人文情報学月報第113号【前編】
ISSN2189-1621 / 2011年8月27日創刊
目次
【前編】
- 《巻頭言》「シビックテックと人文情報学の接点」
:佐賀大学地域学歴史文化研究センター - 《連載》「Digital Japanese Studies寸見」第69回
「CODH、江戸の空間に関するデータベースを発表:韓国国立中央図書館が国立国会図書館と共同で East Asia Digital Libraryを運営開始」
:北海学園大学人文学部 - 《連載》「欧州・中東デジタル・ヒューマニティーズ動向」第30回
「The Digital Rosetta StoneProject:ドイツで進む、大学教育と連動したロゼッタストーンのデジタル化プロジェクト」
:関西大学アジア・オープン・リサーチセンター「KU-ORCAS」
【後編】
- 特別寄稿「キングス・カレッジ・ロンドンにおける DH教育の設計をめぐる一考察:日本デジタル・ヒューマニティーズ学会「人文学のための情報リテラシー研究会」設立に寄せて」
小風尚樹:千葉大学人文社会科学系教育研究機構 - 特別寄稿「TEIにおけるテクスト外情報の注釈とセマンティック記述」
:東京大学大学院人文社会系研究科 - 人文情報学イベント関連カレンダー
- 編集後記
《巻頭言》「シビックテックと人文情報学の接点」
私は地域社会の課題解決に適用可能な種々のフレームワークの構築に強い関心を持っています。市民一人一人がもつ知恵や技術を持ち寄り、その場しのぎでない持続可能な仕組みを考えようということです。シビックテックともいいます。近年は、市民団体や共同研究、コンテストを通じて提案やアプリの試作を行っていました。具体的には、地域で衰退の危機にある公共交通の中でもバスの運行状況に関するデータの活用[1]や、一年を通じて頻繁に起こるようになった水害情報のリアルタイム発信基盤の構築[2]などに参加していました。
一見すると人文情報学での研究対象とは異なりますが、身の回りにある事象に意味を見出し、新しい価値を創る点では同じだと考えます。
先に述べた公共交通(主にバス[3])の衰退問題に関しては、自治体側も2016年時点で対策に着手していました[4]。現状、佐賀県を含め人口が少ない地方では、車社会化に伴い交通手段としてのバスの利用機会が年々低下しています。その結果、業者が経営危機に陥ると同時に便数や運行ルートも大幅に縮小し、さらなる利用者数の減少を引き起こしています。地元に必要な最低限の公共移動手段の消滅が現実になりつつあります。
人々が自動車よりバスを現実的な選択肢として受け入れるようになるには、経路と発着時刻、さらにバス停から目的地までの移動や天気をモバイル機器でシームレスに探索可能にする必要があります。言い換えると、GoogleMap などの Web 地図上でリアルタイム運行状況と経路の「動的」確認を行うシステムが求められます。
しかし、当時のダイヤシステムを構成する路線・バス停時刻案内、運賃表示などの更新作業は全て手作業で、作業完了に数日は掛かるものでした。加えて、県内を走る各バス会社の運行データ規格やWeb 掲載への有償・無償対応もバラバラでした。世界の公共交通の経路検索に対応する GTFS(General Transit FeedSpecification)規格[5]はすでに存在していましたが、主要バス会社は全て未対応でした。
そこにタイミングよく、2017年に国土交通省から GTFS規格に準じた「標準的なバス情報フォーマット[6]」が公開されました。この出来事をきっかけに、全国の運行データ規格は徐々に統一され、佐賀県においては当時2社の運行データが公共財のオープンデータとして佐賀県サイト上に無償公開されました[7]。程なくしてGoogle Mapにも登録され、徒歩による所要時間や他社のダイヤが考慮されたバス経路を、地元市民はもとより来訪者や外国人がリアルタイム検索できるようになりました。業者側も同じ規格データを使い回すことで手作業が減り、業務効率の改善に繋がりました。
さらに、一部の専門業者以外もオープンデータを利用可能になったことで、個人、企業あるいは市民団体などが自分の街の課題解決を目指したアプリを作成できるようになりました。その成果の一部は、例えばアーバンデータチャレンジ[8]のようなオープンデータを地域の課題解決に用いるコンテストに見ることができます。コンテストに応募することで、客観的な評価や反応をもらえることが期待できます。私が参加しているCode for Saga[9]では、2018年度にバスの GTFSデータを使った作品をエントリーしました[10][11]。ちなみに、人文情報学関連のデータ利活用作品もエントリー可能で、2019年度は「石造物3Dアーカイブ[12]」、「小城藩日記プロジェクト[13]」が受賞しています。また、国立国会図書館(NDL)で配信しているデータを使った作品の募集もありました[14]。
一連の活動を通じて、実用的なデータおよびシステムを構築するには、多種多様な人々とのコラボレーションが重要であることを痛感しました。Code for Sagaのようなシビックテック団体には、地元の企業、大学、学生、クリエイター、自治体などの背景をもつ世代を超えた人々が混在しています。IT技術があればなおよいですが、前提条件ではありません。そこで得られる人脈やノウハウは、実践的な人文情報学研究を行う上で有用です。
例えば、小城藩日記プロジェクトでは、江戸期の業務記録の目録からキーワードを抜き出し、その意味をあらかじめ決めたグループに仕分ける固有表現抽出作業をしています。これを実現するには古文書をある程度読めて郷土史に関心ある人々の知識が必要です。研究開始当初、一般的な翻刻作業(くずし字をテキスト化する作業)でない、固有表現抽出という少し変わった作業のため、学芸員か大学の研究員あるいは学生あたりに声を掛けようとしていました。そんな折にCode for Sagaに参加しているメンバーに小城市職員が数名いて、たまたま自分の研究を手伝ってくれる人を探していると話したところ、すぐに小城市立歴史資料館の職員に話を通していただけました。この資料館では古文書教室を開いていて、『小城藩日記』を教材にしているとのことでした。完全に盲点でした。早速、教室の紹介で数名を雇い作業開始したところ、想定以上のペースで作業が進み、ネットでは見つけにくい小城の固有表現を多数抽出できました。固有表現が多数集まると、古文書の読み解きの補助や内容分析などの機械学習への応用が期待できます。
冒頭で述べたように、人文情報学を含む情報学は既存の事実から新しい価値を創りあげることを目的にしています。新しい価値はある意味、多くの人を巻き込むことで磨きあげられるように見えます。シビックテック活動では、IT技術有る無し関係なく誰もが情報の成り立ちと応用を体験することができます。今後、人文情報学分野の研究や教育の発展の鍵のひとつになるのではと考えます。
執筆者プロフィール
《連載》「Digital Japanese Studies寸見」第69回
「CODH、江戸の空間に関するデータベースを発表:韓国国立中央図書館が国立国会図書館と共同で East Asia Digital Libraryを運営開始」
情報・システム研究機構データサイエンス共同利用基盤施設人文学オープンデータ共同利用センター(ROIS-DS-CODH、以下簡単にCODH)は、2020年12月7日、江戸買物案内・江戸観光案内のふたつのデータベースを公開し、さらに、既存の江戸マップ β版の拡充と歴史地名マップの公開を発表した[1][2]。その整備によって、歴史ビッグデータの手法にもとづき、江戸という空間(都市として、あるいは時代として)に関する情報基盤を構築する足がかりを得ようとするものであるという。
江戸買物案内[3]は、19世紀初期の江戸中の商人の名鑑である『江戸買物独案内(えどかいものひとりあんない)』(以下『独案内』)をもとに、先述の江戸マップ β版[4](江戸の19世紀初期地図から地名を抽出し、現代の地図などとも統合したもの)と結びつけたり、『独案内』紙面での取り扱いなどを IIIF Curation Platformによってキュレーションしたものである(現代とおなじで、紙幅によって金額が異なる)。『独案内』は、序にいうように、「これをひらけば居ながら諸色の廛[=店]を知るゆゑに物かふ人足を費さずして用を弁ずればうる人もあせらずして益あ」[5]るものである。『日本歴史地名大系』によって地名の正規化が図られており、データとしては質が高いと思うが、情報単体では取り出しにくいので、CSVでダウンロードというのでもなければ、API などもゆくゆくは望まれるところであろう。
江戸観光案内[6]は、やはり近世後期の江戸名所図会をいくつか選び、その挿絵をキュレーションしたものであるとのことである。こちらも江戸マップ β版との連携が図られているが、そのほかに歴史地名マップ[7](人間・文化研究機構および H-GIS研究会が構築・公開する「歴史地名データ」にバイナリベクトルタイル技術を適用し、多数の歴史地名を同時に表示しつつズームイン/アウトする機能を実現したもの)とも連携できるようにデータ附与されているということである。こちらは、名所の挿絵なので、江戸買物案内よりかは形式化がされておらず、挿絵中のキーワード(自由記述による)と地名が主眼である。キーワードは現時点では「神社」といったような語彙統制的なものが目立つ。構造化されたテクストが入れやすいのであれば、挿絵内のテクストや挿絵前後の関係の記述をすべて翻刻すればひとまずは用を足すのではないかとも思うが、現状では難しいかもしれない。
また、細かいことではあるが、全般的に、報告フォームが分かりやすいところに設置されているのは好感が持てる。
江戸市民の空間把握を知る上で、恰好のデータが提供されるものであり、欲をいわせてもらえば、URL の標準化などが今後なされるようになってほしい。歴史地名データ IDなどは、ひとまず参照点たりうるが、個々の名所図会の記述へのリンクはまだ行えないようである(たとえば[8]は「国府台」という統一地名を指し示しても、どの資料を指したものかは、URLのみによっては分からないし、『江戸名所図会』のような異版の多いものであれば、どの資料なのかもじつのところあまり安心して扱えないのではないか)。
また、2020年12月17日には、韓国国立中央図書館(NLK)が、日本の国立国会図書館の参画を得て East Asia DigitalLibrary(EADL)の運営を開始した[9][10][11]。これは、2010年に両館と中国国家図書館とのあいだに結ばれたイニシアチブによってはじめられ[12]、2020年11月に発効した両館の連携協定にもとづいて運営されているものであるという[13]。現在は、両館がデジタル化した古典籍資料を検索するためのサイトとなっているが、体制としては、他機関の参加もできるようになっているという。ほとんどの画面は英語のみの提供のようであるが(英語以外でも利用できるような記述もあったが確認できない)、書誌解題やAboutページなどは英中日韓の4言語があり、中国語圏の利用者への便宜も図られている[14]。これは、中国国家図書館が参加予定であったこともあるであろうし、これらの言語圏の機関の参画を期待する意味もあるのだろう。
また、SPARQL エンドポイントも用意されており、Linked Dataを活用して検索が可能である。データモデルについても説明した文書が配布されている[15]。2014年ごろから開発が続けられていたとのことで、画像も直接メディアを送ったというし[12]、IIIFなどの飛び道具は選択肢とはならなかったようである。これはすくなからず参加障壁となろうが、いずれにせよ、今後の展開がつつがなく進むことを願いたい。
URL が shops なのは不審。小売とはかぎらず、merchants とあるべきではなかっただろうか。
中国国家図書館は事情により最終的には加わらなかったとのことである。
《連載》「欧州・中東デジタル・ヒューマニティーズ動向」第30回
「The Digital Rosetta StoneProject:ドイツで進む、大学教育と連動したロゼッタストーンのデジタル化プロジェクト」
ロゼッタストーンとは、現在大英博物館の一階の古代エジプト・古代メソポタミアの展示室の入口周辺に設置されたガラスケースに入れられている石碑で、コロナ以前は常に周りに人だかりがありカメラやスマホで写真をとられていたものである。ラムセス2世の巨大石像やアッシリアの人頭有翼獅子像など、古代エジプトや古代メソポタミアの威容を誇る豪華な石像が置かれているフロアで、この欠けている地味な黒い石碑が大英博物館を訪れる人たちの注目を集めるのはどういった理由からだろうか。
その答えは、ご存じの方が多いと思うが、この石碑は、古代エジプトで用いられた文字であるヒエログリフを解読する鍵となった、という歴史偉業が背景にあるからであり、その歴史的偉業を成し遂げた人物は、ジャン=フランソワ・シャンポリオン(1790–1832)というフランス人の文献言語学者であった。
フランス南部の町フィジャックに1790年に生まれたシャンポリオンは、幼いころから語学に才能を発揮し、ラテン語・ギリシア語はもとよりセム諸語、中国語など様々な言語に習熟していた。彼は、19歳の若さでグルノーブル大学の歴史学の助教授となる。そのころフランス軍の将軍であったナポレオン・ボナパルト(1769–1821)はイギリスの重要交易拠点となっていたエジプトを奪うために、エジプトを攻め、カイロまで攻め上がり、ギザにてかの有名なピラミッド前の演説を行った。その後ナポレオンは敗退し、フランス本国に戻ることとなるが、その間、フランス軍は、アレクサンドリアにほど近い地中海沿岸の町アル=ラシードでヒエログリフ・デモティック・ギリシア文字の3種類の文字が刻まれた黒い石碑を発見する。これがロゼッタストーンである[1]。その当時、ヒエログリフは解読されておらず、様々な説が飛び交っていた。有力だったのは、古代のホラポロンやアラブの学者達が唱えた、象形文字の形から意味を見出すものであり、コプト語が古代エジプト語の末裔であることを見抜いていた17世紀の碩学アタナシウス・キルヒャー(1601–1680)でさえもこの謬説に陥っていた。この解釈では、何らかの意味はヒエログリフから導き出せるものの、客観的な証拠のない読みがなされることとなり、解読にはほど遠い状況であった。西洋の知識人に知られた古代ギリシア語がヒエログリフなどとともに彫られたロゼッタストーンはヒエログリフ解読のヒントになるかもしれないとフランス人の学者らは気づき、イギリスに接収される前に、この石碑の写しを作成しておいた。その写しの一つが、イゼール県知事で、数学でも多くの功績を上げたジョゼフ・フーリエ(1768–1830)の手にわたり、彼が写しをシャンポリオンに見せたことが、ヒエログリフ解読の糸口となった。
シャンポリオンは、まずロゼッタストーンの薬莢型の囲い[2]に刻まれた王名に注目し、ギリシア語の王名と対照し、その中の象形文字が実は文字の形とは関係なく音だけを表す表音文字であることを発見した。そして、他の碑文の王名を見て、コプトの司祭からコプト語の手ほどきを受けていたシャンポリオンは、いくつかの文字は表音文字ではなく、語を表す表語文字であることを発見し、それらの文字の音価をコプト語から導き出した。そののち、彼は語のカテゴリーを表す限定符[3]という文字があることも発見し、コプト語およびギリシア語の知識をフルに活用して、ヒエログリフの大部分を解読していった。解読作業は彼の早すぎる死のあともドイツのレプシウス等に引き継がれ、ヒエログリフおよびこの文字で書かれた古代エジプト語は解読されていくことになる。
このようにロゼッタストーンはヒエログリフの解読の最重要の鍵となり、紀元後4世紀に最後のヒエログリフが書かれたあと、完全に読み方が忘れられていたこの文字をフランス人が解読したことで、それは近代国家である当時のフランスの国威発揚に繋がった。
この、当時の近代ヨーロッパの学問的偉業の象徴の一つとなっているロゼッタストーンも、現代21世紀の技術によるデジタル化がなされている。しかし、その中心となっているのは、シャンポリオンの母国フランスではなく、ドイツの2大学である。もちろん、大英博物館もロゼッタストーンの3D画像を公開するなどデジタル化をしているものの[4]、碑文の TEI 化まで踏み込んでいるのは旧東ドイツの2大学、ライプチヒ大学とベルリン・フンボルト大学のみである。
ライプチヒ大学は、タフツ大学での Perseus Digital Library[5]の開発を指導したことで著名な Gregory Craneが2013年にアレクサンダー・フンボルト教授職に着任し、彼を中心に、ドイツにおけるデジタル人文学(DH)の一大拠点を形成している[6]。特に、古代ギリシア語、ラテン語、古典アラビア語など、地中海世界・中東の古典語文献のデジタル化とデジタルツールの開発でよく知られ、多種多様なプロジェクトを有する。そのうちの一つが、古代ギリシア語文献学者Monica Berti とデモティック文献(民衆文字エジプト語文献)学者 Franziska Naether を中心にロゼッタストーンを様々な角度からデジタル化する TheDigital Rosetta StoneProject[7]で、2018年から進められている。このプロジェクトはライプチヒ大学の教育と連動しており、様々なロゼッタストーンを題材にした DH の授業が行われてきた。また、MonicaBerti が中心となっているオンラインでの DH の授業である SunoikisisDCでも、このプロジェクトの進捗は何度か取り上げられた[8]。このプロジェクトで最も目を引くのはロゼッタストーンの TEI XML 化である。

ここでは、文ごとにタグづけされ、<sentence>タグの中にロゼッタストーンに書かれたヒエログリフ文、デモティック文、ギリシア語文、そしてそれらの独訳が入れられている。これは多言語のパラレル・コーパスを作る際の、一種のモデルとなるであろう。ここで作成されたデータはUgarit iAligner[10]で視覚化され公開されている。
Ugarit iAligner はライプチヒ大学のデジタル人文学者である Tariq Yousefが開発・運用している、テクスト・アラインメントのウェブアプリである。テクスト・アラインメントとは、対訳や異なる版など、言語が異なったり、言語は同じだが異同のある複数のテクストで、対応する語をそれぞれリンクさせるものである。例えば、以下のロゼッタストーンのテクスト・アラインメントでは、ヒエログリフ文のある単語の上にカーソルを置くと、その単語に対応するデモティックの文、ギリシア語の文の単語がハイライトで表示されるばかりか、英訳で対応する英単語もハイライトされる。データはXML で出力可能である。
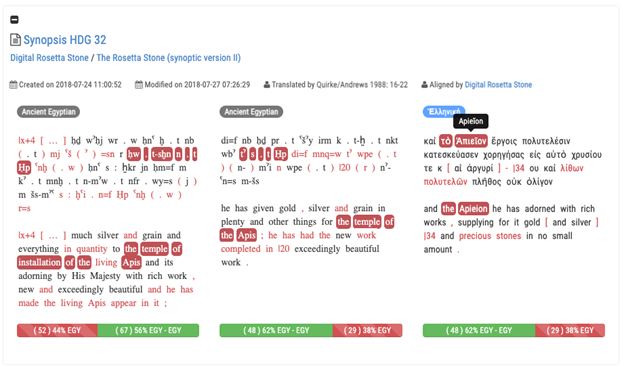
このプロジェクトは、このように教材として非常に有用なものを開発しており、実際に、授業で学生の学習に貢献しているようである。他にも大英博物館でロゼッタストーンの高精細画像を撮影するなどしているようだが、管見では画像関係の公開された成果を見つけることができなかった。また、Arethusa[12]を用いたロゼッタストーンのギリシア語部分のツリーバンクも作成しているとのことである。これらのデータの作成も、プロジェクトが運営する授業にて行われており、教育とデジタル化が結びついた興味深いDH プロジェクトのモデルだといえる。
次回は、もう一つのドイツにおけるロゼッタストーン・デジタル化プロジェクトであり、より言語学的な側面が強いベルリン・フンボルト大学の Rosetta Stone Onlineについて論じる。
- コメントを投稿するにはログインしてください