人文情報学月報第112号
ISSN2189-1621 / 2011年8月27日創刊
目次
- 《巻頭言》「デジタルゲームの保存はどうあるべきか」
:東京大学大学院人文社会系研究科 - 《連載》「Digital Japanese Studies寸見」第68回
「TEIによる日本古辞書符号化モデル」
:北海学園大学人文学部 - 《連載》「欧州・中東デジタル・ヒューマニティーズ動向」第29回
「ヨーロッパで進む人文学のためのデジタル・ツールへの一部課金モデルの導入:Transkribus とTrismegistos」
:関西大学アジア・オープン・リサーチセンター「KU-ORCAS」 - 人文情報学イベント関連カレンダー
- 編集後記
《巻頭言》「デジタルゲームの保存はどうあるべきか」
アドビ社が、この2020年末で Adobe Flash Player のサポートを終了する。2017年にその発表がなされたとき、私が真っ先に考えたのは「Flashで動くゲームが遊べなくなってしまったらどうしよう」ということだった。ウェブサイト上で動画や音声を使ったインタラクティブなコンテンツを作るための規格として1996年に登場したFlash は、2000年代を通して標準規格の地位を確立し、2010年代前半に HTML5にシェアを譲るまで、多くのアニメーションやゲームがその規格で作られた。PCのウェブブラウザ上で無料で簡単に遊べる、いわゆる「ブラウザゲーム」の大半が、Flash のプラグインである Adobe Flash Playerを利用していた。『エイリアン・ホミニッド』(2002年)や『ミート・ボーイ』(2008年)、Facebookと連動した『ファームビル』(2009年)など、2000年代のゲーム史を彩る数々のタイトルが、それを用いて作られた。インディーゲームやソーシャルゲームの発展にとって、Flashは不可欠な存在であった。
もちろん私が抱いた不安は、多くの人々によって共有されており、Flash ゲームを保存しようという動きがすぐさま出現した。Flashのサポート終了が報じられてから半年後の2018年1月、ゲーム系メディアの BlueMaxima が「Flashpoint」という、インターネット上の Flashコンテンツの保存を目的とするプロジェクトを開始した。同プロジェクトは、現在までに59,000以上のゲームと6,000以上のアニメーションを、独自開発の Flash対応アプリケーションを用いてオフラインで動作するかたちで保存・公開している。その中には権利関係の処理が適切になされているかどうか不明なものも多数含まれており、それらが将来どういう扱いになるかは予断を許さないが、ひとまずは、志の高い(?)有志によって多くのゲームが消滅の危機から救われた。
わずか一つの技術や部品の開発を企業が停止しただけで、それまで遊ばれていた膨大な数のゲームが、突然遊べなくなってしまう。それはゲームプレイヤーのコミュニティに大きな打撃を与えるが、とくに経済的利益や社会的意義を損ねるものではないので、誰も「公的」には助けてくれない。そこでファンやクリエイターの「有志」が、さまざまなリスクを背負いつつ、ボランタリーに活動することで、過去の遺産が「非公式」に保護され、プレイできる環境が何とか細々と存続する。こうした展開を辿ったのは、Flashゲームが初めてではない。それはむしろゲームの歴史において幾度となく繰り返されてきた。同様の現象は、PC ゲームだけでなく、アーケードゲームや家庭用ゲームにもみられる。
コンピュータ技術を用いて作動する現代のゲームは、最初から「デジタルなコンテンツ」として作られた、いわゆる「ボーンデジタル」なコンテンツである。しかしだからといってそれらが、そのまますんなりと「デジタルアーカイブ」として保存されるとは限らない。そこには技術的、経済的、制度的にさまざまな困難がある。Flashの事例はその一端を示している。
ここでお断りしておく必要があるだろうが、私は美学・感性学に立脚したゲーム研究者であって、ゲーム保存の専門家ではない。文化財や芸術作品の保存は、どの分野でもそれぞれの難しさがあるだろうし、そもそも完璧な保存などありえない、ということは私も知っている。しかしそのうえでなお、私が研究対象とするゲームの保存はとても難しいと感じている。けれども、その難しさは同時に、ゲーム研究のやりがいや奥の深さでもあると考えている。
先に述べた Flash の問題はまだ軽微であり、より大きな視野のもとでみれば、現在汎用されている OSや記録媒体が遠からず使われなくなり、やがてはデータの互換性も失われることは確実である。かつての MS-DOSやフロッピーディスクが辿った命運を思い起こせばよい。またオンラインゲームの場合、いくらプレイヤーの側が遊ぶための環境を維持したとしても、サーバーがサービスを停止してしまえば終わりである。またGPSによるプレイヤーの位置情報や、同時にログインしている他のプレイヤーの情報は、そもそも残して再現することが不可能である。こうした観点からみれば、2010年代に流行したゲームの多くが、10年後や20年後には遊べなくなり、ゲームの歴史に大きな空白が生じてしまうことが、今から懸念される。
もっともこうした問題は、ゲームに限らず、インターネット上のインタラクティブなコンテンツ全般に共通するものとして、遅くとも2000年代には認識されていた。例えばアメリカで、米国議会図書館の「全米デジタル情報基盤整備・保存プログラム(NDIIPP)」の一環として、「バーチャル世界を保存する(PreservingVirtualWorlds)」というプロジェクト(2008〜2010年)が行われたことは、本稿の読者には周知かもしれない。その最終報告書(2010年)は、デジタルゲームやバーチャル世界の保存の障壁となる「主な問題領域」として、ハードウェアの老朽化、ソフトウェアの老朽化、希少性、保存活動のサードパーティへの依存、コードが複雑で独占されていること、真正性、知的所有権、ゲームの主要な特性(速度や入力方法)を特定する必要があること、ゲームが価値をもつための文脈を構築する必要があること、の九つをあげている。これらのうち、とくに後二者(主要な特性、文脈)は、ゲームは「おもしろく遊ばれる」からこそ、文化的価値をもつのであり、おもしろさのポイントが伝わらなければ保存する価値もなくなってしまう、という本質的な問題を提起している。
ゲームとは何か、それを一言で定義するのは難しい。だがこれまでの研究者の共通見解によれば、ゲームとはプレイヤーが参加するシステムである。つまりルールやアウトプットと並び、プレイヤーの参加(インタラクション)も、それらと同じ資格で、ゲーム(というシステム)の一部を構成するのであり、そうである以上、それも正当に保存の対象とならねばならない。実際、ゲーム機の現物やプログラムのデータの保存に加えて、プレイヤーが操作する様子を映像に記録することで、「そのゲームが実際にどのように遊ばれていたか」を後世に残そうという試みも始まっている(立命館大学の事例[1])。例えば、YouTubeには膨大な数のゲームプレイ動画が保存されているが、プレイヤーが何をどう操作しているのかが記録されない以上、それらの映像はそのゲームを知らない人(数百年後の人類は、間違いなくそれに該当する)から見れば、通常の映画やアニメーションの映像と区別できない。プレイヤーの操作や入力機器など「スクリーンの外側」の情報もセットで記録することで初めて、「ゲーム全体」が保存され、プレイ動画が完全な機能をもつことになるのだ。
もちろん現実には、技術やコストの制約があるため、「ゲーム全体」の保存やデジタルアーカイブ化は困難であろう。しかし、ゲームがインタラクティブなシステムである以上、その保存は、何らかのかたちでプレイヤーの「経験」を含み込まなければならない。そしてその際の手がかりとなるような知見を提供するのも、ゲーム研究者の重要な役割だろうと私は考えている。
毛利仁美「ビデオゲームの保存活動における対象と方法─国内外の実践事例およ び研究の批判的検討」、『アート・リサーチ』第20号(2020年)、pp.21–36。
執筆者プロフィール
《連載》「Digital Japanese Studies寸見」第68回
「TEI による日本古辞書符号化モデル」
拙稿の宣伝じみたことになるが、2020年11月20日、『デジタル・ヒューマニティーズ』誌に日本の古辞書を TEIで符号化するモデルについての論考が掲載された[1]。ここでは、その意義について簡単に解説し、論考ではあまり触れなかった点について補足をしたい。
TEI とは、Text Encoding Initiativeの頭字語で、20余年も前の言ではあるが、豊島正之氏のことばを借りれば、「言語データをテキストとして流通する為の共通交換仕様(encodingformat)の提唱であ」り[2]、仕様そのものの名称でもあれば、提唱活動の名称でもある。P3の時代は SGML を用いていたが、現在では、XML化し、P5と呼ばれる仕様が維持されている[3]。なお、本連載の第46回で稿者が運営委員の末席を汚している東アジア/日本語分科会の紹介をしている[4]。また、永崎研宣氏による紹介もあるので、TEIの意義などはそちらを見ていただきたい[5]。
古典籍の符号化モデルじたいは、東アジア/日本語分科会が日本の古典籍について検討しているが[6]、今回のものはより限定的に、古辞書についてのモデル化を試みたものである。そのちがいはどのような点にあるかといえば、[6]のものは、文献学的な検討を符号化に反映させることを主として試みたのに対して、本モデルでは、古辞書学で必要な符号化はなにか考えた点に差異がある。すなわち、文献学では、本文制定と読解・注解が主たる関心であるのに対して、古辞書学では、そこで論じられる箇々の語や字に多大なる注意を払う。それは現代においても、一般的な文献と辞書の差として残っており、あくまでテクストとしての側面が強い一般的な文献と比して、辞書は、語彙データベースとも称されるように、部分が独立した部分としての意味を持ちやすい。
現行の TEI P5においては、古くからの辞書符号化モジュールから先鋭化して言語資源としての側面にとくに意を払った TEILex-0プロジェクトがあり[7]、それがどれくらい古辞書学と接点を持ち得るのかも興味のあるところであった。TEI Lex-0プロジェクトは、TEIに古くからある辞書の符号化体系の近代化を図る試みである。TEI の辞書モジュールでは、まだ、印刷された辞書から、合理的に情報を取り出すことに主眼があったが、TEILex-0プロジェクトは、語彙データベースとしての利用を最大限高めるための符号化ガイドラインの提唱である(TEIの辞書モジュールの改編を企図したものでないことは説明がある)。
拙稿は、古辞書に共通する構造を軸に、あるていど共通させた符号化を行えることを示すモデルとなっている。それも動機のひとつではあるが、より現実的には、日本古辞書を例に取ったTEI(と辞書モジュール)の解説を行う点にあったと言ってもよい。TEI による日本古辞書符号化モデルは、なにも拙稿がはじめての試みというわけではないが、それらは、TEIの文脈をじゅうぶん理解せずに、既存の概念に近いものを当てはめ、あるいは当てはめかねているように思われた。それは、TEIとしての検証(validation)を行わない点にもっとも顕著に現れる。TEIは、鬱陶しくさえ映る規約の束から成り立つもので、たとえば、ヘッダーにメタ情報として持っているべき要素は最低限なんであるとか、ある要素はかならずどのような属性を持たねばならないとかいったことがらが、XMLの環境のなかで整理されている。TEIを用いるとは、よくもわるくもこの規約のなかに身を置くことである。それによって、規約から曖昧さを可能なかぎり排除し、符号化や解釈、処理のコストを下げることが可能となる。したがって、その規約に従っているかいなかの検証がなくては、わざわざTEI など使う意味はないに等しい。
TEILex-0もそのように辞書に特化した統一規約のひとつで、非構造的な符号化をいっさい排除して、処理の合理性をなるべく高めようとしたものとなっている。もちろん、過去の文献であれば適用できないということはなく、Czaykowska-Higginsらの試みはセイリッシュ語族のコロンビア・ウィナチ語の辞書や語彙カードを TEILex-0に則って符号化したものである[8]。ここでは、もともとの資料の情報構造を符号化担当者が解釈し、TEILex-0の構造に置き換えるということが行われている。そこまでできれば、日本の古辞書についても TEILex-0を直接適用できないわけではないのであるが、本モデルでは、古辞書が言語資源を無批判に取り出せる資料ではないことを加味して、それに見合ったモデル化に取り組んだつもりである。たとえば、<hom>や <cit> を多用することで、TEI の既存の規約を大きく変えることなく古辞書の符号化ができることを示した。とはいえ、それによって、TEILex-0では利用可能な、外部語彙体系の導入や、情報そのものの素性化などといったことは利用できなくなった([7]・[8]の文献に詳しい)。研究のすえに、「安全に」利用可能な箇所だけでもTEI Lex-0で符号化を試みることは学界を裨益するものとなろう。
モデルやガイドラインの制定は、複雑な TEI や XMLの制約に、どのように自身のテクストを当てはめていくか解釈する手助けの意味合いがある。もちろん、それに則って書いたもの同士は、あるていど共通的に扱える利点も期待してはいるが、エコシステムとして意味を持ってくるのは、数年単位の話ではおそらくなかろう。そのような動向を踏まえて、これらのものの改訂や増補が行えれば望ましいのだろうと思われる。
本分科会では、ルビの符号化についての提案を行っている。くわしくは触れられないので、ご関心の向きはつぎの議論を参照されたい。
encoding of rubyglosses – Issue #2054 – TEIC/TEI – GitHub
《連載》「欧州・中東デジタル・ヒューマニティーズ動向」第29回
「ヨーロッパで進む人文学のためのデジタル・ツールへの一部課金モデルの導入:Transkribus と Trismegistos」
最近、ヨーロッパにおいて、DHプロジェクトの財源が打ち切られる、更新できなかったなどの理由で、多数の研究者によって用いられていたデジタル・ツールを使用していて一部課金される例が散発している。筆者がよく使うツールで一部課金化されたものとしてTranskribus と Trismegistos の事例を紹介する。
Transkribus[1]は、特に、欧米や中東の文献の HTR(Handwritten Text Recognition:手書きテクスト認識)のツールとして最もよく用いられてきたものであり、オーストリアのインスブルック大学が中心となって開発されてきたものである。このソフトウェア上で文献の画像を読み込むと、まず、手稿本や写本など、手書き文献のテクストの行を認識させ、その行ごとに画像の下にあるエディタに翻刻を入力していく。50ページほどできたら、その手動で入力したデータをground truth(機械に学習させる教材)として HTR エンジンにパターンマッチングのトレーニングをさせ、文献の残りのページを高い精度で機械に認識させる。その結果は TEIXML で出力でき、大変便利なツールである。筆者はルール大学ボーフムの Sven Osterkamp 教授と共同で、Transkribusを用いて、ローマ字キリシタン資料の自動文字認識モデルを作成している。
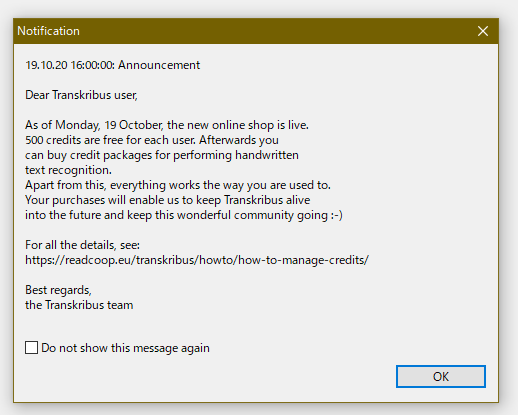
今までは無料でできていた HTR が、2020年10月19日から一部課金化された。この日以降、Transkribusを起動させると図1のようなポップアップウィンドウが表示される。Transkribus の目玉機能である HTR を使わなければ、ほぼ Transkribusで有用なことができないため、この一部課金システムを利用するしかなくなる。この一部課金化は、Transkribusクレジットを購入し、そのクレジットが多い分だけ、多くのページを機械認識させるという仕組みである。まず、支払うシステムとしては、HTRするページの分だけ買うオンデマンド、そして、毎年定期的に支払いその分安くなるサブスクリプションの2つがある。また、使う HTR エンジンに応じて値段が異なる。PyLaiaHandwritten エンジンを使えば1クレジット=1ページとなるが、HTR+エンジンを使えば、1クレジットは1ページ以下と、1ページあたりの値段が高くなる。
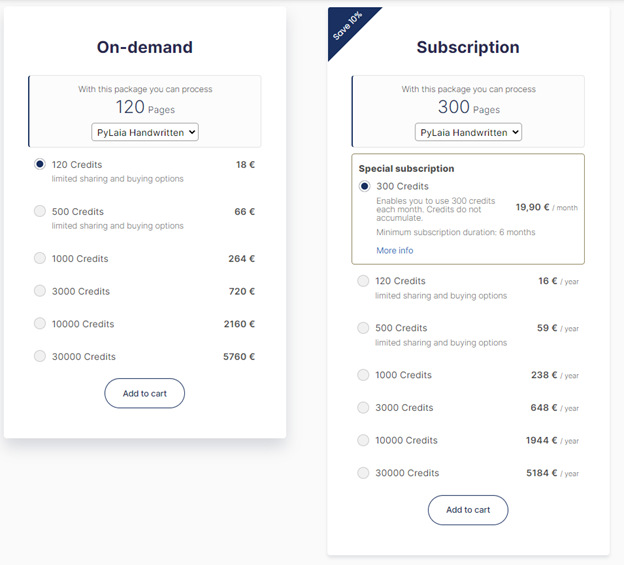
まず、オンデマンドで PyLaia Handwrittenを選んだとして、最も安いのが18ユーロの120クレジットであり、最も多くのページ数をカバーできるのが、30000クレジットの5760ユーロである。最安のものでは1ページあたり0.15ユーロ、つまり現在のレートで換算すると、18.52円、最高のものでは1ページあたり0.192ユーロ、すなわち、23.71円である。通常は、たくさん買えば、単価が安くなると思われるが、ここではそうではないらしい。
他に、READ COOPSCE[3]のメンバーになればこのクレジットが、オンデマンドなら10%、サブスクリプションなら25%安くなる。これには個人では年間250ユーロ、そして団体なら年間1000ユーロ支払わなければならない。メンバーになれば、READCOOP SCE の役員を選ぶ投票権が付与される。
Transkribus 自体は、実はオープンソースで、はじめは GitHub で公開されており[4]、後に GitLab に移った[5]。ライセンスは、Linux と同じようにGNU GPL ライセンス[6]を使用しているため、Transkribus 自体は常にオープンソースとして維持せざるを得ない。しかし、今回は、Transkribus が作ったPyLaia Handwritten や HTR+ といったディープラーニングモデルの使用に課金しているという仕組みである。
また、Transkribus の結果をよりよくするため、スマホで文献を撮影する際に補助として使用する ScanTentも239ユーロで発売中である。これは、机の上に乗るような小型のテント型の装置で、テントの一面は大きな穴が開いており、そこから文献を入れ、底面に置く。そして、テントの頂上にスマホを置き、頂上の穴がカメラの位置にくるようにスマホをセットし、DocScanというアプリを使用して撮影する。このアプリは Transkribus と連携しており、スムーズに Transkribus に写真を転送することが可能である。

現在、メンバーは団体・個人両方合わせて73名である。大学や大学図書館など団体メンバーの方が多い[8]。
もちろん、開発を維持していくには費用がかかる。しかし、このような一部課金化は、発展途上国の個人や学生などにしてみれば高額であることが多く、例えば、エジプトの平均月収の数倍になったりする。このような一部課金化は非常に深刻であり、学問の発展に寄与するのか微妙である。Transkribusは、博士論文のプロジェクトで当ツールを用いる人に限って、無料での使用を許可しているようだが、プロジェクトの計画などを提出して、開発チームに認められる必要があり、許可なしに手軽に無料で使用することはできない。
他に、近年一部課金化された人文学のためのデジタル・ツールとして筆者がよく知っているものが Trismegistos[9]である。Trismesgistosについては、『人文情報学月報』第91号前編で筆者はその詳細を紹介したが[10]、エジプトで発見されたギリシア語文献・民衆文字文献・コプト語文献等を研究する者にとっては必須のツールである。これには、紀元前7世紀から紀元後7世紀までのエジプトで発見された文献のメタデータを網羅的に集めたTrismegistos Catalogue をはじめ、人名のデータベース、地名のデータベースなど研究に応用できるデータベース群である。
こちらも2019年7月22日から一部課金化され、フルに機能を使うには、団体では税抜きで990.91ユーロ、個人では、299ユーロを年額支払わなければならない。無料版でもそこそこ基本的な検索などはできるが、表示数などに制限がかかっているようである。ただし、発展途上国など、国連のHuman Development Index[11]が Very High ではない国の人は、価格について相談することができると書いてある。日本はこの Index が VeryHigh であるため、価格について値下げの交渉をすることはできない。
特にパピルス学者にとっては、Trismegistos の活用は必須で、Papyri.info[12]などに翻刻を登録する際も、Trismegistosの文献のページのリンクを張らなければならない他、様々なパピルス文献関連の DH プロジェクトでは文献ごとに割り振られた Trismegistos ID が使用されている。これらのDH プロジェクトの成果物の資料は通常は無料であるが、Trismegistos が一部課金化されたことで、一部課金化の連鎖が続かないか懸念される。
プトレマイオスーローマービザンツ期のエジプトで発見されたパピルス文献やオストラカ文献、羊皮紙文献を調べる際に、必須のツールであったものが、このように一部課金化されたのは残念だとしか言いようがない。特に、学生や在野研究者などにとってはかなり厳しい措置なのではないだろうか。ただし、もちろん、サービスの発展や維持にコストがかかるのは事実で、かといって、すべてをボランティアに維持してもらってもサービスの低下が考えられる。Linuxや OpenOfficeなどボランティアの無償の労働で支えられている高品質のソフトウェアのように維持されて欲しいが、そのようなボランティアコミュニティがあまり育っていない、人文学のうちのある一分野のためのデジタル・ツールは、金銭をユーザから徴収して維持していく以外方法はないのであろうか。一つのアイデアとしてはより多くのボランティアを誘致することであり、そうするためには、ツールの重要性をその人文学の分野の専門家以外にも知らしめていかなければならない。特にエンジニアの協力は絶対不可欠であり、人文学の魅力をIT の専門家に伝えていく必要があると思われる。
人文情報学イベント関連カレンダー
【2020年12月】
-
2020-12-01 (Tue)
【協働型アジア研究オンラインセミナー】IIIF に準拠した画像公開の方法と TEI との連携於・オンラインによる開催http://u-parl.lib.u-tokyo.ac.jp/archives/japanese/seminar20201201
-
2020-12-04 (Fri)
TEI-C東アジア/日本語分科会 TEI勉強会:電子テキストの理想的な書誌情報を作ってみる (第三回)於・オンラインによる開催 -
2020-12-05 (Sat)
京都大学文学研究科・文学部シンポジウム「デジタル人文学の世界へ」於・オンラインによる開催https://www.kyoto-u.ac.jp/ja/social/events_news/department/bungaku/even… -
2020-12-10 (Thu)
TEI-C東アジア/日本語分科会 TEIガイドライン翻訳会於・オンラインによる開催 -
2020-12-12 (Sat)~2020-12-13 (Sun)
人文科学とコンピュータシンポジウム於・オンラインによる開催 -
2020-12-17 (Thu)
TEI-C東アジア/日本語分科会 TEI勉強会於・オンラインによる開催 -
2020-12-20 (Sun)
東北大学狩野文庫デジタルアーカイブシンポジウム「江戸に学び、江戸に遊ぶ」於・オンラインによる開催
【2021年1月】
-
2021-01-23 (Sat)
第3回関西デジタルヒストリー研究会於・オンラインによる開催
Digital Humanities Events カレンダー共同編集人
◆編集後記
11月21~22日、日本デジタル・ヒューマニティーズ学会(JADH)の年次国際学術大会がオンラインで開催されました。これは元々、大阪大学をホスト校として開催が予定され前年末より通常通りの準備を進めていたところ、コロナ禍により延期され、オンライン開催となったものでした。開催校の先生方のお骨折りにより、小さいながらも本会議2日間+プレイベントという、例年通りのスケジュールで開催され、世界中から集まった興味深い様々な発表だけでなく、インドと韓国のそれぞれのDH学会で中心的に活躍しておられる先生方に講演をいただくなど、意義のある大会となりました。個人的には、デジタル文学をデジタル批評する、という本会議冒頭の発表にとても興味をひかれましたが、今回、なかでも特筆すべきなのは、JADHに新たに Special Interest Groupとして、
JADHとしては、デジタル・ヒューマニティーズとしての研究を推進していくことが重要な課題ですが、同時に、デジタルと冠さずとも今やデジタル技術を多かれ少なかれ利用しないことには人文学研究を進めていくことは困難になってきています。しかしながら、何をどこまで知っていればどれくらいのことができるのか、どれくらいのことは知っていないとついていくのが難しくなるのか、といった、研究を進めていく上でごく基本的なことが十分に共有されずに、コミュニティの中でも個人の中でも知識が偏在化しています。この隙間を、無理のない範囲で埋めていけるようにすることは人文学において喫緊の課題であり、そのためには、情報を収集するだけでなく、継続的な情報の集約・共有の仕方も検討していく必要があります。分野ごとに必要な知識、資料の性質ごとに必要な知識、など、一人の研究者が複数の軸をまたいで自分に必要な情報を無理なく得られるような状況を作り出していくことができれば、個々の研究者においては、情報技術的な手法についての情報収集や適切な使い方の探求よりも、研究対象の内容そのものに没入していける時間を増やすこともできるでしょう。本来、それを教えなければならなかった側にとっては、さらに大きな負担減になるでしょう。
このような営みは、デジタル・ヒューマニティーズ自身の課題からは少しずれますが、しかし、いわば、デジタル・ヒューマニティーズの果実を人文学研究全体に反映させていくということであり、それによって人文学全体が繁栄していくことになれば、それによってデジタル・ヒューマニティーズもまた豊かになっていくはずです。そのようにして、この取り組みが学術研究に裨益し、それを通じて我々の文化を豊穣にすることにつながればと期待しているところです。
(永崎研宣)
- コメントを投稿するにはログインしてください