人文情報学月報第91号【中編】
ISSN 2189-1621 / 2011年8月27日創刊
目次
【前編】
- 《巻頭言》「漢籍の書誌データと利用者タスク」
:慶應義塾大学文学部 - 《連載》「Digital Japanese Studies 寸見」第47回
「東京大学附属図書館アジア研究図書館・漢籍・法帖資料のFlickr公開停止に触れて」
:国文学研究資料館古典籍共同研究事業センター - 《連載》「欧州・中東デジタル・ヒューマニティーズ動向」第11回
「Trismegistos:紀元前8世紀から紀元後8世紀までのエジプト語・ギリシア語・ラテン語、シリア語などの文献のメタデータや関連する人名・地名などのウェブ・データベース群、および、Linked Open Data のサービス」
:ゲッティンゲン大学
【中編】
- 《連載》「東アジア研究と DH を学ぶ」第11回
「「オープン」に関わるイベントで思うことなど」
:関西大学アジア・オープン・リサーチセンター - 《連載》「Tokyo Digital History」第9回
「多言語史料の TEI 化:16世紀の銀山史料の比較研究を事例に」
:東京大学大学院人文社会系研究科 - 特別寄稿「Gregory Crane 氏インタビュー全訳(第2回)」
:東京大学大学院人文社会系研究科
【後編】
- 特別寄稿「著作権法改正で Google Books のような検索サイトを作れるようになる?」
:国立国会図書館関西館 - 人文情報学イベントカレンダー
- 編集後記
《連載》「 東アジア研究と DH を学ぶ」第11回
「「オープン」に関わるイベントで思うことなど」
大学では学期末を迎え、毎週のように様々な研究会やイベントが開催されている。本号では、筆者の参加したそれらのイベントのうち、「オープン」に関わる内容のものを2つ紹介したい。
1つ目は、関西大学を会場に開催された、漢字文献情報処理研究会第21回大会である[1]。 そのセッション2「学術著作物の投稿と契約」では、小島浩之(東京大学大学院経済学研究科講師)が、某団体からの原稿執筆依頼と著作権譲渡の手続きをめぐる疑問から、このセッションを企画したと趣旨説明が行われた。 そして、報告1「学術著作物に関する著作権契約の実態と問題点:原著作者の立場から」では、矢野正隆(東京大学大学院経済学研究科助教)と小島が、「学会名鑑」掲載の学協会の投稿規定を調査し、特に著作権の譲渡に関わる記述の分析について報告した。 矢野らは「掲載論文の著作権は○○学会に帰属する。」という規定が著作権譲渡を定めた規定の典型例と紹介しつつも、そこでいう「著作権」とは著作者人格権のことなのか、それとも著作財産権のことなのかが不明であると指摘した。 その他に、著者が著作権譲渡をしたくない場合の規定や、著作者人格権の不行使、紛争解決にあたっての対応等の規定について、複数の学会の投稿規定を比較しつつ現状と疑問点を報告した。
次に石岡克俊(慶應義塾大学大学院法務研究科教授)が、「学術論文の投稿と契約」と題し、矢野らの調査結果を踏まえて、法学者の観点から投稿規定が抱える問題点を指摘した。 例えば、先ほど「典型例」として紹介された規定は、「譲渡の対象を特定しない著作権の譲渡(包括譲渡)はありえない」ものであり、「契約無効の可能性」があるという。 そのほか、法人格のない学会は団体として契約当事者となることはできず、そのために著作権を論文著者から譲渡されることはできないとも指摘する。 人文系の学会組織に多いケースであり、この点注意が必要だろう。 なお、法人格のない学会の場合には、その代表者たる自然人(例えば会長等)が契約当事者とな流べきであり、規程でその点を明記する必要があるとも論ぜられた。 石岡はさらに、そもそも投稿規定が、学会から著作者に対し一方的な契約関係を強いる附合契約であることを問題視し、両当事者による自由な意思に基づく交渉・協議が行われるための定めを入れておく必要があるという点などについて述べた。
近年、学会誌のバックナンバーのデジタル化やオープンアクセス化のために、著作権譲渡をウェブサイトで呼び掛けるケースが散見されるように思う。 個々の論文著者に対して著作権譲渡等の問い合わせをすること自体が困難な学会は、例えば史学研究会のようにオプトアウト方式で[2]、すなわち問題があれば指摘してほしい、指摘がなければ譲渡を認めたものとするといった方式を採用する場合がある。 このようなケースについて、質疑応答で筆者が質問したところ、やはり実施の際には弁護士等にあらかじめ相談したほうがよさそうだという回答であった。このセッションはディスカッションも盛んで、学会長や学会誌の編集担当らが集まる場所で、改めて開催してほしいと思うほど、有意義な内容であった。
2つ目のイベントは、2月13日に京都大学附属図書館で開催された、平成30年度国立大学図書館協会近畿地区助成事業「オープンサイエンス時代の大学図書館—これから求められる人材とは—」[3]である。1つ目が—やや強引な言い方をすれば—オープンアクセスに関わるようなテーマだったが、こちらは特にオープンデータあるいは研究データ管理が主たるテーマとなった。
最初の講演は、竹内比呂也(千葉大学附属図書館長、アカデミック・リンク・センター長)による「オープンサイエンス時代の大学図書館:教育、研究のパートナーになるために」であった。 竹内は、政策レベルでのオープンサイエンスの動向を述べた後、それが大学図書館の動向(例として言及されたのは国立大学図書館協会ビジョン2020)の示す方向性と基本的な齟齬はないとの現状認識を示した上で、研究データ管理に大学図書館として関与せねばならないと述べた。 その一方で、研究データ管理は大学図書館だけで担えるものではなく、学内組織と大学図書館との連携が必要だと論じた。また、データドリブンな研究活動が進められる現状に対して、大学図書館のサービスは機関リポジトリをその中核に据えて、再度サービス全体を構築しなおす必要があるとも訴えた。
梶田将司(京都大学情報環境機構教授、アカデミックデータ・イノベーション ユニット長)は、「アカデミックデータマネジメント環境での図書館員の役割」というタイトルのもと、京都大学での研究データ管理に関わる活動として2017年11月から進められている、学際融合教育研究センターアカデミックデータ・イノベーションユニット(通称「葛ユニット」)の活動について紹介を行った。 特に、学内の基礎調査を経て、京都大学内にどのような研究データがあるのかを示す研究データマップと、研究データ管理の成熟度モデルなどを作成しているとのことである。これらの詳細については、2月28日に京都大学で開催予定のワークショップで報告する予定とのことで、筆者もこれに参加する予定である。
最後に、山中節子(京都大学附属図書館学術支援課長)は、「大学図書館によるオープンサイエンス支援:国内事例を作る」として、京都大学附属図書館におけるオープンサイエンスの検討状況と取り組みを報告した。 同館では、研究データのうち、まずは論文のエビデンスデータを対象として、公開に向けた検討を進めているとのことであった。 しかし、学内での研究データ管理や公開のための方針が定まるまでの間にも、利用者からはすでに研究データの公開に関する問い合わせが届いているとのことで、同館では利用者への情報提供を行うウェブサイトを学内向けに作成しているとのことであった。 京都大学のように充実した組織基盤を有する大学であっても、オープンサイエンス支援のためには、研究データの公開以外にも大学図書館が取り組むべきオープン化のための課題が山積しているとして、参加者へ連携を呼び掛け、講演は終了した。
その後の質疑応答では、筆者としてはいささか憂慮するような発言が飛び出した。 筆者から、オープンサイエンスの一つの特徴である大学の「外」へのデータ提供については、大学図書館としてどのように取り組むのかを尋ねたところ、竹内から、大学図書館の利用者は学生と教員であって、一般市民は想定しておらず、仮にデータ提供するとしてもそれを行うのは県立図書館等の公共図書館の役割であり、求められれば大学図書館が公共図書館へ協力することはありうるとのことであった。 京都大学所属の残り2名の講演者からも、一般市民へのデータ提供に関しては積極的な姿勢は感じられなかった。 まずはアカデミックな利用を想定してオープンにし、そのオープンなデータが結果的に一般市民に恩恵を与え得る(それでも当初から意図的に提供することはない)という考えだと思われる。
ところで、筆者の関心のひとつにパブリックヒストリー(Public History)という研究・実践分野がある。 パブリックという名前の通り、歴史学の知や研究活動を市民(パブリック)へと開いていく活動やそれを研究する分野である。これは歴史学だけでなく、パブリックヒューマニティーズ(Public Humanities)としてDHの研究領域の一つにも位置付けられ[4]、人文学の様々な分野でも行われている。 仮にそのような研究活動の一環で、大学図書館のもつ研究データを市民(パブリック)へ提供してほしいと教員が要望した場合、大学図書館としてはどのような対応を執るのだろうかと、質疑への応答を聞きながら考えていた。 サービス提供対象者は学生と教員だけだとして、断られるのだろうか。 それとも、サービス提供対象者からの要望によって、大学図書館のサービス提供対象が市民(パブリック)にも広がるのだろうか。あたかも矛で盾を突くようなこの事態は、単なる空想ではない。 大学図書館がオープンサイエンスを妨げる盾、いや壁とならないことを、ただ願うばかりである。
Digital Humanities 2019 : “Complexities” Call for papers. https://dh2019.adho.org/call-for-papers/cfp-english/,(アクセス日:2019-02-20).
《連載》「Tokyo Digital History」第9回
「多言語史料の TEI 化:16世紀の銀山史料の比較研究を事例に」
はじめに
以前本誌で報告したように、2018年9月に開催された TEI 2018では、Tokyo Digital History が「日本における TEI 準拠のデジタル学術資源の普及を促進する」ことをテーマとしたパネル発表を行った[1]。連載第9回目となる今回は、筆者が担当したパネル第2報告「多言語史料の TEI 化:16世紀の銀山史料の比較研究を事例に」を紹介し、多言語史料の TEI 化の試みと課題について述べる。
1. 報告要旨
第2報告は、様々な言語で書かれた歴史史料を、比較研究・共同研究で利用する際、TEI 化がどのように有効であるかを検討するものである。
筆者は、石見銀山世界遺産センターとの共同研究「16世紀の世界の鉱山比較検討」に携わっており、その中で、「銀の世紀」と呼ばれる16世紀に世界で同時多発的に起こった銀山開発ブームについて比較研究をしている[2]。 対象は、当時世界有数の産銀地域であった、日本の石見銀山、スペイン領のポトシ銀山、オスマン領のクラトヴァ銀山である。これらの銀山に関する史料は、日本語、スペイン語、オスマン語で書かれているが、「16世紀の銀山開発」という共通のテーマを持っており、それぞれの史料中に出てくる鉱山用語・数字・計量単位などを比較することは非常に有意義である。 これまでの鉱山史研究では、史料言語の違いから、一地域を超えた世界的な銀山開発の状況を明らかにする試みはなされてこなかったが、共同研究を行うことにより、史料言語の差異を乗り越え、16世紀の銀山開発の様子を面で理解しようとする点が、本研究の大きな特色である。
このような試みにおいて、共同研究で用いる多言語史料をTEIガイドラインに準拠して構造化することは、異なる言語・文字で書かれた情報を共通の形式で記述し直して互いに比較可能な形にし[3]、データベース構築や可視化、テキスト分析など[4]、今後の比較研究をさらに発展させる素地を整えることにつながる。 これは、今はまだない世界の鉱山史のデータベース作成の基礎作業となるだろうし、今後他の鉱山史料の情報を集積するプラットフォーム作りに貢献できるものと考える。
以上のことを踏まえ報告では、石見銀山世界研究センターとの共同プロジェクトについて紹介し、多言語史料マークアップを共同研究で行う際に生じた問題と、それについての対応を、暦と銀の納付額を具体例にとりながら紹介した。
2. 多言語史料の TEI マークアップの課題設定
具体例として取り上げた史料は、石見銀山の開発記『石州仁万郡佐摩村銀山之初』と、オスマン朝帝国の財務帳簿のひとつ“Başbakanlık Osmanlı Arşivi, Maliyeden Müdevvel Defter Nu. 149”(以下、MAD.d.149)である。


これらの史料は、日本語とオスマン語というそれぞれ異なる言語・文字で書かれているが、16世紀半ばの銀山からの納税額について記述されているという共通点を持つ。 このことから今回は、この2つの史料に記述された情報について、暦と納税額の2点に着目し、統一的な形式で TEI マークアップすることを課題とした。
歴史史料に記述される異なる文字・暦・単位については、すでに表記の試みや自動変換サービスの提供が行われている。 例えば、“MAD.d.149” の中で使われている、オスマン帝国の財務官僚のみが用いた特殊なスィヤーカト数字は、現在、ISO/IEC JTC1/SC2/WG2に提案されているところであり、将来的にはユニコードで表記できるようになることが期待される[5]。暦については、関野樹が“Time Information System Hutime”というウェブサイトで、様々な種類の暦を変換できる暦変換サービスを提供している[6]。 この変換サービスでは、和暦から西暦への変換のみならず、ヒジュラ暦から西暦への変換、和暦からヒジュラ暦への変換など、複数の暦の横断的な変換サービスが提供されている。単位については、小風尚樹が歴史的な度量衡の体系をマークアップするためのTEIタグセットを提案しており[7]、それについては同パネルの第3報告として提示された。
本報告での取り組みは、これらの規格やツールを適宜利用しながら変換した情報や記述方法を、TEIマークアップの中に取り入れることで、原語と、誰にでも分かる統一的な基準で記された情報とを、同じ場所に併記することである。 それにより、原語を読めない人でも史料の情報を読み取ることができるし、統一的な基準で記述しておけば比較、データベース化、グラフ化などの処理も容易にできるようになる。 しかも、そのデータベース上での統一的な情報・原語表記・史料上での登場箇所を結びつけて様々な処理をすることも可能になる[8]。
3. 具体事例:暦と銀の納付額のTEIマークアップ
暦の TEI マークアップ
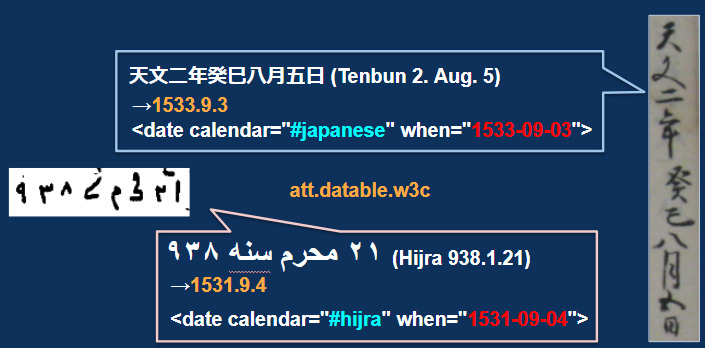
右は和暦で「天文二年癸巳八月五日」と記述したもの、左はヒジュラ暦で「938年第1月21日」と記述したものである。文字や史料についての知識がなければ、判読することができないために暦変換サービスを利用することができず、それぞれ西暦何年に当たるのかを知ることも困難である。 この問題を解決するため、文字を判読した上で暦変換サービスを利用し、変換した情報をTEIで記述することによって、専門知識がない人でも分かるようにする。
作業としては、まずそれぞれの文字を書き起こす。それから暦の情報を読み取り、“Time Information System Hutime”の提供する暦変換ソフトを使って西暦に変換する。“att.datable.w3c”の @when 属性を使って[9]、それぞれの暦が、和暦とヒジュラ暦であること、西暦でそれぞれ1533年9月3日と1531年9月4日に当たることを記述する。 ここでの日付の記述ルールは、ISO や W3C で定められている「YYYY-MM-DD」に準拠することがTEIガイドラインで定められているため、それに従っている。
このようにTEIに準拠して変換結果を記述することで、史料の利用者は実際の記述を確認しつつ西暦に統一して出来事を理解することができる上、データベースを作成する際にもこの実際の表記と西暦とを併記しつつ、その前後の文脈まで戻って確認できるようにする仕組みが可能となるため、研究上の有効性も高い。
納税額の TEI マークアップ

納税額の TEI マークアップにあたっては、納税の詳細に十分注意する必要がある。 それぞれの地域・時代によって、度量衡、納税する素材、価値などが異なるためである。それらの違いについて、可能な限り実際の記述に即して正確に記述すること、また統一的・比較可能な形で記述することが重要である。 この事例では、前述の1533年に石見銀山で1年間に100枚の銀貨が、1531年にクラトヴァ銀山で3年間に1,200,000枚の銀貨が納税された記録を扱う[10]。
まず該当箇所に対し、<measure>タグを使用する。その上で、いくつかのアトリビュートを使用して、納税の詳細を記述する。まず、これが納税額であることを「type」アトリビュートを使って「type=“tax”」と示す。 次に、それぞれ異なる納税期間を「term」アトリビュートを使って「term=“1”」「term=“3”」と示す。そして、単位がそれぞれ「枚」「akçe」であることを「unit」アトリビュートを使って「unit=“#枚”」「unit=“#akçe”」と示す。納税の材料が銀であることを「commodity=“silver”」で示す。 これに加えて、同じアトリビュートの中に、原語での表記「銀」「nuḳre」を示すことで、各原語同士を容易にリンクできるようにする。尚、オスマン語史料の納税額1,200,000アクチェは、実際にはスィヤーカト数字で書かれており、上述のように、将来的にはユニコードで表記できるようになることが期待される。
TEI ヘッダーへの追記
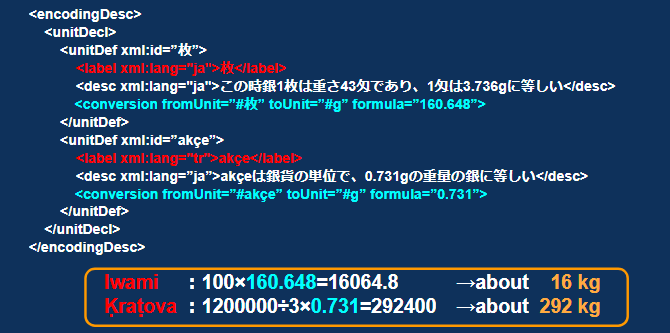
次に、TEI ヘッダーに、この当時の各地の銀貨1枚の重量を記述する。この情報を付加することにより、情報を見た人が自分で銀重量をグラム換算することができるだけでなく、XML の参照の仕組みを用いてこの情報を使った自動換算もできるようになる。
たとえば、前節「納税額の TEI マークアップ」の例における「unit=“#枚”」は、XML の ID 参照として「枚」という ID のついたエレメントを指しているため、ここでの「xml:id=“枚”」を参照することで、それをグラム換算した(toUnit=“#g”)の値を「fomula=“160.648”」として確認することができる[11]。
石見銀山では1年間で銀貨100枚を納めるが、この当時銀貨1枚は160.648グラムだったので[12]、100 × 160.648 = 16064.8となり、年間の納付銀重量は、約16キログラムであったことが分かる。 クラトヴァ銀山では、3年間で銀貨1,200,000枚を納めていたことが前出のマークアップ情報から読み取れるので、石見との比較のために1年分の枚数を求める。この当時銀貨1枚は0.731グラムだったので[13]、1,200,000 ÷ 3 × 0.731 = 292,400となり、年間の納付銀重量は約292キログラムであったことが分かる。
おわりに
多地域・多言語の史料を扱うグローバル・ヒストリーにおいては、時代的・地域的差異を含む情報を比較できるように統一的に表現する必要がある。 そのために必要な、ユニコードや暦変換サービスなどは整えられつつあるので、今後は、それらの情報をスムーズに共有できるようにすることが課題であり、ここまでみてきたように、TEI はそれにあたって有益な手法の一つだろう。 TEI によるマークアップはやや迂遠にみえるかもしれないが、原文との対応づけを機械的に処理しながら正規化されたデータを扱うことができるという点で、一次史料が重要な学問においてはメリットが大きい。 それができるようになれば、原語が読めない人でも史料の理解が可能になり、共同研究がさらに発展することが期待される。
Maura Ives et al., “Encoding the Discipline: English Graduate Student Reflections on Working with TEI,” Journal of the Text Encoding Initiative 6 (2013), available from http://journals.openedition.org/jtei/882 (accessed 18 January 2019).
執筆者プロフィール
特別寄稿「Gregory Crane 氏インタビュー全訳(第2回)」
- コメントを投稿するにはログインしてください