人文情報学月報第148号
ISSN 2189-1621 / 2011年08月27日創刊
目次
- 《巻頭言》「デジタル技術でキュレーションを理解する」
:国立情報学研究所オープンサイエンス基盤研究センター - 《連載》「欧州・中東デジタル・ヒューマニティーズ動向」第65回
「TEI Lex-0による辞書資料の構造化と機械可読化:GPT Builder の援用も含めた一試行」
:人間文化研究機構国立国語研究所研究系 - 《連載》「仏教学のためのデジタルツール」第13回
「国立国会図書館デジタルコレクション」
:東京大学大学院人文社会系研究科 - 人文情報学イベント関連カレンダー
- 編集後記
《巻頭言》「デジタル技術でキュレーションを理解する」
本稿では、特に学芸員の方々には馴染みの深い用語であろう「キュレーション」について取り上げます。あいにく執筆者は人文学に深い知見がある訳ではないのですが、関心領域であるデジタルキュレーションの観点からデジタル技術の適用について面白さをお伝えできればと考えております。
さて、デジタルキュレーションについて触れる前に、その背景となるデータの再利用について簡単に説明させてください。まず、データの再利用は、提供者がデータを解釈可能、かつアクセス可能にしたうえで、再利用者が処理されたデータを利用する、という構図で成り立ちます。データの提供手段は様々ですが、大別して個人間の私的なやり取りと、データを共有可能なリポジトリに登録し、ウェブを通じて広く配信する手法の2つに分けられます。容易に想像がつく通り、データの再利用が生じるパターンは前者に偏っており、主として同じ分野の研究者間でのみ実践されてきました。しかしながら、オープンサイエンスの推進といった国際的潮流、あるいは社会的要請を受け、昨今では分野を超えたデータの再利用に期待が集まっています。
異なる文脈で作成されたデータが思いもよらない形で使われ、新たな価値の創出に繋がる未来は大変魅力的ですが、一方で、データを再利用可能な状態に持ってくるためには多くの課題が存在しています。例えば、研究者はデータを再利用する際、自身の研究との関連性、データの再現可能性といった項目を評価しますが[1]、こういった情報はしばしば暗黙知となっています。そのため、研究者は必要に応じてデータの提供者にコンタクトを取り、データの作成やクリーニング、処理、分析、報告の各方法について議論することになります[2]。この方法は確実性の高い方法ですが、提供者、再利用者の両者にとって非常に手間がかかります。そこで、近年ではデータを共有可能なリポジトリ/アーカイブに登録し、ウェブを通じて広く配信する手法が模索されてきました。この手法においては、データの提供者がデータ及び再利用に必要と思われる情報を事前に掲載しておけば、分野の内外を問わず容易に再利用が可能になることが期待できます。しかしながら、数多くの実証的研究を通じて、データの再利用が失敗に終わる原因がデータに内在する文脈情報のドキュメンテーションにあることが報告されています[3]。参照先にはいくつか具体的な事例が列挙されていますが、不正確な記述が見つかったり、データの値や事前のクリーニング作業に疑義がある場合などは、結局のところ提供者へ確認するしかなく、個別の交渉を望まない研究者から敬遠される理由となっているようです。
上述したようなデータの再利用にまつわる課題を解決していくためには、仲介役となるリポジトリ/アーカイブの管理者がデータを作成した時点から適切に管理するとともに、利用を促進するための継続的な取り組みを実施することが求められます。図書館情報学を中心とする分野では、これを実現する一連の作業をデジタルキュレーションと呼んでいます[4]。同分野におけるデジタルキュレーションには、対象となるデータのクリーニング、ドキュメンテーション、標準化、フォーマット変換、関係するデータやコードとの関連付けといった様々な粒度の作業が含まれます。
ここで、「キュレーション」という用語の使い方に違和感を持たれた方も多いかもしれません。興味深いことに、「キュレーション」は様々な分野で少しずつ異なる使われ方をされています。例えば博物館学では、キュレーションを「博物館のコレクションの保存、充実化、研究、開発、管理」と定義しているようです[5]。したがって、デジタル化された博物館資料に対しては「デジタル化された博物館のコレクションの保存、充実化、研究、開発、管理」として良さそうですが、実際の作業内容がどの程度一致しているのか判然としません。また、天文学、ゲノム学、生態学、経済学などデータ駆動型の手法を用いる分野では「データキュレーション」というひとつながりの用語として用いられています。定義は上述した2つとやや異なり、ジャーナルや報告書、その他のデータベースからデータを選択し、正規化し、注釈を付け、統合するプロセスを表す概念として位置づけられているようです[6] [7]。
一方で、奇しくも同じ用語が用いられているのであれば、何らかの共通性があるだろうと推察されます。実際、各分野の実践を詳細に見てみると、様々な分野で全く同一の作業、あるいは極めて近しい作業が多く含まれています。個別の比較については紙面の都合上取り上げられませんが、ある分野とある分野の作業がほぼ同じということは、扱うデータの内容や構造がほぼ同じということであり、ひいては研究対象の捉え方が酷似している、とも考えられます。このあたり、資料がデジタル化されることによって分野間の繋がりが生まれているようでもあり、個人的に大変面白く感じるポイントです。
しかしながら、この奇妙な類似性を一般化するのはなかなか厄介な作業となります。というのも、「キュレーション」の定義が分野によって異なるため、構成要素の定義にもその曖昧さが反映されてしまうからです。このような曖昧さをデジタル技術で解消する手段として、情報学ではオントロジーという理論体系が提唱されています。オントロジーとは、大雑把には「対象領域における共通の概念を同定し、概念間の関係性を上位下位関係に基づいて組織化したもの」とされます[8]。オントロジーが提供する枠組みで知識を整理することによって、ある用語が示す意味が概念として定義され、人と人との間に留まらず、異なるソフトウェア間でも認識を共有することが可能になります。類似の手法として、統制語彙やシソーラスなどが挙げられますが、オントロジーでは概念を表現する語彙だけではなく、概念と概念の間にある関係性そのものを厳密に明示化することが求められます。そのため、複数の概念間における意味の重複が排除され、「ある作業が後ろの作業にどの程度の影響を及ぼすのか」といった、個々の作業からは見えない全体像を論理的に描くことができます。さらには推論などのより高度な情報処理も可能になり、デジタル技術をフルに活用するための土台が提供される、と言えます。キュレーションをオントロジー化した実例にご興味を持たれた方がいらっしゃれば、是非参照先のウェブサイトもご覧ください[9]。
以上、「データの再利用」、「キュレーション」、「オントロジー」についてご紹介しました。ニッチな事例のご紹介となりましたが、デジタル技術を適用して既存の専門分野を異なる角度から眺め、理解の枠組みをアップデートしていく工程はなお魅力的です。読者の皆さまにとって、本稿がデジタル技術の適用、あるいは新たな実践に繋げる際の一助となれば嬉しい限りです。
執筆者プロフィール
《連載》「欧州・中東デジタル・ヒューマニティーズ動向」第65回
「TEI Lex-0による辞書資料の構造化と機械可読化:GPT Builder の援用も含めた一試行」
本稿の内容は、TEI Lex-0[1]の中心的人物の一人であり、DARIAH-EU[2]の Director の三人のうちの一人で President of the Board である Toma Tasovac[3]氏を招いたワークショップで Workshop on "Digitization of Historical Lexicography and TEI-Lex0"[4]で筆者が発表した内容と Tasovac 氏および参加者からのフィードバックをもとにしている。このワークショップは2023年11月17日に東京ビッグサイトで開催された。一般財団法人人文情報学研究所および科研費 JP23H03696・JP23H00002によって主催された。
Coptic Dictionary Online (CDO)[5]は、コプト語の辞書情報をデジタル化し、オンラインでアクセス可能にするプロジェクトである。2019年の DH Award のうち Best DH Tool or Suite of Tools[6]を受賞した。このプロジェクトの目的は、学術研究だけでなく、一般の人々にもコプト語とその文化的遺産を広く伝えることにある。ユーザーは、単語検索、語形変化、意味、例文など、多岐にわたる情報を得ることができる。世界中の学者や学生、コプト語に興味を持つ一般の人々に向けて、コプト語の辞書情報をデジタル形式で提供するプロジェクトである。利用者は単語の意味、語源、使用例、そして関連する言語学的情報を容易に参照できるようになっており、コプト語学習者や研究者にとって貴重なリソースとなっている。
CDO は、ユーザーインターフェイスが直感的であり、様々な検索機能を提供している。コプト語のタグ付き多層コーパスである全米人文科学基金のCoptic SCRIPTORIUM[7]と連携しており、例文は Coptic SCRIPTORIUM コーパスから自動で取得される他、このコーパスでの頻度、そしてコロケーション分析も CDO 上で表示される。さらに、関連する単語や語句へのリンクも豊富に表示される。
CDO の構築と維持において、辞書データは TEI P5 Guidelines[8]に基づいた XML ファイルで GitHub 上で保守されている[9]。Text Encoding Initiative (TEI) のガイドラインに基づいて人文学資料をマークアップし、構造化・機械可読化したファイルは TEI/XML ファイルと呼ばれる。TEI/XML は、デジタル・ヒューマニティーズにおいて、人文学資料のマークアップの世界標準となっており、この形式で資料を作成し、配布することは、様々なツールを適用可能にし、さらに、他のプロジェクトでも二次利用・再利用ができ、データの持続可能性を担保する。TEI P5で辞書項目をマークアップする際、致命的では決してないにせよ、非効率的ないくつかの課題が伴う。
CDO には、<body> の下に、<superEntry> と <entry> が混在している。<superEntry> の下には必ず複数の <entry> がある。これは XPath を見れば、一目瞭然であるが、<superEntry> に入っている項目と <entry> のみの項目では、<entry> の場所が異なるレベルにある。CDO は <entry> と <superEntry> のみを用いているが、TEI には、この他にも、辞書項目を書くタグとして、<entryFree>(構造化されていない辞書項目)や <re>(関連項目)、<hom>(同義語)がある。<superEntry> は <entry> を内包することができ <entry> は <re> を内包することができる。そして、<re> はさらに <superEntry> や <entry> を内包でき、無制限にループすることができる。
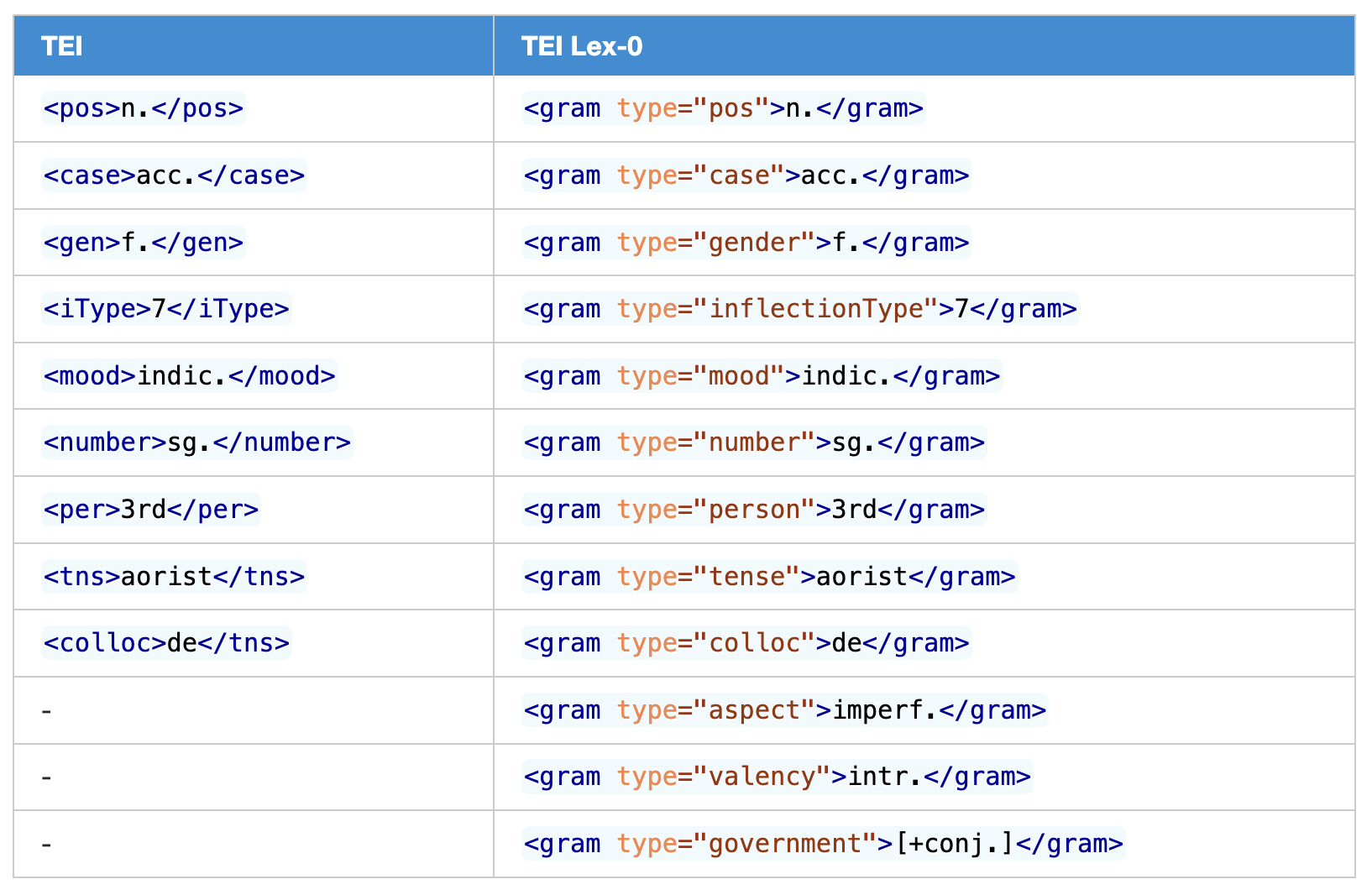
また、TEI P5では、辞書の文法要素の項目については、<case>(格)、 <gen>(性)、<iType>(屈折タイプ)、<mood>(法)、<number>(数)、<per>(人称)、<tns>(時制)などの文法要素がある。しかし、言語の中では、アスペクトで動詞が屈折する言語、バンツー諸語のようにジェンダーというよりも名詞クラスがある言語、コプト語のように、後ろにどんな品詞の語が来るかによって、形を変える言語などが存在する。他にも様々な文法項目があるが、TEI ガイドラインでタグとして文法項目が設定されているものは、ラテン語やギリシア語など、西洋の古典言語の文法項目を基準にしているようである。ただし、能動態や受動態などの態 <voice> のタグがないのが不思議である。これに対して、TEI Lex-0では文法項目は全て <gram> タグで統一し、どの文法項目かは、@type の値に記入する。
TEI Lex-0は、このような TEI P5の辞書で使う項目の、複数のやり方が可能な書き方を、できる限り統一し、さらに様々な効率化を追求した、辞書専門の TEI のサブセットである。TEI Lex-0は、ヨーロッパで制定されてきた。フランスの Inria(フランス国立デジタル科学技術研究所)の Laurent Romary[11]氏と DARIAH およびベオグラード DH センターの Tasovac 氏を中心にヨーロッパの様々な DH 研究者がこの標準化に関わってきた。これは2010年代後半に始まったプロジェクトであり、まず主にヨーロッパ諸言語の辞書で、そして中東の諸言語の少数の辞書で TEI Lex-0によるマークアップを行ってきた。そのため、その使用事例には言語の地理的な偏りがかなりあると言える。TEI Lex-0は完成したプロジェクトではなく、定期的にアップデートされてきている。
筆者の発表では、ChatGPT の GPTs (GPT Builder)[12]による、簡易ファインチューニングによる、TEI Lex-0変換器についても発表した。GPTs は ChatGPT の有料版に11月6日に搭載された機能で、GPT4に、応答形式で前提や挙動の指示のプロンプトを与えたり、スキーマファイルなど様々なファイルを与えることで、ChatGPT を簡易ファインチューニングできるアプリである。Bing と組み合わせたウェブ検索や、Advanced Data Analysis(旧:Code Interpreter)[13]での Python コードの実行、DALL-E 3[14]による絵の生成も組み合わせることができる。
筆者は、TEI Lex-0のサンプルファイル[15]を GitHub からダウンロードしたものを GPT Builder にアップロードし、TEI Lex-0を作成するようにプロンプトで命令した GPT を作成した[16]。この GPT は、TEI P5で書いた辞書ファイルを TEI Lex-0とするほか、「[単語]dog[意味]犬」など人間が理解できる程度の簡易の辞書マークアップも TEI Lex-0にすることができる。
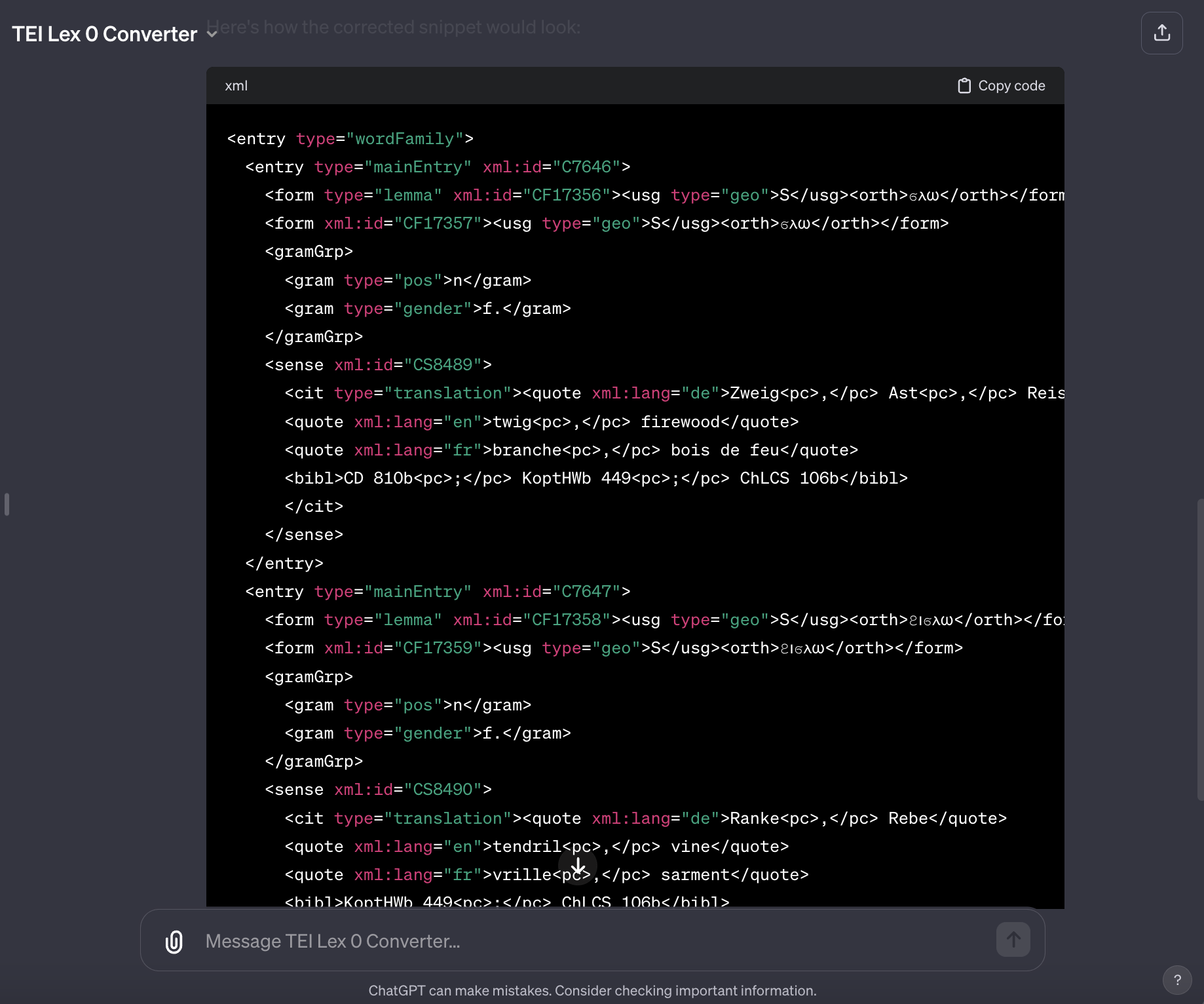
本変換器は完璧ではないが、その都度エラーを直すように修正すべき点を指摘していけば、完璧に近いものができると思われる。もちろん、TEI P5と TEI Lex-0はルールベースのプログラムで変換可である。今回のワークショップでは、永崎研宣氏が2年前に作成した変換プログラムでは、TEI-Lex0に準拠させると TEI P5ガイドラインのスキーマでは検証エラーになってしまう場合があったが、現在改めて最新版の TEI P5ガイドラインで検証してみたところ妥当 (valid) であったとの発表があった。
ワークショップのディスカッションでは、Tasovac 氏が TEI Lex-0は未だ進行中のプロジェクトであり、現在カバーができていない非ヨーロッパの諸言語の辞書での実例などを氏への E メールや TEI Lex-0の GitHubリポジトリ上で報告してほしいと述べていた。日本でも、本ワークショップの参加者のうちの多くが発表したように、東アジアの諸言語の辞書で TEI Lex-0を活用している例が複数ある。TEI P5 Guidelines でルビが「TEI 協会東アジア/日本語分科会」のイニシアチブで追加されたように[17]、TEI Lex-0に対しても、アジア・アフリカの諸言語の辞書から必要な項目が追加されることが期待される。
《連載》「仏教学のためのデジタルツール」第13回
仏教学は世界的に広く研究されており各地に研究拠点がありそれぞれに様々なデジタル研究プロジェクトを展開しています。本連載では、そのようななかでも、実際に研究や教育に役立てられるツールに焦点をあて、それをどのように役立てているか、若手を含む様々な立場の研究者に現場から報告していただきます。仏教学には縁が薄い読者の皆様におかれましても、デジタルツールの多様性やその有用性の在り方といった観点からご高覧いただけますと幸いです。
「国立国会図書館デジタルコレクション」
今回は国立国会図書館が公開している「国立国会図書館デジタルコレクション」(https://dl.ndl.go.jp/)を紹介する。
国立国会図書館は2000年度以降、戦前の近代日本資料を中心に所蔵資料のデジタル化を逐次進め、その画像データを国立国会図書館デジタルコレクション(以下、NDL デジタルコレクション)において公開してきた。その NDL デジタルコレクションが2022年12月21日をもって大幅にリニューアルされた[1]。これまで画像データとしてのみ利用可能であった資料の大部分について全文検索が可能となった。これにより NDL デジタルコレクションは仏教学研究の分野では主に近代仏教研究において必須のツールとなるだろう。
NDL デジタルコレクションは公開資料数および文字認識精度という二点において卓越した全文検索データベースを提供している。2022年12月21日のリニューアル時点で1860年以降に日本で刊行された資料247万点が全文検索の対象となっている。その後も随時対象となる資料が追加されている。同様の試みは既に2004年から Google ブックスにおいて行われている。しかし、日本で刊行された資料の収集数について Google ブックスは NDL デジタルコレクションに及ばない。また、NDL デジタルコレクションにおいて全文検索の対象となっている資料の文字認識精度は90%を超えている。この数値は資料の刊行時期の古さを勘案すると極めて高い。市販の OCR ソフトでは明治期や大正期の資料を同等の精度で文字認識することはできない[2]。
このような NDL デジタルコレクションの検索機能は研究者の資料読解を補助する。とりわけ近代仏教研究をテーマとした場合、研究対象となる明治以降の日本で刊行された資料は膨大である。NDL デジタルコレクションにおいて全文検索の対象となる資料だけでも247万点も存在する。これら全てに目を通し自らの研究に資する資料を選び出すことは到底不可能である。しかし、NDL デジタルコレクションの検索機能はこれらの膨大な資料の中から検索語を瞬時に取り出すことができる。このような機能は研究者の資料調査を代行し、研究者が扱うことのできる資料の幅を今まで以上に広げることにつながるだろう。
次に、NDL デジタルコレクションの使い方について、全文検索機能を用いることを念頭に置いて説明する。利用者がNDLデジタルコレクションで資料を閲覧する際には、具体的には、ログイン(利用者登録)→トップページ→検索結果一覧→資料閲覧画面の順序を辿ることになる。
まず利用者登録(本登録)を行うことは、利用の必須条件ではないが、十分に NDL デジタルコレクションを利活用したい場合には強く推奨する。NDL デジタルコレクションでは公開する資料を「ログインなしで閲覧可能」「送信サービスで閲覧可能」「国立国会図書館内限定」の3種類に分類している。この内「ログインなしで閲覧可能」に分類される資料は、利用者登録無しに誰でも閲覧可能である。しかし、ここに分類される資料の点数は極めて少ない。「送信サービスで閲覧可能」に分類される資料は、利用者登録(本登録)をすることで、国立国会図書館外からアクセスすることができる。管見の限りでは、戦前の書籍・雑誌は概ね「ログインなしで閲覧可能」か「送信サービスで閲覧可能」に含まれる。したがって、戦前の資料を主な研究対象とする研究者は、利用者登録さえすれば、自宅から十分に研究資料を収集・利用できる。最後に「国立国会図書館内限定」とは、文字通り国立国会図書館に行かなければ閲覧できない資料である。
トップページでは、キーワード検索と画像検索を行うことができる。この内、キーワード検索ではデフォルトで全文検索することができるようになっている。さらに詳細検索では、タイトル、著者、出版社、出版年月日、コレクションなどを指定して検索することもできる。一方、画像検索では、手持ちの画像やウェブ上に公開されている画像を用いて、デジタルコレクション内の類似の図版を検索することができる。
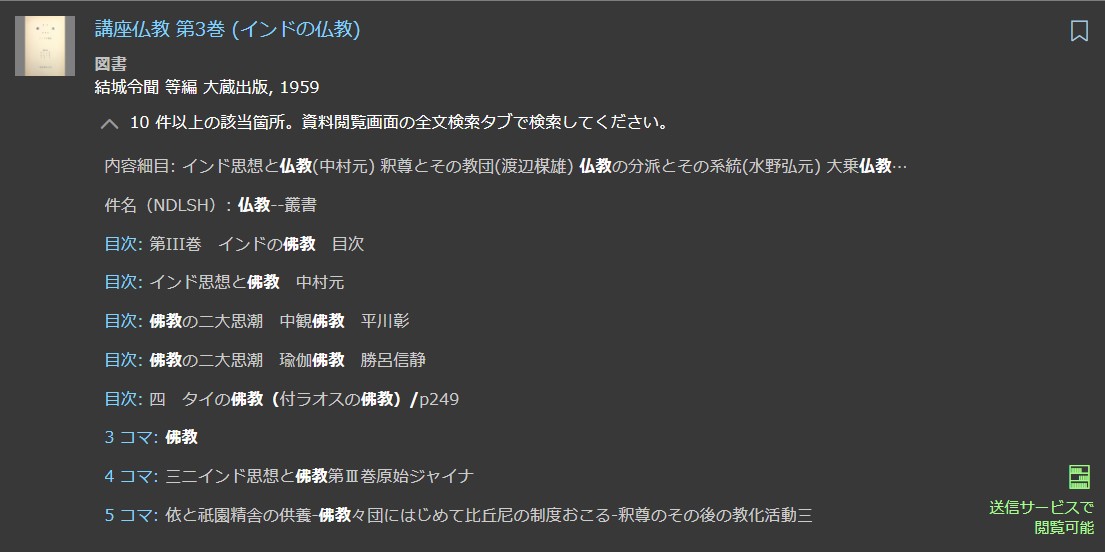
検索結果一覧には、タイトル・目次に加えて本文内に検索語を含む資料が、検索語を含む本文の抜粋及び該当するコマ数(国会図書館における資料の撮影単位。見開き2ページを1コマとする)と共に表示される。資料タイトルとコマ数は青くハイライトされ、それぞれ資料閲覧画面の該当コマへリンクされている。ただし、同一資料内で検索語が複数用いられる場合には、最大10件まで検索結果一覧画面に表示される(図1)。それ以降の検索結果を参照するためには、資料閲覧画面の全文検索タブから再度検索しなければならない。
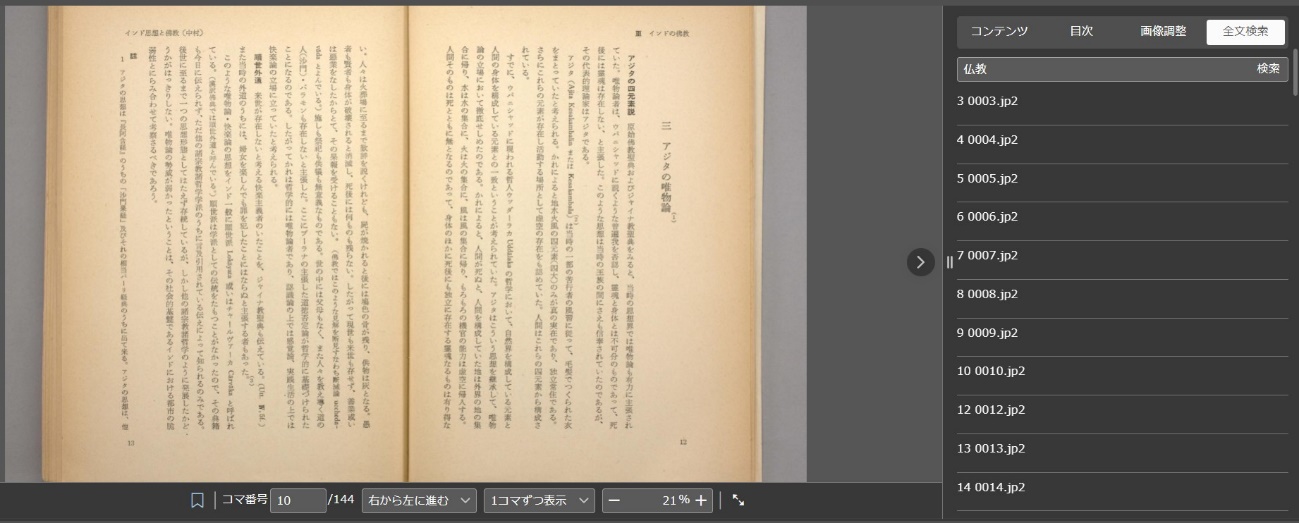
資料閲覧画面では、資料が見開き2ページのデジタル画像として表示される。この画面内で検索語をハイライト表示することは現時点ではできない(次世代デジタルライブラリーでは可能[4])。検索者は該当する見開き2ページから自力で検索語を探す必要がある。特に同一資料内に検索語が11個以上含まれる場合、検索語の特定は困難を極める。先述した通り、検索結果一覧では同一資料内で最大10件まで検索語を含む本文の抜粋とそのコマ数が表示される。しかし、そこで表示されない11件目以降を探す際、資料閲覧画面内の全文検索タブから検索を行っても、検索語を含むコマ数しか表示されない(図2)。そのため、検索結果に表示された該当コマ内に検索語が何個含まれているか分からない。たとえば、検索語「X」が同一資料中において第3コマに4回、第5コマに7回の計11回使われている場合、全文検索タブ内での検索結果には第3コマと第5コマというコマ数が表示されるのみで、そのコマ内のどこに何回検索語が現れるかを知るすべはない。
以上のように NDL デジタルコレクションにはまだまだ改善の余地があるものの、全文検索機能の実装により、近代日本研究を確実に前進させるツールとなるだろう。
人文情報学イベント関連カレンダー
【2023年12月】
-
2023-12-1 (Fri)~2023-12-3 (Sun)
DADH 2023: 14th International Conference of Digital Archives and Digital Humanitieshttps://dadh2023.chinese.ncku.edu.tw/%E9%A6%96%E9%A0%81
於・國立成功大學 -
2023-12-1 (Fri)~2023-12-3 (Sun)
NLP4DH & IWCLUL 2023: The Joint 3rd International Conference on Natural Language Processing for Digital Humanities & 8th International Workshop on Computational Linguistics for Uralic Languageshttp://www.wikicfp.com/cfp/servlet/event.showcfp?eventid=175880©ownerid=116977
於・早稲田大学リサーチイノベーションセンター(121号館) -
2023-12-2 (Sat)
シンポジウム「東洋学・アジア研究の最前線 ―AIの活用と課題―」http://www.tohogakkai.com/kyogikai-sympo.html?
於・東京大学国際学術総合研究棟文学部3番教室 -
2023-12-9 (Sat)~2023-12-10 (Sun)
じんもんこん2023: 人文学のためのデータインフラストラクチャー構築に向けてhttp://jinmoncom.jp/sympo2023/
於・オンライン -
2023-12-6 (Wed), 14 (Thu), 20 (Wed), 28 (Thu)
TEI 研究会於・オンライン
【2024年1月】
-
2024-1-11 (Thu), 17 (Wed), 25 (Thu), 31 (Wed)
TEI 研究会於・オンライン
【2024年2月】
-
2024-2-9 (Fri)
DH 若手の会「デジタル・ヒューマニティーズで“繋がる×広がる”人文学」https://www.nihu.jp/ja/event/20240209
於・オンライン -
2024-2-8 (Thu), 14 (Wed), 22 (Thu), 28 (Wed)
TEI 研究会於・オンライン
Digital Humanities Events カレンダー共同編集人
◆編集後記
11月18日に Toma Tasovac 氏をご招待して開催した DH 国際シンポジウムは、対面イベントでしたが、おかげさまで183名のご参加をいただき、会としても大変盛り上がりました。Tasovac 氏が提起した研究基盤の構築と維持に関わる問題は、まさに我が国においても取り組まれるべき課題であり、先達である欧州の例を参照しつつ、様々な方策を模索していく段階に来ているのだろうと思いました。
今月末が締切りの、ユネスコ「世界の記憶」事業の登録申請において、日本からの申請案件の一つとして増上寺の三大蔵、つまり、増上寺が家康の寄進以来現在に至るまで所蔵してきた宋版・元版・高麗版の3つの大蔵経が選定されました。この大蔵経群は12000巻にのぼるもので、現在広く用いられている『大正新脩大蔵経』の底本及び対校資料となったものです。さらに、この三大蔵は、先週の月曜日にデジタル画像としてすべて公開されました(浄土宗大本山増上寺所蔵三大蔵 )。三つの大蔵経の全画像が同時に公開されるというのは空前絶後のことであり、この学術への貢献の深さについて、増上寺の関係者の方々に深く感謝する次第です。そして、これらの大蔵経画像群は、国立国会図書館の古典籍用 AI-OCR を経て、SAT 大蔵経テキストデータベースの本文と行単位で対応づけられるようになりました。これは、年甲斐もなく、筆者がプログラミングをして実装したものです。テキストデータを読みながら、必要に応じて、底本や対校資料の該当箇所をすぐに確認できるのです。証拠画像を容易に確認できるようになることは、テキストの読みにも何らかの変化をもたらすこともあるかもしれません。今後が楽しみですね。(永崎研宣)
- コメントを投稿するにはログインしてください