人文情報学月報第127号
ISSN 2189-1621 / 2011年8月27日創刊
目次
- 《巻頭言》「『源氏物語』写本本文への計量文献学の応用のー事例」
:淑徳大学経営学部 - 《連載》「Digital Japanese Studies 寸見」第83回
「国立国会図書館次世代デジタルライブラリーで新 OCR のデータが追加される」
:北海学園大学人文学部 - 《連載》「欧州・中東デジタル・ヒューマニティーズ動向」第44回
「計量文献学によるヴェーダ語文献の時代・地域推定と Universal Dependencies によるアノテーション:京都大学デジタル人文学国際会議 KUDH2021「Digital Transformation in the Humanities」3日目 Session 1b 開催報告・後編」
:京都大学大学院文学研究科附属文化遺産学・人文知連携センター - 《連載》「デジタル・ヒストリーの小部屋」第2回
「デジタル時代の史料における歪み」
:千葉大学人文社会科学系教育研究機構 - 人文情報学イベント関連カレンダー
- 編集後記
《巻頭言》「『源氏物語』写本本文への計量文献学の応用のー事例」
古典籍の画像公開が進み[1]、書かれた本文の状態で、様々な作品を目にする機会が増えてきました。公開された古典籍を眺めてみると、高校の「古典」の教科書に掲載されている校訂された本文からは想像できない、本文の多様な姿がそこにはあります。本稿では、この大量の古典籍の画像公開時代の「幕開け」を、新しい研究の可能性の機会をとらえて、『源氏物語』写本を中心として本文の調査に取り組んでみた、現在進行形の悪戦苦闘を述べたいと思います。
一口に、同じ『源氏物語』の写本といっても、異なる写本を比較してみると、その写本のサイズや筆跡に違いがあります。さらに、「同じ作品」と言っても、所々本文が異なっている写本が大量に存在します。それらの写本を比較すると、教科書から受ける印象とは随分と異なった「同じ作品」の世界が広がっています。例えば、変体仮名はもちろんのこと、変体仮名の間に所々に漢字があります。漢字は官職や敬語に多く使われ、当て字の熟語も見つかります。続いて、写本に書かれている本文には、句読点がない場合もあり、読みにくいことに気づきます。段落もありません。段落かと思うと、それは和歌の書き出しであることが多いです。そして、誤写の修正や脱落を挿入している文字や異なる本文の存在を示す文字があります。挿入されている文字は墨の色や筆跡が異なることもあります。カラー画像であれば、朱で斜線が引かれていることも目に入ります。行間に和歌が記入されていることもあります。しかも、ここで指摘した相違点は写本ごとに異なります。
この様に複数の『源氏物語』写本を比較すると、多様な本文の様相に気づきます。同時に、教科書に掲載されている本文は、様々な研究成果が積み重ねられて校訂されていることを教えてくれています。これは視点を変えてみると、それだけ研究の切り口があり、専門家による校訂本文を作るまでのプロセス一つ一つが研究テーマとなり得ることを示しています。そこで、まず古典籍に特徴的に出現する写本本文の変体仮名に着目してみようと考えたことが、研究の始まりでした。幾つかの『源氏物語』写本の変体仮名を読んでいるうちに、筆跡が異なることに加えて、それぞれの写本ごとに使われている変体仮名が異なることに気づいたことがきっかけです。
最初に、図書館にある関連する書籍を順に読んでみることにしました。どうやら、管見によれば、写本に出現する変体仮名の使い方、正確には変体仮名の元となっている漢字である「字母」の使い方に関する調査報告は少数のようでした。この「字母遣い」は、書写した人物や書写年代、書写対象元の写本である親本といった要因によって影響を受けると考えられますが、その実態は明らかではありません。そこで、この「字母遣い」を対象に、統計学の方法を用いて分類する方針を立てました。
その次は、古典籍の選択です。藤原定家の晩年の筆跡は定家様と呼ばれ、特徴的な字形をしています。定家筆の古典籍は長年尊重されてきたことから、定家筆(とされる)写本は多く残り、かつ出版されているので、解題も書かれ、調査も相対的に容易です。そのため、「字母遣い」を調査するためには、適切な対象であると考えられます。幸いなことに図書館には定家筆の『古今和歌集』や『伊勢物語』といった作品の影印本もありました。どんな結果が出るかわからないままに、これらの写本本文のデータを入力することから始めることとしました。
定家筆とされる古典籍の本文データを対象に分類した結果、互いに「字母遣い」がよく似ていることが明らかになりました。また、定家の父である俊成や、姉である坊門局、息子である為家とも、定家の「字母遣い」は異なり、分類できることが明らかになりました。さらに調査を進めると、定家の「字母遣い」は和歌集や物語、日記、といった作品の種類に関係なく分類されることや、「字母遣い」を調査するためには5000字程度調査する必要があることが明らかになってきました[2]。
その後、さらに調査する写本の対象を広げて、この知見を確認することとしました。その調査対象として、利用が容易で、書写者や書写年代が明らかな日大本『源氏物語』写本を選択しました。この写本を調査した結果も、定家による写本と同様に、同一人物による写本の「字母遣い」は互いに似ることが明らかになりました[3]。加えて、同一人物であっても書写年代により「字母遣い」が異なることも示唆される結果となりました。異なる人物が書写した写本の「字母遣い」が似る場合は、文献学の知見を用いて何らかの理由が推定できることも明らかになってきました。
本調査結果は、「字母遣い」という写本本文の一部の情報だけを用いた調査であることと、仮説を提案する方法を用いていることにより、この結果だけで同一人物による写本である、と主張することは困難です。しかし、既存の分野の方法や根拠とは異なり、統計学の方法を用いて写本間関係を提案したことは、通説や提案されている仮説の蓋然性を高めることや新しい仮説の提案が可能であると考えています。
この他にも、文学や文献学の研究において重要視される『源氏物語』写本は多数存在し、公開されています。これらの写本の「字母遣い」を対象に、この知見を応用することで、蓋然性のある写本間関係を提案することを試みています。具体的には、出版されている鎌倉時代と室町時代書写の『源氏物語』写本を対象に調査を進めています。
統一した方法で写本の調査を続けていった結果、本文の相違の比較ができるだけの本文データを蓄積することができました。そこで、次の調査として、仮名と漢字の使い分けといった本文表記の相違に着目して、本文の分類を試みています[4]。この調査結果からは、同一人物が関わっている写本や書写年代が近い写本の中に、表記が似た関係があることが明らかになってきました。表記が似た写本は、それほど多くはないのですが「共通の親本を持つ」関係や「本文異同が少ない」関係にある可能性を指摘することができました。書写年代が近く表記が似る写本は、その時代の写本の流布状況を示している可能性もあるでしょう。表記の調査は、まだ始めたばかりですが、これからも調査対象の写本を増やして、本文表記の知見を得たいと考えています。
今後、古典籍の画像公開に続いて、その変体仮名が翻刻された本文データが公開され、その次の目標は何かと考えてみると、その一つの方向として、他の古典籍と比較し、その古典籍の位置付けを明らかにすることがあるでしょう。その際には、本調査の様な、古典籍の本文の特徴を用いた、新たな古典籍間の関係の指摘をする方法が必要となると考えています。その結果として、古典籍の関係を示した「地図」が描けると、それに基づいた次の研究テーマの設定ができ、さらなる研究の進展が期待できます。本研究が、これからの新しい研究の一助になれば幸いです。
執筆者プロフィール
《連載》「Digital Japanese Studies 寸見」第83回
「国立国会図書館次世代デジタルライブラリーで新 OCR のデータが追加される」
2022年1月31日、国立国会図書館次世代システム開発研究室(以下、国会図書館次世代室)より「次世代デジタルライブラリー」[1]において、全文検索の対象拡大および画像検索機能が改善されたことが発表された[2][3]。この次世代デジタルライブラリーは、国会図書館次世代室で開発中の機能等の検証や早期提供のため試験的な公開を行うために設けている NDL ラボ[4]の一部である。NDL ラボでは、このほかにも外部との協力などからいくつかの試験的サービスが提供されている。
次世代デジタルライブラリーについては、本連載第52回でかつて触れたことがあるが[5]、国会図書館デジタルコレクション[6]の資料の実験的検索システムである。公開の時点では、ごく一部の書籍が対象であったが、今回の追加では、全文検索機能の対象として、著作権保護期間の満了した図書資料を7万点追加したという[2](その後、公式なアナウンスはないが、さらに資料が追加されている[7])。また、画像検索機能についても、Google Landmarks Dataset v2[8]を援用して、認識精度を高めてあるとのことである。これについては、2020年3月31日[9]・2020年8月31日[10]にリニューアルや画像検索対象の大幅な追加が行われている。以下、全文検索について見ていく。
全文検索機能については、2023年4月公開を目指している、次期・国立国会図書館デジタルコレクションで追加される予定だという[2]。これは、たんに全文検索の対象が広がっただけではなく、デジタル化資料の OCR テキスト化事業をあらためて行い、高い精度のデータを得られたものである[11]。この事業は LINE 社が受託して、同社の CLOVA OCR を用いたもので[12]、複雑なレイアウトの画像資料からでも高精度に文字を推定することができるとされる。国会図書館次世代室青池亨氏によれば[11]、94%程度の精度であるという。一字一字の精度は、たしかに当初の全文検索の結果より顕著に上がっているものと思う。また、同氏の資料では、深層学習を用いた OCR の開発が説明されているが、これはまた日を改めてお目見えのあるものと思われる。
全文検索の操作性などはおおむねそのままであるが、書誌情報による絞り込みや検索結果の並び替え機能などが追加されている。また、2文字単位で検索データベースに登録されているため、1文字単位では検索できない旨の注意書きがされた。読めない文字は〓となるようだが、その状況はまだ不分明なところがある。「教」の旧字体である「敎」が取り扱えないということはすでに知られている[13]。
検索結果を開き、検索した文字列のあるコマへと移ると、当該の文字のあるところにピンマークが付くようになっている。これは、OCR の結果が画像上の文字の位置とともに保存されているからできることで、従来はなかったものである。ビューワー画面右下から全文テキストがダウンロードできるようになっている。それを見ると、ルビや行配置の扱いにはやはり難しさがあるようで、とくに目次などのようなレイアウトの複雑なページでは、しばしばもとの順序との対照にも苦労するようなデータになっている。本文ではおおむね順序も問題なく取れているが、見出しの数字などがとんでもない場所にあったりする。文字の位置情報を含んだデータも含まれており、それを見て自力で整えることは多少可能であろう(もともとの OCR の出力結果がどのようなものであるかは、[11]の青池氏資料を参照)。
著作権保護期間の満了した書籍のデジタル画像から1行ごとに切り出した画像データとテキストのペアからなるデータセットなどの公開もされており[14]、技術的な発展としても期待ができる。また、明治から昭和にかけての厖大なテキストデータが一挙に手中に入ったことは驚くべきことであろう。この時期はいわゆる高級語彙を中心に漢語・漢字表記の変化が進む時期であり[15]、辞書も手薄なところがまだまだある。このなかに分け入ろうとすることは、まさに人文情報学的な手腕がものを言うこととなろう。
とくに、国立国会図書館次世代室青池亨氏による資料を参照。
間淵洋子「近代雑誌コーパスにおける漢語語彙の特徴 : BCCWJ との比較から」『国立国語研究所論集』13、2017 https://ci.nii.ac.jp/naid/120006319944。
間淵洋子「コーパスに基づく字順転倒漢語の網羅的把握の試み」『言語資源活用ワークショップ発表論文集』3、2018 https://ci.nii.ac.jp/naid/120006698100。
髙橋雄太「近代における和語の用字法の変化―カワル・カエルとアラワレル・アラワスを中心に―」『明治大学人文科学研究所紀要』85、2019 https://m-repo.lib.meiji.ac.jp/dspace/handle/10291/20227。
《連載》「欧州・中東デジタル・ヒューマニティーズ動向」第44回
「計量文献学によるヴェーダ語文献の時代・地域推定と Universal Dependencies によるアノテーション:京都大学デジタル人文学国際会議 KUDH2021「Digital Transformation in the Humanities」3日目 Session 1b 開催報告・後編」
前回は KUDH2021 “Digital Transformation in the Humanities” の Day 3の最初の発表である、ダニエル・ゼマン氏の Universal Dependencies の歴史と応用についての発表の報告を中心に執筆したが、今回は、Day 3の残りの2つの発表に関する報告を行う。
Day 3の2つめの発表は京都大学白眉センター特定准教授の天野恭子氏の “Historical Background of the Formation of the Veda in Ancient India, as Deciphered from the Visualization of the Influence Relations among the Vedic Texts”(ヴェーダ文献における影響関係の視覚化から解読された、古代インドにおけるヴェーダの形成の歴史的背景)である。
このプロジェクトは、京都大学の国際化や、未踏領域への挑戦、イノベーション創出を目指す学内ファンドプログラムである「SPIRITS」の助成を受けたものである[1]。この関連プロジェクトとして、ヴェーダ文献の形態素解析データ作成のための科研費挑戦的研究(萌芽)課題番号:20K20697『古代インド文献成立過程解明に向けた文体計量分析のためのデータベース構築』[2]、そして、ヴェーダ文献の年代推定のための、国際共同研究加速基金(国際共同研究強化(B)):21KK0004「ヴェーダ文献における言語層の考察とそれを利用した文献年代推定プログラムの開発」(2021-10-07–2027-03-31)[3]がある。
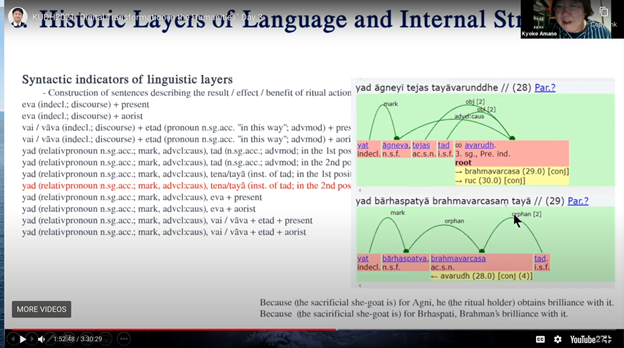
ヴェーダ文献とは、紀元前1500年頃から南アジアに移住してきたインド・アーリア人の宗教文献であり、紀元前1500年から500年頃に作成され、その後何年にもわたって口伝で伝えられてきて、写本になったのは紀元後10世紀以降である。そして、著者や作られた年代、作られた場所などの記述はない。地理的情報に関しては、ヴェーダ文献内で言及される人名や地名、そして、仏典やギリシア語資料などからわかることがあるものの、極少数である。また、考古学証拠や歴史的証拠もない。そこで、このプロジェクトは、コーパス言語学と計量文献学により、年代・作成地がわからないヴェーダ文献の年代・地域を求めることを目的としている。
ヴェーダ語のテキストコーパスでは品詞やレンマ、統語情報などが付与されたものが少ない。これは一つには、サンディ(連声)と呼ばれる、語境界などで生じる音韻規則による変化や融合があり、語境界の判定が難しいことも一因である。現在、天野氏はデュッセルドルフ大学のオリヴァー・ヘルヴィック氏[4]と共同で、形態論情報・統語論情報が付与された XML TEI 形式でのコーパスを開発している。XML TEI は、デジタル・ヒューマニティーズにおいてテキストのマークアップの世界標準となっている形式である。このコーパスプロジェクトは2021年に始動し、2026年までに重要な文献の多くをデータ化することを目指している。
このコーパスでは、ヘルヴィック氏による品詞タグ付与プログラムを活用している。このプログラムがヴェーダ語テキストの自動解析を行い、それをヴェーダ語の専門研究者が訂正・確認することで、正確な品詞タグ付きのデータを作成している。さらにヘルヴィック氏は、現在、Digital Corpus of Sanskrit(DCS)プロジェクトにおいて、UD による統語情報が付与されたサンスクリットおよびヴェーダ語のコーパスを開発中である[5]。
今回の発表では、特に、ヴェーダ文献のなかで最も古い散文とされ、天野氏がドイツ語訳を出版し、長年研究している『マイトラーヤニー・サンヒター』(MS)について、成立過程の解明の鍵を握る言語的特徴とその変遷をどのように考察するか、方法論の検討が中心であった。天野氏は、今回、MS の言語的特徴を示す統語論および文体の分析が、現状の UD およびコーパスの品詞タグでは不十分であることを指摘し、データへの文法情報の追加の提案を行った。このような情報をもとにヴェーダ文献の言語的特徴を考察すれば、ヴェーダ文献が多様な社会的背景を持ついくつもの社会集団の相互の影響関係の中で成立したことが解明され、単一のバラモン(インド・アーリア人の祭官達)文化のみを軸として考えられてきた古代インド社会像を変える可能性があることを述べた。その詳細は、ぜひ録画が公開されている、大会公式ホームページもしくは、成果公開 WEB をご覧いただきたい[6]。
最後の発表は、ライプチヒ大学で Perseus Digital Library に貢献し、Arethusa[7]という古代ギリシア語およびラテン語の UD による統語情報付与のエディタおよびツリーバンク[8]開発プロジェクトの主任研究者であったジュゼッペ・チェラーノ(Giuseppe Celano)氏によるもので、タイトルは、「UD:可能性と限界」(UD: Potential and Limitations)である。チェラーノ氏の Arethusa プロジェクトは、コンピュータの知識を前提とせず、西洋古典学者が、簡単にラテン語やギリシア語などの西洋古典の統語情報を記述できるようにしたもので、矢印やプルダウンメニューによって、直感的に操作することが可能である。
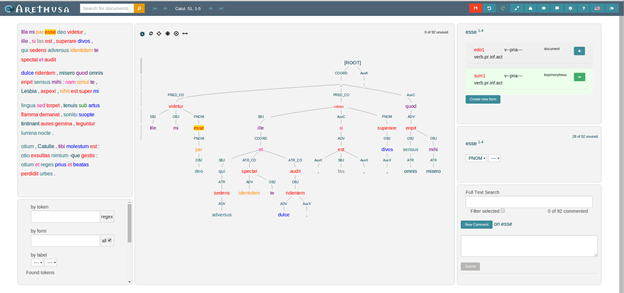
ただ、Arethusa のデータは UD に変換可能であるが、Arethusa の品詞タグおよび依存(係り受け)関係を示すタグは、ラテン語やギリシア語の文法に適した独自のものになっている。
言語独自の品詞や依存関係を UD で用いられるユニバーサル品詞タグやユニバーサル依存関係タグに置き換えることは、他の UD ツリーバンク/コーパスでもよく見られる現象で、例えば、Coptic SCRIPTORIUM の UD ツリーバンクなら、コプト語に最適化された品詞情報を UD コーパスに変換するときは、より単純なユニバーサル品詞タグ(UPOS)に変換される他、日本語の国立国語研究所(国語研)の短単位 UD ツリーバンクは、国語研の UniDic の日本語での独自の品詞をユニバーサル品詞タグに置き換えている。
UD のユニバーサル品詞タグおよび依存関係タグは、どのような言語にも対応できるよう、簡略化・抽象化されたものであるが、チェラーノ氏の発表は、ラテン語や古代ギリシア語で、そうしたユニバーサルタグが問題を引き起こす例を提示し、多様な諸言語を同じ方式で記述することに警鐘を鳴らしている。確かに、全ての人に適応できるような仕組み(例えば、全ての人が着れる T シャツ)を作るのはおそらく不可能である。同じように、世界には現在約7000の言語があると言われているが(標準的な言語・方言の分け方に基づく)、その全ての言語および、より多くの方言に完璧に適用できるような唯一の文法記述形式を作るのは、非常に困難である。ただ、すでに100言語以上のツリーバンクが UD の枠組みで作られているため、すでにあるユニバーサルタグを統合したり置き換えるのならば、対応できるが、UPOS の更なる細分化は途方もないコストがかかる。そのため、現在の枠組みの急速な変更は現実的ではないだろう。
その後、UD の中心メンバーの1人であるゼマン氏、Day 1で登壇した、古典中国語、古典日本語、アイヌ語の UD を発展させている京都大学の安岡孝一氏によりチェラーノ氏が提起した問題が活発に議論された。その様子は公式サイト[10]、および、京都大学大学院文学研究科・文学部成果公開 WEB[11]で公開されているのでぜひご視聴いただきたい。本国際会議の開催が、日本と海外の DH における交流、そして、将来の京都大学および日本における DH の発展に結果的に寄与することを心より願っている。
《連載》「デジタル・ヒストリーの小部屋」第2回
「デジタル時代の史料における歪み」
歴史研究において、「選択」は避けて通れない問題である。自分が明らかにしたい研究上の問いがあり、その問題の解決に資する史料を「選択」し、その史料から情報を抜き出すに値する箇所を「選択」しなければならないからである。もちろん、他者を納得させるための論理構成や叙述表現の「選択」も含まれるだろうが、この点について本稿では深く立ち入らない。今回は、史料の選択における「歪み」、ことデジタル時代に生じる「歪み」と、その意義について試論的に考えてみたいと思う。
歴史研究における主観性のバイアス
近世フランス史家遅塚忠躬は、『史学概論』の中で、歴史研究者が直面する選択と主観性の問題について、次のように述べている。
まず、歴史研究者は、事実を研究してそれを解釈したり叙述したりするのであるが、その研究者が依拠し利用する素材(史料)には、研究対象となる客観的な事実だけが書かれているとは限らない。もちろん、課税台帳や市場価格表のような史料には、もっぱら客観的な事実が記されているだろう。しかし、さまざまな事件や社会の状態などに関する各種の記録や報告(記述史料)は、史料記述者自身の主観的な解釈というフィルターを通して、つまり色づけされて、記述されているのがむしろ通例なのである。
次に、さまざまな史料に記載されたことがらのなかから、どれを重要な事実として選び取るかは、研究者の主観的な判断に依存している。過去の遺物にせよ文書史料にせよ、われわれが入手しうる情報源は、時代を下がるにつれて加速度的に増加し、それらの情報に含まれる事実も、少なくとも近世以降、まことに厖大な量に達している。それゆえ、歴史研究者は、まずもって、みずからの主観的な判断ないし解釈により、それら莫大な量の事実を取捨選択することから始めなければならない。[1]
歴史学は、当然のことながら過ぎ去った事柄を研究対象とするため、その歴史的事象に対する解釈やそもそもの真偽が妥当であるかを追試験することができない[2]。そのため、過去の痕跡を残す一次史料や、ほかの研究者らによる二次文献に見られる記述の整合性を判断し、論理に破綻がないように歴史像を編んでいく作業が必要になる。しかし、上記の遅塚による説明からわかるように、何が客観的な事実であるか、何が重要な事実であるかを判断するには、幾重にも重なる主観性のバイアスという壁が立ちはだかることになり、これはおよそ容易な営みではない。
デジタル化された史料にかかるバイアス
さて、世はデジタル時代。情報の検索や発信にウェブやコンピュータの存在は欠かせなくなった。これらの技術の利便性をここでいまさら強調することはしないでおこう。むしろその利便性がもたらす「歪み」について、とくに歴史研究の観点から考えてみたい。
Romein らは、2020年に公開された論文「デジタル・ヒストリーの研究動向」[3]の中で「デジタル解釈学 Digital Hermeneutics」という節を立て、この問題を論じている。ここで中心的に議論されているのは、デジタル媒体の史料を扱う際に、デジタル以前のアナログ史料を扱う場合と比べて、史料批判にあたって検討すべき新たな事項の存在である。すなわち、
- デジタルライブラリーや文書館の情報システム、あるいは Google や Bing など商業ベースの検索エンジンが重視する SEO(Search Engine Optimization:検索エンジン最適化)の仕組み
- そもそも史料がデジタル化される過程において、何がデジタル化の対象として選ばれてウェブに掲載されるようになったのか
- アナログからデジタルへ移行する際に内容の変更や文脈の欠落などが生じていないか
- 検索結果の出力などの仕組みを支えるプログラムのコード(∵特定の作業を実現するためのアルゴリズム自体が、複雑な現象を簡素化したものであるから)
さて、本稿でとくに問題にしたいのは、Romein らの挙げた論点のうち、「そもそも史料がデジタル化される過程において、何がデジタル化の対象として選ばれてウェブに掲載されるようになったのか」である。
ルクセンブルク大学の Zaagsma は、史料のデジタル化にひそむ政治力学と国家戦略、それに伴う懸念について次のように論じている。まず、デジタル化の過程は選別そのものであって中立的な営みではなく、史料の保存状態・利用頻度・資金といった要因以外にも、その国や地域の過去をどのように発信するかという記憶の政治力学に左右される。このことは、たとえば2000年代以降のドイツにおける史料のデジタル化事業に出資されたドイツ研究振興協会(DFG: Deutsche Forschungsgemeinschaft)の助成金がドイツにおけるユダヤ人の歴史に関するものであったり、対照的にヨーロピアナ Europeana のような全欧州プロジェクトにおいては、共通のヨーロッパ資産としての趣を持つ史料の保存を手がける傾向が見られる。このような政治力学・国家戦略が史料のデジタル化に反映されるとどうなるか。考えられる懸念として、国家として強調したい「大きな物語」に資するような史料の存在感が増すことに伴い、超国家的あるいは周縁的なテーマを扱う史料が隅に追いやられてしまうことが挙げられる。各国の国立公文書館が、利用頻度の高い史料をデジタル化することにその使命のひとつを見出したとすれば、そのことは結局よく知られた歴史像の再生産を促進してしまう危険性をはらむことになるのである[6]。筆者のように外国の歴史を研究する者にとって、オンライン史料を駆使して研究せざるを得ないコロナ禍においては、文書館のデジタル化戦略の影響を強く受けることになるだろう。
史料をオンラインで閲覧できるようになることには、その物質性が失われるといった懸念、史料群の中における位置づけが曖昧になってしまうといった懸念がよく指摘されるが[7]、そもそもデジタル化の選別基準に影響を与える諸要素にも注意を払う必要があるのである。
次回予告
今回は、史料がデジタル化される過程、とくにその選別段階でさまざまな要素が介在することに注目してきた。冒頭で引用した遅塚による説明を読んだ時点で、歴史家の「選択」には幾重にも重なる主観性のバイアスが存在していたというのに、デジタル化の工程を踏むことによってさらに検討事項が増えてしまった。輪をかけて「歪み」が生じているように思われるが、これは歴史学の営みにとってどのような意義があるだろうか。次回の連載では、このような「歪み」はあるものとしてそれをどう説明するか、そこにデジタル・ヒストリーがどう貢献するのか、といった論点について考察したい。
人文情報学イベント関連カレンダー
【2022年3月】
-
2022-3-7 (Mon)
東アジア人文情報学研究センター 第17回 TOKYO 漢籍 SEMINAR於・一橋大学一橋講堂中会議場http://www.kita.zinbun.kyoto-u.ac.jp/zinbun/symposium/seminar/2022_kanseki_tokyo
-
2022-3-10 (Thu)
シンポジウム「古辞書・漢字音研究と人文情報学」於・オンライン -
2022-3-13 (Sun)
国立国語研究所 「通時コーパス」シンポジウム2022於・オンラインhttps://www.ninjal.ac.jp/event/specialists/project-meeting/m-2021/20220313/
Digital Humanities Events カレンダー共同編集人
◆編集後記
2月23日(水)に、DH フェス2022が開催されました。oVice というバーチャル空間で実施され、30数件の発表と、100人以上の参加があり、大変盛り上がりました。最近は、Web ブラウザで複数のビデオ会話グループを自由に設定できるバーチャル空間がいくつか出てきています。oVice はその中でも料金体系の扱いやすさに大きな特徴がありますが、他にも、類似のものとして、Spacial Chat, Remo, Gather town などがよく使われているようです。いずれも、Web ブラウザ上に人を示すアイコンやキャラクターが表示されて、アイコン同士を近づけると、近い人同士でビデオ会話グループを形成できる、ということで、あとは細かい機能の工夫にそれぞれ特徴があります。こうしたツールを用いたコミュニケーションも徐々にあちこちで利用されるようになってきており、Zoom のようなビデオ会議ツールでの「一人が話すと他の人はみなそれを聞かなければならない」「Breakout Room は入りにくい」といった難しさを乗り越えるという意味ではなかなかよい解決策になっています。なかなか対面に戻りにくい状況が続いていますが、オンラインならではの新しい可能性も、一方で引き続き探っていきたいところです。
(永崎研宣)
- コメントを投稿するにはログインしてください