人文情報学月報第146号【前編】
ISSN 2189-1621 / 2011年08月27日創刊
目次
【前編】
- 《巻頭言》「オープンサイエンス時代における人文学の研究データ」
:一般財団法人人文情報学研究所 - 《連載》「欧州・中東デジタル・ヒューマニティーズ動向」第63回
「古代エジプト民衆文字(デモティック)の字形画像データベースとテキストコーパス: Demotic Palaeographical Database Project」
:人間文化研究機構国立国語研究所研究系
【後編】
- 《連載》「仏教学のためのデジタルツール」第11回
「Indoskript 2.0」
:東京大学大学院人文社会系研究科 - 《特別寄稿》「ロンドン滞在備忘録」
:ROIS-DS 人文学オープンデータ共同利用センター - 人文情報学イベント関連カレンダー
- イベントレポート「グラフ形式データ構造化と TEI:Joint MEC and TEI Conference 2023参加報告」
:ROIS-DS 人文学オープンデータ共同利用センター - イベントレポート「Joint MEC TEI conference 2023参加報告」
:早稲田大学大学院文学研究科 - 編集後記
《巻頭言》「オープンサイエンス時代における人文学の研究データ」
1. はじめに
2021年11月の第41回ユネスコ総会において「オープンサイエンスに関する勧告」が採択されるなど、オープンサイエンスの実現に向けた動きが加速している。人文・社会科学という枠組みにおいては、日本学術振興会が昨年度まで推進していた人文学・社会科学データインフラストラクチャー構築推進事業(https://www.jsps.go.jp/j-di/torikumi.html)がその典型例である。海外でも、たとえば EU では Social Sciences & Humanities Open Cloud(https://sshopencloud.eu/)というプロジェクトが展開され、人文・社会科学の総合データカタログの作成が進められている。個別の国で見ていくと、オランダの DANS(https://dans.knaw.nl/en/)は人文・社会科学を含む全分野のデータリポジトリを目指しているようである。
一方、人文学のみ、あるいはさらにそれを分割する形で取組みが行われる場合もある。EU においては、欧州研究インフラコンソーシアム(ERIC)の傘下では人文学全般を扱う DARIAH(https://www.dariah.eu/)、言語資源データを扱う CLARIN(https://www.clarin.eu/)が設置されている。また、ドイツ政府により最近開始された研究データインフラプロジェクト NFDI(https://www.nfdi.de/)もまた全学術分野を対象としているが、NFDI では傘下のプロジェクトとして人文学に関連するプロジェクトが複数展開されている。たとえばテキストデータを対照とした Text+(https://www.text-plus.org/en/home/)、歴史学や歴史的データを扱う4Memory(https://4memory.de/)、文化遺産に関する研究データ全般を対象とした NFDI4Culture(https://nfdi4culture.de/)などがある。
オープンサイエンスを推進する上で基盤となるのは研究データでありそこから構築される知識だが、その基盤の有り様をどのように見定めていくかが今後の人文学について考えていく上では欠かせないものである。そこで、本稿では、隣接分野としてまとめて扱われることもある社会科学を意識しつつ、人文学の研究データの性質について検討してみたい。ただし、本稿は、あくまでも、現在筆者の視野に入っている範囲のうちで現在ここに書くことができる範囲での予備的な考察であり、これを通じて今後の考察の手がかりとしようとするものである。その点についてご容赦いただきたい。
2. 人文学と社会科学の研究データ
社会科学における研究データと言えば統計データを指すことが多いようである。量的研究と質的研究と区分されるところの量的研究の基礎として、EU の CESSDA(https://www.cessda.eu/)やミシガン大学の ICPSR(https://www.icpsr.umich.edu/web/pages/)をはじめとする国際的なデータポータルサイトが各地で提供されており、国内でも東京大学社会科学研究所の SSJ データアーカイブやそれを含むデータポータルサイトとして日本学術振興会が運用を開始した JDCat(https://jdcat.jsps.go.jp/)がある。統計データには、国勢調査等の定期的な調査データや、研究等の目的にあわせて企画されたアンケート結果等のデータなど、様々なものがあるが、いずれにしても、すでに数値データとなっているため、データ分析に際しては統計処理ソフトウェアでの分析にしても自前でプログラミングを行うにしても、色々な課題はあるにせよ、そこから何かを明らかにするという用途には比較的利用しやすい。
一方、社会科学においても質的研究に類する研究手法を採っている分野は様々に存在している。法学や教育学、社会学の一部などはそれにあたるだろう。質的研究手法では何らかのテキストを読んで人が考えることが基本であり、フィールドワークによる聞き取り調査の文字起こしから法令情報まで様々なものがあるが、これらは内容的にも手続き的にも、後述する人文学における研究データの困難さと近しい課題を抱えていると言える。
これに対して、人文学においては、数値化されたデータに基づく研究はあまり多くない。それでも敢えて挙げてみるなら、言語コーパスのデータは、単語毎にタグが付与されていたり、品詞情報等のアノテーションも付されていたりすることが多い。そして、数値化まではされていないものの、機械可読性が高く、何らかの観点から数値化することも比較的容易である。一定のルールの下に研究者の間で利用できるようになっていたり、オープンデータとして公開されていたりすることから、これ自体がオープンサイエンスを支える基盤となるものである。さらに、これを踏まえて研究成果に至るプロセスを示し共有し、そして再利用することも可能であり、その点でもオープンサイエンスが目指すところに資するものであると言える。言語学自体が比較的新しい分野であり、その一部の分野では統計処理にも親和性があることからこういったものが作成されやすくなっているという背景があるかもしれないが、いずれにしても、これに関しては、社会科学の量的研究における研究データに比肩し得る人文学の研究データと言ってもよいだろう。
3. 人文学の研究データ
3.1 量的データの見通し
言語コーパスでは上記のような状況が見られるものの、人文学の多くの分野では研究手法として質的研究とされるものが採用されることが多いようであり、統計的に処理可能なデータを直接的に利用することにはなりにくいようである。研究対象・研究資料から研究成果に至るプロセスの多くの部分は、研究者の思考として複雑な過程を経るものであり、その全体を完全に機械で代替することは不可能だろう。個別にみていくと、研究対象の観察や分析の結果をノートやカードとして記録することがあり、それが現在はコンピュータ上の手元のツールによって記述されている例は比較的多いと想定される。こういったデータは、研究者自身が自らの分析のために機械可読性を高めている場合もあり、そうでなくとも独自形式も含めて何らかの形式に沿って作成されている場合もある。そのようなデータは、オープンサイエンスの好循環において期待される研究プロセスの機械可読なオープン化に資する可能性が十分にありそうである。数値データとはならないまでも、機械可読性の高い人文学データを構築するための標準規格や共通語彙の作成が国際的には推進されており、歴史史料であれば ISAD(G)(https://www.archives.go.jp/news/20220803.html)や EAD(https://www.loc.gov/ead/)、博物館・美術館であれば CIDOC CRM(https://www.cidoc-crm.org/)、その他の人文学資料全般に関しては TEI ガイドラインが策定され、VIAF(https://viaf.org/)や ISNI(https://isni.org/)等の典拠データベースが国際的な枠組みにより蓄積され、Getty vocabularies(https://www.getty.edu/research/tools/vocabularies/)は芸術分野を中心とした多言語による共通語彙を国際的な協働を通じて構築しつつある。近年では、人文学におけるデジタル研究活動の語彙としての TaDiRAH(https://tadirah.info/)が開発され日本語訳も提供されるなど、研究活動そのものも含めた機械可読化に向けた道は着々と整備されつつある。海外では EU においては言語資源共有の枠組みとして CLARIN が運用されている。これと連携する英国の CLARIN-UK では多様な言語資源データを提供しており、ここに参画する Literary and Linguistic Data Service(https://llds.ling-phil.ox.ac.uk/llds/xmlui/, かつての Oxford Text Archive)では、70,135件の TEI 準拠テキストデータが公開されている。ドイツでは、TextGrid Repository(https://textgridrep.org/)が様々な研究プロジェクトの成果としての TEI/XML 準拠テキストデータ106,832件を集約して公開しており、さらに、これを含むより大きな言語資源データポータルとして推進されている DARIAH-DE(https://de.dariah.eu/en_US/)経由でみてみると、Deutsches Textarchiv(https://www.deutschestextarchiv.de/)が1600~1900年頃までの4,661作品をTEIに準拠したデータとして公開している等、機械可読性の高いデータの蓄積が着々と行われつつある。米国でも HathiTrust において主に米国各地の大学図書館に所蔵される著作権保護期間中の書籍も含めた膨大な量のテキストデータが集約され研究者に向けた利用の枠組みを提供している。
しかしながら、その種のデータについては、分野にもよるものの、少なくとも日本においては、人文学全体としては作成・公開・共有するためのコンセンサスは十分に得られているとは言いがたい。国内のデジタル・ヒューマニティーズ関連の学会・研究会での数多の発表に見られるように着実に進展しつつあるが、そのようなデータの公開については研究の先取権だけでなく、プライバシーや著作権などの問題が生じるようなものもあり得るため、一気呵成に推進することは難しく、丁寧な議論と合意形成に基づく着実な進行が必要だろう。
3.2 質的研究に資するデータ
一方で、研究成果からやや遠いものの、デジタルカメラをはじめとするセンサーを介して研究対象となる資料をデジタル化して共有することは近年徐々に盛んになりつつある。日本ではデジタルアーカイブと呼ばれるものであり、海外ではデジタルコレクションやデジタルミュージアム、デジタルアーカイブズなど、専門分野に応じた呼称が用いられることが多いようである。いずれにしても、デジタル画像の作成と公開が容易になってきたことや、デジタル画像を効率的かつ効果的に共有する枠組みとしてのIIIFが普及したこともあり、著作権やプライバシー保護、マネタイズ可能性、信仰上の理由など、いくつかの制約はあるものの、その種のデータが公開され共有される流れは定着しつつあるように思われる。
研究成果へのプロセスとしての研究データが研究対象への解釈を中心とするものと位置づけ得るなら、それと比較すると、この種のデータ(ここでは「研究素材データ」と呼んでおく)は、それとは異なる方向性を持つものと言える。すなわち、これは、可能な限り原資料に忠実であることを目指して作成されたデータであり、換言すれば、誰がデジタル化してもあまり差異のないデータということもできる。原資料に忠実であろうとするが故に、何らかの解釈であるところの研究成果に至るプロセスの一部という意味に関しては可能な限りの捨象が志向されており、そのような意味での研究データではない。しかし、研究に資するデータという意味での研究データと捉えることはできる。なお、厳密に言えばこの場合にも文化的社会的制約に基づく暗黙的な解釈を完全に捨象することはできないはずだが、ここではその点は議論の対象としない。
このようなデータは、デジタル化されているとは言え、少し前までは研究成果に結びつけるまでにはかなりの距離があった。研究プロセスに位置付けて考えてみると、人が読んで解釈を検討する点では変化がない。その資料を探索する手間が多かれ少なかれ省力化でき、そして、デジタル画像で閲覧できるものであれば、閲覧するための様々な手続きや労力を大幅に省力化できることになった、ということになる。省力化がもたらした効率化が研究そのものにも変化をもたらしている可能性は十分に期待されるところだが、それを検証するのはまた別の機会としたい。ここで検討しておきたいのは、この距離を近づける手立てとなる可能性を提示する技術としての人文学オープンデータ共同利用センターによるくずし字 OCR や、国立国会図書館の古典籍 OCR ソフトウェアをはじめとするディープラーニング技術に基づく OCR であり、そして、そのプロセスを公共化することで距離を近づける道を提示した、国内では「みんなで翻刻」に代表されるクラウドソーシング翻刻、すなわち、テキスト化、あるいはデジタル翻刻である。
4. 質的研究における量的データの課題
デジタル翻刻においてよく問題とされるのは、正確性という課題である。確かに、正確性が求められる場面であれば、このような、ディープラーニングによる読み取りの結果やクラウドソーシングによる作業結果は扱いが難しい。しかしながら、必ずしも完全な正確性を求めるような用途ばかりではない。まず、ある程度の誤りを含むことを前提とした利用方法を検討することには、少なくない価値があると思われる。質的研究においては、最終的には研究者の気づきを支援するという意味での量的データの活用が一つの重要な要素である。その場合には、必ずしも正確な情報が得られなくとも、大まかな傾向やイレギュラーな情報を容易に確認できる環境が提供されれば、そこで得た気づきを踏まえて元資料(あるいはそのデジタル版)にアクセスして内容を確認しつつ、議論を組立てることができるだろう。ただし、この利用方法の場合、研究データの利用は気づきを得たことにとどまるため、研究成果に至るプロセスの中で研究データを位置づけることが若干難しい面がある。というのは、気づきを得ること自体は研究データを利用せずとも、研究対象となる資料等に直接あたることでも可能であり、また、現在のオープンサイエンスの枠組みでは、気づきを得る程度のことであれば研究データを利用したことを明示する必要性が薄いからである。このことについては、むしろ、このような利用方法であっても、利用したことを積極的に明示するべきであるというコンセンサスを形成していくことが必要かもしれない。というのは、研究データの構築と運用の継続において利用実績は重要なファクターとなり得るからである。
また、両者をあわせたような、正確性を高めるプラットフォームの開発も期待されるところである。ディープラーニング OCR (あるいは AI-OCR)によって作成されたデータをクラウドソーシングによって確認・修正するような仕組みを効率的に実施可能なシステムが待たれるところである。これについては筆者も取り組んでいるところであり、別稿を期したい。
一方、資料の正確性については、既存の人文学においても無問題というわけではない。世間を騒がせるような大きな問題だけでなく、たとえば、学術的な印刷物であっても間違いが存在しないというわけではない。誤植の結果、正誤表がついている本は少ないとは言え、ないわけではない。そして、刊行当時は完全無欠のものだったとしても、時代が下るにつれて新たな事実が判明したりして書き換えが必要になってくる場合もある。加藤洋介氏の手になる『源氏物語校異集成(稿)』(http://www2.kansai-u.ac.jp/ok_matsu/)における『源氏物語大成』に対する校異情報の追記修正はその種の典型例であると見ることもできる。これは、誤りが出た場合に訂正する手続きがコミュニティで共有されている例として理解することは可能である。しかしながら、正誤表や後世の修正・書き換えといったことが正確性を担保する仕組みとして機能していると期待したいところだが、正誤表は常に参照できるところに用意されているとは限らず、正誤表の有無の確認は書籍の流通と利用のスキームに常に適切に組込まれているわけでもない。個々の研究者の努力に委ねられているのだとしたら、この状況において研究資料の完全性を担保する仕組みは十分に機能してきたと言えるのかどうか、今後の議論が必要となる課題であると筆者は考えている。
5. 終わりに
このように考えてくると、我々がこれまで何を見てきたのか、ということは、デジタル媒体や AI-OCR、クラウドソーシング等によって作成されたデータを前にした時に改めて問い直す必要が出てきている課題であるように思える。このようにして、我々が何をどのようにして探求してきたかを検討することは、これからはどうなのか、ということを考える上でも、重要なことである。この機会が、広く様々な立場の研究者に活かされ、よりよい学術研究の世界を形成していくことを願っている。
《連載》「欧州・中東デジタル・ヒューマニティーズ動向」第63回
「古代エジプト民衆文字(デモティック)の字形画像データベースとテキストコーパス: Demotic Palaeographical Database Project」
前回は、古代エジプト文字のうち、神官文字(ヒエラティック)の字形画像データベースである AKU PAL について述べたが、今回は、古代エジプト文字のうちの民衆文字(デモティック)の字形画像データベースについて述べる。AKU PAL は、ラインラント=プファルツ州のマインツにあるヨハネス・グーテンベルク大学マインツ(通称マインツ大学)が中心となって開発したウェブアプリであるが、今回紹介する「the Demotic Palaeographical Database Project」、通称 DPDP[1]は、バーデン=ヴュルテンベルク州北西部のハイデルベルクにあるループレヒト・カール大学ハイデルベルク(通称ハイデルベルク大学)が開発している。
「Demotic Palaeographical Database Project」は、古代エジプトのデモティックで書かれた文献資料に関する包括的なデータベースプロジェクトである。デモティックは古代エジプト文字の一つである。古代エジプト文字のヒエラティック(神官文字)から派生したこの文字は末期王朝時代の紀元前7世紀頃からビザンツ帝国の初期の紀元後5世紀まで使われた。この文字で記されたエジプト語を民衆文字エジプト語(Demotic Egyptian)と言う。民衆文字エジプト語の文法は、エジプト語の最終段階のコプト語の文法に非常に近い。この DPDP プロジェクトの目的は、古代エジプトのデモティック文書を体系的に収集・分析・分類し、それを研究者や一般の人々と共有することである。プロジェクトリーダーはハイデルベルク大学教授で、デモティックの研究者として世界的にも著名な Joachim F. Quack 教授であり、プロジェクトメンバーには Claudia Maderna-Sieben 博士、Jannik Korte 氏、Fabian Wespi 氏などが名を連ねている。
DPDP データベースは、エジプト全土から収集された文書を含んでいる。年代も紀元前7世紀から紀元後5世紀までと非常に幅広く、このような多様性は、古代エジプトの社会、文化、宗教について多角的に理解するための貴重な資料となっている。
このデータベースのウェブアプリには、(1) djehuti (limited access)、(2) corpus、 (3) palaeography (beta version)、(4) full text search (beta version) と言う4つのモジュールがある。djehuti に関しては、現在、一般公開されておらず、どのような機能があるのか、明らかにされていない。
Corpus モジュールは、デモティックの文献のテキスト、すなわち、コーパスとその翻訳、そしてメタデータを見ることができる。コーパスとは、特定の言語や時代、地域に基づいて収集されたテキストの集合体であり、言語学、文献学、歴史学などの多岐にわたる研究に不可欠な資料である。デモティック文献には法的文書、手紙、領収書、神託、祭りや儀式に関する文書、物語など、多岐にわたる内容が含まれている。各文書エントリには、識別子、文書の種類、発見された場所、文書の年代、他のプロジェクトで定められた識別コード(TM や TLA など)が明記されている。識別子は、文書がどのコレクションや場所に保管されているのかを示す一意のコードである。文書の種類は、それが法的文書であるのか、手紙であるのか、領収書であるのかといった情報を提供する。発見された場所と年代は、文書がどの地域や時代のものであるのかを理解する上で重要な情報である。残念ながら、現在は、これらのコーパスは PDF でのみ公開されている。テキストや訳を一括検索などでき、さらにグロスや品詞などのタグがついているタグ付きコーパスの開発が待たれる。説明や翻訳で用いられている言語は、筆者が調べた限りでは、ドイツ語であり、世界のエジプト学者に向けて、英語版の作成も必要であろう。
Palaeography モジュールは、その名の通り古書体学的データベースであり、デモティックの各時代・各地域の様々な字形画像を検索することができる。デモティックにはこれまで、このような大規模なオンラインデータベースは存在せず、1954年に出版された Wolija Erichsen の語彙集[2]やシカゴ大学古代文化研究所の「Chicago Demotic Dictionary」[3]に記載されている諸字体を参照するしか方法はなかった。ルートヴィヒ・マクシミリアン大学ミュンヘンがデモティックのオンラインワードリスト[4]を公開しているものの、異なる字形に関するデータの量は、Erichsen の語彙集を超えるほどには至っていない。筆者は東海大学に所蔵されている鈴木コレクション[5]のデモティックパピルスに関する、ジョンズ・ホプキンス大学とイェール大学の合同調査チームに同行したことがあるが、デモティックの専門家は、Erichsen の語彙集を主に用いて、そこに掲載されている字形データを調べていた。しかし、その作業には、ページをめくったり、そのページから、現在読んでいる民衆文字文献にある不明文字の形に近いものを選ばなければならず、特定作業には時間がかかる。
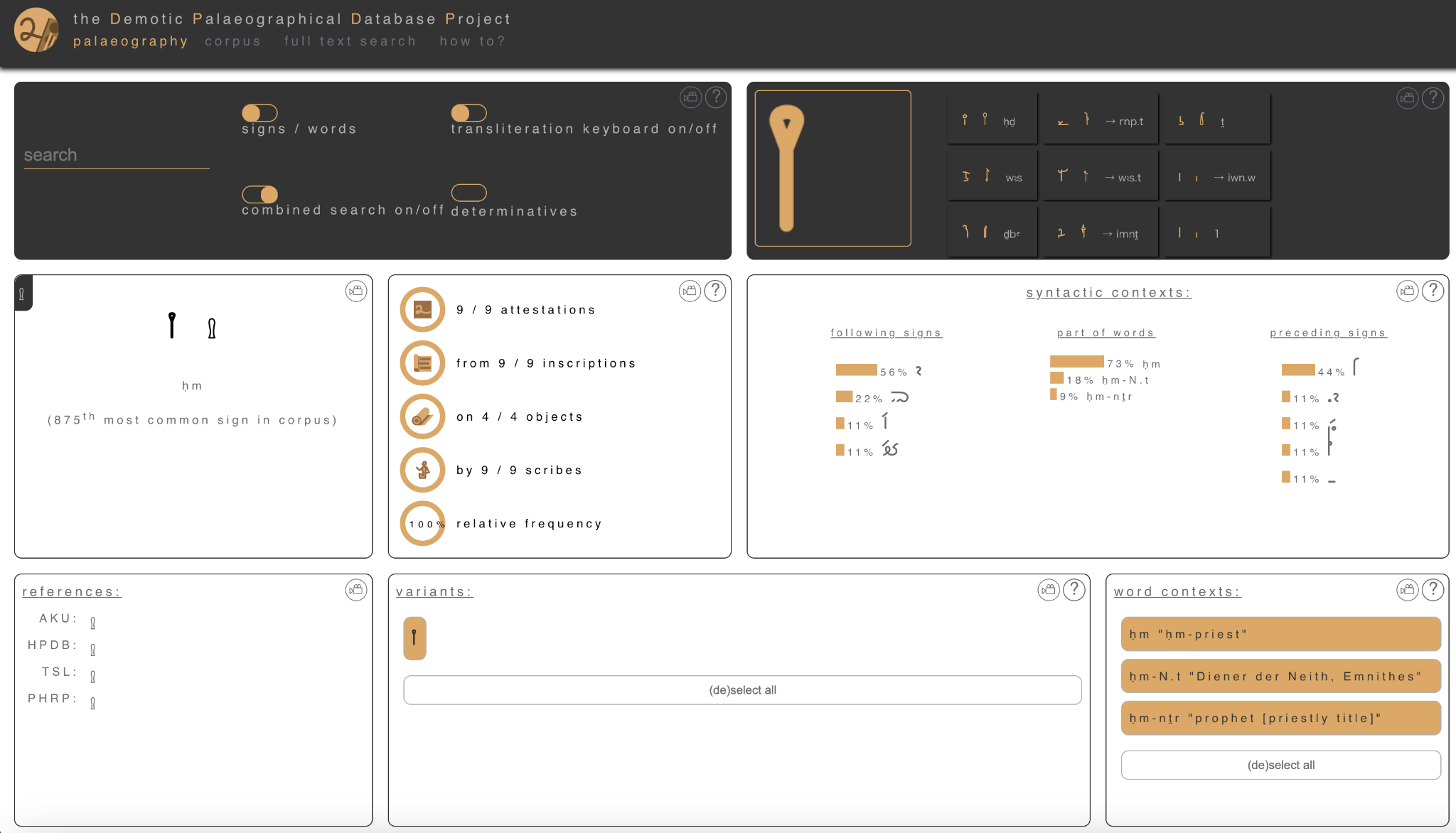
特定の文字を検索、あるいは一覧から選択すると、図1のように、その文字の情報が表示される。図1の左上は、このデモティックの文字と対応するヒエログリフ、および子音転写と、文字データベースにおける頻度ランキングにおける順位が書かれている。上段の真ん中のセクションは、出現頻度などが書かれ、上段右は、その文字が出てくる前後の文字文脈、あるいは、その文字が一部で用いられる単語とその文脈で用いられる割合が表示される。その下の段では、前回紹介した、神官文字データベースの AKU PAL など他の古代エジプト文字のデータベースやコーパスへのリンクがなされ、その文字の変種や、その文字が使われている単語の意味が示される。さらにその下にスクロールすると、図2のような画面が表示される。
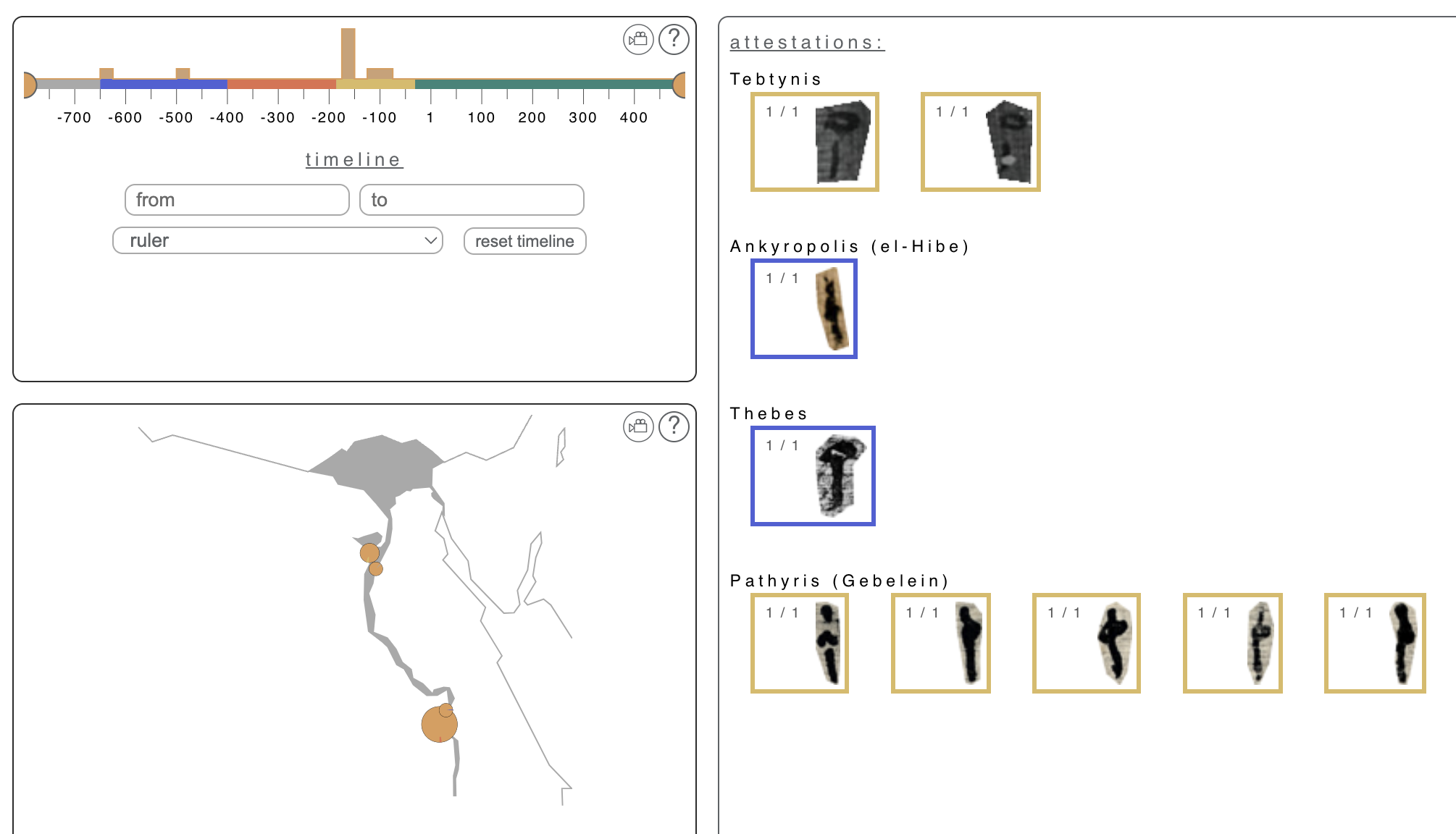
図2の画面では、この文字の発見場所別の字形画像(右)と時代別の出現頻度(左上)、そして地域別の出現頻度(左下)が表されている。このように、Erichsen の語彙集や「Chicago Demotic Dictionary」だけでは表せなかった大量の字形画像の提供や、それらの時代・地域の視覚化がなされていると言う点で、本データベースは革命的と言える。ただし、現在の時点では、デモティックの一部の文字のデータしか公開されておらず、さらなるデータの拡充とそれらの公開が待たれる。
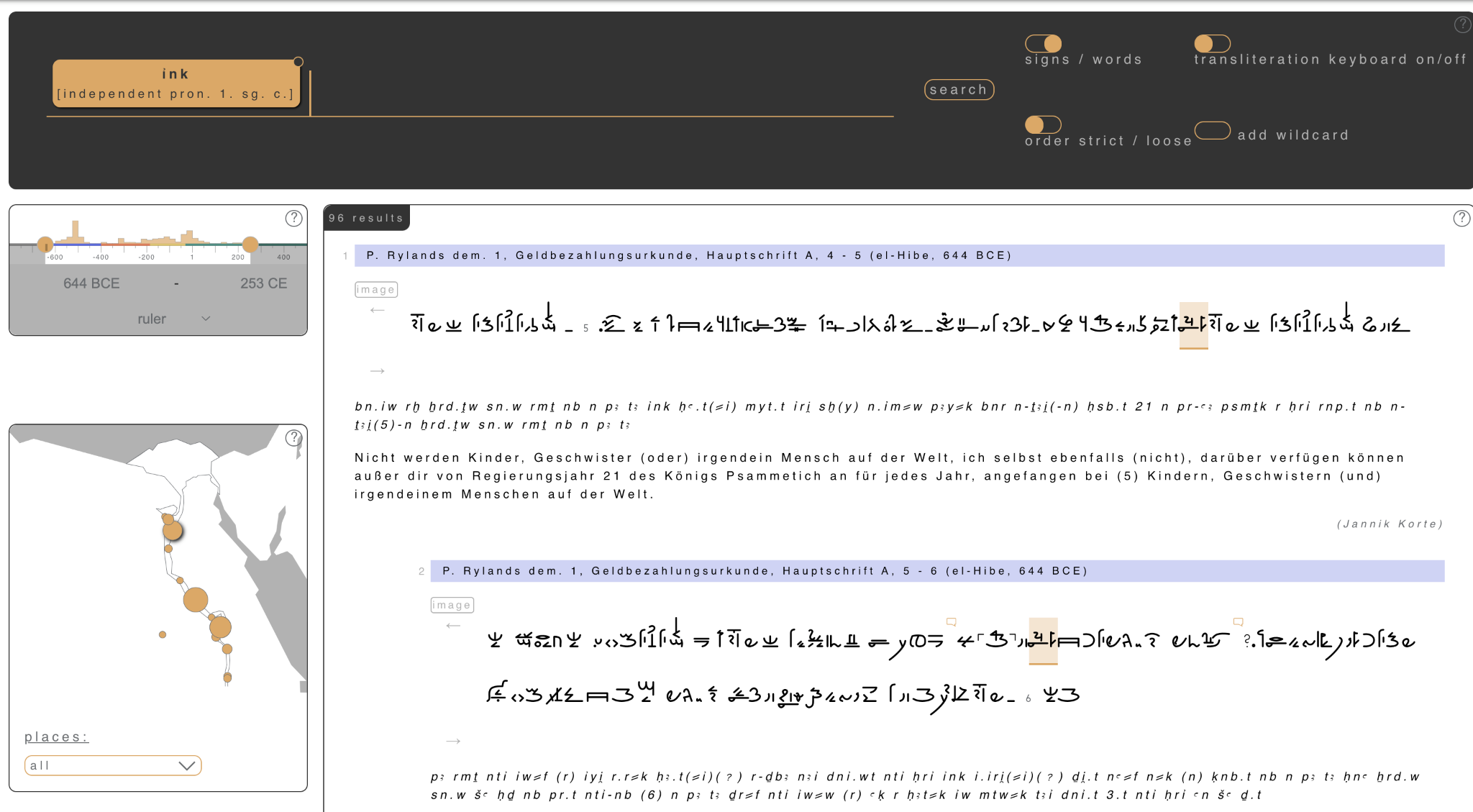
最後に、このプロジェクトでは、古書体学に基づいた全文検索(full text search)も可能である。ここでは、特定の書体、文字、修飾、時代、地域などで条件づけながら、特定の語彙を検索できる。検索結果は、図3のように、コンコーダンスとして前文脈と後文脈を表示させながら、ラテン文字音写と現代語への翻訳付きで閲覧することができる。
以上のように、「the Demotic Palaeographical Database Project」は、古代エジプトのデモティック文献資料に関する研究を飛躍的に前進させる可能性を秘めた、多機能かつ高度なデータベースである。このデータベースを通じて、古代エジプトに関する多くの未解決の問題や新たな研究テーマが明らかになることが期待されている。
- コメントを投稿するにはログインしてください