ペルセウス・デジタル・ライブラリーのご紹介(3)
前回は、Perseusでの作品の読み方を、ホメロス『イリアス』を題材にご紹介しました。作品を読む場合、ウェブブラウザに「表示されたもの」を読むことになりますが、Perseusでは、はじめから表示通りのページが用意されているわけではありません。注釈や翻訳など複数の文献が同一ページに読み込まれることからも分かる通り、各文献のデータファイルは個別に作成されており、リクエストに従ってそれらが組み合わされ、ページが動的に構成されています。今回は、そうしたPerseusのデータに注目しつつ、いわば表示とその裏側をめぐる話題を中心に、簡単にご紹介します。
(なお、筆者の環境ですが、Firefoxのバージョンがあがり、Firefox 30.0(beta版)となっています。表示上の相違はとくにありません。)
ペルセウス紹介記事の初回で、Perseusが各種文献の電子化データ(XMLデータ)をCreative Commons Attribution-ShareAlikeの下で公開していることを記しました。これは、見方を変えると、Perseusが基本的に「公開可能」な文献を電子化しているということを意味しています。そのような公開可能な文献というと、一般的には、著作権の切れた文献か、著作権者に承諾を得た文献に大別されると考えられますが、Perseusも例にもれず、両者を含んでいます。
Perseusがプロジェクトの当初に電子化を進めた文献は、現在ハーバード大学出版局から刊行されているLoeb Classical Library(LCL)に含まれる作品を中心としていました。LCLは1911年に創始された古代ギリシア・ローマの古典作品の古典語-英語対訳本シリーズです。当初のPerseusはその中から利用可能な古代ギリシア語作品を選んで、原典テキストおよび翻訳を電子化したわけです(なお、はじめはデータの記述にSGMLを用いていたようです)。CD-ROM版Perseusに含まれる作品データはそうして準備されたものが利用され、Perseusがウェブベースになったあとも、データは引き継がれています。
前回、原典テキストの右コラムに英文訳や注釈等も表示されることを紹介しましたが、そこで挙げられているものは19世紀末から20世紀初頭のものです。また、現行のPerseusのホメロス『イリアス』をみてみると、ギリシア語原典テキストには定評のあるOCT版(Oxford Classical Text)が利用されており、翻訳にはLCL版や他のものが付されています(OCT版は1920年刊行のものと記されています。同じホメロスの『オデュッセイア』については、ギリシア語原典テキストもLCL版です)。最近のPerseusでは、LCL以外の校訂本を元に電子化された作品も増えていますが、LCL版を利用した場合と異なり、原典テキストのみで英訳等が存在しないこともあります。
ざっと見渡してみると、Perseusでは、古典語の文法書や辞書など、原典テキストや翻訳以外にも種々の文献が電子化されて公開されていますが、その多くは著作権の切れた文献です。したがって、校訂テキストを含め、注釈書などにしても、最新の研究を参照できるわけでない点には注意が必要です。そうした文献の良し悪しは一概にはいえませんが、この点はPerseus(や同種のサイト)のひとつの制約とみることもできます。(なお、Perseusの著作権関連ページを確認すると、一部のテキストは出版社や著者の承諾を得て使用しているようです 。完全には確認できていませんが、そうした作品のXMLデータはダウンロード可能になっていない場合もあるようです。)
既にご紹介したとおり、Perseusプロジェクトは1980年代後半に始まり、1990年代半ばにはウェブサイトでの公開を始めています。古代ギリシアの作品を電子化するにあたって、ひとつの問題は、気息記号やアクセント付のギリシア文字(polytonic Greek)の扱いです。今でこそUnicodeの恩恵で文字の扱いが簡単になり、記号付き文字を直接入力することも可能になっていますが、プロジェクト開始当初はまだそうした仕組みは整っていませんでした。
古代ギリシアの作品を電子化する試みはPerseus以前から既に行われており、1970年代前半には、ギリシア語文献の電子化を進めるTLG(Thesaurus Linguae Graecae)プロジェクトが開始されました 。その中で、TLGの表示、検索システムの開発を率いていたDavid Woodley Packardによって、Beta Codeと呼ばれる、ASCII文字のみでアクセントや気息記号まで表記するための入力規則が開発され、1981年にTLGのギリシア語入力法として採用されました。そして、Perseusプロジェクトも、ギリシア語文献の電子化にあたって、このBeta Codeを採用します。(ただし、基本的には、TLGでは全て大文字、Perseusは小文字での入力です。原則として各文字はギリシア語小文字として扱われ、ギリシア語大文字を表記する際はその文字の前に*をつけます。)

(図1: Perseusにおけるギリシア語入力法)
Beta Codeで入力されたデータは、ウェブブラウザ等で表示される際に、Beta Codeから利用者のシステムに適合する形に変換されて表示されます。
現在はUnicode(UTF-8等)が利用可能となり、ほぼ環境を選ばない状況が出来ていますが、それ以前は、記号付きギリシア文字を表示するためには、特定のフォントを指定するなど特殊な手順が必要となっていたうえ、手法毎に入力規則が異なっており、ある環境で作成したデータは、それと同種の環境でしか表示できない(あるいは表示するためには手間がかかる)という問題がありました。それに対して、ASCII文字のみで規格化されたBeta Codeによって内部の文献データを記述することで、データの入力と出力が切り分けられます。一定の規則に基づいて記述されるのであれば、内部のデータと画面表示が一致している必要はなく、利用者の画面での記号付きギリシア文字の表示は「見せ方」(出力)の処理の問題となります。

(図2: Perseusのギリシア文字表示設定)
現在のPerseusでは、ギリシア文字の表示方法について、各ページ右コラムに表示される設定欄(Display Preferences)から、環境にあわせて利用者自身が設定できます。今日の一般的なPC環境であれば、「Unicode(precombined)」で問題ありません。図2のリストのSPIonicなどは、Unicode以前の表示法の名残ともいえるものです。
Unicodeを用いれば、記号付きギリシア文字を直接指定して入力することが可能です。つまり、入力と出力を共通化する形で内部のデータを蓄積し処理することができます。しかも、ギリシア語に限らず、多言語を共存させることも可能になります。しかしながら、PerseusのウェブサイトはUnicodeに対応済みとなってはいるものの、Perseusのシステム内部では、ギリシア語を処理する際はBeta Codeを用いているようです。
Perseusのギリシア語原文において、それぞれの語彙から語彙分析ツールへのリンクが張られていることは前回ご紹介した通りですが、たとえば『イリアス』冒頭の「μῆνιν」を例にとると、そのリンクのURIは図3のようになっています。
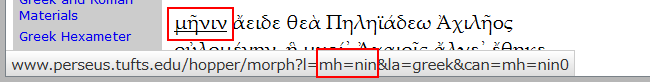
(図3: 「μῆνιν」から語彙分析ツールへのリンク )
「μῆνιν」を分析プログラムに引き渡す際に「mh=nin」と記述しており、Beta Codeが利用されています。また、語彙の分析結果ページでは、図4のように右コラム上部に検索ボックスが表示されますが、ここでも表記はBeta Codeです。

(図4: 「μῆνιν」分析結果ページの右コラム検索ボックス)
ちなみに、検索欄にUnicodeで「μῆνιν」と入力しても検索可能ですが、結果表示後の検索欄は図4と同じになります。つまり、内部でUnicodeからBeta Codeへの変換が行われているわけです。(このあたりの処理については、公開されているプログラムのソースコードをきちんと読めば明確になりますが、筆者はそこまで確認できておりませんので、ここでの話は実際の動作からの推測です。)
Unicodeは利便性の高いコード体系ではありますが、各種プログラムやシステムの対応状況はまちまちです。Unicode対応が完全ではない場合、Unicodeで記述されたデータの取り扱いに困難をきたします。それに対して、ASCII文字のみで記述されるBeta Codeの場合、基本的にどのようなプログラムやシステムでも処理できます。このような、環境に依存しない汎用性は、Beta Codeの大きな特徴ですし、現在なお利用されるひとつの要因であろうと考えられます。なお、今後Unicodeがさらに一般化し、各種データのUnicode化が進む場合も、基本的には現在のBeta Codeから変換するだけで済むため、大きなコストはかからないものと思われます。
さて、現在のPerseusは各文献データをTEI/XML(以下XMLとのみ表記します)を用いて構造化しています。本稿で全体を扱うことは難しいため、ホメロス『イリアス』冒頭の本文部分を中心に、データと画面表示について簡単に触れておきたいと思います。(文字のエンコードに対して、文献のエンコードともいえるかもしれません。)
各文献について、そのページで表示されている部分のXMLデータは、各ページの本文下部にあるXMLリンク( )から確認できます。ホメロス『イリアス』冒頭について、XMLデータを確認すると、図5のように表示されます(データの階層的表示はブラウザによって整形されたものです)。
)から確認できます。ホメロス『イリアス』冒頭について、XMLデータを確認すると、図5のように表示されます(データの階層的表示はブラウザによって整形されたものです)。

(図5: ホメロス『イリアス』冒頭・本文XMLデータ)
ここではUnicodeのギリシア文字が表示されていますが、これは表示設定をUnicode(precombined)としてページを表示した上でXMLデータを表示しているためです。後で確認しますが、元のXMLデータファイルではBeta Codeが用いられています。
このXMLデータが整形されて、通常表示される画面となります(図6)。

(図6: ホメロス『イリアス』冒頭・本文表示)
XMLデータにおいては、詩行が1行ずつ<l></l>タグで囲まれ、5行ごとに<l n=”5”>などとして行番号が付されます。そうした情報を元に、実際の本文表示では、行番号が右側に表示されます。「book」や「card」の情報なども、XMLデータの中に埋め込まれています。一方、XMLデータでは記述されませんが、本文表示の際には、ギリシア語の各語彙に対してPerseusのシステムによって自動的に語彙分析ツールへのリンクが生成されます。
あわせて、右コラムの注釈部分もXMLデータを確認しておきます。注釈は英語とギリシア語などが混在した文献ですので、ギリシア語原典とは性質が異なるものといえます。ここでは、1891年版の注釈について見てみます。

(図7: ホメロス『イリアス』冒頭・右コラム注釈)
右コラムでは図7のように表示されますが、この部分のXMLデータは図8の通りです。(ここでもUnicode表示の関係でギリシア語部分がBeta Codeではなくなっています。)

(図8: ホメロス『イリアス』冒頭・注釈部分XMLデータ)
細かいタグの説明は省きますが、注釈のXMLデータでは、『イリアス』本文の場合と異なり、lang属性による言語指定が行われています。このデータでは、<text lang=”en”>と記述して基本言語に英語を指定しつつ、該当部分ではlang=”greek”やlang=”la”の属性をつけて、その部分がギリシア語やラテン語であることを指定しています。ブラウザで表示される際には、そうした指定に基づき、ギリシア語やラテン語部分の語彙に、Perseusのシステムによって語彙分析ツールへのリンクが自動的に生成されます。また、文献情報も
再び『イリアス』本文に戻りますが、『イリアス』本文下部で先程みたXMLリンクの下に、作品の電子データに関するライセンス表示があります(図9)。
(図9: 『イリアス』本文下部・CCライセンスに関する表示)
このライセンス表示の文章中の「XML version」の部分をクリックすると、(本稿の例では)『イリアス』本文全体のXMLデータファイルを確認することができます。筆者の環境の場合、Firefoxではリンクをそのまま読みこめなかったため、以下の画像はInternet Explorer 11上での表示です。

(図10: ホメロス『イリアス』ギリシア語XMLデータ・ヘッダー部分)
ここまで確認したXMLデータは抜粋表示であり、ヘッダー情報が含まれていませんでしたが、元のデータファイルでは、図10のとおりに種々の情報がヘッダーに記載されています。図10では情報を折りたたんだ状態で表示していますが、すべて展開した状態にすると、<teiHeader></teiHeader>の間に、各種のタグを含めて80行程度あります。また、ヘッダーの情報の一部は、ページ表示の際に利用されています(本文下部に表示される出典情報など)。

(図11: ホメロス『イリアス』ギリシア語XMLデータ・本文冒頭)
ギリシア語本文の部分も見ておきますと、先に述べた通り、ギリシア語がBeta Codeで記述されていることを確認することができます。繰り返しになりますが、このように記述されたデータが機械的に処理されて、図6の本文表示となっているわけです。そのようなデータの加工処理は、データを扱うシステムに依拠します。PerseusはPerseusなり、他のシステムは他のシステムなりの方針に従って処理を行うことになります。
純粋にデータ構造を記述するのであれば、端末の画面表示(あるいは人間へのデータの見え方)に関わる要素は不要です。図10の中で記される「Iliad (Greek). Machine readable text」というタイトルが、電子化データに関するPerseusの考え方を端的に表現しているようにも思われます。
ここまで述べてきたように、Perseusでは、そうした「機械に読ませる」データを記述するにあたって、独自規格ではなく、Beta Codeや(古くは)SGML、(現在は)TEI/XMLといった標準規格を用いています(Beta Codeを「標準」というのは難があるかもしれませんが)。そのため、Perseusの作成するデータは、汎用性・可搬性が非常に高いものとなっています。また、作成されたデータは機械的処理の対象となりますが、そのデータを記述していく作業は、人間の領域です。文献を規格に沿って電子化するにあたっては、たとえば図10や図11のようにタグ付けを行い、文書構造や付随情報を明記する必要があります。この作業自体、文献を意識的に意味づけしていくことに繋がりますので、多大な労力を要する高度な作業ともいえます。場合によっては、そうした意味づけの過程で、それまで意識されていなかった問題が顕在化し、新たな知見が得られることもありえます。Perseusはそうして作成されたデータまで、可能な限り、惜し気もなく公開しているわけです。
デジタル化する人文学の世界の中にあって、Perseusプロジェクトがひとつの先進的なモデルケースであることは、広く認められることと思われます。筆者はやはりキーワードとして「オープン」Openを思い浮かべますが、ここまで紹介してきたPerseusの持つ標準化技術への意識の高さ、データを公開する姿勢、それらを実践していく在り方、情報技術との連携などは、まさにPerseusの先進性を支えてきた柱であると同時に、これまでの、そして、これからの人文学の世界に対する大きな挑戦である、ともいえるかもしれません。今後のPerseusの動向にも要注意です。
Copyright(C)YOSHIKAWA, Hitoshi 2014- All Rights Reserved.
 ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄
=======================
『人文情報学月報』No. 34より
- コメントを投稿するにはログインしてください