人文情報学月報第138号【後編】
ISSN 2189-1621 / 2011年08月27日創刊
目次
【前編】
- 《巻頭言》「戦前の法令を調べる」
:名古屋大学大学院法学研究科 - 《連載》「Digital Japanese Studies 寸見」第94回
「国立国会図書館デジタルコレクションがリニューアルし、全文検索の提供が充実するとともに NDL ラボにおける Ngram ビューワとデータセットの提供が拡充される」
:北海学園大学人文学部 - 《連載》「欧州・中東デジタル・ヒューマニティーズ動向」第55回
「「キリシタン・バンク」と「みんなで翻刻」:キリシタン版翻刻のクラウドプラットフォーム」
:人間文化研究機構国立国語研究所研究系
【後編】
- 《連載》「デジタル・ヒストリーの小部屋」第13回
「(技術レビュー)Jonathan Blaney et al., Doing Digital History: A Beginner's Guide to Working With Text As Data (IHR Research Guides), Manchester University Press, 2021」
:千葉大学人文社会科学系教育研究機構 - 《連載》「仏教学のためのデジタルツール」第3回
「花園大学国際禅学研究所 電子達磨#3」
:東京大学大学院人文社会系研究科 - 人文情報学イベント関連カレンダー
- 編集後記
《連載》「デジタル・ヒストリーの小部屋」第13回
「(技術レビュー)Jonathan Blaney et al., Doing Digital History: A Beginner's Guide to Working With Text As Data (IHR Research Guides), Manchester University Press, 2021」
新年連載第1回は、2021年に出版された Doing Digital History という書籍を対象とした[1]、とくに技術面に注目したレビューとしたい。同書は、ロンドン大学歴史学研究所(Institute of Historical Research)のデジタル・ヒストリー・セミナーのスタッフを務めていた人物らによるデジタル・ヒストリーの入門書である。レビューでは比較的高い評価を得ているようであり、歴史学におけるデジタル技術の在り方という観点では学ぶべき点の多い良書であると思われる。しかしながら、技術面で批判すべき・補足しておきたい論点があるため、本稿ではその点を中心に技術レビューを行いたい。読者によっては、プログラミングに関する退屈な説明と思われることもあるだろうが、デジタル・ヒストリーの入門書として評価されている本の情報処理技術の解説に問題があるのであれば、初歩的な内容でも丁寧に解説しておきたいところである。
同書の構成と技術的な問題点
同書は、デジタル・ヒストリーの入門書として一定の評価を得ており[2]、研究プロジェクトの選択、デジタル・プロジェクトのライフサイクルにわたるメンテナンス、貴重なデータの管理、テキスト処理の実例、研究結果の可視化などに関するアドバイスを提供するものである。同書が強調しているのは、「魔法のような」プログラミング言語を駆使せずとも、ある種の研究課題を解決するためのヒントを大規模なデータから取得できるという点である。具体的には、1878年の Post Office Directory for London から翻刻したテキストファイルおよび XML ファイルを対象とした、コマンドライン上の命令による情報処理のチュートリアルが4~5章で提供されている。
しかしながら、このチュートリアルで紹介されている XML ファイルの現時点でのバージョンを対象とした情報抽出には、以下のような注意すべき点が存在する。
- コマンドラインの grep コマンドで XML の特定のタグ(具体的には<addr>タグ)から情報を抽出しようとしているが、grep コマンドは条件に合致する行を抽出する機能しか持たないため、複数行にわたる<addr>タグから情報を抽出することができない
- (そこまで大きな問題ではないが)チュートリアルで使用されている XML ファイル[3]は、いくつかの文字の実体参照がうまく機能しておらず、Oxygen XML Editor などで検証すると、妥当な XML 文書ではないと判断される
- そもそも、いくつかのタグ同士がオーバーラップしており、妥当な XML 文書になっていない
そこで本稿では、Doing Digital History の第5章で紹介されているチュートリアル課題を、コマンドラインの grep コマンドではなく、Python の BeautifulSoup モジュールを使って実践するコードを紹介する。プログラミング言語を用いることが同書の趣旨にそぐわないことは重々承知しているが、そもそも XML ファイルは grep による検索を前提としたフォーマットではない。XML の構文に沿って検索するためのソフトウェアとして Oxygen XML Editor をはじめとする XML 構文解析機能を含むソフトウェアが様々に提供されている。そして、より効率的な情報抽出の手法としてプログラミングを介した構文解析がある。もちろん、同書で指摘されているように、コマンドラインの命令の方が Python のプログラムを書くよりも日常の研究場面では速いだろうが[4]、欲しい情報が抜け落ちてしまっては元も子もない。
ちなみに、Python の標準モジュールである ElementTree を用いない理由は、チュートリアルで紹介されているファイルが、上記の通り妥当な XML 文書ではないためである。BeautifulSoup モジュールであれば、妥当な XML 文書ではなくともパースできる(というより、強引にできてしまう)ため、今回は BeautifulSoup を用いる。なお、以下で用いる Python のコードの大半はごく初歩的なもの(for ループ、if 文、リスト、辞書の扱い)であり、たとえば The Programming Historian[5]で紹介されているいくつかの Python レッスンを理解できる歴史研究者なら問題なく活用可能だろう。
元データの確認
まずは、必要なモジュールをインポートし、チュートリアルで紹介されている XML ファイルを構文解析してみよう。なお、lxml パーサーを用いて構文解析した結果、HTML ファイルのタグが追加されている点は断っておく。
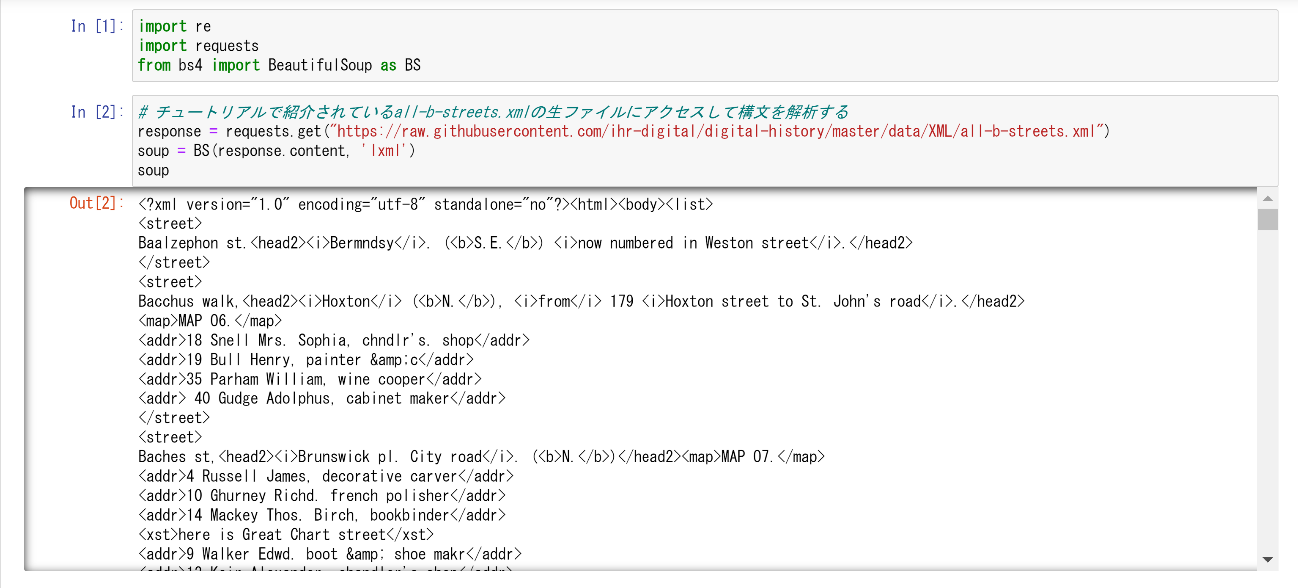
XML 文書のおおまかな構造を確認しておくと、<list>タグの子要素に複数の<street>タグが内包されており、さらにその下位に<addr>タグが子要素として内包されている。この<addr>タグに含まれている文字列が氏名・住所・職業の情報というわけである。職業の情報が含まれていないものもある。
正規表現を用いたデータセット中の男女比の算出
<addr>タグ内に Mrs あるいは Miss を含む場合、女性の情報が記されていることから、この史料における男女比を算出することができる。チュートリアルでは、コマンドライン上で、以下のコマンドを入力するように指示している。
これにより、“<addr>” という文字列を含む行を抽出し、さらにその該当行の中から、“Mrs” もしくは “Miss” という単語を含む行だけを抽出することができる。\bで単語が囲まれているのは、まさにその単語が含まれているものだけをヒットさせたいからである。具体的には、“Miss” はヒットさせたいが、“Mission” はヒットさせたくない場合、\bMiss\b とすればよいということになる。ヒット数は14,021件とある。
さて、このコマンドの問題点は、次のように複数行にわたる<addr>タグに対応できないことである。このような<addr>タグはチュートリアルファイルにいくつも散見され、複数人の情報が格納されているようである。
Beer Julius, merchant</addr>
このように複数行にわたる<addr>タグの各行を分解し、ひとりひとりの情報を網羅するのであれば、たとえば次のような Python コードを書けばよい。
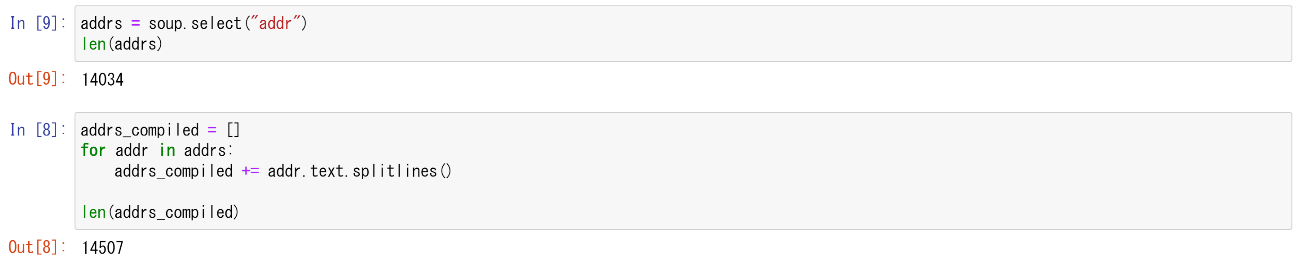
まず、<addr>タグ自体は全部で14,034件あり、その中で複数行にわたる<addr>タグの各行を分解して新しいリストに格納すると、全部で14,507件となった。つまり、チュートリアルの grep コマンドでは約500件の抜け落ちがあるということになるため、XML 文書はやはり構文解析をする必要があることがわかる。
閑話休題。この14,507件のデータセット中の男女比を算出しよう。チュートリアルの正規表現はそのまま Python でも使えるので、次のようなコードが書ける。

人物情報の文字列の中に“Mrs” もしくは “Miss” を含むものは女性の情報、そうでないものは男性の情報ということなので、それぞれの条件に合致する行を female_addrs および male_addrs という変数名のリストに格納することとした。なお、male_addrs に誤って含まれている情報(たとえば通りの名称など)がいくつか存在するが、今回はそこまで厳密さを期さない。男性のデータは13042件、女性のデータが1465件、男女比はおよそ8.9:1となった。
女性の職業一覧を多い順に並べ替える
最後に、<addr>タグ内に “Mrs” あるいは “Miss” を含み、かつカンマで情報が区切られていると、末尾には女性の職業が記されているというテキストの性質を利用し、女性の職業の一覧を多い順に並べるという作業課題に取り組む。チュートリアルでは、下記のコマンドが紹介されている。
grep -Eo ",[^,]+</addr>" | sort | uniq -c | sort -n
grepコマンドの問題点はすでに述べたので改めて指摘することはしないが、実はカンマ以外にもピリオドの後に職業が記されていることもあるので、正規表現を修正する必要がある。たしかに、ピリオドの後には職業以外の情報が記されている場合もあるが、今回はそれよりも職業の抜け落ちがないことを優先した。
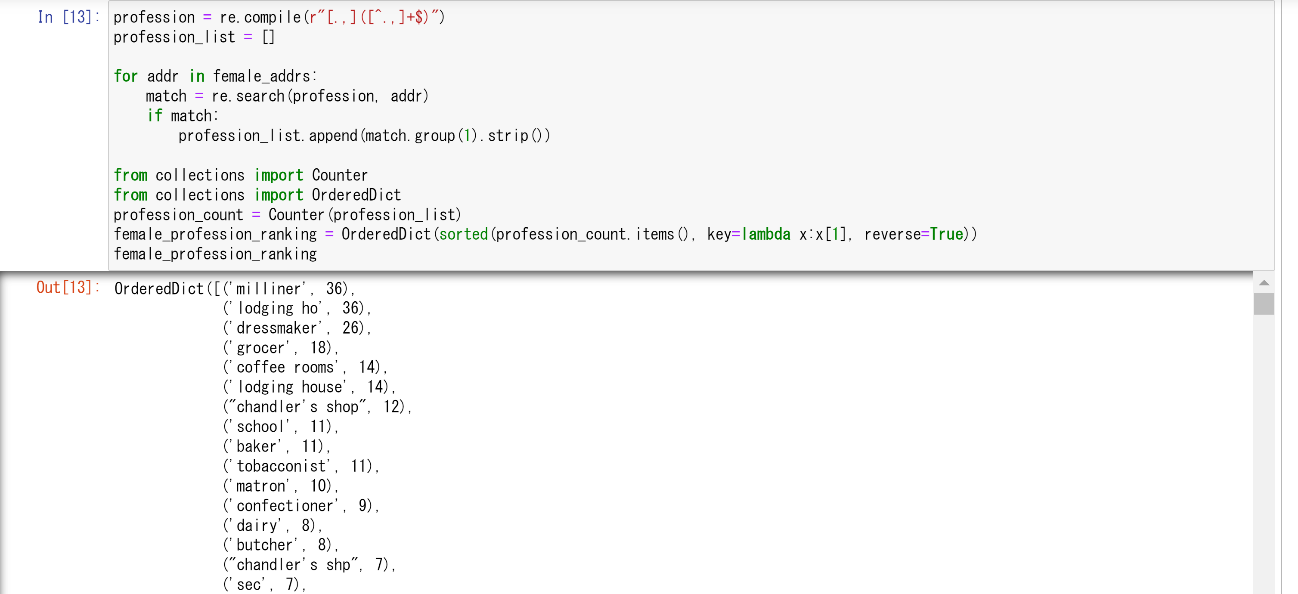
ここで用いた正規表現により、「カンマかピリオドの後、カンマかピリオド以外の文字列が行末まで続く」というパターンを検索している。肝心の職業情報はそのうち「カンマかピリオド以外の文字列が行末まで続く」部分であるから、その部分を抽出できるようにして、前後の不要なスペースなどを削除し、profession_list という変数名のリストに格納している。あとは、そのリストの中で重複する職業があればそれが何回重複しているのかをカウントし、降順に並べ替えるだけでよい。Counter や OrderedDict モジュールを用いた。
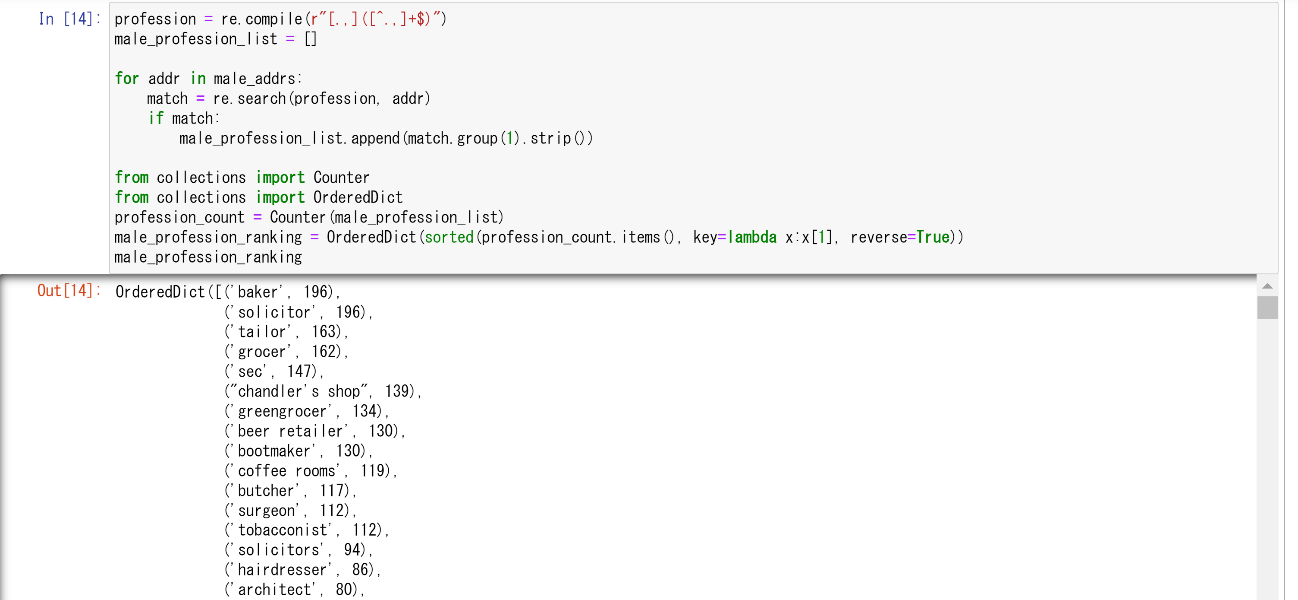
ちなみに、すでに先ほど男性のデータも取得しているわけであるから、上記のコードを再利用するだけで、男性の職業一覧を多い順に並べることもできる。
おわりに
今回は、Doing Digital History の第5章で紹介されている、grep コマンドを用いた XML 文書からの情報抽出チュートリアルの技術的問題を指摘し、代替策として Python によるアプローチを紹介した。たしかに、grep コマンドに比べると多くのコードを書く必要があることは否めない。しかし、XML のタグが複数行にわたることなどごくごく自然なことであるから、grep コマンドによる情報抽出には無理があることは確かである。実際、14,000件程度のデータの中から500件ものデータが抜け落ちてしまっているのは問題である。もちろん、筆者の Python コードにも改善の余地があるだろう。折に触れてフィードバックをいただければ幸いである。
《連載》「仏教学のためのデジタルツール」第3回
仏教学は世界的に広く研究されており各地に研究拠点がありそれぞれに様々なデジタル研究プロジェクトを展開しています。本連載では、そのようななかでも、実際に研究や教育に役立てられるツールに焦点をあて、それをどのように役立てているか、若手を含む様々な立場の研究者に現場から報告していただきます。仏教学には縁が薄い読者の皆様におかれましても、デジタルツールの多様性やその有用性の在り方といった観点からご高覧いただけますと幸いです。
「花園大学国際禅学研究所 電子達磨#3」
今回は、仏教学のなかでも特に禅研究に有用なデータベースとして、花園大学国際禅学研究所「電子達磨#3 禅語漢語考釈支援システム」(http://saku.hanazono.ac.jp/)を紹介する(以下「電子達磨#3」と呼称)。
電子達磨#3は、禅語・漢語をキーワード検索することによって、データベース収録文献中の検索語を含む箇所について、写本・版本の該当ページを画像として閲覧できる、というシステムである。データベースに収録されるのは、江戸時代の学僧、無著道忠(1653–1744)撰述の禅籍をはじめ、禅語の古辞書類や句集、『臨済録』『碧巌録』の抄物(仮名書き・口語体による講義録の総称)類、漢詩文の注釈書類、白隠慧鶴(1685–1768)にかかる禅籍などであり、これらを一括で検索して画像を閲覧することができる(なお一部の画像データについては現在閲覧できないが、今後順次公開されるようである。http://saku.hanazono.ac.jp/news/2022-09-01-0 参照)。また、画像こそ閲覧できないものの、現代になってから刊行された漢語辞典や禅語辞典類について、検索語が掲載される箇所のページ数を示すという機能も搭載されている。
さて、電子達磨#3成立の経緯は、データベース内の「電子達磨のあゆみ」と題するページに詳しい。これによってその概要を紹介しておきたい。そもそも「電子達摩」とは、1991年より花園大学国際禅学研究所副所長を務めたウルス・アップ教授が世界に向けて発信した情報誌(通訊)の名前である。アップ教授は各種禅籍の電子テキストを公開したほか、各種索引を刊行した。その後、2005年より国際禅学研究所副所長を務めた芳澤勝弘教授は、それまでに手掛けた無著道忠禅師の注釈シリーズを中心とした『基本典籍叢刊』(財団法人禅文化研究所刊)の索引シリーズを再編し、これをウェブ上で利用するための検索ツールを構築、これに「禅学綜合資料庫 電子達磨#2 Digital Bodhidharma General Archives for Zen Research」と命名した(このとき、表記が「電子達摩」から「電子達磨」に改められる)。
この電子達磨#2を継承、発展するかたちで2022年に新たに公開されたのが、電子達磨#3である。電子達磨#3の最大の特徴は、IIIF (International Image Interoperability Framework)が採用されたことであろう。これにより、本データベースの利用者が、より自由な形で画像を活用できるようになったのである。
以上、電子達磨#3の概要と成立の経緯について簡単に紹介した。つぎに、電子達磨#3を筆者が実際にどのように使用しているか紹介したい(あくまで筆者の使用方法であり、データベースの使用方法全般を紹介するものではない)。なお電子達磨#3は、あいまい検索機能が備わっており、新旧字体を問わずに検索することができる点が非常に便利である。また、検索語入力フィールド内においてスペースでキーワードを区切ることにより AND 検索を行うこともできる。
日本中世禅、特にその思想研究を専門とする筆者の電子達磨#3の利用方法としては、大きく分けて二通りの場合がある。すなわち、(1)特定の禅語の意味を検討する場合、および(2)特定の禅籍のテキスト内を検索する場合である。
(1)の場合には、特定の語について、データベース全体を横断的に検索することで、その用例や意味を収集する。まさに「電子達磨#3 禅語漢語考釈支援システム」の名の通りの使用法である。この際、電子達磨#3に『禅林象器箋』や『葛藤語箋』が収録されている点は、特に効力を発揮する。これらは、江戸期臨済宗屈指の学僧である無著道忠が著した、いわば禅語の辞書に相当する典籍で、前者には禅林の規則・行事・機構・器物などにかんする語が、後者には俗語・故実・禅門独特の語句などが立項される。それぞれの語に無著道忠による実証的な批判・考証が加えられている両文献は、今日の禅籍研究においても不可欠であり、これらがデータベース化されていることの意義は非常に大きい(なお『禅林象器箋』については CBETA(中華電子佛典協會による仏典のデータベース)でもテキストを検索することはできるが、画像までは閲覧できない。また、『葛藤語箋』は CBETA には収録されない)。このほか、桂洲道倫(1714–1794)・湛堂令椿(1723–1808)等によって編まれた『諸録俗語解』(著名な禅籍に出る難解な語について考証・解説した書)をはじめとする古辞書も収録されており、電子達磨#3は禅語の意味の検討には非常に有用である。
(2)の場合としては、SAT 大正新脩大藏經テキストデータベースや CBETA 等のデータベースに収録されていない禅籍のテキストを検索する際に活用することとなる。たとえば、その一つが『禅林類聚』二十巻である。『禅林類聚』という文献は、禅宗の古則公案(仏祖の示した言行)やそれに対する後代の解釈等を、カテゴリーごとに収録した集成書である。中国元代に刊行されたものが日本に入ると、日本では貞治六(1367)年以降、何度も刊行が行われ、大いに流行した。ところが、現在『禅林類聚』の名で『大日本続蔵経』に収録される文献は、正確には室町時代の成立と考えられる四巻本の『禅林抜類聚』であり、『禅林類聚』から抜粋した抄本であるため、大日本続蔵経を収めるCBETAを利用しても、『禅林類聚』二十巻を検索することはできないのである。そのため筆者は、『禅林類聚』本文を検索できるデータベースとして、電子達磨#3を重宝している(具体的にはホーム(http://saku.hanazono.ac.jp/)内のデータベース選択画面で「禅林類聚」のみにチェックを付け、特定の語が含まれる文を検索する。なお令和4年12月現在、『禅林類聚』はテキスト検索のみで、画像は閲覧できず、また該当箇所の位置も明示されないため、この点は今後の画像公開に俟ちたい)。
以上、筆者の電子達磨#3の利用方法を紹介した。筆者が利用するのは、古辞書、語録等の一部の収録文献に偏っているが、先述のように、本データベースには抄物や漢詩文も含まれており、したがって電子達磨#3は禅学・仏教学研究のみならず、他の様々な分野の研究にも有用であると思われる。また、電子達磨#3は、データベース概要(http://saku.hanazono.ac.jp/about)に「今後も国内外において貴重な禅学資料を増強する計画である」と記される。今後、一層コンテンツが充実することを期待したい。
人文情報学イベント関連カレンダー
【2023年2月】
-
2023-2-2 (Thu)
【ROIS-DS】第3回成果報告会於・オンライン -
2023-2-4 (Sat)
下田正弘教授ご退任記念シンポジウム「デジタル仏教学の歩み 人文情報学教育の歩み」於・山上会館大会議室およびオンライン -
2023-2-10 (Fri)
第71回日文研学術講演会 講演 I「和暦をコンピュータで扱う」 講演 II「国際聖地としての日光東照宮於・国際日本文化研究センター内講堂https://www.nichibun.ac.jp/ja/events/public_lecture/2023/02/10/
-
2023-2-11 (Sat)~12 (Sun)
国際シンポジウム「古典の再生」於・京都産業大学むすびわざ館およびオンライン -
2023-2-18 (Sat)
人文科学とコンピュータ研究会第131回研究発表会於・オンライン -
2023-2-18 (Sat)
連続講演会「TEI (Text Encoding Initiative) × Library が拓くデジタル人文学と図書館の未来 インターフェースを越えて:デジタル人文学のためのデータとしてのTEI」於・東京外国語大学アジア・アフリカ言語文化研究所大会議室およびオンライン -
2023-2-21 (Tue)
連続講演会「TEI (Text Encoding Initiative) × Library が拓くデジタル人文学と図書館の未来 デジタルカタログとデジタルライブラリー:コレクションデータのためのTEIの活用」於・国文学研究資料館およびオンライン -
2023-2-22 (Wed)
第24回京都大学情報学シンポジウム「文理融合の中核となる情報学」於・京都大学時計台記念館百周年記念ホールおよびオンライン -
2023-2-23 (Thu)
DH フェス2023於・オンライン
Digital Humanities Events カレンダー共同編集人
◆編集後記
1月中旬、ハンブルク大学で開催された「 Perspectives of Digital Humanities in the Field of Buddhist Studies」というイベントにご招待いただき、少し発表などをしてきました。 かつてこの主のイベントはシステム開発やサービスの提供が中心でしたが、今回は、いよいよ充実してきたツールや仏教学のデータを用いてどのようにして仏教研究上の問いを解決するか、という発表が目立ち、世代も1回りか2回りくらい若返っている感じでした。発表者は筆者以外は 欧米から来ていたようでしたが、欧米で浸透しつつあるデータを用いた人文学研究の波が、欧米ではマイナーな分野である仏教学にも 押し寄せているということだったのでしょう。日本でもデータ駆動型人文学がいよいよ進みつつありますが、それをうまく進めるためにはデータを全体的に充実させることが重要であると改めて実感したことでした。(永崎研宣)
- コメントを投稿するにはログインしてください