ドキュメンテーション学会 第32回(2021)年次大会於・立命館大学衣笠キャンパス
Digital Humanities Events カレンダー共同編集人
◆編集後記
今年の5月の連休は家で過ごされる人が多いと思います。SNS をみていると、これを機会に家でネットを活用して新しいスキルを身につけよう、原稿を進めよう、等々、 前向きに捉えようとする人も結構おられるようで、頼もしいことだと思っております。筆者としては、とにかくためこんでしまった仕事を片付けるための 時間にすべく有効活用しなければと、今から緊張しております。一方で、一人でずっと取組み続けるのが得意な人いればそうでない人もいると思います。 ずっと一人では大変かもしれない、という人のために、5月3、4日の午後に、出入りのタイミングは自由の、いわゆる「黙々会」が Zoom で開催されることになりました。たまたまその場に詳しい人が居合わせれば、何か教えてもらえたりすることもあるかもしれません。特に、何か作業していて詰まって しまったときに、誰かに聞けばすぐに解決することもあります。そういう場合にも役立つかもしれません。 イベントカレンダーのところに申込先などが書いてありますので、御興味がわいたらご覧になってみてください。
もう一つ話題を。日本デジタル・ヒューマニティーズ学会の年次国際学術大会、JADH2021の発表申し込みは、 締切りが6月7日となっております。このメールマガジンでも毎年色々な形でご紹介してきておりますが、日本にいながら国際会議に参加できる というメリットがオンライン化でやや減ってきているものの、海外の DH 研究者の方々も含め、国際的に活躍する DH 研究者の方々から親切な査読コメントをいただける希有な機会 でもあります。今後、デジタル・ヒューマニティーズに取り組んでいくにあたっては、国際的な場で研究発表をすることは必須となっていくと思われますので、 その第一歩として、さらには、日本の学会という場において海外の研究者の方々と議論する機会として、ご発表を通じて、ぜひご活用いただければと思っております。
(永崎研宣)
- コメントを投稿するにはログインしてください