人文情報学月報第140号【前編】
ISSN 2189-1621 / 2011年08月27日創刊
目次
【前編】
- 《巻頭言》「マルタ国立公文書館における二つのデジタルアーカイブ」
:東京大学文書館デジタルアーカイブ部門 - 《連載》「Digital Japanese Studies 寸見」第96回
「国文学研究資料館、日本古典籍総合目録データベースと新日本古典籍総合データベースを統合し、国書データベースとして公開」
:北海学園大学人文学部 - 《連載》「欧州・中東デジタル・ヒューマニティーズ動向」第57回
「GPT-4の登場と人文学テキスト資料の整理への応用」
:人間文化研究機構国立国語研究所研究系
【後編】
- 《連載》「デジタル・ヒストリーの小部屋」第14回
「デジタル・ヒストリーにおけるルクセンブルク大学のプレゼンス」
:千葉大学人文社会科学系教育研究機構 - 《連載》「仏教学のためのデジタルツール」第5回
「中華電子仏典協会(Chinese Buddhist Electronic Texts Association, CBETA)」
:日本学術振興会外国人特別研究員(駒澤大学) - 《特別寄稿》「チャーティスト運動と DH:政治集会地図製作プロジェクトの事例から」
:東京大学大学院 - 人文情報学イベント関連カレンダー
- イベントレポート「Tools of the Trade Conference 参加報告」
:一般財団法人人文情報学研究所 - 編集後記
《巻頭言》「マルタ国立公文書館における二つのデジタルアーカイブ」
直近の2023年3月にマルタ共和国(通称、マルタ)の国立公文書館(The National Archives of Malta(NAM))[1]を訪問し、資料調査等を行う機会があった。今回はその際に興味深く思った NAM の2つの試みについて紹介する。なお、参照したウェブサイトは全て2023年3月22日現在のものである。
マルタは、地中海に浮かぶ諸島で、シチリア島と北アフリカ沿岸の間に位置している。面積316平方キロメートル(淡路島の半分)で、人口約52万人の島国である[2]。NAMの本館は首都バレッタ(Valleta)の中心地より半径約15km 離れたラバト(Rabat)に所在しており、隣町のイムディーナ(Mdina)とゴゾ島(Gozo)にも閲覧室・事務所がある。NAM は、マルタの歴史に関する膨大な記録を保存、管理する政府機関の一つであり、一般利用者の研究のためにアーカイブズ資料を整理、公開している。NAM の使命は、国立公文書館法(CAP 477)[3]によって規定されたすべての公文書の保護と利用可能性(accessibility)を通じて、マルタ国民の集合的記憶を保存することである[4]。
NAMの公的記録の保存と公開
NAM には1530年代から現在に至るまで、マルタで最も大きなアーカイブズ・コレクションの一つが所蔵されており、書架延長約15kmの資料が保存されている。これにはそれぞれ約10,000枚の地図と写真コレクションが含まれており、その大部分はデジタル化されている。NAM にはマルタ政府の記録管理を担当する部門(Records Management Unit)があり、様々な省庁、部局、機関の記録保管所(records repositories)を継続的に訪問し、点検を実施している。適切な記録管理が実践できるように各事務局等を支援しながら、歴史的な記録を特定し、NAM への移管を計画、実施する[5]。
NAM に移管されたこれらの資料は、アーカイブズ資料の4つの国際記述標準に準拠したオープンソースソフトウェアのデジタルアーカイブアプリケーションAtoM(アトム)[6]を通じて検索、閲覧できる。NAMの所蔵資料のうち、1500年代から現代まで作成された資料群の目録124,437件と、デジタル化された文書と地図、写真データなど24,855件を閲覧することができる[7]。
NAM の民間資料の収集と保存、公開
NAM では、政府機関以外の個人や企業などからもマルタの歴史と共有の記憶に関係する貴重な資料を積極的に収集し、保存している。寄託、寄贈された多くの個人コレクションには、写真、個人的な手紙、計画書、記念品、マルタの伝統音楽など、様々なものが含まれている。
これらの資料とともに、特にオーラル、サウンド、ビジュアルのアーカイブも収集、整理、公開されている。2004年には、社会を構成する個々人の記憶や経験を通じてマルタの国民的記憶を保存し、普及させるために「国家記憶プロジェクト(National Memory Project, NMP)」が発足した。これに関連して、2016年には「オーラル、サウンド、ビジュアルアーカイブ(Arkivju Orali u Awdjoviżiv)」が設立された。NMP を引き継ぐ MEMORJA(メモリア)[8]は、2017年に発足した。オーラルヒストリー、民族誌(ethnography)、最先端のアーカイバルアプローチにおける高度な手法を用い、マルタの人々の個人の記憶、生活史、コミュニティの経験や伝統、共有された歴史的出来事の多様性を伝えるために、個人の記録を収集、記録、保存し、アクセスできるようにしている。
MEMORJA では、オーラルヒストリーの訓練を受けたスタッフとボランティアたちが継続的にコミュニティの中で民族誌的フィールド調査を行っている。マルタ大学の「公共記憶アーカイブ(PMA)[9]」との協業も行われている。MEMORJA で収集されたすべての資料は、ゴゾ館を中心にデジタル化され、保存、整理された後、ウェブサイトを通じて公開されている。MEMORJA のウェブサイトでは、市民参加型の資料整理・情報付与プロジェクトの「市民アーキビスト(Citizen Archivist)」の試みも行われている[10]。
これらの作業により、調査やオーラルヒストリーインタビューを行うフィールドワーカーたちが、地域社会のいたるところに存在することで、NAM は市民により認識されるようになり、その結果、NAM と一般市民との間に幅広い友情と独自の信頼関係が生まれたと評価されている。
NAM が公開する AtoM と MEMORJA の感想
今回はアーカイブズ資料を提供する側ではなく、一利用者として、NAM が提供する二つのデジタルアーカイブ、AtoM と MEMORJA 上で公開されている目録と、デジタル画像、インタビュー動画など各種メディアデータの閲覧を試してみた。
一言で言えば、現在どちらのシステムも安定的に資料提供ができておらず、アクセスしやすいとも言い難い。一時的な問題であろうが、特に AtoM はキーワード検索が正常に機能しない現象があり、階層のリンクが切れている箇所も見つかった。AtoM の熟練者ではない利用者に困惑の声も聞かれる「典拠レコードの登録と管理」面でも補完を必要とする点が多く見受けられる。これらの点については、NAM でもアーカイブズ資料目録の表現に問題があることを認識しており、検索しきれない目録については、館内のパソコンで従来のエクセルファイルでの検索を勧められた。しかし、「AtoM ユーザリスト」[11]に国立公文書館レベルのユーザがほとんど見られない中(自己登録制なので全てがリストされているわけではない)、マルタでは政府レベルの機関がオープンソースの利点とアーカイブズ資料の記述標準に準拠している点は注目に値する。AtoM を検索システムとして採用していたことに加えて、目録は基本的に ISAD(G)と ISARR(CPF)ベースのものであり、デジタル化資料の情報化はまだほとんど進んでいないが、今後、これらの問題をどのように対応していくか、期待しつつ見守っていきたい。
MEMORJA については、ウェブサイト上で画像資料の閲覧ができるものの、インタビューデータは「No Data」と表示されるか、再生できないものが多いようである。ログインしないと閲覧ができないのかと試してみたが、日本国内ではメールによる認証段階から次のステップには進めなかった。セキュリティの問題なのか、海外からの接続問題なのか、今は解決策がわからないため、「市民アーキビスト」機能を試すこともできなかった。「市民アーキビスト」のような機能はすでにアメリカや諸外国でも行われているが、デジタル化された資料にメタデータや人物情報、テキスト情報を付与することで、デジタル化資料の検索性と情報の共有が進むことに意義があると考える。もちろん、市民参加による記憶の共有と貢献、公文書館の社会的役割を再考するきっかけにもなる。
NAM では政府の公文書を検索、閲覧できるデジタルアーカイブ AtoM を運用しており、国や地域の記憶を共有し、後世に伝えるためにオーラルヒストリーと最新のデジタル技法を用いて MEMORJA を構築している。公文書のみならず、民間アーカイブズ資料の収集保存活動を支援し、オープンソースのデジタルアーカイブ技術を積極的に活用している NAM の活動を今後も参考にしたい。
執筆者プロフィール
《連載》「Digital Japanese Studies 寸見」第96回
「国文学研究資料館、日本古典籍総合目録データベースと新日本古典籍総合データベースを統合し、国書データベースとして公開」
国文学研究資料館(以下、同館)は、2023年2月27日、国書データベースの仮稼働を開始し、同月28日に日本古典籍総合目録データベース(および附随する館蔵和古書目録データベース)および新日本古典籍総合データベースの稼働を停止、同年3月1日より国書データベースの正式稼働を開始した[1][2][3]。2023年2月1日付で公表された同館のデータベース整理計画に沿ったものであり[4]、その中軸を担うものとして、従前の日本古典籍総合目録データベースと新日本古典籍総合データベースを統合して公開されたものである。
統合されたうちのひとつである日本古典籍総合目録データベースは、いわゆる「国書」(日本で著述された作品)のうち、慶応4年以前の書物の総合目録である『国書総目録』およびその増補である『古典籍総合目録』にもとづいて前世紀から運用がはじまり、2006年に日本古典籍総合目録データベースとしての運用が開始された、息の長い情報資源であった[5][6]。『源氏物語』などの著作や紫式部といった著者、そしてその明融本といった具体的な伝本を単位とする「書誌」という単位(著作・書誌といった単位については、[5]〜[9]の資料を参照)から検索する伝統的な目録データベースである。なお、漢籍は日本人の著作でなければ積極的には含めないが、和漢書として管理が一括されている場合などで、漢籍が含まれることも珍しくはないようである。また、日本古典籍総合目録データベースとともに統合された館蔵和古書目録データベースは、データ基盤としては日本古典籍総合目録データベースと共通で、同館所蔵の和漢書の検索に特化したデータベースであった[7]。
もう一方の新日本古典籍総合データベースは、同館の主導する大型研究プロジェクト「日本語の歴史的典籍の国際共同研究ネットワーク構築計画」において作成された国書の撮影画像を公開・活用することを企図して2017年に公開されたものであった[8][9]。「唯一の日本古典籍ポータルサイト」を標榜したのが国書データベースに引き継がれたのは、新日本古典籍総合データベースと国書データベースの関係の深さを示すものであろう。検索結果の安定性を重視する従来型の書誌検索システムが日本古典籍総合目録データベースだったとすれば、新日本古典籍総合データベースは、研究データとしての活用を促すべく IIIF での画像公開や DOI の附与を行い、またファセット検索を用いた絞り込み、全文やタグによる検索を取り入れたいわゆる次世代データベースになろうと思われる。データ基盤は、日本古典籍総合目録データベースと共通しており[9]、システムの違いに起因する使い勝手の違いから、検索には日本古典籍総合目録データベース、画像閲覧には新日本古典籍総合データベースといった使い分けもあったと聞く。新日本古典籍総合データベースは、画像の公開と活用が主眼にあったため、日本古典籍総合目録データベースと異なって著作単位での検索や閲覧が用意されていなかったのも大きな相違点である。
国書データベースは、そのような点で、新日本古典籍総合データベースを設計の基盤としながら、そこに著作や著者検索が付け加わったものと見受けられる[10]。トップページの画面を開くと、新日本古典籍総合データベースの構成を受け継いだ簡易検索があり、その下に日本古典籍総合目録データベースから受け継いだ単位ごとの詳細検索が設けられている。新日本古典籍総合データベースでは簡易検索の対象を全文検索やタグ検索などにトグルスイッチで絞るようになっていたものが、国書データベースでは、書誌・著作・著者から選ぶものとなっている。検索結果も全体的な印象は大きく変わらないが、ファセット検索の可能な範囲が狭められている。キーワード欄横の詳細検索を押すと、オプションが選べるようになり、画像の有無などによって結果を狭められるのは新日本古典籍総合データベースと同じ。ライセンスなど、検索できない項目があるのも同様に思われる(なお、東大図書館等、ライセンスを主張しない所蔵館の書誌詳細画面におけるライセンス表示が all rights reserved のままなのも残念ながら同じ)。書誌詳細画面は、新日本古典籍総合データベースと異なり、Mirador 3(新日本古典籍総合データベースでは Mirador 2だった)の画面が統合されていて、その下に詳細情報が提示される、いまどきの画面構成になっている。なお、請求票印刷画面など、館蔵和古書データベースの機能も若干取り込まれている。著作詳細画面は、言うまでもなく日本古典籍総合目録データベースにあったものである。これらの詳細画面における使い勝手は大きく変えないようにしてあるものと見受けられる。
使い勝手という点では、まだまだ改良の余地はあろうかと思われる(執筆時のものであるため、公表時にはすでに解消されている問題もあるだろう)。たとえば、画面の構成が新日本古典籍総合データベースを踏襲している結果、複雑化に追いつかず、扱いにくいものになっている。新日本古典籍総合データベースのようないわゆる Google ライクな検索画面は、検索対象をひとつに絞るからこそ成り立つのであって、書誌だけでなく著作検索や著者検索に、さらに画像タグ検索や本文検索も付け加わるような国書データベースでは限界がすぐ来てしまうのではないか(たとえば、いまのトップページのボタン配置において、「検索」ボタンと「書誌検索」以下の詳細検索ボタンとで動作が異なるのは利用者を驚かせてしまうと思う)。色使いなども拡張した部分の配色が一貫しておらず、初見で使いやすいものとなると今後よいと思われる。また、結果が膨大になる検索を行ったときに、数十秒待たされたりするのも(そのぶん、その後のページ遷移は待たされないが……)、そのような気になる点のひとつだろう。
日本古典籍総合目録データベースは、『古典籍総合目録』刊行からは30余年が経ち、日本の大学図書館の総合目録である NACSIS-CAT の古典籍の典拠のひとつともなるなど、公共性の高いデータベースである。名前としてはそちらを立ててはいるが、設計において新日本古典籍総合データベースの後継というべき国書データベースに統合されたいま、かつての日本古典籍総合目録データベースのドキュメンテーションが必要なのだろう(新日本古典籍総合データベースにかんする記録が、その最初形であるとはいえ、[9]において残されたように)。諸事情あるのだろうが、両者が1日しか併存していなかったことをふまえても、それを行うことができるのは同館だけの特権である。抜け道にしていた通路が塞がれるようなことは、所有者にとっては些事でも、通行人にとっては大きなことでありうるように、内部においてはなにげない変更も、外部においてはなにかをがらっと変えてしまうことはしばしばあることである。違いがどういうものであるかだけでも具体的に提供されれば、学界に裨益するところ大だと思うのである。
《連載》「欧州・中東デジタル・ヒューマニティーズ動向」第57回
「GPT-4の登場と人文学テキスト資料の整理への応用」
2023年3月13日~17日に、沖縄県宜野湾市の沖縄コンベンションセンターで言語処理学会第29回年次大会(NLP2023)[1]が開催された。1日目はチュートリアルとオープニングで、2日目から研究発表が始まった。参加者が1800名を超える大規模な学術大会であった。この大会の2日目の3月14日、本来は昼休みだった時間に、緊急パネルとして、昨年の11月30日に公開されてから、非常に話題となっているテキスト自動生成アプリの ChatGPT[2]に関するセッション「緊急パネル:ChatGPT で自然言語処理は終わるのか?」が行われた。ChatGPT は、アメリカ合衆国の企業 OpenAI が開発した大規模 AI モデルを用いており、英語や日本語などの自然言語を用いた命令(プロンプト)を入力すれば、それに応じたテキストが出力として返ってくる。プロンプトの分野もあらゆるものに対応可能であり、出力の形態も、単純なテキストの他に、表形式、Python などのプログラミング言語、HTML などのマークアップ言語、アスキーアート、文字だけで表現する樹形図など、様々な形式が可能である。よって、「○○学会の紹介文を書いてください」といった文章生成のプロンプト、「○○学会のホームページを作ってください」といった Web ページ(HTML 文書)生成のプロンプト、「このテキストから○○のデータを抜き出して、そのラベルと数値を表で出力してください」などの表生成のプロンプト、「以下の文章を要約してください」などの文章要約のプロンプト、自動翻訳など、様々なプロンプトが可能である。また、お悩み相談や何か良いアイデアはないか聞くなど、チャットで対話するロボット、すなわちチャットボットとしての使い方もできる。ChatGPT は、日本だけでなく、本連載がテーマとするヨーロッパおよび中東の、多くの現地の言語にも対応しており、様々なデジタルプロジェクトで大きな影響を与えつつあるので、本稿では、この ChatGPT について取り上げる。
GPT は、Generative Pretrained Transformer の略であり、2017年に発表された深層学習系で優れた成績を見せた Transformer を基にした大規模言語モデル(LLM)である。これは、大量のテキストデータを学習させたモデルであり、2019年に発表された GPT-2は優れた自動応答の性能で話題になった。さらに、2020年の GPT-3ではさらに大規模なテキストデータを学習し、より精度の高い回答が可能になった。2023年に発表され、ChatGPT に搭載された GPT-3.5 Turbo も、より応答の質などが向上した。しかし、生成された応答の文法面などには問題がないことが多いものの、それでも誤った知識に基づく回答が多く、時折みせる非倫理的な回答の自動生成も問題であった。この GPT-3.5 Turbo が搭載された ChatGPT は2022年11月30日にリリースされ、無料で使えることもあって爆発的な人気を博し、TikTok が9ヶ月、Instagram が2年半かかった1億人月間アクティブユーザーの集客をたった2ヶ月で達成した。その後、2023年2月1日に機能の制限が緩和され、応答速度が速い有料版である ChatGPT Plus が開始された。そして、2023年3月14日、ChatGPT Plus 上で、より大規模なデータで学習が行われた GPT-4がリリースされた。ChatGPT が誤った情報を出力する「幻覚性(ハルシネーション)」の問題はまだあるものの、その程度はより縮減され、さらに、非倫理的応答が生成されないよう倫理的なテキストの生成能力も向上した。何より、分野によっては決して完璧とは言えないものの、さらに精度が高いテキスト生成がなされるようになり、大変な話題となっている。GPT-4は、Microsoft Bing[3]や Microsoft Office(Microsoft 365 Copilot)[4]などにも搭載されている。
冒頭に述べた言語処理学会での「緊急パネル:ChatGPT で自然言語処理は終わるのか?」は、この GPT-4がリリースされる当日、そのリリース前になされた。ファシリテーターは乾健太郎氏(東北大/理研)、パネリストは、黒橋禎夫氏(京大)、相良美織氏(株式会社バオバブ)、佐藤敏紀氏(LINE株式会社)、 鈴木潤氏(東北大)、 谷中瞳氏(東大)と、アカデミアおよび産業界から自然言語処理の第一線で活躍する豪華な顔ぶれだった。筆者は、その直後に2つのポスター発表が控えていたため、このパネル全てに参加することはできなかったが、非常に示唆に富む議論が多かった。そこでは、幻覚性の問題、外部サービスから ChatGPT を使用できるようにする API に関する議論、倫理性に関わる問題など、様々な観点での議論があった。
そして、その夜、GPT-4がついに公開された。それまで、ChatGPT では GPT-3.5 Turbo が使われていた。しかし、今回新しく ChatGPT に搭載された GPT-4は、GPT-3.5 Turbo よりも遙かに大規模な教師データを学び、GPT-3.5 Turbo の8倍の長さの入力が可能になった。用いられているパラメータ数は不明であるが、数千億あるいは一兆の間だと予測される。GPT-3.5 Turbo に全米の模擬司法試験を解かせると、上位10%以下の成績であったところ、GPT-4では上位10%以内の成績を叩き出した[5]。本稿では NLP2023ワークショップ「深層学習時代の計算言語学」[6]で筆者が発表したアイヌ語-日本語自動翻訳[7]の教師データの作成に使用した、ChatGPT によるテキスト資料整理の効率化を紹介した後、ラテン語の文法解析と TEI XML 化の例をあげる。これらの例は、筆者が試してみて役に立つ可能性があると思った例であり、より良いプロンプトがある可能性と同じやり方でも異なる結果が出る可能性があることを断っておく。
図1は、アイヌ語から日本語に自動翻訳する AI モデルを作った際に、翻訳に適しているモデルである MarianMT に学習させるアイヌ語文と日本語訳のデータを「国立アイヌ民族博物館アイヌ語アーカイブ」やアイヌ民族文化財団が公開している教材からスクレイピングした後、整形するために使用したプロンプトである。このプロンプトは、GPT-3.5 Turbo でも GPT-4でも同様の性能であった。誤りはほぼなく、非常に有用なプロンプトであるが、ChatGPT の字数制限で大量のテキストを入力することは叶わなかった。API などで大量のテキストが入力できるようになれば、資料整理に大変有用であると思われる。

次に、ユリウス・カエサルが著したラテン語の『ガリア戦記』の序文を ChatGPT(GPT-4)に解析させ、語ごとに意味と文法情報を書くインターリニア表を作らせた(図2)。その後、このインターリニア表を、デジタル人文学のテキスト構造化の世界標準である TEI XML に書き直させた(図3)。
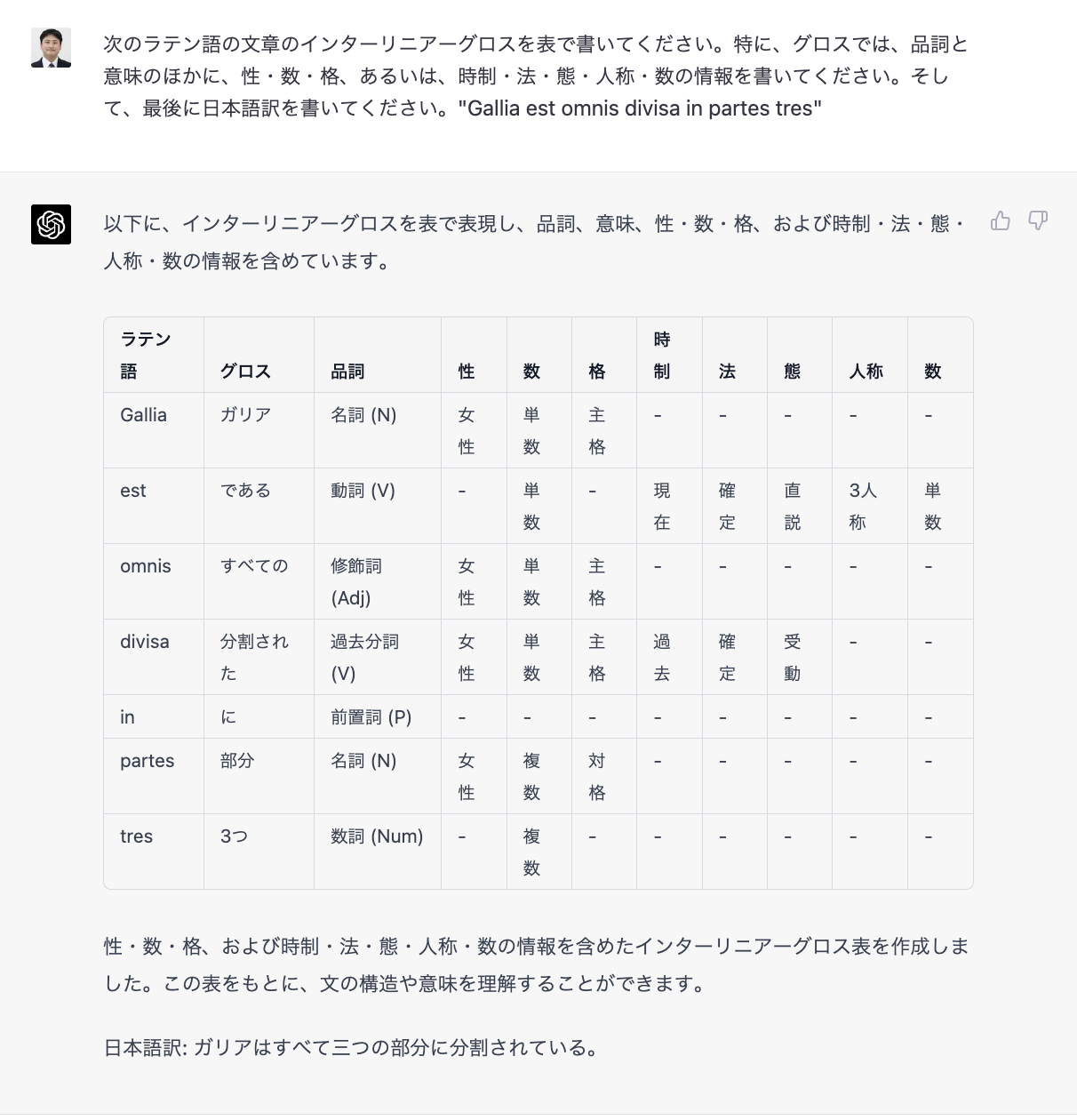
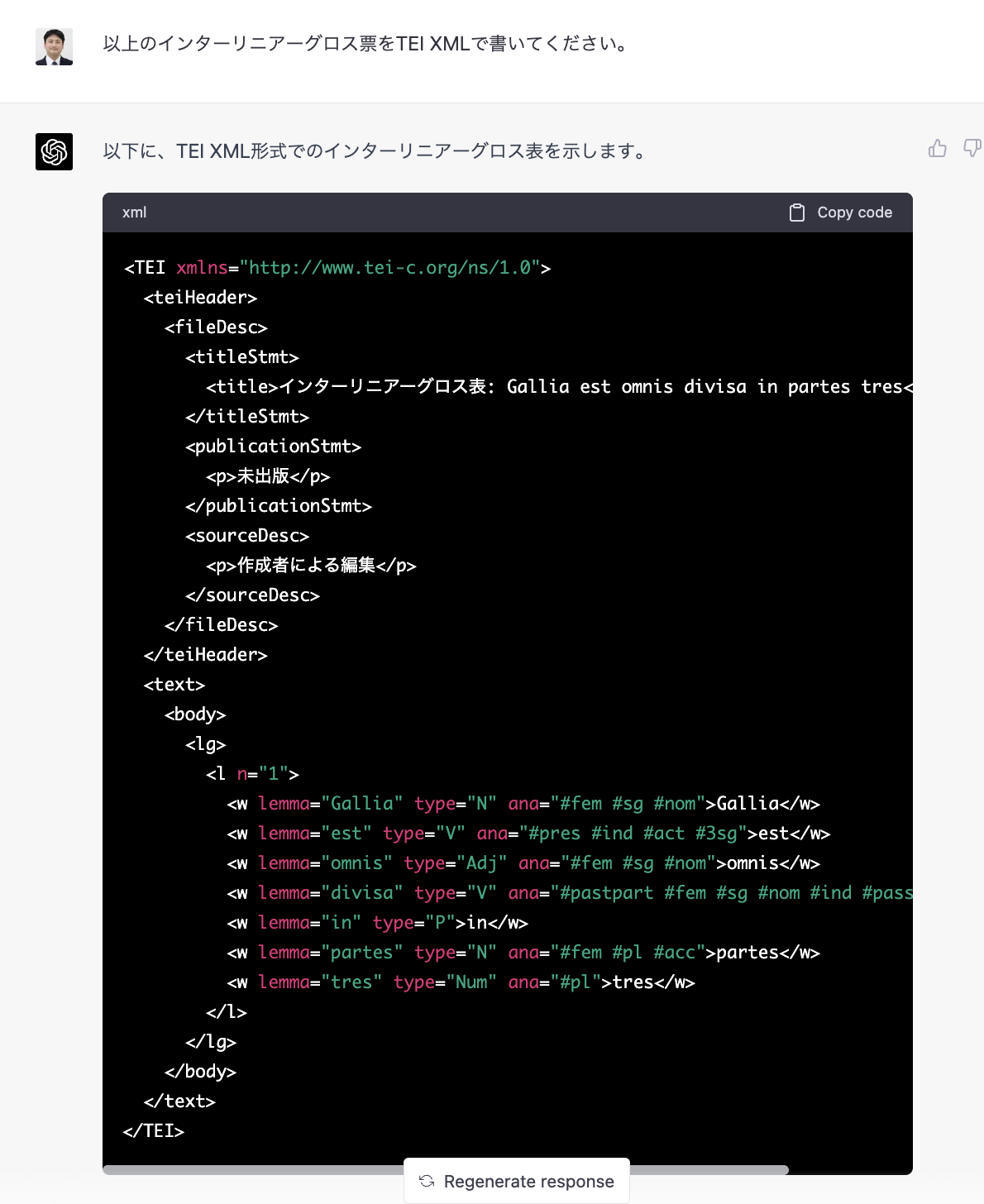
もちろん est の態が能動ではなく直説と書かれているのは、直説が存在するのは態ではなく法であるので、誤りであるが、その他は細かい点を除けば概ね良い結果であった。
このほかにも句構造文法による樹形図や Universal Dependencies による係り受け解析、国際音声字母による発音の精密表記をやらせたが、結果は場合によって精度は安定せず、半分以下から時には8割以上合っているという感触であった。しかし、GPT-4を使えば、精度は完璧ではなく生成される情報の信頼性に問題があるものの、すでに多彩な作業が自動で可能となっている。GPT-4 を完全に信頼すべきではないものの、精度が高まっていけば、資料整理など我々の複雑な作業を補助し、作業時間を短縮させるものになっていくと期待している。
- コメントを投稿するにはログインしてください