人文情報学月報第124号
ISSN 2189-1621 / 2011年8月27日創刊
目次
- 《巻頭言》「人文学におけるデータ駆動型研究に向けた動向」
:一般財団法人人文情報学研究所 - 《連載》「Digital Japanese Studies 寸見」第80回
「日本学術振興会から『人文学・社会科学におけるデータ共有のための手引き』が公開」
:北海学園大学人文学部 - 《連載》「欧州・中東デジタル・ヒューマニティーズ動向」第41回
「京都大学デジタル人文学国際会議 KUDH2021開催記(1):デジタルテキストコーパス、自然言語処理、Universal Dependencies(コプト語、アイヌ語、古典中国語、古典日本語)」
:京都大学大学院文学研究科附属文化遺産学・人文知連携センター - 人文情報学イベント関連カレンダー
- 編集後記
《巻頭言》「人文学におけるデータ駆動型研究に向けた動向」
この数年、人文学においてもデータ駆動型研究という言葉が聞かれるようになってきた。比較的目立つものとしては、一つには2021年4月1日に Web サイトが開設された国文学研究資料館の「データ駆動による課題解決型人文学の創成」プロジェクト[1]、もう一つは令和4年度の文部科学省概算要求として登場した「データ駆動型人文学研究先導事業―「総合知」創出に向けたデジタル・ヒューマニティーズの強化―」[2]である。実際にデータで駆動できるかどうかはともかく、まずは、それぞれの背景について Web で確認できる範囲でみてみよう。
前者は、現在国文学研究資料館でまさに推進されている「日本語の歴史的典籍の国際共同研究ネットワーク構築計画」(歴史的典籍 NW 事業)の後継事業とされているものである[3]。文部科学省の「学術研究の大型プロジェクトの推進に関する基本構想ロードマップの策定―ロードマップ2020―」の一環であり、現在の歴史的典籍 NW 事業を発展させた先にたどり着くところとして考えるとわかりやすい。30万点の歴史的典籍のデジタル化を掲げた事業で蓄積されたデジタルデータとしての画像を対象として、画像そのものを分析したり、テキストデータ化したり、さらにそれを構造化して、より発展的な研究を促す。蓄積されたものをもとにさらなる発展をすることで社会的課題の解決にも貢献するという流れは、研究者ならずとも、一納税者としても大いに期待するところである。
一方、後者は、文部科学省のサイトにあるスライドをみると、これはあくまでも文科省の概算要求の段階ではあるが、令和4年度要求額・要望額が492百万円となっており、人文学としてはやや大規模なものが想定されているとみることができる。この後の予算編成の過程でこの額がどのようになるのかはまだまったくの未知数だが、この背景をたどってみると、文部科学省の科学技術・学術審議会の学術分科会に設置された人文学・社会科学特別委員会[4]が2021年の8月24日に公表した「「総合知」の創出・活用に向けた人文学・社会科学振興の取組方針」に対応するものであるようにみえる。この取り組み方針では、「総合知」の創出・活用を目指すべく、欧米でのデジタル・ヒューマニティーズの事例を引きつつ人文学におけるデータ駆動型研究とそのための環境整備の必要性を謳っており、上述のデータ駆動型人文学研究先導事業だけでなく、日本学術振興会において2018年度より進められている人文学・社会科学データインフラストラクチャー構築推進事業[5]についてもその拡充の必要性とともに言及している。
この特別委員会の検討の背景にあるのは、同委員会による第6回・第7回の会議だろう。それぞれ、資料[6]と議事録[7]が公開されており、誰でも参照できるようになっている。ここでは、これまでの各研究機関や研究者による関連する取り組みが様々に報告されている。テーマ自体はいわゆるデジタル・ヒューマニティーズと重なり合う部分が大きく、そこにある程度焦点があてられている様子がうかがえる。
ここには、そもそも時代の変遷によりデジタルに焦点が当てられるようになったという大きな背景はあるものの、これをもう少し具体的に学術政策的な流れからみていくと、日本では2002年に始まる21世紀 COE プログラムやそれに続くグローバル COE プログラムで一部の研究機関がその恩恵に浴して巨大な研究事業を推進し、そこにはデジタル・ヒューマニティーズ的な研究に取り組む機関も含まれていた。とはいえ、一部の機関はめざましい成果をあげたものの、国際的に卓越した教育研究拠点を形成するという事業の性格もあり、分野全体に波及するような形にはならなかったように思われる。
海外に目を向けてみると、米国や欧州で2006年頃から始まった米国人文学基金 NEH における Office of Digital Humanities 設置の動き(設置されたのは2008年)や、欧州人文学デジタルインフラ事業 DARIAH の設立準備など、人文学全般のデジタル研究環境としてのデジタル・ヒューマニティーズへの学術政策的な支援が始まっており、や研究データインフラの構築運営も含めて相当多くの研究者が携わる巨大な研究事業となり、それを踏まえた研究活動も盛んである。このような分野全体を志向する支援の一つとして、2014年度に文部科学省の大規模学術フロンティア促進事業として開始された上述の国文学研究資料館による歴史的典籍 NW 事業が挙げられることになる。実施機関は国文学を主とする研究機関ではあるものの、30万点のデジタル化を目指す対象となる歴史的典籍は人文学に関わる様々な分野のみならず、自然科学においても活用可能なものであり、デジタル技術を介して人文学を裨益しつつさらに総合的な知識の形成にも貢献する事業であると言える。このような事業の先に、より効果的なデジタル技術の活用形態としてのデータ駆動型人文学があるということは、事業の流れとしては理解しやすい。
一方、前出の「「総合知」の創出・活用に向けた人文学・社会科学振興の取組方針」の背景説明をみてみると、もう一つの文脈が読み取れる。すなわち、科学技術基本法の改正により、これまで科学技術の規定から除外されていた人文学・社会科学が、同法の振興対象である「科学技術」の範囲に位置づけられた。これを踏まえ2021年3月に閣議決定された「第6期科学技術・イノベーション基本計画」[8]では、「今後は、人文・社会科学の厚みのある「知」の蓄積を図るとともに、自然科学の「知」との融合による、人間や社会の総合的理解と課題解決に資する「総合知」の創出・活用がますます重要」であるとしている。この文書の56頁には「人文・社会科学の振興と総合知の創出」という項があり、人文・社会科学に関しても、研究データの管理・利活用機能だけでなく、図書館のデジタル転換等を通じた支援機能の強化も含めて、2022年度までにその方向性を定めようとしていることが示されている。このような大きなことについて、方向性が定められるまで、あと1年半、実質的にはおそらく1年くらいしかない。また、この基本計画を受けて2021年6月18日に閣議決定された「統合イノベーション戦略2021」[9]では「研究 DX を支えるインフラ整備とデータ駆動型研究の推進」が掲げられており、「データ駆動型研究の振興を図るため、人文・社会科学のデータプラットフォームの更なる強化策について、2021中に結論を導出するとともに、必要な取組を推進。」という文章が再掲もあわせて2カ所に登場する。すなわち、学術研究の分野全体が横断的に貢献することによって得られる総合知を創出すべく、そのための手段の一つとして(他にも「学術知共創」という取り組みがある)、今年度・来年度にかけて、データ駆動型人文・社会科学の環境整備を行う、ということになっているようだ。このようなことは時間をかけてじっくり合意形成していくべきものだが、一方で、デジタル技術が普及してもうかなりの時間が経過しており、分野としてこれまで何をしていたのかと言われるとやや苦しいものがある。分野によってはある程度合意形成されているところもあり、当面は、それらを踏まえつつ、諸外国の例を参照しながら進めていくということになるだろうか。
いずれにしても、人文学にデータ駆動型研究は馴染むのか、というのはこれからの大きな課題である。人文学のすべてに同じようにフィットすることはないが、何らかの形で適用できることもあるだろう。データ駆動型研究は、モデル駆動型の演繹的なアプローチではなく個別のデータに基づいて分析を行っていくという帰納的なアプローチであり、アプローチの方向性自体は親和的な分野も少なくないだろう。一方、基になるデータが何らかの基準で適正に作成されたものか、という点と、データを分析するアルゴリズムが適正かどうか、という点がまだ十分に了解できる段階ではなく、その点はこれからの喫緊の課題となるだろう。現在のところ、ゴールや正解が明解に見えているわけではないが、むしろ、そういう状況であってこそ、研究としての醍醐味がある。データ駆動型研究を通じて既存の人文学がより発展し、さらに新たな多様な価値を創り出していくことにつながればと期待するところである。
人文学・社会科学特別委員会(第7回)配布資料 https://www.mext.go.jp/b_menu/shingi/gijyutu/gijyutu4/048/gijiroku/1421468_00003.htm。
人文学・社会科学特別委員会(第7回)議事録 https://www.mext.go.jp/b_menu/shingi/gijyutu/gijyutu4/048/gijiroku/mext_00003.html。
《連載》「Digital Japanese Studies 寸見」第80回
「日本学術振興会から『人文学・社会科学におけるデータ共有のための手引き』が公開」
2021年11月8日、日本学術振興会の人文学・社会科学データインフラストラクチャー構築推進事業より、『人文学・社会科学におけるデータ共有のための手引き』が公開された[1]。人文学・社会科学データインフラストラクチャー構築推進事業(人社データインフラ事業)[2]は、「課題設定による先導的人文学・社会科学研究推進事業」[3]の一プログラムとして2018年に取組みがはじめられたもので、研究データの共有および利活用を行うための基盤整備を通じて、人文・社会科学の振興を図るとするもので、社会科学4拠点機関と人文科学1拠点機関で構成される[4]。
この『人文学・社会科学におけるデータ共有のための手引き』(以下『手引き』)は、人社データインフラ事業運営委員会委員の松本康氏を部会長とする8名の作業部会によって策定されたものだとのことである。社会科学における(とくに社会調査・統計の)データ共有について詳述し、人文学については、コラムや注記のかたちで補っているということである。一読したかぎりでは、注記で触れられている例はほとんど見られず、基本的にはコラムで述べられていると考えてよい。メタデータの章については、社会科学パートと人文学パートがそれぞれ分かれている。その附録として、人文学研究データの説明文書の例が与えられており、メタデータというものについての概観を得ることができるようになっている。全体的には、人文学側からは、人文学向けと明記された箇所を読めばひととおりの内容が把握できるようになっている。とりわけ、刊行テクストを扱う分野の記述は例もあって分かりやすくなっている。
同事業の取組みとして、「人文学・社会科学総合データカタログ」、略して JDCat というデータカタログがある[5]。このカタログは、2021年7月15日に公開され、11月17日に人文学からのデータを追加して正式公開されたとのことである。JDCat は、前述の拠点機関を手始めに、提供されている研究データを横断的に検索可能としているものである。社会科学分野においては、社会調査や社会統計に関するデータが中心であり、人文学分野においては、東京大学史料編纂所の持つ史資料が提供データの基礎となっている。今後拡充を図りたいとするが、このような事業のつねで、その方向性は今のところ明らかにされていない。JDCat では、メタデータのスキーマが定義されており[6]、このスキーマに沿って、データカタログに各機関が登録する仕組みとなっているが、とくだん、解釈の妥当性などの検証はされていないとのことであるから、利用者は利用の際、登録機関に注意する必要があろう。また、バージョンの観念があるようであるが、微細な変更もバージョン番号が変るのかといった運用規則は、公表されていない。
人社データインフラ事業では、今後、研究データのオンライン分析システムの提供も目指すということであり[7]、このカタログはそのデータ取得の出発点となることと予想される。『手引き』も、このような事業の一環として理解されるならば、JDCat を取り巻く発想がまとめられたものとなっているのであろう。すなわち、スキーマによって管理される研究データを作り、守り、活かしていくような世界を目指すというものである。とくに人文学では、データの囲い込みがこれまで著しかったといえるが、いまやそのような秘儀を伝える後継者もなく、退職とともに雲散するケースが増えてしまっているように思う。
近時、データの継承はとかく問題で、今月も日本言語学会第163回大会で「最後のアナログ言語調査資料:危機に瀕した言語データの発掘と救出」と称するワークショップが催されたほどである[8]。そこで取り上げられたもののうち、湯川データ(湯川恭敏氏の蒐集にかかるバントゥ語のフィールドワーク資料)については、前々職のときに概略を聞いたけれども、調査者歿後に残された未公開のデータを含む磁気音声テープを含み、そのデジタル化を業者に委託したというものだった。デジタル化できなかったテープがあったかは記憶していないが、いまできたとしても10年後であればできたともかぎらず、また、してくれる後継者がいるともかぎらない(なお、デジタル品であっても MD テープや CD-R の劣化など、悩みの種には尽きないことは言うまでもない)。そのようななかで、制度としてデータを守っていくほうが、データ継承の確度が上がり、かつ、利用も円滑に行えるということは、図書館を見れば分かるだろう。本が残ってうれしく思うならば、データが残って役に立つ未来のための制度にも加担すべきなのである。そのような点で、この『手引き』は、そうは思ってもどこから手を付けてよいか分からない人のためのよい導入となろう。『手引き』の改訂版において、人文学編が独立するほどに活性化すれば、なお喜ぶべきことである。
なお、『手引き』はよくある PDF 形式にくわえて、DITA 形式でも提供されている。DITA 形式は、XML 形式の出版形式のひとつであるが[9]、変換すれば(あるいは DITA 形式に対応した編集閲覧ソフトウェアがあれば)よくある Windows のヘルプファイルのようなかたちで見ることができ、稿者のように飛ばし読みをするには、こちらのほうが便利だったことを附言しておきたい。
・大阪商業大学 JGSS 研究センター
・慶應義塾大学経済学部附属経済研究所パネルデータ設計・解析センター
・東京大学社会科学研究所附属社会調査・データアーカイブ研究センター
・一橋大学経済研究所、
人文学が
・東京大学史料編纂所
である。
《連載》「欧州・中東デジタル・ヒューマニティーズ動向」第41回
「京都大学デジタル人文学国際会議 KUDH2021開催記(1):デジタルテキストコーパス、自然言語処理、Universal Dependencies(コプト語、アイヌ語、古典中国語、古典日本語)」
2021年10月2日、16日、23日に京都大学大学院文学研究科附属文化遺産学・人文知連携センター主催で京都大学デジタル人文学国際会議 KUDH2021 “Digital Transformation in the Humanities” が開催された[1]。本センターで助教を勤めている筆者は、このオンライン国際会議のオーガナイズを行った。本会議は、京都大学で DH を行っている研究者の研究テーマを研究している、ヨーロッパを中心とした海外の研究者に最新動向を発表していただき、京都大学の DH 研究者も発表し、討論するという方式で行った。
セッションは3つに分かれる。第一セッションは、デジタルテキストコーパスと Universal Dependencies を中心としたセッションである。今回はこの第一セッション前半の開催記を書きたい。京都大学側の研究者は、北東アジア諸言語の Universal Dependencies の枠組みによる自然言語処理において近年目覚ましい業績をあげている、京都大学人文科学研究所附属東アジア人文情報学研究センターの安岡孝一氏と、ヴェーダ語文献の時代推定・地域推定を計量文献学の手法で行っている、白眉センターの天野恭子氏である。
この第一セッションでは、京都大学以外の発表者は、アメリカ、ドイツ、チェコから集まった。はじめは一日でこのセッションを行う予定であったが、参加者の都合上、10月2日の前半と23日の後半に分けて発表されることとなった。
前半の10月2日は、ジョージタウン大学のアミール・ゼルデス氏と安岡孝一氏が発表した。ゼルデス氏は、氏とオクラホマ大学のキャロライン・シュルーダー氏が率いている、米国人文科学基金の Coptic SCRIPTORIUM プロジェクト[2]の主任研究者である。このプロジェクトは、コプト語のタグ付き多層コーパスを開発し公開するためのプロジェクトであり、筆者も2014年から research member として参加している。ゼルデス氏の研究発表は、コプト語の Universal Dependencies (UD) の枠組み[3]による、機械学習を通した統語解析であった。このプロジェクトの、コプト語のための自然言語解析ソフトは、Coptic NLP Service[4]というウェブサイトで公開されている。Unicode で翻刻された、コプト語のテキストのプレインテキストファイル、または、TEI ガイドライン[5]に準拠する形で書かれた XML ファイルをテキストボックスの中に入れ、Process ボタンをクリックすると、レンマ、品詞、UD による統語、外来語、固有表現抽出などが SGML 形式でタグ付けされる。出力された SGML を、TEI XML の <body> と </body> の間に入れるだけで、TEI XML のコーパスとして用いられるほか、GitDox[6]という、共同作業用の SGML コーパス編集ウェブアプリによって、自然言語処理のエラーを容易に集団で修正できる。UD の枠組みでの統語情報は、DepEdit[7]という統語ツリーエディタで視覚的に修正することができる。作られたコーパスは、ベルリン・フンボルト大学が開発した、ANNIS[8]という多層(マルチレイヤー)コーパス表示アプリケーションでウェブ上で公開できる。多層コーパスとは、テキストに付随して、品詞、統語情報、レンマなどの様々なレベルのタグが、レベルごとに層状になるように表示されるものである。これは以下の画像をみていただくと分かりやすい。
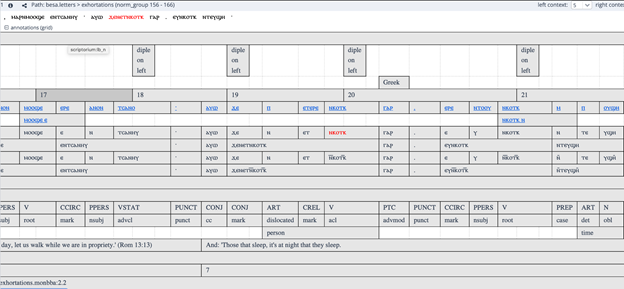
ゼルデス氏は、Coptic SCRIPTORIUM を紹介した後、自然言語処理の解析器を MaltParser ベースから、近年自然言語処理の機械学習でよく用いられる BERT ベースに変更するなど、プロジェクトの最新動向について述べた。
1日目の次の発表者は、京都大学の安岡孝一氏である。安岡氏は、東アジア諸言語の、UD の枠組みでの、統語解析、よりよく知られた言い方で言えば、係り受け解析に関する発表を行った。UD とは先ほどもゼルデス氏の発表で出てきたが、ここで一言説明を入れたい。UD は、Google、スタンフォード大学、プラハ・カレル大学の別々の依存文法による言語の統語情報を解析するプロジェクトが統一されてできた枠組みである。統語とは、単語がどのように組み合わさって文になるかを指す。依存文法は、2単語間の主従関係を軸に、文の構造を明らかにしていく統語分析法である。それに対して、句構造文法、あるいは構成文法は、単語同士が結びつき句を形成し、さらに句と別の単語、あるいは別の語が結びついて新たな句を形成し、最終的に文を形成するという、階層的な、句の入れ子構造を持つ。この入れ子構造は再帰性と呼ばれる。統語情報を機械で解析する上で、この句構造文法と依存文法が大きな選択肢の2つとなっているが、句構造文法は、依存文法よりも、より複雑であり、また、語順が自由な言語などは、句構造文法では、語の移動など様々な現象を考えないといけない点において、依存文法の方が、単純で開発にかかるコストは少なく、かつ、様々な言語に容易に適用できる。UD は依存文法の枠組みの1つであり、Universal という名が示す通り、世界中のどの言語でも対応できることを目標に設計された枠組みである。UD には UPOS という、どんな言語でも、同じ品詞タグを用いることが定められており、また、統語関係のタグも統一されている。UD のコーパスは、欧米中心に作られてきたためか、やはりヨーロッパの諸言語が数の上では多く、特にスラブ諸語のコーパスの多さには目を見張るものがある。もちろんヨーロッパの諸言語も多様であるが、枠組み自体が、ヨーロッパの言語の地域特性を踏まえたもので、他の地域の言語にもそのまま適用でき、本当に Universal であるのか見極めることが必要である。この点、最初のゼルデス氏は、コプト語という、アフリカ北東部の言語で、ヨーロッパの諸言語には見られないような特徴を多数持つ言語の例を提示した。そして、安岡氏は、古典中国語、古典日本語、アイヌ語と、ヨーロッパからは遠く離れた東アジアの諸言語の UD による統語解析について発表した。
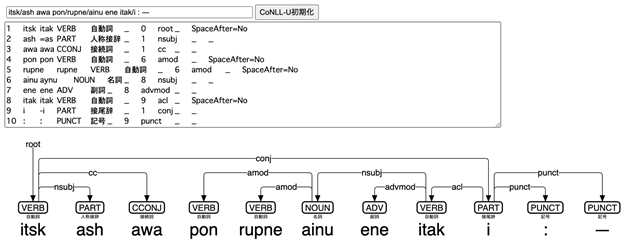
安岡氏は deplacy[12]と呼ばれるプログラムを開発し、spaCy、Stanza、UDPipe など様々な既存の自然言語処理エンジンを用いて、様々な言語の統語を解析するシステムを Google Colaboratory 上に置いている[13]。この deplacy では、古典中国語、古典日本語以外にも、コプト語を含む様々な言語を分析することができる。安岡氏は、東アジアの諸言語の UD による統語解析器開発を踏まえ、UD の諸問題と改善案を議論した。特に、アイヌ語は、世界中の諸言語を類型化して比較し、普遍性や多様性を分析する言語類型論では、一単語に多数の形態素が入りうる複統合語に分類され、同時に、目的語の名詞を動詞に複合させ結合価の操作をする名詞抱合を持つ抱合語にも分類される。UD のトレーニングデータには、南北アメリカ大陸、コーカサス山脈、ニューギニア島、オーストラリアの少数言語など、抱合を持つ言語や複統合語が少数あるが[14]、アイヌ語には、『アイヌ神謡集』だけでなく、国立アイヌ民族博物館アイヌ語アーカイブ[15]や、国立国語研究所のコーパス[16]など比較的多くのデジタル化された言語資料が残っている。このような、1語内の多数の形態素、また、目的語が動詞内に抱合される現象をどのように UD で捉えるかが課題となる。また、カタカナとローマ字の2つの表記方法があり、表記法ごとに、語境界の表記法が異なることから、それらをどのように取り扱うかも問題となる。安岡氏は、フランス語の de と le の2語が融合した du を記述する CoNLL-U 形式の記法の1つを採用し、これらの表記法の違いによる語境界の問題を解決している[17]。
第一セッション前半の録画は、京都大学大学院文学研究科附属人文知連携センター人文知連携拠点のホームページ[18]で公開されている。詳細はぜひこの録画をご覧いただきたい。
人文情報学イベント関連カレンダー
【2021年12月】
-
2021-12-3 (Fri)
史料編纂所 公開研究集会「新たな画像公開方法とデジタル連携」於・オンラインhttps://www.hi.u-tokyo.ac.jp/assets/news/2021/1203公開研究集会チラシ.pdf
-
2021-12-3 (Fri)
2021年度「NDL デジタルライブラリーカフェ」於・オンライン -
2021-12-11 (Sat)~2021-12-12 (Sun)
じんもんこん2021:「越境する」デジタルヒューマニティーズから「総合知」へ於・オンライン -
2021-12-13 (Mon)
日本学術会議公開シンポジウム「科学的知見の創出に資する可視化(7):人間を識り活かす総合知をもたらす「視考」」於・オンライン -
2021-12-18 (Sun)
デジタルアーカイブ学会 DA フォーラム於・オンライン
Digital Humanities Events カレンダー共同編集人
◆編集後記
たまたま、どうしても自分で巻頭言を執筆しておきたいテーマが続いてしまい、2回連続での巻頭言となってしまいました。次回以降はまた色々な方々にご執筆いただきますので ご安心ください。
かなり時間をかけて、若手のみなさんと構築作業を続けてきた Digital 法寶義林を、11月27日(土)に 開催されたデジタル仏教学のシンポジウムでようやく公開できました。仏典や僧侶、そして、僧侶の移動や事績についてのデータベースとしてご利用いただけます が、研究データの構築にご関心がおありの方には、人文学テキストの研究データのデファクト標準である TEI/XML で作成したファイルを用いたソリューションの一つとしても見ていただければと思います。このサイトの作り方も、近々、筆者のブログで少しずつ公開していきますので、TEI/XML ファイルから任意のデータを抽出したり、それを Web サイト上の地図や年表にプロットしたりすることに興味をお持ちの方は、お楽しみにしていてください。
なお、残念ながら今月号には間に合わず、もうじき告知ができると思いますが、1月22日(土)に DH 関連のイベントを開催する予定です。この日はぜひ空けておいていただけますよう、 よろしくお願いいたします。
(永崎研宣)
- コメントを投稿するにはログインしてください