人文情報学月報第149号【後編】
ISSN 2189-1621 / 2011年08月27日創刊
目次
【前編】
- 《巻頭言》「情報でいただく」
:東北大学史料館 - 《連載》「欧州・中東デジタル・ヒューマニティーズ動向」第66回
「生成 AI サービスの新展開:動画・スライド/ホームページ・歌曲の自動生成」
:人間文化研究機構国立国語研究所研究系 - 《連載》「仏教学のためのデジタルツール」第14回
「浄土宗発行の『浄土宗全書テキストデータベース』」
:東京大学大学院人文社会系研究科博士課程単位取得退学
【後編】
- 《特別寄稿》「CIDOC CRM を拡張したテクスト情報表現の試み:CRMtex」
:ROIS-DS 人文学オープンデータ共同利用センター - 《特別寄稿》「Matthew James Driscoll と Elena Pierazzo による「1. Introduction: Old Wine in New Bottles?」(『Digital Scholarly Editing-Theories and Practices』所収)の要約と紹介」
:早稲田大学大学院文学研究科 - 人文情報学イベント関連カレンダー
- イベントレポート「国際シンポジウム「デジタル・ヒューマニティーズと研究基盤」参加報告」
:国立国語研究所 - 編集後記
《特別寄稿》「CIDOC CRM を拡張したテクスト情報表現の試み:CRMtex」
人文情報学の分野においてよく知られるデータモデルの一つに、CIDOC CRM がある[1]。CIDOC CRM は、「国際博物館会議(ICOM)国際ドキュメンテーション委員会(CIDOC)の概念参照モデル(Conceptual Reference Model)」であり、「博物館資料や文化財の収集、管理・保存、調査・分析などの活動において必要となる情報について記述・蓄積し、検索可能なデータベースを構築するために制定された」モデルであるとされ[2]、あらゆる資料に適用可能な汎用的なモデルであるが、その SIG(Special Interest Group)の活動の一環として CRMtex という、古代を中心とした手書き文字資料に関連する情報を構造化するために CIDOC CRM を拡張したモデルが提案されている。ガイドラインは2018年に0.8版、2020年に1.0版、2022年に1.2版、そして2023年6月に2.0版と継続的に更新されており[3]、現在進行形のプロジェクトである。
ウェブサイトやガイドラインの導入によれば、CRMtex の目的は「テクスト」に関わるさまざまな情報とその学術研究における分析プロセスをモデル化することによって、古代の文書資料の研究を支援し、考古学や歴史学といった分野との協働に資することにあるという[4]。このモデルの大きな特徴は、テクストを構成する最小の単位としての音素や書記素、それを表現するための文字体系や記述システムに焦点を当てるとともに、そうしたテクスト記述がなされる媒体の物理的特性や、そのテクストを記述する「行為」そのものも含めてデータとして構造化しようと試みる点にある。これにより、あるテクストを構成する表象に関する情報から物理的・空間的なコンテキストやテクストが生成されたプロセス、さらにはそれを読解する作業に至るまでの情報を参照し、さまざまな学術的観点から検索や分析に用いることが可能になるのである。とはいえ、このようなデータ構造化の意義は文章による説明ではなかなか掴みづらいため、CRMtex のガイドラインに掲載されている図を示しつつ、モデルの詳細を紹介することとする[5]。
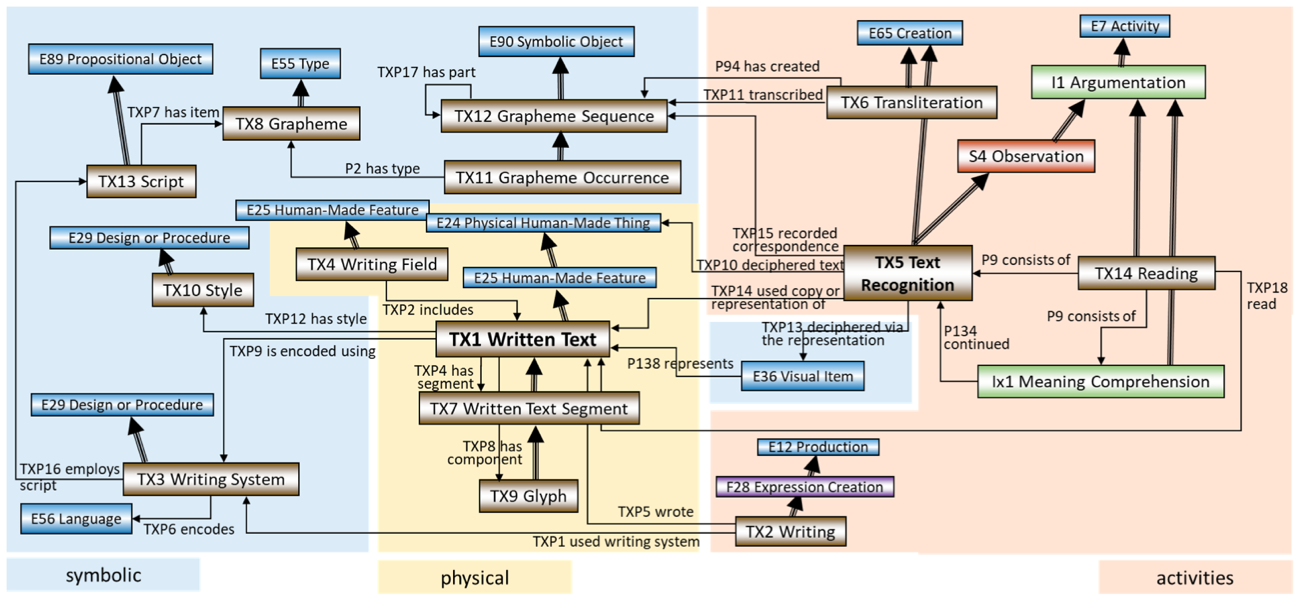
この図からは、CRMtex モデルが大きく、テクストの生成や読解といった「行為 activities」、テクストを保持する物理的な「モノ physical」、そして文字列や個々の文字・記号といった「表象 symbolic」に関する情報を構造化するモノであることがわかる。まず、物理的なものとしてのひとまとまりのテクストは TX1 Written Text で表され、それは場合によってはいくつかの TX7 Written Text Segment からなる。そして、これらの TX1や TX7を生成する行為、すなわち書記行為が TX2 Writingで表される。行為に関してはテクスト生成とは別に、テクストを解読する行為を表す TX5 Text Recognition が定義されており、この読解行為の結果として、複数の書記素が含まれるテクストを単位とする TX12 Grapheme Sequence、あるいは単一の書記素を表す TX11 Grapheme Occurrence が生成される。ただし TX11や TX12はあくまでも、「ある特定のテクストにおいて記述される書記素」、言うなれば「あるテクスト A における B という書記素」を表す概念であり、そこから抽象化された普遍的な概念としての書記素、すなわち「B」を表すのは TX8 Grapheme である。そして、そうした書記素がどのような文字体系や言語体系に属するかという情報も、TX3 Writing System や TX13 Script を参照することで記述される[6]。
このように CRMtex は、何らかの物理的実体の上に刻まれたり、書かれたりした個々の文字等の書記素を土台としつつ、それを生み出した行為やそれを読解する行為、そして読解の結果として抽出され、符号化された抽象的な文字と、それが属する書記体系や言語体系といったより普遍的な情報までを表現しうるデータモデルである。印刷による機械的なテクストの生成技術が普及する以前の時代、とくに CRMtex が主な対象とする古代において、石碑や銅板、あるいはパピルスに記されたテクスト、さらにはそれを構成する書記素はすべて、人の手になる書記行為の結果として生み出されたものである以上、個々の書記素についてそのコンテキストを表現できることは非常に重要である。例えば古代の碑文であれば、同じ文字を表す刻字であっても、時代や地域、刻み手によって字体に大きな違いが現れる。また同じ碑文中でさえ、碑面のスペースや前後の文字との兼ね合いによって差異が生ずることさえある。CRMtex は、このように資料をきわめて緻密に分析しようとする際に問題となる点をまさに課題として、その解決を図るべく提案されたモデルということができよう。
従来の CIDOC CRM によるモデル化においては、資料上(あるいは内)に存在するテクスト情報の構造化は必ずしも十分に扱われてこなかった。しかしながら、上述のように歴史学や考古学の研究にも資するようなデータを構築しようとするならば、こうしたテクスト情報も扱えるようにすることは必須であり、この点において CRMtex の提案は大いに意義がある。さらにいえば CRMtex は、古代の資料に限らず、中世の写本資料など、文字情報を含む資料すべてに適用される可能性を有するものであり、さまざまな時代や地域における資料のより精緻なデータ構造化に広く資するものであるということもできるだろう。
《特別寄稿》「Matthew James Driscoll と Elena Pierazzo による「1. Introduction: Old Wine in New Bottles?」(『Digital Scholarly Editing-Theories and Practices』所収)の要約と紹介」
Matthew James Driscoll と Elena Pierazzo による本章は[1]、『Digital Scholarly Editing』において次章以降に展開される具体的な議論の前準備として、本章執筆段階での、ヨーロッパにおけるデジタル人文学の状況を整理し、デジタル技術が影響を与えてきた7つの項目を参考事例として挙げながら、それらが学問に与える影響について考察することの必要性を論証する構成となっている。
著者らによると、この書籍が出版された当時のヨーロッパでは本書の元となった2012年11月のホイヘンス記念オランダ歴史研究所でのエキスパートセミナーを始め、デジタル人文学を推進する様々な試みが行われていた。つまり、既に学術編集はコンピュータのもたらす変化や影響のただ中にあったのである。こうした状況を踏まえ、著者らはこうした変化や影響によって、「学術編集の世界は何かが根本的に変わりつつあ」り、またその影響範囲は「仕事の方法、仕事に使うツール、研究課題」等広範囲にわたっていることを指摘する。そして、「理論的かつ実践的な観点から、こうした変化の意味するところを考察し、それらが学術編集そのものや研究者が編集するテキストに対する理解(編集の解釈学)にも変化をもたらしているかどうか評価する必要性を生じさせている」、と主張する。つまり、問われるべきは「新しい学問分野なのか、新しい方法論なのか」ということである。であるならば、著者らが主張する様に、上記の問いに取り組む前に、これまで発展してきたデジタル技術が学問に与えた影響を検証する必要があるだろう。
著者らはデジタル技術が影響を与えた分野を7つの項目に整理している。
1つ目は「一次資料を位置づけること (locating primary sources)」について。オンライン版目録の整備は、「テキスト研究者にとって、主に写本やその他の一次資料をこれまでよりも簡単かつ迅速に探し出すことが出来るようになったことを意味する」。主要図書館などが公開するオンライン目録は、「一次資料、二次資料へのアクセスを改善し、研究者の日々の仕事に大きな影響を与えた」。「こうしたことの大部分は、確立された基準と通信規格の使用に拠って可能となった。なぜならば、複数のデータベースの同時検索は、メタデータの品質と相互運用性のみが可能にするからである」。
2つ目は「デジタル画像 (digital images)」の普及である。デジタル・ファクシミリが即時利用可能になったことは、編集作業に大きな影響を与えた。しかし、「デジタル画像の品質にはばらつきがあり、多くの場合、体系的なデジタル化計画がないことから、信頼できる研究ツールとはいえず」、まだ改善の余地のある分野である。しかし、デジタル画像が利用可能になったことで、デジタル古文書学や OCR の研究にも拍車がかかっており、今後多くのことが期待される。
3つ目は「翻刻されたテキスト (transcribed texts)」について。「文化遺産のテキストの電子バージョンはいまやインターネット上で膨大な数が利用できる」。しかし、「著作権の状況や、スクロール可能なページ上での表現の難しさから、註解が無い場合があり、(…)その結果として読者は自分が何を読んでいるのか全く理解できないことになる」。こうしたテキストは、「テキスト研究そのものの存続を損なう事態を招くことから、ないより悪いのである。適切なデジタル編集版は増えつつあるがまだ少ないのが現状である」。
4つ目は「データを解析する (Crunching the data)」ことについて。こうした作業は、「テキスト研究者が常に行ってきたことと根本的に変わるところはない。しかし、唯一の違いは、これまで可能だったよりもはるかに大量のデータを迅速に処理できるようになったことであり」、様々なアプローチの研究が誕生している。勿論、目録の作成と同様に、この分野の可能性を引き出すためには、データの相互運用性が重要なのは言うまでもない。
5つ目は「自動校合 (automatic collation)、写本系統学 (stemmatology)、分岐学的方法 (cladistic methods)」について。「コンピュータは(…)テキスト編集作業を軽減するために、その誕生以来使用されてきた」。が、「自動校合と写本の系統樹の自動生成は未だ幼年期にあり、期待する程には進んでいない」。「しかし、より洗練されたアプリケーションが開発されるにつれて、近い将来に大きな飛躍を遂げることが期待されている」。また、「分岐学的(または系統発生学的)方法はひょっとするとテキスト研究において唯一のボーンデジタルな理論の利用である」。というのも、この方法は、コンピュータ技術に基づいて、学際的な協力によって生まれたものであるからだ。
6つ目は「規格 (standards)」について。これまでの項目で述べられてきた通り、メタデータ、テキストの転写、出来事の記述には共通規格の確立が必要である。この観点に立つならば、World Wide Web 開発以前に Text Encoding Initiative が設立されたことは、デジタル学術編集の概念を発展させる上で基礎となる出来事であった。こうした「標準化に向けた努力は、デジタル編集に関心を持つ国際的な、分野を超えたコミュニティの発展を可能にした。加えて、編集作業の多くの側面で標準となる TEI が存在することで、まだ標準化されていない分野、あるいは競合する基準が多すぎる分野が明らかになりつつある」。
7つ目は「ソーシャル編集 (social editing)」について。「デジタル社会の進化とソーシャルネットワークの普及は、編集におけるチームワーク(ソーシャル編集)に新たな視点をもたらした。あるテキストを「そこに」置き、編集に携わる人々(プロジェクトによっては一般の人々が含まれることもある)に、翻刻、校合、修正、共同編集をしてもらうという考え方は、編集界に波紋を呼び、権威性、編集者の役割、「学術的」と称される編集版には何が必要なのかという疑問を投げかけることとなった」。
以上のように著者らは7つの事例からデジタル技術を使用することは、「単に新しいメディアで同じ古いことを行うことではない、と断言するには十分である」と述べる。さらに、それだけでなく、「この新しいメディアは、我々が行っていることの意義、学問分野やテキスト性に関する概念に与える影響について、かなりの理論的再考と考察」の必要性を主張する。著者によると、「本書はまさにこれを目的としている。そして、一方では、学術的な編集において実際に何が変わりつつあるのかについて、理論的な観点から意見を概観し、他方では、そうした考察を異なる地域や時代の原稿や作品に対して検証する事例を提供する」、とのことである。
以上、著者らの表現を用いながら本章の要約と紹介を行った。本章の実際の事例の丹念な整理を元にした帰納的考察は、ヨーロッパにおける2016年時点でのデジタル学術編集に対する見通しを提供するものである。と同時に、本章での方法論は、本邦におけるデジタル技術の浸透とその影響を論じる際の参考となるであろう。
最後になるが、筆者は普段は日本近代文学が専門であり、西洋文献学用語の訳出に充分でない点があるかもしれないので、お気づきの点があればご批正いただけると幸甚である。
人文情報学イベント関連カレンダー
【2024年1月】
-
2024-1-11 (Thu), 17 (Wed), 25 (Thu), 31 (Wed)
TEI 研究会於・オンライン
【2024年2月】
-
2024-2-9 (Fri)
DH 若手の会「デジタル・ヒューマニティーズで“繋がる×広がる”人文学」https://www.nihu.jp/ja/event/20240209
於・一橋大学一橋講堂・中会議場 -
2024-2-8 (Thu), 14 (Wed), 22 (Thu), 28 (Wed)
TEI 研究会於・オンライン -
2024-2-17 (Sat)
第134回 人文科学とコンピュータ研究発表会http://www.jinmoncom.jp/?CH134
於・オンライン
【2024年3月】
-
2024-3-7 (Thu), 13 (Wed), 21 (Thu), 27 (Wed)
TEI 研究会於・オンライン -
2024-3-17 (Sun)
歴史フェス@名古屋大学https://sites.google.com/view/historyfes2024/home
於・名古屋大学東山キャンパスおよびオンライン
Digital Humanities Events カレンダー共同編集人
イベントレポート「国際シンポジウム「デジタル・ヒューマニティーズと研究基盤」参加報告」
国際シンポジウム「デジタル・ヒューマニティーズと研究基盤」が2023/11/18に東京ビッグサイトで開かれた。([1]などを参照。)
基調講演は、汎欧州人文・芸術デジタル研究基盤(DARIAH)ディレクターなどを務める Toma Tasovac 氏で、歴史的に芸術や人文学は最新のテクノロジーを使い続けてきており、現在のデジタル技術も従来の方法に加えて取り入れ、研究基盤づくりにいかすべきであると主張した。理想的には、DH に有用なデータセットは (1) 機械可読なだけでなく機械処理可能なデータ (2) メタデータと内容の両方に対してきちんとドキュメントがある API (3) クラウドソーシングによるサポートがある注釈 (4) 参考資料サービス (5) データ拡充のためのしくみからなる。研究基盤となるためには、(1) 形式知と暗黙知 (2) ネットワークとコミュニティ (3) ソフトウェアとサービス (4) データセット (5) 研究室と機材 (6) 建物や施設が必要である。(物質ではなく知識がおおもとにあることに注意。)公的な研究基盤の整備が重要課題であり、そのような公的な研究基盤の1つが DARIAH である。
基盤(インフラ、infrastructure)は、私たちが「普通に」生活しているときには気づかないものである。例えば「私は昨日、京都に行った」と言うときには、私が京都以外に住んでいることが暗黙の前提になっているだけでなく、歩いた道路、京都までに乗った電車・新幹線・飛行機などの交通手段、さらには呼吸のために必要な空気などはすべて背景化され、言語表現としては明示されない。明示されないということは、しばしば存在が当然視されるだけでなく、存在自体とその作り手や保守・管理者が意識に上らず忘れられがちということでもある。
研究基盤も同様のものとして捉えることができる。例えば論文を書くときにいちいち「コンピュータを使用した」とか、「Windows11を用いた」とか、「CiNii Research[2]を利用して論文を探してまとめた」とか明示的に書くことはほぼないだろう。しかし、ほとんどの研究者はこれらの基盤を空気のように利用して、意識にものぼらないぐらいあたりまえに恩恵を受けている。基盤は、私たちが「普通に」研究しているときにはほとんど意識されないが、機能が停止するとその果たしていた役割の重要性を痛切に実感することができる。2011年3月に起こった東日本大震災とその直後の福島第一原発事故による関東地方の計画停電、それに伴う CiNii の停止を記憶している読者も多いだろう。
基調講演の後の4つの報告された事例、方言の辞書、江戸時代の古文書、歴史地名、DH 教育は基盤の一部だろうか?方言は、その言語を話す人々、あるいはその人々が暮らす地域にとってはなくてはならないものである。地域の人々どうしが話すのにいちばん通じやすい言語であるだけでなく、「私が私であること」の一部であり、故郷の風景の一部である。日本語(であれ何であれ、自分の言語)が禁止され、記録もなく消滅することを想像してみると、「嫌だ」と思うのではないだろうか。これと全く同じように、それぞれの方言が話される地域にとって方言やその記録はなくてはならない。古文書や歴史地名も消滅してしまったら、私たちがどのように今ここにいるのか、住んでいる土地がどのような経緯を経て今に至るのか、私たちの使う制度や習慣がなぜそのようになっているのかについての根拠がゆらぎ、不安な気持ちになることは想像に難くない。
方言の辞書や古文書・歴史地名が基盤の一部だとして、なぜこれをデジタル化しておく必要があるのだろうか。デジタル化すると(適切な著作権処理とライセンス付与によって)いつでも、誰でも、どこでも、コンピュータとネットワークがあればデータが閲覧・利用可能になる。また、Tasovac 氏の講演でも言及されていた通り、検索も容易になり、適切な構造化や注釈を行うことでさらに検索の利便性を高めることができる。そしてデジタルデータはコピー可能なので、この作業を複数人で協力して行い、各々のデータを統合することができる。また、異なるデータ間の関係付けを行うことも可能である。例えば古文書に出現する方言と方言辞書の見出しを関連付けたり、その方言が話されている地域と地図を関連付けることができる。これを必要な仕事であるとみなすなら、これができる人々を教育するための DH 教育も重要な基盤の一部であることは明らかだろう。さらに、Tasovac 氏が主張していたように、DH のスキルは伝達可能な情報リテラシーのスキルであり、データ管理・データの質や来歴の検証・価値観の批判的検討などの能力は民主主義社会の根幹をなす。
研究データが適切に作り出され、保守・管理されるためには、他の社会基盤である道路・電気・ガス・水道などと同じように、絶え間ない努力でこれを行うための人、そしてお金が必要である。しかし上述した通り、「普通」に暮らしている間は基盤は当たり前の透明な存在であるせいで、背景化され、その存在も作り手も保守・管理者も意識の外に追い出されて忘れられやすい。これらが失われたらどうなるか、想像力を働かせるように私たちは社会に訴える必要があるだろう。また、従来から指摘されているとおり、基盤づくりを評価するような学会の仕組みも必要である。自分の、そして他者の地域の言語や歴史を記録すること、学ぶことを無駄と切り捨てて顧みない世界には人間性(humanity)がないと言わざるを得ない。壊れたり失われたりしてからその重要性を痛感するのでは遅すぎる。(岡真理氏の言葉を引用しておきたい。「私たちは文学の言葉を必要としています。文学は人間に humanity を取り戻させます。[…] 文学によって人間性を取り戻すのはパレスチナ人ではなく、私たちです。パレスチナ人が私たちと同じ人間であるという当たり前のこと――ユダヤ教徒やクリスチャンならこれを人間はみな神の似姿で創られていると言うと思います――そのことを私たちが理解することによって、私たち自身が人間になります。他者の人間性の否定、それこそが humanity の喪失であり、人間であることを自ら手放していることになります。」[3])
4つの事例報告に加えて、名子学氏による特別報告、32もの大学・研究所・博物館・プロジェクトなどの取り組みがポスター・デモンストレーションによって紹介されたが、筆者の能力の限界によりここでは紹介することができなかった。これらの様々な取り組みによって作り出されたデータどうしを繋げれば、私たちは大きな研究基盤のネットワークを作ることができるだろう。また、我々が11/18に同じ場所に集まったことで、人的ネットワークも可視化され、強化された。それはこれまで研究基盤の維持・整備、人的ネットワークの保守を行ってきた方々の努力の賜物であり、1人の新参者としてこの努力に敬意を表してこの稿を終えることとする。
◆編集後記
いよいよ2023年が終わろうとしています。ここまでご高覧いただいてきた読者の皆様に深く感謝しつつ、本年を少しだけ振り返ってみたいと思います。
人文情報学では、コロナ禍以来初めての対面の ADHO DH 国際会議がグラーツで開催されるなど海外では対面イベントが広く行われるようになり、国内でも対面イベントが増えてきました。それに伴い、交流が再び深まってきましたが、一方でハイブリッドのイベントもところどころで開催され、オンラインのメリットを残そうとする動きもみられます。発表の場を広く提供していくという意味でも、オンラインは何らかの方法で残っていっていただきたいところです。
研究のトレンドとしては、どこに行っても大規模言語モデル(LLM)と生成 AI の話を聞くようになりました。ChatGPT をはじめとする様々なソリューションへの対応は、人文情報学というより人文学そのものにとって大きな課題となっています。レポートの作成や英作文、多言語翻訳から教材作成やプログラミングなど、色々な場面で利用したりその課題を明らかにしたり、そもそも LLM や生成 AI 自体の課題について検討するなど、ビッグデータ時代における人文学の新たな重要な課題となってきているように思われます。
そうした新しい動向に対応していくためにも、これまで人文学が積み上げてきたことをデジタルの世界につなげられるようにしていくことがますます重要になってきています。何をどのように記述し、どう伝わるようにすべきか、ということに関する暗黙的な知も含めた知識記述のモデルを日本語文化圏にあわせて構築していくことが喫緊の課題になっているように思えます。欧米では TEI(Text Encoding Initiative)を通じて行われてきたことがその主要な部分を成してきており、これを日本で議論するための体制は、TEI 協会に設置された東アジア/日本語分科会を通じて形成されつつあります。2024年もこの流れが広まり深まっていくことを祈りつつ、執筆者の方々や編集室スタッフの方々とともに、より面白いメールマガジンの刊行に勤めてまいります。引き続きご高覧いただけますよう、よろしくお願いいたします。
- コメントを投稿するにはログインしてください