人文情報学月報第115号【後編】
ISSN2189-1621 / 2011年8月27日創刊
目次
【前編】
- 《巻頭言》「デジタル・シフトとデジタル日本研究の未来」
:Yale University - 《連載》「Digital Japanese Studies寸見」第71回
「DH Awards2020開催」
:北海学園大学人文学部
【後編】
- 《連載》「欧州・中東デジタル・ヒューマニティーズ動向」第32回
「人文学のための深層学習・多層人工ニューラルネットワークを用いた光学文字認識(OCR):kraken を中心に」
:関西大学アジア・オープン・リサーチセンター「KU-ORCAS」 - 人文情報学イベント関連カレンダー
- イベントレポート「ワークショップ「古代文献の言語分析から読み解く社会背景のダイナミズム」」
:東京大学大学院人文社会系研究科 - 編集後記
《連載》「欧州・中東デジタル・ヒューマニティーズ動向」第32回
「人文学のための深層学習・多層人工ニューラルネットワークを用いた光学文字認識(OCR):kraken を中心に」
最近、アラビア文字の機械学習 OCR に興味を持ち、kraken、OCRopus や Calamari など、深層学習・多層人工ニューラルネットワークを用いたものをアラビア文字などで色々試してみた。OCRopus の Python 版である OCRopy[1]に関しては、2015年10月から、筆者は KELLIA プロジェクト[2]でコンピュータ科学者2人[3]とコプト語文献への適用を共同研究し、2017年には、文字文化遺産のデジタル化に関する学会である DATeCH で[4]、そしてモントリオールでの DH2017で発表し、その後、Digital Scholarships in the Humanities に論文が掲載された[5]。この論文では、ニューラルネットワークモデルを用いた OCRopus と、それを用いていない当時のバージョンの Tesseract[6]を比べ、OCRopus が特にコプト語の豊富なダイアクリティカルマークによく対応できることが示された。その後、筆者は ocrocis[7]を試し、90%後半の高い精度を記録したほか、共同研究をしたベルリン・フンボルト大学のエリーゼ=ゾフィア・リンケ(Eliese-Sophia Lincke)は、Tensorflow を用いた Calamari[8]を用いて同様の非常に高い精度のコプト文字 OCR をトレーニングさせた[9]。なお、Tesseract も、2018年10月にリリースされた ver. 4.0から深層学習モデルを用いている[10]。
今回は、特に、近年フランスの eScriptorium[11]という、Transkribus[12]の代替となるような[13]手書きテクスト認識(HTR)の大規模プロジェクトでも使用されている kraken[14]を中心に解説する。kraken はライプチヒ大学のコンピュータ科学者であるベンヤミン・キースリング(Benjamin Kiessling)が、アラビア文字のために OCRopus を改良したのが始まりである。OCRopus は西洋諸言語のように左から右に書く文字順にしか対応できていなかったが、kraken は、右から左、現在は上から下への書き順に対応している。さらに、Transkribus など HTR にも接近している高性能な行分割機能(line segmentation)を実装している。kraken は様々な言語・文字で精度の高い OCR 結果を誇っている。それは、キースリングの DH2017ユトレヒト大会での論文[15]で見ることができる。そこでは、活版印刷物では、アラビア語の文字認識の精度が平均値99.5%・最大99.6%(標準偏差0.05)、ペルシア語・平均値98.3%・最大98.7%(標準偏差0.33)、古典シリア語・平均値98.7%・最大99.2%(標準偏差0.38)、歴史的アクセント表記のギリシア語・平均値99.2%・最大99.6%(標準偏差0.26)、ラテン語・平均値98.8%・99.3%(標準偏差0.09)、ラテン語インキュナブラ[16]・平均値99.0%・最大99.2%(標準偏差0.11)、フラクトゥーア・平均値99.0%・最大99.3%(標準偏差0.31)、キリル文字文献・平均値99.3%・最大99.6%(標準偏差0.15)、手書き写本では、ヘブライ語で文字認識の精度の平均値が96.9%、中世ラテン語で平均値98.2%という非常に高い文字認識の精度を記録したことが発表されている。
もちろんこれは、その言語の出版物の特定のフォントを機械学習させた結果であり、トレーニングなしでやった結果ではない。アラビア語では OpenITI[17]や KITAB[18]プロジェクトで作成された様々なフォントのためのモデル[19]があり、もしフォントが同じものがあれば、それらを使えるが、そうでなければ、新しく kraken をトレーニングさせる必要がある。今回は、kraken のトレーニングの初期段階である、ground truth 入力画面作成の際の行認識について気づいた点を報告する。
筆者は3年前にすでに kraken を試したことがあるが、当時は Linux で動かすことが推奨されていたため、Linux ディストロの1つである Debian 上で kraken を動かした。しかし、今回、Anaconda を用いて Mac 上でも動かす方法があることがわかった。今回筆者が使ったコンピュータは M1チップ(Apple Silicon)搭載の MacBook Pro(late 2020モデル)である。まず、過去に Homebrew を使ってインストールした wget[20]をターミナル上で用いて、kraken をインストールした[21]。起動時は Anaconda を使用して、ターミナル上で conda activate kraken のコマンドを用いて、kraken を起動させた。
今回、Mac 上で様々な文献で ground truth 入力画面を生成して、OCRopus よりも強化されたとされる kraken の行認識機能を試してみた。ここで、機械学習 OCR の基本用語である ground truth について説明する。ground truth とは、機械学習 OCR エンジンに学習させるいわばお手本の文字を含んだ画像とその文字の翻刻である。機械学習 OCR エンジンは、手本の画像にある文字とその文字を翻刻した Unicode 文字の一致するパターンを学習していくことで、その文字体系の OCR モデルを作成する。この課程をトレーニングと呼ぶ。OCR モデルを作成する最初の一歩は、まず、ground truth を作ることであるが、OCRopus や kraken では、html 形式の専門の ground truth 入力ページが作成される。そこでは、画像内のテクストのそれぞれの行ごとにボックスが用意され、そのボックスに翻刻を Unicode で書いていくことが求められる。
まず、アラビア文字のタイプセットで印刷された書籍のページの画像では、行は正しく認識されていた(図1)。
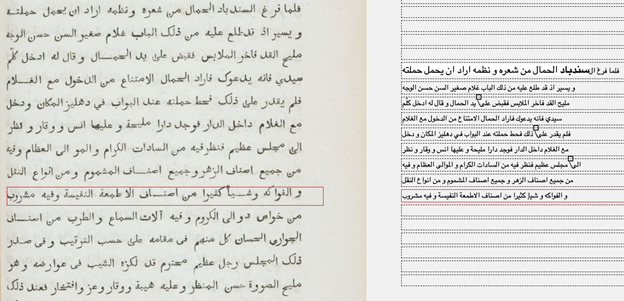
次に、コプト語の手書き写本である Papyrus Bodmer 6の2ページ見開きでは、一行目が2ページに渡って誤って認識されているが、それ以外は、ほぼ完璧な行認識で、ページの区別も認識されていた。次に、縦書きの文字であるモンゴル文字文献も試してみた。縦書きで、行が左から右に流れる場合、
- ketos transcribe -d vertical-lr -o output.html [画像ファイル名]
というコマンドを使って、ground truth 入力画面を作成しなければならない。結果は芳しくなく、正しい行認識ができていなかった(図2)。モンゴル文字の向きを変え、横書きとして認識させても行認識がうまくいかなかったので、行の方向の問題ではないかもしれない。

OCR モデル作成において最も重要なトレーニング、そしてそのモデルの精度を測るために重要となる新規のテクスト画像の認識と精度の評価、および、TEI XML での出力などの重要機能については、今回は紙面が足りなかったため、次回に報告したい。
$ wget https://raw.githubusercontent.com/mittagessen/kraken/master/environment…
$ conda env create -f environment.yml
人文情報学イベント関連カレンダー
【2021年3月】
-
2021-03-05 (Fri)
東洋学へのコンピュータ利用 第33回研究セミナー於・京都大学人文科学研究所本館1F ガラス張りセミナー室 -
2021-03-05 (Fri)
【NINJAL ユニット】国立国語研究所共同研究プロジェクト「大規模日常会話コーパスに基づく話し言葉の多角的研究」主催 全文検索システム『ひまわり』講習会於・オンラインによる開催http://www.tufs.ac.jp/research/js/event/2021/02/21020501.html
-
2021-03-06 (Sat)
JADS 第102回研究会・新型コロナウイルス関連資料の収集と展示於・オンラインによる開催 -
2021-03-08 (Mon)
浄土宗総合研究所 公開講座「仏教の智慧を開く:浄土宗大本山増上寺所蔵元版大蔵経デジタルアーカイブ化」於・オンラインによる開催https://jsri.jodo.or.jp/%E8%AC%9B%E5%BA%A7%E6%A1%88%E5%86%85/%E5%85%AC%… -
2021-03-10 (Wed)
日本デジタル・ヒューマニティーズ学会(JADH) SIGLITH 第1回研究会「若手研究発表セッション」於・オンラインによる開催 -
2021-03-13 (Sat)
国立国語研究所 「通時コーパス」シンポジウム2021於・オンラインによる開催https://www.ninjal.ac.jp/event/specialists/project-meeting/m-2020/20210313/
-
2021-03-13 (Sat)
東京大学附属図書館 U-PARL 【協働型アジア研究オンラインセミナー】3次元データでひらく“人文学”の世界於・オンラインによる開催http://u-parl.lib.u-tokyo.ac.jp/archives/japanese/seminar20210313
-
2021-03-15 (Mon)
東京大学附属図書館 U-PARL シンポジウム:むすび、ひらくアジア4「サブジェクト・ライブラリアンの将来像」於・オンラインによる開催 -
2021-03-20 (Sat)
シンポジウム 「字体資料共有の現在と未来」於・オンラインによる開催https://www.ninjal.ac.jp/event/specialists/project-meeting/m-2020/20210320/
Digital Humanities Events カレンダー共同編集人
イベントレポート「ワークショップ「古代文献の言語分析から読み解く社会背景のダイナミズム」」
京都大学 SPIRITS プロジェクト「データ駆動型科学が解き明かす古代インド文献の時空間的特徴」(天野恭子、夏川浩明、OliverHellwig、京極祐希)主催の、第1回ワークショップ「古代文献の言語分析から読み解く社会背景のダイナミズム」が2021年2月12日にオンラインで開催された。このプロジェクトは、データサイエンスによって時間的/空間的特徴をもとに大規模かつ詳細に文献を分析することで、紀元前2000年紀中頃から始まりおよそ1000年の間に成立したと言われているヴェーダ文献(群)の成立過程、そしてその背景にある社会発展の様相への理解をすすめることを目指している。本レポートは、ヴェーダ研究およびそれへの情報学の応用に携わっている筆者の視点から、いくつかの発表を取り上げる。
本ワークショップは全体として2部で構成された。第1部は、
- 天野恭子 “Problems in the Formation of the Vedas, Ancient Indian Religious Texts”「古代インド宗教文献ヴェーダの成立を巡る諸問題」
- 夏川浩明 “The Possibility of Information Visualization and Data Analysis for Ancient IndianLiterature”「古代インド文献を対象とした情報可視化やデータ分析の可能性」
- 天野恭子 “Relationship among Vedic Schools Deciphered by the Visualization of Mantra Collocation”「マントラ共起関係の可視化から読み解くヴェーダ学派間の関係性」
- 濵地瞬 “Citation Prediction Using Academic Paper Data and Application for Surveys”「学術論文データを用いた引用数予測とサーベイへの活用」
- 京極祐希 “Measuring the Semantic Similarity between the Chapters of Taittirīya Saṃhitā Using a Vector Space Model”「ベクトル空間モデルによる『タイッティリーヤ・サンヒター』の章間類似度比較」
- Oliver Hellwig, “Dating Vedic Texts with Computational Models: Algorithmic Considerations and Data Selection”
- 師茂樹 “morogram: Background, History, and Purpose of a Tool for East Asian Text Analysis”「morogram: 東アジア文献分析ツールの開発の経緯と目的」
まず初めに、ヴェーダ文献に関する基礎知識、すなわち文献の構造や内容、テクストの伝承を担う学派/家系が簡潔に紹介された。特に、テクストの編纂過程に関して、3(or 4)ヴェーダ―リグ・ヴェーダ、サーマ・ヴェーダ、ヤジュル・ヴェーダ(、アタルヴァ・ヴェーダ)―の内の1つヤジュル・ヴェーダ(YV)に焦点が当てられ、3学派の文献の構造が説明された。各文献とも、時の流れに従って内容が追加されていった事情ゆえに、文献間(〜学派間)の関係が非常に複雑であることが理解できる。また伝統的に口頭によって伝承されてきたために絶対年代の特定が困難である。言語分析と可視化・視覚的分析とを用いることで、こうした複雑な関係を解明する手立てを示すのが、続く発表であった。
基礎となるのは、マントラ(=讃歌、祝詞)の共起関係だ。Bloomfield の A Vedic Concordance (Cambridge: Harvard University Press, 1906)、Franceschini によるその増強版An Updated Vedic Concordance (Cambridge: Harvard University Press, 2007) をもとに、各ヴェーダ文献の章/節の関係がデータベース化された。それを視覚化したツールは、試験段階ではあるものの、ユーザー(参加者)が任意に2つの文献を選んで、マントラの共起関係を視ることができるという、たいへん実用的なものである。左右2軸で、共起関係にある章/節が連結されたグラフは、その関係がひと目でわかるほどのものであり、視覚化の有用性が確かに感じられた(図1)。しかしながら、これは2文献間のみの関係を示すため、例えば先述の黒YV の3学派を比較するのは困難になる。そこで導入されるのが Hypergraph である。Hypergraphとは、エッジ(辺)が1つ以上のノード(頂点)と連結できるグラフのことである。ここの文脈に沿って言うならば、マントラ(=エッジ)がいくつかの文献の章/節(=ノード)を連結するグラフが作られる。ノードとエッジを効果的に視覚化するPAOH Vis を応用することで複数文献間の関係がわかりやすく示されていた(図2、3)。YVによって例示されていたものの、他のヴェーダ文献でも同じような分析が行えることが想像でき、参加者もこのような分析手法への期待がより高まったことと思われる。
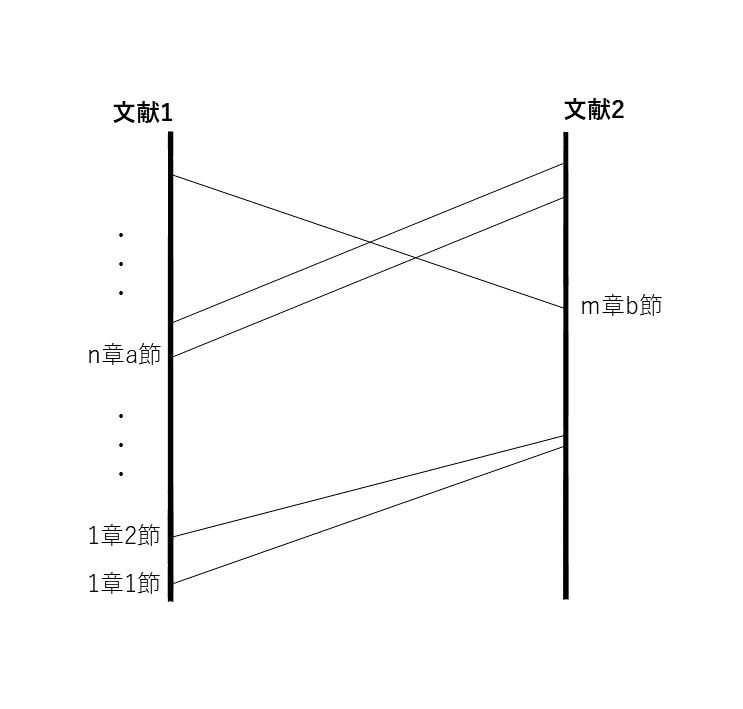
図1 マントラ共起関係
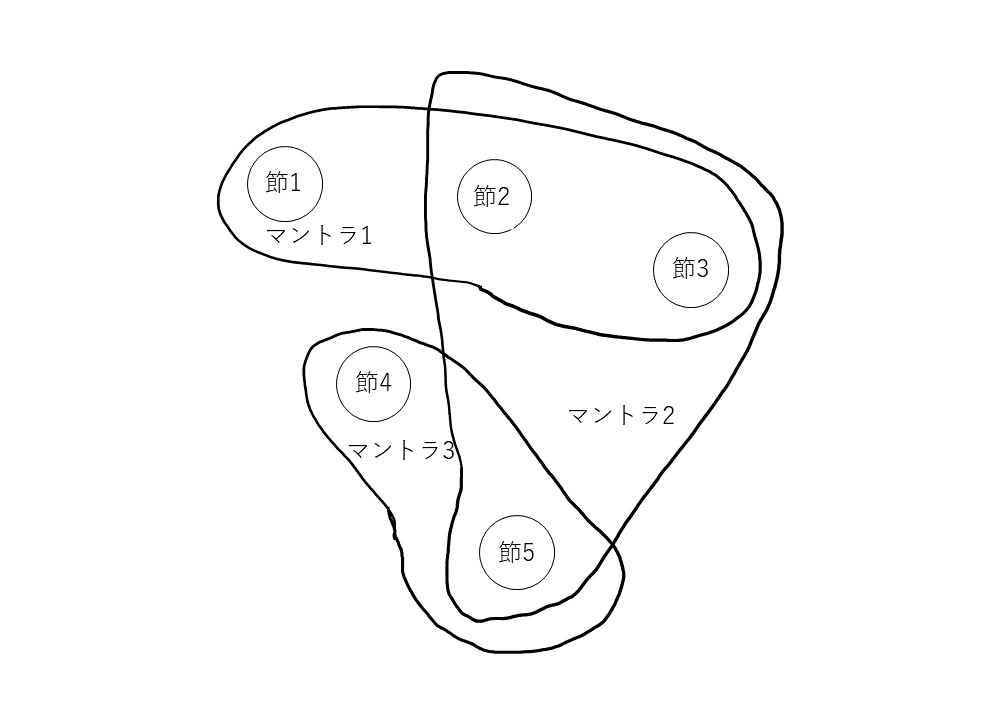
図2 Hypergraph
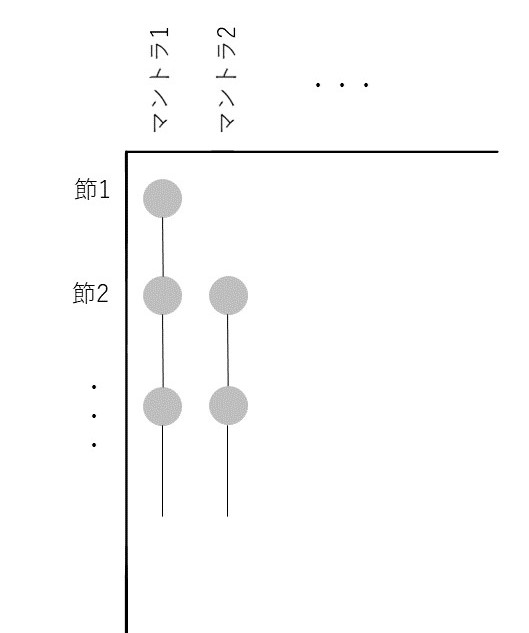
図3 PAOH Vis 応用
さて、夏川氏の提示した視覚化されたデータをもとに、そこから読み取れることを天野氏が続いて発表した。YVを中心として他のヴェーダ(リグ・ヴェーダ(RV)、アタルヴァ・ヴェーダ(AV))との関係が、グラフを活用して細かに説明された。ここでは大まかに記すことにするが、図1のようなグラフによって視覚化された各2文献間のマントラ共起関係は、YVの4文献(=マイトラーヤニー・サンヒター(MS)、カータカ・サンヒター(KS)、タイッティリーヤ・サンヒター(TS)、ヴァージャサネーイン・サンヒター(VS))の編纂方針を知るに有効だという。過去の研究で既に示されているKS と TS との共通性は、視覚的分析によって得られた編集方針の同一性より確固たるものとなった。また、編集(の終了時点)の時系列は MS, KS, TSの順であることや、その時代における RV, AV の広まり具合を推察することができるとのことだった。筆者個人のことではあるが、筆者が研究している RVをとっても巻ごとや節ごとに編集方針が定まっており、それを頼りに時系列は考察されてきた。このような作業が、視覚化を活かした分析によって大規模かつ詳細に行われ、より説明的になりそして新たに知見を広めてくれる可能性を感じた。
個人的な関心が最も高かったのは第2部の京極氏の発表だった。というのも文献は異なるものの、筆者自身同じくヴェーダ文献の1文献に対して同一の手法を用いて分析を行った経験があるからであり、たいへん参考になる内容だった。では肝心の内容について記すと、YV の内の1学派の文献タイッティリーヤ・サンヒター(TS)の各章の類似度を、章中の語の意味をもとにして比較するというものである。Word2Vecという機械学習モデルは、語の意味を表現する単語ベクトルを、その語の周辺語から学習することで作成する。この単語ベクトルを足し合わせることで文や章単位での意味を表現するベクトルを新たに生み出せる。しかし、これを適用するにあたって、加工を施していないサンスクリットの文章をそのまま扱うわけにはいかず、機能語の除去や屈折した語を辞書形へと修正することなどの必要性が注意された。TSほか各ヴェーダ文献の、形態情報が付されたデータベースは既に公開されていることから、分析の際にはそれが活用されていた。章間類似度の分析結果は、ごく単純な感想を述べると、なるほど特異な章がよく際立って図示されていたのが印象的だった。結果もさることながら、分析の準備にかかる作業、分析のもととなる形態情報付与のデータベース作成(次の発表のHellwig 氏による)は、たいへん重要なものであると感じた。こうした材料のおかげで言語分析の裾野が広がることが期待される。
最後に Hellwig氏の発表を紹介するが、筆者の知識不足ゆえに技術的な点の紹介が十分にできないことを先に断っておく。用語を取り出して述べるならば、ニューラルネットワークを用いた、マハーバーラタ(古典サンスクリット文献)の編纂年代、ベイズ混合モデルを用いた、RV、AV・シャウナカ(ヴェーダ文献)の編纂年代の推定および既存研究の結果との比較評価が行われた。Summaryにて最後に挙げられた注意事項あるいは他の研究との差異の各点は教訓になるものだった。十分量のテクストデータを選ぶこと、結果の比較には統計的手法を用いること、多変量のデータを使ってさまざまな手法を適用することなど、基本的なことだからこそ常に注意を払わねばならない。ヴェーダ文献学と情報学の融合における技術的な分析の可能性のみならず、研究手法の基礎を改めて教示してくれたことは、特に筆者のような若手にとって重要だった。
最後に本ワークショップそのものの所感を記しておく。情報学で発展してきた研究手法や技術を活用した、ヴェーダ文献を対象とした研究は稀である。それゆえに、これほどの規模のワークショップが開催されたこと自体たいへんな意義があると感じた。情報学と融合したヴェーダ文献学の発展に大いに期待するとともに、私自身もその隆盛に寄与する活動をしたいと強く思った。
◆編集後記
2月25日付けで、TEI協会が策定・公開している人文学資料のデジタル構造化の国際デファクト標準である TEI ガイドラインの version 4.2.0がリリースされ、日本語のルビが導入されました(リリースノート)。欧米の人文学研究者コミュニティにより米国で始まって以来、34年目にしてようやくの画期的な出来事です。このことは、日本の人文学者にとって有益というだけでなく、漢字文化圏という巨大なテキスト群を抱える地域の周縁においてそれを読解するために生み出されたローカルルールが、人文学の研究手法に関する国際的なコミュニティにおいて正式に受容されたということでもあります。換言すれば、欧米外の地域における多様なテキスト文化のローカルな慣習にも同等の価値を置くという、コミュニティからの正式な表明でもあります。このような状況を作り出すことに日本語文化圏が貢献できたということは、テキストに親しんできた日本語圏の先人達の膨大な積み重ねが結実した結果でもあります。
ちょうど、Paula Curtis さんの巻頭言で DH の近寄りがたさの一例として挙げられている TEI ですが、確かに、入口を見つけるのが少し難しい状況ではありますが、実はそんなに難しいものではありません。2016年に TEI 協会に正式に設立された初の特定言語圏専門分科会である東アジア/日本語分科会では、日本語資料向けガイドラインを作ったり、初心者向け講習会や勉強会なども時々開催したりしています。ご興味がおありのかたは、少しずつでも取り組んでみていただけると、デジタル技術の活用の幅が広がっていくことと思いますので、ぜひご検討してみてください。
(永崎研宣)
- コメントを投稿するにはログインしてください