人文情報学月報第147号【前編】
ISSN 2189-1621 / 2011年08月27日創刊
目次
【前編】
- 《巻頭言》「古辞書研究と DH にまつわる体験からみえたこと」
:京都大学人文科学研究所附属人文情報学創新センター - 《連載》「欧州・中東デジタル・ヒューマニティーズ動向」第64回
「エジプト・エレファンティネ島出土資料の多言語コーパスとデータベース:TEI/XML による文字資料の構造化の一例」
:人間文化研究機構国立国語研究所研究系 - 《連載》「仏教学のためのデジタルツール」第12回
「駒澤大学『禅籍目録 電子版』」
:東京大学大学院人文社会系研究科
【後編】
- 《特別寄稿》「『Digital Scholarly Editing-Theories and Practices』紹介の前置きに代えて」
:早稲田大学大学院文学研究科 - 人文情報学イベント関連カレンダー
- イベントレポート「デジタルの時代におけるテキスト校訂・出版・研究:Joint MEC and TEI conference 2023参加報告」
:東京大学国際高等研究所東京カレッジ - 編集後記
《巻頭言》「古辞書研究と DH にまつわる体験からみえたこと」
筆者は2023年10月14日に羽田空港を後にし、アメリカのイェール大学で2023年10月16日から20日まで開催される IRG (Ideographic Research Group) #61[1]の会議に参加するために向かった。これは、Unicode の対応規格である ISO/IEC 10646において漢字の符号化を検討する IRG の定例会議に、ISO/IEC JTS1/SC2委員会のリエゾンメンバーとして同会議に正式に参加している唯一の学術団体である SAT 大蔵経データベース研究会のメンバーとして参加するとともに、符号化を提案された漢字のレビューの議論に参加するためであった。今回、筆者が IRG 会議に参加するのは5回目となった。コロナの影響で前の4回はオンラインでの参加だったが、今回は初めて対面での参加となった。本稿は、この会議の合間を縫って、これまでの筆者の古辞書研究と DH(デジタル・ヒューマニティーズ)の経験を振り返る機会として執筆するものである。
2011年4月から北海道大学文学部研究生として、筆者は言語情報学講座の研究室に配属されることになった。それまでの人生では、学部時代はコンピュータ情報処理を専攻し、大学を卒業した後、しばらくは民間企業に勤務していた。一方で、人文学、特に漢字研究に魅かれ、京都での一年間の交換留学中に経験した日本語の漢字と中国の簡体字との間の違いに強く関心を持つようになった。そして、この体験によって「異郷有悟」という思いが心に深く残り、北海道大学の日本古辞書研究を専門する国語学者である池田証壽先生の研究室を志望して入学を決意した。
研究生として入学した際の初めの研究計画は簡体字をテーマとするものだった。これは、自分の中で長らく持っていた簡化字と繁体字とのギャップという素朴な問題意識から生まれたものだった。しかし、もし博士課程を目指すのであれば、簡体字の歴史は比較的浅いため、より深く漢字研究を進める方が良いと先生からの提案があり、日本に現存する最古の漢字字書高山寺本『篆隷万象名義』を研究対象とすることになった。
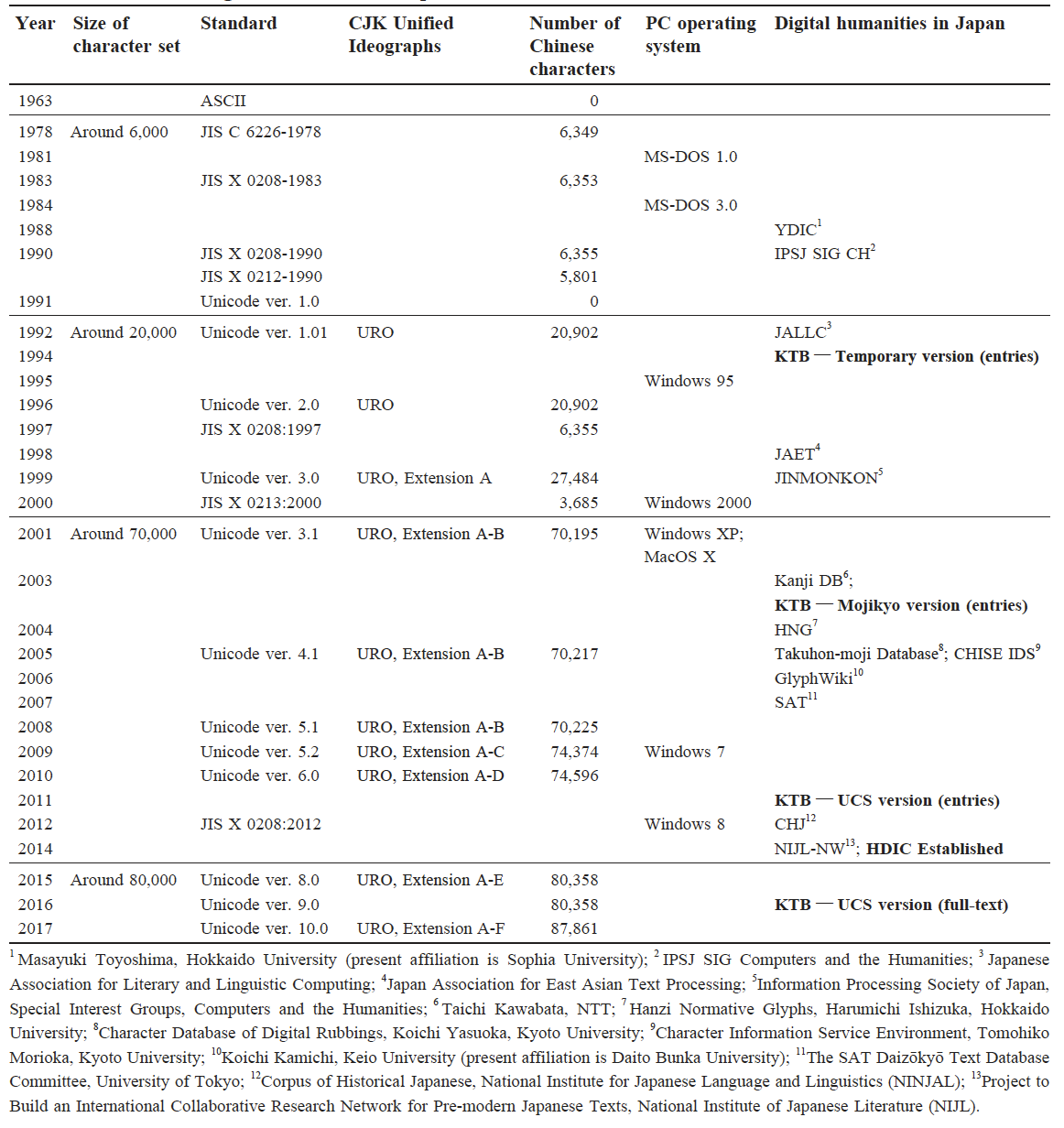
最初に、『篆隷万象名義』の影印テキスト、そして大漢和辞典の番号と漢字の対応するエクセルファイルのリストを渡されて、そこから『篆隷万象名義』の全文テキスト化作業を続けることを提案された。後に知ることとなったが、池田先生はすでに1994年頃から、『篆隷万象名義』のテキスト化の取り組みを始めていた[2]。当時、パソコンの漢字処理環境は初歩的な段階だった。特に古い文献の処理においては漢字不足の問題が際立っていた。しかし、池田先生は将来、漢字処理の課題が克服されるとの確信を持っており、国語学者として、多くの難字を含む古辞書のデジタル化への挑戦を開始した。そして、日本の漢字コード化である JIS 漢字コードの取り組みにも寄与していた。実際に、日本の人文学におけるDHの研究の進展は、大規模漢字符号化集合 Unicode の整備に大きく影響を受けていると考えられる(表1、[3])。
しばらくの間は、このような作業を続けた。はじめのうちは、古文献に触れる経験がない上に、難解な漢字をコンピュータ上に文字コードで表現することも未経験だったため、どのようにしてそれが研究の内容と関連しているのかを把握するのが難しく、挑戦的な日々だった。後になって理解できるようになったが、この感覚は初心者の段階でのものだった。古辞書に関する授業を受講する中で、関連する文献を参照しつつ、『篆隷万象名義』の本文解読やテキスト化作業を少しずつ進めていった。
1994年に、高山寺本篆隷万象名義データベース(Kosanjibon Tenrei Bansho Meigi database, 略称 KTB)の掲出字の電子化を始めた際、Unicode ver. 1.01では20,902字の漢字が扱えた。その時点で、KTB の掲出字テキスト化のテンポラリバージョンが作成され、符号化できなかった部分は69.1%(第一〜四帖、目録部分を含む)であった[2]。しかし、その後の CJK 統合漢字[4] Extension A-B の追加により、Unicode ver. 3.1では扱える漢字の字数は70,195字に増加した。それにもかかわらず、この時点では Unicode がパソコンに実装されるまでにはまだ時間が必要だった。それでも KTB の掲出字テキストは「今昔文字鏡」[5]の支援を受けて、テキスト化がほぼ実現された。筆者がこの作業に関わり始めた2011年には、Unicode ver. 6.0の CJK 統合漢字は既に Extension A-D まで拡張され、Extension A-B の実装も大きく進んできた。同年、KTB の掲出字テキストの UCS バージョン[6]が完成し、2016年には Unicode の収録字数が8万字を超えるなか、ついに KTB の全文テキストが完成し、同年9月に全文テキスト公開が実現した[7]。
このような状況の中で『篆隷万象名義』の全文テキスト化に携わった筆者は、時代の波に乗っていたと言えるだろう。しかし、その当時は、このような大局的な視点を持っていたわけではなく、単に作業と研究に専念していた。表1で総括してみると、Unicode の CJK 統合漢字の収録字数とコンピュータ実装の進化を背景に、日本の DH 関連の多くのプロジェクトが拡大・発展してきたことが伺える。
2016年9月に『篆隷万象名義』の全文プレーンテキストが公開された。この公開された『篆隷万象名義』全文テキストは、図1に示されているように、3つの階層(文字列、単漢字、部品)での検索が可能である[8]。単漢字と部品に関する検索の研究を行っていた。
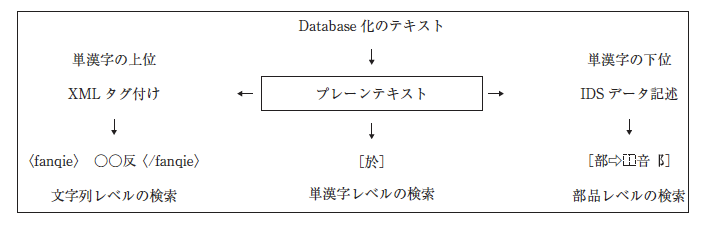
博士課程を終えた後は、日本学術振興会特別研究員(PD)として京都大学人文科学研究所に、その後は、北海道大学文学研究院、関西大学アジア・オープン・リサーチセンター(KU-ORCAS)に所属した。そして、今年の10月1日、京都大学人文科学研究所附属人文情報学創新センターの助教に着任した。今後は引き続き古辞書研究と DH 関連のテーマで研究や業務を進める予定である。具体的には、日本古辞書の翻刻階層モデルの構築についての研究や、人文学のデジタルテクストに対する最新の構造化ガイドラインである TEI P5[9]を基にしたデータの構造化記述の方法に関する研究(図1の左部)を手掛ける。さらに、字形のデータをより詳細に整備する作業も進行中である。
『篆隷万象名義』という研究テーマは、指導教員からの提案を受けて始めたが、古辞書研究を通じて、最先端の DH 研究と触れる機会を得た。さらに、古辞書研究と DH の進展は相互に影響を与え合っている。古辞書研究を深める中、漢字符号化の提案活動にも参加するようになり、漢字の符号化提案レビューや IRG の会議にも参加するようになった。北海道大学文学部の研究生として入学した際、『篆隷万象名義』の文字を大漢和辞典のデータと照らし合わせて符号化する作業を開始したことを思い出すと、感慨深いものがある。
これらの研究や活動は、ある意味、時代の流れや大きな波の中にあった。上記の表1で総括された内容をみると、Unicode の進展と日本の DH の発展との関連性が明らかである。IRG #61に参加したことは、今もなお、その大きな動きや波の中にいると実感させるものがある。時にはその波が激しくなることもあるかもしれないが、ともに研究や活動を進めている仲間たちとともに、その困難を乗り越えることができると信じている。
執筆者プロフィール
《連載》「欧州・中東デジタル・ヒューマニティーズ動向」第64回
「エジプト・エレファンティネ島出土資料の多言語コーパスとデータベース:TEI/XML による文字資料の構造化の一例」
ELEPHANTINE プロジェクト[1]は、エジプト南部の都市アスワンを流れるナイル川の中にあるエレファンティネ島に焦点を当てた野心的な研究プロジェクトであり、この地域における文化史の複雑な織りなしを明らかにすることを目的としている。エレファンティネ島は、エジプトとヌビア地域との境界に位置する、ナイル川に浮かぶ島であることから、古代エジプトにおいて極めて戦略的な重要性を持ち、商業、宗教、政治の各面で重要な役割を果たしていた。この島は、古代エジプトはもちろん、ヌビアの諸王国、古代ギリシア、古代ローマ、ビザンツ、イスラームなど、多くの文明と文化が交錯する場であり、それゆえに異文化間の相互作用や影響を深く理解する上で非常に貴重なケーススタディとなっている。出土資料は、言語を取ってみても、古代エジプト語、コプト語、ギリシア語、アラム語、アラビア語、カリア語、シリア語、フェニキア語、ラテン語 など多言語であり、文字は、ヒエログリフ、ヒエラティック、デモティック、コプト文字、ギリシア文字、アラム文字、アラビア文字、シリア文字、カリア文字、フェニキア文字、ラテン文字など多様である。中には、アラム文字で書かれたエジプト語資料や、デモティックで書かれたアラム語資料など、大変珍しいものも存在する。宗教もエジプト多神教、ヘレニズム的混淆宗教、ユダヤ教、キリスト教、イスラームに関するものなど多様である。この島の複雑な歴史は、現代の多文化主義やグローバリゼーションに関連する課題―たとえば、アイデンティティの複雑性や異文化間の対話といったテーマ―にも有意義な示唆を与えるものである。
たとえば、エレファンティネ島での宗教的な共存や緊張を通して、どのように宗教的アイデンティティが形成され、また影響を与え合うのかを研究することは、現代社会における宗教的対立や共存に対する理解を深める手がかりとなりうる。さらに、この地域が何千年にもわたって多くの文化や宗教が交錯する舞台であったことから、時間軸に沿った変遷とその影響についても詳細な分析が可能となる。このようにエレファンティネ島の歴史を一次資料に基づいて詳細に分析することは、文化や宗教がどのように進化し、互いに影響を与え合ったのかを理解する上で非常に重要な情報を提供することになる。
このエレファンティネ島出土の文献をデジタル化する本プロジェクトは、ヨーロッパ研究評議会(European Research Council、ERC)から1.5百万ユーロの資金を受けて、ベルリン・エジプト博物館・パピルスコレクションのプロジェクトとして、同博物館の Verena Lepper 教授の指揮のもと実施された。この助成金によって、プロジェクトは2015年から2022年までの7年間にわたり、一連の広範な調査と研究を行った。この期間中に行われた活動は、考古学的発掘から言語学、人類学、歴史学など、多岐にわたる研究フィールドを統合するという壮大なスケールを持っている。
研究者チームもまた、その多様性と専門性が特徴である。エジプト学者、西洋古典学者、コプト学者、イスラーム学者、考古学者、言語学者、歴史学者など、各専門分野からのトップレベルの研究者が集まり、互いの知識を結集して研究を推進した。このように、このプロジェクトでは、多角的なアプローチが採用されているのが特徴である。単一の学術分野や手法に依存するのではなく、文献研究、考古学的調査、そしてデジタルヒューマニティーズという三つの異なる手法が組み合わされている。この総合的なアプローチにより、エレファンティネ島の複雑な歴史と文化を多角的に解明する研究に貴重な資料をもたらすことが期待されている。文献研究においては、本データベースを用いることによって、当時の社会構造や宗教、文化などを解析することができる。考古学的調査では、エレファンティネ島自体や周辺地域での発掘調査に資する。本プロジェクトのデータはデジタル化されているため、それによってデータ管理や解析が大幅に効率化される。さらに、地名・人名のマッピングによって、それらの地名・人名が地理的または社会的なコンテクストにどのように関連しているのかを視覚的に示すことができる。そして、時系列分析を通じて、エレファンティネ島の歴史や文化がどのように時間とともに変遷してきたのかを明らかにできる。さらに、文献研究、考古学的調査、デジタルヒューマニティーズの三つの研究方法を融合させることで、多層的かつ総合的な解析が可能となる。
次に、本プロジェクトのデータ収集の方法論について紹介する。本プロジェクトのデータ収集フェーズは非常に重要なステップであると推察される。様々な種類の言語・文字で書かれた資料・史料のデジタル化作業は非常に繊細なプロセスであり、メタデータ収集とテキストの翻刻において高度な技術と専門知識が要求される。メタデータの登録は FileMaker Pro[2]上で、各言語・時代・文化の専門家からなるチームで行われた。現在、その七年間に収集されたデータがポータルサイト「Texts and Scripts from Elephantine in Egypt」上[3]で公開されている。 現在、本データベースに登録されているオブジェクトの個数は10,745である。テキストおよび画像が提供されているオブジェクトもあれば、片方だけのもの、両方とも欠けているオブジェクトも存在する。
テキストは、原文の翻刻、もしくは、デモティックなど Unicode にない文字の場合はラテン文字の転写が、英語による翻訳とともに提供されている。テキストにおいて地名や人名はタグ付けられており、それぞれ別々に検索することが可能である。さらに、これらのテキストデータは Oxygen XML Editor[4]での編集により、デジタルヒューマニティーズのテキスト構造化で世界標準となっている Text Encoding Initiative(TEI)のガイドラインに準拠した XML(TEI/XML)のデジタルエディションとして整備されている。この TEI の XML 標準によるエンコード手法は、テキストデータをより構造化し、多角的な分析やインタラクティブな可視化に使えるようにするための重要な工程である。これにより、全世界の研究者がインターネットを通じてアクセスし、テキストデータを二次利用・再利用して、新たなデータベースを構築したり、既存のツールと組み合わせて様々な分析を行える。このことにより、持続可能な国際的な共同研究や知見の共有が促進される。
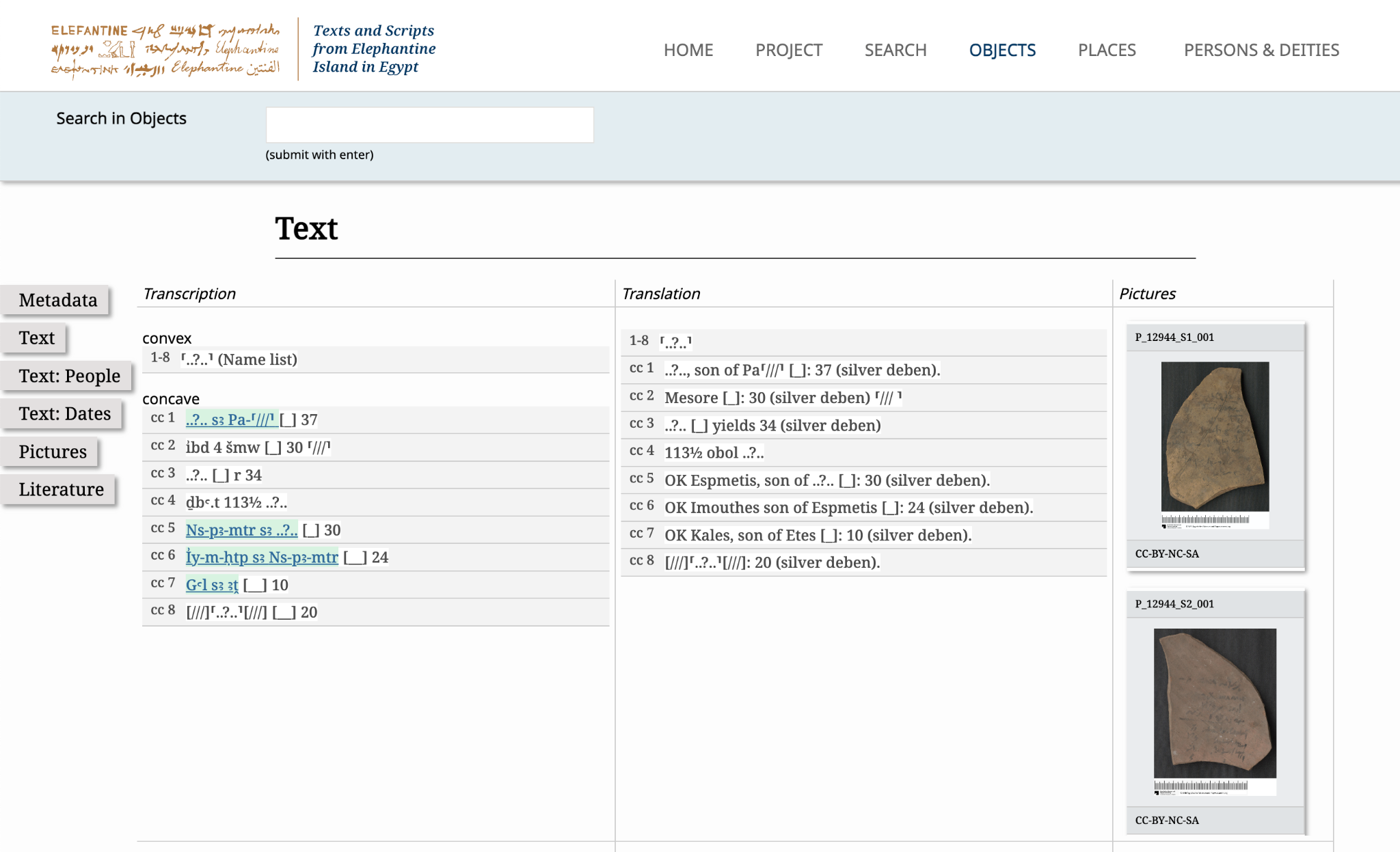
図1は、陶片(オストラコン)の両面にインクを使ってデモティックで書かれたエジプト語の資料である。デモティックのラテン文字転写が左に、その翻訳が右に書かれており、さらに右に資料の写真がある。
この図1の陶片に書かれたテキストのようにエレファンティネ島出土の文書や歴史的テキストの多くは、破片として残っている場合が多い。しかし、本プロジェクトのデータセットを活用すれば、これらの破片をデジタル上で精密に再構築することが容易になる。また、通常、メタデータ、テキスト、写真、その他データセットは CC BY-NC-SA ライセンス[6]で公開されており、容易に二次利用が可能であることは、非常に評価できる。
陶片を含むこれらの資料は、エレファンティネ島という一つの小島から出土したものの、130以上の施設(博物館、図書館、研究機関など)に所蔵されている。それらのメタデータと、数多くの写真とテキストを世界に向けて公開している本プロジェクトは、エレファンティネ島の歴史を調べる学者や学生にとって非常に有益であると言えるだろう。
《連載》「仏教学のためのデジタルツール」第12回
仏教学は世界的に広く研究されており各地に研究拠点がありそれぞれに様々なデジタル研究プロジェクトを展開しています。本連載では、そのようななかでも、実際に研究や教育に役立てられるツールに焦点をあて、それをどのように役立てているか、若手を含む様々な立場の研究者に現場から報告していただきます。仏教学には縁が薄い読者の皆様におかれましても、デジタルツールの多様性やその有用性の在り方といった観点からご高覧いただけますと幸いです。
「駒澤大学『禅籍目録 電子版』」
今回は、禅籍研究に有用なデータベースとして、駒澤大学が公開している『禅籍目録 電子版』(https://zenseki.komazawa-u.ac.jp)を紹介する。
データベースの概要を述べる前に、そもそも『禅籍目録』とはいかなる目録かについて述べておきたい。
『禅籍目録』自体の編纂の歴史については、データベース内の「『禅籍目録 電子版』公開にあたって」(https://zenseki.komazawa-u.ac.jp/first.php)および「『禅籍目録』編纂の歴史」(https://zenseki.komazawa-u.ac.jp/history.php)に簡潔にまとめられている。また、最初の『禅籍目録』の編纂経緯にかんする詳しい論文として、奥野光賢「駒澤大学図書館と『禅籍目録』」(『駒澤大学仏教学部論集』第44号、pp.141–165、2013)がある。
これらによれば、『禅籍目録』(駒澤大学図書館、1928年2月)が初めて刊行されたのは、関東大震災で壊滅的打撃を受けた駒澤大学図書館の、新築落成に合わせてのことであった。同大学図書館に所蔵禅籍が少なく、かつ、補充しようにも基準となる目録が存在しなかった当時の状況を踏まえ、「禅宗研究に資するものは能ふ限り之を渉猟編録し、当該書誌の蒐集に便せしめんと」(『禅籍目録』「緒言」)したのが、当初の目録編纂の目的であったという。
その後、最初の『禅籍目録』刊行にも尽力した小川霊道(1890–1965、第6代駒澤大学図書館長)により、『禅籍目録』の修訂版として刊行されたのが『新纂禅籍目録』(駒澤大学図書館、1962年)である。今日一般に禅宗研究者に用いられているのは、こちらの「新纂」の目録であり、旧版に対して編纂の方法(文献の配列の仕方など)も改められている。
『新纂禅籍目録』は第一編と第二編より成り、第一編には江戸期までの禅籍が五十音順に、第二編には明治以降の文献が内容別に、収録されている。また凡例に示されるとおり、明治以後の著作物のうち、内容が明治以前の文献に拠っているもの(注釈書や伝記の類い)についても、第一編に収められている。収録された各書については適宜、①題号、②巻冊、③著編者名、④刊写の年時及び刊筆者、⑤所蔵者、⑥出拠、⑦註記等が記される。このため当該目録は、(先述のとおり)もともとは図書館資料の充実のために作られた資料であったが、禅籍の写本・刊本の種類やその所在を調べるための工具書として、ながらく禅宗研究に裨益してきた。なお『新纂禅籍目録』の刊行から2年後には、『新纂禅籍目録』追補篇(駒澤大学図書館、1964年)が刊行され、補遺・修正がおこなわれている。
さて、この『新纂禅籍目録』のうち、第一編(江戸期までの禅籍と、江戸期までに成立した禅籍と内容的に関連する明治以降成立の文献)および追補篇が電子データベース化されたのが、『禅籍目録 電子版』である。『禅籍目録 電子版』では、キーワード検索システムが用意されるとともに、『新纂禅籍目録』の画像が掲載されている(『新纂禅籍目録』内での①題号~⑦註記の項目の一部の名称が改められるなど、データベースでは、よりわかりやすい形に整理されている)。
データベースの使い方は簡単であり、書名や著者名といったキーワードを入れて検索することで、『新纂禅籍目録』内の情報を容易に入手することができる。また各典籍の「画像参照」項から、『新纂禅籍目録』の該当ページを参照することも可能である。古典籍の書誌・所在を調査するにあたっては、国書データベース(https://kokusho.nijl.ac.jp/; 人文情報学月報第144号《連載》「仏教学のためのデジタルツール」第9回も参照されたい)の使用も想定されるが、禅籍の書誌・所在や関連する情報を調べるにあたっては、国書データベースとあわせて、『禅籍目録 電子版』でも一度検索してみるとよいであろう。国書データベースが依拠する『国書総目録』記載の書誌・所在情報がそもそも『新纂禅籍目録』の転載で、かつ『新纂禅籍目録』の情報すべてが転載されているわけではないという事例も屡々見られるし、あるいは、国書データベースには収録されない、(明治より前に成立した禅籍と関連する)明治期以降成立の文献が『新纂禅籍目録』に立項されている場合もある。
なおデータベース利用に際して留意すべきこととして、『新纂禅籍目録』そのものに古い情報も含まれるため、データベースの情報も現在の状況を正確に反映していない場合がままある、という点を挙げることができる。この点、データベース利用の注意事項(「禅籍目録 凡例」(https://zenseki.komazawa-u.ac.jp/help.php?target=mokuroku)7. 注意事項)に「「所蔵者・機関」については、『新纂禅籍目録』発刊(昭和37〔1962〕年)当時の情報そのままであり、現時点での所蔵確認は行っていない。その点を特にお断りするとともに、利用の際には十分に注意されるようお願いしたい」と記されるとおりである。
また『禅籍目録 電子版』には、「敦煌禅宗文献目録」および「禅籍抄物」のデータベースも搭載されている。このうち「敦煌禅宗文献目録」は、敦煌禅宗文献の名称とそれに該当する文書番号を検索するためのデータベースであり、田中良昭・程正編『敦煌禅宗文献分類目録』(大東出版社、2014年)をもとに、その後の研究成果も含めて構築されている(「敦煌禅宗文献目録 凡例」(https://zenseki.komazawa-u.ac.jp/help.php?target=tonko)参照)。一方、「禅籍抄物」データベースは順次コンテンツが整備されていくようであるが、目下、建仁寺塔頭両足院所蔵古典籍目録とその全頁画像が収録されている(「『禅籍目録 電子版』公開にあたって」(https://zenseki.komazawa-u.ac.jp/first.php)追記参照)。『新纂禅籍目録』とあわせて、これらを横断的に検索できるのも、本データベースの魅力である。
なお、「禅籍目録 電子版」とは直接は関係しないが、駒澤大学では「駒澤大学電子貴重書庫」(http://repo.komazawa-u.ac.jp/opac/repository/collections/?lang=0)が用意され、同大学図書館所蔵資料の一部が画像公開されている。閲覧を希望する写本・刊本が駒澤大学図書館に所蔵されていることがわかった場合には、当該本が画像公開されていないか、一度こちらの「駒澤大学電子貴重書庫」で確認するとよいであろう。
以上、『禅籍目録 電子版』について紹介した。当該データベース「禅籍目録 凡例」ページ(https://zenseki.komazawa-u.ac.jp/help.php?target=mokuroku)に「本サイトでは、『新纂禅籍目録』第一編未収分の禅籍について、今後増補を行っていく予定である。皆様からの禅籍等に関する情報提供を切にお願いしたい」とあるように、データベースの更なる増補が予定されているようである。今後、一層コンテンツが充実することを期待したい。
- コメントを投稿するにはログインしてください