人文情報学月報第131号(DH2022特集号)【前編】
ISSN 2189-1621 / 2011年08月27日創刊
目次
【前編】
- 《巻頭言》「デジタル人文学における多様性のさまざまな側面」
:アムステルダム大学コンピュータ文学研究科 - 《連載》「Digital Japanese Studies 寸見」第87回
「DH2022東京記念レクチャーシリーズ「デジタル・ヒューマニティーズへの招待」の開催と日本の DH の将来」
:北海学園大学人文学部 - 《連載》「欧州・中東デジタル・ヒューマニティーズ動向」第48回
「手書きテキスト認識(HTR)・自動翻刻ツール eScriptorium と対訳アライメント・ツール Ugarit:DH2022 東京ワークショップ・チュートリアル解説」
:人間文化研究機構国立国語研究所研究系
【中編】
- 《連載》「デジタル・ヒストリーの小部屋」第6回
「イベントレポート「DH2022東京記念レクチャーシリーズデジタル歴史学のジャーナルがもたらす新たな世界」」
:千葉大学人文社会科学系教育研究機構 - 《特集 DH2022》「DH 分野最大の年次国際学術大会が7/25~29に開催されます」
:一般財団法人人文情報学研究所
【後編】
- 《特集 DH2022》「DH 分野最大の年次国際学術大会が7/25~29に開催されます(続き)」
- 《特別寄稿》「留学生から見たドイツの資史料収集事情:ミュンスター編」
:東京大学大学院人文社会系研究科 - 人文情報学イベント関連カレンダー
- 編集後記
《巻頭言》「デジタル人文学における多様性のさまざまな側面」
2015年に私は国際デジタル・ヒューマニティーズ学会連合(Alliance of Digital Humanities Organizations、略称 ADHO)運営委員会の議長になるよう頼まれた。最初の仕事は、多様性や包括性といった議題が ADHO で真摯な形で確実に議論され、とりあげられるようにすることだった。公式ウェブサイトである www.adho.org で述べられているように、ADHO の使命はコミュニティに根ざした助言を行う主体として行動し、研究・刊行・協働・訓練が卓越したものになるよう助力を提供しつつ、人文学芸の全分野にわたるデジタル研究と教育を推進し、支援することである。ADHO の運営委員会は、どのようにして全ての声が聞き届けられ、それぞれがイベントや意志決定に参加する平等な機会を得られるような環境を作っていけるだろうか?
この重要かつ共通の目標に向かう道を模索するのは大変難しいとわかったが、とても多くを学ぶこともできた。世界の様々な地域における文化的・政治的・歴史的な文脈に応じて議論の焦点が変わってくるということを学んだ。さらに、この議論はしばしば怒りを含んだ厳しいトーンのものになり、それによってもたらされる害のほうが利点より多いが、この怒りはそうした課題がいかに重要か、そして課題に適切に対応することがいかに苛立たしいほど困難になり得るかの反映だということも学んだ。実際のところ、こうした困難で時として礼を欠いた議論をするのは不可欠なのだ。おかげで我々全員が抱えているあらゆる種類の偏見について意識を高めることができる。これはより良き理解への第一歩で、あらゆる個人や集団の間に生じる差異に対して偏見のない見方と共感を築き上げていく上で必須である。
2017年に欧州科学技術研究協力機構(COST)のアクションとして「ヨーロッパ文学史遠読 」(Distant Reading for European Literary History, COST Action CA16204)が始まった時、私はこのプロジェクトの多様性アンバサダーになるように頼まれた。COST は EU が財源を出している基金で、アクションと呼ばれる計画に資金を提供する組織だ。こうしたアクションの目的は「ヨーロッパ全域とそれに留まらない地域にわたる研究計画の接続を促進し、研究者や革新的な試みをする人々が仲間との情報共有によってあらゆる科学技術分野のアイディアを伸ばすことができるようにする」(https://www.cost.eu/)ことである。COST のアクションはひとつにつき4年間継続し、学界、中小企業、公的機関、その他の関連組織・当事者をまとめるものである。
COST に属するそれぞれの国は関心のあるどのアクションに参加してもよい。COST のメンバーである40カ国はアルバニア、オーストリア、ベルギー、ボスニア・ヘルツェゴビナ、ブルガリア、クロアチア、キプロス、チェコ共和国、デンマーク、エストニア、フィンランド、フランス、ジョージア、ドイツ、ギリシャ、ハンガリー、アイスランド、アイルランド、イタリア、ラトビア、リトアニア、ルクセンブルク、マルタ、モルドヴァ共和国、モンテネグロ、オランダ、北マケドニア共和国、ノルウェイ、ポーランド、ポルトガル、ルーマニア、セルビア、スロバキア、スロベニア、スペイン、スウェーデン、スイス、トルコ、ウクライナ、イギリスである。さらにイスラエルが非加盟協力国、南アフリカがパートナーメンバーだ。資金は実費のみで、会議費用とこうした会議に出席するのに必要な旅費・生活費となっている。人件費としては使えない。これはネットワーキングを行う機会をもうけるため、非常に様々な背景を有する人々と専門知識を物理的に集めることに明確に焦点をあてているためである。
COST アクション「ヨーロッパ文学史遠読 」は2017年11月に始まった。このアクションの目的は、「ヨーロッパ文学史が書かれるあり方を変えるのに必要な資源と方法を連帯して発達させる」研究者ネットワークを発展させることであった(https://www.distant-reading.net/)。遠読という言葉で、文学テクストの大規模コレクションに適用するコンピュータ分析手法の使用を意味している。このアクションは目的に掲げたもの以上を提供した。多言語のヨーロッパ文学テクストコレクションである ELTeC(European Literary Text Collection)は各国の伝統を横断して各種の方法を試験し、結果を比較するのに役立つものとなる予定で、少なくとも10の異なる言語で書かれた小説の全文を含むコーパスを作ると決まっていたが、より多くのものを提供することができ、他にも多数が今なお進行中である(https://www.distant-reading.net/eltec/)。
COST アクションで始まった協働は今も継続中で、CLS (Computational Literary Studies) INFRA プロジェクトなど、EU が資金を提供している他のプロジェクトへと広がっている。CLS INFRA は「デジタル時代の文学研究に着手するにあたって必要な、共有かつ持続可能なインフラ構築支援を行う。このプロジェクトはそれぞれ調査に必要なツールを用い、より広いユーザ基盤を視野に入れてこうした様々な資源を相互に連携させる。結果として起きる改善により、コンピュータを用いた文学研究及びそれに留まらない範囲において、使用できる資源に差があるコミュニティ間のギャップを埋めて研究者が利益を得ることができ、究極的には新しい研究を創り上げる機会と、共通でもあり多様でもあるヨーロッパの文化的伝統への洞察をもたらすことができる」(https://cordis.europa.eu/project/id/101004984)。これは2021年3月に始まり、2025年2月に終わる予定である。ウェブサイト https://clsinfra.io/ で進展状況を確認することができる。
COST アクションと多様性というトピックに戻ろう。このアクションは「より幅広く、より包括的でより地に足のついたヨーロッパ文学史と文化的アイデンティティの記述を生み出すことを促進」したいと考えていた。全体として見ると、31カ国の人々が COST アクションに参加しており、そのおかげでヨーロッパ全体(及びそこに留まらない地域)の代表者からなる極めて多様なネットワークになり、多くの異なる言語を代表するものとなった。地理的・言語的多様性は別としても、年齢、ジェンダー、研究分野の背景などにおいてとても良いバランスが保たれていた。あらゆる種類の言語や文化を有する文学研究者のみならず、言語学者やコンピュータ科学者、技術者も含んでいた。しかしながら民族という点ではより難しい問題が残っていた。
それから新型コロナウイルスが始まった。現地で実施される COST の会議は中止となり、オンライン会議に変更された。過去にはオンライン会議は現地で実施する対面の会議よりもずっとうまくいかないと思われていたのだが、今やオンラインのコミュニケーションを最大限に活用せざるを得ないことになった。使えるツールの数が増え、同時にどんどんユーザフレンドリーになっていった。そしてこちらも使い方を効率よく学んでいった。実際のところ、現地開催よりも多くの参加者が集まれたヴァーチャル会議もあった。日程調整の点でも、会議の場所に到着するのに必要な旅がなくなったので、直前に決めても会議を計画しやすくなった。
COST アクション「ヨーロッパ文学史遠読 」は2021年11月終了予定だったが、新型コロナウイルスパンデミックのせいで2022年4月まで期限が延期された。最後の研究会は国境を越えた旅行がまた可能になると期待して4月の終わりにポーランドのクラクフで行われる予定だった。2022年1月に、これができるかは極めて不透明だということがはっきりした。そうしてコアチームはリスクを冒さず、最後の研究会は完全にオンラインに移行することに決めた。この決定の理由は単に実際的なものだけではなく、多様性と包括性に関する意見も加味された。さまざまな国から来る人々にとって、地域ごとのパンデミックの展開のせいで旅ができる機会は平等なものではなくなる可能性があった。健康問題を抱えていたり、健康問題を抱えた他の人をケアする責任を負っていたりする人にとっても、まだ旅をして新型コロナウイルスに感染するようなリスクを冒すことはできないだろうということだった。
この方程式には経済的不平等も加えておきたい。ADHO 運営委員会の議長だった間、さまざまな異なる地域のデジタル人文学組織を代表している委員会メンバーは、明らかに毎年行われる ADHO 会議まで赴くのに必要な資金を持っており、そこで ADHO の意志決定プロセスに参加できるあらゆる種類の会議に参加することが期待されていた。実のところ、そうした旅費を賄うのに充分な資金を有する大学や機関と連携していなかったり、通常は旅費手当を計上してくれない機関で仕事をしていたりするデジタル人文学者は意志決定プロセスから排除されているということになる。こうした人々の声は聞き届けられず、資金のある学者に比べるとより困難な状況にあるのに代表となる者がいない。パンデミックの間、COST アクションの会議や最後の研究会をオンラインに移すことで、こうした現地開催の会議では代表者が不足してしまうグループにとっては依然よりもデジタル人文学のコミュニティに接続できるチャンスが増えた。
上に述べたような理由で、私はデジタル人文学分野ではパンデミックが終息した後すぐヴァーチャル会議をやめるということはしないようにすべきだと提案したい。もちろん、気候変動のこれまでになく暗い展開だけでも、会議をまた全部現地開催とするのをやめるのに充分な理由になるだろう。オンライン会議、講義、研究会は現地開催よりもっとずっといろいろな人を包括することができ、保持すべきだ。ある意味では、オンラインの催しはよりうまくいくところもあるとも言える。一例をあげると、スクリーン共有は素晴らしい機能だ。オンラインと現地開催イベント両方のフォーマットで実験を続け、どうすれば世界のさまざまな地域に住むデジタル人文学者皆が互いにつながり、協働できるような支援を行えるのかを探求しよう。
執筆者プロフィール
《連載》「Digital Japanese Studies 寸見」第87回
「DH2022東京記念レクチャーシリーズ「デジタル・ヒューマニティーズへの招待」の開催と日本の DH の将来」
デジタルヒューマニティーズ団体連盟(ADHO)[1]の年次大会 Digital Humanities(DH)が2022年7月末に東京で開催されることにあわせて(なお、コロナ禍下の対応として、参加者はオンラインで参加することとされている)[2]、DH2022実行委員会は、日本語話者に向けた記念レクチャーシリーズの開催をはじめた[3]。
第1回は中国哲学書電子化計画(Chinese Text Project、以下 CTP)[4]を運営する Donald Sturgeon 氏によるもので、原稿執筆時(2022年6月19日)で第3回までが終了し、この後も3回分の開催が発表されている。第1回の告知時よりもすでに開催予定は追加されており、最終的に何回催されるかは現時点で不明である。
第2回は西洋古典学の電子的原典集成・活用プロジェクトである Perseus Digital Library[5]から編集長の Gregory Crane 氏、第3回は論文の複層化をもくろむ Journal of Digital History[6](以下JDH)から編集主幹(Managing Editor)の Frédéric Clavert 氏が講演を行っている。なお、今後の予定としては、中国仏教における歴史 GIS(地理情報システム)の応用を試みる中國佛教寺廟志數位典藏(Digital Archive of Chinese Buddhist Temple Gazetteers)[7]などで知られる Marcus Bingenheimer 氏、ヨーロッパの人文的空間の歴史的発展を既知の資料によってだけでなく AI の力も得て復元する Time Machine プロジェクト[8]から Frédéric Kaplan 氏、3D デジタルオブジェクトの人文学的定位を目指す Susan Schreibman 氏の講演が現時点で告知されている。いずれの回も関係する日本の研究者からコメントがあり、回によっては逐次通訳がつけられているものもあり、参加・理解しやすいようになっている。
稿者は、第1回と第3回に参加することができた。別途イベントレポートがあるだろうから内容の紹介は簡単に留めておく。
第1回は、Sturgeon 氏が CTP の紹介を行うものだった。CTP は2005年にはじめられたもので、日本でも幾度か Sturgeon 氏を招いてワークショップなどが開催されている。今回のものは、最近の動向もふまえて全般的な紹介が行われており、稿者のような時折の利用者にも得るところが多かった。
CTP は、先秦から清にいたるまでの漢籍(仏典は含まれない)の大規模な電子化プロジェクトであり、2017年4月のデータによれば[9]、先秦・漢代のテキストのみで約570万字、漢以降のものは2000万字を数えるという(現在はなお増えているのではないかと思われる)。ここ数年はクラウドソーシングによるテキスト入力や、さらにはアノテーションにも力を入れており、自動でアノテーションする研究も進められているとのことである。日本語歴史コーパスの前近代の総計が現状400万語程度なので[10]、単純に比較できるものではないのは当然のこととして、規模の違いが伺えようか。
第3回は、Clavert 氏が JDH の紹介を行うものであった。これについては、すでに本誌でコメンテーターを務めた小風氏の紹介がある[11]。この雑誌は、ルクセンブルク大学の現代及びデジタル歴史センターに拠点を置いて編集が進められているものだが、デジタル解釈学 digital hermeneutics というものの実践たることを目指している点に特徴がある。それは、Jupyter Notebook という[12]、プログラミング言語 Python の対話的実行環境とテキスト記述の両立―Notebook―を果たす対話的な場によって論文を書くとすればどうなるかという試みでもある。JDH は、このようなコードを用いる解釈学層を下地として、歴史叙述を行う層を重ねるためのプラットフォームである。これは、デジタル歴史学がデータや方法論の場であるデジタル人文学と叙述の場である歴史学に引き裂かれている現状に一体性を取り返す試みなのであろう。Python のプログラムの検証をどのように行うか―プログラム自体の結果の妥当性、また論述に照らしての妥当性をどう担保するか―についての課題は残るというが、それじたいは、著者まかせで見てこなかった論文誌に当てはまらないわけではない。講演では、「紙幅のため」割愛されがちだった解釈学の復権について何度か述べられており、デジタル環境が研究の責任を変えるということのストイックな実践であることを窺わせられた(なお、日本でも CODH の北本氏らの「歴史ビッグデータ」プロジェクト[13]は、類似の発想に基づくもののインフラ作りだといえよう)。
第2回の Perseus Digital Library は、残念ながら拝聴する機会を得られなかったが、すでに本誌上でもコメンテーターもなさった吉川氏の紹介があり[14]、また小川潤氏によるインタビューも備わるので[15]、大要はそれで得られよう。Perseus Digital Library には、CTP とはちがう、大規模テキストプロジェクトゆえの広がりがあり、CTP とともに、日本の古典学テキストプロジェクトがどうあるべきか、学ぶところは大きい。
今回のレクチャーシリーズでは、CTP のような個人プロジェクトもあれば、Time Machine のような大規模プロジェクトもあり、その内容も多彩である。その多彩さは、彼我のよしあしのようなものとして気に掛けるべきものではないのだろう。しょせん人間の思いつくことであり、また、世のしがらみも彼我それぞれにあるわけである。本レクチャーシリーズの個々の内容が極端に先端的で、それを追い越せるよう頑張るべきだといったことではなく、むしろ、そのような多様な実践に触れ、またそれに応答できる日本のDHの現状こそ(このような多様な人材にコメンテーターを依頼できることにこそ)、レガシーとして残るべきものなのだろうと思わされた。
そのレガシーを育む出発点として、今回の DH2022と記念レクチャーシリーズは、じつによい機会なのだろうと思う。本連載の読者諸賢もぜひご参加いただきたい。
小風尚樹「詳細なレシピもいいが、肝心の料理の質を上げてくれ:議論主導型のデジタル・ヒストリーと探索的データ分析」『人文情報学月報』129号、2022年。
https://www.dhii.jp/DHM/dhm32-1.
https://www.dhii.jp/DHM/dhm33-1.
https://www.dhii.jp/DHM/dhm34-1.
https://www.dhii.jp/DHM/dhm90-2.
https://www.dhii.jp/DHM/dhm91-2.
https://www.dhii.jp/DHM/dhm93-2.
https://www.dhii.jp/DHM/dhm94.
《連載》「欧州・中東デジタル・ヒューマニティーズ動向」第48回
「手書きテキスト認識(HTR)・自動翻刻ツール eScriptorium と対訳アライメント・ツール Ugarit:DH2022 東京ワークショップ・チュートリアル解説」
来る7月25日~29日、アジア初となる ADHO(Alliance of Digital Humanities Organizations: 国際 DH 学会連合)の年次学術大会 Digital Humanities (DH) 2022が東京で開催される[1]。そして、開催はオンラインになったが、非常に多様な26のワークショップ・チュートリアル(以下、WT)が7月25日から26日にかけて開催される[2]。これらの WT では、DH の実用的な技術を手を動かして学んだり、あるトピックについて理解を深めることができる。本稿では DH2022のハンズオンの WT で教授される DH ツールのうち、欧州で開発されてきている eScriptorium[3]と Ugarit[4]について解説する。
手書きテキスト認識(Handwritten Text Recognition: HTR)・自動翻刻ツール eScriptorium
- ワークショップ・チュートリアル番号:WT-20[5]
- タイトル: Hands-on Introduction to eScriptorium, an Open-Source Platform for HTR(HTR のオープンソース・プラットフォームの eScriptorium へのハンズオンでの入門)
- 日時:2022年7月26日 日本時間12時から15時半
- 講師:ピーター・ストークス(Peter Stokes)、ダニエル・シュテクル=ベン=エズラ(Daniel Stökl Ben Ezra)
- 定員:45人
- 概要の要約:様々な言語、文字体系、複雑なページレイアウトの手稿や印刷物の文字を自動で翻刻する、オープンソースの HTR ツールである eScriptorium のハンズオンチュートリアルである。ページのレイアウトを自動/手動で分析し、AI を訓練させて文字認識させる。また既存のモデルのインポート方法、自分のモデルのエクスポート方法も学ぶ。学習済みモデルの自由な共有、言語や文字から可能な限り独立したシステムであることなど、本ツールの独自性に焦点を当てて説明する。
手書きテキスト認識としては、これまで Transkribus[6]の動向を数多くこの連載で紹介してきた[7]。しかしながら、ヨーロッパでは、OCR4all[8]等 Transkribus 以外の HTR ソフトの開発も現在盛んである。それらの HTR ソフトの一つ eScriptorium は、本連載でも一度紹介したように[9]、パリのグランゼコールであるエコール・ノルマル・シュペリウールなどが結集して創立されたパリ文理研究大学(PSL大学)の eScripta プロジェクトの DH 部門が開発している[10]。
eScriptorium は現在ブラウザで動く HTR アプリの開発を推し進めており,それが使用可能な域にまで来ている。これを使用するには、これまでのところアカウント登録が必要であるが、全ての人が自由にアカウント登録できるわけではなく、eScriptorium のメンバーに特別に依頼してアカウントを作ってもらう必要があった。東京大学 DH 勉強会(UTDH)の多言語テキスト勉強会にて、現在ライプチヒ大学のインド学の博士課程学生である京極祐希氏が、eScriptorium の中心メンバーであるシュテックル=ベン=エズラ氏からアカウントを取得し、チベット語文献などで、eScriptorium を試した。京極氏は、その結果を勉強会にて披露してくれた。
京極氏のデモによれば、eScriptorium はブラウザ上で動かすことができる。レイアウト分析は独自のものであり、様々な方向のテキストのレイアウトを認識することができる。テキスト認識エンジンは、この連載でも紹介した Kraken を用いており、あらゆる手書きテキスト・文字を学習させることができる[11]。Transkribus は、横書きの文字だけしか対応していなかったが、eScriptorium は、縦書きの言語も対応できるほか、余白に斜めに書かれている文字なども認識することができる。また、レイアウト認識もトレーニングさせることが可能である。
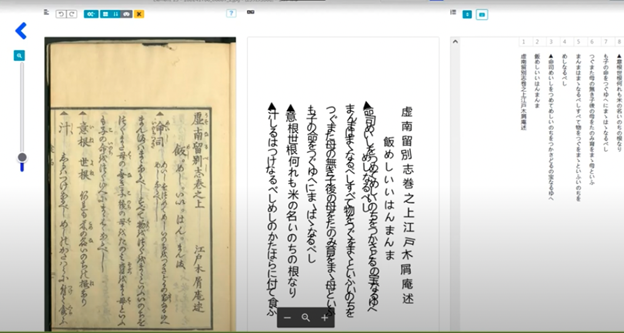
また、出力も人文資料のテキスト構造化の標準である TEI XML での出力がかなり強化されており、DH での使用に適したツールであると言えよう。eScriptorium という良きライバルができたことで、現在欧州の HTR で最大のシェアを誇っている Transkribus も、縦書き対応、レイアウト認識のフル・トレーニング、よりリッチな TEI XML の出力ができるようになることを期待している。実際、この原稿を書いている間、Transkribus のレイアウト認識のうち、ベースライン認識のトレーニングが可能になるという発表があった[12]。
対訳アライメント・ツール Ugarit
- 番号:WT-11[13]
- 講座名:Ugarit: Translation Alignment Technologies for Under-resourced Languages(Ugarit: 少資源言語の翻訳アライメント技術)
- 講師:キアラ・パッラディーノ(Chiara Palladino)、ナディア・カナガワ(Nadia Kanagawa)、タリーク・ユーセフ(Tariq Yousef)、ファルヌーシュ・シャミシアン(Farnoosh Shamsian)
- 時間:2022年7月25日日本時間22時~26日1時半
- 定員:15名
- 講座概要の要約:低リソース言語や歴史的言語の対訳アライメントツールである Ugarit の、研究および言語教育における様々な利用方法についてデモとハンズオンとディスカッションを交えながら学ぶ。受講対象は古文書、翻訳研究、語彙研究、NLP、計算言語学に携わっている者である。DH の専門知識は必要ないが参加者自身がコーパスを持参することが推奨される。
Ugarit は対訳で対応する語彙をマークアップし表示させるツールである。現在、このツールには45言語の、601,771個の対訳ペアを含む26,771個のテキストデータが606名のユーザによって蓄積され、翻訳研究・言語教育・機械翻訳に応用されてきている。アカウントを持つユーザがデータを追加することができ、編集画面では、2つもしくは3つの対訳テキストで、対応している単語もしくは句のペアをクリックして登録していく。語彙の選択率がパーセンテージで表示され、全ての語彙が選択されると100% と表示される。現在様々な言語のデータが登録されており、とくにギリシア語、英語、ラテン語、ペルシア語、ポルトガル語、ジョージア語、イタリア語のデータが非常に多い印象である。
登録したデータは、公開と非公開のどちらかを選べる。公開されたデータはだれもが見ることができ、原文・対訳のどちらかのテキストの単語の上をマウスオーバーすると、もう一方のテキストのほうで、対応する単語がハイライトされ、どの単語・句がどう訳されているかを見ることができる。現在、管見では、西洋古典および聖書の本文と諸言語翻訳の対訳アライメントのデータが非常に多いが、過去の筆者のリクエストによって日本語、沖縄語、アイヌ語が追加されており、元からあった中国語を含めて、東アジアの諸言語も入力可能になりつつある。

eScriptorium や Ugarit のような最先端の DH ツールがチュートリアルで教授されることで、日本の DH でもこれらのツールの認知度が上がり、日本語など東アジア言語を含めより多様な言語・文字体系に適応されていくことが期待される。
- コメントを投稿するにはログインしてください