人文情報学月報第171号
ISSN 2189-1621 / 2011年08月27日創刊
目次
- 《巻頭言》「フランスにおける DH の状況概観」
:フランス国立情報学・自動制御研究所 - 《連載》「欧州・中東デジタル・ヒューマニティーズ動向」第87回
「スペイン・ハエン大学チームによる古代エジプト語 UD(Universal Dependencies)ツリーバンクの公開と展開」
:筑波大学人文社会系 - 《連載》「英米文学と DH」第10回
「反対意見としての DH 批判・続」
:中央大学国際情報学部 - 人文情報学イベント関連カレンダー
- イベントレポート「CLARIAH-AT Summer School: Machine Learning for Digital Scholarly Editions」
:千葉大学大学院人文公共学府 - 編集後記
- 「デジタル研究基盤としての令和大蔵経の編纂―次世代人文学の研究基盤構築モデルの提示」ニューズレター第2号(本誌「特別付録」として隔月配信)
《巻頭言》「フランスにおける DH の状況概観」
フランスにおけるデジタル人文学(DH)の状況を特徴付けるのは、極めて中央集権的な組織である。それは、包括的で専門的なインフラ、大規模な国家的研究事業を中核とするものであり、またそれと相まって、長年にわたってオープンアクセスの政策に関与してきた。以下の概観は、不完全なものではあるが、フランスにおける DH 活用法の代表的な事例を提示することを企図するものである。
フランスのオープンサイエンス環境
フランスは長年にわたってオープンサイエンスを強力に支持してきた。この分野における国家の方針である二度の「オープンサイエンス国家計画」(2018~2021、2021~2024年)は、出版・研究データ・ソフトウェアの分野においてオープンサイエンスの企画を推進した。この政策を取りまとめるのは、高等教育・研究省および多様な関係機関によって代表される「オープンサイエンス委員会 (CoSO)」である。
「オープンサイエンス・モニター (https://frenchopensciencemonitor.esr.gouv.fr/)」は、フランスのオープンサイエンス政策の成果を反映させるものであり、フランスおよびその諸機関における出版物のオープン化率を追跡している。また、データセットやソフトウェアのオープン化についての知見をも提供する。
オープンサイエンスのためのインフラ
このオープンサイエンス計画の基盤となるのは、以下の3つの主要なインフラである。
- HAL:今から20年以上前に設立された国立の出版物リポジトリ。ここでは各組織が独自のポータルを持つことができる。
- Recherche Data Gouv:HAL と同様の理念に基づくものだが、研究データセットに特化している。2022年創設。
- Software Heritage:ソフトウェアのソースコードのための国際的なアーカイブ。
人文学のためのインフラ
人文学に特化した(デジタルの)サービスを、複数のインフラが長年にわたって提供してきた。なかでも言及すべきものに以下がある。
- OpenEdition:以下の4つのプラットフォームを運営する。
- OpenEdition Journals:学術雑誌(現在663誌)
- OpenEdition Books:学術書(現在15678冊)
- Calenda:学術イベント(59195件)
- Hypotheses:研究ブログ(5126サイト)
- Persée:既存の紙媒体の雑誌(多くは人文学分野)の電子化プラットフォーム。現在100万冊以上の文献を収録する。
- Huma-Num:国立の DH インフラ。データリポジトリ、研究者ネットワーク、基礎的なデジタルサービス(データストレージ、文書処理ツールなど)、人文学に特化したデジタルサービス(Le Sphinx, R shiny, MaxQDA, TXM, ArcGis, Stylo, Heurist)、人文学のための汎用検索エンジン(ISIDORE)など、多様なサービスを提供する。
これに加えて、いくつかの国家的方針によって、以下のような特定のインフラ環境が整備された。
- 人文仮想図書館 (BVH):フランスの DH における旗艦事業の一つ。トゥール大学に拠点を置き、ルネサンス期のテキストの保存・研究・公開を主眼とする。1990年代後半に創設された BVH は、文献学の専門性と電子化のテクノロジーとオープンアクセスの理念を統合した最初期の大規模なプロジェクトの一つである。BVH がオンラインアクセスを提供するのは、初期の印刷本や手稿であり、とりわけ15~16世紀の、文学、哲学、宗教、科学を網羅している。著名なコレクションには、フランソワ・ラブレーやミシェル・ド・モンテーニュのようなフランス・ルネサンスの作家による作品が含まれている。
- Biblissima:中世・ルネサンス期の書物文化遺産の研究・保存を主眼とする大規模な DH 事業。手稿や初期の印刷本、関連する学術リソースを結びつける統合デジタルインフラを提供する。Biblissima は、文化遺産コレクション、ツール、サービスへの一般的なアクセスのためのポータル (https://projet.biblissima.fr/fr/ressources/ressources-biblissima) を提供し、そこでは、IIIF や TEI といった国際標準への準拠が特に強調されている。
- eScriptorium:翻刻、注釈、手書き文字認識 (HTR) モデルのトレーニングのためのオープンソースのプラットフォーム。その核となる部分は、Kraken という強力な OCR/HTR エンジンに依拠しており、これによって多様な文字体系や複雑なページ構成に対してレイアウト解析や適応型モデルトレーニングが可能となる。
フランスと TEI
フランスは、TEI (Text Encoding Initiative) の発展と普及において重要かつ持続的な役割を果たしてきた。1990年代初頭以降、フランスの諸機関は TEI を、学術編集や言語学研究、文化遺産の保存のための不可欠なツールとして認識している。
主要な研究図書館、とりわけフランス国立図書館 (BnF) は、大規模な電子化やコーパスのプロジェクトに TEI をいち早く採用した。TEI は、BVH や Persée、OpenEdition や Huma-Num といった事業の中核となっている。これらの事業は、 TEI に根差したコード化のための実践の支援や学習機会の提供に加えて、TEI コンソーシアムのための複数のサービスを主宰している。フランスの研究者たちは、TEI コンソーシアムに、その設立当初から直接的に貢献してきた。
Humanistica:フランス語圏の DH 学会
Humanistica は、フランス語圏の DH 学会である。2014年に創設され、研究者、教員、開発者、学生など、人文社会科学におけるデジタル技術の使用に関心を持つ人々を広く集合させている。Humanistica は毎年、国際大会(2025年度のものは以下を参照。https://humanistica2025.sciencesconf.org/?lang=en)を組織しているほか、メーリングリストや会誌(Humanités numériques、2020年創刊)、ウェブサイトを通じて、情報の普及を支援している。また、国際 DH 学会連合 (ADHO) と密接な関係を保っている。
別の定期的な会議に、DH Nord (https://dhnord2025.sciencesconf.org/) がある。これも2014年に開始され、欧州人間社会科学館 (MESHS) および大学共同デジタル人文学研究センター (CRIHN) が共催している。
フランス人ないしフランスの研究機関と提携する DH 関連の著者による近年のリファレンスとして以下のものがある。
- Lou Burnard, Marjorie Burghart (tr.). Qu’est-ce que la Text Encoding Initiative ?. OpenEdition Press, 2015. (halshs-01984317)
- Jack Bowers, Axel Herold, Laurent Romary, Toma Tasovac. TEI Lex-0 Etym - towards terse recommendations for the encoding of etymological information. Journal of the Text Encoding Initiative, 2022, (10.4000/jtei.4300). (hal-03108781v2)
- Marjorie Burghart, “The TEI Critical Apparatus Toolbox: Empowering Textual Scholars through Display, Control, and Comparison Features”, Journal of the Text Encoding Initiative [Online], Issue 10 | December 2016 - July 2019, Online since 07 December 2016, connection on 13 September 2025. URL: http://journals.openedition.org/jtei/1520; DOI: https://doi.org/10.4000/jtei.1520
- Hugo Scheithauer, Alix Chagué and Laurent Romary, “Which TEI Representation for the Output of Automatic Transcriptions and Their Metadata? An Illustrated Proposition”, Journal of the Text Encoding Initiative [Online], Issue 15 | 2024, Online since 26 February 2025, connection on 13 September 2025. URL: http://journals.openedition.org/jtei/5194; DOI: https://doi.org/10.4000/13e5a
- Peter Anthony Stokes, Benjamin Kiessling, Daniel Stökl Ben Ezra, Robin Tissot, El Hassane Gargem. The eScriptorium VRE for Manuscript Cultures. Classics@, 2021, 18 (1), https://classics-at.chs.harvard.edu/classics18-stokes-kiessling-stokl-ben-ezra-tissot-gargem/. (hal-03991423)
執筆者プロフィール
《連載》「欧州・中東デジタル・ヒューマニティーズ動向」第87回
「スペイン・ハエン大学チームによる古代エジプト語 UD(Universal Dependencies)ツリーバンクの公開と展開」
Universal Dependencies とは何か
Universal Dependencies(UD)とは、世界中の言語を統一的な枠組みで分析するための国際的なプロジェクトである。言語の文法構造を、普遍品詞(UPOS; 名詞、動詞など)と単語間の普遍依存関係(DepRel; 主語、目的語など)という共通の基準で記述することで、異なる言語間での言語構造の定量的比較研究や、自動解析などの自然言語処理技術の開発を可能にする。現在150以上の言語で、合計200以上のツリーバンク(文法解析済みコーパス)が公開されている[1]。
この UD の枠組みに、2024年、ついにコプト語以前のエジプト語の1つである古エジプト語が加わった。これですでに2016年から公開されているコプト語(エジプト語の最終段階)と、古エジプト語(エジプト語の初期段階)の数千年間の統語変化を定量的に解析可能にする大枠ができあがった。
エジプト語5000年の歴史と UD 化の現状
エジプト語は、人類史上最も長い文字記録を持つ言語の1つである。紀元前3200年頃の原ヒエログリフによる文字の筆記から、現代のコプト正教会で使用される典礼言語まで、約5000年間の書記の歴史を持つ。大きく6つの段階に分けられる(併用期間の重なりあり):
- 先古エジプト語(紀元前3200–2700年頃):単純な語句のみが書かれ、文法はわからない。
- 古エジプト語(紀元前2700–2000年頃):文法が分かる、文以上の多様なテキストを持つ最初の段階。ピラミッド・テキストなど、最古の葬祭文学を持つ。
- 中エジプト語(紀元前2300年頃–紀元後394年8月24日):「古典エジプト語」とも呼ばれ、『シヌヘの物語』などの古代エジプト語文学の黄金期の言語。その後も長きにわたって、公式文書や宗教文書など様々な場面で使用された。ヒエログリフ(聖刻文字)とヒエラティックで書かれた多くの文献がこの言語で書かれている。ロゼッタストーンの3言語の1つ。通常エジプトの遺跡で見るヒエログリフ文の多くがこの言語を用いている。
- 新エジプト語(紀元前1400–600年頃):日常語が書記言語に反映されるようになった段階。迂言法・分析的な表現が増加。
これら古・中・新エジプト語はヒエログリフとヒエラティックの2つの文字を用いている。
- 民衆文字エジプト語(紀元前800年頃–紀元後452年12月12日):デモティックという文字で書かれ、契約書や裁判記録や教訓文学や物語文学などに使用。ロゼッタストーンの3言語の一つ。
- コプト語(紀元後3世紀頃から現代):ギリシア文字にデモティック数文字を追加したコプト文字で表記。日常言語としては遅くとも17世紀までに衰退したが、コプト正教会の典礼言語、そして言語復興運動の言語として現代まで使用されている。
この5000年の言語史に対して、UD 形式でデジタル化されているのは、現時点で最古層の古エジプト語と最新層のコプト語のみである。古代エジプト文明の大部分にあたる中間の約3000年間(中エジプト語、新エジプト語、民衆文字エジプト語)は UD 化されていない。
UD_Egyptian-UJaen ツリーバンク
2024年5月、スペインのハエン大学の Roberto Antonio Díaz Hernández 氏が率いるチームが公開した UD_Egyptian-UJaen(EUJA)は、古エジプト語を UD の枠組みで分析した世界初のツリーバンクである(図1はその視覚化の一部)。初版では707文・5,515語だったが、わずか1年で2,181文・21,243トークンまで拡充された(2025年5月現在)[2]。本ツリーバンクの主な資料源は、サッカラのピラミッド群のいくつかの内部に刻まれた呪文集で、世界最古の葬祭文学とされる「ピラミッド・テキスト」である。これは古王国時代第5王朝最後の王ウナス(紀元前2375–2345年頃)のピラミッド内部の壁面に刻まれたもの(図2)が最初で、第6王朝の4人の王と5人の王妃のそれぞれのピラミッドの内部壁面に刻まれ、最後に第1中間期第8王朝カカラー・イビィ王のピラミッド内部に刻まれた。
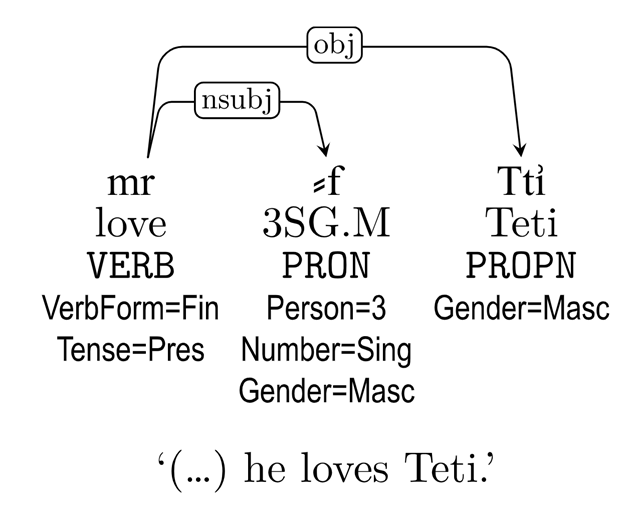

古エジプト語のピラミッド・テキストはヒエログリフで書かれている。ヒエログリフは神、人、動物、植物、建造物など多数の象形文字からなり、これらを表音文字(主に子音)、表意文字、限定符(意味分類記号)として組み合わせて単語を表記する。しかし、ヒエログリフの Unicode 化は配置のための制御文字や追加の文字の整備によって進展しているものの、複雑な文字配置や未収録文字の問題により、完全な表現は困難である。そこでEUJAは、ラテン文字音写を主とし、補助的に Unicode ヒエログリフと MdC(Manuel de Codage)記法を併用する方式を採用した(図3)。音写方式としては、一般的な英国式や大陸式やライデン統一転写(LUT)ではなく、音韻論的により精密な「テュービンゲン式転写」[4]を選択した

コプト語 UD との連携
既存のコプト語 UD(UD_Coptic-Scriptorium)[6]は、コプト語最大の多層タグ付きコーパスである Coptic SCRIPTORIUM[7]の開発チームによって開発されており、2,203文・26,837トークンの規模を持つ。主に聖書、説教、聖人伝などの宗教文書からなり、サイード方言に加えて2025年にはボハイラ方言版も追加された[8]。古エジプト語とコプト語の UD を比較することで、4000年間の言語変化を定量的に分析できる。例えば、語順の変化、動詞活用の簡略化、前置詞や小辞の増加などが、具体的な数値として検証可能になる。
コプト語 UD と同じく、EUJA の古エジプト語 UD データは、クリエイティブ・コモンズ・ライセンス(CC BY-SA 4.0)で公開されており、研究・教育目的で自由に利用できる。UD 公式サイトからダウンロード可能で、オンライン検索システム(PML-TQ)で特定の文法現象を含む例文を即座に検索できる。自動解析の精度も実用レベルに達しており、品詞タグ付けで90.3%、構文解析の LAS(Labeled Attachment Score)で71.97%の正解率が報告されている[9]。また、PARSEME(多語表現解析)プロジェクトとの連携も2025年から開始され、身体部位を含む慣用表現の体系的な分析が進められている[10]。
今後の計画として、まず古王国・第1中間期の伝記文献の追加が予定されている。次に中エジプト語への拡張が計画されており、2千年以上にわたって古典語として使用された豊富な文学・宗教・行政文書の UD 化が期待される。
古代エジプト語 UD の可能性
EUJA プロジェクトは、約4300–4100年前の古エジプト語のピラミッド・テキストを現代のデジタル技術で分析可能にするという、人文学とデジタル技術の理想的な融合例である。従来、古代語研究は少数の専門家による精読と解釈が中心だったが、大規模デジタルコーパスの整備により、統計的分析、機械学習による自動解析、異なる言語・時代との体系的比較など、新たな研究の地平が開かれつつある。
現在のエジプト語 UD は、最古層と最新層のみが整備され、中間の2000年間が空白という特異な状況にある。しかし、この空白が埋められれば、5000年という人類史上最長の言語変化の記録を、統一的な枠組みで分析できるようになる。それは言語学のみならず、文化史、宗教史、社会史研究にも新たな視座をもたらすだろう。エジプト学、言語類型論、計算言語学の交差点に立つ EUJA は、デジタル・ヒューマニティーズの可能性を示す好例と言えるだろう。
《連載》「英米文学と DH」第10回
「反対意見としての DH 批判・続」
前回の連載では、DH 批判の具体例として、2010年代の社会的、時代的な背景から生じたと思われる批判を取り上げた。今回は、文学の立場からの批判、特にスタンリー・フィッシュの DH 批判を取り上げたい。
文学の側からの批判
著名なミルトン学者であり、法学者であり、解釈共同体の文学理論で知られるスタンリー・フィッシュは、DH 批判者としても有名である。現在はカードーゾ・ロースクールでフローシャイマー特別客員法学教授を務めている。デューク大学英文学科長在任時、それまで無名であったデューク大学の知名度を高名な学者を集めることで一気に高めたといった大学運営の手腕により知的企業家としても知られている[1]。
フィッシュの著作の書評を書いたジョン・マランによれば、フィッシュの議論の本質は知的遊戯でありフィッシュは論争を好む懐疑論者であるが[1]、彼の DH に対する批判は前回の連載で指摘した「1.DH 研究の結果と方法論に対する懐疑」が主である。DH はすでに知っていることを明らかにする研究であり、無意味な問題設定は無意味な結果を生み出すのみという論旨に主に依拠する[4][5]。『ニューヨーク・タイムズ』誌に載せた一連の DH 批判ブログでは、DH は文学研究に侵入した「異質な侵略者」[2]であり、グローバル資本主義のヘゲモニーに対抗する左派であって、文学に言及せずに語ることができる学問であるとする[3]。フィッシュにとって、文学研究者による文学研究は、初めに解釈上の仮説から出発し、形式的なパターンを導くことで分析を行う。一方 DH は初めに形式的なパターンを導きそこから解釈仮説を促す方向をとるため、研究者はいったい自分が何を探しているかがわかっていないと批判する。また一部に DH は文学を救う少数精鋭部隊であるかのような論調がみられるが、実際は文学研究が行ってきたことを別の形で同じように行っているだけであると批判する。17世紀イギリスにおいてチャールズ一世率いるエピスコパル派の司教(bishops)が言論統制を行ったことに対し、敵対する議会派が批判したが、その議会派が勢力を握ると議会派の長老(presbyters)は同じように言論統制をはじめ、b を p にひっくり返しただけの結果となった。DH と文学の関係はこれと同じではないかという修辞的比喩を用いた批判である[4]。
フィッシュの立場は「DH がどのようなヴィジョンを持とうと私や私の行う文学批評のような場所には居場所はない」[4]と、DH を一貫して文学研究とは認めないというものであるが、フィッシュの DH 批判は次の二つに注意する必要があるだろう。ひとつは、フィッシュの議論は初めに答えを決めている遊戯であって、出発点が違えば180度異なる議論をしているだろうということである。白が黒になっているかもしれない。もう一つは、フィッシュ自体現在の大規模言語モデルの考え方に近い読者反応の文学理論をかつて提唱していたことである。1972年の『感情的文体論』のなかでフィッシュは読者反応の発展的分析を提唱する。
ある行または文の五番目の語に対する読者の反応は、ある程度、読者が一番目、二番目、三番目、四番目の語に行った反応の産物である。....反応のカテゴリーには、一連の語によって引き起こされるあらゆる活動が含まれる:文法・語彙の確率の予測、その後の発生または非発生などである...分析者は、読書体験の任意の一瞬において、前の瞬間に(読者の頭の中で)起こったあらゆることを考慮に入れねばならず、また各瞬間についてもその各瞬間以前に生じ蓄積された圧力にさらされていることも考える必要がある[6]。
あたかも自然言語処理の教科書を読んでいるかのような分析手法の提案である。フィッシュはもう少し進んで、自然言語処理で前提とされる分布意味論[7][8]に異論を唱えようとしているようにさえみえる。フィッシュ自身はDHを認めていないが、フィッシュが行っていることはDHときわめて関連があるようである。pをひっくり返してもbになりうるということだろうか。
今回は文学の側からの批判を取り上げた。次回は統計・方法論に対する批判を取り上げたい。
人文情報学イベント関連カレンダー
【2025年11月】
-
2025-11-4 (Tue), 13 (Thu), 18 (Tue), 27 (Thu)
TEI 研究会於・オンライン -
2025-11-11 (Tue) ~ 2025-11-17 (Mon)
27th ICOM General Conference 2025https://dubai2025.icom.museum/
於・Dubai World Trade Centre -
2025-11-29 (Sat) ~ 2025-11-30 (Sun)
第十六屆數位典藏與數位人文國際研討會https://dadh2025.digital.ntu.edu.tw/
於・國立臺灣大學
【2025年12月】
-
2025-12-2 (Tue), 11 (Thu), 16 (Tue), 25 (Thu), 30 (Tue)
TEI 研究会於・オンライン -
2025-12-11 (Thu)
国文研 DDH プロジェクト第1回国際研究集会「古典テキストの最前線―夢の書庫を開く―」https://www.nijl.ac.jp/event-info/2025ddh_1_conference/
於・国文学研究資料館2階大会議室およびオンライン -
2025-12-13 (Sat) ~ 2025-12-14 (Sun)
じんもんこん2025https://jinmoncom.jp/sympo2025/index.html
於・九州大学伊都キャンパス
【2026年1月】
-
2026-1-8 (Thu), 13 (Tue), 22 (Thu), 27 (Tue)
TEI 研究会於・オンライン
Digital Humanities Events カレンダー共同編集人
イベントレポート「CLARIAH-AT Summer School: Machine Learning for Digital Scholarly Editions」
1. はじめに
報告者は、2025年9月8日から12日にかけて、オーストリア・グラーツ大学にて開催された CLARIAH-AT[1]主催の Digital Humanities(以下、DH)に関するサマースクール[2]に参加した。CLARIAH-ATは、オーストリアにおける DH の研究組織であり、CLARIN-ERIC[3]や DARIAH-EU[4]といった欧州の DH 研究インフラ[i]のオーストリアでの活動推進を担っている。
本サマースクールは、デジタル学術編集と機械学習を架橋することを目指し、BERTopic の解析パイプラインを学習することを主題として開催された。グラーツ大学の Department of Digital Humanities が開催し、オーストリアだけでなくヨーロッパ各国から DH 分野の研究者や学生が集った。プログラミング実習や理論的講義、ディスカッション、基調講演等を通じて、BERTopic[5][6]に関する一連の解析手法を網羅的に学習し、人文学研究での応用事例や論点についても提示がなされた。
2. 学習内容とその意義
演習では、まず Python プログラミングの基礎や Word2vec や TF-IDF といった自然言語処理の基礎を踏まえつつ、BERTopic の解析パイプラインを学習した。BERTopic の解析パイプラインについては、Sentence-BERT による埋め込み(embedding)、次元削減、クラスタリング、c-TF-IDF といったアルゴリズム群を体系的に学習した。特に、次元削減およびクラスタリングについては、行列の計算やベクトル間の距離算出など数学的理論を踏まえつつ、次元削減については PCA、t-SNE、UMAP を、クラスタリングについては K-means と HDBSCAN が取り扱われた。加えて、いずれのアルゴリズムの実験においても、モデルやパラメータを自由に調整しながらそれぞれの挙動を比較することが求められた。これらを通じて、単なるツール操作の習得にとどまらず、研究目的やデータ特性に応じて自ら解析パイプラインを設計・最適化する実践的スキルを獲得できた。加えて、最終日の実験では、参加者が自らの研究データを解析実験に用いることが推奨され、報告者も自身の研究活動で用いている行政の会議議事録のテキストデータを解析に用いることとした。このことを通じて、得られたトピックの解釈や命名には人文学的な文脈理解が不可欠であり、機械処理と人手による解釈の往還が極めて重要であることを再認識した。
また、応用事例やディスカッションにおいては、BERTopic など機械学習を用いたテキスト解析をデジタル学術編集の営みとして再評価する議論が印象的であった。従来の TEI などを通じたデジタル学術編集は、注釈付与や多言語比較によりテキストの詳細な解釈を明示するのに対し、機械学習によるテキスト解析は、機械処理によりテキストの構造を俯瞰的に抽出し提示する。つまり、デジタル学術編集が精読を支援するのに対し、機械学習は遠読を支援するなど、テキスト理解におけるアプローチの主たる方向性が異なっている。しかしながら、本サマースクールでは、今回のトピックモデリングを機械処理による解釈の営みであると捉えることでデジタル学術編集の営みとして位置付けることが打ち出された。実際に人文学テキストを用いた研究事例紹介では、BERTopic によるトピックモデリングの結果を TEI に記述することが説明された。具体的には、<teiHeader> タグに解析パイプラインの情報を付与しつつ、TEI テキストには割り当てたトピック分類を @ana 属性に付与することで、機械処理による解釈を TEI に記述するというものである。また、最終日に行われた Ulrike Henny-Krahmer 氏の基調講演では、トピックモデリングの解析パイプラインを TEI 上でどのように記述できるかについても詳細に説明された。具体的には、<teiHeader> 内の <encodingDesc> タグに <classDecl> を設けて <taxonomy> タグを活用し、この <taxonomy> 要素の下位に解析過程の詳細を記す <desc> タグと、トピック分類の情報を整理する <category> タグを配置する構造が提案された。このような記述をおこなうことで、従来のデジタル学術編集による精読の解釈と機械処理による遠読の解釈を同時に TEI XML 上に表現でき、両者を統合し相互補完するデジタル学術編集を目指すことが可能となる。この視点は、TEI が単に人手によるテキストの解釈や構造把握を記述するものにとどまらず、機械処理による解析過程や機械の解釈そのものを記録・共有するものへと拡張する可能性が示唆している。
このように、本サマースクールからは、人文学テキストに対する人手の解釈や編集と機械処理による解析を融合する新たなデジタル学術編集の知見を得ることができた。本サマースクールで得られたこうした知見を踏まえて、報告者は自らの研究活動においても、精読による精緻なアノテーションと機械処理による解析をデジタル学術編集の内部で統合的に扱っていくことを通じて、DH における新たな研究コンテキストの創出に寄与することを目指す。
[謝辞]
本サマースクールには、JST 次世代研究者挑戦的研究プログラム JPMJSP2109 の支援を受けて参加しています。加えて、本サマースクールは宮川創先生(筑波大学)よりご紹介を頂きました。さらに、応募書類の作成の際には、永崎研宣先生(慶應義塾大学)、大向一輝先生(東京大学)、小風尚樹先生(人間文化研究機構)より貴重なご助言を賜りました。この場をお借りして厚く御礼を申し上げます。
[注記]
[参考文献]
◆編集後記
今月も、「研究データエコシステム構築事業シンポジウム2025 (https://www.rdes.rcos.nii.ac.jp)」や「科学研究費学術変革領域「歴史情報学の創成」キックオフ 基盤研究S「史料データセンシングに基づく日本列島記憶継承モデルの確立」合同シンポジウム(https://dighis.rekihaku.ac.jp/20251017kickoff/)(以下、合同シンポ)」など、大がかりなプロジェクトによる DH 関連のイベントが開催されました。また、それ以外にも中小様々なイベントがあったようです。
特に、合同シンポについては、昨年度と今年度に開始された科研費による大規模な研究プロジェクトによるものであり、いよいよ歴史学にデジタル技術を応用していく流れが本格化しつつあることを感じさせるものでした。デジタル技術の応用と言っても、対象となる史資料の分量や様態によって応用の仕方がかなり変わってくるものであり、文字資料が残っているがかなり古い時代を対象とする場合には、ある程度限られた分量の情報を対象として丁寧にデジタル技術を応用し、精読(Close reading)を補助するような使い方になる傾向が高い。一方で、時代が下ってくると文字資料が大量に残っており、この場合にはそれらを対象とした遠読(Distant reading)のような技術の活用が有効になりやすい。今月に開催された「DH セミナー 人文学における数量的手法に関する セミナー(https://sites.google.com/view/dhseminar2025-10/)」では、クレール・ルメルシエ、クレール・ザルク著(長野壮一訳)『人文学のための計量分析入門――歴史を数量化する』(人文書院、2025年)を手がかりとしてそのような議論も行なわれていました。いずれの場合にも、だからといって精読や遠読をおろそかにしてよいというわけではありませんが、資料の状況を踏まえた様々な応用の仕方があり得るという点は、DH においても重要なテーマの一つです。このあたりは、生成 AI の精度の問題とも関わってきますが、デジタル技術にそれほど詳しくなくとも議論に参加しやすいところの一つかと思いますので、色々な立場からの議論があるとより面白くなるだろうと思っております。(永崎研宣)
- コメントを投稿するにはログインしてください