人文情報学月報第90号【前編】
目次
【前編】
- 《巻頭言》「2018年の到達点とこれから」
:一般財団法人人文情報学研究所 - 《連載》「Digital Japanese Studies寸見」第46回
「TEI コンソーシアム東アジア/日本語分科会の活動が本格化」
:国文学研究資料館古典籍共同研究事業センター - 《連載》「欧州・中東デジタル・ヒューマニティーズ動向」第10回
「ドイツ語圏のパピルス文献デジタル・アーカイブ」
:ゲッティンゲン大学
【中編】
- 《連載》「東アジア研究と DH を学ぶ」第10回
「デジタル史料批判を学ぶ教育・学習プラットフォーム Ranke.2について」
:関西大学アジア・オープン・リサーチセンター - 特別寄稿「Gregory Crane 氏インタビュー全訳(第1回)」
:東京大学大学院人文社会系研究科
【後編】
- 特別寄稿「Carolina Digital Humanities Initiative Fellow の経験を通じて〈後半〉」
- 人文情報学イベントカレンダー
- 編集後記
《巻頭言》「2018年の到達点とこれから」
2018年の日本の人文情報学に関する事柄を振り返ってみると、デジタル化資料の研究活用のための基盤整備に関わる事柄についての進展が大きかったように思われる。史資料をデジタル化して、いわゆる「デジタルアーカイブ」を作成・公開することは以前から取り組まれてきていたが、公開された画像や音声、動画等をどう活用するかということは大きな課題であり続けてきており、その出口の一つとしての研究活用は、人文情報学との幅広い接点を持ち得るものであった。このところ、それをより効果的に実現するための有力な手段となり得るデータ共有の標準化手法が徐々に広がりを見せてきていたが、そのなかでも、画像をはじめとする Web コンテンツを効率的に連携させる仕組みであるとして国際的に大きな広がりを見せ、日本でも徐々に広まりつつあった IIIF(International Image Interoperability Framework)が、2018年には、ついに国立国会図書館デジタルコレクションにおいて採用されるに至り、30万件を超える資料が IIIF を通じて活用可能となった。IIIF は、Web での動的な二次利用を容易にすることが大きな特徴であり、すでに国内外で公開されている IIIF コンテンツを横断する様々な二次創作的コンテンツが作成・共有され、研究の利便性を高めるだけでなくアウトリーチのツールとしても活用されていくことだろう。IIIF の特徴を活かした組織的な活用事例としては、京都大学・慶應義塾大学等に分散して所蔵されている富士川文庫のデジタル化画像を統合的に閲覧できる仕組みが公開された。さらに、IIIF Discovery in Japanは、国内機関から公開さていれる IIIF コンテンツの横断検索を提供し、また、人文学オープンデータ共同利用センターからはIIIFコンテンツを活用するための便利なソリューションとして、IIIF Curation Platform が公開されるなど、この流れを大きく後押ししていくと期待される。近年の海外の注目すべき活用事例としては、英国図書館が実施するプロジェクトIn the Spotlightがある。ここでは、OCR が困難な芝居のビラを IIIF 準拠で画像公開してしまってタイトルから利用者に付与させるという、以前なら無責任だと批判されそうなことをしているが、今のところ着実に進行しているようである。また、研究分野に特化された活用例としては、SAT 大蔵経テキストデータベース研究会による IIIF Manifests for Buddhist Studies が、国内外の仏教典籍 IIIF コンテンツを集約しつつ、研究者コミュニティ側でメタデータを補足しつつ既存のテキストベースにリンクさせるコラボレーションシステムを提供し、その成果が京都大学貴重資料デジタルアーカイブにフィードバックされたことがあった。2019年に入ってからは、「電子展示『捃拾帖』」が既存の充実したメタデータを統合して地図・年表上でも IIIF コンテンツを閲覧できるシステムを公開するなど、IIIF に関しては、今後より様々な形での研究活用の幅を広げていくことが期待される。
また、人文情報学において有力な資料デジタル化の標準的手法である TEI(Text Encoding Initiative)ガイドラインに関しても、大きな進展がみられた。とりわけ、30年を超える TEI 協会の歴史のなかで、初めて欧米以外の地域で年次総会が開催されたことは国際的な文脈においても大きな意義を持つ出来事であった。そして、東アジア/日本語分科会が本格的に活動を開始し、日本語での TEI ガイドライン利用に関する道を拓きつつある。欧州の人文情報学インフラプロジェクト DARIAH が公開する、西洋中世写本への TEI ガイドライン適用に関するチュートリアル動画に日本語字幕がついたことも、欧州の人文学で何が行われているかを具体的に日本語で共有できるという意味で、地味ではあるが着実な一つの前進だろう。2019年に入って、「TEI で青空文庫」が始動している。テキストデータの効率的・効果的な共有手法は日本の人文学においても喫緊の課題であり、この方面の今後の進展はいっそう重要となっていかざるを得ないだろう。
データの保存と継承に関して、それを自覚的に実施していこうとする漢字字体規範史データセット保存会が設立され、Git リポジトリを通じてデータを公開するようになったたことは、データの保存と継承についてきわめて自覚的であるという点において日本の人文情報学では新しくかつ注目に値する動きだろう。オープンデータ・オープンサイエンスが先進的な事業として取り組まれていく一方で、公開され、活用されつつあるデータが継承できなくなる例は未だに少なくない。筆者もデータをサルベージして再公開した経験は複数回あり、その重要性とともに担当者にとっての困難さ・不毛さもよく実感するところである。上述の「電子展示『捃拾帖』」では、東京大学史料編纂所が公開する目録データを同大学総合図書館が IIIF コンテンツと紐付けて公開するという、データの継承をさらに高い次元での統合に結びつけた興味深い事例であり、単に継承するだけでなく、このように新たな知識を提示するところまでいくような事例が各所から出てくるようになれば、この種の取り組みもより面白いものになっていくだろう。
著作権法の変更により保護期間が70年になってしまったことも、2018年の大きな出来事であった。しかし、一方で、いわゆる HathiTrust や Google Books のような、著作権保護されたコンテンツの検索のみのサービスを提供する道が拓けたこともあり、すでに「語彙索引の検索」という検索サービスが試験公開されている。今後この種のサービスが本格化すれば、人文情報学に資するところも大きくなっていくだろう。この点については、HathiTrust Research Center が提供する「非消費的利用」に基づくサービスを改めて検討し、日本で導入可能な形を模索する必要があるだろう。
12月に開催されたじんもんこんシンポジウムでは、くずし字 OCR の新しい手法が発表された。機械学習を用いることにより、これまでとは異なる次元の精度を実現しており、今後大いに期待できるもののように思われた。これも人文学オープンデータ共同利用センターによる取り組みの一環である。
取り上げるべき事柄は他にも多くあるが、高度なデジタル技術が標準化・コモディティ化されることにより、人文学の知見とマッシュアップされて新しい展開を生み出していく、そのような萌芽がそこここに見られた2018年であった。総じて、人文学の現代的な存在意義を提示していくうえでデジタル技術の利用は不可欠のものになりつつあり、人文情報学がそこに果たし得る役割はますます大きなものになってきている。2019年に入り、明星大学において「古典は本当に必要なのか」というシンポジウムが開かれ大いに議論を呼んだが、この課題においても人文情報学は様々な形で貢献できるだろう。2019年は、その方向性をより推し進め、深化させていくことを期待したい。
《連載》「Digital Japanese Studies 寸見」第46回
「TEI コンソーシアム東アジア/日本語分科会の活動が本格化」
いささか宣伝めくが(これはあくまで個人的に書いている)、2018年4月より TEI コンソーシアム[1]の東アジア/日本語分科会[2]の運営委員を拝命して活動を行っている。TEI は、あまりこの連載で取り上げたことはないが、人文系テキストを電子テキストとして符号化するために Text Encoding Initiative というコミュニティで作られる規格であり、その元締めとして TEI コンソーシアムが設置されている。TEI は1980年代後半より議論され、1990年に最初の規格のリリースである P1が出ており(当時は SGML)、現在は拡充や XML 化された P5が改訂を受けながら流通している[3]。2018年9月に TEI コンソーシアムの年次会議が東京で JADH2018と併催されたことも記憶に新しい[4]。
符号化とは、かみ砕いて言えばコンピュータやネットワーク上でデータを交換する際の共通の形式に変換することといえる。文字を符号化すれば(文字コード)、符号の番号によって電子テキストを送ることができるし、画像を符号化すれば、視覚情報を相手に送ることができる。テキストを符号化すると、単なる文字情報を越えて文書としてやりとりすることが可能になるのである。Microsoft Word や HTML のデータも、その点では符号化された文書であるが、見た目の再現が主であって、文書の構造の意味をやりとりするのには十分でない。文字を画像にしてしまうと、色の集まりとして符号化されてしまうので文字として扱うには不都合が多い。人文系のテキストを扱うには不十分であるとして、その点の解消を目指したもののひとつが TEI である。
さて、TEI は、西欧文献の処理を行う人々が中心になって作り上げられてきたものであり、西欧文献であればかゆいところが一つもないことはなかろうが、その他の地域の文献の処理を TEI で行いたいという要求に対して、さまざまな面から応えきれていないことは否定しがたいことである。そのようなものを補うあらたな規格の開発もひとつの手段ではあろうが、TEI のアプリケーションの多さやコミュニティの厚さに追いつくことは難しく、西欧文献以外でも使えるように TEI を改善したり、西欧文献以外の符号化を目指す人々が TEI へ入りやすくするための活動を行うこともまたひとつの手段である。日本語文献においてそのような活動を行うために、永崎研宣氏とチャールズ・ミュラー氏がコンビーナーとなって2016年に TEI コンソーシアムの分科会(SIG)として設置されたのが東アジア/日本語分科会である。東アジア圏特有の文献的特徴を扱いつつ、とくに日本語を中心にするという意味がこの名称には込められているという。分科会ではこれまで若干の活動を行ってきたが、2018年3月に運営委員選挙があり、筆者を含む3名が立候補して全員が信任を受けて、本格的な活動を始動した。
まず最初に取り組んだのは TEI に関する英語のオンライン教材への字幕作成であり[5]、ついでさきにも述べた TEI2018での分科会ミーティング[6]である。さいきんは、ODD ファイルの翻訳会を定期的に行っており[7]、今月からは青空文庫の電子化テキストをもとに TEI で符号化を行ってプログラム等でより扱いやすくしようという試みを行っている[8]。
設置以来、取り組もうとしていることとしては、TEI 化をいかに進めればよいか多様な具体例を伴うガイドラインを作成することであり、また、TEI 化にあたって仕様上不足がある点をとりまとめて解消を目指すことである。日本語文献でも TEI を適用した事例はすこしずつ増えてはおり[9]、TEI に適用する際の技術的論点が議論されてもいるが[10]、実例があってはじめて困った点も生まれ、そして解決する欲が出るわけであり、いろいろな文献を符号化して困っていきたいと考えている。
運営委員はTEIコンソーシアムの会員であることとされており、筆者の場合、所属先で会員となっている。
Hanna McGaughey, “Digitizing Zeami” (poster session, JADH2018, Hitotsubashi Hall, Tokyo, September 10, 2018).
後藤真・小風尚樹・橋本雄太・小風綾乃・永崎研宣「構造化記述されたテクストの基盤整備に向けて:延喜式の TEI マークアップを事例に」『じんもんこん2018論文集』(2018).
叢艶・高久雅生「唐詩作品の本文フルテキストに対する TEI マークアップ手法の提案」『情報知識学会誌』28, no. 2(2018).
Hanna McGaughey, organizer, “Confronting Challenges in Marking Up Pre-modern East Asian Documents” (panel session, TEI2018, Hitotsubashi Hall, Septemer 11, 2018).
《連載》「欧州・中東デジタル・ヒューマニティーズ動向」第10回
「ドイツ語圏のパピルス文献デジタル・アーカイブ」
先々回は、スイスのボドマー・コレクション(ボドメール・コレクション)のデジタル・アーカイブである Bodmer Lab(https://bodmerlab.unige.ch/fr)を紹介した。今回は、その他のヨーロッパのデジタル・アーカイブで、BodLab のようにパピルス文献で著名なデジタル・アーカイブを紹介したい。ただし、ヨーロッパ全体のパピルス学デジタル・アーカイブを紹介するには一回では足りないので、今回はドイツ語圏のもののみにする。
パピルス文献とは、主にナイル川で生息するカヤツリグサの一種であるパピルス草の茎から作られる紙状のパピルスと呼ばれる記録媒体に炭などから作ったインクで文字を書き記したものである。パピルスは古代エジプト文明で記録媒体として広く用いられ、ギリシアやローマによる支配においても主な記録媒体として活躍し、ビザンツ帝国期には羊皮紙に押されながらも記録媒体としては使われ続け、イスラーム征服後も初期のころはよく用いられ、紙が支配的になるまで用いられた。
歴史的にパピルスに書かれた言語は数多く、エジプト語(古エジプト語、中エジプト語、新エジプト語、民衆文字エジプト語、コプト語の総称)、ギリシア語、ラテン語、シリア語、メロエ語、古ヌビア語、アラム語、パフラヴィー語、アラビア語などが記された。文字としては、ヒエログリフ(聖刻文字)、ヒエラティック(神官文字)、デモティック(民衆文字)、ギリシア文字、コプト文字(ギリシア文字+デモティックより数文字)、メロエ文字、ヌビア文字(コプト文字+メロエ文字より数文字)、アラム文字、ラテン文字、シリア文字、パフラヴィー文字、アラビア文字などがパピルスに書かれた。
主にパピルスを研究対象とし、オストラカ(陶片)なども扱う文献学を特別に、パピルス学(Papyrology)という。オストラカもエジプトやギリシアでよく用いられた記録媒体であるが、オストラカ学(Ostracology)という名称はほぼ使用されず、パピルスではないにもかかわらず、大抵はパピルス学という名の下で研究される。さらに、パピルス学の学会では、パピルス文献やオストラカ文献に関する発表の他にも、羊皮紙文献についての発表を聞くこともある。パピルス学者(papyrologist)は、あまり名称に囚われず、広い視野を持っているようである。
古代エジプト、ヘレニズム期エジプト、ローマ期エジプト、ビザンツ期エジプト、イスラーム期エジプトの社会、言語、文化、経済、政治、音楽など様々な側面を知ることができる資料としてパピルス文献は非常によく研究されている。ただし、オークションサイトで高値がつくように、歴史的なパピルス文献は非常に貴重なものであり、また、紙や羊皮紙に比べ脆いため、パピルス資料は非常に厳重な注意を持って保管される。日本でも東海大学の所謂「鈴木コレクション」(http://papyrus.pr.tokai.ac.jp/)が民衆文字エジプト語などの、また京都大学総合博物館の所謂「ピートリー・コレクション」がギリシア語やコプト語のパピルス文献を所持している。これらのパピルス文献は、大抵、ガラスなどに挟まれて、大変厳重に保管されている。この貴重性と脆弱性から、パピルス資料のアクセスは他のものよりも難しくなる傾向がある。これでは研究者にとって不都合なので、ヨーロッパや北米ではパピルス文献をデジタル・アーカイブ化し、研究者が容易に利用できるような環境を整える努力がなされてきた。今回は、それらの中でも、ドイツ語圏のデジタル・アーカイブで特に研究者たちによく利用されるウェブ・サービスを紹介する。
エジプト博物館とパピルス・コレクション(ベルリン)
ベルリンには博物館島を中心に多数の名だたる博物館があるが、そのうちの一つの新博物館(Neues Musem)は、ネフェルティティの胸像やウェストカー・パピルスなどで有名な古代エジプトのコレクションを展示している。しかし、この新博物館はいわば容れ物であり、この古代エジプト・コレクションおよびパピルス・コレクションの保管・展示を行なっているのは、「エジプト博物館とパピルス・コレクション」(Ägyptisches Museum und Papyrussammlung)という機関である。この機関は、ウェストカー・パピルスや『マリアによる福音書』で有名なベルリン・コーデックスなど、世界でも有数の貴重なパピルス文献を保管している。この機関のポータルである BerlPal(http://berlpap.smb.museum/)では、パピルス文献の高精細写真、そして翻刻をみることが可能である。パピルス文献の高精細写真は DFG Viewer でさらに容易にズームイン・ズームアウトができ、ダウンロードボタンを押すことで、高精細写真自体をダウンロードすることが可能である。翻刻はパピルス文献の翻刻のウェブ・データベースである Papyri.info(http://papyri.info/)に置かれた The Duke Databank of Documentary Papyri のアノテーション付き TEI XML データを表示している。このデータは TEI 準拠の XML の中でも、碑文学、パピルス学に適した EpiDoc を用いている。この翻刻のライセンスは CC BY である。また、文献のメタデータは、西洋古典およびエジプト学の文献のデジタル・カタログである Trismegistos(https://www.trismegistos.org/)から取られている。
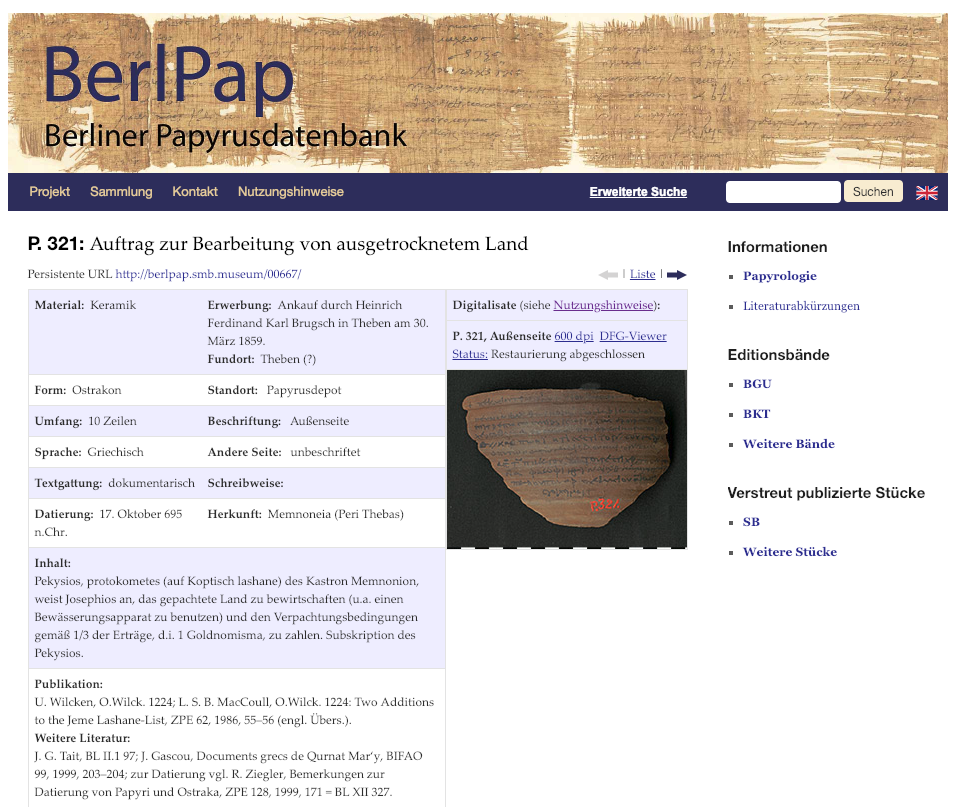
ハイデルベルク大学図書館パピルス・コレクション
ループレヒト・カール大学ハイデルベルク(Ruprecht-Karls-Universität Heidelberg)、通称ハイデルベルク大学は、ドイツ最古の大学として有名であり、その歴史は14世紀に始まる。この大学の図書館は、ギリシア語、コプト語のパピルスのコレクションでも有名であり、そのコプト語コレクションの高精細写真を数多く公開している(https://www.ub.uni-heidelberg.de/helios/digi/hd_papyrus.html)。画像は高精細であり、PDF と JPEG で保存できる。ライセンスは Attribution-ShareAlike 3.0 Unported (CC BY-SA 3.0)であり、適切な方法で典拠を示せば印刷物や論文など、様々な分野において利用することが可能である。また、Papyri.info および Trismegistos とリンクされており、リンクをクリックすることで、翻刻やメタデータを見ることができる。
オーストリア国立図書館パピルス・コレクション
オーストリア国立図書館(Österreichische Nationalbibliothek; https://www.onb.ac.at/)は、そのパピルス・コレクションでも有名で、パピルス学部門がある。そのウェブサイトでもパピルスを検索し、高精細画像を手に入れることができるが、検索に際しては一般図書も入っているデータベースから検索することになり、非常に検索しづらい。所蔵番号をあらかじめ用意しておき、それを検索するのが最も早く目当てのパピルス文献に辿り着ける方法かもしれない。特定のパピルスの所蔵番号を検索すると、次のようなページに辿り着く。
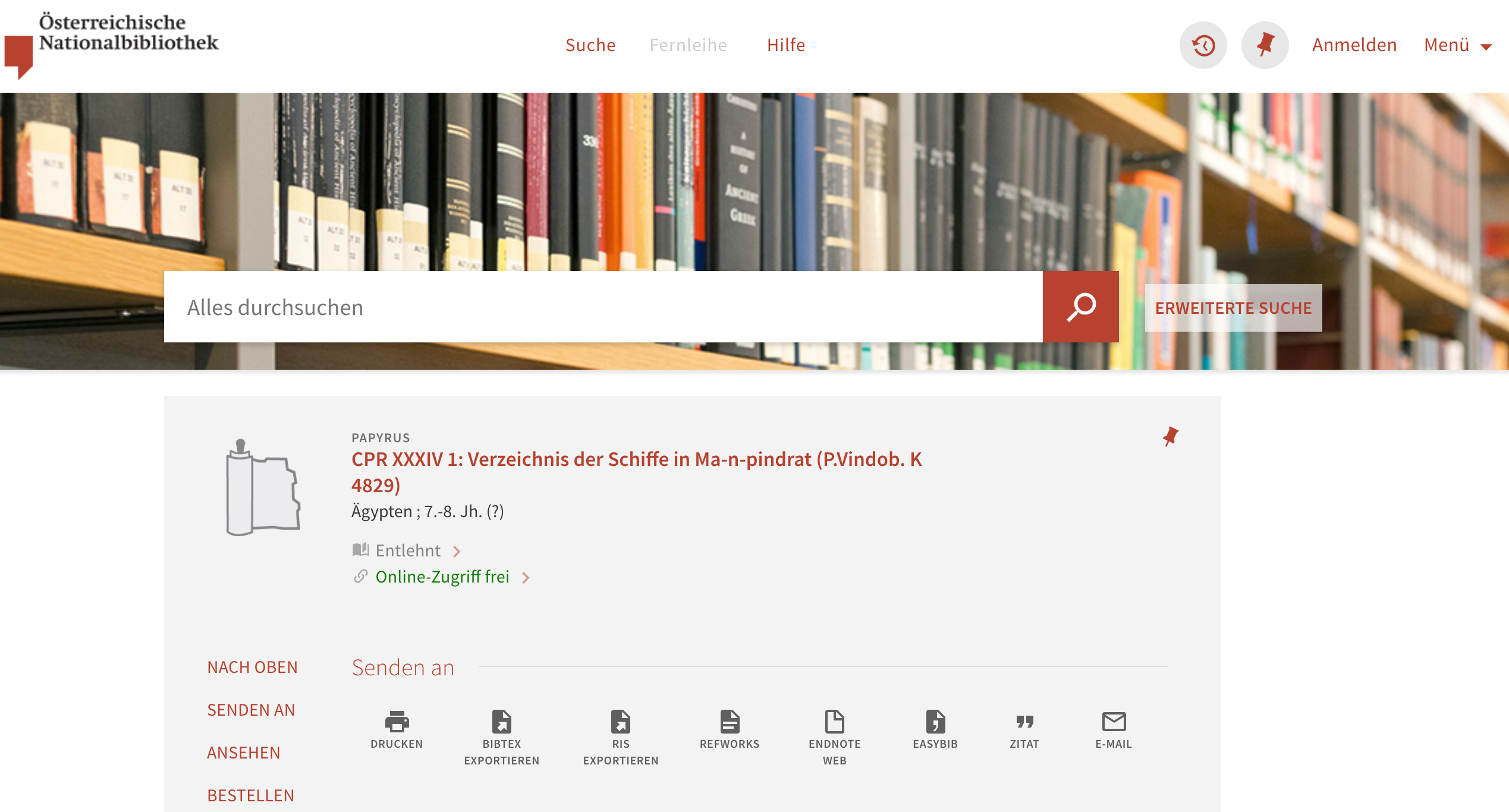
ここでは、Ansehen の項目にある Digitales Objekt をクリックすると高精細画像が手に入る。パピルスの書かれた時代と出土地の情報はあるが、このサイトでは「エジプト博物館とパピルス・コレクション」(ベルリン)やハイデルベルク大学のパピルス・コレクションのサイトのような翻刻や詳しいメタデータは提供されていない。P.Vindob. で検索すると、多くのパピルスがヒットするようである。写真のライセンスなどの情報は、アイテムのページには書かれていないようである。
次回は数々のパピルス文献デジタル・アーカイブによって利用されている翻刻ポータルである Papyri.info とパピルス文献を含むギリシア語、ラテン語、コプト語を含むエジプト語の文献のメタデータの膨大なカタログである Trismegistos について説明する。
- コメントを投稿するにはログインしてください