人文情報学月報第98号
ISSN 2189-1621 / 2011年8月27日創刊
目次
- 《巻頭言》「歴史地震学・人文情報学・みんなで翻刻」
:東京大学地震研究所・東京大学地震火山史料連携研究機構 - 《連載》「Digital Japanese Studies 寸見」第54回
「漢デジ2019参加録」
:国文学研究資料館古典籍共同研究事業センター - 《連載》「欧州・中東デジタル・ヒューマニティーズ動向」第16回
「歴史文書の手書きテクスト認識(HTR)に関して」
:ゲッティンゲン大学 - 人文情報学イベント関連カレンダー
- イベントレポート「18世紀研究における DH の広がり:第15回国際十八世紀学会(ISECS 2019)に参加して 第2回:各種ウェブコンテンツの紹介 (1)」
:お茶の水女子大学大学院人間文化創成科学研究科 - イベントレポート「JADH2019参加報告(前編)」
小川潤:東京大学大学院人文社会系研究科 - 編集後記
《巻頭言》「歴史地震学・人文情報学・みんなで翻刻」
『人文情報学月報』を購読されている皆さんは、「人文情報学」についてはよくご存じのことと思います。では、「歴史地震学」はいかがでしょうか? 歴史時代に発生した地震を調べるのが「歴史地震学」です。過去の地震を調べるために歴史史料を用いることに主眼を置いて、「史料地震学」といわれることもあります。現代の私たちが地震の揺れを感じ、ときには災害に直面するのと同じように、過去の人々も地震を体験し、さまざまに記録してきました。地震について書かれた史資料を分析し、過去に発生した地震について明らかにするわけです。異なる学問分野の名前をつなげたような、境界領域を相手にするという方針が見えるようなところで「人文情報学」と似たようなつくりのことばかもしれません。私は2012年ごろから徐々に歴史地震の研究に取り組みはじめました。本稿では、私がここ数年で体験し、自らとてもおもしろいと思っている取り組みについてご紹介します。
中西一郎さん(京都大学名誉教授)らとともに京都大学古地震研究会[1]で史料解読の勉強をはじめました。2012年ごろのことです。この研究会では、計算機やインターネットの活用には当初から注目していました。その後、林晋さん(京都大学名誉教授)や橋本雄太さん(国立歴史民俗博物館助教)を通じて人文情報学と出会い[2]、古地震研究会の活動のきっかけのひとつとなったくずし字学習支援アプリ「KuLA」のリリース(大阪大学)があり、そして古地震研究会から「みんなで翻刻」[3]が生まれました。じんもんこんシンポジウム2017[4]で基調講演にご指名いただいたこともあってか、人文情報学との接点が増えながら今に至ります。
地震学においては、観測にも解析にも計算機やネットワークを用いるのはあたりまえであり、私も学生のころからプログラミングに親しんでいました。そんな私にとって、歴史史料を用いた地震研究に計算機やネットワーク技術を利用するのはごく自然なことでした。古地震研究会では、史料を撮影した画像を見ながらワープロソフトで翻刻を入力し、それをファイル共有サービスで共有するという作業手順をとっていましたが、このような作業に有用なツールを検索したところ「SMART-GS」[5]にいきあたりました。また、歴史地震学の先輩方によって編さんされた地震史料集は、東京大学地震研究所図書室の特別資料データベース[6]において PDF 形式で公開されていたため、これをダウンロードして簡易 OCR で検索可能な PDF にして利用していました。大部の地震史料集の一部については、既にデータベース化がなされていました[7]。既に歴史地震学を舞台に人文情報学的な取り組みがなされていたのです。その後、既刊の地震史料集の項目の検索に特化したシステムも地震研究者によって公開されました[8]。なお、この検索システムからは IIIF を利用して一部の既刊の史料集の版面画像へのリンクが用意されています。
最近では歴史地震学における史資料の情報化をさらに進め、歴史地震に関する個別の研究成果や地震カタログから、その結論あるいは議論の基礎となった史資料まで(容易に)遡れるような仕組みを作れるのではないかと考えています。上記の IIIF を利用した史料集版面へのリンクはその好例です。歴史地震学で用いられるデータは、原資料、翻刻テキスト、それらを解釈・分析したものなど多様で、しかも紙媒体とデジタルデータとが混在しています。これらをうまく整理し、相互にリンクすることで、新しい切り口での研究の基盤となるとともに、研究成果の再利用や再検証が容易な環境につながるのではないでしょうか。
さて、2017年1月にリリースした「みんなで翻刻」には【地震史料】というサブタイトルがついています[9]。「みんなで翻刻」の仕組み自体は翻刻が必要な史資料に汎用的に使えるものですが、古地震研究会が地震史料を対象とするのはある意味当然でした。最初の対象としては、東京大学地震研究所が所蔵する「石本文庫」と決めました。既に古地震研究会で翻刻作業をはじめていたこと、114点と手頃な分量であること、既にデジタルアーカイブ[10]どが理由です。地震学の分野では観測データの共有・公開が進んでいたことも後押しになると考えました。また、地震史料を取りあげることで、解読プロジェクトへの興味・関心が高まるであろうと期待しました。リリース時期を最終的に1月にしたのは、1995年兵庫県南部地震の報道など、関西で地震災害への関心が高まる時期であることを踏まえてのことです。オープンな取り組みであるがために、学内の学術研究支援や広報関係者とも相談しながら、一般の方やメディアへの展開も意識してプロジェクトを進める経験をしたことは、その後の研究活動にも良い影響を与えています。
2019年7月には「みんなで翻刻」の新バージョンをリリースしました[11]。IIIF に対応し、各地の所蔵機関が公開するアーカイブの史資料を「みんなで翻刻」できることを示すため、「東京大学総合図書館所蔵石本コレクション」[12]と「東寺百合文書」[13]とを登録しています。翻刻テキストを入力するエディタを一新したいっぽうで、学習をベースとしたプロジェクト設計など、旧バージョンで得たノウハウを最大限に継承しています。まだ「みんなで翻刻」をご体験いただいていない方は、冷やかしでもかまいませんので、ぜひ一度ログインしてみていただきたいと思います。
ここのところ、「歴史学×地球惑星科学」と題して、地震学だけでなく、天文学や気象学、気候学など、地球惑星科学の各分野の研究者とともに歴史学との協働を考えるプロジェクトをはじめました。過去の人々が残した身のまわりで起こる出来事の記録の中には、地球惑星科学が対象とする自然現象の分析にたえるものが多数存在します。過去の人々が自然現象をどう認識し、また自然現象が人々や社会にどのような影響を与えたのかというのも興味深いテーマです。地球惑星科学連合2019年大会での同名のセッション[14]などを通して、プロジェクト形成を進めています。分野を越えた協働において人文情報学の役割が大きく、また、人文情報学からすれば、恰好の実践の場になるのではないでしょうか。関連する方々にもぜひご協力いただきたいと思っています。
執筆者プロフィール
《連載》「Digital Japanese Studies 寸見」第54回
「漢デジ2019参加録」
2019年8月22日から24日にかけて、北海道大学文学研究院において「漢デジ2019」が行われた[1]。これは、科研費プロジェクト「平安時代漢字字書総合データベースの機能高度化と類聚名義抄注釈の作成」(代表:池田証壽)の主催で行われたもので、「漢デジ」の名でここ数年行われてきた研究集会のシリーズである。「漢デジ」がなにに立脚した名称かは分らないが、「漢字(字書)とデジタル」あたりなのではなかろうか。
今年度は、22日から23日にかけて「日本古辞書解読セミナー」が行われ、24日に研究講演会が行われるという進行であった。古辞書解読セミナーにおいては、『篆隷万象名義』(平安初期成立)・『新撰字鏡』(900年ごろ成立)・図書寮本『類聚名義抄』(11世紀後半成立か)・観智院本『類聚名義抄』(12世紀後半成立か)の4点の日本の古字書(室町以前の字書)を対象にそれぞれ3時間ずつ概説およびグループに分かれての読解が行われた。古字書のコピーをかたわらに写しつつ他の資料と突き合わせて精読をしてゆくのは、筆者には院生の池田先生のゼミ以来で、入り組んだテキストの構成に容易に近づきがたい感覚を思い出した[2]。古字書の精読ははじめてという参加者もおり、思い掛けない質問に考えさせられもした。
セミナーでは意図的にデジタルの要素を減らしたということであったが、最終日の研究講演会では、筆者のものもふくめ5件中3件がデジタル人文学関係の発表であった。まず、ひとつめは劉冠偉氏の「HDIC Viewer 2019の現状」で、このプロジェクトで構築が進められている平安時代漢字字書総合データベース(Integrated Database of Hanzi Dictionaries in Early Japan; HDIC)のウェブ閲覧システムであるHDIC Viewerの現状について報告がなされた。HDIC では、上記の字書にくわえて、上記字書の編纂に大きな影響を与えた中国の字書についてもデータベースの構築が進められており、関係データベースによって相互の影響関係が記述されている[3]。そのデータベースへは直接アクセスはできず、個々のデータベースがダンプされた CSV が GitHub において公開されている[4]。このほか、検索の便をはかったり、その他のデータを提供したりする UI として提供されるのが HDIC Viewer である[5]。近時追加された字書や機能、内部公開のもの、今後の展望などについて報告があった。
このほか、筆者が「TEI による辞書符号化の動向と課題: TEI-Lex0プロジェクトは古辞書に応用できるのか?」と題して報告を行った。古字書のTEI(Text Encoding Initiative)符号化を筆者が試みたことがあるわけではないのだが、TEIにかぎらず既存の標準による符号化には、単なるタグの当てはめでは解決しがたい問題が多々あり、その枠組みのなかで解決を模索することは本文理解にも資すことが多いことから、TEIによる辞書符号化(欧米言語の例がほとんどである)の動向、とくに既存の TEI の辞書符号化に対する再考を促す TEI-Lex0プロジェクトの紹介をとおして[6]、古字書の符号化におけるコストバランスの検討を試みたものである。TEI-Lex0プロジェクトは、ミニマルな電子辞書作成をつよく志したところがあり、関係情報の構造を効率的に符号化するためのものとなっているため、そもそも古字書にそのまま適用できるものとはなっていないが、そのゆえに TEI-Lex0でどこまで符号化でき、どこからできず、その際にどのような代案を模索するかはその字書の特性を考えるうえでも多くの知的貢献をもたらすものと考えられる。今回は、時間の都合で TEI-Lex0の紹介に留まったが、考察を深める価値はあろう。
最後の発表として、永崎研宣氏の「デジタル環境を活かした文字画像共有システムの構築」が報告された。これは、文字画像を切り出す際のデジタル環境の動向について報告されたものであり、HDIC プロジェクトなどとも連携しているという。話の主眼は永崎氏の開発した文字切り出し関係ツールの紹介にあり、SAT 大正新脩大蔵経テキストデータベースの外字管理と Unicode 登録申請のために開発がはじめられたという経緯、さまざまなプロジェクトの需要にあわせて機能追加などが行われてきた歴史などが話され、とりわけ、IIIF 対応によって切り出すもととなった画像との連携が容易かつ確実になったこと、今後は、異体字の整理を行うための機能整理を進めてゆくことなどが述べられた。 デジタル環境の変化は日々にいやはげしく、しかもその変化がすべてよいものではないし、またすべてに対応しなくとも体感的にはなんとかなってしまうのは、まるで地球環境問題のようである。「漢デジ2019」で示されたものは、(筆者のものを除いて)第一線級の成果であることに疑いはないが、いかなる面からもということはないだろう。そのような多面的な深化をいかにしてゆくか、また、ここで示された最先端の成果をどのように受け入れてもらってゆくかが今後の発展として問われるのではないかと考えるのであった。
漢デジ2019(2019年8月22日(木)~24日(土)、北海道大学文学研究院323室および人文・社会総合教育研究棟 W309(札幌市北区北10西7)) - 文学通信|多様な情報をつなげ、多くの「問い」を世に生み出す出版社 https://bungaku-report.com/blog/2019/08/20192019822-24-323w309107.html
いよいよ刊行!!待ち望まれた決定版(図書館必携書) 『類聚名義抄 観智院本』の世界(八木書店) 大槻信インタビュー〈寄稿・近藤泰弘〉|書評専門紙「週刊読書人ウェブ」https://dokushojin.com/article.html?i=3552
《連載》「欧州・中東デジタル・ヒューマニティーズ動向」第16回
「歴史文書の手書きテクスト認識(HTR)に関して」
近年、ヨーロッパでは、HTR、すなわち Handwritten Text Recognition(手書きテクスト認識)の研究・開発が盛んである。
コプト語文献など古代末期の伝統を受け継ぐ文献文化では、15世紀にドイツのグーテンベルクによる活版印刷が開発され、その技術が広まりその言語に適用されるまで、手書きで写本のテクストを書くことが主流であった。東アジアで盛んであったような木版印刷は通常あまり行われなかった。また、古代末期にはほとんど使用が廃れていたヒエログリフや楔形文字など、古代に使用された表語文字、表音文字、限定符の混合体を除けば、古代末期の地中海世界で用いられていた文字は、コプト文字、ギリシア文字、アラム文字、ヘブライ文字、アルメニア文字、ジョージア文字、シリア文字、ナバテア文字、ラテン文字、アラビア文字などであり、表音文字がほとんどであるため、文字数は、東アジアの漢字よりもはるかに少ない。
コプト文字は、あまり使われない文字を除くと、24のギリシア文字に6–8の民衆文字由来の文字を加えたものであり、文字は30–32個程度である。コプト語では、パピルスやオストラカなどに書かれた手紙などは筆記体でリガチャーがあり、HTRが大変難しいものの、聖書や典礼書など、特に典礼で用いられるキリスト教文献は、大変はっきりしたアンシャル体で書かれており、これらの文献に関しては、HTR は比較的容易であると推測される。大文字・小文字も、基本的に区別はなく、パラグラフの冒頭で時に用いられる、通常の文字とはサイズ以外は形は変わらない大きなサイズの文字を大文字(専門用語でエクテシスと呼ばれる)と呼称しているに過ぎない。ちなみに、当時のギリシア文字も現代におけるような大文字・小文字の区別はなかった。アンシャル体は、基本は現代のギリシア文字の大文字に近いが、シグマが C のように書かれるなど、微妙に異なる。現代のギリシア語に見られるような小文字が生じたのは、9世紀以降のことと言われている。
アラビア語などのようなリガチャーが筆記体以外ではないコプト文字の唯一の問題は、文字の上につくダイアクリティカル・マークの種類と使用が多いことであるが、それでも、ヒエログリフ、神官文字、民衆文字、楔形文字、漢字などの文字の種類が多い文字に比べると、コプト文字では、HTR や OCR は容易であると言わざるを得ない。
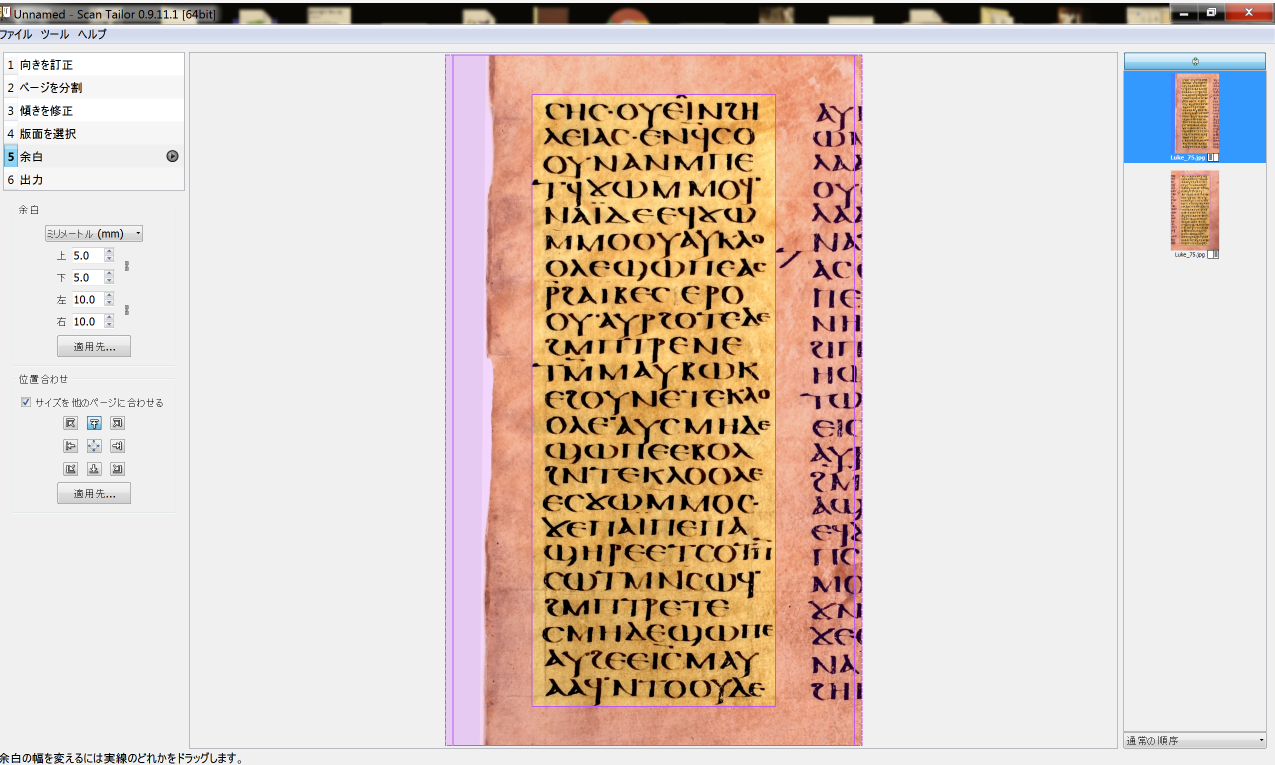
本稿ではこのような歴史的な手書きの文字資料のデジタル翻刻を自動的に抽出する方法に関して論ずる。先月号で紹介した OCR でも手書き文字を認識することは可能である。筆者とマックス・プランク生物物理化学研究所のコンピュータ科学者であった Kirill Bulert は、OCRopy を使って、コプト語手書き写本の認識を試みた。プリ・プロセッシングとして、DVCTVS(http://dvctvs.upf.edu/)からダウンロードしたコプト語文献の高精細画像を自動的に処理できるフリーソフトウェア ScanTailor(https://scantailor.org/)を用いて、白黒にバイナリ化、カラム(列)の分割、傾きの補正、余白の調節、ダストの除去などを行った。
{kind=link}

その後、グラウンド・トゥルス、つまり OCR の機械学習の学習材料を作成し、、植字されたテクストと同様、OCRopy でトレーニングをした後、いくつか画像を与え、認識の精度を確かめた。グラウンド・トゥルスで用いた画像であれば、精度は90%以上を達成したものの、グラウンド・トゥルスで用いた画像以外では70%程度が多く、実用化には向いていないことが判明した。植字された文献ではグラウンド・トゥルスはコプト語では5–10ページで十分であったが、手書き写本の場合は、より多くのグラウンド・トゥルスが必要と思われる。このように OCR ソフトウェアで手書き写本の文字を読み取ることは可能ではあるが、困難がある。
Transkribus
このように、OCR だけでは手書きのテクストの認識に困難が伴うため、近年、手書きのテクストを認識することに特化した HTR の開発が盛んであり、その代表例が Transkribus である。Transkribus は、READ(Recognition and Enrichment of Archival Documents)プロジェクト(https://read.transkribus.eu/)のもと、オーストリアのインスブルック大学を中心に開発され、スペインのバレンシア工科大学、ドイツのグライフスバルト大学、フィンランドのフィンランド国立公文書館など12の研究機関との共同で作られたものである(https://read.transkribus.eu/network/)。
筆者はセミナーで Transkribus の使い方を学び、現在 Kirill Bulert とともにコプト語での実用化を模索している。筆者も博士論文を終えた後、本格的に、Traskribus を使用する予定である。
Transkribus は GUI を備えており、GUI なしの OCRopy や Ocrocis と比べ、コンピュータに詳しくない者でも GUI を通して容易に用いることができる。Transkribus には Windows 版、Mac 版、Linux 版がある。これは、基本的に Linux でしか動かない OCRopy や、基本は Linux 上で動くが、Docker を介すれば Mac でも動く Ocrocis と比べて、より広いローカル環境で用いることができることを意味する。また、これら OCRopy などの OCR ソフトウェアとは異なり、Transkribus はバイナリ化(白黒化)や画像の補正などをScanTailorなどの別のソフトウェアで行う必要はない。Transkribus では、全ての画像やドキュメントは Transkribus のサーバーにアップロードされるため、ローカルで動かすことが基本の OCRopy などと比べてセキュリティの面で多少の課題がある。アップロードされたドキュメントは公開か非公開かを選べる。
Transkribus で画像を読み込んだ後は、まず、画像のうちテクストがある場所のセグメンテーションをする必要がある。セグメンテーションでは、ベースラインとリージョンの認識が自動で行われる。ベースラインとは、赤の線と点で表される、行を区切るためのラインであり、リージョンとは、緑のエリアで表される、複数行のカラムや文章のかたまりである。左から右の横書き、右から左の横書きの行の認識に対応している。その後、文字があるかどうかの認識が行われ、文字だと認識されたエリアは青でマーキングされる。
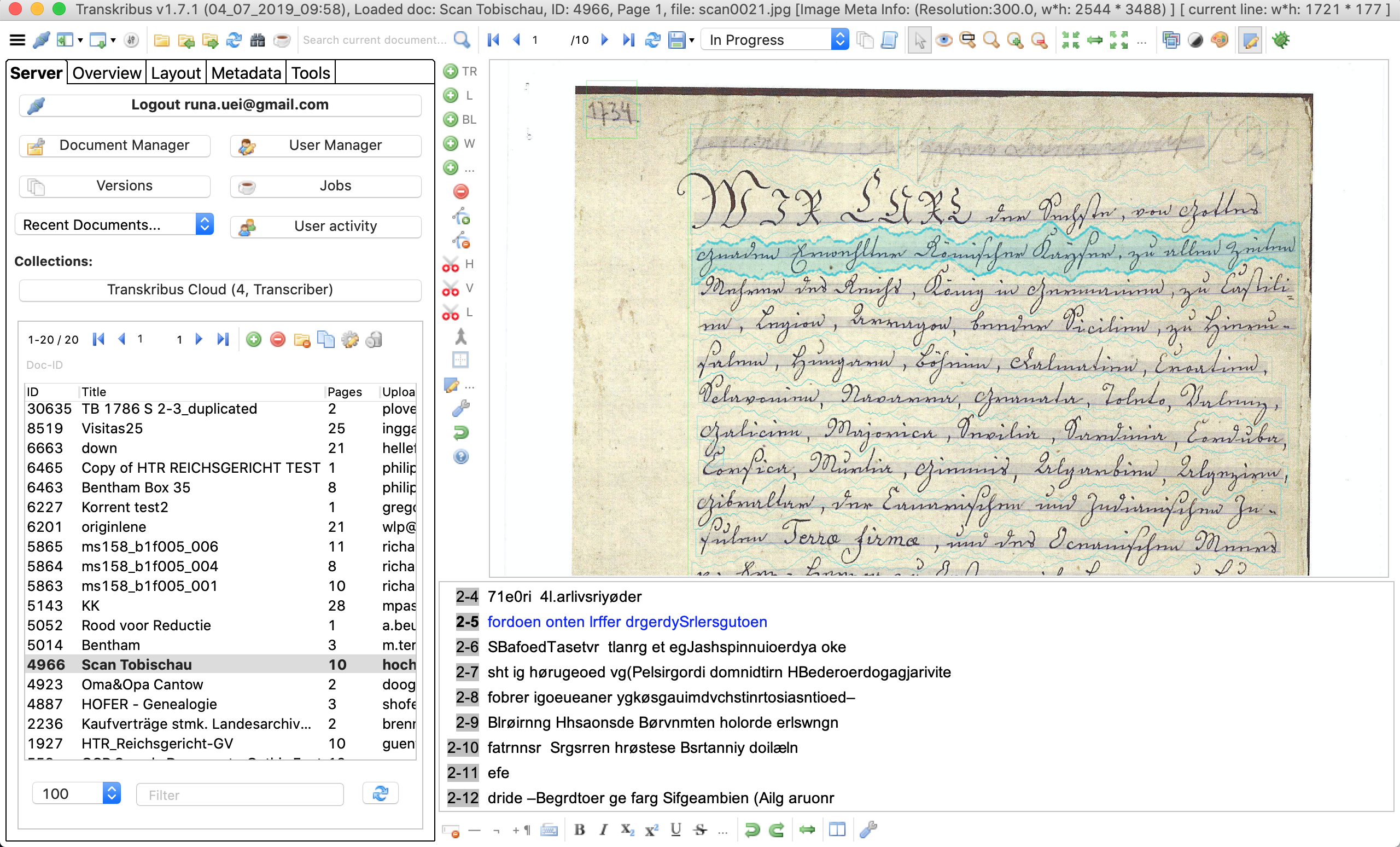
右下のプレーンに、青で表示されているその行に書かれている文字の翻刻を入力することが可能である。もちろん、このように手動で入力することもできるが、Transkribus には、自動で文字を認識する機能も備わっている。ただし、その場合は、複数のページを手動で入力することが必要である。Transkribus Wiki では100ページをまず手動で翻刻することが推奨されている[1]。ただし、50–75ページ程度でも、精度はおそらく落ちるものの、可能であるようである。この手動で入力されたデータをグラウンド・トゥルス、すなわち、HTR の機械学習の学習材料として用いて、モデルのトレーニングが行われる。ただし、モデルをトレーニングするフィーチャーはダウンロードしたデフォルトのヴァージョンには含まれておらず、Transkribus チームに連絡してフィーチャーを使用可能にする必要がある。コプト文字のように、Transkribus のライブラリにモデルがない文字の場合、一からトレーニングする必要がある。
このように Transkribus を新たな文字で用いるにはグラウンド・トゥルスを非常に多く用意しなければならず、それも書記、もしくは手書きのスタイル毎に用意しないとならない。筆者が研究しているコプト語の文献は、欠損部分が非常に多く、インクの劣化や裏写りなどによる不明瞭な部分も多く、また、書記による書体の差も大きいため、100ページ分のグラウンド・トゥルスを一から作成して HTR を動かすのは、効率的ではないように思われる。ただし、ある書き手が数多くのコーデックスの文字を書き、それらのコーデックスが欠損部分や不明瞭な部分も少ない完全に近いものであるとき、Transkribus は、大量の翻刻を自動で作成するための非常に有効なツールとなる。というのは、推奨される100ページ分のグラウンド・トゥルスの作成という、骨の折れる作業はあるものの、一旦トレーニングすると、同一書記の複数のコーデックスの翻刻を自動で生成できるからである。
作成した翻刻は、TEI XML や PDF で出力することができる。特に TEI XML による出力は、TEI が DH の標準の形式を制定し、数多くの DH プロジェクトが TEI XML で文献データを記録している今、大変重要であると思われる。また、Transkribus は、Keyword Spotting という、大変パワフルな検索ツールを備えている。
Transkribus に関しては、DH2017や DATeCH 2017などで数多くのセミナーが行われており、また、ウェビナーも多い。YouTube でも使い方が解説されている動画が複数公開されており、初学者にとっても大変学びやすいツールであると言えよう。ヘブライ語への適用に関しても、DiJeSt(ユダヤ学デジタル化プロジェクト; https://github.com/dijest/DiJeSt)を率いる Sinai Rusinek(ハイファ大学、イスラエル・オープン大学)が YouTube にて動画を公開しており、右から左に書く文字への適用の参考になる[2]。
筆者が博士論文で研究しているコプト語文献は欠損部や不明瞭部分が多く、もうすでに Virtual Manuscript Room(http://vmrcre.org/)を用いて翻刻を作成しているため、セミナーなどで試してきてはいるものの、まだ研究に Transkribus を十分役立てられていない。今後、博士課程後の研究において、欠損部分や不明瞭な部分が少ない複数のコプト語コーデックスで Transkribus を用い、デジタル・エディションおよびデジタル・テクスト・コーパスの作成に役立てたい。
人文情報学イベント関連カレンダー
【2019年10月】
-
2019-10-12 (Sat)
シンポジウム「デジタル知識基盤におけるパブリックドメイン資料の利用条件をめぐって」於・東京都/都市センターホテル -
2019-10-15 (Tue)〜2019-10-18 (Fri)
PNC2019於・シンガポール/Nanyang Technological University (NTU)
【2019年11月】
-
2019-11-04 (Mon)〜2019-11-07 (Thu)
ICADL A-LIEP 2019於・マレーシア/サンウェイ・プトラホテル -
2019-11-12 (Tue)〜2019-11-14 (Thu)
第21回図書館総合展於・神奈川県/パシフィコ横浜
【2019年12月】
-
2019-12-03 (Tue)〜2019-12-06 (Fri)
DADH2019於・台湾/国立台湾師範大学https://dadh2019.conf.tw/site/page.aspx?pid=901&sid=1308&lang=en
-
2019-12-14 (Sat)〜2019-12-15 (Sun)
じんもんこんシンポジウム於・大阪府/立命館大学
Digital Humanities Events カレンダー共同編集人
イベントレポート「18世紀研究における DH の広がり:第15回国際十八世紀学会(ISECS 2019)に参加して 第2回:各種ウェブコンテンツの紹介(1)」
1. はじめに
2019年7月14日(日)から19日(金)にかけて、エディンバラ大学にて第15回国際十八世紀学会(International Society of Eighteenth-Century Studies)大会が開催された。筆者は18世紀研究における DH の広がりを概観すべく、先月号より、本大会の参加報告を投稿している[1]。
今大会では、ヴォルテール財団[2]、COMHIS(Helsinki Computational History Group)[3]などの研究グループの紹介や、データベース・研究ツールの紹介が充実していた。それらの成果物には、すでに公開されて広く認知されているものもあれば、現在は公開準備中で、プロジェクトの構想が紹介されたものもある。第1回ではデジタル技術を取り入れた個別発表に焦点を当てたが、第2回である本稿と次の第3回では、18世紀研究に役立つウェブコンテンツには現在どのようなものがあるか、紹介されたプロジェクトに限定した情報を提供できれば幸いである。なお、筆者の専門は18世紀フランス史であるため、自身の研究に関連するコンテンツに比重を置いた記述となることをご了承いただきたい。
2. 18世紀研究に役立つウェブコンテンツ
2-1. 出版物を対象とした広範な検索ポータル:ESTC, Le gazetier universel
新聞等定期刊行物の広範な検索ポータルとしては、1473年から1800年までに発行された新聞や雑誌、書物を集めた ESTC(English Short Title Catalogue)[4]と、アンシアン・レジーム期および革命期フランスの新聞・雑誌を集めた Le gazetier universel[5]が紹介された。前者の ESTC は英国図書館によって運営され、英語、ウェールズ語、アイルランド語、ゲール語のテキスト、計48万件を超えるエントリが登録されている。一方後者の Le gazetier universel はフランス語の定期刊行物約800タイトルを対象とする検索ポータルで、Google Books や Gallica など約40のサイトに対して1.5万件のリンクを提供する。Le gazetier universel では、Dictionnaire des journaux[6]および Dictionnaire des journalistes[7]のデジタル版へのリンクや参考文献リストも併せて閲覧できるため、閲覧するタイトルがいかなる性格をもつのか、またどのような人物によって編集されたのかについても把握できる。
2-2. 特定の刊行物を対象としたデジタル校訂版テキスト:DIGITARIUM, MHARS, Philosophie cl@ndestine, ARTFL, ENCCRE
特定の新聞・雑誌を対象としたデジタル校訂版テキストとしては、18世紀のハプスブルク帝国における最重要メディアであった Wien[n]erisches Diarium(1703創刊)を対象とした DIGITARIUM[8]と、パリ王立科学アカデミー[9]の機関誌 Mémoires et Histoire de l'Académie Royale de Sciences(1666-1795)を対象とした MHARS[10]が紹介された。前者の DIGITARIUM では、プレーンテキストと画像データを同一画面上に表示して比較することができる。後者の MHARS はまだ電子化の途上にあるため、現在は生前科学アカデミーに属していた一部の物故会員に対する弔辞のテキストのみ閲覧できる。注釈としては、人名に BnF data や IdRef, VIAF へのリンクが付されている。プロジェクトリーダーである Maria Susana Seguin によれば、翻刻作業は OCR にかけたものをベースに学生の協力を得て手動で修正しているとのことである。翻刻終了後にはクラウド・ソーシングによる TEI/XML マークアップを行う構想もあり、MHARS の完全公開はしばらく先になりそうだ。なお、画像データはすでにフランス国立図書館が提供している[11]。
Seguin はさらに、哲学を対象とした啓蒙期の地下文書の書誌情報をまとめたウェブアプリケーションである Philosophie cl@ndestine: Les manuscrits philosophiques clandestins[12]も運用している。このアプリケーションでは、著作タイトル、著者プロフィール、著作画像・プレーンテキストを提供するだけでなく、実物を確認したいユーザに向けて所蔵館の情報を地図付きで提供している。エクスポート機能を使用して関心のある文書のリストをダウンロードすることもできる。
さらに、18世紀フランスの代表的な著作群である『百科全書』のデジタル校訂版は、The ARTFL Project(以下、ARTFL)と ENCCRE の2種類が公開されている。筆者はこれらの『百科全書』のデジタル校訂版を自身の研究に使っているため、若干の検討を試みる。まず ARTFL(American and French Research on the Treasury of the French Language)[13]はシカゴ大学を中心に、幅広いフランス語コーパスの編集(12–20世紀)と、研究者が容易にアクセスできるシステムの作成を目指すプロジェクトである。メインコーパスである ARTFL-FRANTEXT には2.15億語、単語別では67.5万語から構成されており、その一部に『百科全書』も含まれる[14]。ARTFL はテキストの電子化を行うためのノウハウやその後のデータ処理に関するプログラムも提供しており、次回取り上げる予定である FBTEE [15]などはその恩恵を享受している。
一方、ENCCRE(Édition Numérique Collaborative et CRitique de l’Encyclopédie ou Dictionnaire raisonné des sciences, des arts et des métiers(1751–1772))はフランス百科全書研究の第一人者 Marie Leca-Tsiomis を中心に構築され、2017年にフランス科学アカデミーからウェブ公開された『百科全書』研究のプラットフォームである[16]。同一画面上で、マザラン図書館に保存された『百科全書』初版の画像と TEI/XML でマークアップされたテキストを閲覧できるだけでなく、項目ごとのメタデータ、世界中の専門家による査読付き注釈、参考文献情報が提供される。操作メニューは英語で表示される ARTFL とは異なり、ENCCRE は注釈も含め全てフランス語で提供されているため、利用にはフランス語力が必要となるものの、今後『百科全書』研究者の間でシェアが広がることは間違いないだろう。
2-3. 特定の時期・ジャンルを対象としたデジタルアーカイブおよびデータベース:French Revolution Digital Archive, MEDIATE databases
スタンフォード大学図書館とフランス国立図書館の協働で実現した French Revolution Digital Archive[17]には、フランス革命期の主要な研究資料である膨大な画像群と議会記録が集められている。プレーンテキストと画像を同時に閲覧できるだけでなく、画像(jpeg)・テキスト(txt, pdf, TEI-XML)ともにダウンロード可能である。
18世紀の公衆に対する啓蒙のシステムを理解することを主眼に置いた研究グループ MEDIATE(Middlebrow Enlightenment: Disseminating Ideas, Authors, and Texts in Europe, 1665–1830)[18]は、1665年から1830年までにオランダ・フランス・イギリスでオークションにかけられた小規模な私立図書館のカタログを使った2つのデータベースを作成している。The BIBLIO database(Bibliography of Individual Book and Library Inventories Online, 1665–1830)は基本の書誌情報を集めたデータベースであり、The MEDIATE databaseは、検索可能な写本から書物や収集家に関するメタデータを集めたデータベースである。さらに、研究者が同時に複数の書物史データベースに照会するための共通インタフェースである E-ENABLE (Early-modern - Enlightenment Networks of Authors, Books, and Libraries in Europe)も現在作成中とのことで、これら MEDIATE データベースのパブリック版は2019年後半から2020年前半の間に公開される予定である[19]。
3. おわりに
本稿では主に刊行史料を対象にしたウェブコンテンツを紹介してきた。古代や中世に比べ、18世紀研究では研究対象となる刊行史料の数が多いため、ひとりの研究者や研究グループが特定の史資料群をデジタル化しても、それらを使う研究者の数はそれほど多く見込めないかもしれない。しかし様々な史資料がデジタル化されれば、私たちは地理的な制約を越えてウェブ上で新たな史資料と出会える可能性が高まるし、それらがテキストで提供されるのならば、翻訳機能を使うことで言語的制約を幾許か取り除きやすくなるだろう。デジタル化はこのように、それまでのユーザに対する有用性を持つだけでなく、新規ユーザ層を広げる効果も持つため、一部の研究者だけが使ってきたような史資料をデジタル化することにも意義があると言えるのではないだろうか。多くの研究者がそれぞれにとっての重要史資料をデジタル化していけば、点と点が繋がって線となり、そしていずれは面となっていくように、18世紀研究の空間は広がり、一層行き届いたものになっていくことだろう。
紙幅の関係上、書簡を対象にしたものや、分析機能を持つものについては本稿では取り上げなかった。第3回ではコンテンツ紹介の続きとして、これらのコンテンツについて取り上げることとしたい。
イベントレポート「JADH2019参加報告(前編)」
2019年8月29日から31日にかけて、関西大学千里山キャンパスで開催された JADH2019(Japanese Association for Digital Humanities)に参加した。JADH は日本で開催されるデジタル・ヒューマニティーズの国際学会であり、国内のみならず、国外からも多くの研究者が参加する。第9回目の開催となった2019年は、“Localization in Global DH” というテーマを掲げており、全体として地域研究、とくに8月30日に同時開催された KU-ORCAS 国際シンポジウムの内容を含めて、東アジア研究に関する報告が充実していた印象がある。残念ながら紙幅の関係上、本稿においてすべての内容を紹介することはできないが、とくに筆者の印象に残ったいくつかの研究報告の概要を紹介するとともに、筆者の専門である歴史学からの視点を交えて、それらについての所感を述べたいと思う。
ところで、具体的な研究報告の紹介に入る前に、まずは今回の学会の趣旨について考えてみたい。JADH2019のホームページにおける「グローバル化が研究活動の幅を広げる一方、デジタル・ヒューマニティーズは必然的に、言語、地理、歴史の各側面でローカルの問題に取り組まなければならない」との簡潔な言明[1]、そして、開会に際して大阪大学の田畑智司氏が述べた趣旨説明を踏まえると、学会の趣旨は以下のように解釈することが可能かと思う。すなわち、DH の営みを考えた場合、グローバル化によって我々の知的活動の枠組みが世界規模に拡大する一方で、言語的・地理的・歴史文化的側面におけるローカル性に着目する必要性もまた増してきており、この両者を相反する運動と捉えるのではなく、嚙み合う歯車のごとく連動し、協働するものとして認識する必要がある、ということである。ここでいう「グローバル」「ローカル」とは、単に地理空間的な大小のみに言及しているのではないことは明らかであり、人文・社会科学研究の目的に関する本質的な問題に関わるものであろう。とくに、歴史学における論点として捉えるならば、法則定立 vs. 個性記述、あるいは事実 vs 解釈という、科学的学問としての歴史学が成立した19世紀後半以降、長らく論争が続きながら未だに決着のついていない(つきえない)問いに関わるのではないだろうか。
上にあげたような対立構図に対して、両者を融合し、対立を超克するべきであるとする議論が提起されるようになってすでに久しい。例えば、法則定立 vs 個性記述という構図に関して、近代世界システムで名高いウォーラーステインは、両者を融合させる形での史的社会科学を提唱し、巨視的な視点と微視的な視点の相補性を説いた[2]。彼の議論は必ずしも歴史学に限られるものではないが、歴史学においても同様の議論が生じていることは間違いない。というのも近年、グローバルヒストリーなる語が盛んに叫ばれるが、この概念がこれまで巨視的で法則定立的な方法とみなされてきたことは間違いなく、とくにグローバル経済史が重要な役割を果たしてきたように思われる[3]。しかし、こうしたいわばトップダウン型のグローバルヒストリーに対して、リン・ハントはボトムアップ型、すなわち微視的なミクロヒストリー、あるいは近接する対象間に限定された比較研究の視点を掛け合わせることを提案している[4]。さらに、彼の主張に厳密に従うならば、個人の内面といった心理学に属するような、いわば究極に「ローカルな」視点までを含めることになるだろう。個人の内面までを歴史学の対象に含めるという主張の是非はともかく、ハントがトップダウンとボトムアップの「中間路線」を採っていることは確かであり、この点でウォーラーステインの主張に通ずる部分がある。加えて、事実 vs. 解釈という構図に関しても、両者の中間を取るような主張は為されうると筆者は考える。事実 vs 解釈論争の詳細をここで述べることはできないが、両者の融合を提起する議論としては、差し当たって遅塚忠躬の示す「柔らかな実在論」をあげるのがよいだろう[5]。
ここまで、JADH2019の趣旨紹介に端を発して、歴史学の認識論と方法論に関わる議論に深入りしてきた。その理由は明快で、“Localization in Global DH ” という学会の趣旨と、上で述べた「中間路線」的な方法の間には、明らかに共通の理念が存在すると考えるがゆえである。田畑氏の言にもあったように、一見、正反対の方向を向いていると思われる「グローバル」と「ローカル」という二つの視座は、実は二つの歯車のごとく連動しており、相補的なものである。そしてこのような考えは、ローカルでミクロな記述の重要性は認めつつ、それはグローバルでマクロな文脈の中に置かれた時に初めて意義を持つとするウォーラーステインの主張とも重なる[6]。このことから、今回の JADH は、「グローバル」と「ローカル」、「巨視的」と「微視的」、あるいは「法則定立」と「個性記述」など、二律背反的とみなされてきた対立項間の融合、そして協働という新しい道を模索するにあたって、DH が果たしうる役割を考えることを目的としていたのではないかと筆者は考える。
より具体的に言えば、殊にローカルな(あるいは微視的な)視点からの分析に際し、DH をどのように取り入れていくことができるかという問題意識が提起されていたことは、趣旨の文言からも明らかである。人文・社会科学全般における法則定立的・巨視的な研究、とくに歴史学においては、例えばハントが言うところのトップダウン型グローバルヒストリーの実践に際して、DH の手法、殊にビッグデータを活用した統計的分析が有効であることは疑いない[7]。しかし一方で、特定の地域、あるいは特定の史資料に限定された研究においては、地域の文化や自然環境など様々な側面を考慮に入れた質的研究の重要性が増すこともあり、DH をどのように取り入れていくべきかは慎重に検討されるべきであろう。今回の JADH の趣旨は、この点に関しての議論を呼びかけるものであったのではないだろうか。
ここまで、今回の趣旨に関する筆者なりの考えを述べてきたが、これは、あくまでも人文・社会科学の方法論的・認識論的側面に焦点を当てた場合の解釈であり、視点に偏りがある点は断っておく。他の視点としては例えば、研究者間の協働によるコミュニティ形成における「グローバル」と「ローカル」の問題などが考えられ、研究報告においても大きなテーマの一つとなっていたように思うが、ここでこれ以上述べる余裕はないため言及は控える。
◆編集後記
今月のイベントレポートは、国際十八世紀学会の続編に加えて、JADH2019のものもご寄稿いただきました。DHの国際的な盛り上がりのなかで日本がどういう流れになっていくのか、今後も注目していきたいところです。
(永崎研宣)
- コメントを投稿するにはログインしてください