人文情報学月報第121号【前編】
ISSN 2189-1621 / 2011年8月27日創刊
目次
【前編】
- 《巻頭言》「日本近現代文学研究者はコンピュータを使って何をしたいのか。したくないのか。」
:名古屋大学 - 《連載》「Digital Japanese Studies 寸見」第77回
「CiNii Articles の CiNii Research への統合が発表:CiNii Research でなにが変るのか」
:北海学園大学人文学部 - 《連載》「欧州・中東デジタル・ヒューマニティーズ動向」第38回
「手書きテキスト認識・自動翻刻ソフトウェア・Transkribus の基本知識と最新動向 Fabricius」
:京都大学大学院文学研究科附属文化遺産学・人文知連携センター
【後編】
- 人文情報学イベント関連カレンダー
- イベントレポート「ワークショップ「Digital Orientalist’s Virtual Workshop and Conference 2021」」
:東京大学大学院人文社会系研究科 - イベントレポート「「2021年度アート・ドキュメンテーション学会年次大会」参加報告(後編)」
:東京大学大学院学際情報学府 - 編集後記
《巻頭言》「日本近現代文学研究者はコンピュータを使って何をしたいのか。したくないのか。」
1. 研究会のこと
昨年から、「コンピュータを使った近現代文学研究」勉強会というのをやっている。学内の小さな研究会で、関心のある大学院生や修了生たちと文献を読んだり、KH Coder を使ってみたり、Phython の入門的な勉強をしたりしている。新しいことを学ぶのは面白い。
私自身は、2年ほど前に KH Coder を使って簡単な研究を行ったことがある[1]。1972–2019年の科研費の研究題目や概要を対象として、細目の「日本文学」「国文学」および特別研究員奨励費ならびに奨励研究(特別研究員)のうち日本文学関係のものを分析にかけた。おおむね、私自身の経験と一致する分析結果もあれば、思いもよらない発見もあった。行ったことは、コンピュータを使ったテキストの量的な分析の初歩の初歩だったと思うが、そうした手法が、ぼんやりと認識していた学的見取り図を確実な数字で示したり、思い込みとは異なる事実を示してくれたりすることを体感した。
この小文では、「日本近現代文学研究者はコンピュータを使って何をしたいのか。したくないのか」ということをめぐって書いてみたい。異なる分野が歩み寄り、新しい共同研究を始めるためには―私はそうしたいと願っている―、日本近現代文学研究者が何をしたいのか、したくないのかを言語化しておくのがよいような気がするからである。むろん、日本近現代文学の研究者といってもいろいろであるから、ここでいう「日本近現代文学研究者」とは日比の考えるだいたいこんな感じというイメージで書いている。反論がある人は、そうじゃないんだということを、この拙文を踏み台に書いていただければうれしい。
2. 日本近現代文学研究者は何をしたいのか。したくないのか。
上述した勉強会のメンバーと、いくつかのコンピュータを用いて行った近現代文学研究の文献を読んだ。それについての感想を書くことが、間接的に近現代文学研究の関心の方向性を語ることにまずはなるだろう。勉強を始めたばかりなので網羅的とは到底言えないが、次のような研究の方向性が存在しているように私にはみえる。
(1) 文体論、(2) 作品本文の内容分析、(3) 文学に関連する各種記事の内容分析。(1) の文体論としては、書き癖などを抽出してその作品が代作かどうか推定したりする。同じような発想で、漱石と自然主義文学の差を測定したりする研究もある。(2) は KH Coder の作者樋口耕一による『社会調査のための計量テキスト分析』が、夏目漱石の「こころ」を使ってチュートリアルを行っているのが、もしかしたら代表かもしれない。(3) はさほど多くないが、太宰治の命日である桜桃忌について、新聞記事を編年的に分析する論文がある。
(1) (2) は文学研究者からみると、ストライクゾーンが違うという感じを抱いてしまう。(1) 文体論はそもそも人気がない。文学研究者は「物語の内容」が好きだからだろう。(2) コンピュータを用いた単独の作品の内容分析は、文学研究者が精読に要求する水準から見るとやはり物足りない。(3) は可能性を感じるが、実践例はまだ多くない。
一方、当然といえば当然だが、文学研究者がもともともっていた問題意識と、コンピュータを用いた分析がもつ力とをうまく融合させた研究はやはり面白いと感じる。古典和歌の研究だが、故・近藤みゆきの N-gram 分析とジェンダー分析とを融合させた和歌文学史論とか(『古代後期和歌文学の研究』『王朝和歌研究の方法』)、最近新著を出したホイト・ロングの青空文庫の分析(The Values in Numbers)などである。日本文学研究ではないが、フランコ・モレッティの『遠読―〈世界文学システム〉への挑戦』も面白かった。
精読と遠読についてもう少し補足しよう。日本近現代文学研究者は、これまで作品の緻密な分析「精読」に価値をおいてきたが、作品の精読だけをしているわけでもない。というのも1990年代後半以降、ミシェル・フーコーの言説分析やカルチュラル・スタディーズの手法が導入され、大量の―しばしば文学以外の―関係資料を読むようになり、量的な分析をするようになった。また、文学史の見直し方の一つであるキャノン(正典)批判の雰囲気も存在した。著名作家による有名作品だけでなく、より小さな作品を、数を集めつつ傾向を分析し、その同時代的な配置や文学史的な位置づけを考えるようになった。
先ほど (3) に可能性を感じると書き、近藤、ロング、モレッティの論が面白いと感じるのは、こうした方向性とは接続しやすいように見えるからである。
3. どんな本文テキストが必要なのか。
そろそろ文字数制限なのだが、最後に日本近現代文学の研究者は、どんな本文テキストが必要だと考えているかについて書いておきたい。
当面、「ある程度の信頼性」のあるプレーンなテキストがあれば、十分と考えているのではないかと思う。本文が手元のデバイスで読める書籍や雑誌版面のデジタルデータが増えることも望ましいが、やはり本文のテキストデータの増加が今後の研究の革新の鍵を握っているだろう。(本文テキストに付与されうる各種のタグの機能と可能性については、私には知識がなく、今は論じられない)
ここでいう近代文学の研究者にとっての「ある程度の信頼性」とはどの程度だろうか。誤入力・誤認識がない(少ない)ことは言うまでもないとして、テキストの本文校訂の方針がそろっていることがありがたい。つまり初出雑誌形なのか、初刊単行本なのか、全集版なのか、あるいは著者が手を入れた最終版なのか。旧仮名なのか、新仮名なのか。旧漢字なのか、新漢字なのか。これらがばらばらだと、使いにくいと感じる。またどの文学者を採録しているかの採択基準も重要である。青空文庫は、このあたりのバラツキがつらい。
この意味では、すでに一定の方針の下で編集されている『明治文学全集』や『昭和文学全集』『現代日本文学大系』のような大規模なアンソロジーの類いを全文テキストデータ化すると、使い勝手がいいかもしれない。近現代文学研究者が実際の研究で使用するテキスト=底本は、人により、場合により多様なので、そのまま直接使える本文テキストを目指す必要はひとまずなかろう。それより、ある程度の規模で、ある程度の水準、方針で統一された本文テキストがまとまって手に入り、検索やデータ分析などで利用可能となる方がよい。実際に使う底本との本文上の差異は、各自の研究の中で配慮すればいいわけである。
4. おわりに
書き終えて、当たり前のことばかり書き連ねてきたような気がするが、人の精読と機械の遠読とをうまく組み合わせ、文学研究のもつ問題意識を盛り込むような研究は、これから次第に現れてくるだろうと思う。突破口になる面白い研究が出現することが、ターニングポイントになるにちがいない。
問題はその先の、文学研究以外の領域への「再接続」なのかもしれないと、ぼんやりおもっている。文学研究だけでなく、人文学研究に漂う斜陽感を払拭するための出口の一つは、デジタル人文学の方向にあることは確実である。そしてそれが成功するためには、「文学研究のもつ問題意識」そのものがかなりその姿を変えている必要があるのだろう。
執筆者プロフィール
《連載》「Digital Japanese Studies 寸見」第77回
「CiNii Articles の CiNii Research への統合が発表:CiNii Research でなにが変るのか」
2021年7月6日、国立情報学研究所(以下 NII)から、同所の研究論文検索サービスの CiNii Articles を、2022年4月にむけて CiNii Resaerch へと統合してゆくことが発表された[1][2]。CiNii Articles は、もと CiNii の名で2005年にはじまったもので[3]、Webcat の後継として CiNii Books が提供されることにともない、CiNii Articles へと名称を変更したものであった[4]。CiNii Research は、2020年11月6日にプレ公開され、2021年4月1日に本公開となっていたもので[5]、研究を広くカバーし、研究データや論文・書籍・プロジェクトなどを検索できるようにしたものだという[6]。これは、「日本国内の研究活動の全てを一つの「CiNii ナレッジグラフ」としてまとめ,セマンティックな情報として公開していくための先進的な試みである」[6]。
いま述べたことからも窺えるが、CiNii Articles は、NII を取り巻く研究・書誌データ管理の歴史の所産である[7][8]。[7]によれば、CiNii Articles は、GeNii という、2013年に終了した[9]学術情報ポータルの一部となるべく作られたという。GeNii と CiNii の先後など正確には分らなかったので、GeNii における CiNii の位置づけの細部をここで議論はしないが、重要なこととしては、CiNii Articles が NII の電子図書館サービスの一部を担ったことである。NII の電子図書館サービスは、論文書誌情報データベース、学術雑誌目次速報データベースや記事本文画像データベースなどがあり、前身の学術情報センター(NACSIS)に遡るものであった。この電子図書館サービスで構築されたデータベースに、国立国会図書館の雑誌記事索引、科学技術振興機構の J-STAGE などの書誌データを取り込んで現れたのが CiNii Articles であった。[3]に述べられるように、初期の CiNii では、機関契約がなければ論文本文はもとより書誌情報も見られなかったし、PPV(Pay per View; 閲覧ごとの販売)での提供もされていた。[8]に詳説されるように、紆余曲折のすえ、電子図書館サービスは廃止となり、2017年には、それにともなう本文提供のJ-STAGE等への移管をめぐって、おおきな混乱があったが、それを経て CiNii Articles は論文検索に特化したサービスへと変化を遂げた。その間にも、2015年に、インターネット公開された博士論文を検索するための CiNii Dissertations が公開される[10]など、NII の学術情報検索ポータルとして、CiNii がおおきな変化を遂げてきたことがあらためて感得される。Webcat から CiNii Books への流れなどは、NII の事業体制整理の側面が大きく、CiNii Dissertations は、博士論文のインターネット公開義務化の影響下にあり[11]、こちらは、政府の研究成果政策の一環であるというように、CiNii には、NII のサービス体制の変遷の影響が大きいのである。
CiNii Articles の回顧が長くなったが、[6]にもあるように、CiNii Research には、そのような研究成果政策の変化への対応も大きい。それは、資金提供元の意向による成果のオープン化であったり、研究公正[12]の観点から研究データの保全が重視されるようになったり、あるいは、そもそも情報処理技術の高度化によってデータ共有のありさまが一変したりというような背景がある[13]。それが CiNii Articles の終了とどのように結びつくのかは、かならずしも図りかねるところもあるが、管理開発体制上の問題などが大きいのであろう。
さて、本題の CiNii Research への CiNii Articles 統合でなにが変るのかという点であるが、目録検索から Google 検索のようなふわっとした検索への変化というものがもっとも大きい[14]。その最たる例が、「関連度順」である。メタデータや関連するエンティティ(各論文や書籍など、検索結果に表れる単位)によって検索キーワードと関連が深いと判定されたものがより上位に現れるということである。関連度順検索じたいは、すでに新世代の書誌検索エンジンを導入しているサービスや、J-STAGEなどで利用できるが、CiNii に現れたのはついにと言った感じがする。関連度とは難しい概念で、書誌 DB で有用だと思ったことは一度もないのだが、それはともかく、CiNii Articles でないものでは比較しにくいので、出版年順で比較してみると(現状の CiNii Research ではタイトル順や収録誌順ではソートができない)、収録データソースの違いから、CiNii Articles では見つからなかった欧米欧文誌(科研報告書由来が多いか)や全国遺跡報告総覧からのデータで差がある。現状では、CiNii Articles のメインデータである国立国会図書館の雑誌記事索引が CiNii Research で使えないので、そのへんは、統合以後確かめることとなろう。検索結果の統御なども大きく違って、CiNii Research ではファセット検索が主となっている。ファセット検索はマスキング機能でしかないから、データベースとしての作りが違うとはいえ、不便なことである。
CiNii Articles は、大学生になって早い段階で便利さにのめり込んだツールであったから、それがなくなるのは国会図書館の OPAC が今風のものに変ったときに似た衝撃がある。それは、NACSIS-CAT で並立書誌が作られるようになったのと、ある種似た驚きである[15]。もうすこし分かりやすい譬喩をすると、Yahoo!のディレクトリ型検索から、Google のフラットな検索に変ったときの驚きと言おうか。いよいよ、学生たちに学問への分け入り方を教えにくくなった気がする。
国立情報学研究所(NII)、CiNii Articles の CiNii Research への統合スケジュールを公表 | カレントアウェアネス・ポータル https://current.ndl.go.jp/node/44442。
CiNii Articlesへの名称変更は、
国立情報学研究所(NII)、大学図書館所蔵資料を検索できる CiNii Books を公開 | カレントアウェアネス・ポータル https://current.ndl.go.jp/node/19478
に推断の記載があるように、はっきりと告知はされなかったのであるが、のちに示す[7]には、当事者として、CiNii Books の公開によるものとの認識が示されている(その注に上記のプレスリリースが指し示されているのは、正しくないのであるが)。
研究データを含めた幅広い研究リソースの統合検索を実現 ~「CiNii Research プレ版」を先行公開~ - 国立情報学研究所 / National Institute of Informatics https://www.nii.ac.jp/news/release/2020/1106.html。
CiNii - お知らせ - CiNii Dissertations 正式公開について - サポート - 学術コンテンツサービス - 国立情報学研究所 https://support.nii.ac.jp/ja/news/cinii/20151028。
研究公正ポータル │ 国立研究開発法人 科学技術振興機構 https://www.jst.go.jp/kousei_p/。
拙稿「設立記念シンポジウムが催され HNG データセット保存会が発足」『人文情報学月報』85、2018。
拙稿「「くずし字データセット」と「KMNIST データセット」」 『人文情報学月報』89、2018。
研究データリポジトリについては、CiNii Research とも関わるものとして、GakuNin RDM をまず挙げるべきであろう。
込山悠介「日本の学術機関に向けた研究データ管理サービス GakuNin RDM」カレントアウェアネス・ポータル E2409、2021 https://current.ndl.go.jp/e2409。
また、人文学にも関わってくる話としては、日本学術振興会の JDCat がある。
日本学術振興会(JSPS)・国立情報学研究所(NII)、人文学・社会科学総合データカタログ「JDCat」の運用を開始 | カレントアウェアネス・ポータル https://current.ndl.go.jp/node/44451。
先進的な取組みとして、英国の例を挙げておく。
英・Research England(RE)、研究を8つの要素に分解して公開できるプラットフォーム“Octopus”の開発支援への資金提供を合意 | カレントアウェアネス・ポータル https://current.ndl.go.jp/node/44577。
《連載》「欧州・中東デジタル・ヒューマニティーズ動向」第38回
「手書きテキスト認識・自動翻刻ソフトウェア・Transkribus の基本知識と最新動向」
8月14日夕刻、UTDH 勉強会(東京大学デジタル・ヒューマニティーズ勉強会)の分科会である多言語テキスト勉強会は、第5回目の勉強会を迎えた。この分科会は、デジタル・ヒューマニティーズで扱う、様々なテキスト処理に関する技術を学ぶ勉強会であり、予定としては、OCR(光学文字認識)・HTR(手書きテキスト認識)の他にも、テキストマイニング、自然言語処理、ツリーバンク、文字の符号化などを研究する予定である。これまでは筆者がこの会の幹事件進行役を努めており、本連載にも何度か取り上げた手書きテキスト認識・自動翻刻ソフトウェアである Transkribus[1]や OCR4all[2]といったソフトウェアの実践・研究を進めてきた。その過程で、筆者は Transkribus 開発チームの代表格であるインスブルック大学のギュンター・ミュールバーガー (Günter Mühlberger) 氏[3]に質問のメールをお送りし、回答を得ていたのだが、勉強会に実際に来て、直接勉強会のメンバーからの質問に答えていただけないかとお尋ねしたところ、快諾いただけた。本稿では、その勉強会で得られた Transkribus の高度な使い方や機能、そして、最近、便利な機能の実装が進んでいる Transkribus Lite の動向などを説明する。
Transkribus とは、インスブルック大学が中心になって開発している、主に人文学で用いられる手書き歴史資料を自動で翻刻するソフトウェアである。深層学習を用いており、トレーニングをすれば、基本的には、どんな文字・どんな言語でも対応できる。Unicode にない文字であっても、ラテン文字転写を用いてトレーニングさせたり、縦書きでも、90度回転させれば、対応することができる。他にもヴュルツブルク大学の OCR4all や、kraken を用いた eScriptorium[4]など、HTR ソフトウェアはあるが、現在のところ、Transkribus が最も、インストールが容易で、充実したグラフィカル・ユーザ・インターフェース(GUI)を有しており、使い勝手が良いようである。以下、今回のミュールバーガー氏をゲストに招いた勉強会で得られた知識の中で、有益と思われるものをハイライトしてお届けする。
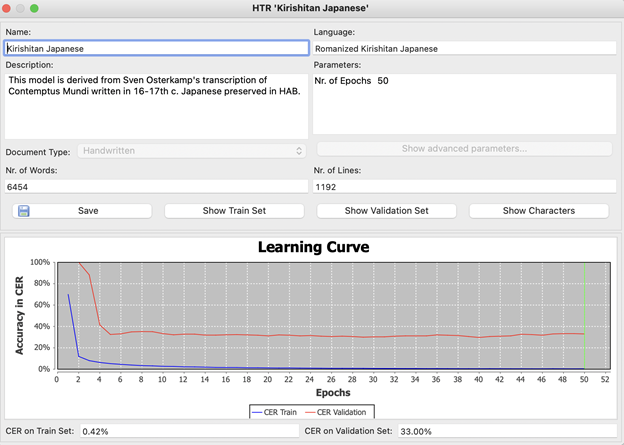
CER-Train と CER-Validation の違い
Transkribus を使っていると CER という用語がよく目につく。CER とは Character Error Rate(文字エラー率)の略であり、文字単位でその HTR モデルのエラー率のことであり、そのモデルの精度の指標となっている。以下は、ローマ字日本語キリシタン資料である、Contemptus Mundi(コンテムツス・ムンヂ)[5]の、スヱン・オースタカンプ(Sven Osterkamp)氏による20ページほどの翻刻をトレーニングデータとして用いたものである。青が作成したモデルで、トレーニングデータで認識させて、でてきたエラー率である。トレーニングがうまくできていると、通常はほぼ100%に近い数字をたたき出す。赤が、トレーニングデータとは別にあたえた、バリデーションデータである。これはトレーニングデータとは別の画像をもちいて、かつ手動翻刻したもので、トレーニングデータには入っていないことが必須である。これは、HTR モデルの精度をはかるもので、学術的な制度の向上研究に使われるものである。このモデルでは、バリデーションデータの設定がよくなかったのか、30%ほどのエラーがでるというよくない結果となっている。もう一度バリデーションデータをうまく設定して、良い CER Validation を得たい。
HTRエンジン
2020年10月から Transkribus には、credit 制が導入された[6]。これは最初の500credit を使用したあとは、credit を購入して使用しなければ、自動翻刻ができないと言う仕組みである。Transkribus では、PyLaia と HTR+ という2つの HTR エンジンが用意されている。トレーニングの際にはどちらかのエンジンを選択しなければならないが、PyLaia[7]はオープンソースであるため、コストが低く、少ない credit で HTR を行うことができる。それに対して HTR+[8]は、ロストック大学の CITlab チームが開発したプロプライエタリ・ソフトウェアであるため、コストが高く、PyLaia よりも多い credit がかかる。ミュールバーガー氏にこの2つの HTR エンジンの性能の差を聞いてみたところ、目立つような差はなく、credit の違いは、オープンソースかそうでないかの差だということであった。
縦書きテキスト
Transkribus はまだ縦書きテキストには対応していないが、将来対応するよう開発されることが期待されている。現状では、90度回転方式が有効である。90度回転するには、様々な方法がある。元の画像データを90度回転させて、縦書きをあたかも横書きすることを通して可能にすることもできるが、ここではミュールバーガー氏に教えてもらった、方法を紹介したい。これは、ベースライン(BL)の機能を使うもので、ベースラインの方向を指定するときに、90度回転させて、最初に設定すると、元画像が縦書きのもので正しく表示されたものであっても、ベースラインを読み込むときにそれが横書きとして認識される。
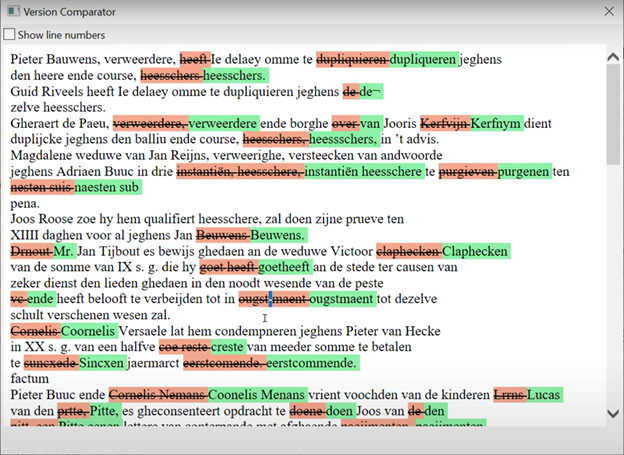
バージョン比較
Transkribus には、編集した際に保存したそれぞれの新旧の翻刻のバージョンを色付きで表示する機能がある。このツールは Version Comparator と言われる(図2)。いわゆる diff 機能であるが、HTR モデルの自動翻刻を修正した際、この機能を使えば、その HTR モデルがどこで誤ることが多いのか一眼でわかる。
ヘッダー・ページ番号・人名・地名・タグ付け
また、Transkribus は、各部位にタグをつけることができる。例えば、下の写真では、自動的に、QVAN DAIICHI「巻・第一」と書かれた巻名のところが header のタグとなっており、水色の色が振り分けられている。また、ページ番号も page-number と黄色の字が書かれており、黄色のハイライトがつけてあるが、これはページ番号がテキスト中でタグづけされていることを意味する。
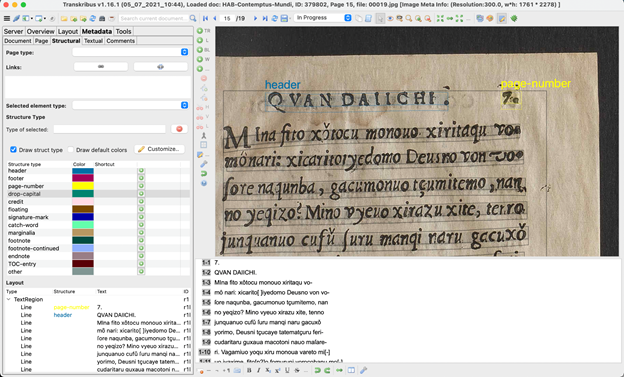
Transkribus のデータ、テキストとそれが対応する画像中の位置のデータは XML で構成されており、XML を直接修正することで、タグをつけたり、変更したりすることも可能である。
これをつかえば、ページ番号やヘッダーなどレイアウトに関することだけでなく、CatMa[9]のように、地名や人名などオントロジーもタグ付けでき、それを XML で出力することができる。このオントロジーをトレーニングデータに施しておけば、PyLaia などの HTR エンジンがそれを覚え、自動で、タグ付けしてくれる、という便利な使い方もできる。オペラの台本における舞台上の指示などもこのタグ付け機能を使用すれば、HTR エンジンがパターンを覚え、舞台上の指示などを細かくタグ付けを自動で行う。
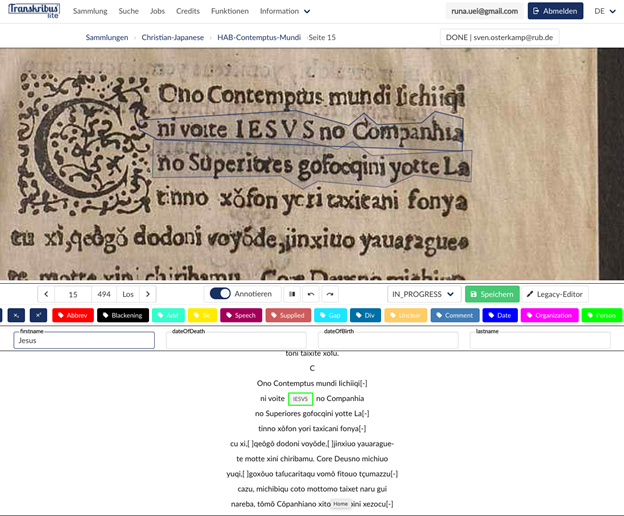
最近、さらにこのタグ付け機能が、ブラウザ上で動く Transkribus lite[10]でも使えるようになった(図4)。こちらは、ローカル版よりもよりみやすいインターフェースを持ち、非常に手軽に使用できる。有料 credit 制を導入して以降、Transkribus はこうした機能の拡張を進めており、将来は、ローカル版でできること全てが、ブラウザ上で手軽にできる日が来るのかもしれない。
- コメントを投稿するにはログインしてください