人文情報学月報第162号【前編】
ISSN 2189-1621 / 2011年08月27日創刊
目次
【前編】
- 《巻頭言》「北京大学デジタル・ヒューマニティーズ研究センターについて」
:北京大学情報管理学部 - 《連載》「欧州・中東デジタル・ヒューマニティーズ動向」第78回
「DraCor:TEI ガイドライン準拠の多言語演劇テキスト・コーパス」
:筑波大学人文社会系
【後編】
- 《連載》「英米文学と DH」第1回
「ハティトラスト・デジタルライブラリーとハティトラスト・リサーチセンター」
:中央大学国際情報学部 - 《特別寄稿》「Cynthia Damon による「11. Beyond Variants: Some Digital Desiderata for the Critical Apparatus of Ancient Greek and Latin Texts」(『Digital Scholarly Editing-Theories and Practices』所収)の要約と紹介」
:早稲田大学大学院文学研究科 - 人文情報学イベント関連カレンダー
- 編集後記
《巻頭言》「北京大学デジタル・ヒューマニティーズ研究センターについて」
北京大学デジタル・ヒューマニティーズ研究センター(Research Center for Digital Humanities of Peking University、以下 PKUDH;デジタル・ヒューマニティーズは DH と略す)は、2020年5月に設立された。2020年初頭に新型コロナウィルスのパンデミックの急拡大を受けて、中国の大学では対面授業が中止され、すべてがオンラインに移行されたため、学生や教員の行動範囲が制限され、賑やかだったキャンパスは一気に静かになった。このようにひっそりしている状況に活気をもたらすために、PKUDH は第1回オンライン DH ワークショップを開催した。その後の4年間で、PKUDH は引き続き北京大学初の DH プロジェクト展、北京大学・ハーバード大学・プリンストン大学合同の DH サマーワークショップ、DH 教育の国際シンポジウムなどの学術活動を主催した。また、『宋元学案』知識グラフ、「識典古籍」閲覧プラットフォーム、「吾与点」知識グラフ生成プラットフォーム、「詩千家」古詩自動生成プラットフォームなどの DH 研究プラットフォームを開発した。それに加えて、関連分野のトップジャーナルやトップカンファレンスで画期的な研究成果を発表し、現在は中国国内の重要な DH 研究の拠点となっている。
PKUDH は、AI 時代の人文学の発展のためにツールやプラットフォームを開発し、AI 時代の人文学研究のデータ駆動型パラダイムを促進することをコア目標として掲げている。北京大学学内では、人文学と理工系の交流と協力のプラットフォームを構築することに注力している。一方、学外では、中国のインターネット企業と協力し、高品質な中国語情報リソース とプラットフォームを共に構築している。さらに、国際的には、海外の大学と積極的に協力し、DH の教育と人材育成を推進している。
デジタル・ヒューマニティーズは学際的な分野である。伝統的な人文学の研究者のなかには、DH の手法を人文学の研究に応用する必要がないと思う人もいる。中国では、人文学のバックボーンは中国の文学、歴史、哲学の三大分野である。中国古代の文献 は、これら3つの学問分野に利用される基本的、核心的な研究資料である。伝統的な人文学の研究者にデジタル技術が人文学の研究に有用であることを認識させ、そして文学、歴史、哲学の分野における DH の手法の発展を促進するためには、まず中国の古典籍のデジタル化と AI による処理を可能にすることから始める必要がある。これは PKUDH がここ数年、主にこの分野に取り組んできた理由でもある。以下では、PKUDH で展開される中国の古典籍の AI を用いた処理に係るプロジェクトを紹介する。中国の古典籍は日本での人文学研究にとっても重要な研究資料であるため、我々の研究成果が日本の研究者にとっても参考になればと願う。
1. 「識典古籍」閲覧と校勘 プラットフォーム(https://www.shidianguji.com)
中国古典籍のデジタル化は早くも20年前に始まった。統計によると、現存する中国古典籍は約20万種類あり、そのなかの約8万種類がデジタル化されたいう。しかし、精緻な校勘を経て出版に適しているのは1万種類に満たない。また、既存の高品質な古典籍データベースのほとんどは有料となっている。2022年3月、PKUDH はインターネット企業バイトダンス(ByteDance)からの公益寄付を受け入れ、「識典古籍」というデジタル閲覧プラットフォームを共同で構築し始めた。著作権問題を避けるため、古典籍の OCR 文字認識から始めた。OCR の修正、句切り、固有名詞の認識、注釈まで、高品質の古典籍翻刻・校正を実現している。3年間の作業を経て、『四庫全書』、『乾隆大蔵経』、『正統道蔵』といった儒教、仏教、道教の基本資料のデジタルデキスト化を相次いで完了した。現時点で同プラットフォームからアクセスできる古典籍は1万種類に達し、「識典古籍」は中国最大規模のオープンアクセス古典籍デジタルプラットフォームとなった。「識典古籍」の最も大きな特徴は、古典籍デジタル化の全プロセスの AI 化を実現したことである。ユーザーがスキャンした古典籍の画像をアップロードすると、AI のアルゴリズムによって OCR文字認識、句切り、人名・地名・官職名・時代名の認識、異版校勘などが自動的に完了し、その後、人によるマニュアル作業で確認・校正が行われる。このプラットフォームは、すべての機関や個人に開放され、無料で利用できるため、中国古典籍のデジタル化にかつてない弾みをつけることができた。「識典古籍」プラットフォームは、最新の AI 技術である大規模言語モデル(以下 LLM)の技術を十分に駆使している。プラットフォーム上では、ユーザーは LLM を活用して、選択した古文テキストを現代語に翻訳したり、要約や AI との知識対話 を行ったりすることができる。テキスト中の固有名詞はオンライン百科事典にリンクされ、ユーザーの読解をサポートしている。

「識典古籍」プラットフォームを活用して、PKUDH とバイトダンス公益基金は、2024年7月末、全国の大学生を対象に「私は校書官」という参加型古典籍校勘の企画を開始した。これまでに958もの大学から12000人以上の大学生が参加し、参加大学数、参加人数ともに2024年度は過去最多となっており、校勘効率も過去最高となっている。この企画は、中国の大学生に古典籍整理に参加してもらうことで、古典籍文化を大いに普及させた。しかし、現代における古典籍文化の「復興」を真に推進するためには、若者の古典籍への関心を喚起する必要がある。その上で彼らに古典籍と現代社会の精神的ニーズを融合させ、新しいメディア技術を駆使して古典籍の内容を再解釈させ、創造的な利用と変容を実現してもらうことも不可欠である。これが PKUDH の今後の活動の方向性でもある。
2. 「吾与点」知識グラフ AI 生成プラットフォーム(Widen Your Data Intelligent Annotation Platform, https://wyd.pkudh.org)
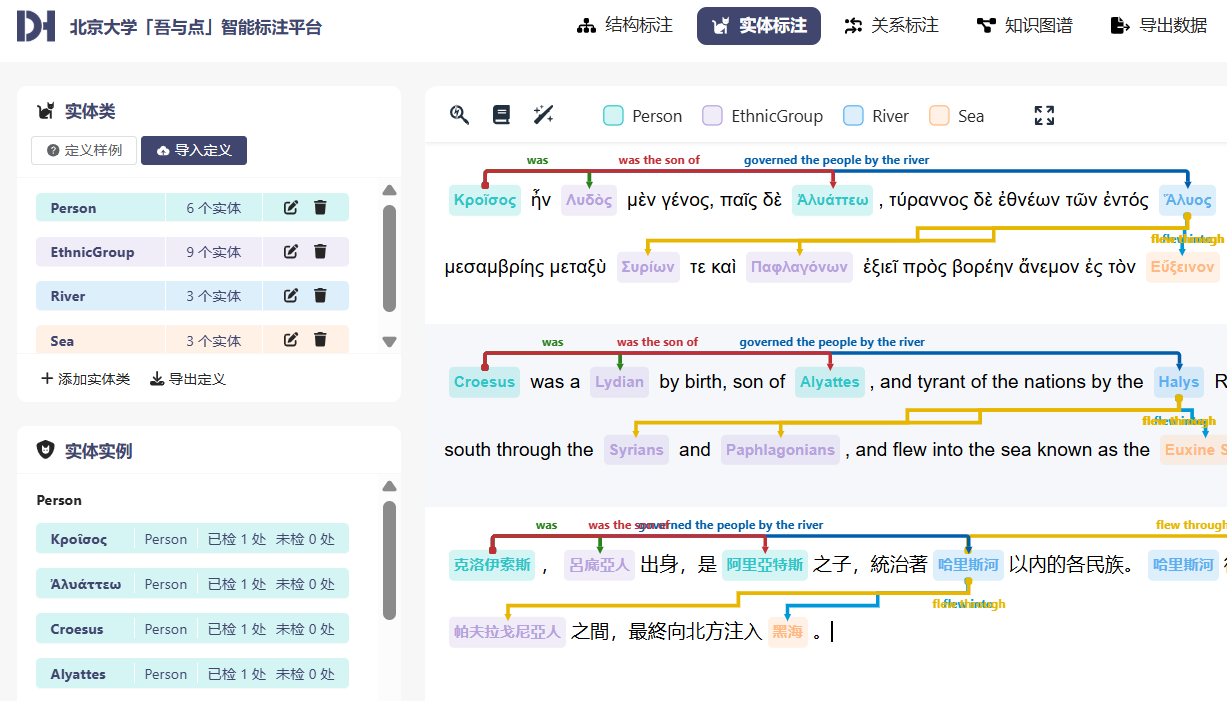
DH 研究に取り組むには、統計、社会ネットワーク分析、GIS マッピング、可視化などの研究手法を適用する前に、全文テキストをコンピューター可読なデータセットに変換する必要がある。従来、データ・アノテーションは研究者のマニュアル作業によって行われ、時間と努力を要するうえ、コストが高かったことが DH 研究のボトルネックとなっていた。PKUDH は独自に「吾与点」AI アノテーションシステムを開発した。当初は、BERT モデルを応用し、プレアノテーション済みのデータを使用しトレーニングした。その結果、エンティティ抽出モデルと関係抽出モデルが可能となった。これらのモデルは主に中国古代の歴史テキストに対する自動的な句区切りや実体と関係の抽出に活用された。2022年 LLM が登場してからは 、「吾与点」は LLM を全面的に採用するようになった。ユーザーはアノテーションしたいエンティティや関係の種類を自ら定義するだけで、GPT-4o、Claude、GLM、QWEN、ERNIE などの主要な LLM のいずれかを選択することで、自動的にテキストのなかのエンティティ関係を抽出し知識グラフを生成することができるようになった。このように自動生成されたデータは JSON、EXCEL、CSV、Gephi などの様々なデータ形式にエクスポートすることができ、専用ソフトウェアにインポートしてさらに分析するのに便利である。図3に示すように、ユーザーはまずシステムの左上隅にあるウィンドウに、全文テキストから抽出したい人物(person)、民族(ethnic group)、川(river)などのエンティティ、そして親と子、川と海などの関係を定義する。続いて、LLM を応用して自動抽出を完了させる。「吾与点」は多言語処理に対応しており、図3に示した例では、ギリシャ語、英語、中国語を同時に処理できる。日本語にも対応している。「吾与点」プラットフォームは現在アップデートのためメンテナンス中で、2025年1月には利用が再開される予定である。
3. 北京大学・ハーバード大学・プリンストン大学合同 DH サマーワークショップ
人文学的な問題意識を持ちながら、コンピューターの知識と技術 および国際的視野を備えた DH 研究者を育成するため、北京大学、ハーバード大学、プリンストン大学は2023年8月に合同で、DH サマーワークショップを開催した。PKUDH が主催する同ワークショップは、「AI 情報環境における人文学のイノベーション」をテーマとし、そこではどのようにデジタル手法を人文学の資料に応用し、人文学的な課題を研究するかを教えた。ワークショップでは、中国、アメリカ、ヨーロッパから6名の研究者を招き、講義と実習を組み合わせている。歴史学者は歴史的資料の特質と探求のための研究テーマを紹介し、デジタル技術の専門家は一般的な DH 手法とデジタルツールについて教えた。学生は学際的なプロジェクトチームを結成して興味のある研究テーマを選択し、プロジェクトベース のスタイルで研究を展開した。
このサマーワークショップには、世界17カ国の277の大学(内訳:中国205、米国49、イギリス29、ドイツ6、韓国6、シンガポール6)から計863件の応募があり、最終的に、14カ国の59大学から83名の参加者が受け入れられた。積極的な応募状況は、DH の世界的なブームを反映していると言える。
2週間続いたワークショップの第1週目では、コンピューター的思考 法、テキスト分析、社会ネットワーク分析、GIS 分析などを内容とする講義が行われた。続いて第2週目では、80名あまりの参加者が17のチームを作り、自由にテーマを選び、協力して一つの DH プロジェクトを完成させた。最終報告として、17チームはそれぞれプロジェクトの研究成果をポスター発表した。
学術研究の面においては、PKUDH は現在定量的な文化の分析 とデジタル・ヒストリーに注力している。1)定量的文化分析:統計学、機械学習、可視化などの技術を応用して、中国古代の思想の変遷を考察する。具体的には長い間蓄積された古代中国思想史に関する言語コーパスを素材に、主にテキスト間の相互分析とコア概念の語彙的・意味的変遷の分析を通して考察を進める。これに関する研究成果の一部は、すでに Nature 傘下 のジャーナル「Humanities and Social Sciences Communications」に発表されている[1]。2)デジタル・ヒストリー:「吾与点」プラットフォームでは、LLM がテキストから任意の意味データを抽出する能力を持っていることを検証した[2]。膨大な歴史資料から必要な構造化データを抽出し、統計分布 、データマイニング、ベクトル計算 (Vector Computing)などの手法による歴史研究を可能にする。我々は現在このような研究を進めている。「吾与点」プラットフォームは日本語の処理能力も備えているため、日本の研究者にもお試しいただきたい。このような研究において、今後日本の研究者と共同研究を行う機会があることを願っている。
執筆者プロフィール
《連載》「欧州・中東デジタル・ヒューマニティーズ動向」第78回
「DraCor:TEI ガイドライン準拠の多言語演劇テキスト・コーパス」
DraCor[1]は、多言語の演劇テキストを統一的な形式で整備し、研究者が自由に分析・比較できるよう公開しているオープンアクセスのデータプラットフォームである。ヨーロッパをはじめとする各地域の戯曲を対象とし、研究者が高度なテキスト解析やネットワーク分析を実行するための基礎データを提供している。もともとはドイツ語演劇コーパス GerDraCor とロシア語演劇コーパス RusDraCor を中心に始動し、現在では英語、フランス語、イタリア語、スペイン語、スウェーデン語、アルザス語、ハンガリー語、イディッシュ語、ウクライナ語、タタール語、バシキール語、古代ギリシア語など、ヨーロッパを中心とした多言語・多地域の演劇が収録されている。DraCor で公開されている戯曲数は数千点におよび、複数の言語コーパスに振り分けられて管理されている。いずれのコーパスも人文学テキスト構造化の世界標準である TEI(Text Encoding Initiative)ガイドラインに準拠した XML 形式(TEI/XML)でマークアップされており、登場人物の発話単位や場面区切りなどの構造情報が機械可読な状態で記録されている。これにより、登場人物抽出や台詞の分割など、複雑な作業が効率化され、従来の手作業に比べて大幅に時間を削減できる環境が整えられている。
言語毎に用意されているコーパスの他に、シェイクスピア全集などを専門に扱うコーパスも加わり、ある特定の劇作家の全作品を横断的に研究するといった高度な分析が可能になった。マルチリンガルなコーパスが同一基準のもとで整理されているため、言語や時代を越えた比較研究にもつなげやすい。さらにテキストの編成に用いられている TEI/XML では、著者や初演年、初出版年などのメタデータ、登場人物や台詞、ト書きといった要素が厳密に構造化されている。この点が単なる電子書籍データとの差異であり、研究者が計量的手法やテキストマイニングを実施する際に有効な下地となっている。いずれもパブリックドメイン化した作品がメインであり、著作権上の問題を気にせずダウンロード可能なケースが多い。DraCor のウェブページには、個別作品を閲覧できる仕組みが用意され、登場人物ネットワークの簡易表示などが行われているが、本格的な活用には API アクセスが推奨されている。これによって多様な形式でデータを取得し、大規模比較や言語間の相違点を定量的に示す研究が飛躍的に実施しやすくなる。
DraCor では、テキストを「プログラム可能なコーパス」(programmable corpora)[2]として活用する姿勢が際立っている。テキストの論理構造が TEI/XML として定義されていることで、研究者はプログラミング言語を用いた API リクエストによって、台詞や人物リストを動的に取得することが可能になる。幕や場の区切り、発話単位、登場人物同士の共起状況などが明確にマークアップされており、これらを短時間で抽出・再編できるため、大規模な調査や複数言語間の比較分析にも対応しやすい。高度な研究や分析に集中できるようになるのは、従来の手動によるデータ作成では困難だった大きなメリットである。
演劇研究では、人物同士が同じ場面で登場する共起関係をネットワークとして可視化する分析がしばしば行われる。DraCor では、そのようなネットワーク分析の素材を得るためのデータ抽出が容易であり、台詞回数や発話総数をもとに中心人物を定量的に割り出すことなども手早く実行できる。特に古代ギリシア語コーパスには、アイスキュロスやソフォクレス、エウリピデス、アリストファネスといった劇作家の代表作が複数含まれており(図1)、悲劇・喜劇それぞれにおける人物登場パターンや合唱隊コロスの役割を総合的に比較することが可能になっている。紙媒体では非常に煩雑だった作業が、DraCor を介したプログラム利用によって大規模に実施できるようになった点は、研究の飛躍を後押ししている。

TEI 形式で整備されたデータを効率よく扱ううえで不可欠なのが、DraCor の API 機能である[4]。ウェブブラウザから簡易的な検索や閲覧を行うだけでなく、プログラム経由で台詞や登場人物のデータを呼び出し、必要に応じて CSV や JSON、XML といった形式で受け取れるよう設計されている。たとえば「特定の女性登場人物が発話する総単語数」「ある作品の全台詞のうち場面番号と話者名をセットで抜き出す」などのリクエストを、URL パラメータによって指定できる。すべての言語コーパスに対して同様の抽出方法が通用するため、比較対象の作品数が増えても手間が大きく変わらない点は研究者にとって大きな利点である。
DraCor が Linked Open Data(LOD)との連携を進めていることも注目に値する。著者の情報を Wikidata などから補完し、同時代の人物や関連する事象を相互参照しやすくすることで、テキストの分析を文化史的・社会学的な視点へと拡張できる余地が広がっている。すでにプロジェクトとしては、メタデータやコーパスデータをバージョン管理しながら GitHub で公開しており[5]、世界中の研究者や専門家が Pull Request や Issue を通じて改善や更新に参加できる体制を整えている。このようなオープンで協働的な運営方針が、DraCor のコーパス拡充や品質向上に寄与しており、多言語・多分野の研究者が集まって知見や注釈を付け加えることで、より豊かなデータベースへと発展を続けている。
教育面でも、このプラットフォームは大きな役割を果たす。大学の講義や演習で、学生が DraCor の API を使い、簡単なスクリプトを組んで台詞の分布や登場人物の相関を可視化することで、データサイエンスやプログラミングの初歩を体得しながら演劇の構造を深く理解できる。プログラミング未経験者であっても、ブラウザ上でネットワーク図などを閲覧できる機能が提供されており、研究や学習の導入として有益である。さらに深い分析を行いたい場合には API を利用したプログラム的なデータ取得へ進むという二段階の使い分けが、学習の進度に合わせて可能になっている。また、ゲーミフィケーション(図2)として、本データベースを用いた様々なゲームが用意されている。

以上のように、DraCor は演劇研究とデジタル・ヒューマニティーズを結びつける重要なインフラとして機能している。紙媒体の戯曲を一つひとつ入手し、研究者自身がデータ入力と注釈付けを行う従来の方法は、国際的な比較研究を行ううえで大きな障壁となっていた。しかし DraCor は、国際標準の TEI フォーマットでテキストを整備し、ダウンロード機能や API を用意することで、研究者が必要なデータを即座に取得できる仕組みを実現している。台詞の構造やメタデータに付された属性情報に容易にアクセスでき、分析や可視化に必要な作業を大幅に簡略化できる点が大きな利点である。このように、多言語の演劇テキストを TEI で標準化し、API を通じてプログラム的にアクセスできるようにすることで、これまで膨大な労力が必要だった大規模分析や横断的な比較研究が手頃になった。古代ギリシア語を含む幅広い演劇作品が同一の枠組みで整備されているため、学際的・国際的な共同研究を推進する基盤としても意義が大きい。文化史や文学史の研究はもちろん、教育現場での活用や、LOD との連携による多角的アプローチも期待されており、DraCor が学界に提供しているメリットは今後も拡充していくと考えられている。
- コメントを投稿するにはログインしてください