人文情報学月報第150号【前編】
ISSN 2189-1621 / 2011年08月27日創刊
目次
【前編】
- 《巻頭言》「イギリス文学の研究にデジタル・ヒューマニティーズを取り入れることの楽しさ-読みを後押しする数字」
:中央大学国際情報学部 - 《連載》「欧州・中東デジタル・ヒューマニティーズ動向」第67回
「Coptic Translator:コプト語多層タグ付きコーパス Coptic SCRIPTORIUM を学習させた英語–コプト語・コプト語–英語のニューラル機械翻訳」
:人間文化研究機構国立国語研究所研究系
【後編】
- 《特別寄稿》「歴史研究における「解釈行為」をモデル化する試み(1)」
:ROIS-DS 人文学オープンデータ共同利用センター - 《特別寄稿》「Patrick Sahle による「2. What is a Scholarly Digital Edition?」(『Digital Scholarly Editing-Theories and Practices』所収)の要約と紹介」
:早稲田大学大学院文学研究科 - 人文情報学イベント関連カレンダー
- イベントレポート「Digital Humanities Winter Days 2023:ハンブルク大学・ロマノフ先生を迎えて」
:東京外国語大学アジア・アフリカ言語文化研究所 - 編集後記
《巻頭言》「イギリス文学の研究にデジタル・ヒューマニティーズを取り入れることの楽しさ-読みを後押しする数字」
私は19世紀イギリス・ロマン派の詩の研究を専門としている。文学研究の立場からデジタル・ヒューマニティーズ(以下 DH)の学問領域に関わるという立ち位置であり、データの共有か利活用かの区分でいえば、データの利活用の研究になる[1]。最近の研究活動としては、文学、情報、言語学、教育、哲学の研究者を交えたデータ分析研究会を行い、イギリス文学のテクスト間における影響の DH 的分析や、イギリス文学研究に特化した機械学習の構築について話し合っている。
人文学研究の諸領域のうちイギリス文学が DH と関わることは、海外では盛んである [2]。日本でも今後増えていくことを願いつつ、本稿では、文学研究の楽しさを確認し、DH 研究を取り入れる楽しさおよびその具体例や教育上の展開について取り上げたい。
イギリス文学研究は、英語でエッセイと称されることがあるように、リサーチとは異なり、主観的な解釈の余地の大きい研究である[3]。文学作品のテクストを一次資料とし、他の研究者による研究や批評理論等の理論的枠組みや、あるいは歴史的事実などのテクスト外の資料や情報をもとに、誰もが納得のいく論を組み立てる。前提として、テクストの意味は一意に定まらず、その解釈は多様である[4]。このような文学研究全般が目指している知的興味とは、私は1.鑑賞と2.解釈という二つの面白さだと考えている。1.鑑賞とはテクストを読む面白さである。言葉自体の面白さ、心に響く言葉や文章、作品世界の内容的な面白さ、著者の思考の追体験やテクストの対話を味わい、テクストの世界に浸ることである[5]。文学研究の基本的な方法である、テクストを時間をかけて精緻に読み解くという精読を行ってテクストを読解すると、テクストの随所で同様の読む面白さが開けてくる。文学研究者が日々行い、また論文執筆の直接的なきっかけとなるのは、このような精読を通しテクストを読む活動であるといえるだろう。
2.解釈とは、作品世界を広げる楽しさである。新しい視点からテクストを読むことで、作品世界そのものが広がってゆき、テクスト自体の価値のみならず、社会におけるテクストの価値も変わってゆく。新しい視点とは、歴史、哲学、宗教、社会学、ジェンダーや環境といった異なる学問領域を取り入れることでもよいし、現代の視点から見たテクストの再解釈でも、テクストが書かれた社会・文化・時代とテクストを取り巻く環境を踏まえてテクストを再解釈することでもよい。
ここで、精読と遠読について簡単に確認しておきたい。精読とは、テクストを精緻に読み込むことで言葉の意味や形式、それらの複雑な統一を見出す試み、あるいは定まらない意味を見出していく発展的な読みのアプローチを意味する。ゆっくりと内容やテクスト内の他の語句の意味を味わいながら読むという行為である [6]。
一方、DH における遠読とは、データ全体にみられる特徴的な傾向を選び示す読みを意味する。テクストから距離を置いて、特徴のグラフ化や図示を行い、テクストの大規模なパターンを見つけることであり、テクスト全体を俯瞰して傾向を見出す活動である[7]。伝統的な文学研究における精読とは、比較的少量のテクストを丹念に読む微視的なものであり、DH における遠読とは、大量のテクストを横断的に読む巨視的なものといえる。
DH の手法を取り入れることによる文学研究の楽しさには、1.データの操作と2.新しい視点の二つがあると考えている。1.データの操作とは、大量のデータを操作すること自体の面白さである。ある視点をもとにモデルを作り、大量のテクストから必要なデータを取り出して人間に理解可能な形にするのは、おそらく多くの人に共通する一つの知的興味であろう。2.新しい視点は、DH 的な分析を通して初めて明らかになる視点である。例えば、17世紀詩人ジョン・ミルトンの『失楽園』が19世紀ロマン派詩人 S.T.コールリッジの詩作品に与えた影響を調べた際、語彙の頻出の点で『失楽園』に類似する作品の一つとして”Ne Plus Ultra”と題する作品が選び出された[8]。この詩は、地獄の辺土との関連や、理由は不明だがミルトン的だという指摘がある [9]。論文で使用したモデルに問題点はあるものの、もし本当に『失楽園』に影響を受けているとすれば、この意味の読み取りにくい詩の冒頭は次のように読むことができるかもしれない。
夜をただ一人肯定するものよ!
光に反感をもつものよ!
<運命>の唯一の本質よ! 第一のサソリの杖よ-
神に相対することを許されたものよ! -
濃縮された暗黒さと深淵の嵐よ
一つの王位と盟約を結んだものよ-
膨大な支配で武装するものよ
簒奪者よ-
今なお陰なす<死>を投げかける実体よ- (CPW, 1–9)[10]
もしテクストが『失楽園』の世界を描いているとしたら、一人の人物への呼びかけととることができる。一人の人物とは、おそらく主要な登場人物の一人である堕天使の長サタンか、その息子であり深淵に住まう<死>であろう。サタンも<死>もサソリの杖は持たないが、神に相対することを許されたという言葉からサタンに向けた呼びかけとみるのが妥当だろう。するとタイトルの”Ne Plus Ultra”は、辞書的な意味の「極限」ではなく、「極みにあるもの」とでもいえる意味かもしれない。あるいは、テクスト全体を通して、『失楽園』そのものとは似ているようで似ていない記述があるため、もしかすると『失楽園』のその後の話であり、タイトルは「もはや地獄の長ではない」や「もはや天には行けない」の意味ととれるかもしれない。このように、DH による分析結果は、読みの解釈を後押しし、作品世界のさらなる読みの可能性を広げてくれるのである。
DH による分析は、新たな読みの方法を提示するだろうか。私の行うデータ分析研究会では、イギリス・ロマン派の詩人パーシー・シェリーの詩「クイーン・マブ」と、その妻メアリー・シェリーの作品『マチルダ』の間の影響を機械学習を用いて調べたことがある。類似するテクストを選び出し、本当に類似しているかどうかテクストを読んで調べていく。その際気づいたのは、通常の文学研究ではテクストを読んで疑問や類似に気づくという過程をとるが、ここではその逆で、分析結果をもとに、なにか影響しているはずだという視点でこれまで指摘されていないテクストどうしを読んでいたのである。数字が読みを後押しする、そんな読み方もあるかもしれない。
最後に、教育への展開を簡単に触れておきたい。DH の文学研究は、定まった方法がなく、調べてみたいと思ったことを実現するにはその都度モデルを作る必要がある。そこで、授業で基本的知識やツール、前処理等の講義のほかに、本当に使用したデータやモデルが正しいかどうか批判する機会を設けることは重要であろう。今年度、私の DH を扱った授業では、中島敦の「文字禍」のネガポジ分析や、シェイクスピアの劇作品を、機械学習を用いて比較し、悲劇と喜劇に分類するという試みをした[11]。やり方は正しいか、手法やモデルは適切か、テクストの該当箇所はどうなっているかなど議論させた。テクストの読みの楽しさのほかに、数字を起点に話し合うことの楽しさも加えてもいいかもしれない。
執筆者プロフィール
《連載》「欧州・中東デジタル・ヒューマニティーズ動向」第67回
「Coptic Translator:コプト語多層タグ付きコーパス Coptic SCRIPTORIUM を学習させた英語–コプト語・コプト語–英語のニューラル機械翻訳」
低資源言語における機械翻訳は、言語保全と普及の重要な手段である。これは、資料や話者が限られている言語において、言語学習の機会を拡大し、文化的な交流を促進するための有効なアプローチである。機械翻訳は、これらの言語の文献や文化遺産をアクセスしやすくし、言語学習者にとっての障壁を低減する。機械翻訳は、低資源言語のアクティブな教材となりうる。限られた資源しかない言語では、教育資料の不足が学習の障害となることが多い。学習者が作りたい文章を機械翻訳を用いることで作成し、意味を知りたい文章を学習者の知っている言語に翻訳し、学習者の理解を促進することが可能になる。
主要な古典言語と比べて低資源言語の一つに数えられるコプト語は、古代エジプト語の最終段階であり、主にエジプトのキリスト教、コプト正教会の典礼言語として使用されている。古代エジプト語は約4000年以上にわたってエジプトで用いられてきた言語で、主にヒエログリフなどの古代エジプト文字で書かれた。コプト語は、これらの古代の形態から派生し、主にギリシア文字を用いて書かれているが、エジプト固有の文字もいくつか加えられている。コプト語は、紀元3世紀頃に発展し始め、キリスト教の聖書や宗教的文書の言語として広く使われるようになった。この言語の研究は、エジプトのキリスト教の初期の歴史の理解に不可欠である。しかし、アラビア語の普及に伴い、話される言語としては徐々に衰退し、17世紀には日常言語としては使われなくなった。現在、コプト語はコプト正教会の典礼で使用されているが、19世紀後半から言語復興運動も存在する。コプト語は、古代エジプト語の言語学的研究においても重要な地位を占めており、エジプト語の歴史的変遷を理解する上で欠かせない言語である。
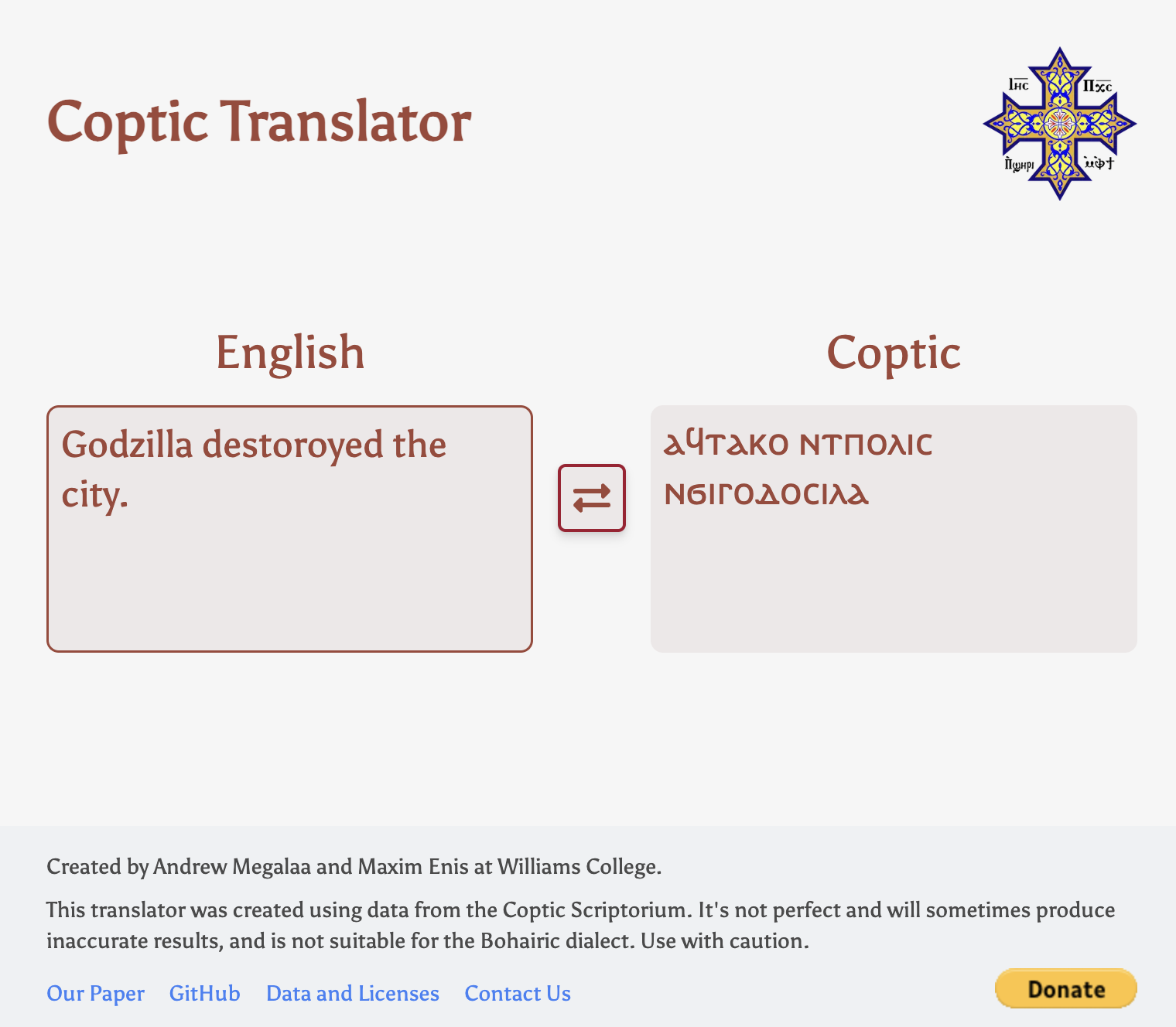
このコプト語の自動翻訳のためのアプリである Coptic Translator というアプリが2023年の12月に、公開された[1]。開発者はウィリアムズ大学の Andrew Megalaa と Maxim Enis である。このアプリのリリースは、特に、コプト語の復興運動をするコミュニティにおいても大変話題になった。ただし、これらの復興運動で用いられているのは、現在コプト正教会の典礼言語として用いられているコプト語ボハイラ方言であり、本自動翻訳は、ボハイラ方言が中世に台頭してくる前にコプト語の共通語的な地位を占めていたサイード方言である。 このウェブサイトを開くと、左右にテキストボックスが出てくる。最初は、左が英語で右がコプト語になっている。この状態で左のテキストボックスに英語を入れると、右のテキストボックスで、その英語のコプト語訳が表示される。さらに、真ん中の入れ替えアイコンを押すと、コプト語が左に、英語が右に移動する。この状態で、左のボックスにコプト語を入れると、右のボックスで英語訳が表示される。このように非常に単純でわかりやすいインターフェースである。翻訳の性能に関しては、聖書や聖人伝などでよく出現する単語を使った単純な文ならばかなり高い精度で翻訳がなされるように感じる。また、コプト語のコーパスにはないであろう、現代的な単語(コンピュータなど)や固有名詞(ゴジラなど)も、ある程度コプト語風に外来語化して反映される (図1参照)。 このサイトのモデルおよびインターフェースのコードは全て GitHub で公開されている[2]。また、このモデルを作成した際のデータやプロセス、実験結果などを記した論文へのリンクも付されている[3]。
論文では、低リソース言語 (low-resource language) であるコプト語のための機械翻訳モデルの実験が詳述されている。具体的なモデルとしては、Hugging Face ライブラリで提供されている既存の Transformer ベースの多言語モデルをコプト語ー英語の対訳データで訓練するアプローチが採られている。この研究ではヘルシンキ大学 Helsinki-NLP チームの「opus-mt-mul-en」[4](多言語-英語翻訳用)および「opus-mt-en-mul」[5](英語-多言語翻訳用)が使用された。これらのモデルは、エンコーダ・デコーダの変換アーキテクチャを使用し、119の異なる言語の翻訳で訓練されている。筆者も、この親モデルを用いて、日本語-アイヌ語、および、アイヌ語-日本語の機械翻訳モデルを作成し、比較的良好な結果を得た[6]。この親モデルを基に、研究者たちはコプト語テキストの特性に合わせて微調整を行い、コプト語の機械翻訳システムを開発した。 伝達学習やバックトランスレーションを利用し、言語間の大規模な並列データセットでモデルを訓練することで、高品質な翻訳が可能になっているという。
データは全て、コプト語最大のタグ付きデジタルコーパスである Coptic SCRIPTORIUM[7]のデータが用いられている。このコーパスは、筆者も2014年から senior editor / encoder / annotator / translator として作業した、全米人文科学基金 (NEH) のプロジェクトによって作られており、データを全て TEI XML などの形式で GitHub で公開しているほか、オンライン・コーパス表示・分析プラットフォームである ANNIS でもユーザはコーパスを検索・統計的分析を行うことができる。データの前処理では、コプト語の文字をギリシア文字に転写したり、句読点などを除去したり、ラテン文字で転写したりしたデータも作成された。モデルの訓練と検証では、特定のパラメータを調整して、最適な翻訳結果を得るための実験が行われた。また、ベースラインとして、既存のコプト語辞書を使用した単語ごとの翻訳アルゴリズムが開発された。しかし、コプト語辞書の定義が語レベルではなく文レベルや句レベルの形式であるため、単純なマッピングベースのアプローチは不十分であった。そこで、セマンティック検索を利用して辞書の機能を模倣し、英語の単語をコプト語の単語にマッピングする新しい方法が採用された。その中では、bert-base-cased6モデルを使用して各定義をベクトル にエンコードし、softmax を使用して埋め込みが正規化された。
この論文の後半は、コプト語の機械翻訳モデルの評価とその制限に焦点を当てている。異なる方言のデータセットでのモデルの性能評価、宗教的文脈と口語的文脈での性能の違い、および実世界での応用に関する考察が含まれている。モデルの結果は、テストデータに対するすべてのモデルの相対的な性能が検証データに対する性能と一致していることを示し、文脈モデルが辞書ベースラインを上回る結果を得ている。特に、ラテン文字転写で前処理した新約聖書のデータで BLEU[8]スコア61.73と、chrF[9]スコア73.63という良い評価スコアを達成している。しかしながら、モデルは宗教的な文脈では優れた性能を発揮するものの、非宗教的なコプト語テキストの英訳や一般的な英文のコプト語への翻訳には適していない可能性も示されている。また、モデルの出力には文体の一貫性が欠けることや、反復翻訳の問題があることも指摘されている。これらの制限は、コプト語の機械翻訳モデルの開発における今後の課題である。
筆者は、この論文で提示された方法を用いて、現在コプト語の言語復興運動で用いられているボハイラ方言の機械翻訳を試みている。そのために、Coptic Translator の開発者との共同作業を見据えて、現在、ボハイラ方言テキストと英語訳のペアのパラレルコーパスを作成中である。
- コメントを投稿するにはログインしてください