人文情報学月報第108号
ISSN2189-1621 / 2011年8月27日創刊
目次
- 《巻頭言》「中国・北魏研究とデジタル・ヒューマニティーズ」
:名城大学理工学部教養教育 - 《連載》「Digital Japanese Studies寸見」第64回
「文化庁が「文化財デジタルコンテンツダウンロード機能」をリニューアル公開」
:北海学園大学人文学部 - 《連載》「欧州・中東デジタル・ヒューマニティーズ動向」第25回
「国際オンライン・ワークショップ「Digital Coptic 3」での運営・司会・研究発表、および、第4回LingTech ワークショップ「Field Linguist’s Toolboxとコーパス分析の初歩」(オンライン)の講師を終えて」
:関西大学アジア・オープン・リサーチセンター「KU-ORCAS」 - 人文情報学イベント関連カレンダー
- 編集後記
《巻頭言》「中国・北魏研究とデジタル・ヒューマニティーズ」
筆者は中国・北魏(4~6世紀)の歴史研究を専門とし、編纂資料(正史など)および出土資料である墓誌(石刻史料)を扱っている。今回は自らの研究を振り返る形でデジタル・ヒューマニティーズとの関わりと今後の展望を紹介し、デジタル技術を歴史研究に適用する面白さと難しさについて私見を述べたい。
筆者はこれまで北魏の爵制について研究を進めてきた[1]。2000年代初頭には既に編纂資料の電子テキスト化が進んでおり、たとえば中央研究院漢籍電子文献[2]を使ってキーワードを検索することが可能であった。しかし、検索結果については稀にではあるが誤字の可能性があり、また文脈についても確認する必要があるため、結局は書籍の精読が研究の中心となっていた。たとえば正史の『魏書』を扱う場合、中央研究院の検索方法では不向きな単語(たとえば人名は姓名併記と名のみの記述があるが、名のみで検索しても違う人物が多くヒットする)があるため、魏書研究会編『魏書語彙索引』(汲古書院、1999年)を調べ、併せて『魏書』を通読・精読していた。このようなデジタル技術の使い方はテキストデータを検索する便利ツールの域を出ていなかった。
出土資料の北魏墓誌については電子テキスト化が余り進んでおらず、基本的には梶山智史編『北朝隋代墓誌所在総合目録』(明治大学東アジア石刻文物研究所、2013年)にて所在を調べ図書や論文を自分で収集する必要があった[3]。
以上の方法で編纂資料・出土資料から網羅的に各人物の爵位・将軍号・官職およびその官品(ランク)を拾い出し、さらに各人物の民族(漢族か否か)・出身地などのデータも付与し、割合を算出する手法で研究を進めたが、研究に行き詰まりを覚えた。その理由について考えてみると、新しい出土資料である北魏墓誌を用いていても、編纂資料の情報を補助的に追加・訂正する利用方法、あるいは家系図の復元や整理に止まっており、研究手法が全く新しくなかったからであった。
このような現状を打破するためには、デジタル・ヒューマニティーズ、その中でもテキストマイニングが大いなる可能性を秘めていると考えるようになった。なぜならテキストマイニングを使うことにより、人間の思い込みを排除し、普段は読み飛ばしてしまうテキストの特徴を抽出することが可能だからである。また計量テキスト分析を行う場合、現在では単純なコーディングであればKH Coder によって容易に実行可能となっており[4]、ツール面でも条件が整っていた。
加えてデータの整理と分析についても切り口を変える必要があった。北魏墓誌には被葬者の官歴・事績等が記されるが、実はこの項目は序文に該当し、その後に続く銘辞という韻文形式の文学的修辞部分が主となっている。ただし歴史研究において銘辞は詩文として読み飛ばされるのが常であった。誰も注目していないが豊富にある資料の部分を使って、マイニングという宝探しができるツールを使えば新発見があるのではないか、そのような甘美な期待があった。
しかし、実際に着手してみると、面白さだけではなく難しさの連続であった。
まず北魏墓誌を収集しデータベース化を行ったが、データベース構築に3年ほどかかってしまった。梶山目録において掲載された北魏墓誌は556点であるが、銘辞を伴わない墓誌を除外し、目録未掲載の新出墓誌を加え、総計451点について文字情報を移録した。いわゆる下準備の時間が長くかかり、かつ、データベースのみでは研究成果にならない点に難しさを覚えた。歴史情報学の研究を進めるうえで指摘される「データ論文」が認められるようになってほしいと切に願う[5]。
次にデータ分析を行った。古典中国語(漢文)の形態素分析を高精度で行うことのできるツールは現時点ではまだ無い。今回は MeCabに自分が作成した辞書(筆者が作成した墓誌の銘辞部分の語彙データを追加したもの)をコンパイルし、MeCab を KH Coderに入れ、テキストマイニングを行った。この結果、語数として17447語を抽出することができた。そこで使われる頻出単語を抽出してグラフ化し、また、抽出した語彙に基づき共起ネットワーク図を作成し、相関関係を調べた。北魏墓誌の銘辞部分の共起ネットワークやクラスター分析などは初めての試みなので、面白味と新鮮味を感じた。
最後に銘辞部分の用語の出現頻度の傾向によるグループ分けをし、社会集団分析を行った。上記の作業によって得られた数量データを元に埋葬時期・埋葬地・社会階層・民族・本貫地などのメタデータを付与し、時系列に排列することで、はじめに差異化を図り「流行」の先端となる集団、およびそれを模倣し先端集団に新たな差異化の必要性を生じさせる集団を探った。この各集団間の文化的な影響関係を明らかにすることで、従来の研究では見えてこなかった文化的集団を浮かび上がらせようとしている最中である。
KH Coder や MeCabなど大変に優れたフリーソフトのおかげで、データの下準備をすればすぐに分析でき、約二万語の語彙の中から共通点や相違点が明らかになったのは、従来の地味な手作業では気づけなかったことなので画期性を感じた。またメタデータを付与することにより時系列での変化を可視化でき、文化的社会集団を浮かび上がらせる手応えもあった。
しかし、同時に難しさも存在した。北魏研究においてデジタル技術を適用した歴史研究、特にテキスト分析は進んでいない。その理由について考えてみると、中国古代史に共通する問題点として近現代史に比べ圧倒的に資料が少なく、かつ、資料の偏在が著しいことが考えられる。たとえ網羅的に資料を集めたとしても、結論については0頻度問題が出てくる[6]。さらに長時間かけてデータベースを構築しデジタル技術を活用して分析しても、その結論が結局のところ従来の学説を補強する程度に止まれば、コスパよく業績を生み出せないからだろう。
ただし、従来の学説を補強するにしても数的データを示せる点は優れた魅力の一つであろう。何より根本的な面白さは、これまでの歴史研究では気づけなかったことが明らかになり、これまでの歴史研究では気づけなかったことが明らかになる可能性がある点だと考えている。
なおコロナ禍における学術振興のため、本来は有料である「授権使用」の機能が2020年9月末まで無料で使える。
執筆者プロフィール
《連載》「Digital Japanese Studies寸見」第64回
「文化庁が「文化財デジタルコンテンツダウンロード機能」をリニューアル公開」
文化庁は、2020年7月16日ごろ、「文化財デジタルコンテンツダウンロード機能」をリニューアルして公開したという[1][2]。[2]においては、3月開設であると述べられているが、もともとどういうものであったかはよく分らない[3]。名称も問題で、「文化財デジタルコンテンツダウンロード機能」というのは稟議書に仮題として付けるような名前で、一瞬ほんとうにこれが正式な題名なのか疑ってしまう。利用規約を見ると、「文化庁(以下「当庁」という。)が提供する文化財デジタルコンテンツ ダウンロード機能(以下「コンテンツバンク」という。)」と定義があって[4]、正式名称ではあるようだが、この利用規約以外に出てこないコンテンツバンクなる名称が出てくることもまた問題である。英語版では、この正式名称はCultural Properties Digital Content Download Site とされており、トップページのバナーに大きく書かれているものとなっている。内容としては、「日本の国宝・重要文化財等の文化財に関する高精細な動画・静止画・解説文をオンラインでダウンロードすることができる機能」[2]とあり、映像プロダクションの TBSスパークルが業務を委託されている。日本遺産関連のものでは、[3]で示した「日本遺産公式サイト」で取材された内容との重複が多い[5]。こちらのウェブサイトは、日本政府観光局が開設するもので、訪日観光客向けに英語版のみ(!)が存在している。日本遺産のいくつかについて、ストーリーというかたちで動画とテクストで名所紹介をしたうえで、個々の名所にはTripadvisor へのリンクが貼られているようなウェブサイトである。このために撮影された全天球カメラなどの動画も、YouTubeを通じてヴァーチャル・リアリティ(VR)動画として公開されている。「文化財デジタルコンテンツダウンロード機能」のみ見ていると、撮影の意図などを図りかねる映像もすくなからずあるのだが、CM用動画の副産物といわれればこんなものかとは思われる。コンテンツそのものの資料性、個々の解説の内容の妥当性などからではない再利用性があるという判断なのであろう。時間軸が勝手に進みながら、かつ視点は回転できるという「VR」動画というものははじめて目にしたが、視聴していてなんとも途方に暮れるものではあった。たとえば、円通三匝堂のVR動画では、撮影者の歩みが早すぎて、1/4に速度を落としても視点を定めることも叶わないという奇妙な体験をした[6]。また、撮影物についてひとことも述べていない「詳細情報」などもあった[7]。BGMを宛てる前提であるためか、一定数の動画が現実の音を記録していないということも特記すべきであろう[8]。そのほかの内容は、世界遺産を取材したものがある。6月1日時点では、日本遺産と世界遺産を取材したコンテンツが155点あったというが[9]、執筆時点(7月23日)では174点あった。うちわけとしては、日本遺産142点、世界遺産32点である。全件では384点あるが、現状の検索システムでは観点の違う国宝・重文というカテゴリが「文化財区分」として一括されているので、全容はいまいちあきらかでない。操作性・利用性については、アクセシビリティチェックの結果を公表していること、クリエイティブ・コモンズ4.0表示ライセンスを全面的に採用していることなどが目を引く。前者については、JIS-X8341-3:2016(WCAG2.0)での等級 AA を達成しているという[10]。しかし、チェックリストの見方がまず分らず困惑させられるが、全ページが同じタイトルなのに(なぜか SNS 対策のOGPだけはしっかり細目まで付いている)、7.2.4.2(「ページタイトルに関する達成基準」)を達成しているとされていたり、機械的な適用をしていないか疑問なしとはしない。すくなくとも、上記カテゴリ区分からもあきらかなように、迷いなく使いやすくはできていない。後者については、例外となっているものが50件ほどある。そのなかには、使用許諾が必要なもの、商用不可あるいは条件付きとされるもの、クレジット表記が全体と異なるものがある。是非は論じないが、ダウンロード機能の利用には都度利用条件への同意を経ることになっており、追加条件があるものは、そちらの確認同意をも行ったうえでダウンロードが可能となっている。このほか、動画の長さやエンコーディングの詳細は表示されるが検索できるようなカテゴリは個々のコンテンツでは表示できないとか、テキストだけのダウンロードはできないとか、わたしのような人間は相手にされていないのだなという感想を抱かせる細部が目に入った。その点についていえば、[11]のようにここに掲載された動画などをさらに観光動画作成などに利用する向きもあるようなので、そちらが本来的ターゲットなのであろう。すなわち、全体として文化資源「観光活用」の流れを承けたものとなっている。せめて教育番組系制作のチームを割り当ててほしいとは思いつつ、描かれた活用の内容として見ておくべきものではあろう。また、実質はともかく、アクセシビリティの規定を守ろうとしていることは、アクセシビリティを十分に考慮しないものが増えているなかで注目に値する。それだけに、形式的な遵守が目に付くのであり、真にアクセシブルなものとしてほしい。極言すれば、APIや LOD への対応がないことはアクセシビリティへの態度がその程度だということになるのかもしれない。
《連載》「欧州・中東デジタル・ヒューマニティーズ動向」第25回
「国際オンライン・ワークショップ「Digital Coptic3」での運営・司会・研究発表、および、第4回 LingTech ワークショップ「Field Linguist’s Toolboxとコーパス分析の初歩」(オンライン)の講師を終えて」
筆者も日本に戻って来たため、本連載のテーマである欧米や中東の DHシーンにはアクセスが難しくなった、と思いきや、COVID-19のパンデミックとともに、オンラインのイベントが増え、世界中の DHカンファレンスやワークショップに参加することができ、DHの最新情報を得ることができている。この連載は「欧州・中東デジタル・ヒューマニティーズ動向」というシリーズ名の通り、筆者が活動してきたドイツを中心とするヨーロッパ諸国とイスラエルのDHシーンの最新情報を主に紹介してきた。中東はこれまで筆者が研究滞在したイスラエルしか取り上げてこなかったが、近年はカタール大学で様々な DHプロジェクトの活動が活発化していたり、エジプトのカイロ・アメリカン大学がオンライン DH レクチャーシリーズを開催するなど、イスラエル以外の中東でも DHが活発化している。
筆者も7月12–13日に開催されたオンライン・ワークショップ Digital Coptic3[1]にてはじめてオーガナイザーを務めた。もともとは全米人文学基金とドイツ研究振興協会のジョイントプロジェクトであるKELLIA[2]のワークショップとして第12回国際コプト学会の開催前にブリュッセルで開催する予定であったが、オンラインに移行した。参加者が多いドイツの時間では16時、アメリカ東部時間では10時、日本時間では23時に始まり、学会は3–4時間続いた。参加者は80–90人程度であった。筆者は、12日と13日の第2セッションの司会進行を務め、13日の第1セッションでは発表をし、その後のディスカッションでも調整役をし、家路についたのは夜の4時ころで、大変骨が折れた。このワークショップでは、コプト語のOCR、WordNet、テクストリユース、辞書編纂、デジタル・エディション、写本の地理情報、コプト語教育への ICT の活用など、DHの様々な分野の優れた発表があり、熱い議論が交わされ、大変実りのあるワークショップであった。ワークショップは録画されており、YouTubeで見ることができる[3]。来月は本連載でこのワークショップの報告を行う予定である。
さて、日本でも COVID-19のために、DH のオンライン・ワークショップやオンライン勉強会が盛んになってきている。筆者が知る限りでも、東京大学の UTDH[4]、TokyoDigital History[5]、TEI-C東アジア/日本語分科会[6]、関西デジタルヒストリー研究会[7]などがオンラインでの勉強会・研究会を開いている。その中で、言語学の院生や若手研究者を対象とする言語学へのデジタル技術の適用に関するLingTechワークショップがある[8]。これは、東京外国語大学の加藤幹次氏、国立国語研究所の中川奈津子氏が運営している。初回は加藤氏が正規表現、その次は中川氏が辞書の作成、3回目は加藤氏が正規表現の続きを教授し、4回目は筆者がインターリニア・グロスの作成とコーパス分析の基礎の授業をすることになった。タイトルは、「FieldLinguist’s Toolbox とコーパス分析ツールの初歩」である。
Field Linguist’s Toolbox(以下 Toolbox と略)[9]とはアメリカの SIL International(旧称 Summer InstituteofLinguistics)が開発した言語学者向けにあらゆる言語のインターリニア・グロスつきテキストや辞書などのデータを作成するためのソフトウェアである。このソフトウェアは、言語学者、とくにフィールドワークで少数言語を記述する学者がよく使っている。筆者は2015年3月に東京外国語大学で開催されたDocLing2015という言語ドキュメンテーションのセミナーを受講したが、そこで、言語ドキュメンテーションの大家である、ロンドン大学東洋アフリカ学院の教授であった PeterAustin 氏が Toolbox を勧めていた。近年、SIL International は本連載[10]でも紹介したことのある Fieldworks LanguageExplorer(FLEx)[11]の開発に力をいれている。FLEx は非常に多機能であるものの、今のところバグが多く、かつデータの管理が複雑であるため、Toolboxを愛用している学者は多い。
Toolbox はもともと Field Linguist’s Shoeboxと呼ばれていたが、これは、パソコンが普及していなかった時代にフィールド言語学者が靴箱に言語データを書いたカードを入れていたことによる。このソフトの最大の魅力は、ユーザが作成した辞書データをもとにどんな言語にも対応できる形態素解析によるインターリニア・グロスの自動生成である。言語学者の中には、何十年も一つの言語を研究し、ネイティブスピーカーレベルにその言語に習熟する学者ももちろんいるが、多くはそのレベルに達することがない。先行研究が全くない言語のフィールド調査の初期段階では、当然学者はその言語の初心者であり、自分で一から語や文法現象を話者から聞き出していかなければならない。また、理論的な関心から、言語のある一面、例えば特定の文法現象だけに絞って様々な言語のフィールド調査を行う学者もおり、その場合、その言語学者の言語レベルは通常低い。こういった場合、出てきた単語や研究対象外の文法要素に習熟していないことが多いが、当該の言語現象を研究するには調査で得られた文をしっかりと理解しなければならない。そういったときに、あらかじめ、調査で得られた語や形態素とその意味を記録していき、調査で得られた文の各語・形態素の下にその語・形態素の意味がそれぞれ自動で記されれば、その言語に習熟していなくとも、その文を効率的に理解できる。これがインターリニア・グロスであり、言語学の様々な分野で、特に対象言語を読者が理解できないと想定できる場合、この表示方法をとることが常識となっている。そして、特に記述言語学や言語類型論の分野では、図1がその一例であるが、ドイツのマックスプランク進化人類学研究所が定めたLeipzig Glossing Rules がインターリニア・グロスの標準形となっている。

Toolbox で作成したインターリニア・グロスは非常に単純なテクストファイルで保存され、単純な正規表現を用いて、言語学者がよく論文で用いる LaTeX や XeLaTeXでのインターリニア・グロスを作成する expex[13]や gb4e[14]のパッケージの形式に変換したり、ウェブサイトでインターリニア・グロスを美しく表示するためのJavaScript である leipzig.js[15]の形式に変換できたりする。
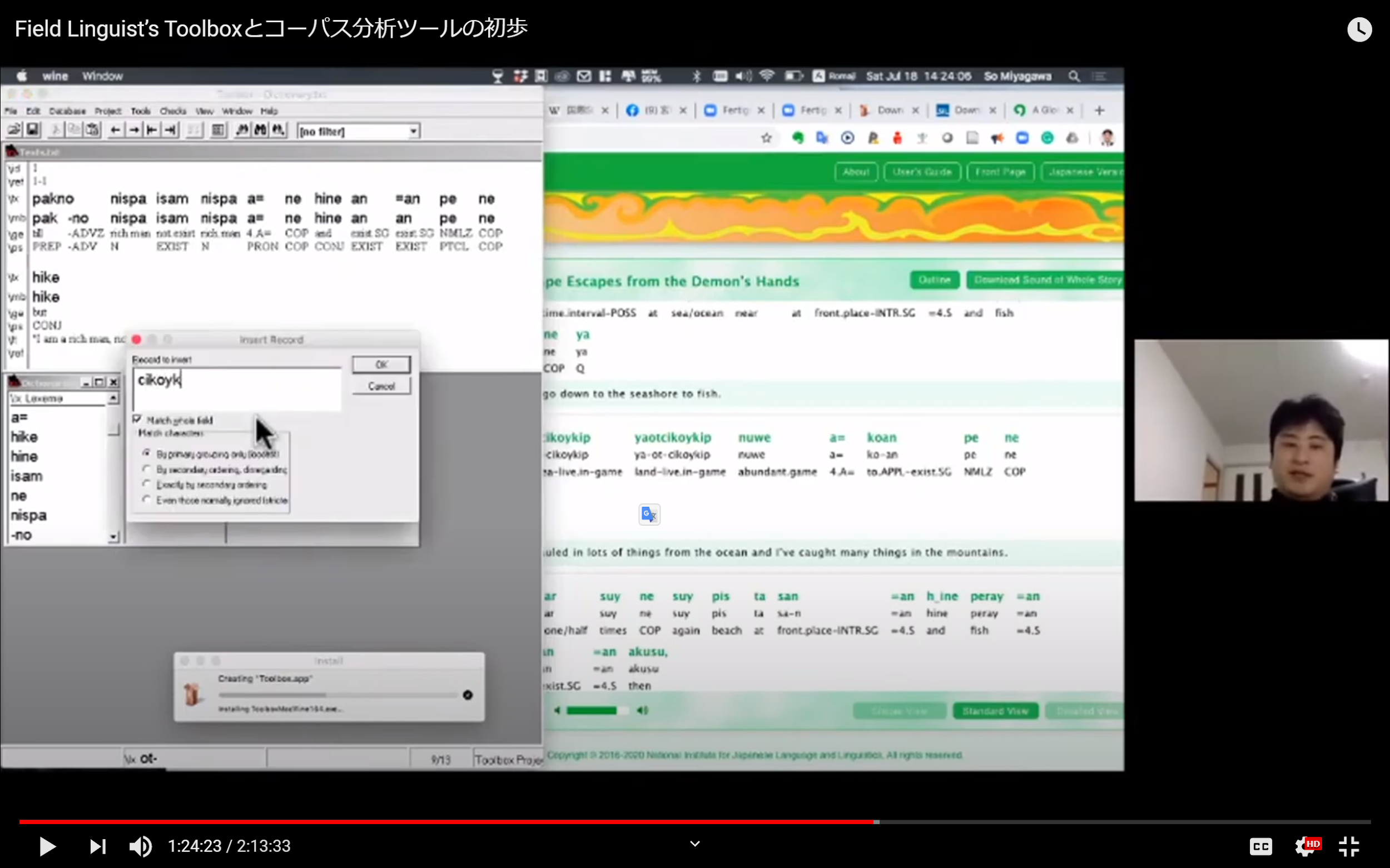
Toolbox の使い方を教授した後は、様々な簡易コーパス分析ができる Voyant Tools[16]と Universal Dependenciesに基づく統語樹が自動で描ける UDPipe[17]を紹介し、コーパス分析に基づいたグラフや統語樹などを作る方法を紹介した。
LingTechワークショップはハンズ・オン・ワークショップであるが、オンラインであるため、他の参加者がどれくらい進んでいるのか確認が難しく、また、講師の作業を見せる時間が長かったため、参加者を退屈させたかもしれない。これらの点はオンラインという場の特性を考えて、改善していかねばならない。当日はZoom とともに YouTube Live で講義が配信された[18]。質問は、直接 Zoom 音声を通しての他、Zoom や YouTube Live のチャット、そしてslido[19]でも受け付けた。講義の説明パートではスライドを用いず、新しい試みとして、アウトライナーアプリのWorkFlowy[20]で構造化したアウトラインを表示した。
今回は両ワークショップとも好評価のフィードバックを多数得られたのが救いであった。これらで見出された反省点を改善していき、より良いオンライン・ワークショップの運営・進行ができるよう努力していきたい。
宮川創「Universal Dependenciesの統語記述の特徴と自動統語解析」『人文情報学月報』102(2020年1月)。
宮川創「Universal Dependencies:依存文法ツリーバンクの世界標準」『人文情報学月報』101(2019年12月)。
人文情報学イベント関連カレンダー
【2020年8月】
-
2020-08-08 (Sat)
日本図書館研究会情報組織化研究グループ月例研究会於・オンラインによる開催 -
2020-08-25 (Tue)
ジャパンサーチ正式版公開 -
2020-08-31 (Mon)~2020-09-04 (Fri)
AAS-in-Asia 2020於・オンラインによる開催
【2020年9月】
-
2020-09-05 (Sat)
情報処理学会人文科学とコンピュータ研究会第124回研究発表会於・オンラインによる開催 -
2020-09-07 (Mon)
【発表申込締切】人文科学とコンピュータシンポジウム於・オンラインによる開催:12月12日(土)~13日(日)
【2020年10月】
-
2020-10-17 (Sat)~2020-10-18 (Sun)
デジタルアーカイブ学会第5回研究大会於・東京都/東京大学本郷キャンパス
Digital Humanities Events カレンダー共同編集人
◆編集後記
ここのところ、この欄ではオンライン会議の話を続けておりますが、イベントカレンダーもオンラインイベントの方が普通の状態のようになってきています。7月初旬には日本印度学仏教学会のオンライン学術大会の裏方をお手伝いしましたが、二日間、10部会を並行して Zoom開催し、多少のトラブルはあったものの、大過なく実施することができました。相当な数の裏方の方々の周到な準備の結果でしたが、きちんと組み立てればこれほどのことができるのかと、終わってみて改めて圧倒されているところです。一方、カナダ・オタワで開催予定だった、一年に一度の人文情報学の世界大会、DH2020も、バーチャル開催となり、こちらは1100人を超える参加登録があったとのことですが、大規模な実施は難しく、結果として、コミュニティサイトにコンテンツをアップロードしてそこで議論をするというオンデマンド型を主体として、少しだけフォーラム等をオンラインで実施するという形になりました。オンラインのセッションは開催地時間で実施されたため、日本時間の深夜から未明にかけてのセッションが多く、筆者も少しだけ参加しましたが、起きているだけでもなかなか大変でした。また、これに伴って学会の運営委員会もオンラインで開催されましたが、こちらはニュージーランドから米国中西部まで幅広い時間帯からの参加があり、深夜や早朝に参加する委員もいて大変そうでした。国際会議をオンラインで開催となると、 時差の問題はどうしても避けられません。この点を本人の努力に任せるのか、何かガイドラインのようなものを 色々な立場から用意していくのか、今後の研究活動の国際化を進めていく上で、検討が必要な事項になってきているように思われます。
(永崎研宣)
- コメントを投稿するにはログインしてください