人文情報学月報第168号
ISSN 2189-1621 / 2011年08月27日創刊
目次
- 《巻頭言》「統計と言語の接点を求めて:コーパス消費者から生産者へ」
:慶應義塾湘南藤沢キャンパス環境情報学部 - 《連載》「欧州・中東デジタル・ヒューマニティーズ動向」第84回
「楔形文字粘土板文献デジタル化 DH プロジェクトの諸動向」
:筑波大学人文社会系 - 《連載》「英米文学と DH」第7回
「DH における英米文学研究と DH 批評」
:中央大学国際情報学部 - 人文情報学イベント関連カレンダー
- 編集後記
《巻頭言》「統計と言語の接点を求めて:コーパス消費者から生産者へ」
2025年度4月より、慶應義塾大学湘南藤沢キャンパス 環境情報学部/政策・メディア研究科に着任いたしました、山田彬尭(Akitaka Yamada, he/him)と申します。私は、理論言語学と定量的テキスト分析を融合させる研究を行っている研究者で、大阪大学人文学研究科(旧・言語文化研究科)の勤務を経て、現所属へ異動となりました。
これまでは、阪大の優秀な同僚の先生方に支えていただきながら、研究科再編に伴う重点施策の一つであった「デジタル・ヒューマニティーズ講座」の設置・拡充に、微力ながら貢献させていただく一方、研究面では、デジタル・ヒューマニティーズ的視点を取り入れた言語学の実践的研究を推進しておりました。
そうお話しすると、「ああ、コーパス言語学ね」と思われる方もいらっしゃるかもしれません。確かに間違ってはいないのですが、最近では、自分から進んで「コーパス言語学者です」と名乗ることは少なくなりました。というのも、「コーパス言語学」は非常に多様な研究手法を包摂する概念であり、多くの研究者がその名を肩書として掲げています。そのため、単に「コーパス言語学」と言うだけでは、自分がどういった研究をしているのかが伝わりにくいと感じるようになったのです。とはいえ、それに代わるぴったりの名称があるわけでもないので、少し説明が長くなることを承知のうえで、自己紹介の際には「主にベイズ推論に基づく統計的手法と、定性的な言語理論の融合を目指しています」とお話しするようにしています。
この「融合」という言葉には、二つの意味があります。
一つ目は、理論言語学の枠組みと統計的推論の融合です。理論言語学は伝統的に、音声学・音韻論・形態論・統語論・意味論・語用論の六領域に分類されます。このうち語用論は、談話における命題と命題のつながりが、論理的な意味を超えてどのように推論されるかをモデル化する領域です。古典的には、集合論に基づく可能世界の操作や、感情を反映した実数値の更新などによって談話効果がモデル化されてきました。
しかし私は、発話によって文脈が更新されるというメカニズム自体が、ベイズ統計における「事前分布がデータにより事後分布へと更新される」というモデルと極めて高い親和性をもつことを指摘し、その視点から理論を発展させ、成果をまとめたものが、私の博士論文でございました。
二つ目は、ベイズ推論を手法としてコーパス分析に適用するという意味での融合です。
私が大学生だったころ、ベイズ統計といえば、当時まだ懐かしいWinBUGSを使って分析を行うというものでした。今のようにハンズオン形式で学べるベイズ統計の授業も少なく、積分を含む長い数式を変形して、「共役事前分布は見つかりましたか?」「条件付き事後分布は既知の形ですか?」(ギブスサンプラーを前提として)といった問いに、なかなか「Yes」と答えられず、隣の友人に「どこで計算ミスしてると思う?」と助けを求めながら、必死に食らいついていく――そんな風景の中でこの道に入りました。ようやく手応えを感じられるようになった頃、Stan によるハミルトニアン・モンテカルロ法が登場し、「なんて便利な時代になったのだろう」と驚嘆したのを今でも覚えています。ちょうど博士論文を書き上げた頃のことです。
その後、2020年に阪大に着任しましたが、コロナ禍により全面オンライン化され、家にぽつんと取り残されたような空虚さを埋めるかのように、Stan を回しながら、「このツールを使って、これまで手が届かなかったリサーチクエスチョンに挑んでみよう」と、日々模索していたのを思い出します。言語学の研究課題は、統計モデルにそのまま翻訳するには難しいものが多く、変量効果や時系列的要素など、複雑な潜在変数が絡みます。そのため、t検定やカイ二乗検定といった単純な統計モデルには収まりません。しかし、Stan は、複雑なモデルでも(収束さえすれば)確実に結果を返してくれる頼もしさがあり、熱中していきました。ありがたいことに、多くの現象に対して研究成果を挙げることができ、特に、こうした統計モデルを、非常に定性的な言語理論である「分散形態論」の枠組みに応用した論文が、2023年春に国際誌に掲載されたことは、自分にとって大きな転機となりました
ベイズ統計モデリングが、通時言語学の課題解決に有効であることも示し、 一里塚を見たという意味でも転機ではありました。ただし、同時に新たな問いが自分の中に巣くってきたのを感じました。統計モデルに関しては一定の手応えを感じられるようになってきた今、次にどのような新規性を追求するべきか―。ちょうど30代前半が終わる時期、この問いは長く自分を縛り続けました。「さて、自分よ、次はどうする?」
そんな折、2024年2月、秋冬学期の採点を終えた翌日だったと記憶していますが、神戸大学の石川慎一郎先生によるワークショップに、聴衆として参加しました。多様なコーパスをご紹介される中で、特に印象的だったのが、学生の皆さんを含む多くの方々が研究基盤として活用していた「JASWRIC」――小中高大生による日本語の絵描写ストーリーを集めたコーパスでした。
この優れたプラットフォームを眺めているうちに、「あ、これは通時言語学と同じデータ構造だ」と、ふと、これまでの自分の研究と目の前のデータが重なる瞬間がありました。それだけではありません。通時コーパスと比べて、学習者コーパスには大きな強みがあります。それは、(きちんと設計していることで)データが統制されているということです。統制されたデータであれば、より強い推論が可能となり、理論言語学への貢献度も高まります。
実際、JASWRIC を用いて「適用形」の発達過程を解析したところ、非常に興味深い傾向が浮かび上がりました。この研究成果を発表できた2024年9月――ちょうど30代後半に差しかかる時期でしたが、「自分のこれからの研究は何か?」という長年の問いに、自然と答えが導かれたような、不思議な感覚がありました。であれば、JASWRIC と類似した新たなコーパスを、それもより理論言語学的な視点が意識されたコーパスを作成したいという思いを抱くようになりました。もう一つおまけに、ベイズ統計モデリングを用いた解析がしやすくなるように設計されたコーパスです。統計解析の視点から、コーパスと言語理論のインターフェースを模索してきた自分だからこそ見えるものがあるという、確かな手応えがありました。
その意志が固まったタイミングで、2025年4月、このたび、慶應義塾へ異動となりました。この構想をもとに学内の研究助成金の申請が通り、倫理審査についても何とかGOサインが出た今、カレンダーを見ると気がつけば、もう春学期が終わっていきます。
「解析者」――すなわち、コーパスの“消費者”から、「作成者」――つまり、コーパスの“生産者”へと、自身の立ち位置が大きく変わることになります。この変化を楽しみつつ、これまで出会った、そしてこれから出会うDHの先達たちから多くを学びながら、新たな研究の地平を目指していきたいと考えています。色々な研究会やワークショップ、学会などで、お会いできました際には、どうぞよろしくお願いいたします。
執筆者プロフィール
《連載》「欧州・中東デジタル・ヒューマニティーズ動向」第84回
「楔形文字粘土板文献デジタル化 DH プロジェクトの諸動向」
紀元前3350年頃から使用された楔形文字は、人類最古の体系的文字記録として、古代メソポタミア文明の社会、経済、法律、文学、科学のあらゆる側面を現代に伝える貴重な資料群である。世界中の博物館や個人コレクションに散在する楔形文字粘土板は推定50万から200万点に及ぶが、専門家による解読・出版は一部に留まっている。さらに、楔形文字を用いた言語は、シュメール語、アッカド語、エラム語、ヒッタイト語、フリ語、ウラルトゥ語など様々な言語であり、流暢に読解できる研究者は世界でも限られている中で、膨大な未読テキストが研究を待っている状況にある。本稿では、この状況を打破すべく展開されている楔形文字デジタル化プロジェクトの最新動向を概観し、人文情報学における意義と課題を考察する。
楔形文字デジタル化の中核を担うのが、UCLA とマックス・プランク科学史研究所が主導する Cuneiform Digital Library Initiative(CDLI)[1]である。2000年に開始された本プロジェクトは、現在までに約32万点以上の粘土板をデジタル化し、完全オープンアクセスのオンラインライブラリを構築している。

CDLI の革新性は、単なるデジタル画像の公開に留まらない。各粘土板には永続的識別子(P 番号)が付与され、高解像度画像、専門家による翻字(楔形文字のラテン文字転写)、出土地・年代等のメタデータが統合的に管理されている。特筆すべきは、市民科学(Citizen Science)の手法を導入し、登録ユーザーが翻字の入力・修正作業に参加できるクラウドソーシング・プラットフォームを実装した点である。これにより、専門家と市民が協働して巨大なデジタルライブラリの構築に貢献する、新たな研究パラダイムが確立された。
ペンシルベニア大学が中心となって推進する Open Richly Annotated Cuneiform Corpus(Oracc)[3]は、テキストに深層的な言語学的アノテーションを付与することに特化したプロジェクトである。レンマ化(lemmatization)、品詞タグ付け(POS tagging)、統語解析(syntactic parsing)といった言語学的情報の付与により、コンピュータによる高度な言語分析が可能となった。Oracc の L2 lemmatizer は、訓練データ量に応じて高い精度の形態素解析を達成しており、古代語処理における重要な技術的マイルストーンとなっている。

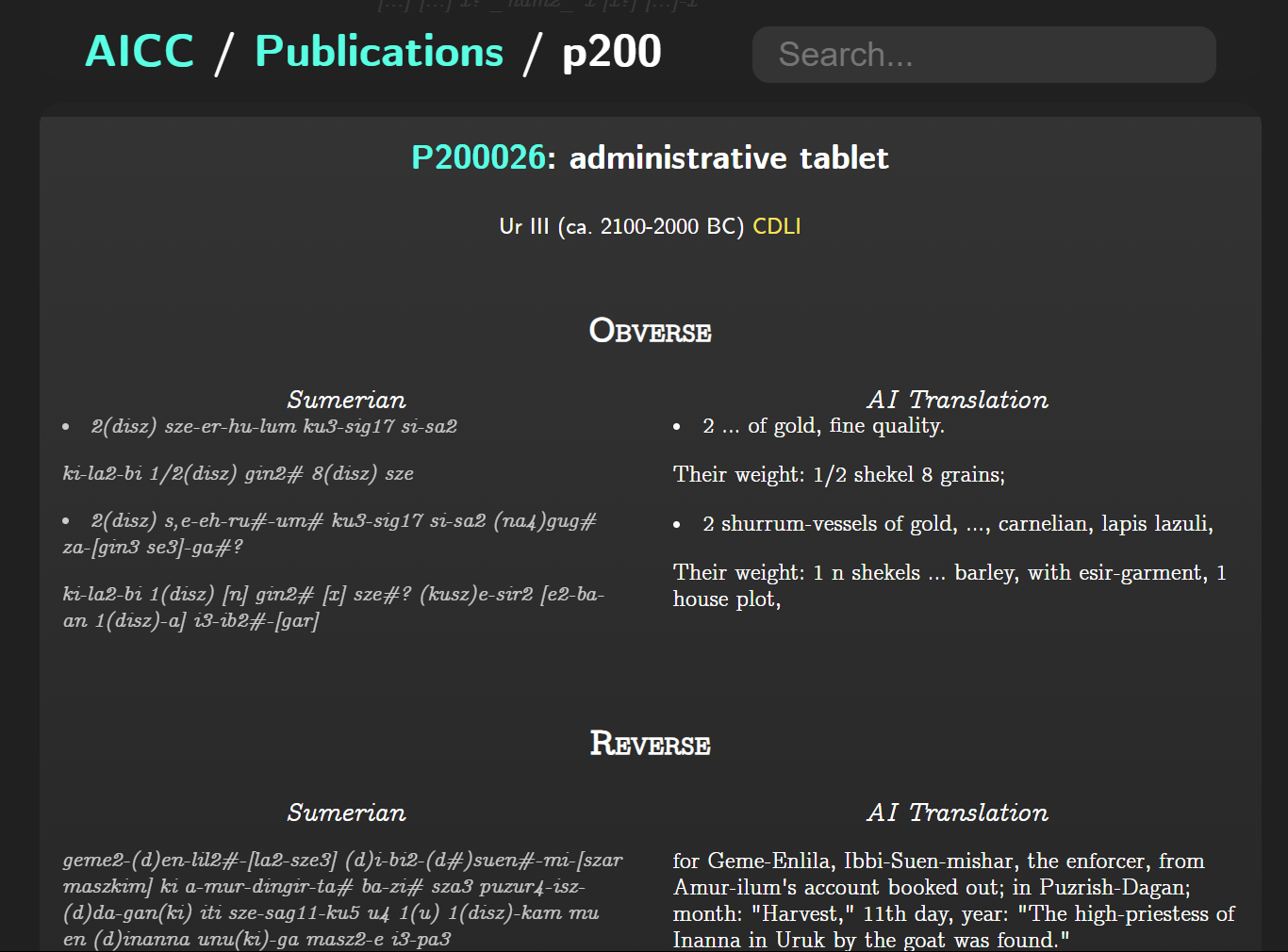
2023年に発表された Frank Ramos 氏による AI Cuneiform Corpus(AICC)[5]は、楔形文字研究に革命的な転換をもたらした。Google の T5トランスフォーマーモデルを楔形文字テキストに適用し、129,705件(シュメール語99,295件、アッカド語30,410件)の自動翻訳を実現したのである。このうち、従来未翻訳であったシュメール語98,492件、アッカド語21,678件が英語でアクセス可能となり、研究資料の大幅な拡充が達成された。
楔形文字研究における技術革新の一つは、高精度3D スキャニングの導入である。ジョンズ・ホプキンス大学の Digital Hammurabi Project[7]は、この分野の先駆者として、構造化光スキャナーを用いた粘土板の三次元記録を実現した。マイクロメートル単位の精度で表面形状を記録することにより、以下の革新的な研究が可能となった:
- 粘土板の全面(表・裏・側面・上下面)の統合的記録
- 仮想光源による微細な刻線や摩耗文字の可視化
- 楔の深さ・角度・文字サイズの非破壊的計測
- 書記の指紋抽出による個人特定研究
2025年にコーネル大学、テルアビブ大学、アリエル大学、および、ミュンヘン大学の研究チームが発表した ProtoSnap[8]は、楔形文字認識における画期的なブレークスルーである。この技術は、各文字の標準的「プロトタイプ」を基準とし、拡散モデル AI を用いて個々の文字の変形に適合させる手法を採用している。従来の畳み込みニューラルネットワーク(CNN)では対応困難であった、時代・地域・書記による字体の多様性に対して、ProtoSnap は優れた適応性を示し、特に希少文字の認識において顕著な性能向上を実現した。
楔形文字デジタル化の成功には、データ標準化が不可欠である。ATF(ASCII Transliteration Format)[9]は、CDLI と Oracc が推進する翻字記述の統一規格であり、破損状態や判読不明箇所を含む粘土板の完全な情報をプレーンテキストで表現可能にする。さらに、XML によるメタデータ記述により、長期的なデータ保存性と異なるシステム間での相互運用性が保証されている。これらの標準化により、世界中の研究者がデータを共有し、統合的な分析を行うことが可能となった。
日本も楔形文字デジタル化において重要な貢献を行っている。横浜ユーラシア文化館は326点の楔形文字粘土板データベースを構築・公開し、国内最大のデジタルコレクションを形成している。広島大学と京都大学が所蔵する楔形文字文献については、森若葉氏、山本孟氏らによる包括的な再調査が進行中である。特に注目されるのは、そのほか、塚越柚季氏、山内健二氏、山本孟氏、川浪拓也ティモスィー氏がドイツ・マインツの研究機関と協力し、断片化した粘土板の文字情報による自動照合システムの構築を進めており、楔形文字研究の統合的デジタル化への新たな展開が始まっている[10]。
楔形文字デジタル化は顕著な成果を上げているが、同時に重要な課題も抱えている。AI の「幻覚(ハルシネーション)」問題は依然として深刻であり、否定文を肯定文に誤訳するなど、学術的信頼性を損なう事例が報告されている。また、プロジェクトの持続可能性も大きな課題である。サーバー維持、システム更新、データの継続的追加には安定した資金が必要だが、多くのプロジェクトが短期的な研究助成金に依存している現状は、長期的な知識基盤構築の観点から問題である。
これらの課題に対する有効な解決策として、Human-in-the-Loop(HITL)アプローチが注目されている。AI が生成する「第一稿」を専門家が検証・修正するワークフローは、限られた人的資源を最大限活用しながら、研究の質と効率を両立させる現実的な方法論である。このアプローチは、AI を研究者の代替ではなく、強力な補助ツールとして位置づけることで、人間の専門知識と AI の処理能力の最適な融合を実現する。
CDLI が先駆的に導入した市民科学の手法は、専門家の閉鎖的コミュニティに限定されていた楔形文字研究を、より開かれた知識創造活動へと変革する可能性を示している。専門的訓練を受けていない市民が、適切なインターフェースとガイダンスのもとで研究に参加できる仕組みは、人文学研究の社会的基盤を拡大し、新たな研究人材の発掘にもつながる重要な展開である。
楔形文字デジタル化は、人類最古の文字記録を最新のデジタル技術によって現代に蘇らせ、未来へと継承する壮大な文化事業である。構造化光スキャナーによる精密な3D記録、ProtoSnap をはじめとするAI技術の革新、ATF によるデータ標準化、そして市民科学による参加型研究の展開は、この分野に前例のない発展をもたらしている。
楔形文字研究で確立された方法論とテクノロジーは、他の古代文字研究はもとより、消滅危機にある現代の少数言語の記録・保存にも応用可能である。デジタル技術と人文学の創造的融合により、人類の知的遺産を真の意味で「人類共通の財産」として共有する道が開かれつつある。粘土板から AI へ――この変革は、人文情報学が切り拓く新たな知の地平を象徴的に示している。
[謝辞]日本の楔形文字文献DHプロジェクトについて情報提供をいただいた、ヒッタイト学者の山本孟氏に感謝を表する。
《連載》「英米文学と DH」第7回
「DH における英米文学研究と DH 批評」
DH における英米文学研究
今回から、デジタル・ヒューマニティーズ(以下 DH)における英米文学研究の分野の全体像を考察していきたい。DH には歴史や宗教といった各研究者がよって立つ専門の研究分野があるが、その一つとしての文学研究を取り上げ、また特に英米文学研究に焦点を当てて、研究領域全般を考察するという試みである。研究者や組織によって DLS(Digital Literary Studies)や CLS(Computational Literary Studies)[1]、あるいは遠読(distant reading)などの呼び方を使うことがある。文学や文学研究といった一般的な単語(literature, literary studies, the field of literary study)にコンピュータの語彙を付加する呼び名(computational approaches to literature, computational analysis, computationally driven literary scholarship)やあるいは単に DH における文学研究を DH と示す呼び名もよくみられるところである[2]。なお、より広い DH 自体の研究の分類については、TaDiRAH および TaDiRAH の日本語訳を参照されたい[3][4]。
初めに全体像を示すのは難しいため、連載では現在筆者が考えている簡単なカテゴリ領域を示したうえで、当面は各領域を少しずつみていきたいと考えている。最終的に全体像を示せればよいが、どこまでうまくいくかは未知数である。
![]()
図1は、現在考えてるところの、DH における英米文学分野の研究領域の概要である。これは仮の分類であり、目安位に考えられたい。今後研究分野の進展や筆者の理解度に応じて随時更新していく予定である。どこまで変わるか、後に振り返ってみていただければと思う。英米文学研究とことわりをいれているが、現在の DH にはもともと英米文学研究から出発した研究者が多いことから(その多くは英米圏で母国語の文学を研究していた研究者と思われる)、英米文学研究としているが、広く日本文学や外国文学をいれても大きくは変わらないことと思われる。なお人文学の英米圏の文学分野は英文学、米文学、英語圏文学などの区分で大きく分かれているが、本連載では区別しない。
図1の DH の英米文学研究をみると、DH 研究で一般的なデータ構築、分析、ツールの領域のほかに、他の分野の DH 研究者にとっては多少見慣れない領域が目に入ることと思う。遠読、ジャンル、登場人物の特徴分析、影響などである。これらは DH の英米文学分野では計量分析と相性のよい研究としてよく取り上げられる研究である。遠読は大量のテクストを俯瞰して特定のパターンを見出す読みであり DH の文学研究の代表的な研究手法である[5]。ジャンルは文学史の長期的傾向として研究されることが多く、登場人物の特徴分析は伝統的な文学研究において物語を分析する上で主要な分析の一つである。影響は伝統的な文学研究でよく取り上げられるテーマである[6]。なお研究者によっては、コーパス言語学、文体論、DH を別の分野と分ける見方もあるが[7]、本論では DH の英米文学分野の中に位置づけている。
DH 批評
各領域の研究を少しずつ取り上げ研究をみていくにあたり、はじめに DH 批評を取り上げたい。人文学の伝統的な研究には、テクストを読んでその内容について考えるテクスト分析のほかに、理論、批評、アクティビズムがあるといわれるように[8]、批評は人文学研究の中心となる研究活動の一つである。アラン・リウが DH に社会、経済、政治、文化に関する批評を求めるように[9]、専門の範囲を越えた領域への批評もあれば、文学の分野内に生じた新しい学問領域やテーマに対する批評もある。
本連載で取り上げる DH 批評は主にアメリカで交わされた DH に対する賛成、反対意見を含む議論である。DH の是非を問う議論は折に触れ出てくるため、どういった議論や背景があるか押さえておくことは有益であろう。基本的には DH 支持者と DH 懐疑論者の間の議論であるが、どのような立場の意見にも耳を傾け、自らの思考の材料とされたい。
2000年に発表されたフランコ・モレッティの著名な論文「世界文学への試論」(“Conjectures on World Literature”)以降、遠読の手法を用いた DH 的な研究が文学研究においても増加し、また2004年の『デジタル・ヒューマニティーズの参考書』(A Companion to Digital Humanities)刊行以降、コンピュータを使用したデジタル人文学研究の総称として DH が使われはじめた[10]。
アダム・ハモンドは2000年代以降の DH の隆盛と2010年代以降の DH 懐疑論の登場を時間的な経緯とともに紹介している[11]。2009年、アメリカの英米文学のトップカンファレンスであり、数多くのDH研究者が所属する米国現代語学文学協会(Modern Language Association、以下 MLA)では DH の将来性に希望がもたれ明るい未来を期待させる研究発表やレポートが行われたようである。ウィリアム・パンナパッカーはそれを人文学の分野における初めての「大ヒット」と称した[12]。当時、DH は世間の注目を集め、研究費の獲得をもたらし、若手の研究者にテニュアトラックの道を開くという、それ以前にはなかった好状況を人文学にもたらしていた。700ものデジタルメディアに関するプログラムがアメリカに存在し、大学の20%がそうしたプログラムを持っていたという。
しかしながら、2013年にははやくも DH に懐疑的な、「DH の暗黒面」と題するパネルがMLAに現れる。2014年には DH 反対論者であるアダム・キルシュが「テクノロジーが英文科を支配している:デジタル人文学の偽りの約束」と題する記事を発表し人文学が行うべきことは「デジタルに抵抗し批評することである」と主張し[13]、2016年にはダニエル・アリントン他が「新自由主義的ツール(とアーカイブ):デジタル人文学の政治史」と題する記事を発表して、新自由主義に批判的な立場から、DH が新自由主義的で企業の論理に沿うよう大学を改革しようとしており、文学研究に真っ向から対立するものと評価している[14]。著名なミルトン学者であるスタンリー・フィッシュは早い時期から DH の理論に異議を唱えていたが[15]、決定的なのは、ナン・Z・ダによる「計算文学研究に対する計算的訴訟」("The Computational Case against Computational Literary Studies”)[16]による DH の著名な学者の研究への批判である。DH 研究が、結果が出ないか出ても間違っていると評したこの論文は、「文学の統計的アプローチに対する統計分野からの却下」[17]とも評されている。
本稿は、DH における英米文学研究の簡単なカテゴリ領域を示したあと、DH 批評の近年の主要な流れを概観した。次回以降は、DH 批評の具体的な中身や反論、DH がアメリカで発達した背景などを取り上げたい。
人文情報学イベント関連カレンダー
【2025年8月】
-
2025-8-3 (Sun)
第139回人文科学とコンピュータ研究発表会https://www.ipsj.or.jp/kenkyukai/event/ch139.html
於・シャトレーゼホテル談露館 -
2025-8-7 (Thu), 12 (Tue), 21 (Thu), 26 (Tue)
TEI 研究会於・オンライン -
2025-8-29 (Fri)
シンポジウム「デジタルアーカイブ評価基準策定への道―対話からはじまる共通理解」於・慶應義塾大学三田キャンパス
【2025年9月】
-
2025-9-4 (Thu), 9 (Tue), 18 (Thu), 23 (Tue)
TEI 研究会於・オンライン -
2025-9-6 (Sat) ~ 2025-9-7 (Sun)
Code4Lib JAPAN Conference 2025https://wiki.code4lib.jp/wiki/C4ljp2025
於・オンライン -
2025-9-16 (Tue) ~ 2025-9-20 (Sat)
TEI 2025https://tei2025.confer.uj.edu.pl/en_GB/
於・Jagiellonian University -
2025-9-19 (Fri) ~ 2025-9-21 (Sun)
JADH 2025https://jadh2025.hmt.osaka-u.ac.jp/
於・大阪大学豊中キャンパス
【2025年10月】
-
2025-10-2 (Thu), 7 (Tue), 16 (Thu), 21 (Tue), 30 (Thu)
TEI 研究会於・オンライン
Digital Humanities Events カレンダー共同編集人
◆編集後記
7月は、個人的には出張が続いて大変な月になりましたが、なかでも DH に深く関わるものが2つありましたので少しご報告します。
7月14~18日に、国際デジタル・ヒューマニティーズ学会連合(ADHO)の年次学術大会、DH2025(https://dh2025.adho.org/)がポルトガルのリスボンで開催されました。欧州では熱波が問題になっていましたが、この時期のリスボンは日本から行った自分にとってはそれほど暑くなく過ごしやすい気候でした。イベントとしてはオンラインも含めて980人の参加があったようで、大変盛況なものでした。概要論文投稿900件以上に対して査読が行なわれ、最終的には479件が採択され発表に至りました。内訳はポスター発表133件、発表時間10数分のショートペーパー218件、発表時間30分のロングペーパー118件、同90分のパネルセッション10件でした。ペーパーセッションとパネルセッションは主に9つのパラレルセッションに分かれて行なわれ、ポスター発表は3日間に分割されて中庭のテントのようなところで発表する形になりました。
内容は、生成 AI を使った実験的な取組みやその課題についての様々な角度からの検討があったかと思えば、研究対象となる文献の部分的な位置情報を効率的に共有するための共通の枠組みの提案や、人手で丹念に作成している構造化テキストやデータベースの公開などがあり、その一方で、テキストや画像などのデータを分析して新しい成果を示すなど、人文学にデジタル技術を適用しようとしたら思いつきそうなことが実に幅広く発表され、議論されていました。筆者は、共同研究として取り組んでいる TEI 古典籍ビューワの最新の状況についてポスター発表を行い、それだけに飽き足らず休憩時間(毎回30分確保される)に研究者仲間を捕まえてはデモンストレーションをしてみせて色々議論し、楽しく有意義な時間を過ごしましたが、一方で、もう一つの学会の醍醐味は他の方々の発表です。特に個人的に興味深かったのは、ケルン大学のチームによる「Playing the Past, Predicting the Future: Sortes Texts in Virtual Reality」でした。3D で構築した修道院の図書館、占星術師の研究室、酒場などの没入型環境に占いの文献を配置して操作できるようにし、儀式的でインタラクティブな性質を利用者が体験できる環境を開発した、というもので、デモンストレーションを見た限りではなかなかの完成度でした。この発表では様々な分野の専門知を集め、それらを踏まえて文献研究を体験するための3D 仮想環境を構築しており、3D を文献研究に活かしたいと思って勉強をしてきた筆者にとっては大変勉強になるものでした。
これはほんの一例に過ぎず、9セッションが並行して行なわれていると参加したセッション以外の8セッションは常に聞き逃し続けるということで、なんとももったいないことでもありました。しかしながら、ここでチェックした発表をした人の今後の発表やテーマに引き続き注目していくことで、今後の自分の知見をさらに広げていけるかと思うと、それもまた楽しみなことです。
7月28~29日には、中国のフフホトにて、中国の Digital Humanities Education Collaboration Committee によるシンポジウムがありました。中国全土から DH 教育に携わる大学の代表者が集まり、大学院生たちも集めて大変盛況な会合でした。集まっていた大学はまだ二十と少しでしたが、本メールマガジンにも寄稿をしていただいた北京大学、中国語で DH のジャーナルを刊行している精華大学、中国の巨大電子図書館 CADAL を運営している浙江大学、日本研究 DH にも力を入れている中山大学等々、すでによく知られている大学も含めて各地からの参加がありました。今回のシンポジウムのテーマは「Cultural Diversity and Digital Humanities」でしたので、筆者の講演では、特にテキスト研究において多様性を実現するための課題として Unicode や TEI Guidelines 等の話題を扱いました。今後、このコミュニティでは Web サイトを構築し、アジア太平洋地域における DH 教育に関するツールやカリキュラム等の情報共有を作るなどして DH 教育のリソースを集約していくことを目指しているようです。すでに EU の DARIAH・CLARIN では DH コースレジストリ(https://dhcr.clarin-dariah.eu/)や DH の MOOC(https://teach.dariah.eu/)などを作成・公開していますが、中国からもこういう動きが出てくるのだとすると、大変頼もしいことです。
このところ、当メールマガジンではイベントレポートが少なくなってしまっていますが、筆者がやや依頼を怠ってしまっている面があり、代わりにこのようにして簡単にご報告をしております。イベントレポートはいつでも受け付けておりまして、特に開催者の方々による詳細なレポートは大歓迎ですので、ぜひご寄稿をご検討ください。
- コメントを投稿するにはログインしてください