人文情報学月報第126号【前編】
ISSN 2189-1621 / 2011年08月27日創刊
目次
【前編】
- 《巻頭言》「文献をデジタル化する意義」
:東京大学大学院人文社会系研究科 - 《連載》「Digital Japanese Studies 寸見」第82回
「「文化財論文ナビ」がサービス開始」
:北海学園大学人文学部 - 《連載》「欧州・中東デジタル・ヒューマニティーズ動向」第43回
「Universal Dependencies の発展と言語類型論・歴史言語学研究への応用:京都大学デジタル人文学国際会議 KUDH2021「Digital Transformation in the Humanities」3日目 Session 1b 開催報告・前編」
:京都大学大学院文学研究科附属文化遺産学・人文知連携センター
【後編】
- 《連載》「デジタル・ヒストリーの小部屋」第1回
「「シェアハウス」の住人」
:千葉大学人文社会科学系教育研究機構 - 人文情報学イベント関連カレンダー
- イベントレポート「シンポジウム「人文情報学による仏教知識構造化の新潮流」」
:東京大学文学部インド哲学仏教学研究室 - 編集後記
《巻頭言》「文献をデジタル化する意義」
文献の電子化にどんな利点があるかということについて、いまさら書き連ねる必要はないと思うが、私が仏教学の研究を始めた1990年代半ばは、まだコンピュータを使った文献研究などは珍しかった。そうした中で、私の指導教官だった故江島惠教先生は、早くからコンピュータを利用した仏教文献の検索の有用性に着目し、大正新脩大蔵経(専門家の間では大正蔵とよんでいる)の電子化を試みた。大学院の修士課程の学生だった私もアルバイトで入力作業をお手伝いした。(ちなみに私はそのために初めてコンピュータを買った。)当初は刊本を見ながら手作業で入力していたそうだが、私が参加したころには OCR で読み込んだデータを刊本と突き合わせて校閲するというやり方になっていた。それでも当時の OCR の精度は低く、結局、半分以上は手で入力しているようなものだった。それが現在の SAT データベースのもととなる作業だった。詳しいことはすでに紹介されているのでそちらを参照してもらいたい[1]。
江島先生の野望(?)は大正蔵の入力にとどまらなかった。日本印度学仏教学会で発行している『印度学仏教学研究』という学術雑誌の論文データベースを作ろうと密かに構想していた。1990年代半ばはインターネットの黎明期で、いまのようにネットで公開することは考えておられなかったと思う。おそらく、フロッピーディスクで配布する予定だったのだろう。しかしながら、これは構想だけで終わった。当時は手書きの原稿もまだ当たり前で、版下も活字を拾っていた。時代は平成に入っていたが、印刷業者などにはまだ昭和の雰囲気が多分に残っていた。1990年代後半になると、ようやく電算写植というものが登場し、コンピュータが出版技術に導入されたが、そうしたデータを論文読者が利用するということは考えられていなかった。また、こうした技術的な制約だけでなく、論文は読むものだという考えも根強くあり、論文のデータベース化自体に抵抗を感じる人も多かったそうだ。しかし、オープンアクセスが主流となり、論文の探し方も、成果の公開方法も大きく様変わりした。江島先生に先見の明があったということだろう。
そのような経緯があったので、文献資料は電子化しておくべきものだと、研究を始めたころから当たり前のように思っていた。ただ、電子化といっても学生時代はワードで入力し、異読もワードの脚注機能を使っていた。特定のアプリケーションに依存したデータには汎用性がないということに気づかされたのはかなり後のことで、それからはテキストファイルで保存するようにしたが、単なるテキストファイルでは、異読を注記すること一つを取ってみても非常に不便に感じたものだった。そうしたときに、人文情報学研究所の永﨑研宣先生から教えていただいたのが XML であり、文献研究のために XML のタグの標準化を提唱した TEI ガイドラインだった。タグを使って様々な情報をマークアップするという手法は、文献資料に調査や分析の結果をメモしたり、カードを取る作業に似ていて、文献研究と非常に相性がよかった。また文字として表に出ていない情報を要素内の属性として記述できることも大きな魅力だった。私の場合はサンスクリット語やチベット語で書かれた仏教の哲学文献が研究対象なのだが、そうした文献では出典も明記しないまま、ときには引用であることを示唆しないまま、ほかの典籍から文章が引かれていることも珍しくない。そのような場合に、タグを使って当該箇所が引用であると示すことや、その典拠がどこにあるかを記録しておくことに対して、XML は非常に有効である。これは XML の特性を知っている人なら容易に理解できるであろう。
このように、文献資料の電子化は、単に文字列を入力することではなくなってきている。これは電子テキストが単なるツールではなく、研究成果そのものであることを意味している。実際、いま行っている共同研究では、『阿毘達磨集論』(「あびだつまじゅうろん」と読む)という仏教文献に対して、チベット語で書かれた注釈書の分析を行っているが、何をマークアップするのかということを議論すると、研究会の参加者の間で、各人各様の意見が出る。例えば、段落構成に着目し、議論の階層構造の分析を重視する視点もあれば、注釈の内容に着目した分析を検討したいという意見もある。つまりそれぞれの研究者の視点が、マークアップの仕方に反映するのである。このような電子テキストは、いわば個々の研究者の読書ノートでもあり、それをほかの研究者が活用するのは、読書体験の追体験とも言えるだろう。(ちなみに『阿毘達磨集論』については、これまでの研究状況を一変させるような新資料が21世紀になって数多く発見され、仏教文献学の観点からも研究の進展が期待されている[2]。)
どんな形であれ、文献資料の電子化は、単なる作業ではなく、研究そのものになってきた。だから、決まりきったフォーマットがあるわけではなく、様々な観点があっていい。電子テキストの意義が変わってきていることを理解し、その構築に携わっていくことは、これまで意識していなかった文献研究の方法論を顕在化し、反省することにつながる。そしてそれが、より理想的な電子テキストの構築につながっていく。
もともと、江島先生が大正蔵のテキストデータベースを構築しようとした背景には、江島先生よりも一世代前の東大教授だった故平川彰先生の影響が大きかったと聞いている。平川先生は大正蔵を熟知されていて、「こういう文章を探しているのですが」と尋ねると、大正蔵の何巻のどこそこにある、と答えることができたそうである。まるで生きたデータベースである。江島先生はコンピュータを利用することで、平川先生の学識に匹敵する研究手法を確立することを模索しておられた。またそれによって、新たな研究の方向性が生まれることを期待されていたと思う。今日の人文情報学は、そうした意味で新しい人文学の成果として認められるべきものとなりつつある。若い世代に期待すると同時に、私自身も研鑽を深めたいと、あらためて思う。
執筆者プロフィール
《連載》「Digital Japanese Studies 寸見」第82回
「「文化財論文ナビ」がサービス開始」
2021年3月17日、奈良文化財研究所(奈文研)が、「全国遺跡報告総覧」[1]内において「文化財論文ナビ」のサービスをはじめたことを発表した[2][3][4]。これは、文化財を所蔵する機関などが雑誌や報告書のかたちで刊行した論文を検索するものである。開始から時日が経ってしまっており、機能追加や[5]、関係者からの紹介などもすでに公にされているが[6]、あらためて整理しておこう。
まず、本サービスが置かれる「全国遺跡報告総覧」は、島根大学附属図書館を中心に進められていた「全国遺跡資料リポジトリ・プロジェクト」の跡を受けて設けられたもので、日本全国の埋蔵文化財発掘調査報告書などを主とした文化財報告書を全文電子化し、インターネット上での検索・閲覧を可能にした主題リポジトリであるという[7]。奈文研は、ホストとしてシステムの管理を行い、報告書等を刊行する主体からのデータ提供を受ける形で参与している。データベース参加への説明会も頻繁に行われているようである[8]。
奈文研には、この情報などを活かした「文化財総覧 WebGIS」などもあり[9][10]、埋蔵文化財情報センターとしての蓄積を最大限活かしたサービスを展開している。埋蔵文化財の調査は、市民の経済活動や居住などに関わることであり、文献の世界でいう GIS 活用とは切実さが異なるのを強く感じる。
さて、この「文化財論文ナビ」は、文化財(埋蔵文化財に限定されない)にかかわる論文を刊行する機関が、その書誌情報を登録、公開するためのサービスである。全国遺跡報告総覧ですでに登録されている刊行物について登録ができ、登録事項は著者・題名・掲載ページや、所在の都道府県あるいは世界の地域、時代、種別(文化財、遺跡、遺物の材質、研究分野、テーマ)、キーワードなどである。「CiNii」上の NAID があれば、それも登録ができる。
このようなものが準備された理由は、[3]やそこで紹介される持田論攷[11]によれば、国立国会図書館の「雑誌記事索引」[12]で対象外である発掘調査報告書や市町村立の博物館や埋蔵文化財センターの刊行物に収録される論文が、そのために「CiNii Articles」を筆頭とする大規模論文データベースなどで検索できない状況が続いてきたことによる。「雑誌記事索引」は、収録範囲を都道府県より狭い地域を対象とする雑誌などを除外しており、市町村立機関はそれに当たらないためと考えられている。しかしながら、それはこれらの雑誌が読むに値する論攷を掲載していないことを意味しないことから、学術情報流通改善の観点から、このデータベースが整備されたという。
これまでも、「全国遺跡報告総覧」内に刊行物の目次情報を副次的に持たせることができたが、構造化されたデータではなかった。また、奈文研でも「遺跡報告内論考データベース」や考古学系の「CiNii Articles」未収録雑誌[13]を対象とした「考古関連雑誌論文補完データベース」を構築していたが、外部連携をしていないという憾みがあった。それが、「文化財論文ナビ」としてあらためて整理し、国立情報学研究所の「学術機関リポジトリデータベース」と繫がったことで、外部書誌データベースとの連携が可能となり、国立国会図書館の「国立国会図書館サーチ」や、当面の目標であった「CiNii Articles」での検索が可能となったとのことである。個々の書誌アイテムには DOI が附与され、安定したアクセスが可能となっている。
[6]は持田誠氏と高田祐一氏の連名記事で、前半で[3]に述べたような「文化財論文ナビ」整備の背景、後半でそのものの紹介がなされている。持田氏執筆箇所では、市町村立機関と都道府県立以上の機関とで扱いの差があることが述べられ、高田氏執筆箇所では、分野ごとの共同リポジトリの拡充に触れつつ、最終的には、「雑誌記事索引」への採録を重視する。もちろん、不採録の理由として差別的な扱いがあることは好ましくないことはとうぜんの前提としても、かつての論攷[11]では持田氏は国立国会図書館の能力の限界を指摘し、分野ごとの共同リポジトリを解決策として挙げていながら、高田氏執筆箇所であるとはいえ、連名執筆の論攷[6]ではデータの協力体制のようなことよりも、現状の「雑誌記事索引」への採録にこだわっているように見受けられるのは、すこし意外に映った。雑誌記事索引は、むしろ、このような雑誌索引を整備できない分野や、特定の分野の興味からの採録では網羅できないような雑誌のデータ採取に注力したほうがよいという議論もありうる(じっさい、医学分野では医学中央雑誌刊行会の「医中誌 Web」[14]などに大部分を委ねて採録を中止している)。また、分野別索引を整備できる分野は、専門機関ないし学会が、継続的に整備しつづけられるよう、予算化を求めて分野の基礎力を高めることだってあってよい(もちろん、高田氏が指摘するように、人材の確保や機運の醸成が容易だと言うのではないが、どんな分野にも社会的側面はあり、個々人が研究だけしていては分野としては成り立たないのである)。国立国会図書館の「雑誌記事索引」への選定がある種のランク付けとなっているのは、エルゼビアの「Scopus」やクラリベイト・アナリティクスの「Web of Science」のような商業索引とちがって、好ましいことではない。学術の未来に向けて、健全な方向へ進むことが望まれる。
持田・高田両氏論攷への評が長くなったが、分野別索引としても「文化財論文ナビ」は重要なあり方を示したものと考える。発信の根幹には、継続して総合的に情報を集約する体制がなければならない。「雑誌記事索引」の存在におんぶに抱っこになるようなことは、それこそ死活問題となるのだろう。
高田祐一ほか「発掘調査報告書全文データベース「全国遺跡報告総覧」の開発:遺跡情報のプラットフォームを目指して」『じんもんこん2015論文集』2015年 http://id.nii.ac.jp/1001/00146536/。
E1700 - 「全国遺跡報告総覧」の機能と期待される効果 | カレントアウェアネス・ポータル https://current.ndl.go.jp/e1700。
《連載》「欧州・中東デジタル・ヒューマニティーズ動向」第43回
「Universal Dependencies の発展と言語類型論・歴史言語学研究への応用:京都大学デジタル人文学国際会議 KUDH2021「Digital Transformation in the Humanities」3日目 Session 1b 開催報告・前編」
前々回から10月に開催された、京都大学大学院文学研究科附属文化遺産学・人文知連携センター人文知連携拠点主催の、京都大学デジタル人文学国際会議 KUDH2021 “Digital Transformation in the Humanities” の開催記を記している。今回は本会議の3日目・Day 3(10月25日)の Session 1b 開催記の前編である。
Day 3は、Day 1の Universal Dependencies(UD)を用いたコーパス開発のセッション Session 1a の続きである。Session 1は、本来1日でやる予定だったものが、講演者の都合などによって、2日に分割された。Session 1a は、古典中国語、古典日本語、アイヌ語、そして、コプト語の UD 解析器の実装などであったが、Session 1b は、ヴェーダ語、ラテン語、古典ギリシア語、スラブ諸語とインド・ヨーロッパ諸語に結果的には偏ったが、UD の理念や問題点など UD の根本に関わる重要な議論が展開された。会議の録画は、「京都大学文学研究科・文学部人文知連携拠点 成果公開 WEB」および大会公式ホームページ上で公開されているので、ぜひご覧いただきたい[1]。
最初の発表は、プラハ・カレル大学教授のダニエル・ゼマン氏で発表タイトルは、“Universal Dependencies: Comparing Languages in Space and Time”(Universal Dependencies:通時的・地理的に諸言語を比較する)であった。プラハ・カレル大学は、UD の創立メンバーの1つである。ゼマン氏は、UD の発展に非常に貢献した人物の一人であり、現在、UD の GitHub リポジトリ上で様々な言語の UD コーパスの修正などを頻繁に行っている。
UD は、目的を同じくする、プラハ・カレル大学、Google、スタンフォード大学の3つの依存文法プロジェクトが、統合されて形成された。日本では、依存文法による統語解析は係り受け解析と言われるが、これは日本独特の用語で、「係り受け解析」は、英語の dependency analysis「依存解析」に対応する。おそらく、日本語では係り結びなど、ある語が別の遠くの語の形態に影響を及ぼす文法事象があるため、「依存」というよりも「係り受け」と言ったほうが、わかりやすかったのだろう。「依存」とは、文中である語が別のある語に支配されている状況、すなわち、逆から考えれば、ある語が別のある語に依存している状況である。ヨーロッパでは、スイスのフェルディナン・ド・ソシュール(1857–1913)の構造主義言語学の創立以降、いくつかの依存文法のフレームワークができた。特にルシアン・テニエール(1893–1954)のものは有名であるが、後にイギリスのリチャード・ハドソン(1939–)のワード・グラマーなどかなり特色のあるものもある。一方、アメリカでは、アメリカ構造主義言語学後期に、ゼリグ・ハリス(1909–1992)などにより句構造文法(構成文法)が導入され、それは、後に、ハリスの弟子のノーム・チョムスキー(1928–)によって、生成文法の中核に組み込まれ、爆発的に発展していった。依存文法は、文中のある単語と別の単語、すなわち二単語間の依存関係を文内の全ての単語で記述していくものであるが、句構造文法では、単語と単語が句を形成し、さらに句と単語も句を、句同士も句を形成する。すなわち、句構造文法は、単語が単位である依存文法よりもより大きな単位を設定し、大きな単位である句の中にさらに句が入り、最終的には単語に分解される入れ子構造を想定する。統語情報をツリー上に図示した図を統語樹というが、図1の左が依存文法で書いた統語樹であり、右が句構造文法で書いた統語樹である。
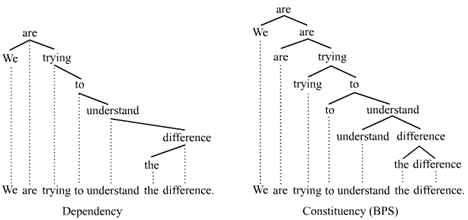
図1の2つの統語樹を比較すると、左の依存文法は入れ子構造を想定しない分、よりフラットであるのに対し、右の句構造文法は構造が複雑で階層的であることがみてとれる。英語や中国語など語順が比較的固定されている言語では、句構造文法での記述も苦ではないが、古典ギリシア語やラテン語、サンスクリット、また現代語ではチェコ語など、形態論がリッチで語順が比較的自由な言語では、句構造文法で統語情報を記述する際に、語の移動等様々な操作を加えないと説明できない。これらの言語ではコンピュータで自動統語解析する場合、依存文法の枠組みを用いたほうが遙かに容易である。たしかに、句構造文法でのほうが、より精緻な検索ができるものの、依存文法でも、位置と依存関係の情報をクエリに入れれば、ほとんどの構文を検索することは十分可能である。
さらに、UD では、この依存文法の依存関係に主語、述語、格付与など、機能的なラベルをつけることが求められており、単語にも品詞のラベルが与えられている。そのため、例えば、「形容詞があり、その形容詞に前に名詞があって、形容詞が名詞を修飾し、その名詞が文の主語となって、その文の動詞が主語よりも前にある構文」など非常に細かい条件を指定して構文を検索することができる[3]。
ゼマン氏の発表では、UD の歴史と理念、そして、現在 UD の歴史がどれほど歴史言語学や言語類型論の研究に貢献しているかが例とともに紹介された。とくに、UD は、現在(Ver. 2.9)、122言語で217のツリーバンクが作られており[4]、それらの言語で、理想的には同じ方法統語情報が記述されている。そのため、それらの122言語全てである構文を検索する、または、主語などの位置の統計を取る、など様々な検索・分析をすることができる。言語類型論は、世界中の言語の文法や音韻特徴を類型化して、それぞれの類型間での規則性や傾向などを探っていく学問であるが、この UD は、徐々に、この分野で存在感を増している。言語類型論では、基本語順で類型化し、世界の言語の41パーセントは SOV 型で[5]、次が SVO 型…などといった大雑把な類型化と統計がなされてきた。しかし、UD によって、その基本語順がどれだけ頻繁なのか、他の語順がどれだけの割合で出てくるのか具体的な数値を出し、統計的な分析が可能となる。歴史言語学でも、UD を用いた研究成果は増えている。UD はスラブ諸語に限っては、最も古く記録されている古代教会スラブ語から、それぞれの地域の教会スラブ語、そして現代スラブ諸語と、様々な段階のものがあり、UD を用いて、それぞれの段階での語順などを比較し、あるスラブ語では歴史的に語順の自由度が減っていったなどといった分析を行うことが可能となった。このように、UD は、多言語間の統語論の比較に大きな貢献をする可能性を有している。図2は、動詞が文末に来る割合を各言語の UD ツリーバンクで示しており、韓国語がその割合が最も高く、イギリスのケルト諸語の1つであるマン島語が最も低い。
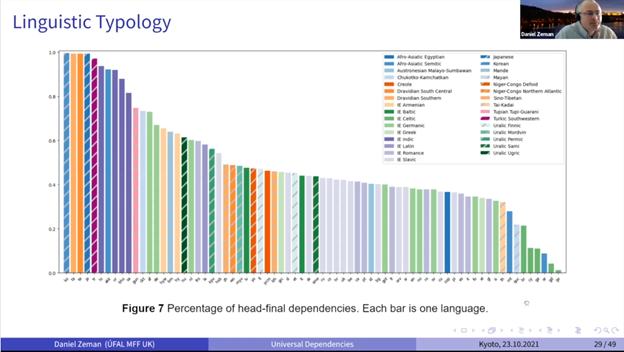
今回はゼマン氏の発表だけに注目したが、次回は後編として天野恭子氏およびジュゼッペ・チェラーノ氏の発表について述べる予定である。天野氏の発表は、ヴェーダ語文献の年代推定・地域推定とコーパス開発について、チェラーノ氏の発表は UD の問題点についてであった。2月11日には、天野氏が主宰するプロジェクトの国際シンポジウム “Ancient India meets Data-Science” 「古代インドとデータサイエンス」が開かれる[7]。天野氏、オリヴァー・ヘルヴィック氏、夏川浩明氏、京極祐希氏そして著者が登壇予定である。この国際シンポジウムに関しても折に触れて参加記・登壇記を執筆させていただこうと思う。
.jpg){kind=link}
- コメントを投稿するにはログインしてください