人文情報学月報第131号(DH2022特集号)【中編】
ISSN 2189-1621 / 2011年08月27日創刊
目次
【前編】
- 《巻頭言》「デジタル人文学における多様性のさまざまな側面」
:アムステルダム大学コンピュータ文学研究科 - 《連載》「Digital Japanese Studies 寸見」第87回
「DH2022東京記念レクチャーシリーズ「デジタル・ヒューマニティーズへの招待」の開催と日本のDHの将来」
:北海学園大学人文学部 - 《連載》「欧州・中東デジタル・ヒューマニティーズ動向」第48回
「手書きテキスト認識(HTR)・自動翻刻ツール eScriptorium と対訳アライメント・ツール Ugarit:DH2022 東京ワークショップ・チュートリアル解説」
:人間文化研究機構国立国語研究所研究系
【中編】
- 《連載》「デジタル・ヒストリーの小部屋」第6回
「イベントレポート「DH2022東京記念レクチャーシリーズデジタル歴史学のジャーナルがもたらす新たな世界」」
:千葉大学人文社会科学系教育研究機構 - 《特集 DH2022》「DH 分野最大の年次国際学術大会が7/25~29に開催されます」
:一般財団法人人文情報学研究所
【後編】
- 《特集 DH2022》「DH 分野最大の年次国際学術大会が7/25~29に開催されます(続き)」
- 《特別寄稿》「留学生から見たドイツの資史料収集事情:ミュンスター編」
:東京大学大学院人文社会系研究科 - 人文情報学イベント関連カレンダー
- 編集後記
《連載》「デジタル・ヒストリーの小部屋」第6回
「イベントレポート「DH2022東京記念レクチャーシリーズデジタル歴史学のジャーナルがもたらす新たな世界」」
はじめに
今回の連載は、来月に本番が迫った DH2022 Tokyo 大会の開催に向けた番外編企画として、2022年6月17日に開催された、DH2022東京記念レクチャーシリーズの第3回「デジタル歴史学のジャーナルがもたらす新たな世界」についてのイベントレポートとしたい。講師はルクセンブルク大学 C2DH(現代史とデジタル・ヒストリー研究センター)の Frédéric Clavert 氏、全体司会は人文情報学研究所の永崎研宣氏、コメンテーターは筆者が務めた。講演部分と質疑応答部分は逐次通訳つきということで、日本の参加者にとっては低コストで最新の情報を入手できる貴重な機会であったように思われる。参加申込は110人強、当日参加は70人程度と盛況であったのではないだろうか。
なお、本講演については、本連載の第3回「フルコースにレシピを添えて:Journal of Digital History 誌のねらいと意義」、および第4回「詳細なレシピもいいが、肝心の料理の質を上げてくれ:議論主導型のデジタル・ヒストリーと探索的データ分析」の内容が直接関連するものであり、本イベントレポートとあわせてご覧いただければ幸いである。
講師について
まず、講師のプロフィールについて簡単に紹介しておこう[1]。講師のFrédéric Clavert は、ドイツの経済大臣(1934–1937)および帝国銀行総裁(1924–1930, 1933–1939)であったヤルマール・シャハトに関する博士論文を執筆し、20世紀におけるヨーロッパ大陸の通貨組織について研究した。その後、ルクセンブルク大学の Centre Virtuel de la Connaissance sur l’Europe (CVCE) に所属していた際にデジタル・ヒューマニティーズのコミュニティに積極的に参加するようになり、デジタル時代における歴史家と一次史料の関係や、一方で記憶研究におけるウェブプラットフォームの大規模データの活用に徐々に目を向けるようになった。デジタル・ヒストリーのプロジェクトとしては、Twitter を使った第一次世界大戦100周年の #ww1プロジェクトを主導したことでも知られている[2]。現代史およびパブリック・ヒストリーの文脈では、International Federation for Public History の会長であった Serge Noiret との編著本が有名である[3]。そして、現在は C2DH に所属し[4]、Journal of Digital History(JDH)誌の managing editor を務めている。
講演内容のまとめ
次に、講演の流れをまとめていこう。その際、本連載の第3・4回で扱わなかった点についてはやや詳しく解説を付け加えておきたい。
講演タイトルは“Narrative, Data, Hermeneutics: the Journal of Digital History”で、JDH 誌の構成とその設計理念について解説するものであった。共同発表者として、同じくC2DH に所属する JDH 誌の編集長 Andreas Fickers も名を連ねている。JDH 誌は、国際誌・ダブルブラインド形式による査読・オープンアクセスの学術誌で、複層構造を持つ論文(multilayered articles)をウェブ上で出版することに最大の特徴がある。その複層を構成するのが、narrative layer, data layer, hermeneutics layer というわけである。
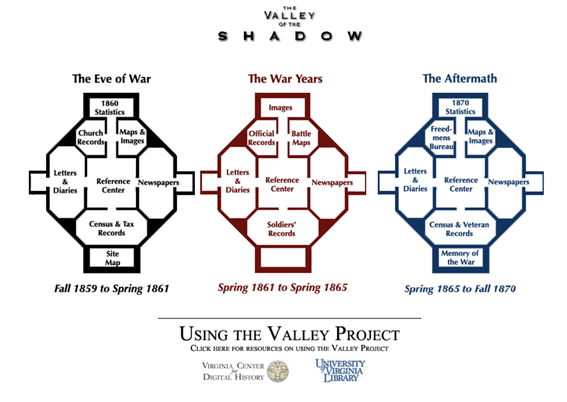
この複層構造の着想に至った経緯として、2つの研究が挙げられている。ひとつ目は、『猫の大虐殺』の著者で知られる文化史家 Robert Darnton によるエッセイである。彼が1999年当時アメリカ歴史学協会の会長代理であった際に、電子出版を用いた歴史研究の新しい形として、史料に基づく証拠・歴史的な議論・分析をピラミッドのように階層的に構造化することでまったく新しい意味を持たせられるとしていたという[5]。この Darnton の構想に触発されたアメリカのデジタル・ヒストリアン、Edward L. Ayers と William G. Thomas は、アメリカ南北戦争前後における白人と黒人奴隷という二つのコミュニティに属した個人個人の声を、統計資料・教会記録・地図や挿絵・手紙や日記・新聞・センサスや徴税記録といった多様な種類の一次史料をウェブ上で探索できるサイト The Valley of the Shadow を構築したのであった[6]。Ayers はこの取り組みについて、歴史の複雑さを高度に理解する喜びとその複雑さが持つ美しさを結び付けられる点に、デジタル媒体上での歴史叙述の美学を見出したという。一方 Thomas は、デジタル出版物の「プリズム機能」とでも呼ぶべきものに注目していた。彼は、一連の、相互に関連した歴史的解釈・歴史叙述・歴史的証拠・先行研究との関係についての解説といった要素を織り込むことによって、歴史的解釈のプロセスが開示され、読者がそれを追体験できるようになると考えていたという。
たしかに、このような歴史叙述の複層性に着目して、それを実装しようとした試みはいくつか存在していた。たとえば、フランス国立科学研究センター(CNRS: Centre national de la recherche scientifique)が発行する OpenEdition や[7]、Clavert 氏自身が主導しているオンライン書籍出版プロジェクトが挙げられるが[8]、デジタル・ヒストリーが要求するような、歴史的議論と一次史料、あるいは研究データとソースコードといった解釈と情報技術を架橋するような機能が実装されていなかった[9]。
こういった経緯から、JDH 誌は narrative, hermeneutics, data の3つのレイヤーからなる複層構造を、De Gruyter 社との協働で実装したのであった。この複層性を表現するにあたり、JDH 誌のデザイン面でのこだわりが見られるのが、下図に円形で示されている Fingerprint である。この図は、それぞれの論文における各層の配置の様子であり、叙述にどの程度の段落を割いていて、その語数はどの程度か、あるいはデータ分析に用いたコードの説明にどの程度の段落を割いているかといったことを幾何学模様で示しているという。さらに、マウスのカーソルを合わせれば、該当する段落へのハイパーリンクが貼られている目次の機能も有している。円の内側に伸びる線は、技術的な解説やソースコードを表しており、外側に伸びる線は歴史叙述を表している。これらのデザインは審美性に訴えるものである一方、実用的にどのような意義があるかは議論が分かれるところだろう。少なくとも筆者の目には、手法と解釈の両立を目指すデジタル・ヒストリーの叙述パターンの個性が可視化されるものとして、つまり目には見えない語りの構造を観測可能なものにする試みとして映る。「手法の解説ばかりで議論がない」研究は、内側にばかり線が伸びる Fingerprint を生成するということになるのではないかと思われる。

JDH 誌の技術的基盤となるシステムは、次の図に示すようなオープンソースのアプリケーションである。
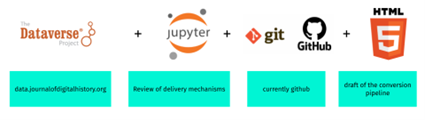
肝となるのは Jupyter Notebook であり、マークダウン言語を用いた叙述層の記述、コードセルにおけるプログラミングコードの実行が可能である。これによって narrative layer と hermeneutic layer の実装が支えられていると言ってよい。さらに、重要なこととして、研究データの公開による検証可能性の担保を実現しているのが Dataverse である。JDH 誌はデータ・ジャーナルを目指しているわけではないとしつつも、掲載されたすべての論文に必要なデータセットをホストすることによって、データの使用ライセンスや法的な問題をクリアすれば、データとノートブックをダウンロードできるようにしているという。
JDH 誌の編集上の課題もいくつか存在する。そもそも叙述と解釈を区別することが難しいこと、著者ごとに叙述スタイルがあまりに異なるため、Fingerprint をはじめとする誌面構成を納得のいくものにするには入念な議論が必要であること、R 言語のコードを Jupyter Notebook 上で動作させること、ソースコードの評価をどのようにすれば良いか、といった点が挙げられる。とは言え、ウェブ媒体の学術誌であることから、すべての論文を一斉に公開する必要がないなど、デジタル出版の利点も見受けられる。著者や読者からのフィードバックも数多く寄せられているようで、「走りながら考える」アジャイル開発の発想でJDH誌をより良いものにしていきたいと考えているようだ[10]。
執筆・投稿には、いくつか越えるべきハードルが存在するが、ぜひ前向きに投稿を検討してほしいというメッセージで講演は締めくくられた。
コメント・質疑応答
講演に対する筆者のコメントは、本連載第3・4回の執筆内容に基づき、Clavert 氏によるやや技術寄りの講演内容を、デジタル・ヒストリーの分野固有の問題と照らし合わせた俯瞰的意義について補足しようとするものであった。とくに、なぜ JDH 誌の複層構造が重要なのかという点について補足した点が重要だと考えている。すなわち、デジタル・ヒストリー研究の大半は手法の新規性を論じることに紙幅を割きすぎて、歴史的解釈に富んだ中身のある議論を展開してこなかった、議論の材料を提供するのみであった、という批判への回答を JDH 誌の複層構造が示しているからだ、という点である。その他の点については、本連載第3・4回の内容をまとめたものになっている。
続く質疑応答では、JDH 誌の持つデータリポジトリ以外のデータソースとの接続に関する見通しや、JDH 誌に投稿しようとする著者への負担があまりに大きいことへの懸念、ひろく人文学と情報学双方の知見に習熟した人材を教育・研究を通してどのように育成していくかといった点が取り上げられたように思う。
たしかに、講演内容からは、JDH 誌への投稿論文の執筆にあたっては、通常の歴史学の論文を執筆するよりも多くの、かつ多様なスキルが執筆者に要求されていることが窺えた。歴史叙述とプログラミング、構造化された研究データのいずれも高いレベルで記述しなければならないとなると、投稿コストは非常に高く、学術誌としての持続性すら問われかねない。デジタル・ヒストリー実践のすそ野を広げていくというよりは、むしろ先進的な取り組みを結集した学術空間としてデザインすることに重きを置いている印象を受けた次第である。
おわりに
今回は、JDH 誌の構成とねらいについての Clavert 氏の講演内容とコメント・質疑応答についてそれぞれ簡単にまとめ、最後に筆者なりのコメントを付した。筆者も近い将来 JDH 誌への投稿を目指しつつ、掲載される論文もレビューしていけたらと考えている。デジタル・ヒストリーの分野をけん引するひとつの中心的存在として、JDH 誌の今後に注目していきたい。
ちなみに、DH2022 Tokyo の本プログラムの一環として、定員10名ではあるが、JDH 誌に投稿するフォーマットの論文を執筆するためのワークショップが、日本時間2022年7月25日(月)21時から26日(火)0時半まで開催される予定である。ご関心の向きは本大会へのご参加も含めて検討されたい。また、ぜひ本講演に当日参加された方々からもイベントレポートを頂戴できればなお幸いである。
《特集 DH2022》「DH 分野最大の年次国際学術大会が7/25~29に開催されます」
デジタル・ヒューマニティーズ(以下、DH)分野最大の年次国際学術大会は、本年7月25~29日、東京にてフルオンラインで開催されます。人文学にコンピュータを応用することに取り組む欧州と米国の学会が1990年共同で開始した年次学術大会は、2006年よりDHを冠するようになり、2021年のコロナ禍による延期を経て、2022年、ついにアジアでの初開催となりました。
今回の国際会議では、“Responding to Asian Diversity”というテーマが掲げられており、会議本体はもちろんのこと、プレ会議企画としても、ツィッタでのショートビデオによる、アジアに関するDH 研究の紹介が着々とツィートされつつあります。これは、ADHO(国際DH学会連合)の各構成組織から推薦された、アジアに関するDHに取り組む研究者が応じたもので、日本・台湾・インドといったアジア諸国だけでなく、ドイツ・米国等の学会からもそれぞれの地域でDHに取り組む研究者がビデオを提供しています。それぞれのビデオは現在もツィッタ上で閲覧(https://twitter.com/hashtag/AsianDiversityInDH?f=live)できますのでよかったらご覧になってみてください。
また、フルオンラインとは言え日本で開催するということで、国際的なDHの最新動向に日本で触れる機会を提供するべく、DH2022実行委員会学術ワーキンググループが企画したのが DH2022記念レクチャーシリーズ(https://dh2022.adho.org/pre-conference-lecture-series)です。本メールマガジンが出る頃には、おそらく4件のレクチャーが終了しているはずです。中国古典(漢籍)の巨大テキストデータベース CTEXT.ORG の Donald Sturgeon 氏、西洋古典テクストの最大級のデータベース、ペルセウス・デジタル図書館のリーダー、Gregory Crane 氏、最先端のデジタル歴史学ジャーナルのエディター、Frédéric Clavert 氏、仏教学における歴史 GIS 分析を牽引する Marcus Bingenheimer 氏を招聘し、それぞれに逐次通訳をつけて日本語でも聴ける気楽な会として、多くの参加者があり議論も盛り上がり、盛況でした。岡田氏、小風氏の連載記事でも紹介されていますのでぜひご参照ください。7月にも、3Dの学術利用をテーマとする講演や、ウクライナ文化遺産のオンライン保存プロジェクト SUCHO に関する講演、欧州タイムマシーンプロジェクトに関するものなど、数件が予定されていますので、ぜひご参加ください。
会議本体の説明に入る前に、すでに多くの紙幅を費やしてしまいました。ここまでのプレイベントは無料ですが、会議本体は有料の会議となっております。これはあくまでも筆者の主観ですが、この会議は、費用に見合うか、それ以上に魅力的なものです。350件を超える海外の最新のDH研究の発表を聴けることはもちろんですが、それだけでなく、7月の25日・26日には、DH の最新の手法をハンズオンで学べる機会や方法論について議論できるワークショップが26件提供されます。これは日本語で開催されるものはあまりありませんが、非英語圏の参加者がいることを前提に開催されますので、比較的参加しやすいものになると思います。そのリストの日本語訳をこの記事の末尾に添付いたしますので、そちらをご覧になり、ぜひご参加をご検討ください。
メインの会議以外にも、実行委員会提供セッションとして、会期中には、ウクライナの文化遺産をオンラインで保存する活動 SUCHO(Saving Ukrainian Cultural Heritage Online)によるセッション、日本学術振興会と European Research Council によるセッション、東京大学史料編纂所、国文学研究資料館等のセッションが行われ、また、欧州の人文学デジタルインフラ事業である CLARIN ERIC(https://www.clarin.eu/)と DARIAH-EU(https://www.dariah.eu/)が出展する予定です。欧州のデジタルインフラの最先端を知るという意味でも良い機会になりそうです。
そのようなことで、みなさまにおかれましても、DH2022に参加することで、最新の国際的なDHの事情に触れ、その雰囲気を味わっていただくことで、日本の人文学のあり方や行く末を考える機会とするだけでなく、DH を媒介とした人文学における国際的な議論の場へのつながりを作っていく場の一つとしていただけますと幸いです。
以下、DH2022のワークショップの説明の日本語訳になります。ぜひご活用ください。
| WT-01 - 3Dスキャンをモバイルフレンドリーにし、オンライン視聴者への発信を拡大する:手動リトポロジーの紹介 | ||
| Angel Leelasorn | ||
| 現実世界の遺物を3Dスキャンしてオンラインで共有したり、VR/AR の構築に使用したいが、ファイルサイズが大きいと潜在的な視聴者のモバイルデータを消耗してしまい、遺物を完全に見てもらえないのではないかと心配されていませんか?あるいは、VR のフレームレート低下による乗り物酔いの原因になっていませんか?このワークショップでは、3Dモデルを簡略化しながらも、細部や複雑さをすべて保持するパフォーマンス最適化手法である手動リトポロジーを紹介します。手動リトポロジーは、数十年にわたりビデオゲームや VFX 業界で使用されており、リアルタイムレンダリングに非常に強力であることが証明されています。 | このワークショップでは、ファイルサイズが大きい3Dスキャンモデルをモバイルフレンドリーなものに変換する方法と、パフォーマンス最適化の基礎知識を学びます。また、手動リトポロジーを自分のスキルに追加することで、色々な人にとってより利用しやすい最適化された3Dモデルを作成し、公開できるようになります。 | パート1:Autodesk Maya - ナビゲーション、カメラコントロール、ユーザインタフェースの紹介 - メッシュの作成、頂点の変形と押し出し - 単純なジオメトリでスキャンされたオブジェクトの基本的な手動リトポロジー パート2:Autodesk Maya - 複雑なジオメトリを持つスキャンされたオブジェクトの手動リトポロジー パート3:Substance 3D Painter と Substance 3D Designer - Substance 3D Designer を使用して、オリジナルモデルからテクスチャを転送し、ディフューズマップを作成する - Substance 3D Painter でハイポリモデルからローポリモデルにディテールを焼き付ける |
| WT-02 - 古典中国語による東アジア資料のテキスト・データマイニング | ||
| Donald Sturgeon | ||
| 中国や他の東アジア文明の歴史的な文書記録にとって重要な大量の一次資料が、翻刻、画像シーケンス、またはその両方として、オンラインデータベースを通じて利用できるようになりました。また、数は少ないですが、適切な知識ベースにリンクされた固有表現によって、セマンティック・アノテーションが付されたテキストも増えてきています。このワークショップでは、Chinese Text Project (https://ctext.org) を用いて、デジタル化され注釈された歴史的テキストを扱う方法を紹介するとともに、OCRの手動修正、固有表現のセマンティック・アノテーション、オープンな知識グラフの構築と活用を支援するクラウドソーシング環境において、そのようなテキストのデジタル化の状態を改善する方法を説明します。 | このチュートリアルの目標は、参加者がこのデジタルライブラリー内でデジタル化された資料を効率的に探し出し、これらの資料を探索的なテキスト・データマイニングに利用し、さらにこれらの資料やその他の関連資料の進行中のデジタル化とアノテーションに貢献することを直接、体験してもらうことにあります。 | このセッションでは、参加者に以下のことを紹介します。 1) 大規模で中程度に複雑なデジタルライブラリーの基本的なナビゲーション。 2) インタラクティブな可視化を用いて、このデジタルライブラリーと、任意の言語での任意のユーザー提供資料双方の内容からコンテンツをユーザー主導で探索できる、オープンなブラウザベースのツールを用いたテキストマイニング。 3) テキスト翻刻の誤記とバージョン管理されたテキストリポジトリの編集方針を訂正するためのクラウドソーシングによる編集。 4) セマンティック・アノテーションと知識ベースの構築。 5) 基本的な知識グラフのクエリとデータマイニング。 6) RDFとSPARQLを用いた知識グラフのクエリ。 |
| WT-03 - TXMを用いた演説原稿コーパスチュートリアルの解析 | ||
| Serge Heiden | ||
| TXMプラットフォーム これは、XMLでタグ付けされ、構造化されたあらゆるタイプのデジタルテキストコーパスの構築と分析を支援します。TXMと呼ばれる、Windows、Mac、Linuxのソフトウェア(Eclipse RCPベース)およびWebポータル(GWTベース)として配布され、コーパスにオンラインでアクセスすることができます。 これは、歴史、文学、地理、言語学、社会学、政治学など、人文・社会科学の様々な分野の研究プロジェクトで一般的に利用されています。テキストメトリクスの科学的発表は、Days of Textual Data statistical Analysis (JADT - Journées d'Analyse statistique des Données Textuelles) 国際会議 |
このチュートリアルの目的は、TXM で開発された新しいツールを紹介します。このツールは、オーディオやビデオのソースレコードと同期したテキストを、話者交替、発話、単語レベルで分析するためのものです。参加者はまず、好きなワープロソフト(MS Word や LibreOffice Writer など)を使って、話者交替における話者、バレットタイム、コメント、セクションリミットを符号化する簡単な構文を使って、記録を書き起こす方法を学びます。次に、これらの記録を XML Transcriber フォーマットに変換してTXMにインポートし、利用可能なコンテンツ分析ツール(単語頻度リスト、共起分析、KWIC コンコーダンス、オーディオまたはビデオ記録の再生と同期した読み上げ)を使って分析する方法について学びます。 | これは半日のチュートリアルです。 パート1:イントロダクション [30分] ミートアップの紹介 TXMとレコード文字起こしコーパスの紹介 第2部: インタラクティブハンズオンセッション [2時間30分] Part 2.1: コーパスの作成 LibreOffice Writer または MS Word (.odt または .docx ファイル) で簡単な構文を使ってレコードを書き写す。 ** 音声ターンとそのロキュータコード、タイムバレット、コメント、セクションの制限について TXM ユーティリティを使用した Word テープ起こし用文書の Transcriber XML 形式(.trs ファイル)への変換 Transcriber のトランスクリプション(.trs)を TXM にインポート。 ** 記録メディアファイル(.mp4 または .mp3)の作成 ** TreeTaggerによる自動レムマター化 パート2.2: コーパス分析 TXMによるトランスクリプトのコーパス解析 ** 単語頻度リスト ** KWICコンコーダンサー ** 文字起こし版リーディング ** 音声・映像再生へのリンク(エディションまたはコンコーダンスより) |
| WT-04 - 百聞は一見にしかず:DHのための画像分析 | ||
| Stuart James, Mathieu Aubry, Nanne van Noord, Noa Garcia, Leonardo Impett | ||
| このチュートリアルでは、コンピュータビジョン(CV)の手法をDH(DH)研究を強化するために活用する方法についての洞察を提供することを目的としています。CV のデジタル化利用とは対照的に、我々は遠読に利用可能なコンテンツの解釈に焦点を当てます。このチュートリアルでは、美術品や文化遺産の視覚データに適用されている CV の4つの最先端の研究課題を取り上げ、その後、DH の問いに答えるために CV の手法がどのように適用されているかを検討します。このチュートリアルでは、DH への CV の適用に豊富な経験を持つCV研究者4名とDH研究者1名をお招きしています。 | このチュートリアルでは、コンピュータビジョン(CV)の手法をDH(DH)研究を強化するために活用する方法についての洞察を提供することを目的としています。CV のデジタル化利用とは対照的に、我々は遠読に利用可能なコンテンツの解釈に焦点を当てます。このチュートリアルでは、美術品や文化遺産の視覚データに適用されている CV の4つの最先端の研究課題を取り上げ、その後、DHの問いに答えるためにCVの手法がどのように適用されているかを検討します。このチュートリアルでは、DH への CV の適用に豊富な経験を持つCV研究者4名とDH研究者1名をお招きしています。 | このワークショップは5つのセクションに分かれます。 1: 検索とナレッジ・グラフ(Stuart James) 2: コンテンツに基づく分析(Mathieu Aubry) 3: マルチタスク学習(Nanne van Noord) 4: 自動解釈(Noa Garcia) 5: 人文学研究におけるコンピュータビジョンの活用(Leonardo Impett) |
| WT-05 - デジタル世界における伝記データワークショップ2022 | ||
| Angel Daza, Antske Fokkens, Richard Hadden, Eero Hyvönen, Mikko Koho, Eveline Wandl-Vogt | ||
| 伝記はコンピュータ分析にとって興味深いものです。個人というのは、生年月日、職業、社会的ネットワークなど、情報検索やデータ分析に利用できる共通の特徴を有しています。DH アプローチは、このようなデータの定量的分析にも、より質的な研究上の問いへの手がかりを提供するためにも利用できます。Link | 伝記データやDHに取り組むグループは、それぞれ異なる強みを持っています。歴史学、図書館学、文学の知識が豊富なドメインエキスパートで構成されているグループもあります。また、自動解析、形式的モデリング、可視化を専門とする研究者で主に構成されているチームもあります。これらのグループをまとめることで、どちらの種類のグループも見識を深めることができます。 伝記情報の国際的な研究への関心は非常に高いものがあります。ほとんどのリソースは国のリソースであり、多くはオープンなものですが、情報を共有するということは、お互いのデータ表現を理解し、関連情報をリンクさせることなども意味します。 |
1日かけて行われるワークショップは、3つのセッションに分かれます。 1) 参加研究者は自分の研究を発表する機会があります。 2) 2つの対話型テーマセッション:最初は技術志向のテーマセッション(データのリンクと共有、データ分析、データの可視化)で、2つ目のセッションは人文学からの事例を中心に構成され、人文学者が異なる技術専門知識を持つチームと交流します。 3) 作業グループは、対話型セッションで得た洞察を他の参加者と共有します。 |
| WT-06 - テキスト・エディタ Stylo を使って学術論文を執筆・編集しよう | ||
| Antoine Fauchié, Roch Delannay, | ||
| このチュートリアルでは、Canada Chair in Digital Textualities が開発した人文学のためのテキストエディタ Stylo の理念と使用方法を紹介します。Stylo は、人文社会科学系の学術誌のデジタルワークフローを変革するために設計されたツールです。人文学分野の WYSIWYM(What You See Is What You Mean)セマンティック(※XML のように文書構造が理解しやすい形式で表示すること)テキストエディタとして、学術出版の一連の流れを改善することを目的としています。 参加者には、Stylo を使って自分のテキストを用いて試しに編集してもらいます。このワークショップでは、既存の Stylo のマニュアル、すなわちマニュアルサイトとビデオチュートリアルを使用する予定です。 |
Markdown, BibTeX, Pandoc, Hypothes.is, LaTex といった、モジュール型でローテクな標準編集ツールやフォーマットをベースに作られた Stylo は、執筆とWeb上での出版におけるベストプラクティスを一つのインターフェースに統合しています。 Stylo には、共有、バージョン管理、変更履歴、参考文献管理、改訂時の注釈、複数フォーマットでのエクスポート、典拠の標準的枠組み(LOC、Wikidata、ORCID など)に沿ったメタデータ、そしてオンラインセマンティックタギングなどの機能が含まれています。 このワークショップでは、Stylo が科学雑誌の執筆・編集ツールとして日々どのように使われているか、そして、研究者や学生が個人的または集団的にどのように使うことができるかを紹介する予定です。 |
デモンストレーションでは、(1)Stylo の理論的基礎、(2)主な編集機能、(3)利用可能なエクスポートオプション、(4)人文学分野の学術雑誌の文脈における Stylo の具体的な使い方、(5)ツールの現在および将来の開発、そして実装について紹介します。 |
| WT-07 - Computer Vision を用いた図版の視覚解析 | ||
| Giles Bergel, Abhishek Dutta | ||
| このチュートリアルでは、オクスフォード大学の Visual Geometry Group と書物史・美術史家との10年以上に渡る共同研究に基づいて、図版研究における Computer Vision の利用について説明します。このチュートリアルでは、機械学習を用いた図版の検出、マッチング、比較、分類を含む、図版の完全な処理手順を紹介する予定です。Computer Vision の予備知識やプログラミングの経験は問いませんが、技術的に十分な能力を持つユーザーにも対応するチュートリアルです。参加者は、この分野における Computer Vision の最先端の状況を理解し、自分の画像を検索可能にする方法を学ぶことができます。 |
DHの研究者は、印刷物からテキストを抽出・処理するためのツールを数多く持っていますが、その一方で、視覚的要素を対象としたコンピュータ解析の選択肢はあまりありません。この半日チュートリアルは、そのような研究者のニーズに応えるために企画されました。参加者は、19世紀のインドの印刷物も参照しながら、西洋の初期印刷物に基づいたケーススタディを使って、4つのアプリケーションを体験していきます。これらの史資料に関する知識は必要ありません。また、データの取得、機械学習におけるバイアス、ユーザ・エクスペリエンス、研究の再現性、ソフトウェアの引用、認証などの、重要な運用上の課題についても取り上げる予定です。 | このチュートリアルでは、図版を分析するための4つの段階の手順を紹介します。 1. 事前に学習したオブジェクト検出モデルを使用した図版の検出、および検出結果の確認と改良に使用する List Annotator(LISA)ツールを併用します。 2. 視覚的な画像検索とグループ化:VGG 画像検索エンジン(VISE)を使用し、画像を検索クエリとして使用して画像のコレクションを視覚的に検索することができます。 3. 画像比較:図版間の微細な差異を検討することができるソフトウェアを活用します。 4. VGG Image Classifier (VIC)を用いた視覚的分類。これによりキーワード検索や画像をクエリとしてデータセット内の画像を意味的に分類します。 |
| WT-08 - 理論的概念からテキスト現象へ、そして回帰する:DHにおける操作化(※定量化できない抽象的なものを測定可能にすること) | ||
| Melanie Andresen, Benjamin Krautter, Janis Pagel, Axel Pichler | ||
| このチュートリアルでは、DHの中心的な課題の1つである、人文学の理論的概念をコンピュータに基づいた研究のために操作化することを取り上げます。 人文学者が主に扱う理論的概念は、しばしば複数のテキスト現象を内包し、さらにその解釈に関連すると考えられるコンテキストを前提としたものであるのに対し、コンピュータを用いた研究は、テキスト表面の識別可能な現象に束縛されます。その結果として生じる、理論的な予想と具体的な結果との間の乖離は、適切な操作化によって橋渡しをする必要があります。そこで、いくつかのサブステップを経て、理論的概念をテキスト表面の現象に遡及させる手順を開発することを目指します。 |
このチュートリアルの目的は、人文学と、コンピュータに基づいたアプローチとの違いを認識し、典型的な課題を取り上げ、人文学の理論的概念を操作化するための異なるアプローチを開発することです。このようなプロセスで行われる操作化の仮説を反映させることによってのみ、結果の適切な取り扱いが保証されると確信しています。 | このチュートリアルでは、操作化の実践とその理論的背景に焦点を当てます。厳選したいくつかの事例を基に、人文学の分野でコンピュータを用いて研究を行う場合、どのような課題があり、それらにどのように対処すればよいかを紹介します。実践編では、模範となるテキスト解析に関連する概念の操作化を体験していただきます。そのために、用意した事例のための Jupyter ノートブックを提供します。プログラミングのスキルは必要ありません。 |
| WT-09 - XSLT を使って TEI ファイルからデータを操作・処理しよう | ||
| Elisa Beshero-Bondar, Martina Scholger, Kiyonori Nagasaki | ||
| 文書内のマークアップは、いわゆる「プレーンテキスト」でできることを超えて、データを処理するために特に有用な構造とコンテキストを提供します。本ワークショップでは、XML/TEI から、単純で再利用可能な XSLT テンプレートを用いて、単純な TSV/CSV や HTML テーブル/チャートで表現するデータの抽出処理を学びます。 | TEI と XML の扱い方を学ぶには、エンコーディングでデータを操作し、探索する方法を知ることが重要となります。このワークショップは、マークアップ言語の経験があり、分析と研究の基礎としてデジタル学術編集版を扱う方法についてより深く学びたい人のために設計されています。文書内のマークアップは、いわゆる「プレーンテキスト」でできることを超えて、データを処理するために特に有用な構造と文脈を提供します。 | ワークショップは3部構成になっています。第1部:XML のツリー構造を理解し、構造化された文書から抽出されたデータを分析する多言語の XML および TEI プロジェクトに取り組みます。第2部:講師が用意したソースドキュメントを使って、XPath の基礎を学びます。第3部:XSLT の基本を学んで、データをキュレーションする簡単な出力を作成し、それらを簡単なチャートやグラフに利用する方法を紹介します。 |
- コメントを投稿するにはログインしてください