人文情報学月報第123号
ISSN 2189-1621 / 2011年8月27日創刊
目次
- 《巻頭言》「デジタル・ヒューマニティーズ年次国際会議 DH2022@東京の開催」
:一般財団法人人文情報学研究所 - 《連載》「Digital Japanese Studies 寸見」第79回
「UniDic の源を見に:中俣尚己『「中納言」を活用したコーパス日本語研究入門』」
:北海学園大学人文学部 - 《連載》「欧州・中東デジタル・ヒューマニティーズ動向」第40回
「欧州デジタル・ヒューマニティーズ学会 第2回国際大会参加記:言語資源の Linked Open Data と Text Alignment Network を中心に」
:京都大学大学院文学研究科附属文化遺産学・人文知連携センター - 人文情報学イベント関連カレンダー
- 編集後記
《巻頭言》「デジタル・ヒューマニティーズ年次国際会議 DH2022@東京の開催」
メールマガジン『人文情報学月報』の創刊準備号の最初の記事は、2011年にスタンフォード大学で開催されたデジタル・ヒューマニティーズ(DH)の年次国際会議について簡潔に紹介するものであった。それから10年が経ち、ついに、2022年7月、この国際会議が日本で開催されることになった。人文学にデジタル技術を応用することやそれについての批評を行う研究者達が世界中から集結して各自の研究を発表し議論し交流する会となる。現在、発表論文募集が開始されており、締切りは2021年11月30日となっている。多様な観点からの査読コメントをはじめとして、学会での質疑応答やその後の交流から国際的な共同研究への展開など、研究を深め、広げていく機会が様々に提供される場であるため、その方面の研究に取り組んでおられる方々におかれてはぜひご投稿をご検討いただきたい。以下では、この国際会議について少し紹介してみたい[1]。
この年次国際会議の淵源は、1970年代に設立された欧州の学会 ALLC(Association for Literary and Linguistic Computing)と米国の学会 ACH(Association for Computers and the Humanities)による合同会議である。1990年のドイツ・ジーゲン大学での開催を皮切りに、主に欧州と北米で交互に開催されてきた。当初は Humanities Computing などと呼ばれていたこの学会が DH を冠するようになったのは2006年のパリ大会からである。2004–2005年頃に国際 DH 学会連合 Alliance of Digital Humanities Organizations(ADHO)が設立されたことが反映された形となった。さらに、その時期には DH の総合的な教科書である A Companion to Digital Humanities[2]が当時北米の DH を牽引していたイリノイ大学アーバナ・シャンペーン校(当時)の John Unsworth 氏に加えてメリーランド大学(当時)の Susan Schreibman 氏、ヴィクトリア大学の Ray Siemens 氏らの編集のもと、国際的な DH 研究者達の分担執筆により刊行されるなど、まさに DH の旗印を掲げて新しい潮流が作り出される時期であった。その後、DH は欧州と北米のそれぞれにおいて、学術政策としても着実に推進され、研究者を増やしていくこととなった。やがて、欧州・北米を離れて別の地域でも年次大会が開催されることになり、2015年はシドニー、2018年はメキシコシティでの開催となった。
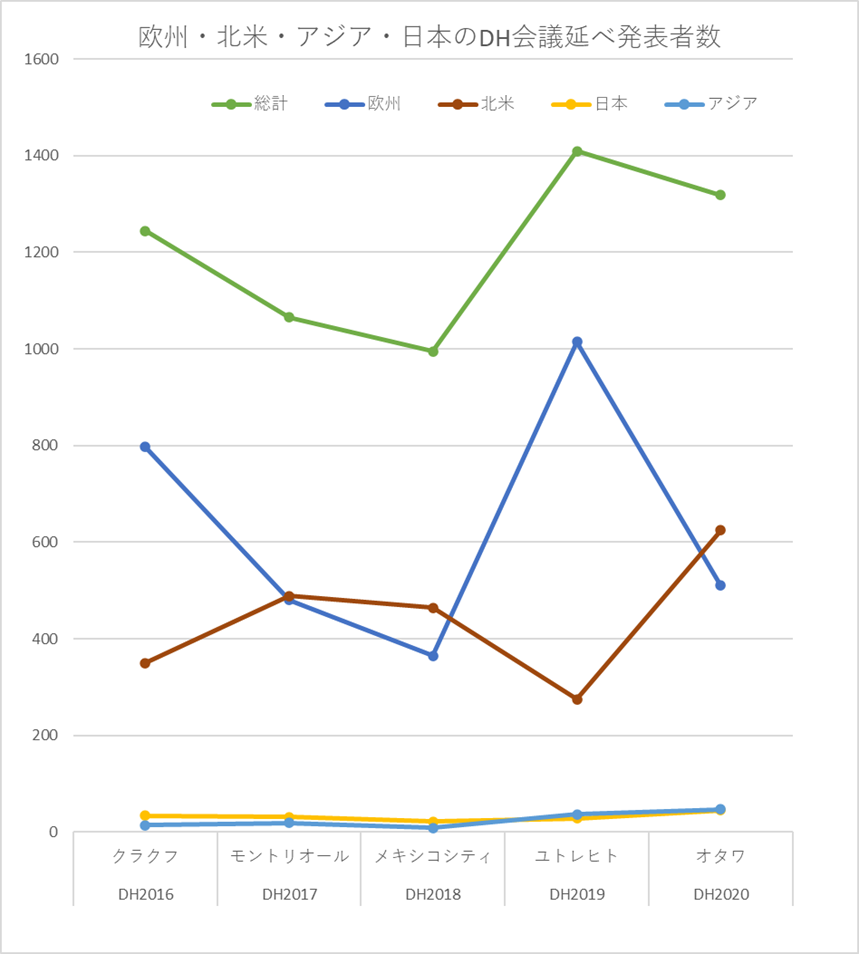
発表者の傾向については、ADHO の国際会議では過去の発表論文を構造化データ(TEI/XML)で公開しており、機械的な分析が比較的やりやすい。そこで、まずは、発表者の所属組織を地域別にみてみよう。この5年間の延べ発表者数のうち、数の多い地域である欧州・北米と日本・アジア(日本を除く)の数をグラフとして示したのが図1である。これをみてみると、メキシコシティでの開催時は1000名をやや割り込んだものの、欧州や北米での開催時には1000名を超えている。全体としては増減があり、欧州開催時に特に増加する傾向があるが、欧州開催のみ、北米開催のみでみた場合、いずれも増加傾向にある。また、日本はアジア地域としては比較的発表者を多く出してきたものの、2019年までは、日本を除くアジア地域よりも日本の方が多かったが、2020年にはこれが逆転した。現在、特に中国で DH が盛んになりつつあることもあり、今後はアジア全体の数も急増していくことが予想される。
また、同じデータを利用することで、「一つの発表にどれくらいの国・地域の研究者が連名しているか」、つまり、国際的な共同研究の輪がどれくらい広がっているか、ということも機械的に抽出できる。それを示したのが図2である[3]。
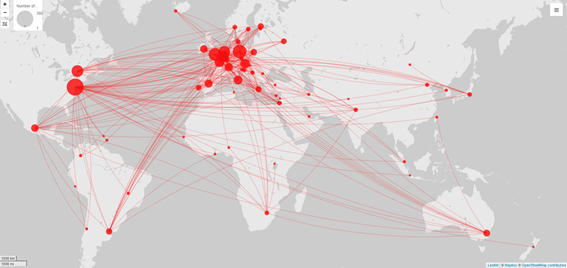
プロットの座標がいわゆる「首都」になっているため、現実の多様性を十分に反映しないやや大雑把な図になってしまっているが、米国・カナダに加えて、英独仏の円が大きく、それらの国々同士での共同研究が盛んに行われていることが想定される。中南米、アジア、オセアニア、アフリカもやや弱いネットワークとしてつながっており、日本は発表者数の割にネットワークが弱いが、これは国際的な研究発表が少ないことを示していると言えるだろう。中南米に関しては、メキシコシティでの開催による影響が大きく、その意味では2022年の東京大会により、日本の国際ネットワークも強化される可能性は大いにある。
そもそもアジア地域では DH は行われてこなかったのかと言えば決してそうではなく、アジア地域でも人文学におけるデジタル技術の応用は様々に取り組まれてきたものの、ADHO の DH 年次国際大会はこれまで行われることがなく、その存在感を十分に発揮することができなかったと言うべきだろう。日本では上述の ALLC、ACH の日本版とも言える JALLC(Japan Association for Literary and Linguistic Computing, 情報処理語学文学研究会)、JACH(Japan Association for Computers and Humanities, テキスト・データベース研究会)が1980年代に設立され、それぞれがテキストデータベースの構築共有を中心とした活動を行い、さらに1989年には情報処理学会に設置された人文科学とコンピュータ研究会によりこの種の研究のためのコミュニティが形成された。アジア地域としてみてみると、1992年には仏教テキストデジタル化の国際ネットワークとして Electronic Buddhist Text Initiative が設立されてアジア圏の仏教研究者を広く集め、1997年には環太平洋地域での人文学へのコンピュータ応用の国際会議を開催する Pacific Neighborhood Consortium (PNC) が形成され、2007年に始まった International Sanskrit Computational Linguistics Symposium は2009年の第三回をインドのハイデラバード大学で開催するなど、筆者の周囲を見渡しただけでも様々な取り組みが行われてきた。しかしながら、欧米の DH の潮流から見えるようになってきておらず、また、こちらからもそれが十分に見えておらず、2011年~2012年の日本デジタル・ヒューマニティーズ学会の設立と ADHO への加盟や、2018年に国際的な DH の重要な基盤の一つである Text Encoding Initiative (TEI) 協会の年次総会が欧米を出て初めて東京で開催されたこと等を通じて、ようやく DH の国際的な動きが本格的に日本やそれを含むアジアとも接続してきたところである。
2022年の東京大会のテーマは、Responding to Asian Diversity である。これまで欧米が中心となって推進されてきた国際的な DH の潮流に、多様なアジアの文化を背景とするアジアの DH がどのように対応していくのか。DH は、個々の研究者が持つ研究課題の解決の場という側面だけでなく、デジタル時代の人文学のインフラを担うという側面も持っており、この国際的な潮流において日本を含むアジアの DH がどのような位置を占めていくかということは、今後の人文学やそれを踏まえた国際的な文化交流においても重要な意味を持ってくる可能性がある。現在のところ、言語が異なると十分な議論をすることは難しく、研究の前提の共有すら困難なことも少なくない。アジアの DH と言っても、アジアの言語、たとえば日本語と中国語を用いて学術的な議論を行うことは、両言語に通じている人でない限り、やがて自動翻訳が高度化していけば可能になるかもしれないが、今のところはまだ距離がある。一方で、現時点で DH に期待したいのは、むしろ、デジタル技術という「共通言語」が持つコミュニケーション能力である。たとえ使用言語が異なっていても、デジタル化されたコンテンツを扱う場合に、何をすればどうなるのか、ある動作の背景にはどういう技術や規格があるのか、ということは相互に理解しあえていることが多い。パソコンの OS や Web 技術をはじめとして、デジタル技術には国際的に標準化されているものが多いためである。特定の製品を皆が使っているからというだけでなく、たとえば、マイクロソフトのワード・エクセル・パワーポイントのフォーマット[4]のように、近年は、この種の規格は一定の手続きを経て国際的に標準化されて公開されていることが多い。結果として我々は、たとえば、ワードの編集履歴機能がなんであるか、翻訳ソフトを介さずともその国際的に定められたフォーマットに基づく動作によって国際的に共通理解を得ることができる。すなわち、データを作成・分析する際の手法が国際的に標準化されていることによって伝達可能性が高まるということである。そして、この種のことに日本からも参画すれば、それはそのまま日本の海外発信力が強化されるということにもなる。言語そのものを研究対象に含む人文学は言語の壁が大きく、国際的な協働や海外発信は、それを研究の基礎にする研究者以外には取り組むことがなかなか容易ではない。しかしながら、Web やワードをはじめとするデジタル技術についてはすでに大部分の研究者が否応なしになんらかの形で利用しており、様々な外国語で学術的な議論を行うことに比べれば近しい存在であるという人も少なくないだろう。デジタル技術を媒介として国際的な協働や海外発信に取り組むことができれば、人文学としても、すべての分野にわたってということは難しいかもしれないが、それほど大きな負担にならずに新たな道を拓ける可能性がある[5]。東京での DH 会議の開催が、そのような状況をもたらす一つのきっかけになることも、筆者としては期待するところである。
《連載》「Digital Japanese Studies 寸見」第79回
「UniDic の源を見に:中俣尚己『「中納言」を活用したコーパス日本語研究入門』」
京都教育大学の中俣尚己氏の執筆した『「中納言」を活用したコーパス日本語研究入門』(ひつじ書房、2021。以下、本書)が刊行された[1]。本書にはすでに青山学院大学の近藤泰弘氏の書評が『週刊読書人』にあるが[2]、ここでも紹介したい。本月報読者にも、「中納言」は無関係ではないからである。
「中納言」は、国立国語研究所(国語研)の提供するコーパス検索プラットフォームで、現在は同所のコーパス開発センターが中核となって開発が進められている[3]。なお、「大納言」は同所内で活用されているコーパス開発プラットフォーム、「少納言」は、本書でも紹介されているが、登録不要のコーパス検索ツールの名称である。「少納言」は、2021年2月にセキュリティ上の問題によって公開が一時停止されていたが、2021年12月の再開を目指して改修中とのことである[4]。これは、下記の「現代日本語書き言葉均衡コーパス」を簡易的に検索できるツールで、検索結果も500件までと制限されているが、正規表現を利用して柔軟に文字列検索できるなど、「中納言」にない利点もある。
コーパスはもはや説明に多言を弄する必要もなくなりつつあるが、なんらかの基準でまとめられた言語資料編纂体のことである。言語資料として言語学的分析が各文各語に施され、分析が容易にできるようにされることがほとんどである。国語研では、現代の書きことばをバランスよく集めた「現代日本語書き言葉均衡コーパス」(Balanced Corpus of Contemporary Written Japanese; BCCWJ)、おなじく話しことばについて収集した「日本語話し言葉コーパス」(Corpus of Spoken Japanese; CSJ)、日本語の歴史資料を集めている「日本語歴史コーパス」(Corpus of Historical Japanese; CHJ)をはじめとして、会話や方言、言語学習者、ウェブなどからあつめた言語資料をコーパスとして提供している。国語研のコーパスの詳細については、[3]のコーパス開発センターウェブサイトに各種資料があるほか、概説的なものとして朝倉書店から「講座日本語コーパス」[5]や「コーパスで学ぶ日本語学」[6]が出ているので、そちらを参看されたい。
これらのコーパスの処理には、基本的に UniDic と呼ばれる「辞書」が用いられている。UniDic は、伝ほか[7]で提示された形態素解析用辞書である。MeCab[8]などで処理をしたことがある人であれば、さいきんは UniDic を用いることがかなり多いのではないかと思うが(IPADIC などを使うこともとうぜんあろう)、その本家がこの国語研のコーパス開発なのである。一貫して UniDic を用いることで、横断的な検索を最大限可能にしようとしているのが、国語研の現在のコーパス開発体制で、それによって、古語の文献も UniDic の現代語のデータを通じてかなり扱いやすくされている。
さて、「中納言」は、そのようなコーパスから検索するための環境である。個々のコーパスについて検索することもできるし、「まとめて検索」として「KOTONOHA」という統合検索も実験的に公開されている。つまり、「中納言」を通じて、どのような意図で UniDic が作られているのか、より正確に理解することができるということである。
本書は、言語研究者向けのガイドであるから(中俣氏は日本語文法の研究者である)、かならずしも非専門家の興味に沿うものではないが、平易な語り口なので、自然と言語研究者の興味というものも理解しやすくなっているのではないかと思う。また、UniDic の活用体系や細々した情報など、非専門家にはその意義が分りにくいことがらが「中納言」でフル活用されているさまが見られることで、なんとなく使っていた MeCab の結果もよりビビッドに理解されるのではなかろうか。
このようなオンラインサービスのガイドブックのつねで、「少納言」の紹介から入っているものの「少納言」が止まってしまっている(脱稿後の加筆で、サービス停止中である旨は明記されている)などのことはあるが、まちがいなく「中納言」の現在の最良の入門書であろう。自然言語処理の数理的な部分だけではなく、辞書の正しさなどに関心を持った方には、お勧めできる一冊である。
《連載》「欧州・中東デジタル・ヒューマニティーズ動向」第40回
「欧州デジタル・ヒューマニティーズ学会 第2回国際大会参加記:言語資源の Linked Open Data と Text Alignment Network を中心に」
2021年9月21日から24日まで、欧州デジタル・ヒューマニティーズ学会(European Association for Digital Humanities; 以下 EADH)が主催する第2回国際大会(Second International Conference)が開催された[1]。EADH は、日本デジタル・ヒューマニティーズ学会(Japan Association for Digital Humanities; JADH)と同様、世界の DH 系学会を束ねる ADHO(Alliance of Digital Humanities Organizations)の一員である[2]。
9月21日から22日までは、3つのワークショップが開催され、23日から24日は、研究発表が行われた。毎日、最後の時間に、Topia と呼ばれる、オンライン会議・懇親会プラットフォームで懇親会が一時間程度行われた。本来オフラインで、ロシアのシベリアに位置するエニセイ川の河畔に存在するクラスノヤルスクという都市にあるシベリア連邦大学で行われる予定であったが、コロナ禍のため、全てオンラインになった。クラスノヤルスクの時間は GMT+7で、GMT+9の日本とはわずか2時間の時差であるため、日本から大変参加しやすかった。ワークショップの数は3、口頭発表の数は100に近く、キーノートとパネルの数はそれぞれ2つ、そして多数のポスター発表があり、もちろん本稿で全てを詳述することはできない。そこで、筆者がメモを多数残し、最も印象に残った、2つのワークショップを中心に述べたい。
LiLa: Linking Latin: ラテン語言語資源の LOD
最初のワークショップは、“Interlinking through Lemmas. Linking Linguistic Resources to a lexically-based LLOD Knowledge Base” である。これは、マルコ・パッサロッティ氏が率いる、イタリアのミラノにあるサクロ・クオーレ・カトリック大学の LiLa: Linking Latin プロジェクトによるワークショップであり、そこでは、LiLa プロジェクトが開発した、ラテン語の言語資源 LOD 関連のプロダクトの使い方および理念や基本設計が教授された[3]。
LiLa プロジェクトの核心は、ラテン語の語彙の知識ベースである LiLa Knowledge Base である。現在、同じく LiLa プロジェクトが開発した Latin Wordnet と呼ばれるラテン語の概念辞書データや[4]、Perseus Digital Library の TEI XML 化された Lewis & Short のラテン語―英語辞典など、様々な辞書データが公開されている[5]。また、ラテン語それ自体は、語形変化が非常に豊富な屈折語であり、名詞類なら、性・数・格が、動詞なら、時制・相・態・法の文法情報が語形に現れるが、LiLa lemmaBank がこれらの文法情報を解析する。他、UDPipe というチェコのプラハ・カレル大学で開発されている、Universal Dependencies を用いた係り受け解析器はラテン語のテキストの係り受け解析を行ってくれる[6]。LiLa Knowledge Base では、ラテン語のテキストを入力すると、Latin Wordnet などの語彙データベースから語彙の情報を、LiLa lemmaBank から文法情報、UDPipe などから UPOS 情報を返してくれる。このサービスは、Linked Open Data で用いられているRDF(Resource Description Framework)を通して提供される。
このような、言語資源の LOD は、LLOD(Linguistic Linked Open Data)と呼ばれる。最近は、この分野での開発が盛んである[7]。LiLa の LLOD は The OntoLex Lemon Lexicography Module という辞書データベース向けのオントロジーのモデルを用いている[8]。オントロジーの中心は、様々な変化形を一つにまとめたレンマである。そこに、様々な文法情報や辞書情報が LOD のトリプルの形で記述され、ネットワークを形成していく。LiLa では、ユーザが入力したラテン語テキストに、LiLa Knowledge Base の知識ネットワークを自動で付すことができるインターフェースを作成している。このチュートリアルでは、LLOD の理念を学んだあと、そのインターフェースを操作して実践を行った[9]。
理念の解説では、トークン化、品詞タグ付け、係り受け解析の概念や技術など、ラテン語の自然言語処理の基礎が伝授された。その後、知識グラフや、言語的に注釈されたデータセットを相互運用可能な形で LOD 化する技術、具体的には、オントロジー、RDF、SPARQL、LLOD などの基礎、そして、レンマによるインターリンク、語彙ベースの LLOD 知識ベースへの言語資源のリンクなどの応用も説明された。
実践編では、各受講生が用意したラテン語テキストを LiLa 知識ベースに登録するまでのやり方を学んだ。具体的には、LiLa のインターフェース上で自動トークン化、品詞タグ付け、レンマ化を行い、RDF の Turtle で出力し、LiLa 知識ベースへ登録した。そして最後に SPARQL による知識ベースへの問い合わせを行った。図1は、あるラテン語テキストを自動で LiLa 知識ベースのインターフェースを使って分析した場面である。

Text Alignment Network: パラレルテキストのためのシステム
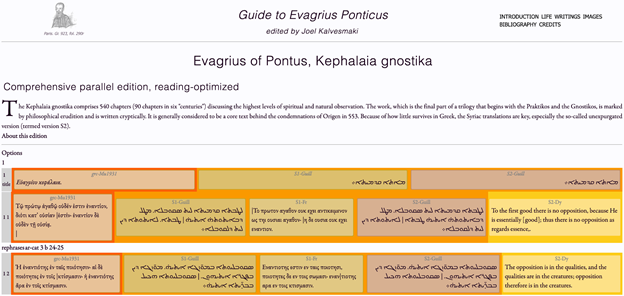
筆者が参加したもう一つのワークショップ “Preparing a TEI Corpus for the Text Alignment Network” は、アメリカ・カトリック大学のジョエル・カリヴェスマキ氏による TAN 講座である。TAN とは Text Alignment Network の略であり、TEI XML で作ったテキストコーパスで、別の写本や別の版、または別の言語での翻訳がある場合に、それらのパラレルテキストを整列させて容易に比較可能にするようなシステムである。このシステムはまた、Linked Open Data のエコシステムのなかで成り立っており、RDF によって、パラレルテキストの様々な情報がリンクされている。講師の説明によれば、TAN は TEI の拡張であるが、異なる設計原則に従っているということである。TEI のコーパスを用意し、TAN のための XSLT を用いることで、比較的容易に、TAN のアラインメントファイルを作ることができる。アラインメントとは、翻訳や異版、異本などのパラレルテキストを比較しやすいように整列させて表示するものである。図2が TAN をウェブサイトとして表示させた例であり、ここでは、古代末期のキリスト教思想家の著作のギリシア語原典の2つの異本のテキスト、同じ著作の古典シリア語訳の2つの異本のテキスト、そして現代の英訳の5つのパラレルテキストが、文に近い単位毎に整列されている。
本学会の懇親会は Topia という、いわゆる「ゆるキャラ」的なアバターを操作してオンライン上で他人と対話できるアプリで行われ[12]、今まで話したことがなかったが、論文などで名前を存じていた DH 研究者の何人かとお話することができた。また、最終日の1つのセッションの司会を代打で務めさせていただいたりした。研究発表およびキーノートでも印象に残った点が多数あるが、盛り沢山なので、今回の参加記は、最も印象に残った2つのワークショップについて述べることにとどめ、研究発表や懇親会についてはまたの機会に述べたい。
人文情報学イベント関連カレンダー
【2021年11月】
-
2021-11-2 (Tue)
国立公文書館アジア歴史資料センター開設20周年記念シンポジウム「デジタル・アーカイブの進化と歴史教育・歴史研究」於・オンライン -
2021-11-11 (Thu)
第7回日本語の歴史的典籍国際研究集会於・オンライン -
2021-11-13 (Sat)
三田図書館・情報学会2021年度研究大会於・オンライン -
2021-11-27 (Sat)
シンポジウム「資料・情報資源管理組織のミッションと専門職人材」於・九州大学中央図書館およびオンライン -
2021-11-29 (Mon)
令和3(2021)年度増上寺所蔵三大蔵電子化公開に関するシンポジウム於・オンライン
【2021年12月】
-
2021-12-3 (Fri)
史料編纂所 公開研究集会「新たな画像公開方法とデジタル連携」於・オンラインhttps://www.hi.u-tokyo.ac.jp/assets/news/2021/1203公開研究集会チラシ.pdf
-
2021-12-11 (Sat)~2021-12-12 (Sun)
じんもんこん2021:「越境する」デジタルヒューマニティーズから「総合知」へ於・オンライン
Digital Humanities Events カレンダー共同編集人
◆編集後記
先週は、TEI(Text Encoding Initiative)の年次大会に参加しました。昨年は ネブラスカ大学リンカーン校で開催予定だったものが、コロナ禍で中止になって しまったので、年次大会なのに2年ぶりの参加でした。2019年のオーストリア・グラーツでの開催以来、久しぶりに TEI の関係者が一同に集って、デジタル化された人文学資料の 構造化や活用手法に関する熱い議論が交わされました。もちろん、オンラインでの 開催です。通常発表は Zoom で、ポスター発表は Gather.town というオンラインビデオ通話スペースを使って行われましたが、さすがにもう 皆さん慣れたもので、トラブルがあっても対処の仕方まで共有されていて、 とくに困ったことにはならないのはもう世界中どこでも同じかもしれません。Gather.townは、ポスター発表に便利なスライド表示ツールが用意されて いて、行ったり来たりしながら発表者に質問をするだけでなく、対話の なかで、発表内容ではないものでもお互いにみせたくなった サイトやツールを適宜画面共有しながらデモをしてみせたりと、楽しく有意義な時間を過ごすことが できました。かつてなら、出張の予算確保や旅行の予約に加えて長時間の 移動をしなければ難しかった対話が、こんなにも簡単にできてしまうのかと、 この1年半ほどで思い知ったことではありますが、馴染んだコミュニティの 初めてのオンライン年次大会に出てみて改めて実感したのでした。 とはいえ、米国東部標準時での開催だったため、3日間ほど昼夜逆転に なってしまってしばらくは体調を戻すのも大変でした。こればかりは いつになっても慣れないですね。
(永崎研宣)
- コメントを投稿するにはログインしてください