人文情報学月報第143号【前編】
ISSN 2189-1621 / 2011年08月27日創刊
目次
【前編】
- 《巻頭言》「図書館サービスの研究開発と成果のオープン化について」
:国立国会図書館 - 《連載》「Digital Japanese Studies 寸見」第99回
「デジタルアーカイブ学会「デジタルアーカイブ憲章」とデジタル日本研究」
:慶應義塾大学文学部 - 《連載》「欧州・中東デジタル・ヒューマニティーズ動向」第60回
「ドイツにおけるデジタルインフラストラクチャと DH ツールの開発への助成」
:人間文化研究機構国立国語研究所研究系
【後編】
- 《連載》「デジタル・ヒストリーの小部屋」第17回
「コミュニティによって生成されたデジタル・コンテンツ(CGDC)とデジタル・パブリック・ヒストリー:沖縄県南城市の取り組みをうけて」
:千葉大学人文社会科学系教育研究機構 - 《連載》「仏教学のためのデジタルツール」第8回
「天台宗典編纂所刊行『天台電子佛典』」
:早稲田大学 - 人文情報学イベント関連カレンダー
- 編集後記
《巻頭言》「図書館サービスの研究開発と成果のオープン化について」
筆者の所属する次世代システム開発研究室(次世代室)は、先端技術を図書館サービスに対して応用することをミッションとして技術開発・実証実験を進めている。
その成果を広く公開し、当館外の技術者・研究者の皆さんに役立ててもらうため、2019年に NDL ラボとして GitHub アカウント(https://github.com/ndl-lab)の運用を開始し、2023年6月時点で合計34リポジトリのデータセット及びプログラムソースコードを提供中である。
これまで、当館外の研究者からのフィードバックや二次利用による当館外での新たなサービス展開等、好ましい効果が多くあったと認識している。
人文情報学月報の読者の皆さんの中にも、既に利用されていたり、更にはフィードバックに協力くださったりしている方が多く存在する。この場を借りて改めて謝意を表しつつ、今後利用を検討する皆さんに情報提供できるよう、これまでの大まかな経緯と代表的なリポジトリの概要を紹介する。
2019年に運用を開始した際、実験サービスである次世代デジタルライブラリーに関するものとして、そのソースコード[1]や、画像検索機能のために資料中から図版を自動抽出するための機械学習モデル[2]等を公開した。
次世代デジタルライブラリーのソースコードについては、新機能公開の節目に合わせて現在も定期的に更新しているものの、複雑で大規模であることから、当館外での利活用には不向きな側面もあると認識している。一方、実は担当者視点では大変重宝しているものである。というのも、次世代デジタルライブラリーの実装に関する当館外の技術者からの問合せに対して、GitHub 上のソースコードの該当箇所を参考実装として示して簡単に回答できるという裏技的(?)な使い方ができるからである。実装に関心をお持ちの方であれば、ソースコード内を検索されることで新たな発見があるかもしれない。
資料中から図版を自動抽出するための機械学習モデルについては、東京大学の『デジタル源氏物語』[3]プロジェクトにおいて、デジタル化資料からの挿絵の検出に活用頂いている。特定の機能を有する機械学習モデルを切り出して公開したことで、当館外で活用が進んだことやコレクションの持ち味を生かした新しいサービスにつながったことに意義があったと考えている。
2019年度は他にも、NDC Predictor[4]の機械学習モデルの公開[5]や、著作権保護期間が満了した資料画像から作成した資料画像レイアウトデータセット(NDL-DocL)[6]の公開も行った。特に NDL-DocL は、当館における OCR 関連の研究開発において重要な役割を果たしてきた。図書資料から作成したデータセットは、後述する NDLOCR の開発初期段階の検討に活用したほか、古典籍資料から作成したデータセットは NDL 古典籍 OCR の開発において現在も活用している。
2020年度には、2016年度から NDL ラボのホームページ上で公開していた、著作権保護期間の満了した図書資料から切り出して作成した文字画像データセット(平仮名73文字及び漢字300文字)[7][8]を GitHub に移行し、再公開した。このデータセットは筆者が入館する以前に当館が作成した、NDLラボ最古参の公開データセットであるが、画像認識をテーマにした研修の題材や、OCR 技術検討用に人工的な紙面を作成する用途に使い勝手が良く、先に紹介した NDL-DocL と共にこれまで筆者が最も頻繫に利用してきたデータセットである。
2022年4月に、前年度の OCR 研究開発事業[9]によって開発した NDLOCR[10]を GitHub で公開したことは大きな転機となったと考える。NDLOCR は当館が2021年度以降デジタル化する資料をテキスト化するために外部委託によって開発した OCR であり、明治期等の古い資料のデジタル画像も高い認識性能でテキスト化できる点に特色がある。各所で話題になり、多くのスター(2023年6月時点で300スター以上)が付いているが、寄せられる報告や要望も増えている。Google Colaboratory 等外部サービス上で動作させる際の不具合や、GPU メーカーが更新する公式 Docker コンテナとの設定の不一致等、公開後に外的要因によって新たに生じた不具合の報告が多いが、これらは逐一把握することが難しい性質の不具合であるため、迅速な修正対応に役立っている。
2022年度後半は、NDLOCR の技術的知見も活用した、くずし字等の古典籍資料をテキスト化する NDL 古典籍 OCR[11]のソースコードや、みんなで翻刻[12]の成果物を加工した NDL 古典籍 OCR の学習用データセット[13]、NDL Ngram Viewer のソースコード[14]及び搭載データセット[15]を公開した。
次世代室のミッションにおいて、資料のアクセス可能性の改善は大きなテーマであるが、これは所蔵資料全体に資する改善、という意味合いが強く、特定の研究分野の資料についてリクエストに応じて重点的に研究開発を行ったり、特殊な要望に対応したりすることは困難であることが多い。こうした特化型の研究開発の需要に対して、技術をオープンな利用条件(CC BY4.0)で公開することは、必要な人が追加開発できる下地を提供する、という意味で重要と考えている。
また、公開した技術を用いて、国内外の研究機関が、当館が所蔵しない、出版物以外の特色のある資料群に対し、全文検索の実現や新しいサービスを立ち上げていくことになれば、様々な日本語資料のアクセス可能性が高まっていくことになる。そのためには多くの方に関心を持っていただき、さらに活用されることが重要である。
最後に個人的な所感を述べて結びとする。機械学習をはじめとする情報技術の進展は日進月歩であり、図書館サービスにおいて数年先に実現できることは何か、現時点で正確に目利きすることは難しい。現在直面している技術的課題が、数年後の技術革新によってエレガントに解決されるかもしれないということは、より良いサービスの実現に思いを馳せる一人の図書館関係者として純粋に喜ばしく、わくわくしているところである。一方で、機械学習分野を念頭に最良とされる技術や手法が瞬く間に置き換わっていく時勢の中で、獲得した新しい知見が次々と陳腐化していく懸念を前に、図書館における R&D 業務の担当者としての仕事のあり方に思いを巡らせている。特に、先端技術を借用・追従した実験的サービス開発にとどまらない、時勢に左右されず、図書館サービス全体を着実により良いものにしていく取組とはどうあるべきか、ということを最近考える。
本稿で述べた、次世代室におけるデータセットやソースコードを含めた研究成果を誰でも利用・検証・応用可能にしていくオープン化の取組は、現在の当館の技術を広く開示・提供することに加え、人文情報学や図書館情報学をはじめとする各種分野の今後のツール開発における土台となる素材や今後登場する新技術の検証材料を世の中に提供するものである、という点が大切と思っている。一歩ずつであるが、「図書館サービス全体を着実により良いものにしていく取組」へと育っていくことを筆者は願っている。
https://github.com/ndl-lab/tugidigi-web
https://github.com/ndl-lab/tensorflow-deeplab-v3-plus
https://genji.dl.itc.u-tokyo.ac.jp/
https://lab.ndl.go.jp/ndc/
https://github.com/ndl-lab/ndc_predictor
https://github.com/ndl-lab/layout-dataset
https://github.com/ndl-lab/hiragana_mojigazo
https://github.com/ndl-lab/kanji_mojigazo
https://lab.ndl.go.jp/data_set/ocr/r3_software/
https://github.com/ndl-lab/ndlocr_cli
https://github.com/ndl-lab/ndlkotenocr_cli
https://honkoku.org/
https://github.com/ndl-lab/ndl-minhon-ocrdataset
https://github.com/ndl-lab/ndlngramviewer_v2
https://github.com/ndl-lab/ndlngramdata
執筆者プロフィール
《連載》「Digital Japanese Studies 寸見」第99回
「デジタルアーカイブ学会「デジタルアーカイブ憲章」とデジタル日本研究」
デジタルアーカイブ学会(以下、同学会)は、2023年6月6日に「デジタルアーカイブ憲章」(以下憲章)を制定・公表した[1][2]。2022年8月に憲章制定にむけた公開会議が催されてから、数次の検討を経て同学会理事会において制定されたものである。
デジタルアーカイブ学会は、2017年に誕生したまだ新しい学会である[3]。デジタルアーカイブとは、月尾嘉男氏が90年代中葉に考案したことばとされ[4]、本連載においても幾度となく注釈なしで登場してきた。提唱当初は文化財の電子的保存と利活用に焦点があったようだが[5]、そのニュアンスは次第に薄れ、物質的な資源の電子的保管庫としてひろく解釈されるまでにそう時間は掛らなかったようである[6]。同学会は、その広義のデジタルアーカイブの関係者を糾合し、かつ政策的におし進めたいという意図から成立した。
本憲章の必要性がどのように唱えられてきたかについての記述は、憲章には存在しない[6]。そこまで精査していないが、吉見俊哉同学会会長の就任挨拶にも憲章の制定の必要性は説かれず[7]、2022年度第1回理事会(2022年5月30日)の議事録にはじめて現れたものと思われる(報告事項⑶)[8]。本憲章の第1次公開検討会(「第1回デジタルアーカイブ憲章をみんなで創る円卓会議」)の開催報告において、城田晴栄氏は、デジタルアーカイブの認知を高め、あるべきデジタルアーカイブ社会をもたらすために憲章を策定する必要があったことを述べる[9](同会の報告に[10]もある)。[7]によって、同学会の法制度部会[11]の関与が大であることが窺い知られるが、そのような観点からは、法制度部会が関与する「デジタルアーカイブ整備推進法(仮称)」の議論の過程で必要性の認識が生まれたのかとも推察される[11]。また、[12]では、吉見会長からマグナカルタのような憲章の持つ意味が説かれたよしであるが、それがどのように日本の「デジタルアーカイブ」を取り巻く環境にないか、それによってどのような事態が起っているかについての記述はないことに変わりはない。マグナカルタのような行動の規矩を求めるのだとすれば、なおのこと、行動の規範を設ける切実な背景があってしかるべきではなかろうか。
さて、[2]において、憲章の制定までの過程が文書として保存されているので、それによって第三者(稿者も学会会員ではあるが、憲章制定にはいっさい関わっていない)がどれくらい制定過程を理解できるか見てみたい(なお会員限定とされる策定過程の議事録は、パスワードを受け取った記録もなく、確認できていない)。
まず、憲章の制定に関わったのがだれなのかにかんする記録は現時点で提供されていない(策定過程の議事録に書いてあるのでなければ)。さきに述べたことから、同学会の法制度部会でかと思われるが、明記されているわけではない。ただし、公開検討会の会議次第において[13]、趣旨説明を行うのが法制度部会の幹事であることは、この傍証としてよいだろう。
制定の流れとしては、2022年7月5日のオンラインの会員ウェブ懇談会でさきんじて提示されたのち(同年6月28日発出告知)、同年8月3日に第1回の検討会がオンラインで、同年10月11日に第2回がやはりオンラインで行われ(参加記録は[12])、同学会第7回研究大会がコロナ禍の落ち着きを捉えて琉球大学で開催されたのにあわせて、第3回がはじめて対面で同年11月26日に開催された。2023年2月15日から28日にかけてパブリックコメントを実施した後、同年3月14日に総括のためのシンポジウムが開催され、最終的な調整を経て理事会における採択となったものと窺われる。第3回までにおける論点は、文責があきらかではないものの、まとめられて提供されている[2]。この間、2022年12月に「デジタル温故知新社会に向けた政策提言2022年」というものが出され、憲章の対となっている[14]。対であることは[8]に述べられる。都合4回の検討を経たことになるが、2022年8月案と最終的な採択案の差は語句の若干の加筆に留まるようである。
内容は、基本的には「コモンズ」[10]を単位とした「記憶する権利」を仮設し、それを通じてゆたかな社会を実現し、デジタルアーカイブをその基盤とする「デジタルアーカイブ社会」実現のためにデジタルアーカイブに関わるものが鋭意努力すべきものを提示するものとなっている。
論点整理を見ると、デジタルアーカイブの定義はデジタルアーカイブジャパン実務者検討委員会の定義の取意によることが述べてある[15]。それが具体的になにかは述べられていないが、おそらくは内閣知的財産戦略本部デジタルアーカイブジャパン推進委員会及び実務者検討委員会の報告書「我が国が目指すデジタルアーカイブ社会の実現に向けて」[16]などにある定義にもとづくのであろう。これは奇である。アイディアの依拠元を示していないのが論外であるのはともかく、デジタルアーカイブジャパン実務者検討委員会の構成員とデジタルアーカイブ学会の憲章を起草した面々とは重なるのかもしれないが、デジタルアーカイブの多様な背景や係わり方を汲むうえで、援用するのが真によいことかは分からない。
そもそもデジタルアーカイブがその対象を広げたいまでも、デジタルアーカイブを称するものには、伝統文化資料の電子的保存と利活用を主眼とし、それ以外のものは対象外とするものがまま見受けられる。これは、(月尾氏の構想の影響がどのようにあるかは今後の検証を待たねばならないが、)その分野において、(諸外国にある図書館としてのデジタルライブラリや、選別を含意するデジタルコレクションではなく)デジタルアーカイブという名がサービス名称として選び取られてきた経緯が影響しているように思われる。また、デジタルアーカイブとデジタルアーカイブス(電子的文書館)をある種同等のものと見たとき、アーカイブスが具有すべき網羅性をデジタルコレクションは有してこなかったという問題があり、そのような経緯を軽んじて、デジタルアーカイブに無限定の「コモンズ」にとってのデータ保管庫としての役割を主たる役割として求めようとするのは、政策ありきの態度に思える。
さて、憲章がこのようなものであることを見てきたうえで、デジタル日本研究にどう関わるだろうかということを考えたい。デジタルアーカイブ社会を築きたいというこの憲章の意図は、特にデジタル日本研究との接点があるものではない。ただ、デジタル日本研究には、国文学研究資料館が日本語の歴史的典籍の国際共同研究ネットワーク構築計画を行っていたように、エビデンスを共通のデータ基盤に求め、それによって検証可能性などを高めていく機運がある。そのとき、デジタルアーカイブ社会なるものが実現されるのであるとすれば、ただたんに傍観者として振る舞うのではなく、専門家として望ましいデータ基盤のありかたの検討の先頭を切る責任がデジタル日本研究者には生まれてくるのではないかと思われる。
なお、憲章制定を祝したシンポジウムが2023年7月に開催されるとのことである[17]。
《連載》「欧州・中東デジタル・ヒューマニティーズ動向」第60回
「ドイツにおけるデジタルインフラストラクチャと DH ツールの開発への助成」
ドイツではデジタルヒューマニティーズが非常に活発で、多くのプロジェクトが様々な助成元からの資金援助を受けている。筆者もまた、それらのプロジェクトの1つに研究員として雇われて、2015年10月から約5年半働いていた。本稿では、ドイツにおけるデジタルヒューマニティーズに対する主な助成元を、具体例を挙げながら述べる。まず、ドイツも加盟している欧州連合系の助成元について述べ、そのあとは、ドイツ国内の助成元について述べる。
まず、欧州連合系の助成元の筆頭は ERC(European Research Council「欧州研究評議会」)[1]である。ERC は、欧州の研究基盤の強化と、卓越した研究者の育成を目的としている。ERC の助成金は、欧州の研究開発に大きな貢献をしている。ERC には大小様々なプロジェクトの助成が用意されている[2]。この ERC の助成金は、全ての学問分野に適応されており、デジタルヒューマニティーズに限らない。ただし、成果物として何らかのウェブデータベースを提供することを目指すことが多く、人文学分野では DH にも関連するプロジェクトが多い。これに対して、ERIC(European Research Infrastructure Consortium「欧州研究基盤コンソーシアム」)[3]は、ヨーロッパ全域の研究を支援するためのデジタルインフラストラクチャを整備するための機関であり、デジタルインフラストラクチャのプロジェクトを助成している。また、同じ欧州連合の OpenAIRE[4]もデジタルインフラストラクチャ事業を行っている。OpenAIRE のもっとも有名な成果としては、欧州原子核研究機構(CERN)と共同開発した学術成果のリポジトリ Zenodo[5]である。ここには、論文やデータセットなどあらゆる研究成果を DOI(Digital Object Identifier「デジタルオブジェクト識別子」)つきで、誰でも公開できる。
DARIAH(Digital Research Infrastructure for the Arts and Humanities)[6]は、人文科学と芸術のデジタル研究基盤を提供する。ヨーロッパ各国に設置されたそれぞれの DARIAH、たとえばドイツの DARIAH-DE[7]とヨーロッパ全域を管轄する DARIAH-EU[8]がある。DARIAH-DE は、例えば、TEI(Text Encoding Initiative)が定めた、デジタルヒューマニティーズにおける人文学テキストの機械可読化・構造化の世界標準である TEI Guidelines[9]に準拠した XML(Extensive Markup Language)ファイルをベースに、文献の写真を見て座標をつけながら、人文学テキスト資料をデジタル化するツールである TextGrid[10]がある。このアプリなどを用いて作られたデジタル学術編集版としては、ゲッティンゲン大学とゲッティンゲン・ニーダーザクセン州立大学図書館の「Theodor Fontane: Notizbücher」プロジェクト[11]がある。このプロジェクトでは、図1のように、ドイツの19世紀の作家テオドール・フォンターネのノートの写真、その TEI/XML による機械可読化、そして TEI/XML を実際のノートのレイアウトに近づけたウェブ上での視覚化を提供している。DARIAH-EU では、例えば、デジタル学術編集版に関する講座[12]など、DH の教育コンテンツを提供するウェブサイトである dariahTeach[13]などを提供している。
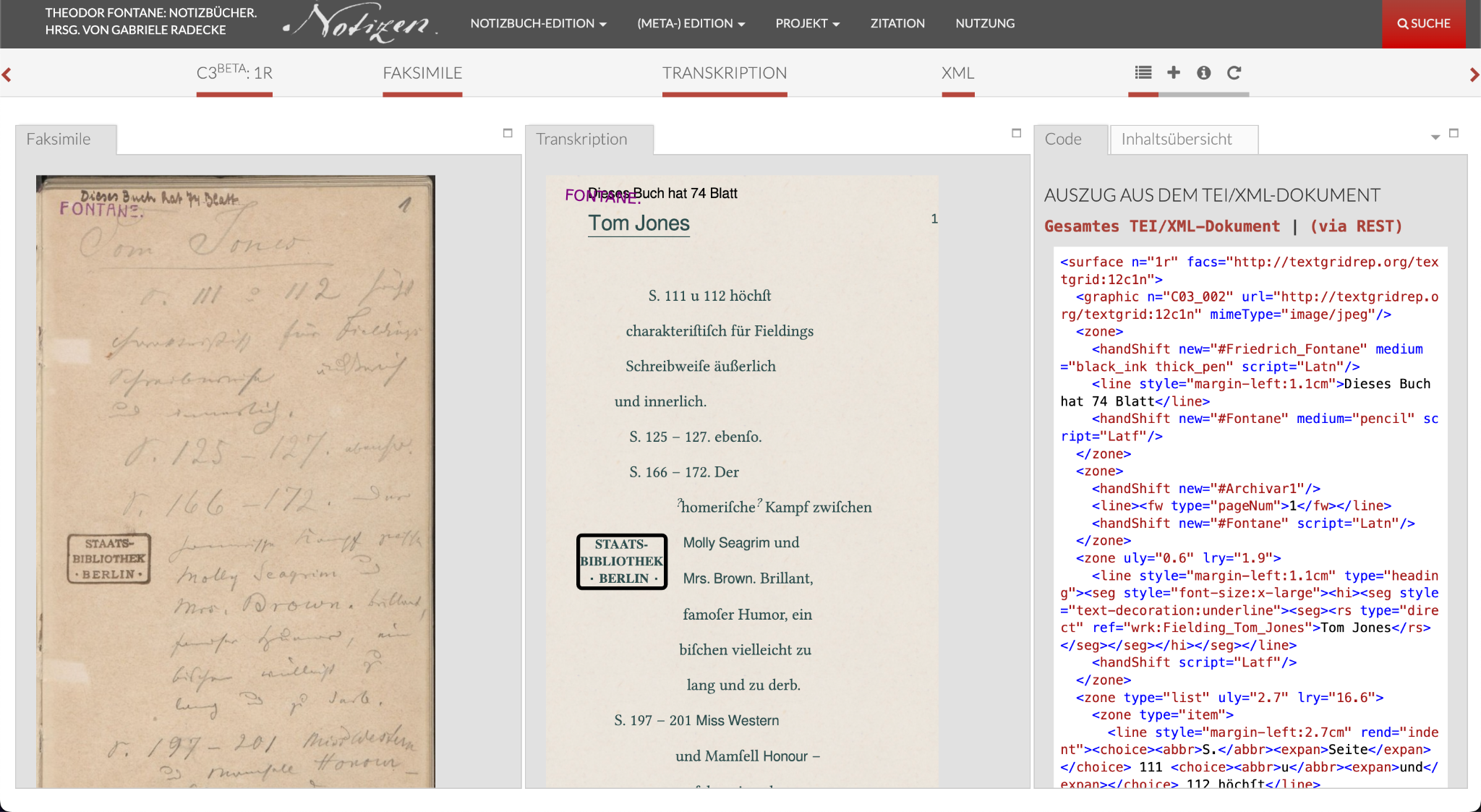
DARIAH-DE は、DARIAH-DE 第一期(2011–2014)、第二期(2014–2016)、第三期(2016–2019)となり、2019年から2021年に DARIAH-DE Betriebskooperation と CLARIAH-DE に分かれた後、それぞれ Geistes- und Kulturwissenschaftliche Forschungsinfrastrukturen e.V.「登記社団 人文・文化学研究インフラストラクチャ」[15]と NFDI(Nationale Forschungsdaten Infrastruktur「国立研究データインフラストラクチャ」)[16] へと進化を遂げた。このうち NFDI は、2023年の時点で、249の組織が加盟する非常に大規模なデジタルインフラストラクチャプロジェクトになっている。このプロジェクトの目的はデジタルインフラストラクチャの整備により、ドイツ国内外の研究者が、データの収集・保存・共有・アクセス・分析をより簡単に行えるようになることで、研究の効率と質を向上させ、新たな研究の可能性を広げることである。

NFDI は、広く様々な分野をカバーしているが、DH に関係のあるものとしては、2020年10月から始まった Runde 1の NDFI4Culture(文化学)、 2021年10月から始まった Runde 2の Text+(言語学・文献学・そのほかテキスト基盤の人文学)、2023年3月から始まった Runde 3の NFDI4Memory(歴史学)、 NFDI4Objects(物質文化学・考古学・人類学など)、NFDIxCS(コンピュータサイエンス)といった NFDIのコンソーシアムが様々な DH プロジェクトを助成している。
CLARIN(Common Language Resources and Technology Infrastructure)[18]は、研究資源と技術の共有インフラを提供している。DARIAH と同様、欧州各国に CLARIN センターがある。ドイツを管轄するのは CLARIN-D[19]である。CLARIN-D は、例えば、WebAnno[20]といった、広くテキストを扱う DH プロジェクトで使えるマークアップツールの開発などを支援してきた。このほか、CLARIN-D の助成を受けた WebLicht[21]は、テュービンゲン大学を中心に開発されてきた様々な自然言語処理サービスを提供するウェブベースのプラットフォームである。
ドイツ研究振興協会(DFG:Deutsche Forschungsgemeinschaft)[22]の様々な助成によって支援されたプロジェクトもまた、様々な DH ツールを提供している。例えば、DFG の助成制度の一つ SFB(Sonderforschungsbereich「特別研究領域」:一期4年間で最大三期まで更新可能)では、様々なツールが開発されてきた。例えば、フンボルト大学に設置された SFB 632では、ウェブ上でのタグ付きコーパスの視覚化・分析アプリケーション ANNIS[23]を開発し提供している。SFB の予算に関しては、例えば、筆者が所属していた SFB 1136は、第一期の助成金全体が670万ユーロ(2023年6月19日のレートで、10億3759万円)であった。そのほかの助成には、SFB よりも大きな金額の助成である Exzellenzcluster や SFB よりも小さい助成である Forschungsgruppen などがある。また、州や都市に配置された科学アカデミーでは、20年以上など長い単位のプロジェクトが行われている。
最後に、ドイツ連邦教育研究省(Bundesministerium für Bildung und Forschung: BMBF)[24]も独自の助成を行っている。その一例として、Early Career Research Group がある。引用や引喩を自動で探知するテキスト・リユース探知ソフト TRACER を開発した eTRAP[25]がその例で、2015年から2019年の4年間で160万ユーロ(日本円で2億4779万円)の助成金を得た。
以上がドイツにおけるデジタルインフラストラクチャと DH ツール開発への助成の主なものである。今回は欧州連合やドイツ連邦政府系の助成を中心に取り上げたが、全てを網羅できたわけでは決してない。ほかにも、フリッツ・ティッセン財団やフォルクスワーゲン財団などの助成や、州や市など地方自治体による助成など、様々な助成がある。さらに、ツールに関しても紙幅の制限のために助成元に対して1つ程度しか例示できなかったが、実際は数多く開発されている。このようにドイツでは、DH 基盤やツール開発にとって様々な助成が用意されていると言える。
- コメントを投稿するにはログインしてください