人文情報学月報第164号【前編】
ISSN 2189-1621 / 2011年08月27日創刊
目次
【前編】
- 《巻頭言》「東北大学におけるチベット資料の性格と展望:デルゲ版チベット大蔵経を中心に」
:高野山大学/東北大学 - 《連載》「欧州・中東デジタル・ヒューマニティーズ動向」第80回
「古典シリア語のデジタル・コーパスと包括的な書誌情報ネットワーク」
:筑波大学人文社会系 - 《連載》「英米文学と DH」第3回
「データカプセルの利用方法」
:中央大学国際情報学部
【後編】
- 《特別寄稿》「Roberto Rosselli Del Turco による「12. The Battle We Forgot to Fight: Should We Make a Case for Digital Editions?」(『Digital Scholarly Editing-Theories and Practices』所収)の要約と紹介」
:早稲田大学大学院文学研究科 - 人文情報学イベント関連カレンダー
- イベントレポート「九州大学大学院人文情報連係学府学際シンポジウムシリーズ「接続する人文学」」
:九州大学大学院人文科学研究院 - 編集後記
《巻頭言》「東北大学におけるチベット資料の性格と展望:デルゲ版チベット大蔵経を中心に」
東北大学総合知デジタルアーカイブ
2024(令和6)年に提供が開始された「東北大学総合知デジタルアーカイブ(Tohoku University Digital Archives/略称 ToUDA)」(https://touda.tohoku.ac.jp/portal/)は、同学が所有する学術・文化資源を統合的に公開し、「総合知」の形成と発展への寄与とともに社会での幅広い利活用をも目的としている。そして、過去に河口慧海・多田等観の両師によって東北大学へ将来された膨大なチベット資料もその主たる対象となっている。
実は東北大学は世界的に特筆すべきチベット資料の宝庫であり、およそ1世紀近く国際的にチベット学(Tibetology/Tibetan Studies)の分野を牽引してきた。本稿では知られざるこの学術資源について、東北大学附属図書館所蔵のデルゲ版チベット大蔵経を中心にその魅力の一端を紐解きたい。
東北大学が所蔵するチベット関連資料
現在、東北大学に所蔵されるチベット関連資料は、その出自に応じて次の五つに区分される:①デルゲ版チベット大蔵経、②多田等観請来チベット蔵外文献、③河口慧海コレクション、④河口慧海請来チベット蔵外文献、⑤河口慧海関連資料。このうち①②が多田等観(1890–1967)によって請来されたもの、③④⑤が河口慧海(1866–1945)に由来するものである。①②④は附属図書館の所管。③はインド・ネパール・チベットの各地で収集された仏教美術・民俗資料であり、文学研究科東洋・日本美術史研究室によって管理されている。⑤は総合学術博物館に保管され、仏像ないし手紙類とされるが、ほとんど未整理であり、カタログ化もなされていない。④は慧海がおもに北京を経由し入手したと目されるチベット蔵外文献資料であり、全体の概要に関する簡単な言及はあるものの(磯田[1989: 110(n. 8)])、⑤と同じく目録作成をも射程に入れた本格的な調査が急務であり、④⑤ともに現在予備的な調査が進められている。
「デルゲ版チベット大蔵経」と『西藏大藏經總目録』
ところで、上記の「蔵外文献(②④)」とは、「大蔵経(①)」に含まれないすべてのチベット語資料を指す。それでは、「チベット大蔵経」とはいったいいかなるものか。仏説部(カンギュル)・論疏部(テンギュル)という二つの群れからなるそれは、数世紀にわたってチベットで積み重ねられてきた翻訳事業の集大成である。典籍の多くはインドのことばからチベット語へと訳されたものであるが、一部チベット人自身の手になる著作や漢訳などからの重訳も含まれる。現在の写本・版本合わせて十数種類を数えうる大蔵経のうち、最も重要とされるものの一つが、東北大学附属図書館所蔵のデルゲ版チベット大蔵経である。
デルゲとはすなわちこの大蔵経が開版されたチベット東部カムの一地方を指し、正確な文典的校閲と極めて鮮明な印刷を特徴とする。従来は門外不出であり、その希少性はデルゲ王が流出を恐れて版工の右手を切り落としたという伝説を産んだほどである。ダライラマ十三世トゥプテン・ギャムツォ(1876–1933)の庇護を受けた多田等観の尽力によって請来され、仙台の一般財団法人斎藤報恩会の支援を受けて東北大学へと齎された。多田は金倉圓照とともに総計97,159葉にも及ぶ大蔵経の内容を精査し、世界にさきがけて文献学手法にもとづいた近代的な目録を実現した(宇井伯寿・鈴木宗忠・金倉円照・多田等観編『西藏大藏經總目録』仙台・東北帝國大学法文学部、1934年)。その際に割り振られた番号は「東北番号(Tōhoku number)」と称され、現在もなお世界的基準として一般的に用いられている。
知られざるデルゲ版のひみつ
それでは、デルゲ版独自の特徴とはいったいなにか。鮮明さと精密さとに加えて、出自として仏説部はジャン(リタン)版の流れを汲み、論疏部はシャル寺テンギュルにもとづくとされる。しかしながら、われわれの視線を惹き付けるのは各バンドル(帙)第一葉・裏面に刷り込まれた細密画ならびにそのキャプションであろう(下図③④参照)。

③細密画作製は論疏部の主席校閲官を務めたシュチェン・ツルティムリンチェン(1697–1774)によって主導され、④キャプション部分もシュチェン自身の手になることがわかっている。④は各細密画の下に一行二連で半偈ずつ記されるが、左右をあわせれば二行四連、アヌシュトゥブ(シュローカ)形式の一偈となる。とりわけ重要なのは、二連目と四連目には真上に描かれた図像の固有名詞が提示され、一連目と三連目には当該バンドルに収録されたテキスト名あるいはそれに由来する教理・事績などが埋め込まれており、それぞれの内容を互いに組み合わせることによってはじめて意味をもつ。たとえば上記④の現代語訳とチベット語翻刻は以下のとおり:
2・4)に聖典の守護尊(金剛薩埵)と注釈の著者(アバヤーカラグプタ)とが、1・3)に聖典と注釈との名が記され、細密画へのキャプション機能だけでなく、各バンドルにどのような文献が収録されているのか、その概要を①②を直接見ることなく把握できる。③④に秘められたこのような一種の簡易検索装置とも呼ぶべきギミックの存在は従来まったく注目されることはなかったが、これについてはデルゲ版における仏画師・彫刻師の役割とともに別稿において詳細に扱う予定である。いずれにしてもメタデータの構築にあたってこのようなギミックの役割が極めて重要であることに議論の余地はないだろう。
以上のように、東北大学附属図書館が所蔵するデルゲ版は出自・内容とともにまさしく至宝と呼ぶにふさわしく、全体の電子化と公開を目指して現在準備を進めているところである。
参照文献(配列は著者姓のアルファベット順)
執筆者プロフィール
《連載》「欧州・中東デジタル・ヒューマニティーズ動向」第80回
「古典シリア語のデジタル・コーパスと包括的な書誌情報ネットワーク」
古典シリア語の概要
古典シリア語は、アフロ・アジア語族セム語派に属する言語のひとつアラム語の1変種で、主に紀元1世紀から中東で広く用いられていた。主に都市エデッサとその周辺で発達し、キリスト教文学の媒体として栄え、現代に至るまで、中東やインドのキリスト教諸教派―例えば、アッシリア東方教会、シリア正教会、インドのマランカラ・シリア正教会、マロン派典礼カトリック教会など多数―で典礼語として使用されてきた。文字体系は、アラム文字から発展した独自のアルファベットであるシリア文字を使用し、主に3つの書体がある。エストランゲロと呼ばれる古典期の書体は、古典シリア語文学の黄金時代(4~7世紀)に使用され、その後、西(セルトー書体)と東(ネストリオス書体)の2方向に発展した。
古典シリア語では、宗教、哲学、科学など幅広い分野の著作が生み出された。また、イスラーム期の東地中海において古代ギリシア語からアラビア語への知識伝達の重要な媒体でもあり、古典シリア語翻訳者はアラビア哲学の黄金時代に重要な役割を果たした。
デジタル・シリア語コーパス
Digital Syriac Corpus(デジタル・シリア語コーパス: DSC)[1]は、古典シリア語テキストを収集、整理し、デジタル形式で利用可能にするリポジトリである。2004年にオックスフォード大学の David G.K. Taylor 氏とブリガム・ヤング大学の Kristian S. Heal 氏の共同研究として作成され、2018年5月に一般公開された。
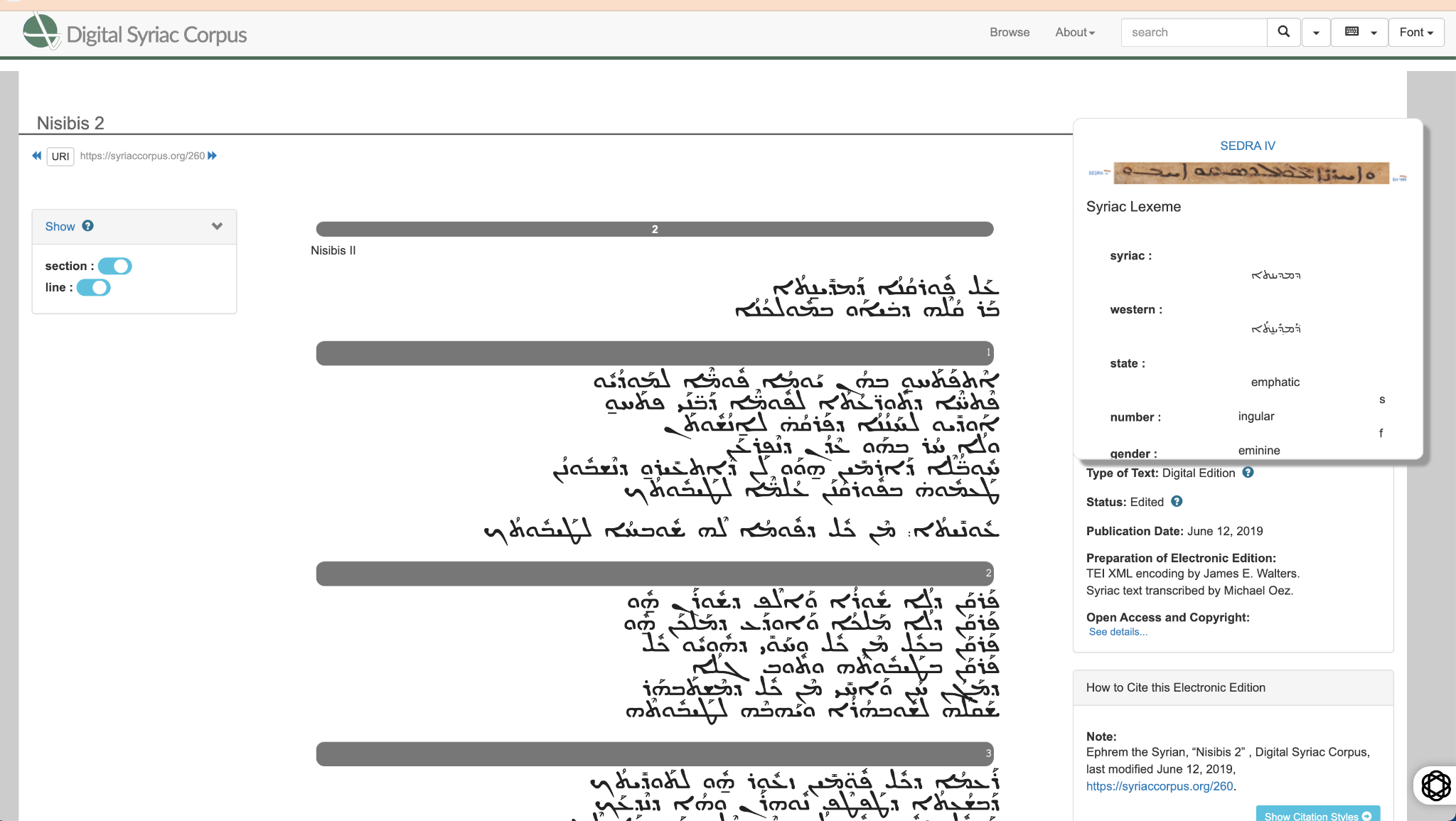
DSC の最大の特徴は、人文学資料の構造化の世界標準である Text Encoding Initiative(TEI)のガイドラインに沿った XML 形式を採用していることだ。これにより、テキストの学術的厳密性を維持しつつ、機械可読性と人間による可読性の両方が確保されている。
テキスト表示機能(図1)により、ユーザはエストランゲロ、西シリア語、東シリア語のスクリプトを切り替えることができ、これは現代のシリア語を用いるキリスト教徒コミュニティにとって重要なアクセシビリティ機能である。さらに、SEDRA 語彙データベース(後述)と連携し、単語をクリックするだけで、形態素情報や語義を表示する機能を提供している。
検索機能には、簡易検索と詳細検索があり、特に詳細検索では、著者、タイトル、日付範囲などの条件を指定できるほか、ワイルドカード検索や近接検索などの高度なテクニックも利用できます。これにより、大規模なシリア語テキストデータベースを新しい方法で分析することができる。
このコーパス内のすべてのタグ付きテキストは CC BY 4.0ライセンスで公開され、コードを含む TEI/XML ドキュメント(図2)は Github で利用可能だ 。このオープン性は、研究におけるデータの透明性と再現性というデジタル・ヒューマニティーズの中核的価値を体現している。

シリア語書誌情報の統合と知識ネットワークの構築
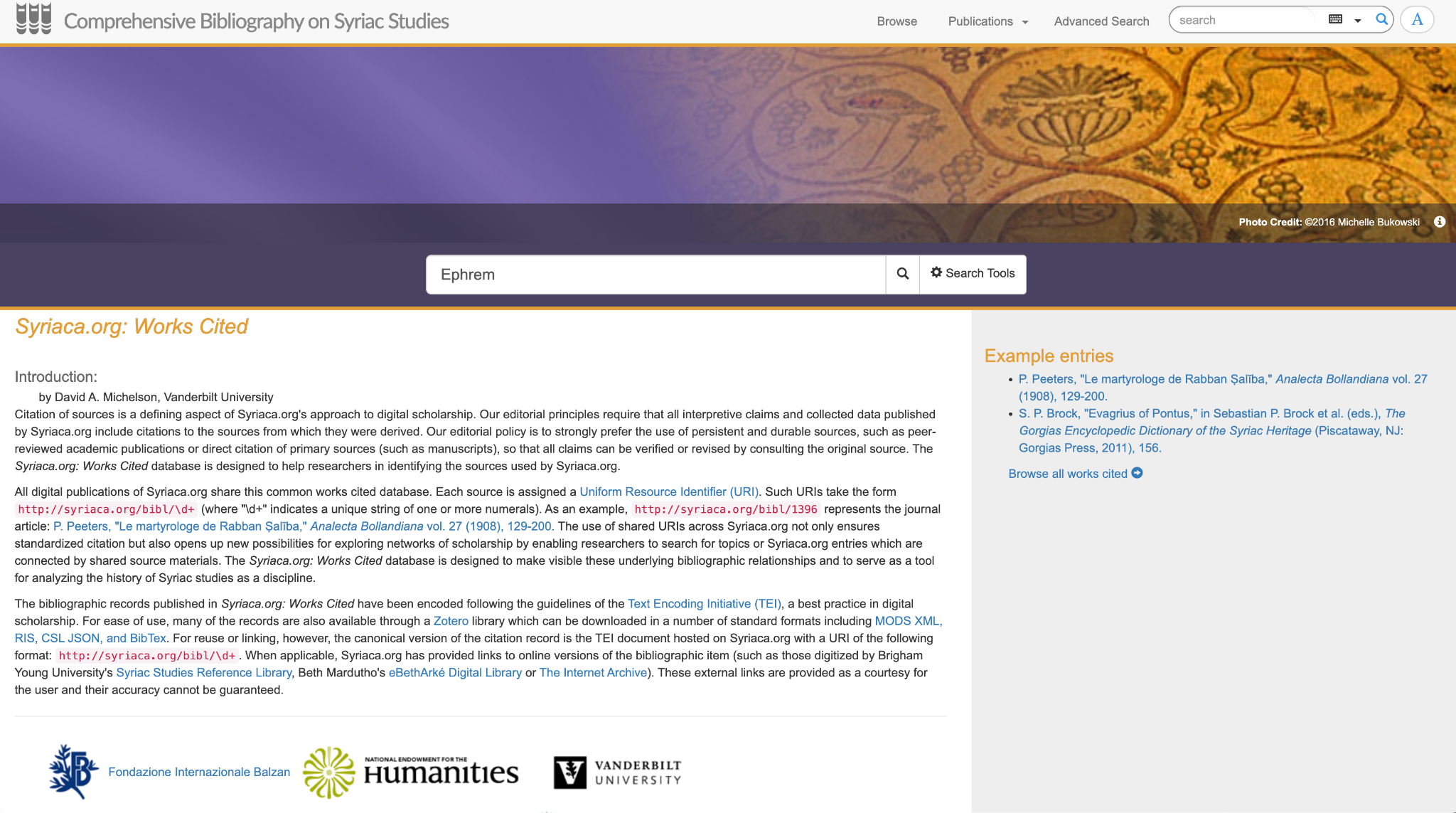
Comprehensive Bibliography on Syriac Studies(CBSS: シリア語研究総合文献目録)[2]は、古典シリア語のデジタルリソースのイニシアチブである Syriaca.org[3]の一部として開発されたシリア語研究に関する書誌情報の総合データベースであり(図3)、古典シリア語文献に関する学術論文、書籍、研究報告の書誌情報をリンクト・オープン・データ(Linked Open Data: LOD) に準じたフォーマットで提供している。
例えば、当データベースは、各引用文献に固有の永続的な識別子 URI(Uniform Resource Identifier)を割り当てている。この URI システムにより、Syriaca.org 上の他のリソースへのリンクが可能になり、シリア語研究における知識ネットワークの視覚化と研究が容易になる。
CBSS は TEI ガイドラインに従ってもエンコードされており、Zotero ライブラリとしても利用可能であるため、様々な標準フォーマットでデータをダウンロードすることができる。相互運用性を重視することで、異なるデジタルツール間でのデータ交換や統合を容易にしている。
技術・方法論的革新
CBSS を含む Syriaca.org のデータベースおよび DSC は、アイテム毎に相互に多数のリンクが張られており、ユーザは相互参照が可能である。これらのプロジェクトにおけるデジタル・ヒューマニティーズ(DH)的な重要点には、以下の4つがある。
第一に、Srophé[4]アプリケーションの開発と活用である。Srophé は、Winona Salesky によって開発されたアプリケーションで、TEI/XML でエンコードされたシリア語データの閲覧、検索、表示を可能にする。このアプリケーションは eXist-db データベースソフトウェアと連携して動作し、複雑な XML データを読みやすいウェブインターフェースとして表示する機能を提供している。Srophé の重要な特徴は、特定のプロジェクトだけでなく、様々なDHプロジェクトで再利用できるように設計されていることである。
第二に、永続的な識別子(URI)の体系的な採用である。これらのプロジェクトでは、すべてのリソース(テキスト、書誌情報、人物、場所など)に固有の URI が割り当てられている。これは、デジタル資源の長期的な安定性と参照可能性を確保するための重要な方法論的アプローチである。
第三に、相互運用性の重視である。TEI/XML といった世界標準の採用や、古典シリア語辞書ツール SEDRA[5]や文献管理ソフトウェア Zotero[6]など、外部のデジタルリソースとのリンクを容易にする機能を実装することで、DH における「コンパートメント化」の問題に対する解決策を提供している。
第四に、参加型研究モデルの採用である。DSC は研究者や一般読者からのテキスト訂正や新しいテキストの提供を積極的に奨励している。このオープンなモデルは、専門家以外にも門戸を広げ、より民主的で包括的な学問を促進するものである。
現在の課題と将来の展望
主な課題は、データの質の確保、形態素解析の不足、技術的な持続可能性などである。多くのテキストは「未修正の書き起こし」であり、質の向上には、自然言語処理および古典シリア語文献学のより多くの研究者の協力が必要である。
今後の展望としては、古典シリア語のための OCR(光学文字認識)・HTR(手書きテキスト認識)技術の精度向上によるデジタル化の加速、デジタル形式の批判校訂版の増加、AI と機械学習の統合、クラウドソーシングを含めた市民科学的アプローチの拡大などが挙げられる。これらの発展により、デジタル化を通したシリア語研究はさらに拡大・深化していくだろう。
おわりに
DSC と CBSS は、古典シリア語研究の分野におけるデジタル人文学的アプローチの成功例である。TEI/XML の採用、URI による永続的識別子、オープンライセンスの採用により、高度な検索機能を通じてシリア語研究の方法論を根本的にオープンな方向へ変えてきている。
これらのデジタルリソースは、学術研究だけでなく、古典シリア語を保存してきたキリスト教徒コミュニティにとっても、文化遺産を保存するための重要なツールである。異なる文字体系で表示することができるため、中東やインドの異なるシリア語の伝統に属するコミュニティからのアクセスも可能である。
全体として、これらのプロジェクトは、DH が伝統的な人文学研究をどのようにオープンな学問へと変革し、拡大できるかを示す優れた例であり、古典シリア語の文化遺産が現代のデジタル環境で活性化され、この貴重な言語的・文化的伝統を後世に残すことが期待される。デジタル化・オープン化を通して、この貴重な言語的・文化的伝統が将来の世代のために保存されることが望まれる。
《連載》「英米文学と DH」第3回
「データカプセルの利用方法」
データカプセル
前回の連載では、ハティトラストの関連組織の一つ、ハティトラスト・リサーチセンター(以下 HTRC)が提供するサービス概要について述べた[1]。今回はそれらのうち、データカプセルという名の、ハティトラストの電子テクストを用いてテクスト分析を行うことができるコンピュータ環境の使用方法について述べたい[2]。データカプセルは、仮想のサーバー環境であり、OS は Ubuntu を使用している。ユーザーはサーバー(つまり通常使用しているローカル PC のようなコンピュータ)にウェブブラウザからアクセスし、遠隔操作によりコンピュータを動かす。
ユーザー目線では、サーバーと通常の PC の違いは、サーバーはPCと異なり、多くの場合 UNIX の OS を操作するシェルと呼ばれるコマンドを入力することでコンピュータを操作することだろう。データカプセルには、ターミナル接続およびリモートデスクトップ接続の二つの接続方法が用意されている。ターミナル接続では、Windows や MacOS のターミナルアプリと同じく文字だけの画面でコマンドを入力して操作を行う。リモートデスクトップ接続では、ブラウザ上でウインドウズのような画面を出してマウスとキーボードを使って操作を行う。リモートデスクトップ接続の場合も、簡単なフォルダ操作やアプリの起動を除き、メインの操作はターミナルウインドウを出して行うコマンドの入力や、Jupyter Notebook や R といったプログラミング環境でのコードの入力による操作である。
UNIX のコマンドと聞くと抵抗感がある読者は多いかもしれない。だがよく使うコマンドは10種類もないし、上矢印キー(以前実行したコマンドを出す)とタブ(そこまでの入力に続く一つしかないディレクトリ名やファイル名を表示させる)という二つのターミナルの操作方法を覚えるとコマンドの入力の手間はかなり省ける。
データカプセルの構成
このデータカプセルは、ユーザーが自由に使えるオープンプラットフォームであるが、同時に著作権で保護されたデータを扱う環境でもある。そのため二つの異なる実行環境が存在する。メンテナンスモードと呼ばれるオープンネットワークの環境およびセキュアモードと呼ばれるクローズドネットワークの環境である(図1参照)。メンテナンスモードではインターネットが使用でき、必要なソフトウェアをダウンロードしたり、データをアップロードしたりできる。一方、セキュアモードではインターネット接続ができず、代わりにハティトラスト・デジタルライブラリ―のデータ資源とつながりダウンロード可能となる。ユーザーはセキュアモードのデータを外部にエクスポートできない。分析結果をダウンロードしたい場合は、特殊なリクエストを HTRC に送ることになる。このようにしてデータカプセルでは著作権で保護された電子テクストが流出しないように配慮している。なお利用できるデータは、会員の場合著作権で保護された電子テクストを含む1700万件、非会員の場合パブリックドメインの650万件とのことである[3]。
データカプセルではユーザーが自由に使えるディスク領域が割り当てられているが( /home/dcuser/[ユーザー名] )、メンテナンスモードとセキュアモードで扱いに注意する必要がある。セキュアモードに入るとき、おそらくメンテナンスモードのスナップショット、つまり実行環境のコピーが作られる。これは再びメンテナンスモードに戻るときに破棄される一方通行のコピーである。つまりメンテナンスモードに戻ると、あらゆるデータや実行環境は最後にメンテナンスモードを実行していた時の状態に戻る。セキュアモードで作成したプログラムや分析結果のデータは、保存場所に注意しないとメンテナンスモードに移行したときに消えてしまう。では分析結果などはどうしたらよいのかといえば、セキュアモード時のみ利用できるデータの保管場所( /media/secure_volume/ )があるため、重要なデータはこの保管場所に入れておくとよい。この保管場所のデータはメンテナンスモードに移ってもサーバーを再起動しても消えることはない。ただし前述のとおり、セキュアモードにおけるあらゆるデータは、メンテナンスモードでは利用することができない[4]。
![]()
データカプセル利用時にはじめにすること
最後に、データカプセルの利用前に一度のみ行うことについて述べる[5]。一度のみ必要な設定とは、ログイン認証、プロジェクトの作成、SSH の設定である。HTRC のウェブサイトへのログイン方法はログイン認証として連載の第1回で述べたとおりである。一点付け加えるとすれば、HTRC のウェブサイトの右上にある Sign in ボタンを押したときの Select Institution の画面で自分の所属する研究機関や大学名が見つけられないときは HTRC にリクエストを送るとよい[6]。
ログイン認証の次は、プロジェクトの作成を行う。ログインすると、右上の表示が自分のメールアドレスに変わる。ページ上の上部バーから Tools を選び、さらに Create a data capsule を選ぶと、利用したいデータカプセルの種類が表示される。デモカプセル、一般的な研究カプセル、カスタマイズした研究カプセルの三種類である。ここでは一般的な研究カプセルについてのみ述べる。ハードディスク100GB、メモリ20GB、仮想 CPU10個までのシステムを構成でき、結果のエクスポートや5人までの共同利用者の追加ができる。ただし18か月利用がないと消されてしまう。
一般的な研究カプセルを選ぶと、プロジェクトの申請画面が表示される。ここから行いたい研究を英語で説明して、HTRC からの承認が得られれば、プロジェクトが利用できることとなる。研究タイトル、研究内容、どんなデータをエクスポートするか、エクスポートしたデータをどのように使うかといったことを記述する。重要なのは、商用利用でないこと、著作権侵害となる恐れがないことを示すことであろう。申請後、HTRC のスタッフが審査をするので、数日待つことになる。
なお、安全にサーバーの遠隔操作を行う SSH の設定も可能である。プロジェクト利用開始後に、Tools から Data Capsules 内の My data capsule allocations を選択し、SSH パブリックキーを追加する旨のボタンを押すと設定できる。詳しくはチュートリアルを参照されたい[5]。次回はデータの準備や分析などの実例について述べる。
- コメントを投稿するにはログインしてください