人文情報学月報第135号【中編】
ISSN 2189-1621 / 2011年08月27日創刊
目次
【前編】
- 《巻頭言》「和歌を対象とした古典文学研究と作品データの集積:古典和歌の研究者は何を求めてどのような検討を行っているのか?」
:国文学研究資料館 - 《連載》「Digital Japanese Studies 寸見」第91回
「明治期官僚・官職データベース(國岡 DB)、Web UI 版を公開」
:北海学園大学人文学部 - 《連載》「欧州・中東デジタル・ヒューマニティーズ動向」第52回
「Hugging Face AutoTrain における最新鋭 AI モデルによるノーコード機械学習」
:人間文化研究機構国立国語研究所研究系
【中編】
- 《連載》「デジタル・ヒストリーの小部屋」第10回
「デジタル・ヒストリーと可視化(1)」
:千葉大学人文社会科学系教育研究機構 - 《特別寄稿》「TEI ガイドラインにおける性別とジェンダーの改訂」
:ペンシルヴァニア州立大学 - 《特別寄稿》「Extended Matrix と考古学・歴史研究:3D モデル構築のプロセスを記録し可視化するためのデータモデル」
:ROIS-DS 人文学オープンデータ共同利用センター(CODH)
【後編】
- 人文情報学イベント関連カレンダー
- イベントレポート「「3D Imaging and Modelling for Classics and Cultural Heritage」参加記(後編)」
:ROIS-DS 人文学オープンデータ共同利用センター(CODH) - イベントレポート「TEI2022@Newcastle (UK)」
:ROIS-DS 人文学オープンデータ共同利用センター(CODH) - 編集後記
《連載》「デジタル・ヒストリーの小部屋」第10回
「デジタル・ヒストリーと可視化(1)」
はじめに
今回の連載では、デジタル・ヒストリーにおける「可視化」について考察を始めていきたい。可視化 visualization は、多くの場合、何らかのデータや情報を視覚化することを指し、data visualizationやinformation visualization といった複合語で呼ばれることが多い。可視化は、言葉による叙述を補完する役割を持つことが多いが、形や色の選択によって相手に与える印象が大きく変わることがあり、認知科学やデザインの領域における議論と親和性が高い。筆者は、これらの背景知識に関する専門性を持つわけではないが、デジタル・ヒューマニティーズおよびデジタル・ヒストリーにおける可視化の効用についてはある程度肯定的に捉えており、有効な可視化を作成できる知見を習得することに注力してきた。
今回は、前回の連載でも紹介した、ロイ・ローゼンツヴァイク歴史とニューメディア研究所(RRCHNM)による「デジタル・ヒストリー白書[1]」の第5節が可視化を扱っているので、その内容を要約しつつ、デジタル・ヒストリーにおける可視化について考えていくこととしたい。
言葉による叙述と可視化の関係性
「デジタル・ヒストリー白書」第5節は、全体として、3Dモデリングやビデオゲーム、そしてマッピングを具体例としながら、「可視化はそれ自体で歴史学の議論になりうるのか、それとも常に叙述による議論を支える証拠にすぎないのか」という問いを検討するものである。その際、議論の前提としておさえておきたいのは、次の主張である。
ここで論じているのは、言葉による叙述と可視化を比べるにあたって、本稿「はじめに」でも述べたように、形や色の選択によって相手に与える印象を変えるというイメージを持たれがちな可視化を擁護するために、叙述も、たとえばレトリックや語彙の選択によって、相手に与える印象を変えるという点で共通していることである。叙述と可視化の共通点を指摘する記述は他にもあり、
ここでは、John Unsworth による scholarly primitives の議論を引きながら[2]、学問的実践の基本をなす7つの営為、すなわち発見・註釈・比較・参照・サンプリング・例示・表現のうち、可視化と叙述で共通するものとそうでないものを比べている。可視化と叙述は、多くの点で共通するものの、表現と伝達の過程において違いが見られるとしており、「しかし、可視化を作成する歴史家は、その可視化が行う議論が、他の歴史家にとって必ずしも容易ではないことを認識する必要がある」と注意を促している。
慣れ親しんだ形式か新しい形式か
「デジタル・ヒストリー白書」第5節では、議論の前提を述べた後、3D モデリングやビデオゲーム、そして地図という可視化形式について順に考察している。思うに、これらは歴史家にとって慣れ親しんだ可視化形式かどうかを基準とした配置なのではないだろうか。
まず、地図に比べて歴史が浅い可視化形式である3D モデリングは、新しいものだとしても、歴史学の論証における史資料の選択と配置に関する一連の選択を必要とする点で、前述の「学問のイロハ」を共有するものであるとしている。その他一般的な可視化形式と同様に、3D モデルは、そこで提示された空間において読者が探索するための手段として機能することもある。重要な貢献として考えられているのは、仮想環境内でモデル化された構造物の周囲を移動できるようにしておくことによって、その構造物の建築環境が、当時を生きた人々に対してどのような空間的影響力を持っていたのかを、追体験させられることであるとしている。例で挙げられているのは、アパルトヘイト・ヘリテージというプロジェクトであり、すでにリンクは切れているものの、プロジェクトの説明は YouTube で閲覧可能になっている。

3D モデルといえば、近年の Susan Schreibman を中心とした3D Digital Scholarly Editions の研究を参照すべきであるが[4]、さしあたっては、今後の実践的検討を通した歴史学的議論の進展に期待したい。
3D モデルやビデオゲームと比較すると、地図は非常に長きにわたって人類が共に歩んできた可視化形式である。可視化された情報について、何を・どのように読めば良いのかがすぐにわかるというのは、可視化における情報伝達の効率さという観点から重要なことであり、その意味で地図は優れた可視化手法である。地図は、人々・場所・出来事が置かれた場所のパターンを探り、それらの空間的な関係を問うことを容易にする伝達媒体であり、歴史学の議論とも親和性が高い。
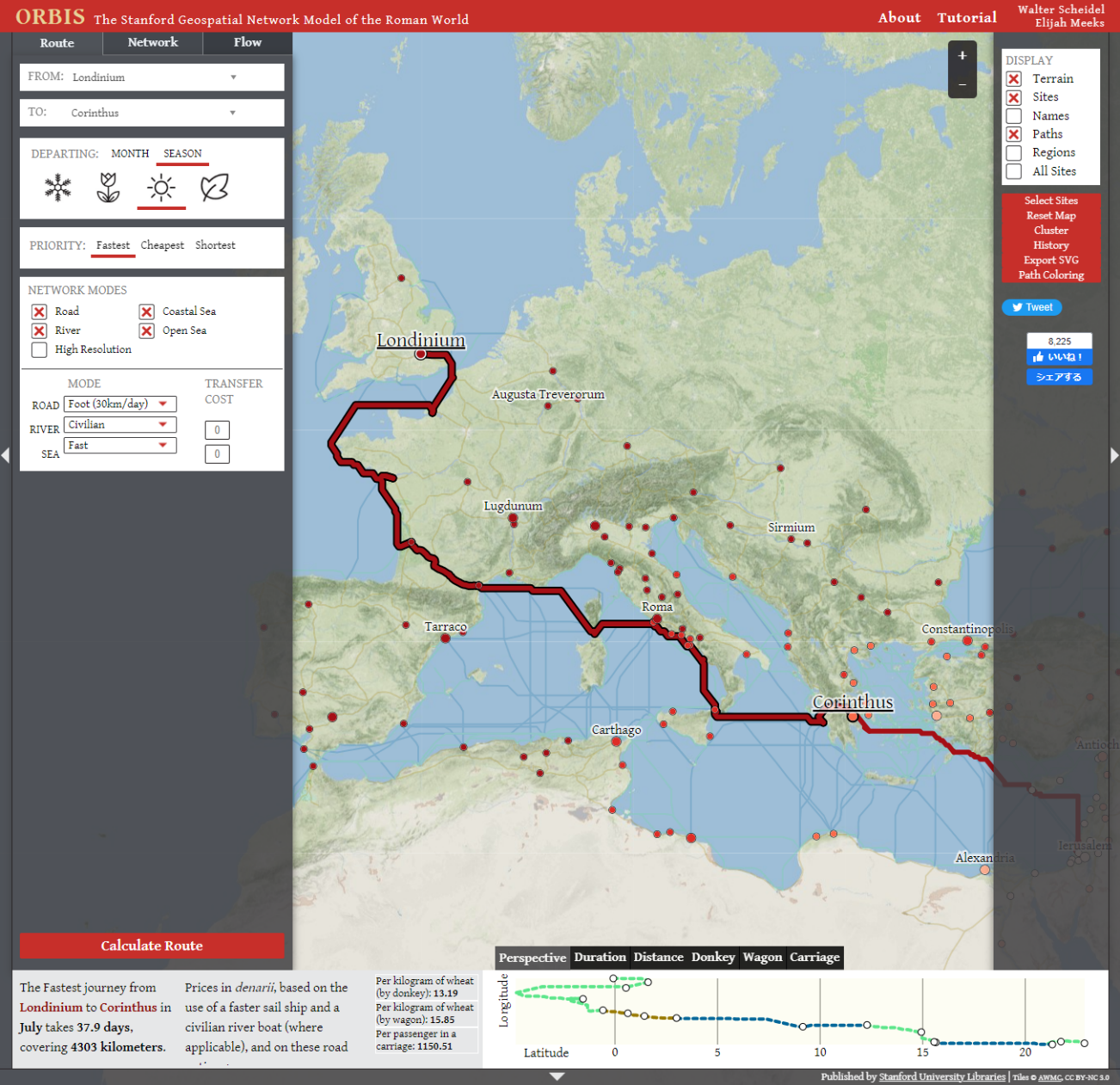
地図の重要な貢献として挙げられているのは、言葉による叙述ではできないような方法で、当時の空間的状況をありありと提示できる点である。たとえば、スタンフォード大学による古代ローマ世界における移動の地理的ネットワークを示した ORBIS プロジェクトは、出発地と目的地をつなぐ経路を、季節や移動手段を変えながらインタラクティブに探索できるプラットフォームを提供している。これにより、当時の地中海沿岸における移動のシミュレーションを行うことができ、古代世界の移動における時間と空間の概念を理解するのに役立つのである。
まとめにかえて
「デジタル・ヒストリー白書」第5節では、デジタル・ヒストリーにおける可視化と叙述の関係性について、以下のように結論づけている。
まず、歴史学の成果を出版する媒体における印刷指向が、あらゆる形式の視覚化を取り入れる上で障害となることを指摘している。印刷物として出版できる静止画像としてレンダリングできるのは、一部の可視化だけであり、ORBIS の例で見たようなインタラクティブ性によってのみ伝達できる情報、つまりまさに歴史学的論証そのものを提示することが、印刷媒体上では困難なのである。この点を踏まえて、近年発刊されているデジタル・ヒストリーの学術誌は、Current Research in Digital History 誌や Journal of Digital History 誌などのように、初めからウェブ媒体で論文を公開するようにしていると考えて良い。
このように、歴史学的論証そのものになるような可視化というのは、叙述では伝達不可能なほど複雑で多変量な方法で議論を提示する。つまり、叙述を補完する役割を持つだけにとどまらず、叙述にはできない役割を持つことがある。多くの歴史家は、これまで可視化を読み解くためのビジュアルリテラシーを身につけることにほとんど関心を示さず、テキストに傾倒してきたことはよく指摘される。しかし、現在のデジタル環境では、ビジュアルリテラシーはより重要な問題であり、歴史家が持つべきスキルの一部となる必要がある、と「デジタル・ヒストリー白書」は主張している。
複雑な可視化を作成するスキルを育てると同時に、コミュニティ全体でそのような可視化を読み解くスキルを習得する機会をどのように設ければ良いのだろうか。このような点については、次回以降、また別の文献などを用いながら、デジタル・ヒストリーにおける可視化について考えていきたい。
《特別寄稿》「TEI ガイドラインにおける性別とジェンダーの改訂」
2022年10月の TEI ガイドラインのリリースに伴い、TEI (Text Encoding Initiative) 技術委員会[1]は<gender>エレメント[2]を導入し、関連するエレメントや属性のドキュメントにいくつかの改訂を行う。これらの改訂は、言語形態学的なジェンダーとは異なるプロソフォグラフィ(あるいは TEI personography)の文脈でジェンダーを符号化する方法を求める TEI コミュニティの声に応えたものである。この新しい符号化方法を導入する過程で、名前、日付、人物、そして場所(Names, Dates, People, and Places (ND))の章[3]を改訂して、ここからセックスとジェンダーに関する規範的な記述を削除し、個々の状態や特徴を表現するために TEI のガイダンスを変更した。
2022年10月までは、性別とジェンダーにかかわる TEI personography の符号化手法において利用可能なものは<sex>エレメント[4]か、<person>エレメントにおいて使用可能な @sex 属性のみであった。2013年以降、<sex>の@value 属性と@sex 属性の内容として妥当とされるものは、teidata.sex というデータ型によって、1つの個別の単語の形で定義されるようになった。また、TEI ガイドラインでは<sex>に対する @type 属性の使用例はないものの、@type 属性は<sex>用にカスタマイズされ、implicit と explicit という値が提案されている。<sex>の符号化手法に関する注記では、正規化属性が「不適切または役に立たない」場合は使用しないように注意し、「エレメントのコンテンツは、プレーンテキストを使用して、意図する概念をより詳細に記述することができる」と助言している。<sex>とその @value 属性に関する注記は、相互運用性のために内外の標準と協力するというプロジェクトの必要性との緊張関係のなかで、不適切な分類という潜在的問題があることを認めている。
2013年以降、<sex>に関する TEI ガイドラインの解説は、プロジェクト開発者に対し、他のプロジェクトやツールとの相互運用性に優れ、かつ誤表示やバイアスのないシステムを決定するという方法論上の課題を投げかけている。<sex>の改訂をより詳細に調査することは、TEI ガイドラインが ISO 標準に依存していることにおける問題の出所を探る助けになる。2013年以前、TEI ガイドラインは<sex>エレメントの@value 属性の定義(または@sex 属性の定義)を ISO のみに依存していた。その値は ISO 5218:2004 Representation of Human Sexes に依存し、0(不明)、1(男性)、2(女性)、9(なしまたは適用不可)に限定されており、一時期はこれらの数値のみが妥当な TEI として表現されていた。時代遅れで還元的な ISO の表現を義務付けることをやめるべきであるという要請を受け、技術委員会は 2013 年に妥当とされる属性値を ISO の 4 つの数値から data.word(現在の teidata.word) に変更した。2013年以降、ガイドラインは依然として ISO 標準を参照しているが、「広く不適切と考えられている」と注意を促し、単純な代替案として vCard sex property (http://microformats.org/wiki/gender-formats) を提示している。1998 年に提案され、2013 年に最終更新された vCard 規格は、連絡先情報の記録に適用され、性別のために M(男性)、F(女性)、O(その他)、N(なしまたは該当なし)、U(不明)の値を提供し、さらに、ジェンダー・アイデンティティのためのオープンなプレーンテキストのフィールドを提供している。ISO と vCard の規格は両方とも、TEI personography の符号化手法の提案としては、還元的で時代遅れで、役に立つかどうか疑わしいと思われる。
2022年10月のリリースで、TEI ガイドラインは4つのメジャーな変更を実施する。
- 性別のコーディングに関する外部規格への言及を削除。
- ガイドラインの参考文献に新たな引用を踏まえた、状態と特徴の符号化に関する文言の修正
- 新しい<gender>エレメントとそれに付随する属性(@value と @gender)、および teidata.gender データタイプの導入。
- <sex>エレメントとそれに付随する属性の見直し、および teidata.sex データタイプの変更。
技術委員会は、人間社会がそれぞれ別個に持つ生物学的生殖に関する概念やルールと、ジェンダー・アイデンティティの定義とを整理した「セックス/ジェンダー・システム」に関するゲイル・ルービンの影響力のある仕事を参照し、ジェンダー理論における明確な基盤を踏まえてガイドラインを改訂する。ルービンの理論は、ガイドラインの ND 章に引用されており、TEI personographies におけるセックスとジェンダーの符号化手法が、人の暮らし方を分類するための文化的システムを表すものとして、議論を手助けするだろう。2022年10月の改訂では、ND 章における特徴としてのセックスとジェンダーの議論が更新される。改訂前は、「セックスは明らかに身体的特徴であるが、ジェンダーはむしろ文化的に決定されたものと見なすべきである」と書かれていた。改訂後は、「ジェンダーとセックスは、その時代と場所の社会的ヒエラルキーに基づいて解釈された身体的な表現であり、文化的に決定されたとみなすことができる」となっている。ND 章における他の箇所の改訂は、TEI プロジェクト開発者が TEI ヘッダーの<editorialDecl>エレメントを使用して、アイデンティティの変化と同様に文化的に定義された特徴の符号化のための方法を文書化することを案内している。
新しい<gender>エレメントは「人物やペルソナ、キャラクターのジェンダー・アイデンティティを示す」ものであり、TEI ガイドライン第13章(ND 章)の(13.3.2.1)で紹介されている。 <sex>と同様に、<gender>は<person>、<personGrp>、<persona>のエレメントに含まれる。<gender>の@value 属性と@gender 属性は、新しい teidata.gender データ型によって定義され、「人物、ペルソナ、キャラクターのジェンダーを表すのに使われる属性値の範囲を定義する」ものである。今後は、teidata.gender と teidata.sex の両方のフォーマットは teidata.enumerated となる。これは「記述された候補の一覧から取り出された単一の XML 名として表される属性値の範囲を定義する」ものである。つまり、これらの属性は、スペースで区切られた複数の値を保持するように定義することが可能であり、それぞれの値が命名に関する XML 規則に適合していることのみが条件となる[5]。
teidata.gender の注釈では、値は「プロジェクトによってローカルに定義されるかもしれないし、外部標準を参照するかもしれない」と、どの標準も指定せずに示している。また、辞書的な用語の符号化で使用される<gen>と新しいエレメントを混同しないように、「このデータ型の値は形態素の性別を符号化するために使用すべきではない」と注記されている。teidata.sex と teidata.gender の例は、ノンバイナリ(non-binary)のための NB、インターセックス(intersex)のための I、そして、複数の属性値の使用のようなカテゴリを示す。
新しい<gender>エレメントの作成は、<sex>エレメントとそれに対応する属性値であるteidata.sexの改訂を促した。<gender>は個人のアイデンティティを符号化するものであり、<sex>は人間か非人間かを問わず生命体の生殖的な特徴に広く適用するものである。そこで、その記述は現在、“specifies the sex of an organism”(生物の性別を指定する)と修正された。TEI ガイドラインでは現在、人間以外の生命体に関するエレメントはなく、model.persStateLike(<person>, <personGrp>, <persona>)の同じエレメントに<sex>エレメントや @sex 属性が適用されたままになっている。これは将来的に改良されるはずである。人間以外の生命体を定義するための新しいエレメントの可能性を議論する中で、技術委員会は、あらゆる種類のオントロジー分類システム用にカスタマイズ可能な<entity>と<listEntity>エレメントを導入するチケット (https://github.com/TEIC/TEI/issues/2341) [6]をオープンした。
新しい<gender>エレメントは、他の比較的新しい TEI エレメントを踏まえて構築されている。すなわち、2016年に導入された<persona>と昨年導入された<persPronouns>である。<persona>エレメントにより、TEI プロジェクトは、新しく作られ、遂行されたアイデンティティをよりよく記述することができる。<persPronouns>は人物を参照するために好ましい代名詞を提供し、@value は正規の代名詞の値をリストし、@evidence は情報を供給するソースを記述する。
<sex>と<gender>に関する新しいガイドラインは、どの値も排除しないので、性別の符号化手法の後方互換性を維持し、この変更は TEI personographies におけるオントロジーに関する仕事をよりよいものにするはずである。このガイドラインは、性別のエンコーディングに過不足のないグローバルスタンダードがないことを認識している。この改訂では、外部標準への参照を削除し、代わりに ND 章での状態や特徴についての議論と、TEI personography 開発の指針となる様々な例に依拠することとした。
2022年10月の改訂は、TEI プロジェクトのために設計されたリンクトデータマッピングとツールに関する活動や議論が活発になってきた時期に行われた。ISO 5218:2004はもとより、特定の外部オントロジーを推奨しないことで、ガイドラインは TEI プロジェクトで開発されるオントロジーを使った理論的作業をよりよくサポートすることができるかもしれない。<gender>と<sex>の新しい符号化手法は、TEI ガイドラインの国際化にも強く影響を受けており、そして、多様な TEI コミュニティの根拠は、コンピュータ文化における偏り-相互運用の言語とツールを形成してきた偏り、現在の支配的文化の重視よる制限、文化遺産の多様性への認識を欠いた偏りを解消することにも強く影響されている。一般に、TEI のプロジェクトはプロジェクト遂行者がいるところとは異なる様々な時代や場所のテキストをデジタル化しており、そのプロソポグラフィの符号化手法は、人間に関する別の考え方や、存在の状態や特徴に結びつけられるセックス、ジェンダー、年齢などのコンセプトに関する別のモデリングにより、西欧や現代の「グローバル・ノース」の仮定に対抗することができる。
<sex>の改訂と<gender>の導入に関わった技術委員会のメンバー、Elisa Beshero-Bondar, Raffaele Viglianti, Helena Bermúdez Sabel, Janelle Jenstad は、イングランドのニューカッスルでの TEI 2022会議用にスライドショーのプレゼンテーションを共同執筆した。彼らの会議発表用スライドは、改訂作業の詳細を記録したもので、Zenodo: https://doi.org/10.5281/zenodo.7091048 にアーカイブされている。
《特別寄稿》「Extended Matrix と考古学・歴史研究:3D モデル構築のプロセスを記録し可視化するためのデータモデル」
3D 技術を用いて過去の空間や建築物を再現する手法はいまや、考古学や歴史学の分野で一般的に用いられるものとなりつつある。とくに考古学分野は比較的早い時期から3D 技術に関わり、フォトグラメトリやレーザーを用いた3D スキャン技術や3D モデリング技術に精通する研究者も存在する[1]。ただし、3D を用いた新たな学術研究手法を確立するためには、3D モデル作成技術を高めて大量のモデルを生産するだけでは十分でなく、いかなる条件のもと、どのような学術的根拠に基づいて作成されたのかをしっかり記録し、検索・可視化できるようなシステムを整備する必要がある。とくに、すでに存在しない空間や建築物を、関連資料や解釈に基づいて3D モデルとして再現しようとする場合、この点は極めて重要である。このような課題に取り組むべく、考古学の分野ではさまざまな試みがなされており、本稿が取り上げるExtended Matrix(EM)もその一つである。
EM とは、3D モデリングによる事物の再現プロセス、学術的な調査や意思決定の内容をグラフ形式のデータとして記録するための記述言語である。この言語による記述の詳細については EM のウェブサイトや論文を参照していただきたいが[2]、簡潔に言えば、残存する遺跡や遺物、再現の根拠となる資料、それらに基づく「再現仮説」をそれぞれノードとして記述し、それらの空間的・時間的・意味的関係性をグラフ構造で表現する。EM そのものはあくまでもデータモデルであるが、これに基づいて実際にデータを記述し、3D 空間上で可視化するための一連のシステムである Extended Matrix Framework(EMF)が、イタリア・ローマの国立文化遺産科学研究所(CNR ISPC)の Emanuel Demetrescu を中心に開発され、公開されている[3]。EMF のワークフローは主に、①グラフ描画ツールである yEd を用いて[4]、EM 準拠のデータを GraphML 形式で作成、②作成した EM データを3D モデリングソフト Blender に読み込み、グラフ上の各ノードに対応する3D オブジェクトモデルとリンクした上で、各種形式でエクスポート、③EMF が提供する可視化ツール EMviq、あるいは独自のシステムを用いた可視化・鑑賞、の三つのプロセスからなる。このうち、③のプロセスついては、構築したデータをシステムに与えさえすれば、ある程度自動で実現できるため、本稿ではデータ構築に関わる①②のプロセスに焦点を当てて記述を進める。
まず、EM 準拠のグラフデータ作成に関して、EMF では yEd の利用を推奨しており、EM データを構築するためのテンプレートを公開している[5]。yEd 上でこのテンプレートを読み込むことで、EM データ記述のためのノードを選択することが可能になる。それらのノードを用いて構築されるグラフは図1のようになる。
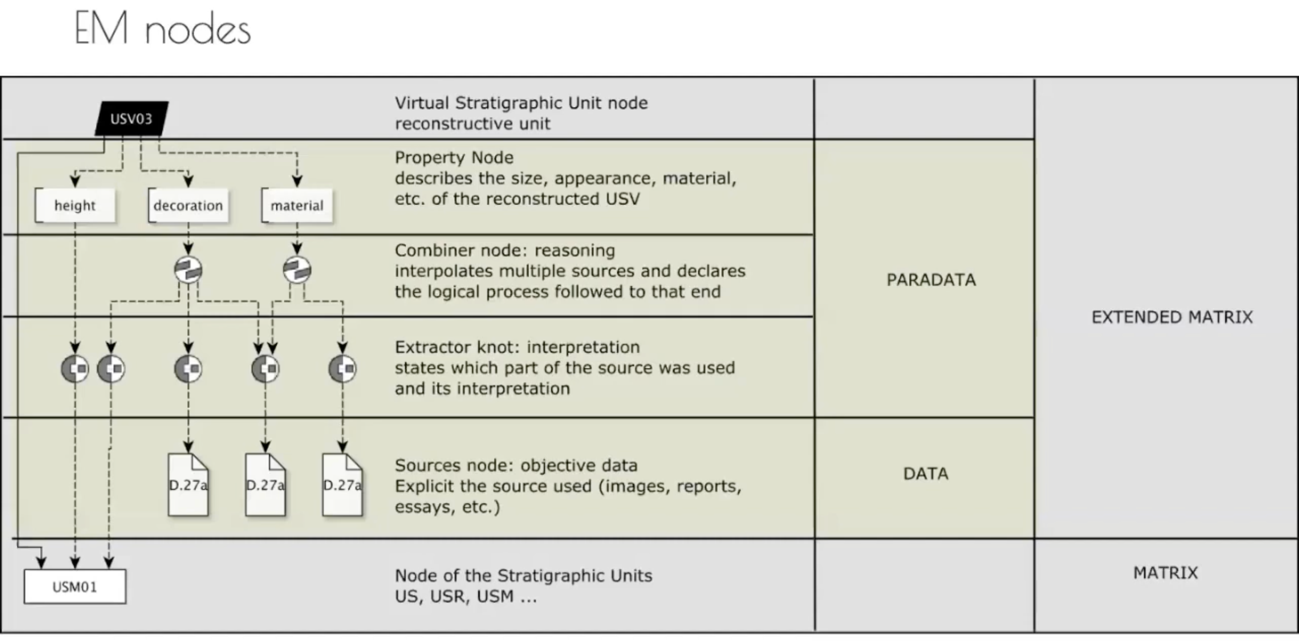
最上段の黒地ノードは、さまざまなデータに基づく再現モデルを表すノードであり、最下段の白地ノードは、黒地ノードで表される再現モデルの土台であり、現存する部分を表す。両者は実線エッジで繋がれており、両者が土台部分-再現部分という層序的(階層的)な関係性にあることを示している。そして両者の間には、height, decoration, material などの再現作業に不可欠な情報を与えるためのノードが記述されている。上から二段目の白地長方形ノードは、どのような属性情報を再現モデルに与えるかを示すノードであり、具体的な属性情報は文字列としてこのノードに紐づける。上から三段目・四段目はいずれも、解釈のプロセスに関わるノードである。四段目の Extractor は、何らかの資料から特定の情報を抽出するプロセスそのものをノードとして表現したものであり、資料から抽出されうる情報が文字列で紐付けられる。一方、三段目の Combiner は、資料から抽出された複数の情報を統合するプロセスを表し、複数の Extractor を参照する。最後に、五段目の白地長方形ノードは典拠となる資料を表すノードであり、資料情報を文字列で記述できるほか、参照先 URL を紐づけることも可能である。
このように、さまざまなエレメントを表すノードをリンクさせることで、再現モデルを作成する過程をデータとして記述することが可能になる。また、土台部分や再現部分を表すノードには複数の形状が用意されており、土台部分であれば元来の位置を保っているかどうか、再現部分であれば、何らかの物理的痕跡に基づくか否かによって、用いるべき形状が異なってくる。これによって、再現されたモデルの位置情報や形状についての信憑性の度合いを表現することができるのである。一例として図2にあげたグラフは、ローマに遺跡が残る「アウグストゥスのフォルム」にかつて存在したマルス・ウルトル神殿の列柱および内陣壁を再現するために、筆者が作成したものである。
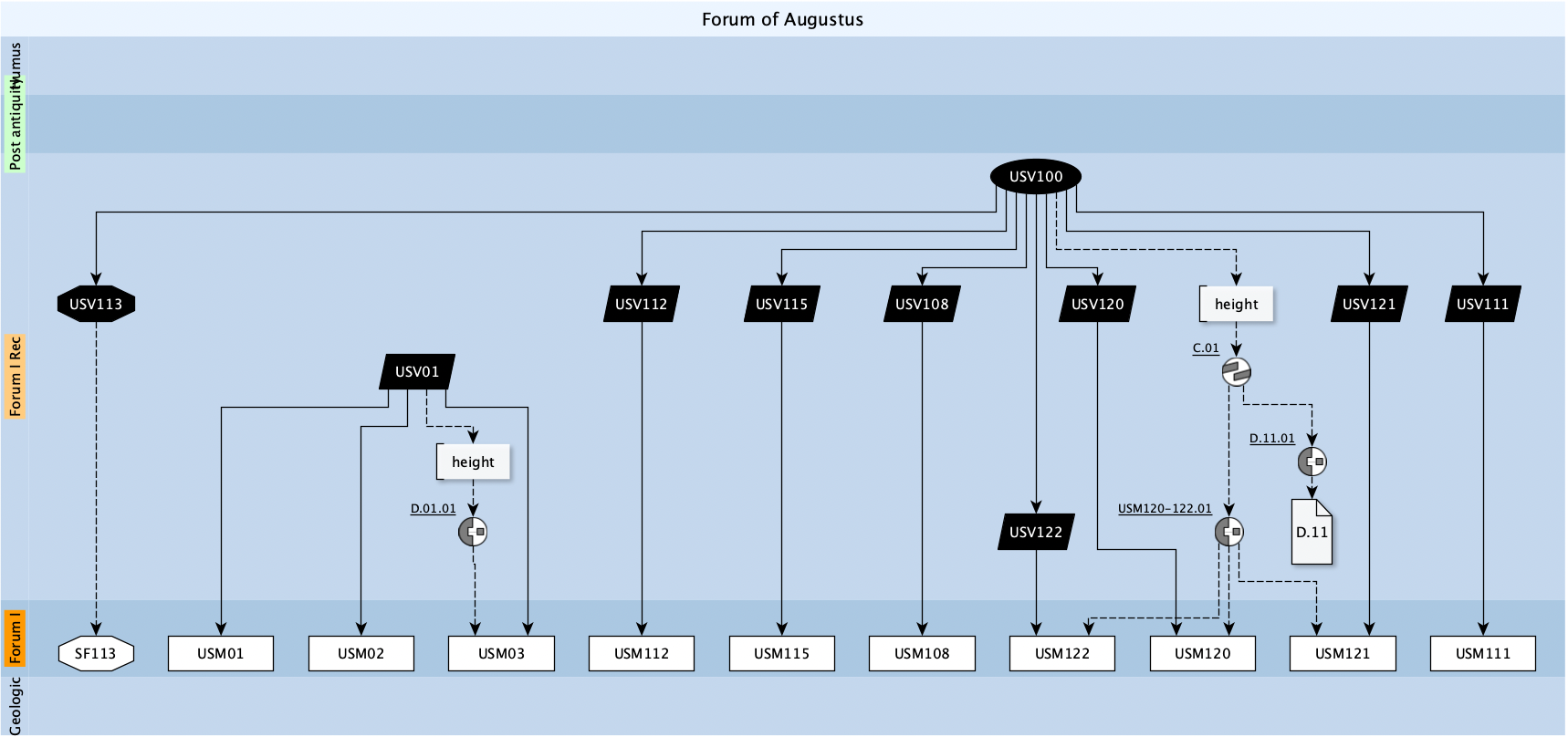
左端のノードをみると、他のノードとは異なる八角形になっていることがわかる。これは土台部分の発見位置が元来の位置とは明らかに異なっていたことを示している。またテーブル全体の構造をみると、左端の濃オレンジ、薄オレンジ、緑でハイライトされた文字列によって行が分割されていることがわかる。この分割は時間の区分に基づくものであり、時代やコンテキストごとに異なる再現モデルを記述することができる。
以上が、プロセス①としてあげた EM データ作成プロセスであるが、この段階ではあくまで概念的なデータ構造を定めたのみであり、実際の3D モデルとは紐づいていない。この、3D モデルとのリンク構築を担うのがプロセス②である。次回はこのプロセス②について、EM データと3D モデルを Blender 上でリンクするためのサービスとして開発された EMtools を中心に説明したいと思う。
- コメントを投稿するにはログインしてください