人文情報学月報第109号
ISSN2189-1621 / 2011年8月27日創刊
目次
- 《巻頭言》「人文情報学のいくつかの断面」
村上祐子:立教大学大学院人工知能科学研究科・文学部 - 《連載》「Digital Japanese Studies寸見」第65回
「過去とデジタル展開」
:北海学園大学人文学部 - 《連載》「欧州・中東デジタル・ヒューマニティーズ動向」第26回
「コプト語のための Named and Non-named Entity Recognition とOCR4all:オンライン国際ワークショップ Digital Coptic 3報告(1)」
:関西大学アジア・オープン・リサーチセンター「KU-ORCAS」 - 人文情報学イベント関連カレンダー
- 編集後記
《巻頭言》「人文情報学のいくつかの断面」
特に専門的な訓練を受けたわけではなくあくまでも趣味の領域だが、城跡が好きだ。立派な天守閣や石垣があるような城ではない。中世城郭ではそもそも建物は残っていないし、石垣すらほとんどなくて土塁と堀切ばかりだ。山に埋もれた廃城や再開発されてもはや何が何だかわからなくなったような街中の一隅にかろうじて残る遺構を眺めながら、素人ながらに妄想するのがせいぜいだ。どういう人たちがどんな暮らしをしていたのか、戦時にはこの縄張りを生かしてどのように守備戦の布陣を敷いていたのか、どのくらい耐久力があったのか。
そのなかでも石垣が楽しくて、どこからだれがどうやってこの石を持ってきたんだろう?石組はだれが担当したのだろう?と素人目でぼんやり見ている。もちろん江戸城クラスになると伊豆半島の石丁場跡も史跡になっているし、安土城や彦根城みたいにほかの城を廃城にしたときに持ってきてしまったことがわかっている城もあるけれど、大概の城ではぽっと立ち寄る素人には石の由来まではよくわからない。丸亀城のようにもともとはらんでいた石垣では最近の修復の予算も気になっていたが、先日台風で崩れてしまった。石垣の災害復旧は長期戦なので、自治体の底力が問われる。皇居と北の丸公園のように隣接していても管理者によって石垣のメンテナンスに大きな差があることからも、単に現状だけ見ていてはいけないこともわかる。石垣に着目すると海外の城郭との比較も楽しい。地震国ならではの組み方の工夫以外に、治水工事に携わっていた人々とのつながりも気になる。
というような話を口走っていたところ、一緒にやってみませんか?とお誘いをいただき、歴史学素人の自分にできることはいったい?と思いつつ科研費プロジェクト「古代末期~中世ビザンツ期城塞の年代測定にむけた物質的・統計的アプローチの開発」に参加することとなった。この地域の城塞の石垣は繰り返し修復されたとはいえ、石の表面の自然風化のデータからの年代測定は十分可能だと考えられる。そこで収集した石垣の画像データに画像認識技術を適用して築造や修復の時代測定を精密化する手法開発が想定される。建築物の様式をベースにした年代測定に加えて、建材の状況によって分析を精密化できれば、都市防備に向けられる社会的資源の推定も可能になる。個人的に気になっているのは、この地域の石工がどういう集団を構成していたのか?ということだ。築造・修復手法で石工集団を分類できないものだろうか?パンデミック到来に伴い直接現地の遺構調査はできなくなってしまったが、この間こそデータを集め、デジタル技術を用いた分析を進める好機とポジティブに考えていきたい。
しかし一方でもう一つ気になっているのは、このような人文学におけるデジタル技術の応用という観点が高校生以下にあまり伝わっていないように思えることである。高等学校における情報の取り扱いでは、情報科にとどまらず、あらゆる教科で情報技術の適用を含めていくことになっている。しかし、「文系だから情報は「社会と情報」あたりでスマホで犯罪に巻き込まれないように教えるくらいで十分」だと考えられているのか、文学部に入学してくる学生には情報技術は今のところわが事にはとても思えない無縁のものと思われているようだ。最新の研究にはテキスト分析や画像認識が用いられていることや、データベース構築によってこれまで注目されてこなかったような俗語が多用されるテキストも分析対象となってきていることを大学入学以前に意識する機会があれば、高校時代に履修する科目にも相当の変化が生じるかもしれない。このようなデジタル技術と人文学のかかわりを高校生や高校教員、また保護者に対して伝えていく機会をもっと設定できないだろうか?たとえばオープンキャンパスなどの機会に、この種のスキルが身に着けられるかもしれないと考えてもらえれば、数学や情報も学びたいと考えている生徒が人文学に関心を寄せるかもしれない。また文学部の学生対象に、それぞれの専門領域の研究で現在用いられているデジタル技術を示していく授業の開発が、ここしばらくの仕事になっている。デジタル技術が浸透した社会に将来生きていく学生たちに、それが新しい自然だと思ってもらいたい。
執筆者プロフィール
《連載》「Digital Japanese Studies寸見」第65回
「過去とデジタル展開」
この連載にしてはタイムリーなはなしになるが、NHK 広島放送局(以下 NHK 広島局)が Twitter 上で展開している原爆被爆者による仮想tweet「1945ひろしまタイムライン:もし75年前に SNSがあったら?」[1]において、差別扇動を行ったとして批判が相次いでいる。差別扇動の意図があったのか現時点では判然としないなど(大きな問題ではないが)、進行中のできごとであり、脱稿から掲載までにもおおきな動きが予想されることであるが、デジタル人文学と社会という観点からは見逃せない問題であろう。
この連載でもすでに何度か取り上げているように、現代につながる過去の出来事は、容易に現代の争点となりうる。アーリア人のインド侵入すら現代の問題になりうるのだから、歴史時代のことがらで問題にならないものはないとすらいえる。まして、当事者が記憶として残している近現代のできごとをや。デジタル人文学の展開とてももちろん例外ではなく、さまざまな配慮のうえにかろうじて成り立っている展開事例をわれわれはいくつも知っているし、配慮が欠けているとして批判されたものも知っている。守られるべき権利、薄れゆく過去をつたえる使命、あるいは追加害の問題がどうしても入り交じって、過去を再構成する試みは一筋縄ではゆかないのである。
今回の発端となった NHK 広島局の試みは、被爆者となった3人の人物の日記と、存命の人物についてはインタビューを踏まえて、かれらが tweetをしていたらどう書いただろうかという切り口から過去を再構成しようとしたものである[2][3][4](なお、テレビ番組と連動しているとのことであるが、それについては視聴していないので分からない)。その3名は男性中学生・女性主婦・男性新聞記者で、男性中学生のモデルとなった人物がまだ存命であるという。男性中学生・男性新聞記者のtweet は3月30日からはじまり、女性主婦については5月から開始し、8月6日の広島原爆投下を生き延び、玉音放送を経て降伏文書署名へいたるさなかの tweetに関するできごとであった[5]。
できごとは[3]・[4]にくわしいが、8月20日に男性中学生のアカウントから差別扇動にあたる内容の tweet がなされた。Twitter上では、差別扇動に呼応するがごとき内容のもの、それを批判するものなどが入り乱れることとなった。とりわけ、NHK広島局が公開している当時の日記の抜粋にその内容が見当たらないことから、創作によって差別を扇動するものであると強く批判された。NHK広島局は、翌日、この内容がインタビューに基づくものであるという見解を示した[2]。
今回の問題では、NHK 広島局がとった再構成の手法がひとつの焦点となっている。[4]によれば、NHK広島局がこれまで集めてきた被爆体験談や資料、また取材などを踏まえて、被爆を題材とした劇を制作してきた作家に監修を依頼し、内容の取捨選択、展開を決めているという。また、日記をもとにしたものであり、tweetとして再構成する作業は NHK広島局で行ったという。批判の要点としては、現実のものだとしながらも再構成をする者の観点の混入をとくに排除しない点、(もとがなんであれ)原資料にふくまれる取り扱いに注意を要する問題を断りなく、また不用意に取り上げる点、適切な監修がなされていないのではないかという点などがある。また、男性中学生や男性新聞記者のアカウントは広島出身であり、共通語でtweet している点にも疑義が呈されている。これについては、文化の盗用などとも近い問題が潜んでいよう。
このような問題はまったくひとごとではなく、ほぼすべての人文学の対象を取り扱ううえでも問題となりうることがらであろうし、それは過去を再生しようとするタイプのデジタル人文学研究にはほぼつねに問われることがらではないか。古典を過去のただの研究対象として封印するのではなく、生きたものだと擁護をするうえは、古典作品や歴史資料の取り扱いを熟知しない一般社会にむけて、このような問題に一般的に対処する勧告や声明を適時に発信していく必要があるのであろう。
https://twitter.com/dgtack25/status/1291290413995761665.
《連載》「欧州・中東デジタル・ヒューマニティーズ動向」第26回
「コプト語のための Named and Non-named EntityRecognition と OCR4all:オンライン国際ワークショップ Digital Coptic 3報告(1)」
今月号から、筆者が2020年7月12日と13日にオーガナイズした国際ワークショップ Digital Coptic3の報告を行う。本ワークショップは、ブリュッセルで7月に開かれる予定であった国際コプト学会[1]の前日にブリュッセル自由大学で開かれる予定であったが、国際コプト学会がCOVID-19の感染拡大のために2021年の7月に延期された。そのため、本ワークショップも延期するか、それともオンライン開催するか、もう1人のオーガナイザーと発表者と議論したが、発表者からオンライン開催を望む意見が強かったので、オンライン開催を行うことになった。発表者と事前に登録があった参加者は Zoom で参加し、その映像は YouTube にてライブ配信も行った。Zoom では最大80人、YouTubeのライブ配信では最大20人ほどが参加した。YouTubeでの配信は録画され、公開されており、誰でも無料で視聴することができる[2]。また、ほとんどの発表のスライドをワークショップホームページで閲覧することが可能である[3]。なお、本ワークショップは、全米人文学基金(NationalEndowment for the Humanities, NEH)の支援を受けており、その規定に基づき、ホームページもオープンソースのテンプレートを用いて、ソースを GitHubで公開している[4]。
今回は、1日目に行われた発表のうち、コプト語の Named and Non-named Entity Recognition とコプト語 OCRの2つの発表をここに要約する。
Named and Non-named Entity Recognition
Named Entity Recognition は日本語では通常、「固有表現抽出」と訳されるが、Non-Named Entity Recognitionは日本語では定訳がないようであるので、ここでは「一般表現抽出」と訳すことにする。現在、Amir Zeldes 氏(ジョージタウン大学准教授)とCaroline T.Schroeder 氏(オクラホマ大学教授)が率いるコプト語最大のコーパスプロジェクトの CopticSCRIPTORIUM[5]では、品詞、レンマ、ページ、行、作品、統語情報など様々な情報が付与されたタグ付き多層コーパスをウェブ公開している。このタグ付き多層コーパスは、フンボルト大学が開発したANNIS[6]をプラットフォームとして用いており、ANNIS Query Languageを用いて、例えば、「ギリシア語形借用語の動詞の後に、1文字の前置詞が来て、人名が来る」場合など、非常に細かな条件を課して、検索することができる。
多層コーパス(multi-layer corpus)というのは、XML 上で、メインのテクストに層のように注釈が多数ついているもので、Coptic SCRIPTORIUMでは、オリジナルの綴りでスペースで区切られたコプト語の層、オリジナルの綴りで形態素で区切られた層、一般化された綴りでスペースで区切られたコプト語の層、一般化された綴りで形態素で区切られた層、レンマの層、品詞の層、UniversalDependencies に基づいた統語情報の層、文毎の英訳が表示される層、ページ番号の層、行番号の層、柱番号の層、作品 ID などの層があり、それぞれの層でsegmentation(分割)の位置が異なる。例えば、レンマや品詞の層では語毎に層が分割されているが、ページ番号の層では、一ページ上に書かれているテクスト毎に分割され、ページ末が語の途中に来ている場合、ページ番号のブロックは、その語の途中までであり、その分割された切れ目から次のページ番号のブロックが始まる。このように、CopticSCRIPTORIUM が用いている ANNIS のシステムでは、テクストに言語学的タグのみならず文献学的タグも層という形式で表示することが可能である。データは TEIXML、TIGER-XML あるいは PAULA XMLを用いることができる。今回の固有表現抽出と一般表現抽出によって、また新たな層がこの多層コーパスに加わることになる(図1)。

この固有表現抽出と一般表現抽出によって、コプト語のコーパスにおいて、どれが人名でどれが地名か(固有表現抽出)、その名詞が人物か、動物か、植物か、抽象名詞か(一般表現抽出)が瞬時にわかる。それぞれの名詞はそれぞれのカテゴリーの色の枠で囲まれ、その右肩には、アイコンがある。また、固有表現抽出では、人名・地名別のカテゴリーの色の枠で囲まれ、その左肩にアイコンがあるほか、ウィキペディアのロゴも書かれ、クリックすると、ウィキペディアのページに移動することができる[7]。
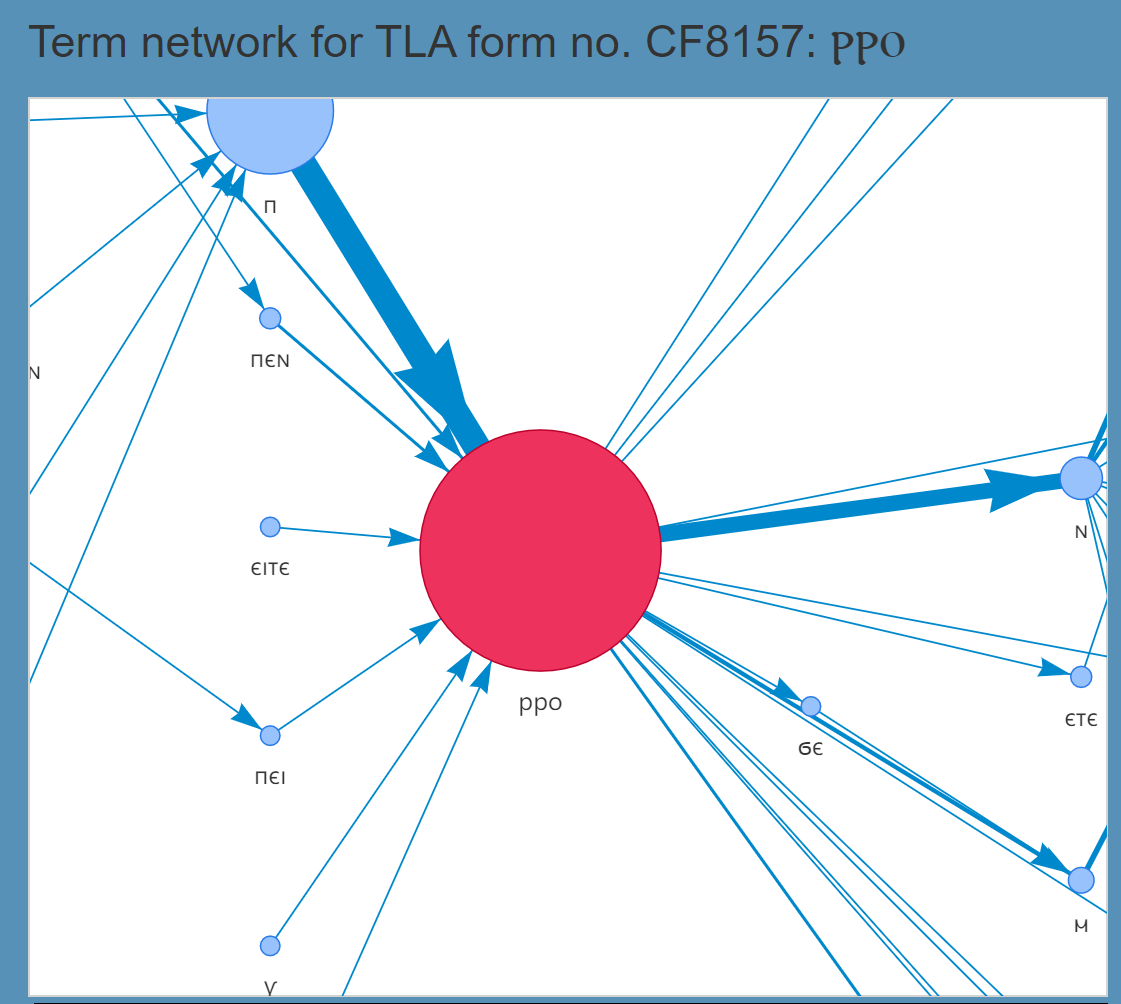
この固有表現抽出と一般表現抽出は、Coptic SCRIPTORIUM の ANNIS だけでなく、筆者も参加した KELLIA プロジェクトで作られた CopticDictionaryOnline[9]でも表示される。まだ、一部しか公開されていないが、次がそのベータ版の写真である(図2)。また、このほかに新機能もあり、ある語の全ての前後文脈をノード上で、統語情報とともに見ることができるterm network 図へのリンクが Attestation の右側にある。

OCR4all を用いたコプト語 OCR
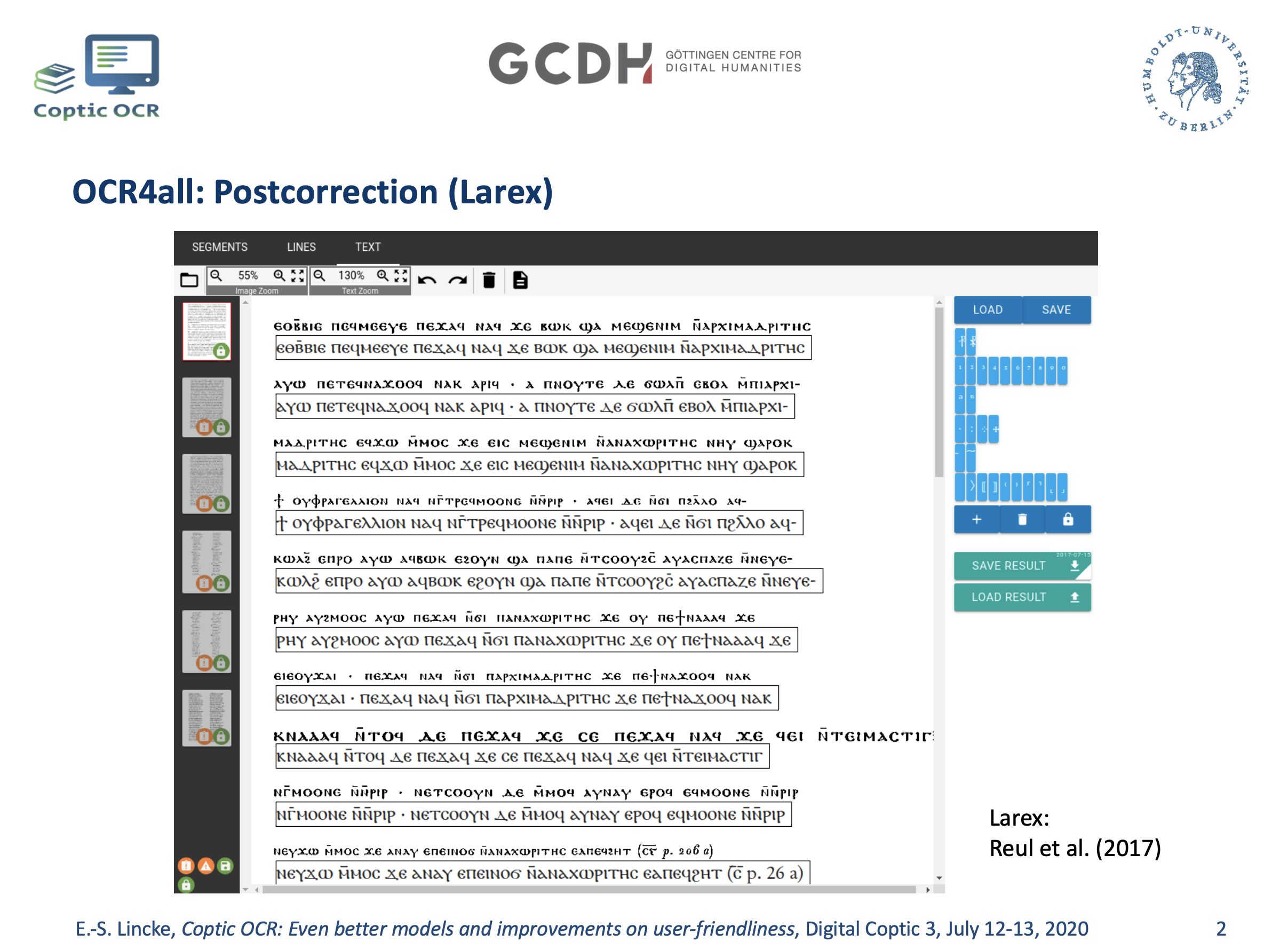
ベルリン・フンボルト大学の Eliese-Sophia Lincke 氏がヴュルツブルク大学のOCR4all プロジェクト[11]と共同で行っている研究は、Tensorflow を OCRopus のモデルに適用させたcalamari を使用し、しかもそれをウェブで誰でも用いられるようすることを目標にしている。これは、筆者も参加していた eTRAPプロジェクトが開発していたニューラルネットワークモデルを用いたコプト語 OCR(ocropy および tesseractを使用)の研究[12]を引継いだものである。Lincke 氏は、2018年から2019年にかけて6ヶ月間 eTRAPプロジェクトに客員研究員として雇われ、筆者らとともにコプト語 OCR の開発を担当したが、そこで開発したモデル[13]をこの OCR4allに適用し、コプト語テクストをユーザがウェブアプリを通して OCRできるようにするため、日々開発中とのことである。精度は特定のフォントだと98-99%であるということである。更に、ドイツの OCR 学の第一人者である Uwe Springmann氏らが開発した potoco と呼ばれるポストコレクティングツールがあるが、その後継でウェブ上で使用可能である LAREX[14]が OCR4allプロジェクトで開発されており、これも Lincke 氏によってコプト語への適用が試みられている。発表では、LAREXのデモの写真などが表示された(図3)。筆者も参加してきたコプト語 OCR プロジェクトだが、今まではコマンドラインで、しかも Linux上でしか動かせなかった[15]。しかしながら、これだとコプト学者など、この技術を最も必要とする普通のユーザにとっては扱いにくい。この OCR4all の GUIがあるウェブペースのアプリケーションだと、誰でも自分の手持ちのコプト語テクストを手軽に OCR に掛けることが可能である。Lincke氏の今後の開発と実現に期待したい。筆者も含めた旧 eTRAP チーム(ドイツ研究教育省の助成は2015年3月に始まり、2019年2月に終了)はこれからも Lincke氏の開発を援助していく計画である。
2日目:“Digital Coptic 3 - Day 2(July 13, 2020),” YouTube, accessed 27 August, 2020,
人文情報学イベント関連カレンダー
【2020年9月】
-
2020-08-31 (Mon)~2020-09-04 (Fri)
AAS-in-Asia 2020於・オンラインによる開催 -
2020-09-05 (Sat)
情報処理学会人文科学とコンピュータ研究会第124回研究発表会於・オンラインによる開催 -
2020-09-07 (Mon)
【発表申込締切】人文科学とコンピュータシンポジウム於・オンラインによる開催:2020年12月12日(土)~13日(日)
【2020年10月】
-
2020-10-17 (Sat)~2020-10-18 (Sun)
デジタルアーカイブ学会第5回研究大会於・東京都/東京大学本郷キャンパス
Digital Humanities Events カレンダー共同編集人
◆編集後記
これまで、イベントレポートのほとんどは、イベントに参加した際に、最初から最後まで参加している書いてくれそうな人にお声がけをしていたのですが、昨今のZoom等でのオンライン開催では、それができないことが多い(=参加者同士の個別のやりとりができない)ために、依頼をする機会を得ることが非常に難しくなってしまいました。オンライン会議だと、そもそも、参加(=接続)していたとしても、ずっとパソコンの前にいるとは限りませんので、どの人が最初から最後まで聞いていたのかもよくわかりません。ということで、イベントレポートを依頼することがなかなか難しいという状況に陥っております。もし、イベントレポートをご寄稿してくださるという人がおられましたら、ぜひ、編集部のメールアドレスにご一報いただければと思っております。よろしくお願いいたします。
(永崎研宣)
- コメントを投稿するにはログインしてください